


Qëllimi kryesor i Patroni është të sigurojë Disponueshmëri të Lartë për PostgreSQL. Por Patroni është vetëm një template, jo një mjet i gatshëm (çfarë gjithashtu thuhet në dokumentacion). Në një shikim të parë, duke e konfiguruar Patroni në një laboratore testuese, mund të shohësh se sa mjet i shkëlqyer është dhe si e trajton lehtësisht përpjekjen tonë për të shkatërruar klastri. Megjithatë, në praktikë, në një mjedis prodhimi, gjithçka nuk ndodh gjithmonë aq bukur dhe elegant si në laboratorin e testeve.

Do të flas pak për veten time. Kam filluar si administrator sistemi. Kam punuar në zhvillimin e uebit. Nga viti 2014 punoj në Data Egret. Kompania merret me konsulencë në fushën e Postgres. Dhe ne shërbejmë pikërisht Postgres, duke punuar çdo ditë me të, prandaj kemi ekspertizë të ndryshme të lidhura me operimin.
Dhe në fund të vitit 2018 filluam ngadalë të përdorim Patroni. Dhe kemi akumuluar një përvojë të caktuar. Ne e diagnostikuam, e përshtatëm, erdhëm në praktikat tona më të mira. Në këtë prezantim do të flas për to.
Përveç Postgres, unë pëlqej Linux-in. Më pëlqen ta eksploroja dhe të eksperimentoj me të, më pëlqen të ndërtoj bërthama. Më pëlqejnë virtualizimi, kontejnerët, Docker, Kubernetes. Këto gjëra më interesojnë sepse pasojat e zakoneve të vjetra të administratës shfaqen. Më pëlqen të merrem me monitorimet. Dhe më pëlqejnë gjërat e Postgres-it që lidhen me administrimin, pra replikimi, kopjimi rezervë. Dhe në kohën time të lirë shkruaj në Go. Nuk jam inxhinier software-i, thjesht shkruaj për vete në Go. Dhe më sjell kënaqësi.

- Mendoj se shumica prej jush e dinë se në Postgres nuk ka HA (Disponibilitet të Lartë) nga kutia. Për të pasur HA, duhet të vendosni diçka, ta konfiguroni, të shkoni përpara dhe ta arrini atë.
- Ekzistojnë disa mjete dhe Patroni është një prej tyre që e zgjidh HA mjaft mirë dhe shumë efektivisht. Por duke vendosur gjithçka në një laboratori provues dhe duke e nisur, mund të shohim se gjithçka funksionon, mund të riprodhojmë disa probleme, të shohim se si i trajton Patroni ato. Dhe do të shohim se gjithçka funksionon për mrekulli.
- Por në praktikë kemi hasur në probleme të ndryshme. Dhe mbi këto probleme do të flas.
- Do të tregoj se si e diagnostikuam, çfarë ndryshuam - na ndihmoi kjo apo jo.

- Nuk do të flas për mënyrën se si të instaloni Patroni, sepse mund ta kërkoni në internet, mund të shikoni skedarët e konfigurimit për të kuptuar se si funksionon dhe si konfiguroni gjithçka. Mund të kuptoni arkitekturën, duke gjetur informacion për këtë në internet.
- Nuk do të flas për përvojën e të tjerëve. Do të flas vetëm për problemet që kemi hasur ne vetë.
- Dhe nuk do të flas për problemet që janë jashtë Patroni dhe PostgreSQL. Nëse, për shembull, ka probleme që lidhen me balancimin, kur klasteri ynë u shkatërrua, për këtë nuk do të flas.

Dhe një shpërndarje e vogël para se të fillojmë prezantimin tonë.
Të gjitha këto probleme që kemi hasur ndodhen gjatë 6-7-8 muajve të parë të përdorimit. Me kalimin e kohës, arritëm në praktikat tona më të mira. Dhe problemet nuk na kanë shqetësuar më. Prandaj, prezantimi ishte planifikuar rreth gjashtë muaj më parë, kur gjithçka ishte ende e freskët në mendje dhe unë e mbaja mend mirë.
Gjatë përgatitjes së raportit, kam shqyrtuar postmortemet e mëparshme dhe kam parë logët. Disa detaje mund të kenë rënë në harresë, ose disa informacione mund të mos kenë qenë të studiuara plotësisht gjatë analizës së problemeve, prandaj në disa momente mund të duket se problemet nuk janë shqyrtuar plotësisht, ose ekziston ndonjë mangësi informacioni. Prandaj, ju lutem, më falni për këtë moment.

Çfarë është Patroni?
- Është një model për ndërtimin e HA. Kështu është shkruar në dokumentacion. Dhe nga pikëpamja ime, është një sqarim shumë i drejtë. Patroni nuk është një plumb argjendi që do të zgjidhë të gjitha problemet tuaja, pra është e nevojshme të bëni përpjekje që të fillojë të punojë dhe të sjellë përfitime.
- Është një shërbim agjential që instalohet në çdo shërbim me databazë dhe që funksionon si një lloj sistemi init për Postgres-in tuaj. Ai nis Postgres-in, e ndalon, e ribën, ndryshon konfigurimin dhe ndryshon topologjinë e klasterit tuaj.
- Në mënyrë që të mbani gjendjen e klasterit, përfaqësimin e tij aktual dhe si ai duket, nevojitet ndonjë magazinë. Nga kjo pikëpamje, Patroni ndjek rrugën e ruajtjes së gjendjes në një sistem të jashtëm. Ky është një sistem i ruajtjes së konfigurations së shpërndarë. Mund të jetë Etcd, Consul, ZooKeeper, ose Etcd i Kubernetes, pra ndonjë nga këto opsione.
- Një nga veçoritë e Patroni është se ju merrni auto-failover-in që nga fillimi, vetëm duke e konfiguruar. Në krahasim me Repmgr, atje failover-i vjen me paketën. Me Repmgr ne marrim switchover, por nëse duam auto-failover, duhet ta konfiguroni atë ndryshe. Në Patroni, auto-failover është tashmë përfshirë nga fillimi.
- Ka shumë gjëra të tjera gjithashtu. Përdorimi i konfigurimeve, kalimi i replikave të reja, kopjimi rezervë etj. Por këto janë jashtë këtij raporti, nuk do flas për to.

Një përmbledhje e vogël – detyra kryesore e Patroni është të bëjë auto-failover-in në mënyrë të sigurt dhe të besueshme, për të siguruar që klasteri të vazhdojë të jetë operativ dhe aplikacioni mos e vë re ndryshimin në topologjinë e klasterit.

Por kur ne fillojmë të përdorim Patroni, sistemi ynë bëhet pak më i komplikuar. Nëse më parë kishim Postgres, tani me përdorimin e Patroni marrim vetë Patroni, marrim DCS, ku ruhet gjendja. Dhe gjithë kjo duhet të funksionojë në një mënyrë. Prandaj, çfarë mund të dështojë?
Mund të dështojë:
- Mund të dështojë Postgres. Kjo mund të jetë master ose replikë, diçka nga këto mund të dalë jashtë funksionimit.
- Mund të dështojë vetë Patroni.
- Mund të dështojë DCS, ku ruhet gjendja.
- Dhe mund të dështojë rrjeti.
Të gjitha këto aspekte do t'i shqyrtoj në prezantimin tim.

Do të shqyrtoj rastet sipas kompleksitetit të tyre, jo nga pikëpamja se rasti përfshin shumë komponente. Por nga pikëpamja e ndjenjave subjektive, që ky rast ishte i komplikuar për mua, ishte e vështirë për t'u analizuar... dhe anasjelltas, ndonjë rast ishte i lehtë dhe ishte e thjeshtë për t'u analizuar.

Dhe rasti i parë është më i lehti. Është ai rast ku ne morëm një grup të dhënash dhe në të njëjtin grup vendosëm ruajtjen tonë DCS. Kjo është gabimi më i zakonshëm. Është një gabim në ndërtimin e arkitekturës, dmth, kombinimi i komponenteve të ndryshme në një vend.
Pra, ndodhi një dështim i dosjes, shkojmë të shqyrtojmë se çfarë ndodhi.

Këtu na intereson kur ndodhi fileri. Domethënë, na intereson ky moment i përkohshëm kur ndodhi ndryshimi i gjendjes së klasterit.
Por fileri nuk është gjithmonë një moment i vetëm, domethënë nuk zgjat vetëm një njësi kohe, mund të jetë i zgjatur. Ai mund të zgjatet për një kohë të gjatë.
Prandaj, ai ka një kohë fillimi dhe një kohë përfundimi, domethënë është një ngjarje që zgjat. Ne ndajmë të gjitha ngjarjet në tre intervale: kemi kohën para filerit, gjatë filerit dhe pas filerit. Domethënë, ne shqyrtojmë të gjitha ngjarjet në këtë shkallë të kohës.

Dhe e para gjë që bëjmë kur ndodh fileri, është të kërkojmë shkakun, çfarë ndodhi, çfarë e shkaktoi atë që çoi në filer.
Nëse shohim logjet, ato do të jenë logjet klasike të Patroni. Ai na njofton se serveri është bërë master dhe roli i masterit është kaluar në këtë nyje. Këtu është e shënuar.

Më pas, na nevojitet të kuptojmë pse ndodhi ndarja e skedarit, dmth. çfarë ndodhi që detyroi rolin e mjeshtrit të kalojë nga një nyje në një tjetër. Në këtë rast, këtu është e thjeshtë. Kemi një gabim në ndërveprimin me sistemin e ruajtjes. Mjeshtri kuptoi se nuk mund të punonte me DCS, dmth. ndodhi ndonjë problem në ndërveprim. Dhe ai thotë se nuk mund të jetë më mjeshtër dhe heq dorë nga autoritetet. Kjo linjë "demoted self" flet pikërisht për këtë.

Nëse shohim ngjarjet që i paraprinë ndarjes së skedarit, mund të shohim ato arsye që shërbyen si problem për vazhdimin e punës së mjeshtrit.
Nëse shohim log-et e Patroni, do të shohim se kemi një mori gabimesh, këputjesh, dmth. agjenti Patroni nuk mund të punojë me DCS. Në këtë rast, është agjenti Consul, me të cilin komunikohet përmes portit 8500.
Dhe problemi këtu është se Patroni dhe baza e të dhënave janë të drejtuara në të njëjtin host. Dhe në këtë nyje ishin të drejtuar serverët Consul. Duke krijuar ngarkesë në server, ne krijuam probleme edhe për serverëve Consul. Ata nuk arritën të komunikonin normalisht.

Pas një kohe, kur ngarkesa u ul, Patroni ynë arriti të komunikonte përsëri me agjentët. Puna normale u rinis. Dhe e njëjta server Pgdb-2 u bë përsëri master. Do thotë, kishte një fluks të vogël, për shkak të të cilit nyja humbi autoritetin e masterit, dhe më pas e rimori, pra gjithçka u kthye siç ishte.

Dhe kjo mund të interpretohet si një alarm false, ose mund të shihet si një veprim i duhur nga Patroni. Do thotë, ai e kuptoi se nuk mund të mbante gjendjen e klasterit dhe e hoqi veten nga autoriteti.
Dhe problemi ka lindur nga fakti se serverët e Consul ndodhen në të njëjtën pajisje si bazat e të dhënave. Prandaj, çdo ngarkesë, qoftë ngarkesë në disk ose procesorë, ndikon gjithashtu në bashkëpunimin me klasterin Consul.

Dhe ne vendosëm se kjo nuk duhet të jetë në të njëjtën vend, ne ndamë një klaster të veçantë për Consul. Dhe Patroni punoi tashmë me një Consul të veçantë, do thotë, kishte një klaster Postgres të veçantë dhe një klaster Consul të veçantë. Kjo është udhëzimi bazë se si duhet të shperndahen dhe mbahen të gjitha këto gjëra, për të mos jetuar së bashku.
Si kemi mundësi të konfiguroni parametrat ttl, loop_wait, retry_timeout, dmth, të përpiqemi të mbijetojmë gjatë këtyre kulmeve të ngarkesës përmes rritjes së këtyre parametrave. Por kjo nuk është zgjidhja më e përshtatshme, sepse këto ngarkesa mund të jenë të vazhdueshme. Në këtë kuptim, do të tejkalojmë kufijtë e këtyre parametrave. Dhe kjo mund të mos ndihmojë fare.
Problemi i parë, siç e kuptoni, është i thjeshtë. Ne e vendosëm DCS-in së bashku me bazën, dhe kështu e morëm problemin.

Problemi i dytë është i ngjashëm me të parin. Ai është i ngjashëm sepse përsëri kemi probleme me bashkëpunimin me sistemin DCS.

Nëse shikojmë në log-et, do të shohim se sërish kemi gabim në komunikim. Dhe Patroni thotë se nuk mund të bashkëpunoj me DCS, kështu që mjeshtri aktual kalon në modin replikë.
Mjeshtri i vjetër bëhet replikë, këtu Patroni punon siç duhet. Ai aktivizon pg_rewind, për të kthyer regjistrin e transaksioneve dhe pastaj për t'u lidhur me mjeshtrin e ri, dhe për të arritur në mjeshtrin e ri. Këtu Patroni funksionon si duhet.

Këtu ne duhet të gjejmë vendin që e parapriu failover-in, pra gabimet që shërbyen si shkak, pse ndodhi failover. Në këtë aspekt, punimi me logët e Patroni është mjaft i lehtë. Ai shkruan të njëjtat mesazhe në intervale të caktuara. Dhe nëse fillojmë të rrokullisim shpejt këto log, ne shohim që logët janë ndryshuar, që do të thotë se kanë filluar ndonjë problem. Ne kthehemi shpejt në atë vend dhe shohim se çfarë po ndodh.
Dhe në situata normale, logët duken kështu. Kontrollohet pronari i bllokimit. Dhe nëse, për shembull, pronari ka ndryshuar, atëherë mund të ndodhin disa ngjarje, për të cilat Patroni duhet të reagojë. Por në këtë rast, gjithçka është në rregull. Ne jemi duke kërkuar vendin ku kanë filluar gabimet.

Dhe duke u kthyer në atë vend kur filluan të shfaqen gabimet, ne shohim që kemi pasur auto-failover. Dhe pasi gabimet tona ishin të lidhura me ndërveprimin me DCS dhe në rastin tonë ne përdorëm Consul, ne gjithashtu shikojmë logët e Consul për të parë çfarë ka ndodhur atje.
Duke krahasoshim kohën e skanerëve dhe kohën në regjistrat e Consul, shohim se fqinjët tanë në cluster-in e Consul filluan të dyshojnë për egzistencën e pjesëmarrësve të tjerë të cluster-it të Consul.

Dhe nëse shohim regjistrat e agjentëve të tjerë të Consul, gjithashtu shihet që ka ndodhur një kolaps rrjeti. Të gjithë pjesëtarët e cluster-it të Consul dyshojnë për egzistencën e njëri-tjetrit. Kjo ishte nxitja për skanerin.
Nëse shohim se çfarë ndodhi para këtyre gabimeve, mund të shohim se ka pasur lloje të ndryshme gabimesh, si deadline, RPC falled, domethënë qartë një problem gjatë bashkëpunimit të pjesëmarrësve të cluster-it të Consul me njëri-tjetrin.

Përgjigjja më e thjeshtë është të riparosh rrjetin. Por unë, duke qëndruar në tribunë, është e lehtë të them këtë. Por rrethanat janë të tilla që nuk gjithmonë klienti mund të përballojë riparimet e rrjetit. Ai mund të jetojë në qendrën e të dhënave dhe mund të mos ketë mundësi për të riparuar rrjetin, për të ndikuar te pajisjet. Prandaj nevojiten disa alternativa të tjera.

Ka alternativa:
- Opsioni më i thjeshtë, i cili është shkruar, mendoj, madje në dokumentacion, është të çaktivizosh verifikimet e Consul, pra thjesht të kalosh një array të zbrazët. Kështu, ne i themi agjentit të Consul të mos përdorë asnjë verifikim. Falë këtyre verifikimeve, ne mund të injorojmë këto stuhi rrjetesh dhe të mos inicojmë dështimin e skedarëve.
- Një opsion tjetër është të kontrollosh raft_multiplier-in. Ky është një parametr i serverit Consul. Në parazgjedhje, ai është vendosur në vlerën 5. Kjo vlerë rekomandohet në dokumentacion për ambientet staging. Në thelb, kjo ndikon në frekuencën e shkëmbimeve të mesazheve mes anëtarëve të rrjetit Consul. Pra, ky parametr ndikon në shpejtësinë e komunikimit shërbyes mes anëtarëve të klasterit Consul. Dhe për producim, tashmë rekomandohet ta reduktosh që nyjat të shkëmbejnë mesazhe më shpesh.
- Një tjetër mundësi që filluam ta përdorim është rritja e prioritetit të proceseve të Consul-it mes proceseve të tjera për planifikuesin e proceseve të sistemit operativ. Ka një parametrin "nice", i cili pikërisht përcakton prioritetin e proceseve që merret parasysh nga planifikuesi i OS gjatë planifikimit. Ne ulëm vlerën e nice për agjentët e Consul-it, dmth. rritëm prioritetin, në mënyrë që sistemi operativ t'u jepte më shumë kohë proceseve të Consul për të punuar dhe për të ekzekutuar kodin e tij. Në rastin tonë, kjo e zgjidhi problemin tonë.
- Një opsion tjetër është që të mos përdorsh Consul. Kam një mik, i cili është një mbështetës i madh i Etcd. Ne rregullisht debatojmë se cila është më e mira, Etcd apo Consul. Megjithatë, sa i përket asaj se cila është më e mirë, zakonisht arrijmë në përfundimin se Consul ka një agjent që duhet të jetë aktiv në çdo nyje me bazën e të dhënave. Domethënë, ndërveprimi i Patroni me klasterin Consul kalon përmes këtij agjenti. Dhe ky agjent bëhet pika e ngushtë. Nëse ndodh diçka me agjentin, atëherë Patroni nuk mund të punojë me klasterin Consul. Kjo është një problem. Në rastin e Etcd, nuk ka asnjë agjent. Patroni mund të punojë drejtpërdrejt me listën e serverëve Etcd dhe të komunikojë me ta. Në këtë këndvështrim, nëse përdorni Etcd në kompaninë tuaj, ndoshta Etcd do të ishte zgjedhja më e mirë sesa Consul. Por ne te klientët tanë, gjithmonë jemi të kufizuar nga ajo që ka zgjedhur dhe përdor klienti. Dhe në shumicën e rasteve, Consul është i pranishëm te të gjithë klientët.
- Dhe pika e fundit është të rishikojmë vlerat e parametrave. Ne mund të rrisim këto parametra në anën e madhe duke shpresuar se problemet tona të shkurtra në rrjet do të jenë të shkurtra dhe nuk do të bien brenda intervalit të këtyre parametrave. Kështu, ne mund të zvogëlojmë agresivitetin e Patroni për të kryer autodiskrimim, nëse ndodhin ndonjë problem në rrjet.
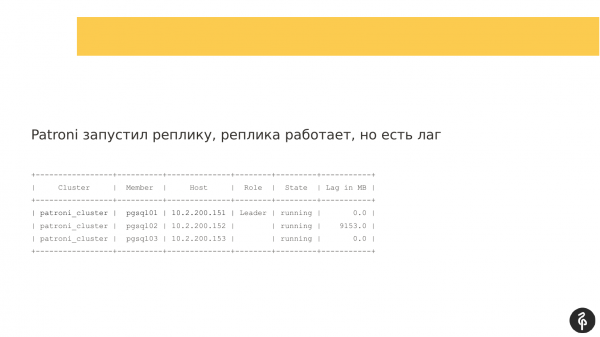
Mendoj se shumë nga ata që përdorin Patroni janë të njohur me këtë komandë.
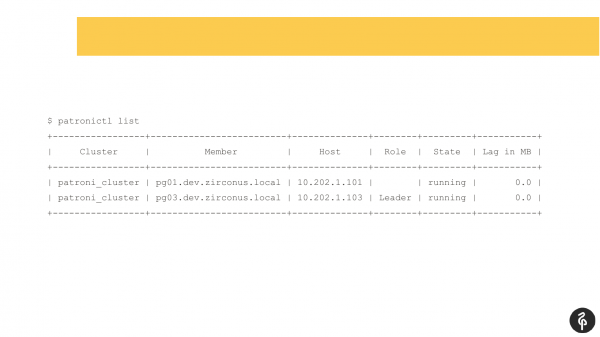
Kjo komandë tregon gjendjen aktuale të klasterit. Dhe me sy të parë, kjo pamje mund të duket normale. Kemi një master, kemi një replikë, nuk ka asnjë vonesë në replikim. Por kjo pamje është normale derisa të dimë se në këtë klaster duhet të ketë tre nodë, e jo dy.

Për këtë arsye, ndodhi autodiskrimimi. Pas këtij autodiskrimimi, ne humbëm replikën. Duhet të zbulojmë se pse ajo humbi dhe ta kthejmë atë përsëri, ta rikuperojmë. Dhe ne përsëri shkojmë në loge dhe shohim pse ndodhi autodiskrimimi.

Në këtë rast, replikë e dytë u bë master. Këtu gjithçka është në rregull.

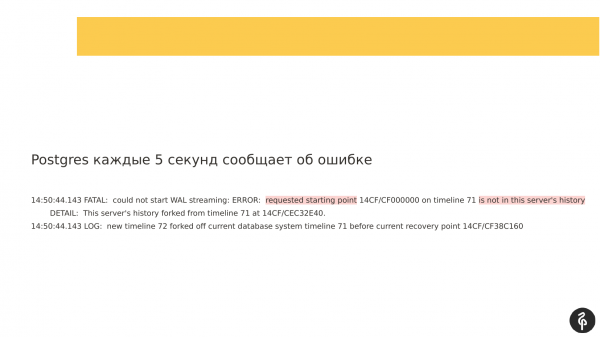
Dhe ne duhet të shikojmë tashmë në replikën që ka humbur dhe që nuk është në klaster. Hapim logjet e Patroni dhe shohim se kemi pasur një problem në fazën e lidhjes me klasterin në procesin e pg_rewind. Për t'u lidhur me klasterin, duhet të kthejmë regjistrin e transaksioneve, të kërkojmë regjistrin e nevojshëm të transaksioneve nga masteri dhe të arrijmë masterin përmes tij.
Në këtë rast, ne nuk kemi regjistrin e transaksioneve dhe replika nuk mund të ndizet. Për rrjedhojë, ne e ndalojmë Postgres-in me një gabim. Dhe prandaj ajo nuk është në klaster.

Duhet të kuptojmë pse ajo nuk është në klaster dhe pse nuk kishte logje. Ne shkojmë te masteri i ri dhe shohim çfarë ka në logjet e tij. Del se kur u bë pg_rewind, ndodhi një checkpoint. Dhe një pjesë e vjetër e regjistrave të transaksioneve thjesht u rinominua. Kur masteri i vjetër përpiqej të lidhej me masterin e ri dhe të kërkonte këto logje, ato ishin tashmë të rinominuara, thjesht nuk ishin më.

Unë kam krahasuar timestamps kur kanë ndodhur këto ngjarje. Dhe diferenca është në të vërtetë vetëm 150 milisekonda, pra në 369 milisekonda përfundoi checkpointi, u rinovuan segmentet e WAL. Dhe vetëm në 517 milisekonda, pas 150 milisekondave, filloi rewinding në replikën e vjetër. Pra, vetëm 150 milisekonda na mjaftuan që replika të mos mund të lidhë dhe të punojë.

Çfarë opionesh ka?
Fillimisht kemi përdorur slotet e replikimit. Na dukej se ishte mirë. Megjithatë, në fazën e parë të eksploatimit i çuam slotet mënjanë. Na dukej se, nëse slotet do të grumbullonin shumë segmente WAL, mund të rrëzonim masterin. Ai do të bie. Ndjemë pak pa slotet. Dhe kuptuam se na nevojiteshin slotet, prandaj i kthyem ato.
Por këtu ka një problem, sepse kur masteri kalon në replikë, ai fshin slotet dhe së bashku me slotet fshin segmentet WAL. Dhe për të eliminuar shfaqjen e kësaj problemi, vendosëm të rrisim parametrin wal_keep_segments. Ai është 8 segmente si parazgjedhje. E rritëm në 1,000 dhe pamë sa hapësirë të lirë kishim. Dhe ne dhuruam 16 gigabajt për wal_keep_segments. Pra, gjatë kalimit, gjithmonë kemi një rezervë prej 16 gigabajtësh të regjistrimeve të transaksioneve në të gjitha nyjet.
Dhe plus – kjo është akoma e rëndësishme për detyrat afatgjata të mirëmbajtjes. Supozoni se duhet të përditësojmë një nga replikat. Dhe duam ta ndalim atë. Duhet të përditësojmë softin, ndoshta sistemin operativ, diçka tjetër. Dhe kur e ndalim replikën, sloti për atë replikë eliminohet gjithashtu. Nëse përdorim një wal_keep_segments të vogël, atëherë në mungesë të vazhdueshme të replikës, regjistrat e transaksionit do të riprodhohen. Ne do ta ngremë replikën, ajo do të kërkojë ato regjistra transaksionesh ku u ndal, por mund të mos jenë të pranishëm te masteri. Dhe replika gjithashtu nuk do të mund të lidhë. Prandaj, ne mbajmë një rezervë të madhe regjistrash.

Ne kemi një bazë production. Aty tashmë janë projektet në punë.
Ka ndodhur një failure. Ne hyjmë dhe shohim – gjithçka është në rregull, replikat janë në vend, nuk ka vonesa në replikim. Nuk ka gabime në regjistra gjithashtu, gjithçka është në rregull.
Ekipa e produktit thotë se duhet të ketë disa të dhëna, por ne i shohim në një burim, ndërsa në bazë nuk i shohim. Dhe duhet të kuptojmë se çfarë i ndodhi atyre.

E qartë, pg_rewind i ka fshirë ata. Ne e kuptuam menjëherë këtë, por shkuam të shihnim se çfarë ndodhi.

Në log-e gjithmonë mund të gjejmë kur ndodhi dështimi, kush u bë masteri dhe mund të përcaktojmë kush ishte masteri i vjetër dhe kur vendosi të bëhej replikë, pra na nevojiten këto log-e për të zbuluar atë sasi të regjistrimeve të transaksioneve që është humbur.
Masteri ynë i vjetër u riaktivizua. Dhe në nisjen automatike ishte përmendur Patroni. Patroni filloi. Ai menjëherë nisi Postgres. Më saktë, para se të fillonte Postgres-in dhe para se ta bënte atë replikë, Patroni nisi procesin pg_rewind. Si pasojë, ai fshiu një pjesë të regjistrimeve të transaksioneve, shkarkoi të rejat dhe u lidh. Këtu Patroni funksionoi shkëlqyeshëm, pra ashtu siç është parashikuar. Klustri ynë u rikuperua. Kishim 3 nodë, pas dështimit 3 nodë – gjithçka është super.

Ne humbëm një pjesë të të dhënave. Dhe na nevojitet të kuptojmë sa kemi humbur. Po kërkojmë pikërisht atë moment kur ndodhi rewind-i. Mund ta gjejmë këtë sipas këtyre shënimeve në log. Rewind nisi, bëri diçka dhe përfundoi.

Na nevojitet të gjejmë atë pozicion në regjistrin e transaksioneve, ku ndaloi masteri i vjetër. Në këtë rast – është ky shënim. Dhe na nevojitet një shënim i dytë, pra ajo distancë, me të cilën ndan masteri i vjetër nga i ri.
Ne marrim ndryshimin e zakonshëm pg_wal_lsn_diff dhe krahasojmë këto dy shënime. Në këtë rast, ne marrim 17 megabajt. Çfarë është shumë e çfarë është pak, secili e vendos për vete. Sepse për disa 17 megabajt është pak, për disa të tjerë është shumë dhe e papranueshme. Këtu çdo njëri duhet të përcaktojë në përputhje me nevojat e biznesit.

Por çfarë zbuluam ne për vete?
Së pari, ne duhet të vendosim për vete – a na nevojitet gjithmonë autostart i Patroni pas rinisjes së sistemit? Ndodh shpesh që duhet të hyjmë në masterin e vjetër, të shohim se sa larg është shkuar. Ndoshta, të inspektojmë segmentet e gazetës së transaksioneve, të shohim çfarë është atje. Dhe të kuptojmë – a mund të humbasim këta të dhëna apo na nevojitet të nisemi në një modalitet standalone për të nxjerrë këto të dhëna.
Dhe vetëm pas kësaj duhet të marrim vendim, nëse mund t’i hedhim këto të dhëna apo mund t’i rikuperojmë, duke lidhur këtë nyje si replikë në klasterin tonë.
Përveç kësaj, ekziston parametri “maximum_lag_on_failover”. Sipas standardit, nëse nuk më tradhton mendja, ky parametr ka vlerë 1 megabajt.
Si e ka punon? Nëse kopja jonë ndjek me 1 megabajt të dhënash për vonesën e replikimit, atëherë kjo kopje nuk merr pjesë në zgjedhje. Dhe, nëse ndodh një ndarje e çfarëdo lloji, Patroni shikon se cilat kopje kanë ngecje. Nëse ato kanë ngecje të madhe me shumë regjistra transaksionesh, ato nuk mund të bëhen master. Kjo është një funksion mbrojtës shumë i miratë, i cili ndihmon të mos humbasim shumë të dhëna.
Por këtu ka një problem që vonesa e replikimit në klasterin Patroni dhe DCS përditësohet me një interval të caktuar. Mendoj se është 30 sekonda vlere e paracaktuar ttl.
Për rrjedhojë, mund të ketë një situatë ku vonesa e replikimit për kopjet në DCS është një, ndërsa në të vërtetë mund të ketë një vonesë krejtësisht tjetër ose nuk ka vonesë fare, dmth, kjo gjë nuk është realtime. Dhe ajo nuk e reflekton gjithmonë imazhin real. Dhe nuk ia vlef të bësh logjikë të avancuar mbi të.
Dhe rreziku i humbjeve gjithmonë mbetet. Në rastin më të keq kemi një formulë, ndërsa në rastin mesatar një formulë tjetër. Pra, kur planifikojmë implementimin e Patroni dhe vlerësojmë se sa të dhëna mund të humbasim, duhet të mbështetemi në këto formula dhe të kemi një ide të përafërt se sa të dhëna mund të humbasim.
Dhe ka një lajm të mirë. Kur masteri i vjetër u largua, ai mund të ikte përmes disa proceseve në background. Do të thotë, kishte një avto-vakuum, ai shkroi të dhënat, i ruajti ato në regjistrin e transaksionit. Dhe ne mund t'i injorojmë lehtësisht ato të dhëna dhe t'i humbasim. Nuk ka asnjë problem në këtë.

Ja si duken log-et në rast se është vendosur maximum_lag_on_failover dhe ndodhi një failover, dhe duhet të zgjidhet një master i ri. Replica e vlerëson veten si të paaftë për të marrë pjesë në zgjedhje. Ajo refuzon të marrë pjesë në garën për liderin. Dhe pret derisa të zgjidhet një master i ri për t'u lidhur me të. Kjo është një masë shtesë për të parandaluar humbjen e të dhënave.

Këtu ekipi ynë produkt shkruajti se produkti i tyre përballet me probleme gjatë përdorimit të Postgres. Megjithatë, nuk mund të hyhet në masterin vetë, sepse është i paaksesueshëm përmes SSH. Dhe failover-i automatik gjithashtu nuk ndodh.
Ky host u dërgua me forcë për t'u rindërtuar. Për shkak të rindërtimit ndodhi një failover automatik, megjithëse mund të ishte bërë edhe një failover manual, siç e kuptoj tani. Dhe pas rindërtimit ne shkojmë të shikojmë se çfarë ndodhi me masterin aktual.
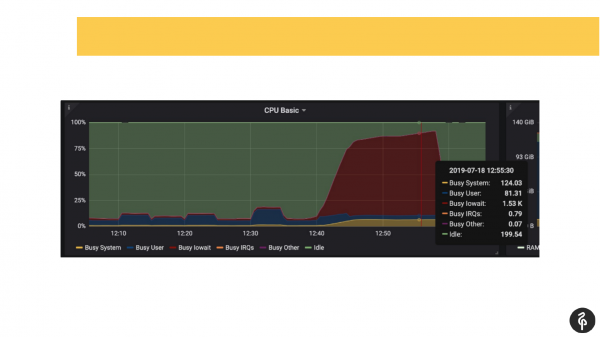
Megjithatë, ne e dinim paraprakisht që kishim probleme me disqet, domethënë, përmes monitorimit tashmë e dinim se ku duhej të shikonim dhe çfarë të kërkonim.

Ne hyrëm në log-un e postgres-it dhe filluam të shikonim çfarë po ndodhte atje. Pamë komitetet që zgjatnin një, dy, tre sekonda, gjë që nuk është normale. Pamë që avtokorrigjimi po fillonte shumë ngadalë dhe në mënyrë të çuditshme. Dhe pamë skedarë të përkohshëm në disk. Domethënë, të gjitha këto janë tregues të problemeve me disqet.

Ne hodhëm një sy në sistemin dmesg (në log-un e mesazheve të kernelit). Dhe pamë se kishim probleme me një nga disqet. Sistemi i diskut përbënte një Raid softuerik. Shikuan /proc/mdstat dhe panë se na mungonte një disk. Domethënë, këtu është një Raid prej 8 disqesh, na mungon një. Nëse e shqyrtojmë me kujdes slajdin, mund të shohim në përfundim se disku sde mungon. Pra, në terma të thjeshtë, disku ka rënë. Kjo shkaktoi probleme në disk dhe aplikacionet gjithashtu hasën probleme gjatë punës me cluster-in Postgres.

As in this case, Patroni wouldn't have helped us because it doesn't have the task of monitoring server status or disk status. We need to track such situations with external monitoring. We have added disk monitoring to our external monitoring system promptly.
There was a thought — could fencing or a software watchdog help us? We thought it unlikely because during the issues, Patroni continued to interact with the DCS cluster and didn't see any problems. From the perspective of DCS and Patroni, everything was fine with the cluster, although there were indeed problems with the disk and database availability.
In my opinion, this is one of the strangest problems I've investigated for a long time; I've read through many logs, dissected them, and dubbed it the cluster-simulating issue.

The problem was that the old master couldn't become a proper replica; that is, Patroni started it, and Patroni showed that this node was present as a replica, but at the same time, it wasn't a normal replica. You will now see why. I have retained this from the analysis of that problem.

Dhe si filloi gjithçka? Filloi, ashtu si në problemin e mëparshëm, me frenat disk. Kishim komitë një herë në sekondë, dy.

Ishte ndërprerje lidhjesh, dmth klientët u ndanë.

Ishte bllokime të ndryshme të rëndësisë.

Dhe, për pasojë, nën sistemi i disqeve nuk ishte shumë reaktiv.

Dhe më e misteriozja për mua – ishte kërkesa për ndalim të menjëhershëm. Postgres ka tri mënyra për të shkuar në ndalim:
- Ka graceful, kur presim që të gjithë klientët të çaktivizohen vetvetiu.
- Ka fast, kur e detyrojmë klientët të çaktivizohen, sepse po shkojmë për ndalim.
- Dhe immediate. Në këtë rast, immediate as nuk i njofton klientët se duhet të çaktivizohen, thjesht ndalon pa paralajmërim. Të gjithë klientët gjithashtu dërgohet një mesazh RST nga sistemi operativ (mesazh TCP që lidhja është ndërprerë dhe klienti nuk ka më çfarë të kapë).
Kush e dërgoi këtë sinjal? Proceset e prapavijës të Postgres nuk dërgojnë sinjale të tilla njëra-tjetrës, dmth është kill-9. Ata nuk dërgojnë njëri-tjetrit diçka të tillë, ata vetëm reagojnë ndaj saj, dmth është një ripërshtatje emergjente e Postgres. Kush e dërgoi, nuk e di.
Shikova pas ekipit "last", pashë një person që kishte hyrë në këtë server bashkë me ne, por e ndjeva veten të turpëruar të bëja pyetje. Mund të ketë qenë kill -9. Unë do të kisha parë kill -9 në log, sepse Postgres shkruan që mori kill -9, por nuk e pashë këtë në log.

Duke vazhduar hetimin, pashë që Patroni nuk kishte shkruar në log për një kohë të gjatë - 54 sekonda. Dhe nëse krahasoj dy timestamp, ka qenë rreth 54 sekonda pa mesazhe.
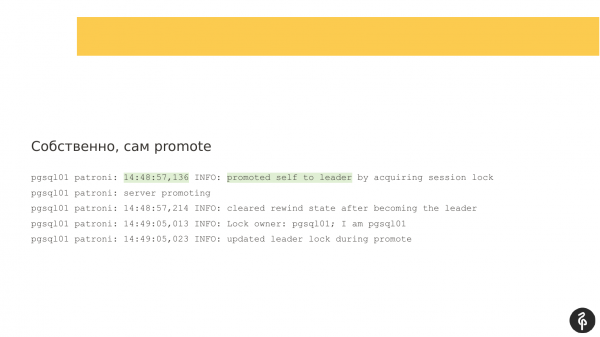
Dhe gjatë kësaj kohe ndodhi auto failover. Patroni punoi përsëri perfekt. Mjeshtri ynë i vjetër nuk ishte i aksesueshëm, ndodhi diçka me të. Dhe nisi zgjedhja e një mjeshtri të ri. Këtu gjithçka funksionoi mirë. Pgsql01 u bë lideri i ri.

Kemi një replikë që u bë mjeshtër. Dhe kemi një replikë të dytë. Dhe me replikën e dytë kishim pikërisht probleme. Ajo përpiqej të rikonstruktohej. Sa kuptoj, ajo përpiqej të ndryshonte recovery.conf, të riniste Postgres dhe të lidhej me mjeshtrin e ri. Ajo çdo 10 sekonda shkruan mesazhe që po përpiqet, por nuk po arrin.

Dhe gjatë këtyre përpjekjeve, sinjali i mbylljes së menjëhershme i dërgohet masterit të vjetër. Masteri ri starton. Po ashtu, rikuperimi ndalon, sepse masteri i vjetër kalon në ri-startim. Pra, kloni nuk mund të lidhet me të, sepse është në modalitetin e fikjes.

Në një moment ajo filloi të funksionojë, por replikimi nuk u aktivizua.
Kam vetëm një hipotezë, që në recovery.conf ishte adresa e masterit të vjetër. Dhe kur doli masteri i ri, kloni i dytë vazhdonte të përpiqej të lidhej me masterin e vjetër.
Kur Patroni startoi në klonin e dytë, nodi u nis, por nuk mundi të lidhej për replikim. Kështu që u formua një vonesë e replikimit, e cila dukej kështu. Pra, të tre nodet ishin në vend, por nody i dytë mbeti prapa.
Në të njëjtën kohë, nëse shikoni log-ët që ishin shkruar, mund të vëreni se replikimi nuk mund të iniciohej, sepse regjistrat e transaksioneve ndryshojnë. Dhe ato regjistra të transaksioneve që ofron masteri, që janë të specifikuara në recovery.conf, thjesht nuk i përshtaten nodit tonë aktual.

Dhe këtu kam bërë një gabim. Duhej të isha shkruar për të kontrolluar çfarë kishte aty në recovery.conf, për të verifikuar hipotezën time se ne po lidhnim me masterin e gabuar. Por atëherë sapo po merresha me këtë dhe nuk më erdhi në mendje, ose pashë që replikimi po vonohej dhe do të duhej ta riparoj, pra ndihmova siç mundesha. Kjo ishte gabimi im.

30 minuta më vonë erdhi administrator, pra e rinisja Patroni në replikë. Isha ndjerë i pafat me të, mendova se do të duhej ta riparoja. Dhe mendova – do ta rinis Patroni, ndoshta do dalë ndonjë gjë e mirë. U hap recovery. Dhe baza madje u hap, ishte gati të priste lidhjet.
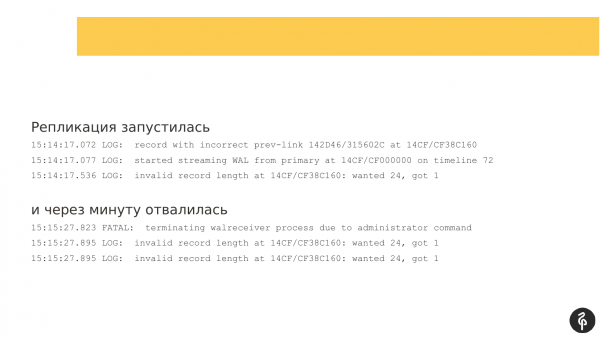
Replikimi filloi. Por pas një minute ajo u ndal me një gabim se nuk i përshtaten regjistrat e transaksioneve.

Mendova se do ta rinisja përsëri. E rinisa përsëri Patroni, përveç se nuk e rinisa Postgres, por rinisa saktësisht Patroni me shpresën se ai do ta hapë bazën në mënyrë magjike.

Replikimi u rinis sërish, por shenjat në regjistrin e transaksioneve ishin ndryshe, ato nuk ishin ato që ishin gjatë përpjekjes së mëparshme për të nisur. Replikimi u ndal sërish. Dhe mesazhi ishte pak më i ndryshëm. Dhe për mua, ai nuk ishte shumë informues.

Dhe këtu më vjen në mendje – çfarë nëse ri-startoj Postgres, gjatë kësaj kohe të bëj një checkpoint në masterin aktual, për të zhvendosur pikën në regjistrin e transaksioneve pak më përpara, në mënyrë që rikuperimi të fillonte nga një moment tjetër? Plus, kishim edhe disa rezervat WAL.

Rini-startova Patroni, bëra disa checkpoints në master, disa pika të rikthimit në replikë, kur ajo u hap. Dhe kjo ndihmoi. Mendova për një kohë të gjatë se pse kjo ndihmoi dhe se si ndodhi kjo. Dhe replika u nis. Dhe replikimi nuk u ndërpre më.

Një problem i tillë për mua është një nga më misteriozët, mbi të cilin ende po mendoj, se çfarë ndodhi në të vërtetë.
Cilat janë përfundimet këtu? Patroni mund të punojë siç ishte menduar pa asnjë gabim. Por, kjo nuk është një garanci 100% që gjithçka është në rregull. Një replikë mund të ngrihet, por mund të jetë në një gjendje gjysmë-funksionale, dhe aplikacioni nuk duhet të punojë me një replikë të tillë, pasi do të ketë të dhëna të vjetra.
Dhe pas çdo failover-i, gjithmonë duhet të kontrolloni që gjithçka është në rregull me klasterin, pra, të ketë numrin e duhur të replikave, dhe të mos ketë vonesa në replikim.
Dhe gjatë shqyrtimit të këtyre problemeve, do të formuloj rekomandime. Kam përgatitur dy slajde për to. Besoj se të gjitha histori mund të ishin bashkuar në dy slajde dhe vetëm ato të ishin treguar.

Kur përdorni Patroni, duhet patjetër të keni monitorim. Duhet gjithmonë të dini kur ka ndodhur një auto-failover, sepse, nëse nuk e dini që keni pasur një auto-failover, nuk e kontrolloni klasterin. Dhe kjo është e keqe.
Pas çdo failover-i, gjithmonë duhet të kontrollojmë dorazi klasterin. Duhet të sigurohemi që gjithmonë të kemi numrin e saktë të replikave, të mos ketë vonesa në replikim, dhe në regjistrat të mos ketë gabime të lidhura me replikimin e rrjedhës, me Patroni, me sistemin DCS.
Automatika mund të funksionojë me sukses, Patroni është një mjet shumë i mirë. Ai mund të funksionojë, por kjo nuk do ta çojë grupin në gjendjen e duhur. Dhe nëse nuk e mësojmë këtë, do të kemi probleme.
Dhe Patroni nuk është një plumb argjendi. Ne duhet të kemi gjithsesi një kuptim se si punon Postgres, si funksionon replikimi dhe se si Patroni punon me Postgres, dhe si sigurohet ndërveprimi mes nyjave. Kjo është e nevojshme për të ditur si të zgjidhim problemet që shfaqen me duar.

Si e qasem unë çështjen e diagnostikimit? Ka ndodhur që ne punojmë me klientë të ndryshëm dhe askujt nuk i ka steka ELK, kështu që e kemi të nevojshme të merremi me logjet, duke hapur 6 konsola dhe 2 tab. Në një tab janë logjet e Patronit për çdo nyjë, në tab tjetër janë logjet e Consul-it ose Postgres-it sipas nevojës. Të diagnostikosh këtë është shumë e vështirë.
Cilat qasje kam zhvilluar? Si fillim, gjithmonë shikoj kur ka ardhur fileveri. Dhe për mua kjo është një ndarje. Shikoj çfarë ka ndodhur para fileverit, gjatë fileverit dhe pas fileverit. Fileveri ka dy etiketa: koha e fillimit dhe e përfundimit.
Pastaj, unë shikoj ngjarjet në logjet para dështimit, që parashikuan dështimin, dmth. po kërkoj arsyet pse ndodhi dështimi.
Dhe kjo jep një pamje se çfarë ndodhi dhe çfarë mund të bëj në të ardhmen që rrethana të tilla të mos ndodhin (dhe si pasojë, që dështimi të mos ndodhë).
Dhe ku shikojmë zakonisht? Unë shikoj:
- Fillimisht në logjet e Patroni.
- Pastaj shikoj logjet e Postgres, ose logjet DCS në varësi të asaj që gjendet në logjet e Patroni.
- Dhe logjet e sistemit gjithashtu ndonjëherë ofrojnë një kuptim të asaj që ishte shkak i dështimit.

Si e shoh Patroni? Patroni më pëlqen shumë. Në mendimin tim, kjo është gjëja më e mirë që ekziston sot. Njoh shumë produkte të tjera. Këto janë Stolon, Repmgr, Pg_auto_failover, PAF. 4 mjete. I kam provuar të gjitha. Patroni më pëlqeu më shumë.
Nëse më pyesin: "A rekomandoj Patroni?". Do të them po, sepse më pëlqen Patroni. Dhe, besoj se kam mësuar ta përdor.
Nëse jeni të interesuar të shikoni çfarë probleme të tjera ekzistojnë me Patroni, përveç atyre që kam përmendur, gjithmonë mund të shkoni në faqen në GitHub. Atje ka shumë histori të ndryshme dhe diskutojnë shumë probleme interesante. Dhe në fund, disa bug-e janë regjistruar dhe zgjidhur, pra është një lexim interesant.
Atje ka histori interesante për mënyrën se si ndokush i shënon veten në këmbë. Shumë edukative. Lexon dhe kupton se nuk duhet ta bësh atë. Kam shënuar një shenjë për veten.
Dhe do të donja të shprehja falënderimin tim të madh për kompaninë Zalando për zhvillimin e këtij projekti, veçanërisht Aleksandrit Kukushkin dhe Aleksej Kljukin. Aleksej Kljukin është një nga bashkëautorët, ai nuk punon më në Zalando, por këta janë dy njerëz që filluan të punojnë me këtë produkt.
Dhe besoj se Patroni është një gjë shumë e shkëlqyer. Jam i kënaqur që ekziston, është interesante. Dhe një falënderim i madh për të gjithë kontribuuesit që shkruajnë patch-e në Patroni. Shpresoj që Patroni, me kalimin e kohës, të bëhet më i pjekur, më cool dhe më funksional. Ai është funksional në këtë moment, por shpresoj se do të bëhet edhe më i mirë. Pra, nëse planifikoni ta përdorni Patroni, mos u frikësoni. Është një zgjidhje e mirë, mund ta implementoni dhe përdorni.
Kjo është tërë. Nëse keni pyetje, pyetni.

Pyetje
Faleminderit për raportin! Nëse pas filesh errorit ende duhet të shikojmë shumë me kujdes, atëherë përse na nevojitet një files error automatik?
Sepse kjo është një gjë e re. Ne po punojmë me të vetëm për një vit. Më mirë të jemi të sigurt. Duam të hyjmë dhe të shohim se çdo gjë ka funksionuar ashtu si duhet. Ky është një nivel i mosbesimit të rritur - më mirë të kontrollojmë dhe të shohim.
Për shembull, ne hynim dhe kontrollonim në mëngjes, apo jo?
Jo në mëngjes, ne zakonisht e mësojmë për filesh errorin automatik praktikisht menjëherë. Na vijnë njoftimet, shohim që ka ndodhur një files error automatik. Ne hyjmë dhe kontrollojmë praktikisht menjëherë. Por të gjitha këto kontrolle duhet të jenë të transferuara në nivelin e monitorimit. Nëse i drejtohemi Patroni përmes REST API, ka historikun. Nga historia, mund të shohim shenjat kohore kur ka ndodhur files errori. Në bazë të kësaj, mund të bëjmë monitorim. Mund të shohim historikun, sa ngjarje ka pasur. Nëse kemi më shumë ngjarje, do të thotë se ka ndodhur një files error automatik. Mund të shkojmë dhe të shohim. Ose automatikja jonë në monitorim kontrolloi që të gjitha replikat janë në vend, nuk ka vonesa dhe gjithçka është në rregull.
Faleminderit!
Faleminderit shumë për tregimin e shkëlqyer! Nëse ne e zhvendosim grumbullin DCS në ndonjë vend larg grumbullit Postgres, a duhet ta mirëmbajmë atë grumbull gjithashtu nga kohë në kohë? Cilat janë praktikat më të mira për të çaktivizuar disa pjesë të grumbullit DCS, çfarë të bëjmë me to etj.? Si funksionon e gjithë kjo konstruktion? Dhe si mund të realizohen këto gjëra?
Për një kompani duhej të bëhej një matricë problemesh, që ndodh nëse ndonjë nga komponentët ose disa komponentë dalin jashtë funksionit. Sipas kësaj matrice, ne kalojmë rregullisht të gjithë komponentët dhe ndërtuam skenarët në rast të dështimit të këtyre komponentëve. Për çdo skenar dështimi mund të kemi një plan veprimi për rikuperim. Dhe në rastin e DCS, kjo bëhet si pjesë e infrastrukturës standarde. Dhe administratori e menaxhon, dhe ne tashmë mbështetemi te administratorët që e menaxhojnë dhe aftësitë e tij për ta riparuar atë në rast situatash emergjente. Nëse DCS nuk ekziston fare, ne e vendosim atë, por nuk e ndjekim shumë, sepse nuk jemi përgjegjës për infrastrukturën, por japim rekomandime si dhe çfarë të monitorohet.
Kjo do të thotë, a e kuptova saktë që duhet të fikim Patroni, të fikim failoverin, të fikim gjithçka para se të bëjmë diçka me gazurat?
Kjo varet nga sa node ka në klasterin DCS. Nëse ka shumë node dhe ne e dalim jashtë funksioni vetëm një nga node-t (replikën), atëherë klasteri e ruan kuorumin. Dhe Patroni mbetet në funksion. Asgjë nuk aktivizohet. Nëse kemi ndonjë operacion më të komplikuar që prek më shumë node, mungesa e të cilëve mund të shkatërrojë kuorumin, atëherë - po, ndoshta ka kuptim ta vendosim Patronin në pauzë. Ka një komandë përkatëse - patronictl pause, patronictl resume. Ne thjesht e vendosim në pauzë, dhe failover-i automatik nuk aktivizohet në këtë kohë. Ne bëjmë mirëmbajtje në klasterin DCS, pastaj e heqim pauzën dhe kemi vazhduar si zakonisht.
Faleminderit shumë!
Faleminderit shumë për raportin! Si e sheh ekipi i produktit faktin që të dhënat mund të humbasin?
Ekipet e produktit nuk e bëjnë shumë për këtë, por liderët e ekipeve janë të shqetësuar.
Çfarë garancish ka atje?
Garancitë janë shumë të komplikuara. Ka një raport nga Aleksandër Kukushkin titulluar "Si të llogarisim RPO dhe RTO", që do të thotë koha e rikuperimit dhe sa të dhëna mund të humbasim. Mendoj se duhet të gjejmë këto prezantime dhe t'i studiojmë ato. Sa e mbaj mend, aty ka hapa të veçantë se si të llogaritni këto gjëra. Sa transaksione mund të humbasim, sa të dhëna mund të humbasim. Si mundësi mund të përdorim replikimin sinkron në nivelin e Patroni, por kjo është një thikë me dy presa: ose kemi besueshmërinë e të dhënave, ose humbasim në shpejtësi. Ka replikim sinkron, por edhe ai nuk garanton mbrojtje 100% nga humbja e të dhënave.
Alex, faleminderit për raportin e shkëlqyer! Ka ndonjë eksperiencë në përdorimin e Patroni për mbrojtje në nivel zero? Domethënë, në kombinim me standby sinkron? Ky është një pyetje e parë. Dhe pyetje e dytë. Keni përdorur zgjidhje të ndryshme. Ne kemi përdorur Repmgr, por pa auto-failover dhe tani planifikojmë të lidhim auto-failover. Po shqyrtojmë Patroni si një zgjidhje alternative. Çfarë mund të thoni për avantazhet në krahasim me Repmgr?
Pyety i parë ishte për replikat sinherike. Askush te ne nuk përdor replikimin sinhronik, sepse të gjithë kanë frikë (Disa klientë tashmë po e përdorin, nuk kanë vënë re probleme me performancën në parim — Shënimi i foli). Por ne kemi krijuar një rregull për veten tonë, që në një klaster replikimi sinhronik duhet të ketë të paktën tre nyje, sepse, nëse kemi dy nyje dhe nëse masteri ose replikimi dështojnë, atëherë Patroni e kalon këtë nyje në modin Standalone, për të vazhduar funksionimin e aplikacionit. Në këtë rast, ka rreziqe për humbje të të dhënave.
Sa i përket pyetjes së dytë, ne kemi përdorur Repmgr dhe vazhdojmë ta përdorim me disa klientë për arsye historike. Çfarë mund të themi? Në Patroni auto-failoveri është i integruar, ndërsa në Repmgr auto-failoveri është një tipar shtesë që duhet aktivizuar. Duhet të fillojmë daemon-in e Repmgr në çdo nyje dhe atëherë mund të konfiguroni auto-failoverin.
Repmgr kontrollon nëse node-t e Postgres janë aktive. Proceset e Repmgr kontrollojnë njëri-tjetrin, që nuk është një qasje shumë efikase pasi mund të ketë raste komplekse të izolimit rrjetit ku një kluster i madh Repmgr mund të ndahet në disa të vogla dhe të vazhdojë të funksionojë. Nuk e kam ndjekur prej kohësh Repmgr, ndoshta e kanë rregulluar këtë... ndoshta jo. Por, nxjerrja e informacionit mbi gjendjen e klustrit në DCS, siç bën Stolon, Patroni, është varianti më i jetueshëm.
Alexei, kam një pyetje, ndoshta të thjeshtë. Në një nga shembujt e parë, ju nxorrët DCS-në nga makina lokale në një node të largët. E kuptojmë që rrjeti është një gjë që ka karakteristikat e veta, ai vetë jeton. Çfarë do të ndodhte nëse për ndonjë arsye klustri DCS do të bëhej i paaksesueshëm? Nuk do të flas për arsyet, mund të ketë shumë: nga duar të këqija të rrjetikëve deri te probleme reale.
Nuk e thashë këtë me zë të lartë, por klasteri DCS duhet të jetë gjithashtu i qëndrueshëm ndaj dështimeve, dmth. duhet të ketë një numër të ç oddit të nyjeve, në mënyrë që të mund të formohet një kuorum. Çfarë ndodh nëse klasteri DCS bëhet i paqartë, ose nuk mund të formohet kuorumi, dmth. ndonjë ndarje rrjetore ose dështim nyjesh? Në këtë rast, klasteri Patroni kalon në modin read only. Klasteri Patroni nuk mund të përcaktojë gjendjen e klasterit dhe çfarë duhet të bëjë. Ai nuk mund të lidhet me DCS dhe të ruajë atje gjendjen e re të klasterit, prandaj i gjithë klasteri kalon në read only. Dhe pret ose ndërhyrje manuale nga operatori ose rikthimin e DCS.
Në terma të thjeshtë, DCS për ne bëhet një shërbim po aq i rëndësishëm sa vetë baza?
Po, në shumë kompani moderne, Zbulimi i Shërbimeve është një pjesë e pandashme e infrastrukturës. Ai implementohet madje para se të ketë një bazë të dhënash në infrastrukturë. Siç thuhet, ne kemi nisur infrastrukturën, kemi vendosur në Qendrën e të Dhënave, dhe menjëherë kemi Zbulimin e Shërbimeve. Nëse është Consul, atëherë edhe DNS mund të ndërtohet mbi të. Nëse është Etcd, mund të jetë një pjesë nga klasteri Kubernetes, në të cilin gjithçka tjetër do të vendoset. Më duket se Zbulimi i Shërbimeve është tashmë një pjesë e pandashme e infrastrukturave moderne. Dhe për të mendohet shumë më herët sesa për bazat e të dhënave.
Faleminderit!
Burimi: habr.com
