

Unë ju sugjeroj të lexoni transkriptin e raportit nga Alexey Lesovsky nga Data Egret "Bazat e monitorimit PostgreSQL"
Në këtë raport, Alexey Lesovsky do të flasë për pikat kyçe të statistikave të post-gresit, çfarë nënkuptojnë ato dhe pse ato duhet të jenë të pranishme në monitorim; se çfarë grafikë duhet të jenë në monitorim, si t'i shtoni dhe si t'i interpretoni ato. Raporti do të jetë i dobishëm për administratorët e bazës së të dhënave, administratorët e sistemit dhe zhvilluesit që janë të interesuar për zgjidhjen e problemeve të Postgres.


Emri im është Alexey Lesovsky, unë përfaqësoj kompaninë Data Egret.
Disa fjalë për veten time. Kam filluar shumë kohë më parë si administrator sistemi.
Administroi të gjitha llojet e gjërave të ndryshme Linux, ishte i përfshirë në gjëra të ndryshme që lidheshin me Linux, d.m.th., virtualizimi, monitorimi, puna me proxy, etj. Por në një moment, fillova të punoja më shumë me bazat e të dhënave, PostgreSQL. Më pëlqeu shumë. Dhe në një moment, fillova ta kaloja pjesën më të madhe të kohës duke punuar me PostgreSQL. Dhe kështu, gradualisht, u bëra një DBA i PostgreSQL.
Dhe gjatë gjithë karrierës sime, gjithmonë kam qenë i interesuar për temat e statistikave, monitorimit dhe telemetrisë. Dhe kur isha administrator sistemi, kam punuar shumë ngushtë me Zabbix. Dhe unë shkrova një grup të vogël skenarësh si Ishte mjaft popullor në kohën e tij. Dhe atje mund të monitoroje shumë gjëra të rëndësishme, jo vetëm Linux, por edhe komponentë të ndryshëm.
Tani jam duke punuar në PostgreSQL. Unë tashmë po shkruaj një gjë tjetër që ju lejon të punoni me statistikat PostgreSQL. Quhet (artikull në Habré - ).

Një shënim i vogël hyrës. Çfarë situatash kanë klientët tanë, klientët tanë? Ka një lloj aksidenti që lidhet me bazën e të dhënave. Dhe kur databaza është restauruar tashmë, shefi i departamentit ose shefi i zhvillimit vjen dhe thotë: "Miq, duhet të monitorojmë bazën e të dhënave, sepse ka ndodhur diçka e keqe dhe duhet të parandalojmë që kjo të ndodhë në të ardhmen." Dhe këtu fillon procesi interesant i zgjedhjes së një sistemi monitorimi ose përshtatjes së një sistemi ekzistues monitorimi në mënyrë që të mund të monitoroni bazën tuaj të të dhënave - PostgreSQL, MySQL ose disa të tjerë. Dhe kolegët fillojnë të sugjerojnë: "Kam dëgjuar që ka një bazë të dhënash të tillë dhe të tillë. Le ta përdorim atë." Kolegët fillojnë të debatojnë me njëri-tjetrin. Dhe në fund rezulton se ne zgjedhim një lloj bazë të dhënash, por monitorimi PostgreSQL paraqitet në të mjaft dobët dhe gjithmonë duhet të shtojmë diçka. Merrni disa depo nga GitHub, klononi ato, përshtatni skriptet dhe disi personalizoni ato. Dhe në fund përfundon të jetë një lloj pune manuale.

Prandaj, në këtë bisedë do të përpiqem t'ju jap disa njohuri se si të zgjidhni monitorimin jo vetëm për PostgreSQL, por edhe për bazën e të dhënave. Dhe t'ju japë njohuri që do t'ju lejojë të përfundoni monitorimin tuaj në mënyrë që të përfitoni prej tij, në mënyrë që të monitoroni me përfitim bazën tuaj të të dhënave, në mënyrë që të parandaloni menjëherë çdo situatë emergjente të ardhshme që mund të lindë.
Dhe idetë që do të jenë në këtë raport mund të përshtaten drejtpërdrejt në çdo bazë të dhënash, qoftë ajo një DBMS ose noSQL. Prandaj, nuk ka vetëm PostgreSQL, por do të ketë shumë receta se si ta bëni këtë në PostgreSQL. Do të ketë shembuj të pyetjeve, shembuj të entiteteve që PostgreSQL ka për monitorim. Dhe nëse DBMS-ja juaj ka të njëjtat gjëra që ju lejojnë t'i vendosni ato në monitorim, mund t'i përshtatni ato, t'i shtoni dhe do të jetë mirë.
 Unë nuk do të jem në raport
Unë nuk do të jem në raport
flisni për mënyrën e dorëzimit dhe ruajtjes së matjeve. Nuk do të them asgjë në lidhje me përpunimin e mëposhtëm të të dhënave dhe paraqitjen e tyre tek përdoruesi. Dhe nuk do të them asgjë për paralajmërimin.
Por ndërsa historia përparon, unë do të tregoj pamje të ndryshme të monitorimit ekzistues dhe do t'i kritikoj disi ato. Por sidoqoftë, do të përpiqem të mos emërtoj marka që të mos krijoj reklamë apo antireklamim për këto produkte. Prandaj, të gjitha rastësitë janë të rastësishme dhe janë lënë në imagjinatën tuaj.

Së pari, le të kuptojmë se çfarë është monitorimi. Monitorimi është një gjë shumë e rëndësishme. Të gjithë e kuptojnë këtë. Por në të njëjtën kohë, monitorimi nuk lidhet me një produkt biznesi dhe nuk ndikon drejtpërdrejt në fitimin e kompanisë, kështu që koha i ndahet gjithmonë monitorimit në bazë të mbetur. Nëse kemi kohë, atëherë bëjmë monitorim; nëse nuk kemi kohë, atëherë OK, do ta fusim atë në prapavijë dhe një ditë do t'u kthehemi këtyre detyrave.
Prandaj, nga praktika jonë, kur vijmë te klientët, shpeshherë monitorimi është jo i plotë dhe nuk ka ndonjë gjë interesante që do të na ndihmonte të bënim një punë më të mirë me bazën e të dhënave. Dhe për këtë arsye monitorimi gjithmonë duhet të përfundojë.
Bazat e të dhënave janë gjëra kaq komplekse që duhet gjithashtu të monitorohen, sepse bazat e të dhënave janë një depo informacioni. Dhe informacioni është shumë i rëndësishëm për kompaninë, ai nuk mund të humbet në asnjë mënyrë. Por në të njëjtën kohë, bazat e të dhënave janë pjesë shumë komplekse të softuerit. Ato përbëhen nga një numër i madh komponentësh. Dhe shumë prej këtyre komponentëve duhet të monitorohen.
 Nëse po flasim në mënyrë specifike për PostgreSQL, atëherë ai mund të përfaqësohet në formën e një skeme që përbëhet nga një numër i madh komponentësh. Këta komponentë ndërveprojnë me njëri-tjetrin. Dhe në të njëjtën kohë, PostgreSQL ka të ashtuquajturin nënsistemi Stats Collector, i cili ju lejon të mbledhni statistika në lidhje me funksionimin e këtyre nënsistemeve dhe t'i ofroni një lloj ndërfaqeje administratorit ose përdoruesit në mënyrë që ai të mund t'i shikojë këto statistika.
Nëse po flasim në mënyrë specifike për PostgreSQL, atëherë ai mund të përfaqësohet në formën e një skeme që përbëhet nga një numër i madh komponentësh. Këta komponentë ndërveprojnë me njëri-tjetrin. Dhe në të njëjtën kohë, PostgreSQL ka të ashtuquajturin nënsistemi Stats Collector, i cili ju lejon të mbledhni statistika në lidhje me funksionimin e këtyre nënsistemeve dhe t'i ofroni një lloj ndërfaqeje administratorit ose përdoruesit në mënyrë që ai të mund t'i shikojë këto statistika.
Këto statistika paraqiten në formën e një grupi të caktuar funksionesh dhe pamjesh. Ato mund të quhen edhe tabela. Kjo do të thotë, duke përdorur një klient të rregullt psql, mund të lidheni me bazën e të dhënave, të bëni një përzgjedhje për këto funksione dhe pamje dhe të merrni disa numra specifikë në lidhje me funksionimin e nënsistemeve PostgreSQL.
Ju mund t'i shtoni këto numra në sistemin tuaj të preferuar të monitorimit, të vizatoni grafikë, të shtoni funksione dhe të merrni analitikë në planin afatgjatë.
Por në këtë raport nuk do t'i mbuloj plotësisht të gjitha këto funksione, sepse mund të zgjasë gjithë ditën. Do të trajtoj fjalë për fjalë dy, tre ose katër gjëra dhe do t'ju tregoj se si ato ndihmojnë në përmirësimin e monitorimit.

Dhe nëse flasim për monitorimin e bazës së të dhënave, atëherë çfarë duhet të monitorohet? Para së gjithash, ne duhet të monitorojmë disponueshmërinë, sepse baza e të dhënave është një shërbim që ofron qasje në të dhëna për klientët dhe ne duhet të monitorojmë disponueshmërinë, si dhe të ofrojmë disa nga karakteristikat e saj cilësore dhe sasiore.

Ne gjithashtu duhet të monitorojmë klientët që lidhen me bazën tonë të të dhënave, sepse ata mund të jenë klientë normalë dhe klientë të dëmshëm që mund të dëmtojnë bazën e të dhënave. Ata gjithashtu duhet të monitorohen dhe të gjurmohen aktivitetet e tyre.

Kur klientët lidhen me bazën e të dhënave, është e qartë se ata fillojnë të punojnë me të dhënat tona, kështu që ne duhet të monitorojmë se si klientët punojnë me të dhënat: me cilat tabela, dhe në një masë më të vogël, me cilët indekse. Kjo do të thotë, ne duhet të vlerësojmë ngarkesën e punës që krijohet nga klientët tanë.

Por ngarkesa e punës përbëhet, natyrisht, edhe nga kërkesat. Aplikacionet lidhen me bazën e të dhënave, aksesojnë të dhënat duke përdorur pyetje, kështu që është e rëndësishme të vlerësojmë se çfarë pyetjesh kemi në bazën e të dhënave, të monitorojmë përshtatshmërinë e tyre, që ato të mos jenë të shkruara shtrembër, që disa opsione duhet të rishkruhen dhe të bëhen në mënyrë që të funksionojnë më shpejt. dhe me performancë më të mirë.

Dhe meqenëse po flasim për një bazë të dhënash, baza e të dhënave është gjithmonë procese në sfond. Proceset e sfondit ndihmojnë në ruajtjen e performancës së bazës së të dhënave në një nivel të mirë, kështu që ata kërkojnë një sasi të caktuar burimesh për veten e tyre për të operuar. Dhe në të njëjtën kohë, ato mund të mbivendosen me burimet e kërkesave të klientit, kështu që proceset e pangopura të sfondit mund të ndikojnë drejtpërdrejt në performancën e kërkesave të klientit. Prandaj, ato gjithashtu duhet të monitorohen dhe gjurmohen në mënyrë që të mos ketë shtrembërime për sa i përket proceseve të sfondit.

Dhe e gjithë kjo për sa i përket monitorimit të bazës së të dhënave mbetet në metrikën e sistemit. Por duke pasur parasysh se shumica e infrastrukturës sonë po lëviz drejt reve, metrikat e sistemit të një hosti individual gjithmonë zbehen në sfond. Por në bazat e të dhënave ato janë ende relevante dhe, natyrisht, është gjithashtu e nevojshme të monitorohen metrikat e sistemit.

Gjithçka është pak a shumë mirë me matjet e sistemit, të gjitha sistemet moderne të monitorimit tashmë i mbështesin këto metrika, por në përgjithësi, disa komponentë ende nuk janë të mjaftueshëm dhe disa gjëra duhet të shtohen. Unë gjithashtu do t'i prek ato, do të ketë disa rrëshqitje rreth tyre.

Pika e parë e planit është aksesueshmëria. Çfarë është aksesueshmëria? Disponueshmëria në kuptimin tim është aftësia e bazës për të shërbyer lidhjet, pra baza është ngritur, ajo, si shërbim, pranon lidhje nga klientët. Dhe kjo aksesueshmëri mund të vlerësohet nga disa karakteristika. Është shumë i përshtatshëm për të shfaqur këto karakteristika në pult.

Të gjithë e dinë se çfarë janë panelet. Kjo është kur i hodhët një sy ekranit në të cilin përmblidhen informacionet e nevojshme. Dhe menjëherë mund të përcaktoni nëse ka ndonjë problem në bazën e të dhënave apo jo.
Prandaj, disponueshmëria e bazës së të dhënave dhe karakteristikat e tjera kyçe duhet të shfaqen gjithmonë në panelet e kontrollit, në mënyrë që ky informacion të jetë në dispozicion dhe gjithmonë i disponueshëm për ju. Disa detaje shtesë që tashmë ndihmojnë në hetimin e incidenteve, kur hetohen disa situata emergjente, ato tashmë duhet të vendosen në tabelat dytësore, ose të fshihen në lidhjet e analizës që çojnë në sistemet e monitorimit të palëve të treta.
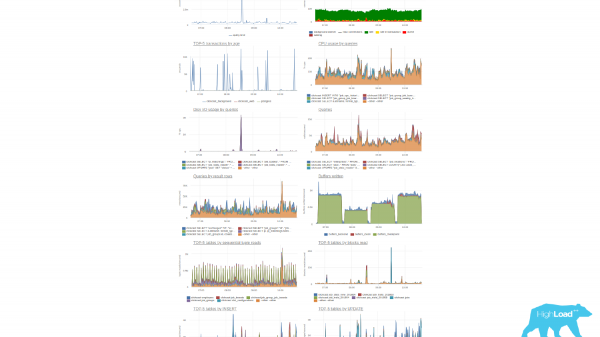
Një shembull i një sistemi të mirënjohur monitorimi. Ky është një sistem monitorimi shumë i lezetshëm. Ajo mbledh shumë të dhëna, por nga këndvështrimi im, ajo ka një koncept të çuditshëm të paneleve. Ekziston një lidhje për "krijoni një panel kontrolli". Por kur krijoni një pult, krijoni një listë me dy kolona, një listë grafikësh. Dhe kur duhet të shikoni diçka, filloni të klikoni me miun, të lëvizni, të kërkoni grafikun e dëshiruar. Dhe kjo kërkon kohë, d.m.th. nuk ka pult si të tillë. Ka vetëm lista të grafikëve.

Çfarë duhet të shtoni në këto tabela? Mund të filloni me një karakteristikë të tillë si koha e përgjigjes. PostgreSQL ka pamjen pg_stat_statements. Ai është i çaktivizuar si parazgjedhje, por është një nga pamjet e rëndësishme të sistemit që duhet të aktivizohet dhe përdoret gjithmonë. Ai ruan informacione për të gjitha pyetjet e ekzekutuara që janë ekzekutuar në bazën e të dhënave.
Prandaj, mund të nisemi nga fakti se mund të marrim kohën totale të ekzekutimit të të gjitha kërkesave dhe ta ndajmë atë me numrin e kërkesave duke përdorur fushat e mësipërme. Por kjo është temperatura mesatare në spital. Mund të fillojmë nga fusha të tjera - koha minimale e ekzekutimit të pyetjes, maksimumi dhe mesatarja. Dhe ne mund të ndërtojmë edhe përqindje; PostgreSQL ka funksionet përkatëse për këtë. Dhe ne mund të marrim disa numra që karakterizojnë kohën e përgjigjes së bazës sonë të të dhënave për kërkesat tashmë të përfunduara, d.m.th. ose një figurë më vete, ose ndërtojmë një grafik bazuar në të.
Është gjithashtu e rëndësishme të monitorohet numri i gabimeve që gjenerohen aktualisht nga sistemi. Dhe për këtë ju mund të përdorni pamjen pg_stat_database. Ne fokusohemi në fushën xact_rollback. Kjo fushë tregon jo vetëm numrin e rikthimeve që ndodhin në bazën e të dhënave, por gjithashtu merr parasysh numrin e gabimeve. Duke folur relativisht, ne mund ta shfaqim këtë shifër në pultin tonë dhe të shohim se sa gabime kemi aktualisht. Nëse ka shumë gabime, atëherë kjo është një arsye e mirë për të parë në regjistrat dhe për të parë se çfarë lloj gabimesh janë dhe pse ndodhin, dhe më pas investoni dhe zgjidhni ato.

Ju mund të shtoni një gjë të tillë si një tahometër. Këto janë numri i transaksioneve për sekondë dhe numri i kërkesave për sekondë. Relativisht, ju mund t'i përdorni këta numra si performancën aktuale të bazës së të dhënave tuaja dhe të vëzhgoni nëse ka maksimumin e kërkesave, maksimumin në transaksione ose, anasjelltas, nëse baza e të dhënave është e nënngarkuar sepse një pjesë e pasme ka dështuar. Është e rëndësishme të shikojmë gjithmonë këtë shifër dhe të kujtojmë se për projektin tonë kjo lloj performancë është normale, por vlerat lart dhe poshtë janë tashmë një lloj problematike dhe të pakuptueshme, që do të thotë se duhet të shohim pse janë këto shifra. aq i lartë.
Për të vlerësuar numrin e transaksioneve, mund t'i referohemi përsëri pamjes pg_stat_database. Mund të shtojmë numrin e angazhimeve dhe numrin e rikthimeve dhe të marrim numrin e transaksioneve për sekondë.
A e kuptojnë të gjithë se disa kërkesa mund të përshtaten në një transaksion? Prandaj, TPS dhe QPS janë paksa të ndryshme.
Numri i kërkesave për sekondë mund të merret nga pg_stat_statements dhe thjesht të llogaritet shuma e të gjitha kërkesave të përfunduara. Është e qartë se ne krahasojmë vlerën aktuale me atë të mëparshme, e zbresim atë, marrim deltën dhe marrim sasinë.

Ju mund të shtoni metrikë shtesë nëse dëshironi, të cilat gjithashtu ndihmojnë në vlerësimin e disponueshmërisë së bazës së të dhënave tona dhe monitorimin nëse ka pasur ndonjë ndërprerje.
Një nga këto metrika është koha e funksionimit. Por koha e funksionimit në PostgreSQL është pak e ndërlikuar. Unë do t'ju them pse. Kur PostgreSQL ka filluar, koha e funksionimit fillon të raportojë. Por nëse në një moment, për shembull, një detyrë po ekzekutohej natën, erdhi një vrasës OOM dhe ndërpreu me forcë procesin e fëmijës PostgreSQL, atëherë në këtë rast PostgreSQL ndërpret lidhjen e të gjithë klientëve, rivendos zonën e memories së copëtuar dhe fillon rikuperimin nga pika e fundit e kontrollit. Dhe përderisa ky rikuperim nga pika e kontrollit zgjat, baza e të dhënave nuk pranon lidhje, pra kjo situatë mund të vlerësohet si joproduktive. Por numëruesi i kohës së funksionimit nuk do të rivendoset, sepse merr parasysh kohën e fillimit të postmasterit që në momentin e parë. Prandaj, situata të tilla mund të anashkalohen.
Ju gjithashtu duhet të monitoroni numrin e punëtorëve me vakum. A e dinë të gjithë se çfarë është autovakum në PostgreSQL? Ky është një nënsistem interesant në PostgreSQL. Për të janë shkruar shumë artikuj, janë bërë shumë raporte. Ka shumë diskutime rreth vakumit dhe si duhet të funksionojë. Shumë e konsiderojnë atë një të keqe të domosdoshme. Por kështu është. Ky është një lloj analog i një grumbulluesi mbeturinash që pastron versionet e vjetruara të rreshtave që nuk nevojiten nga asnjë transaksion dhe liron hapësirë në tabela dhe indekse për rreshtat e rinj.
Pse keni nevojë ta monitoroni atë? Sepse vakuumi ndonjëherë dhemb shumë. Ai konsumon një sasi të madhe burimesh dhe kërkesat e klientëve fillojnë të vuajnë si rezultat.
Dhe duhet të monitorohet përmes pamjes pg_stat_activity, për të cilën do të flas në pjesën tjetër. Kjo pamje tregon aktivitetin aktual në bazën e të dhënave. Dhe përmes këtij aktiviteti ne mund të gjurmojmë numrin e vakuumeve që po funksionojnë tani. Ne mund të gjurmojmë vakuumet dhe të shohim që nëse e kemi tejkaluar kufirin, atëherë kjo është një arsye për të parë cilësimet e PostgreSQL dhe për të optimizuar disi funksionimin e vakumit.
Një tjetër gjë në lidhje me PostgreSQL është se PostgreSQL është shumë i sëmurë nga transaksionet e gjata. Sidomos nga transaksionet që rrinë për një kohë të gjatë dhe nuk bëjnë asgjë. Ky është i ashtuquajturi stat idle-in-transaction. Një transaksion i tillë mban bravë dhe parandalon funksionimin e vakumit. Dhe si rezultat, tavolinat fryhen dhe rriten në madhësi. Dhe pyetjet që funksionojnë me këto tabela fillojnë të funksionojnë më ngadalë, sepse ju duhet të hiqni të gjitha versionet e vjetra të rreshtave nga memoria në disk dhe mbrapa. Prandaj, koha, kohëzgjatja e transaksioneve më të gjata, kërkesat më të gjata të vakumit gjithashtu duhet të monitorohen. Dhe nëse shohim disa procese që kanë funksionuar për një kohë shumë të gjatë, tashmë më shumë se 10-20-30 minuta për një ngarkesë OLTP, atëherë duhet t'u kushtojmë vëmendje atyre dhe t'i mbyllim ato me forcë, ose të optimizojmë aplikacionin në mënyrë që ato nuk thirren dhe mos rri kaq gjatë. Për një ngarkesë analitike, 10-20-30 minuta është normale, ka edhe më të gjata.

Më pas kemi opsionin me klientët e lidhur. Kur kemi krijuar tashmë një panel kontrolli dhe kemi postuar matjet kryesore të disponueshmërisë në të, mund të shtojmë gjithashtu informacione shtesë për klientët e lidhur atje.
Informacioni rreth klientëve të lidhur është i rëndësishëm sepse, nga një këndvështrim PostgreSQL, klientët janë të ndryshëm. Ka klientë të mirë dhe ka klientë të këqij.
Një shembull i thjeshtë. Nga klienti e kuptoj aplikacionin. Aplikacioni është lidhur me bazën e të dhënave dhe menjëherë fillon dërgimin e kërkesave të tij atje, baza e të dhënave i përpunon dhe i ekzekuton ato dhe i kthen rezultatet te klienti. Këta janë klientë të mirë dhe korrekt.
Ka situata kur klienti është lidhur, e mban lidhjen, por nuk bën asgjë. Është në gjendje boshe.
Por ka klientë të këqij. Për shembull, i njëjti klient u lidh, hapi një transaksion, bëri diçka në bazën e të dhënave dhe më pas hyri në kod, për shembull, për të hyrë në një burim të jashtëm ose për të përpunuar të dhënat e marra atje. Por ai nuk e mbylli transaksionin. Dhe transaksioni varet në bazën e të dhënave dhe mbahet në një bllokim në linjë. Kjo është një gjendje e keqe. Dhe nëse papritmas një aplikacion diku brenda vetes dështon me një përjashtim, atëherë transaksioni mund të mbetet i hapur për një kohë shumë të gjatë. Dhe kjo ndikon drejtpërdrejt në performancën e PostgreSQL. PostgreSQL do të jetë më i ngadalshëm. Prandaj, është e rëndësishme të gjurmohen klientët e tillë në kohën e duhur dhe të ndërpritet me forcë puna e tyre. Dhe ju duhet të optimizoni aplikacionin tuaj në mënyrë që situata të tilla të mos ndodhin.
Klientë të tjerë të këqij janë klientë në pritje. Por ata bëhen të këqij për shkak të rrethanave. Për shembull, një transaksion i thjeshtë boshe: ai mund të hapë një transaksion, të marrë bllokime në disa rreshta, pastaj diku në kod do të dështojë, duke lënë një transaksion të varur. Një klient tjetër do të vijë dhe do të kërkojë të njëjtat të dhëna, por ai do të ndeshet me një bllokim, sepse ai transaksion i varur tashmë mban bravë në disa rreshta të kërkuar. Dhe transaksioni i dytë do të rrijë duke pritur që transaksioni i parë të përfundojë ose ta mbyllë me forcë nga administratori. Prandaj, transaksionet në pritje mund të grumbullohen dhe plotësojnë kufirin e lidhjes së bazës së të dhënave. Dhe kur kufiri është i plotë, aplikacioni nuk mund të funksionojë më me bazën e të dhënave. Kjo tashmë është një situatë emergjente për projektin. Prandaj, klientët e këqij duhet të gjurmohen dhe të përgjigjen në kohën e duhur.
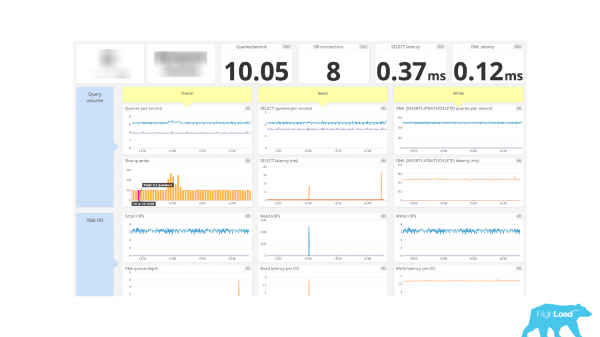
Një shembull tjetër i monitorimit. Dhe tashmë ka një pult të mirë këtu. Ka informacione për lidhjet e mësipërme. Lidhja DB - 8 copë. Dhe është e gjitha. Ne nuk kemi informacion se cilët klientë janë aktivë, cilët klientë janë thjesht të papunë, duke mos bërë asgjë. Nuk ka asnjë informacion për transaksionet në pritje dhe lidhjet në pritje, domethënë kjo është një shifër që tregon numrin e lidhjeve dhe kaq. Dhe pastaj merrni me mend vetë.

Prandaj, për të shtuar këtë informacion në monitorim, duhet të hyni në pamjen e sistemit pg_stat_activity. Nëse kaloni shumë kohë në PostgreSQL, atëherë kjo është një pamje shumë e mirë që duhet të bëhet miku juaj, sepse tregon aktivitetin aktual në PostgreSQL, pra çfarë po ndodh në të. Për secilin proces ka një linjë të veçantë që tregon informacione rreth këtij procesi: nga cili host është bërë lidhja, me cilin përdorues, me çfarë emri, kur ka filluar transaksioni, çfarë kërkese është aktualisht në ekzekutim, çfarë kërkese është ekzekutuar për herë të fundit. Dhe, në përputhje me rrethanat, ne mund të vlerësojmë gjendjen e klientit duke përdorur fushën stat. Duke folur relativisht, ne mund të grupojmë sipas kësaj fushe dhe të marrim ato statistika që janë aktualisht në bazën e të dhënave dhe numrin e lidhjeve që kanë këtë statistikë në bazën e të dhënave. Dhe ne mund t'i dërgojmë numrat e marrë tashmë në monitorimin tonë dhe të nxjerrim grafikët në bazë të tyre.
Është gjithashtu e rëndësishme të vlerësohet kohëzgjatja e transaksionit. Tashmë thashë se është e rëndësishme të vlerësohet kohëzgjatja e vakumeve, por transaksionet vlerësohen në të njëjtën mënyrë. Ka fushat xact_start dhe query_start. Ata, duke folur relativisht, tregojnë kohën e fillimit të transaksionit dhe kohën e fillimit të kërkesës. Marrim funksionin now(), i cili tregon vulën kohore aktuale, dhe zbresim transaksionin dhe vulën kohore të kërkesës. Dhe marrim kohëzgjatjen e transaksionit, kohëzgjatjen e kërkesës.
Nëse shohim transaksione të gjata, duhet t'i kryejmë ato tashmë. Për një ngarkesë OLTP, transaksionet e gjata janë tashmë më shumë se 1-2-3 minuta. Për një ngarkesë pune OLAP, transaksionet e gjata janë normale, por nëse duhen më shumë se dy orë për t'u përfunduar, atëherë kjo është gjithashtu një shenjë se ne kemi një anim diku.

Pasi klientët janë lidhur me bazën e të dhënave, ata fillojnë të punojnë me të dhënat tona. Ata hyjnë në tabela, ata aksesojnë indekset për të marrë të dhëna nga tabela. Dhe është e rëndësishme të vlerësohet se si klientët ndërveprojnë me këto të dhëna.
Kjo është e nevojshme për të vlerësuar ngarkesën tonë të punës dhe për të kuptuar përafërsisht se cilat tabela janë "më të nxehta" për ne. Për shembull, kjo është e nevojshme në situatat kur duam të vendosim tabela "të nxehta" në një lloj ruajtjeje të shpejtë SSD. Për shembull, disa tabela arkivore që nuk i kemi përdorur për një kohë të gjatë mund të zhvendosen në një lloj arkivi "të ftohtë", në disqet SATA dhe t'i lini të jetojnë atje, ato do të aksesohen sipas nevojës.
Kjo është gjithashtu e dobishme për zbulimin e anomalive pas çdo lëshimi dhe vendosjeje. Le të themi se projekti ka lëshuar disa veçori të reja. Për shembull, ne shtuam funksionalitet të ri për të punuar me bazën e të dhënave. Dhe nëse vizatojmë grafikët e përdorimit të tabelës, ne mund t'i zbulojmë lehtësisht këto anomali në këta grafikë. Për shembull, përditësoni shpërthimet ose fshini shpërthimet. Do të jetë shumë e dukshme.
Ju gjithashtu mund të zbuloni anomali në statistikat "lundruese". Çfarë do të thotë? PostgreSQL ka një programues shumë të fortë dhe shumë të mirë të pyetjeve. Dhe zhvilluesit i kushtojnë shumë kohë zhvillimit të tij. Si punon ai? Për të bërë plane të mira, PostgreSQL mbledh statistika mbi shpërndarjen e të dhënave në tabela në një interval të caktuar kohor dhe me një frekuencë të caktuar. Këto janë vlerat më të zakonshme: numri i vlerave unike, informacioni për NULL në tabelë, shumë informacione.
Bazuar në këto statistika, planifikuesi ndërton disa pyetje, zgjedh atë më optimalin dhe përdor këtë plan pyetësor për të ekzekutuar vetë pyetjen dhe për të kthyer të dhënat.
Dhe ndodh që statistikat "lundrojnë". Të dhënat cilësore dhe sasiore ndryshuan disi në tabelë, por statistikat nuk u mblodhën. Dhe planet e formuara mund të mos jenë optimale. Dhe nëse planet tona rezultojnë jooptimale në bazë të monitorimeve të mbledhura, në bazë të tabelave, ne do të mund të shohim këto anomali. Për shembull, diku të dhënat ndryshuan cilësisht dhe në vend të indeksit, filloi të përdoret një kalim sekuencial përmes tabelës, d.m.th. nëse një pyetje duhet të kthejë vetëm 100 rreshta (ka një kufi prej 100), atëherë do të kryhet një kërkim i plotë për këtë pyetje. Dhe kjo gjithmonë ka një efekt shumë të keq në performancën.
Dhe këtë mund ta shohim në monitorim. Dhe tashmë shikoni këtë pyetje, bëni një shpjegim për të, mblidhni statistika, ndërtoni një indeks të ri shtesë. Dhe tashmë i përgjigjeni këtij problemi. Kjo është arsyeja pse është e rëndësishme.
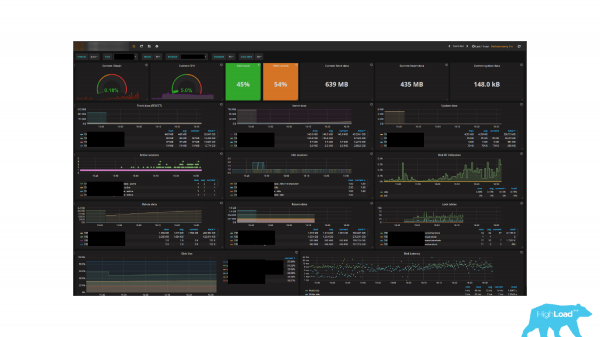
Një shembull tjetër i monitorimit. Mendoj se shumë njerëz e njohën sepse është shumë popullor. Të cilët e përdorin atë në projektet e tyre ? Kush e përdor këtë produkt në lidhje me Prometheus? Fakti është se në depon standarde të këtij monitorimi ekziston një pult për të punuar me PostgreSQL - Prometeu. Por ka një detaj të keq.
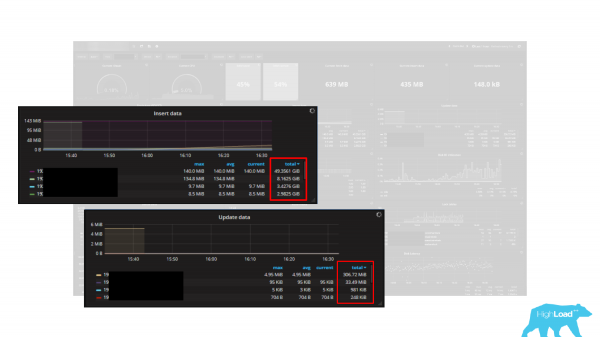
Ka disa grafikë. Dhe bajtët tregohen si unitet, d.m.th. ka 5 grafikë. Këto janë Futja e të dhënave, Përditësimi i të dhënave, Fshija e të dhënave, Marrja e të dhënave dhe Kthimi i të dhënave. Matja e njësisë është bajt. Por gjëja është se statistikat në PostgreSQL kthejnë të dhënat në tufa (rreshta). Dhe, në përputhje me rrethanat, këta grafikë janë një mënyrë shumë e mirë për të nënvlerësuar ngarkesën tuaj të punës disa herë, dhjetëra herë, sepse një tuple nuk është një bajt, një tuple është një varg, është shumë bajt dhe është gjithmonë me gjatësi të ndryshueshme. Kjo do të thotë, llogaritja e ngarkesës në bajt duke përdorur tuple është një detyrë joreale ose shumë e vështirë. Prandaj, kur përdorni një panel kontrolli ose monitorim të integruar, është gjithmonë e rëndësishme të kuptoni se funksionon si duhet dhe ju kthen të dhënat e vlerësuara saktë.

Si të merrni statistika në këto tabela? Për këtë qëllim, PostgreSQL ka një familje të caktuar pikëpamjesh. Dhe pamja kryesore është . User_tables - kjo do të thotë tabela të krijuara në emër të përdoruesit. Në të kundërt, ka pamje të sistemit që përdoren nga vetë PostgreSQL. Dhe ekziston një tabelë përmbledhëse Alltables, e cila përfshin si ato të sistemit ashtu edhe ato të përdoruesit. Mund të filloni nga cilido prej tyre që ju pëlqen më shumë.
Duke përdorur fushat e mësipërme mund të vlerësoni numrin e futjeve, përditësimeve dhe fshirjeve. Shembulli i një pulti që përdora përdor këto fusha për të vlerësuar karakteristikat e një ngarkese pune. Prandaj, ne gjithashtu mund të ndërtojmë mbi to. Por ia vlen të kujtojmë se këto janë tuple, jo byte, kështu që ne nuk mund ta bëjmë atë vetëm në bajt.
Bazuar në këto të dhëna, ne mund të ndërtojmë të ashtuquajturat tabela TopN. Për shembull, Top-5, Top-10. Dhe mund të gjurmoni ato tavolina të nxehta që riciklohen më shumë se të tjerët. Për shembull, 5 tabela "të nxehta" për futje. Dhe duke përdorur këto tabela TopN ne vlerësojmë ngarkesën tonë të punës dhe mund të vlerësojmë shpërthimet e ngarkesës pas çdo lëshimi, përditësimi dhe vendosjeje.
Është gjithashtu e rëndësishme të vlerësohet madhësia e tabelës, sepse ndonjëherë zhvilluesit nxjerrin një veçori të re dhe tabelat tona fillojnë të rriten në madhësitë e tyre të mëdha, sepse ata vendosën të shtojnë një sasi shtesë të dhënash, por nuk parashikuan se si do të ndikojnë në madhësinë e bazës së të dhënave. Raste të tilla na vijnë edhe befasi.

Dhe tani një pyetje e vogël për ju. Çfarë pyetje lind kur vëreni ngarkesën në serverin tuaj të bazës së të dhënave? Cila është pyetja tjetër që keni?

Por në fakt pyetja lind si më poshtë. Çfarë kërkesash shkakton ngarkesa? Kjo do të thotë, nuk është interesante të shikosh proceset që shkaktohen nga ngarkesa. Është e qartë se nëse hosti ka një bazë të dhënash, atëherë baza e të dhënave funksionon atje dhe është e qartë se vetëm bazat e të dhënave do të hidhen atje. Nëse hapim Top, do të shohim atje një listë të proceseve në PostgreSQL që po bëjnë diçka. Nga Top-i nuk do të jetë e qartë se çfarë po bëjnë.

Prandaj, ju duhet të gjeni ato pyetje që shkaktojnë ngarkesën më të lartë, sepse akordimi i pyetjeve, si rregull, jep më shumë fitim sesa akordimi i PostgreSQL ose konfigurimi i sistemit operativ, apo edhe akordimi i harduerit. Sipas vlerësimit tim, kjo është afërsisht 80-85-90%. Dhe kjo bëhet shumë më shpejt. Është më shpejt të korrigjoni një kërkesë sesa të korrigjoni konfigurimin, të planifikoni një rinisje, veçanërisht nëse baza e të dhënave nuk mund të riniset ose të shtoni pajisje. Është më e lehtë të rishkruash pyetjen diku ose të shtosh një indeks për të marrë një rezultat më të mirë nga kjo pyetje.
Prandaj, është e nevojshme të monitorohen kërkesat dhe përshtatshmëria e tyre. Le të marrim një shembull tjetër të monitorimit. Dhe këtu, gjithashtu, duket se ka një monitorim të shkëlqyer. Ka informacion mbi replikimin, ka informacion mbi xhiros, bllokimin, përdorimin e burimeve. Gjithçka është në rregull, por nuk ka asnjë informacion për kërkesat. Nuk është e qartë se cilat pyetje janë duke u ekzekutuar në bazën tonë të të dhënave, sa kohë janë duke u ekzekutuar, sa prej këtyre pyetjeve janë. Ne gjithmonë duhet ta kemi këtë informacion në monitorimin tonë.

Dhe për të marrë këtë informacion mund të përdorim modulin pg_stat_statements. Bazuar në të, ju mund të ndërtoni një sërë grafikësh. Për shembull, mund të merrni informacion për pyetjet më të shpeshta, domethënë për ato pyetje që ekzekutohen më shpesh. Po, pas vendosjeve është gjithashtu shumë e dobishme ta shikoni atë dhe të kuptoni nëse ka ndonjë rritje të kërkesave.
Ju mund të monitoroni pyetjet më të gjata, domethënë ato pyetje që kërkojnë më shumë kohë për t'u përfunduar. Ata funksionojnë në procesor, ata konsumojnë I/O. Ne gjithashtu mund ta vlerësojmë këtë duke përdorur fushat total_time, mean_time, blk_write_time dhe blk_read_time.
Ne mund të vlerësojmë dhe monitorojmë kërkesat më të rënda për sa i përket përdorimit të burimeve, ato që lexojnë nga disku, që punojnë me memorie ose, anasjelltas, krijojnë një lloj ngarkese shkrimi.
Ne mund të vlerësojmë kërkesat më bujare. Këto janë pyetjet që kthejnë një numër të madh rreshtash. Për shembull, kjo mund të jetë një kërkesë ku ata harruan të vendosnin një kufi. Dhe thjesht kthen të gjithë përmbajtjen e tabelës ose pyetjes nëpër tabelat e kërkuara.
Dhe gjithashtu mund të monitoroni pyetjet që përdorin skedarë të përkohshëm ose tabela të përkohshme.

Dhe ne kemi ende procese në sfond. Proceset e sfondit janë kryesisht pika kontrolli ose quhen gjithashtu pika kontrolli, këto janë autovakum dhe përsëritje.
Një shembull tjetër i monitorimit. Ekziston një skedë Mirëmbajtja në të majtë, shkoni tek ajo dhe shpresoni të shihni diçka të dobishme. Por këtu është vetëm koha e funksionimit të vakumit dhe mbledhjes së statistikave, asgjë më shumë. Ky është informacion shumë i dobët, kështu që ne gjithmonë duhet të kemi informacion se si funksionojnë proceset e sfondit në bazën tonë të të dhënave dhe nëse ka ndonjë problem nga puna e tyre.

Kur shikojmë pikat e kontrollit, duhet të kujtojmë se pikat e kontrollit shpëlajnë faqet e ndotura nga zona e memories së copëtuar në disk dhe më pas krijojnë një pikë kontrolli. Dhe kjo pikë kontrolli mund të përdoret më pas si një vend për rikuperim nëse PostgreSQL u ndërpre papritur në rast urgjence.
Prandaj, në mënyrë që të fshini të gjitha faqet "të pista" në disk, duhet të bëni një sasi të caktuar shkrimi. Dhe, si rregull, në sistemet me sasi të mëdha memorie, kjo është shumë. Dhe nëse bëjmë pika kontrolli shumë shpesh në një interval të shkurtër, atëherë performanca e diskut do të bjerë shumë ndjeshëm. Dhe kërkesat e klientëve do të vuajnë nga mungesa e burimeve. Ata do të konkurrojnë për burime dhe do të kenë mungesë produktiviteti.
Prandaj, përmes pg_stat_bgwriter duke përdorur fushat e specifikuara ne mund të monitorojmë numrin e pikave të kontrollit që ndodhin. Dhe nëse kemi shumë pika kontrolli për një periudhë të caktuar kohore (në 10-15-20 minuta, në gjysmë ore), për shembull, 3-4-5, atëherë kjo tashmë mund të jetë një problem. Dhe tashmë duhet të shikoni në bazën e të dhënave, të shikoni në konfigurim, çfarë shkakton një bollëk të tillë pikash kontrolli. Ndoshta po ndodh një lloj regjistrimi i madh. Tashmë mund të vlerësojmë ngarkesën e punës, sepse tashmë kemi shtuar grafikët e ngarkesës. Tashmë mund të rregullojmë parametrat e pikës së kontrollit dhe të sigurohemi që ato të mos ndikojnë shumë në performancën e pyetjes.

Po i kthehem përsëri autovakumit sepse është një gjë e tillë, siç thashë, që mund të shtojë lehtësisht performancën e diskut dhe pyetjes, kështu që është gjithmonë e rëndësishme të vlerësohet sasia e autovakumit.
Numri i punonjësve të autovakumit në bazën e të dhënave është i kufizuar. Si parazgjedhje, ka tre prej tyre, kështu që nëse kemi gjithmonë tre punëtorë që punojnë në bazën e të dhënave, kjo do të thotë që autovakuumi ynë nuk është i konfiguruar, duhet të rrisim kufijtë, të rishikojmë cilësimet e autovakumit dhe të futemi në konfigurim.
Është e rëndësishme të vlerësojmë se cilët punëtorë vakum kemi. Ose ishte nisur nga përdoruesi, DBA erdhi dhe lëshoi manualisht një lloj vakumi, dhe kjo krijoi një ngarkesë. Kemi një lloj problemi. Ose ky është numri i vakumeve që zhvidhosin numëruesin e transaksioneve. Për disa versione të PostgreSQL këto janë vakum shumë të rënda. Dhe ata mund të shtojnë lehtësisht performancën sepse lexojnë të gjithë tabelën, skanojnë të gjitha blloqet në atë tabelë.
Dhe, natyrisht, kohëzgjatja e vakumeve. Nëse kemi vakum afatgjatë që funksionojnë për një kohë shumë të gjatë, atëherë kjo do të thotë që përsëri duhet t'i kushtojmë vëmendje konfigurimit të vakumit dhe ndoshta të rishqyrtojmë cilësimet e tij. Sepse mund të krijohet një situatë kur vakuumi punon në tavolinë për një kohë të gjatë (3-4 orë), por gjatë kohës që vakuumi punonte, një sasi e madhe rreshtash të vdekur arritën të grumbulloheshin përsëri në tryezë. Dhe sapo të përfundojë vakuumi, ai duhet ta pastrojë përsëri këtë tryezë. Dhe ne vijmë në një situatë - një vakum të pafund. Dhe në këtë rast, vakuumi nuk e përballon punën e tij, dhe tabelat gradualisht fillojnë të rriten në madhësi, megjithëse vëllimi i të dhënave të dobishme në të mbetet i njëjtë. Prandaj, gjatë vakumeve të gjata, ne gjithmonë shikojmë konfigurimin dhe përpiqemi ta optimizojmë atë, por në të njëjtën kohë në mënyrë që performanca e kërkesave të klientit të mos pësojë.

Në ditët e sotme nuk ka praktikisht asnjë instalim PostgreSQL që të mos ketë përsëritje të transmetimit. Replikimi është procesi i zhvendosjes së të dhënave nga një master në një kopje.
Replikimi në PostgreSQL bëhet përmes një regjistri transaksionesh. Magjistari gjeneron një regjistër transaksionesh. Regjistri i transaksioneve udhëton përmes lidhjes së rrjetit tek replika, dhe më pas riprodhohet në kopje. Është e thjeshtë.
Prandaj, pamja pg_stat_replication përdoret për të monitoruar vonesën e riprodhimit. Por jo gjithçka është e thjeshtë me të. Në versionin 10, pamja ka pësuar disa ndryshime. Së pari, disa fusha janë riemërtuar. Dhe disa fusha janë shtuar. Në versionin 10, u shfaqën fusha që ju lejojnë të vlerësoni vonesën e përsëritjes në sekonda. Është shumë komode. Përpara versionit 10, ishte e mundur të vlerësohej vonesa e replikimit në bajt. Ky opsion mbetet në versionin 10, d.m.th. ju mund të zgjidhni atë që është më e përshtatshme për ju - vlerësoni vonesën në bajt ose vlerësoni vonesën në sekonda. Shumë njerëz i bëjnë të dyja.
Por megjithatë, për të vlerësuar vonesën e përsëritjes, duhet të dini pozicionin e regjistrit në transaksion. Dhe këto pozicione të regjistrit të transaksioneve janë pikërisht në pamjen pg_stat_replication. Duke folur relativisht, ne mund të marrim dy pika në regjistrin e transaksioneve duke përdorur funksionin pg_xlog_location_diff(). Llogaritni deltën midis tyre dhe merrni vonesën e replikimit në bajt. Është shumë i përshtatshëm dhe i thjeshtë.
Në versionin 10, ky funksion u riemërua në pg_wal_lsn_diff(). Në përgjithësi, në të gjitha funksionet, pamjet dhe shërbimet ku u shfaq fjala "xlog", ajo u zëvendësua me vlerën "wal". Kjo vlen si për pamjet ashtu edhe për funksionet. Kjo është një risi e tillë.
Plus, në versionin 10, u shtuan linja që tregojnë në mënyrë specifike vonesën. Këto janë vonesa e shkrimit, vonesa e rrjedhjes, vonesa e riprodhimit. Kjo është, është e rëndësishme të monitorohen këto gjëra. Nëse shohim që kemi një vonesë replikimi, atëherë duhet të hetojmë pse u shfaq, nga erdhi dhe të rregullojmë problemin.

Pothuajse gjithçka është në rregull me matjet e sistemit. Kur fillon çdo monitorim, ai fillon me matjet e sistemit. Kjo është asgjësimi i procesorëve, kujtesës, shkëmbimit, rrjetit dhe diskut. Megjithatë, shumë parametra nuk janë aty si parazgjedhje.
Nëse gjithçka është në rregull me procesin e riciklimit, atëherë ka probleme me riciklimin e diskut. Si rregull, zhvilluesit e monitorimit shtojnë informacione rreth xhiros. Mund të jetë në iops ose bytes. Por ata harrojnë vonesën dhe përdorimin e pajisjeve të diskut. Këta janë parametra më të rëndësishëm që na lejojnë të vlerësojmë se sa të ngarkuar janë disqet tanë dhe sa të ngadalshëm janë. Nëse kemi vonesë të lartë, atëherë kjo do të thotë se ka disa probleme me disqet. Nëse kemi përdorim të lartë, do të thotë që disqet nuk po përballen. Këto janë karakteristika më të mira se xhiroja.
Për më tepër, këto statistika mund të merren edhe nga sistemi i skedarëve /proc, siç bëhet për përpunuesit e riciklimit. Nuk e di pse ky informacion nuk i shtohet monitorimit. Por megjithatë, është e rëndësishme ta keni këtë në monitorimin tuaj.
E njëjta gjë vlen edhe për ndërfaqet e rrjetit. Ka informacione rreth xhiros së rrjetit në pako, në bajt, por megjithatë nuk ka informacion për vonesën dhe asnjë informacion rreth përdorimit, megjithëse ky është gjithashtu informacion i dobishëm.

Çdo monitorim ka të meta. Dhe pavarësisht se çfarë lloj monitorimi do të bëni, ai gjithmonë nuk do të plotësojë disa kritere. Por megjithatë, ato po zhvillohen, veçori të reja dhe gjëra të reja po shtohen, kështu që zgjidhni diçka dhe përfundoni atë.
Dhe për të përfunduar, duhet të keni gjithmonë një ide se çfarë nënkuptojnë statistikat e dhëna dhe si mund t'i përdorni ato për të zgjidhur problemet.
Dhe disa pika kryesore:
- Gjithmonë duhet të monitoroni disponueshmërinë dhe të keni panele kontrolli në mënyrë që të vlerësoni shpejt se gjithçka është në rregull me bazën e të dhënave.
- Ju gjithmonë duhet të keni një ide se çfarë po punojnë klientët me bazën e të dhënave tuaja në mënyrë që të eliminoni klientët e këqij dhe t'i rrëzoni ata.
- Është e rëndësishme të vlerësohet se si këta klientë punojnë me të dhënat. Ju duhet të keni një ide për ngarkesën tuaj të punës.
- Është e rëndësishme të vlerësohet se si formohet kjo ngarkesë pune, me ndihmën e çfarë pyetjesh. Ju mund të vlerësoni pyetjet, mund t'i optimizoni ato, t'i rifaktoroni, të ndërtoni indekse për to. Eshte shume e rendesishme.
- Proceset në sfond mund të ndikojnë negativisht në kërkesat e klientit, prandaj është e rëndësishme të monitorohet që ata të mos përdorin shumë burime.
- Metrikat e sistemit ju lejojnë të bëni plane për shkallëzimin dhe rritjen e kapacitetit të serverëve tuaj, kështu që është e rëndësishme t'i gjurmoni dhe vlerësoni gjithashtu.

Nëse jeni të interesuar për këtë temë, atëherë mund të ndiqni këto lidhje.
- ky është dokumentacion zyrtar nga mbledhësi i statistikave. Ekziston një përshkrim i të gjitha pamjeve statistikore dhe një përshkrim i të gjitha fushave. Ju mund t'i lexoni, kuptoni dhe analizoni ato. Dhe bazuar në to, ndërtoni grafikët tuaj dhe shtoni ato në monitorimin tuaj.
Shembuj të kërkesave:
Kjo është depoja jonë e korporatës dhe e imja. Ato përmbajnë pyetje shembull. Nuk ka pyetje nga të përzgjedhurit* nga seritë atje. Tashmë ka pyetje të gatshme me bashkime, duke përdorur funksione interesante që ju lejojnë të ktheni numrat e papërpunuar në vlera të lexueshme, të përshtatshme, d.m.th., këto janë bajt, kohë. Ju mund t'i zgjidhni, t'i shikoni, t'i analizoni, t'i shtoni ato në monitorimin tuaj, të ndërtoni monitorimin tuaj bazuar në to.
Pyetjet tuaja
Pyetje: Ju thatë që nuk do të reklamoni markat, por unë jam ende kurioz - çfarë lloj panelesh përdorni në projektet tuaja?
Përgjigje: Ai ndryshon. Ndodh që ne vijmë te një klient dhe ai tashmë ka monitorimin e tij. Dhe ne e këshillojmë klientin se çfarë duhet të shtohet në monitorimin e tyre. Situata më e keqe është me Zabbix. Sepse nuk ka aftësinë për të ndërtuar grafikë TopN. Ne vetë përdorim , sepse ishim duke u konsultuar me këta djem për monitorimin. Ata monitoruan PostgreSQL bazuar në specifikimet tona teknike. Unë jam duke shkruar projektin tim për kafshët shtëpiake, i cili mbledh të dhëna nëpërmjet Prometheus dhe i jep ato në . Detyra ime është të krijoj eksportuesin tim në Prometheus dhe më pas të jap gjithçka në Grafana.
Pyetje: A ka analoge të raporteve AWR apo... grumbullim? A dini për diçka të tillë?
Përgjigje: Po, e di se çfarë është AWR, është një gjë e lezetshme. Për momentin ka një shumëllojshmëri biçikletash që zbatojnë afërsisht modelin e mëposhtëm. Në një interval kohor, disa vija bazë shkruhen në të njëjtën PostgreSQL ose në një ruajtje të veçantë. Mund t'i kërkoni në google në internet, ata janë atje. Një nga zhvilluesit e një gjëje të tillë është ulur në forumin sql.ru në temën PostgreSQL. Mund ta kapni atje. Po, ka gjëra të tilla, ato mund të përdoren. Plus në të Po shkruaj gjithashtu një gjë që ju lejon të bëni të njëjtën gjë.
PS1 Nëse përdorni postgres_exporter, çfarë paneli po përdorni? Ka disa prej tyre. Ata tashmë janë të vjetëruar. Ndoshta komuniteti do të krijojë një shabllon të përditësuar?
PS2 u hoq pganalyze sepse është një ofertë e pronarit SaaS e cila fokusohet në monitorimin e performancës dhe sugjerimet e automatizuara të akordimit.
Vetëm përdoruesit e regjistruar mund të marrin pjesë në anketë. , te lutem
Cilin monitorim postgresql të vetë-pritur (me pult) e konsideroni më të mirën?
30,0%Zabbix + shtesa nga Alexey Lesovsky ose zabbix 4.4 ose libzbxpgsql + zabbix libzbxpgsql + zabbix3
0,0%https://github.com/lesovsky/pgcenter0
0,0%https://github.com/pg-monz/pg_monz0
20,0%https://github.com/cybertec-postgresql/pgwatch22
20,0%https://github.com/postgrespro/mamonsu2
0,0%https://www.percona.com/doc/percona-monitoring-and-management/conf-postgres.html0
10,0%pganalyze është një SaaS e pronarit - nuk mund ta fshij1
10,0%https://github.com/powa-team/powa1
0,0%https://github.com/darold/pgbadger0
0,0%https://github.com/darold/pgcluu0
0,0%https://github.com/zalando/PGObserver0
10,0%https://github.com/spotify/postgresql-metrics1
10 përdorues votuan. 26 përdorues abstenuan.
Burimi: www.habr.com
