

Përshëndetje, Habr! Emri im është Maksim Vasilev, punoj si analist dhe menaxher projektesh në FINCH. Sot do të flas për how we were able to process 15 million requests in just 6 minutes and optimize daily loads on the website of one of our clients. Fatkeqësisht, do të duhet të kalojmë pa emra, sepse kemi një NDA, shpresojmë që përmbajtja e artikullit të mos ndikohet nga kjo. Le të fillojmë.
Si është organizuar projekti
Në backendin tonë ne krijojmë shërbime që sigurojnë funksionalitetin e faqeve të internetit dhe aplikacionit mobil të klientit tonë. Strukturën e përgjithshme mund ta shihni në diagram:
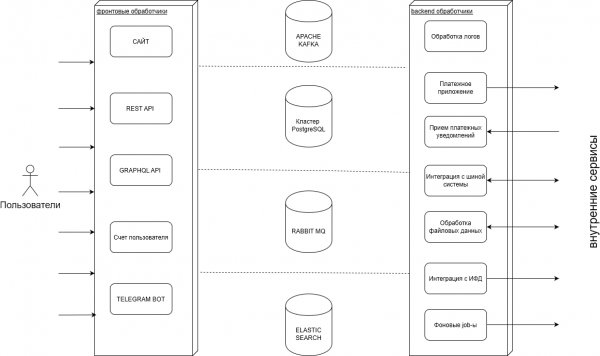
Gjatë punës, ne përpunojmë një sasi të madhe transaksionesh: blerjeve, pagesave, operacioneve me bilancet e përdoruesve, për të cilat ruajmë shumë skeda, si dhe importojmë dhe eksportojmë këto të dhëna në sisteme të jashtme.
Gjithashtu ndodhin procese të kundërta, kur ne marrim të dhëna nga klienti dhe i transferojmë ato tek përdoruesit. Përveç kësaj, ekzistojnë gjithashtu procese që lidhen me pagesat dhe programet e bonusit.
Një histori e shkurtër
Fillimi me një sistem të vetëm ruajtjeje të dhënash ishte PostgreSQL. Përfitimet e tij të zakonshme për DBMS: ekzistenca e transaksioneve, një gjuhë e zhvilluar për të zgjedhur të dhënat, një gamë e gjerë mjetesh për integrim; së bashku me një performancë të mirë, ata për një kohë të gjatë përmbushën nevojat tona.
Ne ruajtëm në Postgres të gjitha të dhënat: nga transaksionet te lajmet. Por numri i përdoruesve u rrit, siç u rrit edhe numri i kërkesave.
Për të kuptuar, numri vjetor i seancave në vitin 2017 vetëm në sitin desktop — 131 milion. Në vitin 2018 — 125 milion. Në vitin 2019 përsëri 130 milion. Shtoni atje edhe 100-200 milion nga versioni mobil i sitit dhe aplikacioni mobil dhe do të merrni një numër kolosal kërkesash.
Me rritjen e projektit, Postgres nuk mund të përballonte ngarkesën, ne nuk po arrinim — pati një numër të madh kërkesash të ndryshme për të cilat nuk arritëm të krijonim një numër të mjaftueshëm indekse.
E kuptuam se kishte një nevojë për depo të tjera të dhënash që do të përmbushnin nevojat tona dhe do të lehtësonin ngarkesën nga PostgreSQL. Si mundësi shqyrtuam Elasticsearch dhe MongoDB. E fundit humbte në disa pika:
- Shpejtësi e ngadaltë indeksoni me rritjen e volumit të të dhënave në indekset. Me Elastic, shpejtësia nuk varet nga volumi i të dhënave.
- Nuk ka kërkim me tekst të plotë
Kështu që ne zgjodhëm Elastic për veten tonë dhe u përgatitëm për kalim.
Kalimi në Elastic
1. Ne filluam kalimin nga shërbimi i kërkimit të pikave të shitjes. Klienti ynë ka gjithsej rreth 70,000 pika shitjeje dhe kërkohen disa lloje kërkimesh në sit dhe në aplikacion:
- Kërkimi tekstual sipas emrit të vendit
- Kërkimi gjeografik brenda një rrethi të caktuar nga një pikë. Për shembull, nëse përdoruesi dëshiron të shohë se cilat pika shitjeje janë më afër shtëpisë së tij.
- Kërkimi në një katror të caktuar – përdoruesi tërhiqet një katror mbi hartë dhe ai shfaqet të gjitha pikat në këtë rreth.
- Kërkimi sipas filtrave shtesë. Pikat e shitjes ndryshojnë nga njëra-tjetra sipas asortimentit.
Kur flasim për organizimin, në Postgres kemi burimin e të dhënave si për hartën, ashtu edhe për lajmet, ndërsa në Elastic bëhen Snapshot’ë nga të dhënat origjinale. Çështja është se fillimisht Postgres nuk përballonte me kërkimin sipas të gjithë kritereve. Jo vetëm që kishte shumë indekse, ato mund të përputheshin gjithashtu, prandaj planifikuesi i Postgres humbiste dhe nuk kuptonte se cili indeks duhet të përdorte.
2. Tjetra në rend ishte seksioni i lajmeve. Në faqe, çdo ditë publikohen artikuj, për të siguruar që përdoruesi të mos humbasë në rrjedhën e informacionit, të dhënat duhet të renditen para se të jepen. Për këtë është e nevojshme kërkimi: në faqe mund të kërkoni sipas përputhjes tekstuale, dhe për më tepër të lidhni filtre shtesë, pasi ato gjithashtu janë bërë përmes Elastic.
3. Më pas ne transferuam përpunimin e transaksioneve. Përdoruesit mund të blejnë një produkt të caktuar në faqe dhe të marrë pjesë në një tërheqje shpërblimesh. Pas këtyre blerjeve, ne përpunojmë një sasi të madhe të dhënash, veçanërisht gjatë fundjavave dhe festave. Për krahasim, në ditët e zakonshme numri i blerjeve është diku rreth 1.5-2 milion, ndërsa gjatë festave numri mund të arrijë deri në 53 milion.
Në këtë rast, të dhënat duhet të përpunohen në një kohë minimale - përdoruesit nuk e duan të presin disa ditë për rezultate. Me Postgres, nuk arrin dot një afat të tillë - shpesh kemi përjetuar bllokime, dhe përsa kohë përpunonim të gjitha kërkesat, përdoruesit nuk mund të kontrollonin nëse kishin marrë çmime apo jo. Kjo nuk është shumë e këndshme për biznesin, prandaj ne e kemi transferuar përpunimin në Elasticsearch.
Periudha
Tani, përditësimet janë të konfiguruara me ngjarje, sipas kushteve të mëposhtme:
- Pikat e Shkëmbimit. Sa herë që marrim të dhëna nga një burim të jashtëm, ne menjëherë fillojmë përditësimin.
- Lajmet. Sa herë që në sit redaktohet një lajm, ai automatikisht dërgohet në Elastic.
Këtu vlen të përmendim përsëri përfitimet e Elastic. Në Postgres, gjatë dërgimit të kërkesës, duhet të presësh ndërsa ai përpunon të gjitha regjistrimet. Në Elastic, mund të dërgosh 10,000 regjistrime dhe menjëherë të fillosh punën, pa pritur që regjistrimet të shpërndahen në të gjitha Shard-ët. Sigurisht, ndonjë Shard ose Replica mund të mos shohin të dhënat menjëherë, por shumë shpejt gjithçka do të jetë e disponueshme.
Metodat e integrimit
Ka 2 metoda integrimi me Elastic:
- Përmes klientit natyror për TCP. Drejtori natyror gradualisht po zhduket: nuk po mbështetet më, ka një sintaksë shumë të vështirë. Prandaj ne praktikisht nuk e përdorim dhe përpiqemi të heqim dorë nga ai.
- Përmes ndërfaqes HTTP, ku mund të përdorim si kërkesa JSON ashtu edhe sintaksën Lucene. E fundit është një motor tekstual që përdor Elastic. Në këtë variant, ne kemi mundësinë e Batch përmes kërkesave JSON për HTTP. Ky është variant që përpiqemi ta përdorim.
Falë ndërfaqes HTTP ne mund të përdorim biblioteka që ofrojnë një implementim asinkron të HTTP klientit. Ne mund të shfrytëzojmë avantazhin e Batch dhe API-së asinkrone, që në fund ofron performancë të lartë, e cila na ndihmoi shumë në ditët e aksioneve të mëdha (për këtë më poshtë).
Pak numra për krahasim:
- Ruajtja e përdoruesve që morën çmime në Postgres në 20 thread pa grumbullime: 460713 regjistrime për 42 sekonda.
- Elastic + klient reaktiv në 10 thread + batch në 1000 elemente: 596749 regjistrime për 11 sekonda.
- Elastic + klient reaktiv në 10 thread + batch në 1000 elemente: 23801684 regjistrime për 4 minuta.
Tani kemi shkruar një menaxher kërkesash HTTP, i cili ndalon JSON, si Batch/nuk Batch dhe dërgon përmes çdo klienti HTTP pavarësisht nga biblioteka. Po ashtu, mund të zgjidhet dërgimi sinhron ose asinkron i kërkesave.
Në disa integrime ne ende përdorim klientin zyrtar të transportit, por kjo është një çështje e ristrukturimit të afërt. Megjithatë, për përpunimin përdoret klienti ynë, i ndërtuar mbi bazën e Spring WebClient.
Promocion i madh
Një herë në vit, në projekt zhvillohet një promovim i madh për përdoruesit — ky është ai Highload, sepse në këtë kohë ne punojmë me miliona përdorues njëkohësisht.
Zakonisht, peaks e ngarkesave ndodhin gjatë festave, por ky promovim është një nivel krejt tjetër. Dy vite më parë, në ditën e promovimit shitëm 27 580 890 njësi të mallrave. Të dhënat u përpunuan për më shumë se një gjysmë ore, duke shkaktuar shqetësim te përdoruesit. Përdoruesit morën çmime për pjesëmarrje, por u bë e qartë se procesi duhet të përshpejtohet.
Në fillim të vitit 2019, ne vendosëm që na duhej ElasticSearch. Për një vit organizuam përpunimin e të dhënave të marra në Elastic dhe shpërndarjen e tyre në API-në e aplikacionit mobil dhe në sit. Në fund, gjatë vitit të ardhshëm gjatë një fushate ne përpunuam 15 131 783 regjistrime brenda 6 minutash.
Duke qenë se kemi shumë të interesuar për të blerë produkte dhe për të marrë pjesë në shpërblime gjatë fushatave, kjo është një masë përkohësore. Tani ne dërgojmë informacionin e saktë në Elastic, por në të ardhmen planifikojmë të transferojmë informacionin arkivor nga muajt e kaluar në Postgres, si një depo të përhershme. Për të mos mbushur indeksin Elastic, i cili gjithashtu ka kufizimet e tij.
Përfundimi/konkluzionet
Derimë tani, ne kemi transferuar në Elastic të gjitha shërbimet që dëshironim dhe për këtë arsye kemi bërë një pauzë. Tani ne po ndërtojmë një indeks në Elastic mbi depozitimin kryesor të përhershëm në Postgres, i cili merr ngarkesën e përdoruesve.
Në të ardhmen planifikojmë të transferojmë shërbimet nëse kuptojmë që kërkesa për të dhëna bëhet shumë e ndryshme dhe kërkohet në një numër të papërcaktuar kolonash. Kjo tashmë është një detyrë jo për Postgres.
Если нам будет нужен полнотекстовый поиск в функционале или если у нас появится много разнообразных критериев поиска то мы уже знаем, что это нужно переводить в Elastic.
⌘⌘⌘
Спасибо, что прочитали. Если у вас в компании тоже используются ElasticSearch и есть собственные кейсы реализации, то расскажите. Будет интересно узнать как у других 🙂
Burimi: habr.com
