

Në këtë artikull, unë do të flas se si projekti për të cilin jam duke punuar u shndërrua nga një monolit i madh në një grup mikroshërbimesh.
Projekti filloi historinë e tij shumë kohë më parë, në fillim të vitit 2000. Versionet e para u shkruan në Visual Basic 6. Me kalimin e kohës, u bë e qartë se zhvillimi në këtë gjuhë do të ishte i vështirë për t'u mbështetur në të ardhmen, pasi IDE dhe vetë gjuha janë të zhvilluara dobët. Në fund të viteve 2000, u vendos të kalonte në C# më premtues. Versioni i ri u shkrua paralelisht me rishikimin e të vjetrit, gradualisht gjithnjë e më shumë kod u shkrua në .NET. Backend në C# fillimisht u fokusua në një arkitekturë shërbimi, por gjatë zhvillimit, bibliotekat e zakonshme me logjikë u përdorën dhe shërbimet u lansuan në një proces të vetëm. Rezultati ishte një aplikacion që ne e quajtëm "monolit shërbimi".
Një nga avantazhet e pakta të këtij kombinimi ishte aftësia e shërbimeve për të thirrur njëri-tjetrin përmes një API të jashtëm. Kishte parakushte të qarta për kalimin në një shërbim më korrekt, dhe në të ardhmen, në arkitekturën e mikroshërbimeve.
Ne filluam punën tonë për dekompozimin rreth vitit 2015. Ne nuk kemi arritur ende një gjendje ideale - ka ende pjesë të një projekti të madh që vështirë se mund të quhen monolite, por ato nuk duken as si mikroshërbime. Gjithsesi, progresi është domethënës.
Unë do të flas për këtë në artikull.
Përmbajtje
Arkitektura dhe problemet e zgjidhjes ekzistuese
Fillimisht, arkitektura dukej kështu: UI është një aplikacion i veçantë, pjesa monolit është shkruar në Visual Basic 6, aplikacioni .NET është një grup shërbimesh të lidhura që punojnë me një bazë të dhënash mjaft të madhe.
Disavantazhet e zgjidhjes së mëparshme
Pika e vetme e dështimit
Kishim një pikë të vetme dështimi: aplikacioni .NET u ekzekutua në një proces të vetëm. Nëse ndonjë modul dështonte, i gjithë aplikacioni dështoi dhe duhej të rifillohej. Meqenëse ne automatizojmë një numër të madh procesesh për përdorues të ndryshëm, për shkak të një dështimi në njërin prej tyre, të gjithë nuk mund të punonin për ca kohë. Dhe në rast të një gabimi të softuerit, as rezervimi nuk ndihmoi.
Radha e përmirësimeve
Ky pengesë është më tepër organizative. Aplikacioni ynë ka shumë klientë dhe të gjithë duan ta përmirësojnë sa më shpejt të jetë e mundur. Më parë, ishte e pamundur për ta bërë këtë paralelisht, dhe të gjithë klientët qëndronin në radhë. Ky proces ishte negativ për bizneset sepse duhej të dëshmonin se detyra e tyre ishte e vlefshme. Dhe ekipi i zhvillimit kaloi kohë duke organizuar këtë radhë. Kjo mori shumë kohë dhe përpjekje, dhe produkti në fund të fundit nuk mund të ndryshonte aq shpejt sa ata do të dëshironin.
Përdorimi jo optimal i burimeve
Kur presim shërbime në një proces të vetëm, ne gjithmonë e kopjojmë plotësisht konfigurimin nga serveri në server. Ne donim të vendosnim veçmas shërbimet më të ngarkuara, në mënyrë që të mos shpërdornim burimet dhe të fitonim kontroll më fleksibël mbi skemën tonë të vendosjes.
Vështirë për të zbatuar teknologji moderne
Një problem i njohur për të gjithë zhvilluesit: ekziston një dëshirë për të futur teknologji moderne në projekt, por nuk ka asnjë mundësi. Me një zgjidhje të madhe monolit, çdo përditësim i bibliotekës aktuale, për të mos përmendur kalimin në një të re, kthehet në një detyrë mjaft jo të parëndësishme. Duhet shumë kohë për t'i vërtetuar drejtuesit të ekipit se kjo do të sjellë më shumë shpërblime sesa nerva të humbura.
Vështirësi në nxjerrjen e ndryshimeve
Ky ishte problemi më serioz - ne lëshonim botime çdo dy muaj.
Çdo lëshim u shndërrua në një fatkeqësi të vërtetë për bankën, pavarësisht testimit dhe përpjekjeve të zhvilluesve. Biznesi e kuptoi që në fillim të javës një pjesë e funksionalitetit të tij nuk do të funksiononte. Dhe zhvilluesit e kuptuan që i priste një javë incidentesh serioze.
Të gjithë kishin një dëshirë për të ndryshuar situatën.
Pritjet nga mikroshërbimet
Lëshimi i komponentëve kur të jetë gati. Dorëzimi i komponentëve kur të jetë gati duke dekompozuar tretësirën dhe duke ndarë procese të ndryshme.
Ekipet e vogla të produkteve. Kjo është e rëndësishme sepse një ekip i madh që punonte në monolitin e vjetër ishte i vështirë për t'u menaxhuar. Një ekip i tillë u detyrua të punonte sipas një procesi të rreptë, por ata donin më shumë kreativitet dhe pavarësi. Vetëm ekipet e vogla mund ta përballonin këtë.
Izolimi i shërbimeve në procese të veçanta. Idealisht, do të doja ta izoloja atë në kontejnerë, por një numër i madh shërbimesh të shkruara në .NET Framework funksionojnë vetëm nën WindowsShërbimet e bazuara në .NET Core po shfaqen tani, por ka ende pak prej tyre.
Fleksibiliteti i vendosjes. Ne do të donim t'i kombinonim shërbimet ashtu siç na duhen, dhe jo siç e detyron kodi.
Përdorimi i teknologjive të reja. Kjo është interesante për çdo programues.
Problemet e tranzicionit
Sigurisht, nëse do të ishte e lehtë për të thyer një monolit në mikroshërbime, nuk do të kishte nevojë të flitej për të në konferenca dhe të shkruani artikuj. Ka shumë gracka në këtë proces; unë do të përshkruaj ato kryesore që na penguan.
Problemi i parë tipike për shumicën e monoliteve: koherenca e logjikës së biznesit. Kur shkruajmë një monolit, duam të ripërdorim klasat tona në mënyrë që të mos shkruajmë kod të panevojshëm. Dhe kur kaloni në mikroshërbime, kjo bëhet problem: i gjithë kodi është i lidhur ngushtë dhe është e vështirë të ndash shërbimet.
Në kohën e fillimit të punës, depoja kishte më shumë se 500 projekte dhe më shumë se 700 mijë rreshta kodi. Ky është një vendim mjaft i madh dhe problemi i dytë. Nuk ishte e mundur që thjesht ta merrje dhe ta ndante në mikroshërbime.
Problemi i tretë — mungesa e infrastrukturës së nevojshme. Në fakt, ne po kopjonim manualisht kodin burim në serverë.
Si të kaloni nga monolit në mikroshërbime
Ofrimi i mikroshërbimeve
Së pari, ne përcaktuam menjëherë vetë se ndarja e mikroshërbimeve është një proces përsëritës. Gjithmonë na kërkohet të zhvillojmë paralelisht problemet e biznesit. Si do ta zbatojmë teknikisht këtë është tashmë problemi ynë. Prandaj, u përgatitëm për një proces përsëritës. Nuk do të funksionojë ndryshe nëse keni një aplikacion të madh dhe nuk është fillimisht gati për t'u rishkruar.
Çfarë metodash përdorim për të izoluar mikroshërbimet?
Mënyra e parë — zhvendosni modulet ekzistuese si shërbime. Në këtë drejtim, ne ishim me fat: tashmë kishte shërbime të regjistruara që funksiononin duke përdorur protokollin WCF. Ata u ndanë në asamble të veçanta. Ne i transferuam ato veç e veç, duke shtuar një lëshues të vogël në çdo ndërtim. Ajo u shkrua duke përdorur bibliotekën e mrekullueshme Topshelf, e cila ju lejon të ekzekutoni aplikacionin si shërbim dhe si konsolë. Kjo është e përshtatshme për korrigjimin e gabimeve pasi nuk kërkohen projekte shtesë në zgjidhje.
Shërbimet ishin të lidhura sipas logjikës së biznesit, pasi përdornin asamble të përbashkëta dhe punonin me një bazë të dhënash të përbashkët. Ato vështirë se mund të quheshin mikroshërbime në formën e tyre të pastër. Megjithatë, ne mund t'i ofrojmë këto shërbime veçmas, në procese të ndryshme. Vetëm kjo bëri të mundur uljen e ndikimit të tyre tek njëri-tjetri, duke reduktuar problemin me zhvillimin paralel dhe një pikë të vetme dështimi.
Asambleja me hostin është vetëm një rresht kodi në klasën e Programit. Ne e fshehëm punën me Topshelf në një klasë ndihmëse.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Mënyra e dytë për të ndarë mikroshërbimet është: krijoni ato për të zgjidhur probleme të reja. Nëse në të njëjtën kohë monoliti nuk rritet, kjo tashmë është e shkëlqyeshme, që do të thotë se ne po ecim në drejtimin e duhur. Për të zgjidhur problemet e reja, ne u përpoqëm të krijonim shërbime të veçanta. Nëse ekzistonte një mundësi e tillë, atëherë ne krijuam më shumë shërbime "kanonike" që menaxhojnë plotësisht modelin e tyre të të dhënave, një bazë të dhënash të veçantë.
Ne, si shumë, filluam me shërbimet e vërtetimit dhe autorizimit. Ata janë të përsosur për këtë. Ata janë të pavarur, si rregull, ata kanë një model të veçantë të dhënash. Ata vetë nuk ndërveprojnë me monolitin, vetëm ai u drejtohet atyre për të zgjidhur disa probleme. Duke përdorur këto shërbime, mund të filloni kalimin në një arkitekturë të re, të korrigjoni infrastrukturën në to, të provoni disa qasje që lidhen me bibliotekat e rrjetit, etj. Ne nuk kemi asnjë ekip në organizatën tonë që nuk mund të krijonte një shërbim vërtetimi.
Mënyra e tretë për të ndarë mikroshërbimetAi që përdorim është pak specifik për ne. Kjo është heqja e logjikës së biznesit nga shtresa UI. Aplikacioni ynë kryesor i UI është desktopi; ai, si pjesa e pasme, është e shkruar në C#. Zhvilluesit në mënyrë periodike bënin gabime dhe transferuan pjesë të logjikës në UI që duhej të ekzistonin në backend dhe të ripërdoreshin.
Nëse shikoni një shembull real nga kodi i pjesës UI, mund të shihni se shumica e kësaj zgjidhjeje përmban logjikë reale biznesi që është e dobishme në procese të tjera, jo vetëm për ndërtimin e formularit UI.
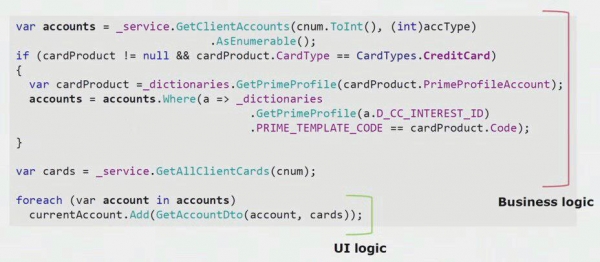
Logjika e vërtetë e ndërfaqes është vetëm në dy rreshtat e fundit. Ne e transferuam atë në server në mënyrë që të mund të ripërdoret, duke zvogëluar kështu ndërfaqen e përdoruesit dhe duke arritur arkitekturën e duhur.
Mënyra e katërt dhe më e rëndësishme për të izoluar mikroshërbimet, e cila bën të mundur uljen e monolitit, është heqja e shërbimeve ekzistuese me përpunim. Kur nxjerrim modulet ekzistuese siç janë, rezultati nuk është gjithmonë sipas dëshirës së zhvilluesve dhe procesi i biznesit mund të jetë vjetëruar që nga krijimi i funksionalitetit. Me rifaktorimin, ne mund të mbështesim një proces të ri biznesi sepse kërkesat e biznesit po ndryshojnë vazhdimisht. Ne mund të përmirësojmë kodin burimor, të heqim defektet e njohura dhe të krijojmë një model më të mirë të të dhënave. Ka shumë përfitime që rrjedhin.
Ndarja e shërbimeve nga përpunimi është e lidhur pazgjidhshmërisht me konceptin e kontekstit të kufizuar. Ky është një koncept nga Domain Driven Design. Do të thotë një seksion i modelit të domenit në të cilin të gjitha termat e një gjuhe të vetme përcaktohen në mënyrë unike. Le të shohim kontekstin e sigurimeve dhe faturave si shembull. Ne kemi një aplikim monolit, dhe duhet të punojmë me llogarinë në sigurime. Ne presim që zhvilluesi të gjejë një klasë ekzistuese Llogarie në një asamble tjetër, ta referojë atë nga klasa e Sigurimeve dhe ne do të kemi kodin e punës. Parimi DRY do të respektohet, detyra do të kryhet më shpejt duke përdorur kodin ekzistues.
Si rezultat, rezulton se kontekstet e llogarive dhe sigurimit janë të lidhura. Ndërsa shfaqen kërkesa të reja, ky bashkim do të ndërhyjë në zhvillim, duke rritur kompleksitetin e logjikës tashmë komplekse të biznesit. Për të zgjidhur këtë problem, duhet të gjeni kufijtë midis konteksteve në kod dhe të hiqni shkeljet e tyre. Për shembull, në kontekstin e sigurimit, është mjaft e mundshme që një numër 20-shifror i llogarisë së Bankës Qendrore dhe data e hapjes së llogarisë të jenë të mjaftueshme.
Për të ndarë këto kontekste të kufizuara nga njëri-tjetri dhe për të filluar procesin e ndarjes së mikroshërbimeve nga një zgjidhje monolit, ne përdorëm një qasje të tillë si krijimi i API-ve të jashtme brenda aplikacionit. Nëse do ta dinim që një modul duhet të shndërrohej në një mikroshërbim, i modifikuar disi brenda procesit, atëherë ne bënim menjëherë thirrje në logjikën që i përket një konteksti tjetër të kufizuar përmes thirrjeve të jashtme. Për shembull, nëpërmjet REST ose WCF.
Ne vendosëm me vendosmëri se nuk do të shmangnim kodin që do të kërkonte transaksione të shpërndara. Në rastin tonë, doli të ishte mjaft e lehtë për të ndjekur këtë rregull. Ne nuk kemi hasur ende situata ku transaksione strikte të shpërndara janë vërtet të nevojshme - konsistenca përfundimtare midis moduleve është mjaft e mjaftueshme.
Le të shohim një shembull specifik. Ne kemi konceptin e një orkestruesi - një tubacion që përpunon entitetin e "aplikacionit". Ai krijon një klient, një llogari dhe një kartë bankare nga ana tjetër. Nëse klienti dhe llogaria krijohen me sukses, por krijimi i kartës dështon, aplikacioni nuk kalon në statusin "i suksesshëm" dhe mbetet në statusin "karta nuk u krijua". Në të ardhmen, aktiviteti në sfond do ta marrë dhe do ta përfundojë. Sistemi ka kohë që është në një gjendje mospërputhjeje, por ne përgjithësisht jemi të kënaqur me këtë.
Nëse lind një situatë kur është e nevojshme të ruhet vazhdimisht një pjesë e të dhënave, me shumë mundësi do të shkojmë në konsolidimin e shërbimit për ta përpunuar atë në një proces.
Le të shohim një shembull të ndarjes së një mikroshërbimi. Si mund ta sillni atë në prodhim relativisht të sigurt? Në këtë shembull, ne kemi një pjesë të veçantë të sistemit - një modul shërbimi të listës së pagave, një nga seksionet e kodit të të cilit do të dëshironim të bënim mikroshërbim.
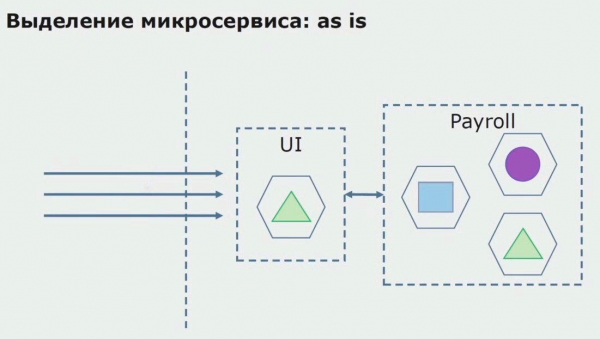
Para së gjithash, ne krijojmë një mikroshërbim duke rishkruar kodin. Ne po përmirësojmë disa aspekte me të cilat nuk ishim të kënaqur. Ne zbatojmë kërkesat e reja të biznesit nga klienti. Ne shtojmë një portë API në lidhjen midis UI dhe backend, i cili do të sigurojë përcjelljen e thirrjeve.
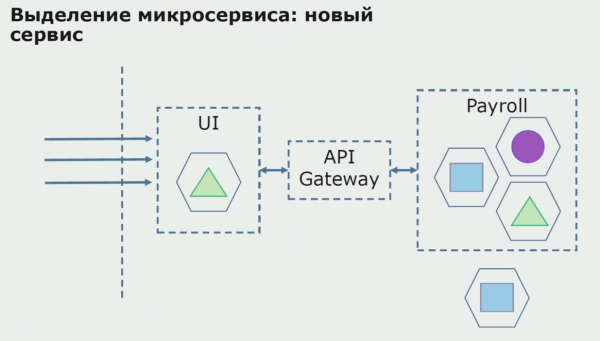
Më pas, ne e lëshojmë këtë konfigurim në funksion, por në një gjendje pilot. Shumica e përdoruesve tanë ende punojnë me procese të vjetra biznesi. Për përdoruesit e rinj, ne po zhvillojmë një version të ri të aplikacionit monolit që nuk e përmban më këtë proces. Në thelb, ne kemi një kombinim të një monoliti dhe një mikroshërbimi që punon si pilot.
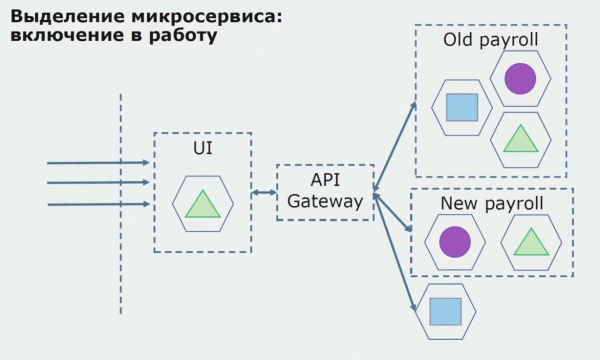
Me një pilot të suksesshëm, ne kuptojmë se konfigurimi i ri është me të vërtetë i zbatueshëm, ne mund të heqim monolitin e vjetër nga ekuacioni dhe të lëmë konfigurimin e ri në vend të zgjidhjes së vjetër.
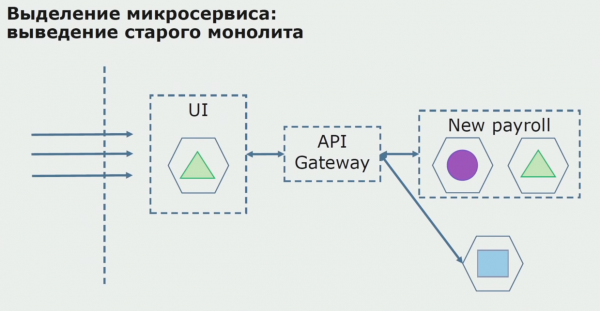
Në total, ne përdorim pothuajse të gjitha metodat ekzistuese për ndarjen e kodit burimor të një monoliti. Të gjitha ato na lejojnë të zvogëlojmë madhësinë e pjesëve të aplikacionit dhe t'i përkthejmë ato në biblioteka të reja, duke e bërë kodin burimor më të mirë.
Puna me bazën e të dhënave
Baza e të dhënave mund të ndahet më keq se kodi burimor, pasi përmban jo vetëm skemën aktuale, por edhe të dhëna historike të grumbulluara.
Baza jonë e të dhënave, si shumë të tjera, kishte një pengesë tjetër të rëndësishme - madhësinë e saj të madhe. Kjo bazë të dhënash është projektuar sipas logjikës së ndërlikuar të biznesit të një monoliti, dhe marrëdhënieve të grumbulluara midis tabelave të konteksteve të ndryshme të kufizuara.
Në rastin tonë, për të përfunduar të gjitha problemet (baza e të dhënave e madhe, shumë lidhje, ndonjëherë kufij të paqartë midis tabelave), u shfaq një problem që ndodh në shumë projekte të mëdha: përdorimi i shabllonit të bazës së të dhënave të përbashkët. Të dhënat u morën nga tabelat përmes pamjes, përmes replikimit dhe u dërguan në sisteme të tjera ku ky përsëritje ishte i nevojshëm. Si rezultat, ne nuk mund t'i zhvendosim tabelat në një skemë të veçantë, sepse ato u përdorën në mënyrë aktive.
E njëjta ndarje në kontekste të kufizuara në kod na ndihmon në ndarje. Zakonisht na jep një ide mjaft të mirë se si i zbërthejmë të dhënat në nivelin e bazës së të dhënave. Ne kuptojmë se cilat tabela i përkasin një konteksti të kufizuar dhe cilat një tjetri.
Ne përdorëm dy metoda globale të ndarjes së bazës së të dhënave: ndarjen e tabelave ekzistuese dhe ndarjen me përpunim.
Ndarja e tabelave ekzistuese është një metodë e mirë për t'u përdorur nëse struktura e të dhënave është e mirë, plotëson kërkesat e biznesit dhe të gjithë janë të kënaqur me të. Në këtë rast, ne mund të ndajmë tabelat ekzistuese në një skemë të veçantë.
Një departament me përpunim nevojitet kur modeli i biznesit ka ndryshuar shumë, dhe tabelat nuk na kënaqin më.
Ndarja e tabelave ekzistuese. Duhet të përcaktojmë se çfarë do të ndajmë. Pa këtë njohuri, asgjë nuk do të funksionojë, dhe këtu ndarja e konteksteve të kufizuara në kod do të na ndihmojë. Si rregull, nëse mund të kuptoni kufijtë e konteksteve në kodin burimor, bëhet e qartë se cilat tabela duhet të përfshihen në listën për departamentin.
Le të imagjinojmë se kemi një zgjidhje në të cilën dy module monolit ndërveprojnë me një bazë të dhënash. Duhet të sigurohemi që vetëm një modul të ndërveprojë me seksionin e tabelave të ndara dhe tjetri të fillojë të ndërveprojë me të nëpërmjet API-së. Për të filluar, mjafton që vetëm regjistrimi të kryhet përmes API. Ky është një kusht i domosdoshëm që ne të flasim për pavarësinë e mikroshërbimeve. Lidhjet e leximit mund të mbeten për aq kohë sa nuk ka ndonjë problem të madh.
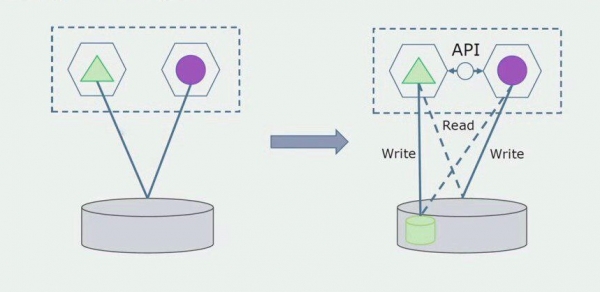
Hapi tjetër është që ne mund të ndajmë seksionin e kodit që funksionon me tabela të ndara, me ose pa përpunim, në një mikroshërbim të veçantë dhe ta ekzekutojmë në një proces të veçantë, një kontejner. Ky do të jetë një shërbim i veçantë me një lidhje me bazën e të dhënave monolit dhe ato tabela që nuk lidhen drejtpërdrejt me të. Monoliti ende ndërvepron për lexim me pjesën e shkëputshme.
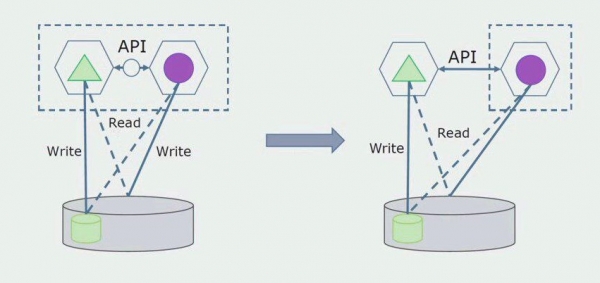
Më vonë do ta heqim këtë lidhje, domethënë, leximi i të dhënave nga një aplikacion monolit nga tabela të ndara do të transferohet gjithashtu në API.
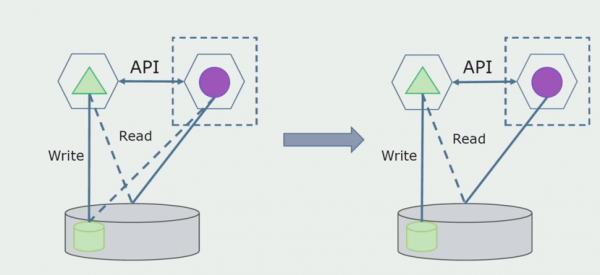
Më pas, do të zgjedhim nga baza e përgjithshme e të dhënave tabelat me të cilat funksionon vetëm mikroservis i ri. Ne mund t'i zhvendosim tabelat në një skemë të veçantë ose edhe në një bazë të dhënash fizike të veçantë. Ekziston ende një lidhje leximi midis mikroshërbimit dhe bazës së të dhënave monolit, por nuk ka asgjë për t'u shqetësuar, në këtë konfigurim mund të jetojë për një kohë mjaft të gjatë.
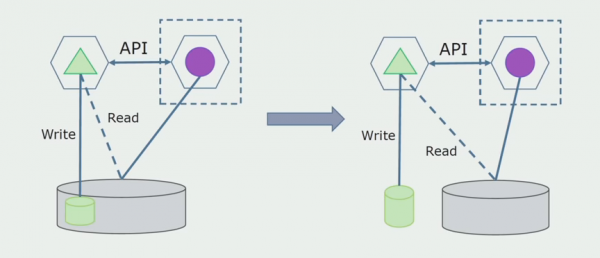
Hapi i fundit është të hiqni plotësisht të gjitha lidhjet. Në këtë rast, mund të na duhet të migrojmë të dhënat nga baza e të dhënave kryesore. Ndonjëherë duam të ripërdorim disa të dhëna ose direktori të kopjuara nga sisteme të jashtme në disa baza të dhënash. Kjo na ndodh periodikisht.
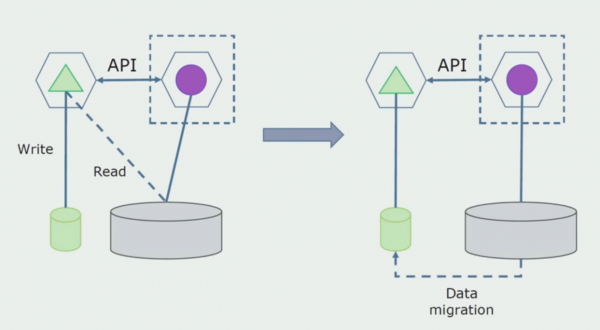
Departamenti i përpunimit. Kjo metodë është shumë e ngjashme me të parën, vetëm në rend të kundërt. Ne shpërndajmë menjëherë një bazë të dhënash të re dhe një mikroshërbim të ri që ndërvepron me monolitin nëpërmjet një API. Por në të njëjtën kohë, mbetet një grup tabelash të bazës së të dhënave që duam t'i fshijmë në të ardhmen. Nuk na nevojitet më; e zëvendësuam në modelin e ri.
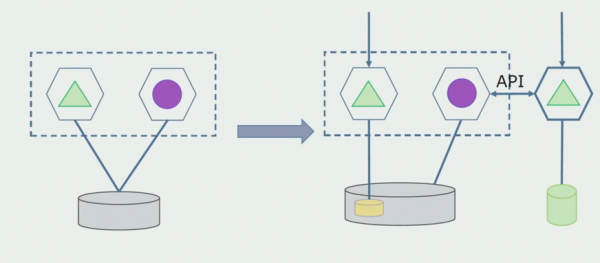
Që kjo skemë të funksionojë, ka të ngjarë të na duhet një periudhë tranzicioni.
Atëherë ka dy qasje të mundshme.
I parë: ne dublikojmë të gjitha të dhënat në bazën e të dhënave të reja dhe të vjetra. Në këtë rast, kemi tepricë të të dhënave dhe mund të lindin probleme sinkronizimi. Por ne mund të marrim dy klientë të ndryshëm. Njëri do të punojë me versionin e ri, tjetri me atë të vjetër.
I dytë: i ndajmë të dhënat sipas disa kritereve të biznesit. Për shembull, ne kishim 5 produkte në sistem që ishin të ruajtura në bazën e të dhënave të vjetër. Ne e vendosim të gjashtin brenda detyrës së re të biznesit në një bazë të dhënash të re. Por do të na duhet një API Gateway që do të sinkronizojë këto të dhëna dhe do t'i tregojë klientit nga dhe nga të marrë.
Të dyja qasjet funksionojnë, zgjidhni në varësi të situatës.
Pasi të jemi të sigurt se gjithçka funksionon, pjesa e monolitit që funksionon me strukturat e vjetra të bazës së të dhënave mund të çaktivizohet.
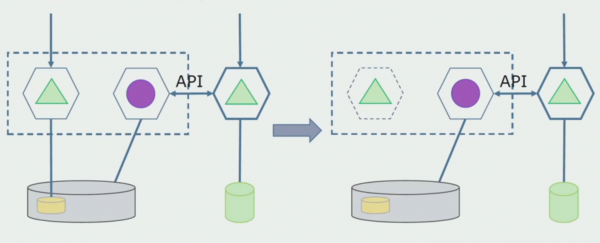
Hapi i fundit është heqja e strukturave të vjetra të të dhënave.
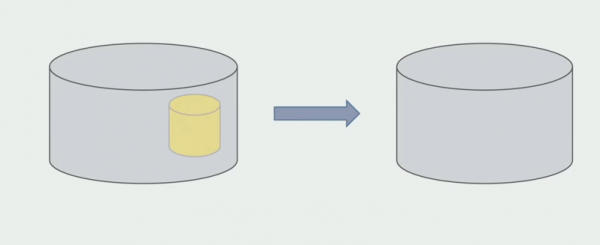
Për ta përmbledhur, mund të themi se kemi probleme me bazën e të dhënave: është e vështirë të punosh me të në krahasim me kodin burimor, është më e vështirë të ndash, por mund dhe duhet të bëhet. Ne kemi gjetur disa mënyra që na lejojnë ta bëjmë këtë në mënyrë mjaft të sigurt, por është akoma më e lehtë të bëjmë gabime me të dhënat sesa me kodin burimor.
Puna me kodin burimor
Kështu dukej diagrami i kodit burimor kur filluam të analizonim projektin monolit.
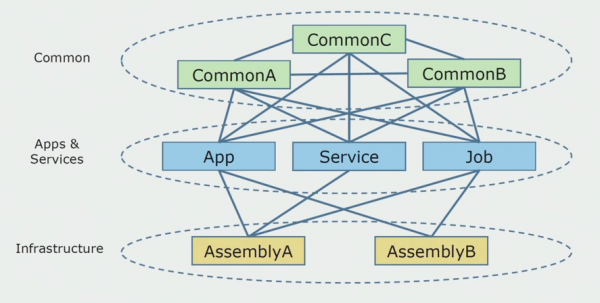
Mund të ndahet përafërsisht në tre shtresa. Kjo është një shtresë e moduleve të lançuara, shtojcave, shërbimeve dhe aktiviteteve individuale. Në fakt, këto ishin pika hyrëse brenda një zgjidhjeje monolitike. Të gjithë ata ishin të mbyllur fort me një shtresë të përbashkët. Kishte logjikë biznesi që shërbimet ndanin dhe shumë lidhje. Çdo shërbim dhe shtojcë përdorte deri në 10 ose më shumë asamble të zakonshme, në varësi të madhësisë së tyre dhe ndërgjegjes së zhvilluesve.
Ne ishim me fat që kishim biblioteka infrastrukturore që mund të përdoreshin veçmas.
Ndonjëherë krijohej një situatë kur disa objekte të zakonshme nuk i përkisnin në fakt kësaj shtrese, por ishin biblioteka infrastrukturore. Kjo u zgjidh duke riemërtuar.
Shqetësimi më i madh ishin kontekstet e kufizuara. Ndodhi që 3-4 kontekste të përziheshin në një asamble të përbashkët dhe të përdornin njëri-tjetrin brenda të njëjtave funksione biznesi. Ishte e nevojshme të kuptohej se ku mund të ndahej kjo dhe përgjatë çfarë kufijsh, dhe çfarë të bëhej më pas me hartimin e kësaj ndarjeje në asambletë e kodit burimor.
Ne kemi formuluar disa rregulla për procesin e ndarjes së kodit.
Parë: Nuk donim më të ndajmë logjikën e biznesit midis shërbimeve, aktiviteteve dhe shtojcave. Ne donim të bënim logjikën e biznesit të pavarur brenda mikroshërbimeve. Mikroshërbimet, nga ana tjetër, mendohen në mënyrë ideale si shërbime që ekzistojnë plotësisht në mënyrë të pavarur. Unë besoj se kjo qasje është disi e kotë dhe është e vështirë të arrihet, sepse, për shembull, shërbimet në C# në çdo rast do të lidhen nga një bibliotekë standarde. Sistemi ynë është i shkruar në C#; ne nuk kemi përdorur ende teknologji të tjera. Prandaj, ne vendosëm që ne mund të përballonim përdorimin e asambleve të përbashkëta teknike. Gjëja kryesore është se ato nuk përmbajnë asnjë fragment të logjikës së biznesit. Nëse keni një mbështjellës të përshtatshëm mbi ORM-në që po përdorni, atëherë kopjimi i tij nga shërbimi në shërbim është shumë i shtrenjtë.
Ekipi ynë është një adhurues i dizajnit të drejtuar nga domeni, kështu që arkitektura e qepëve ishte një përshtatje e shkëlqyer për ne. Baza e shërbimeve tona nuk është shtresa e aksesit të të dhënave, por një asamble me logjikë domeni, e cila përmban vetëm logjikë biznesi dhe nuk ka lidhje me infrastrukturën. Në të njëjtën kohë, ne mund të modifikojmë në mënyrë të pavarur asamblenë e domenit për të zgjidhur problemet që lidhen me kornizat.
Në këtë fazë hasëm problemin tonë të parë serioz. Shërbimi duhej t'i referohej një asambleje domeni, ne donim ta bënim logjikën të pavarur dhe parimi DRY na pengoi shumë këtu. Zhvilluesit donin të ripërdornin klasa nga asambletë fqinje për të shmangur dyfishimin, dhe si rezultat, domenet filluan të lidhen përsëri së bashku. Ne analizuam rezultatet dhe vendosëm që ndoshta problemi qëndron edhe në zonën e pajisjes së ruajtjes së kodit burimor. Ne kishim një depo të madhe që përmbante të gjithë kodin burimor. Zgjidhja për të gjithë projektin ishte shumë e vështirë për t'u montuar në një makinë lokale. Prandaj, u krijuan zgjidhje të veçanta të vogla për pjesë të projektit, dhe askush nuk e ndaloi shtimin e ndonjë asambleje të zakonshme ose domeni në to dhe ripërdorimin e tyre. I vetmi mjet që nuk na lejoi ta bënim këtë ishte rishikimi i kodit. Por ndonjëherë edhe dështoi.
Pastaj filluam të kalojmë në një model me depo të veçanta. Logjika e biznesit nuk rrjedh më nga shërbimi në shërbim, domenet janë bërë vërtet të pavarura. Kontektet e kufizuara mbështeten më qartë. Si i ripërdorim bibliotekat e infrastrukturës? I ndamë në një depo të veçantë, më pas i vendosëm në paketat Nuget, të cilat i vendosëm në Artifactory. Me çdo ndryshim, montimi dhe publikimi ndodh automatikisht.
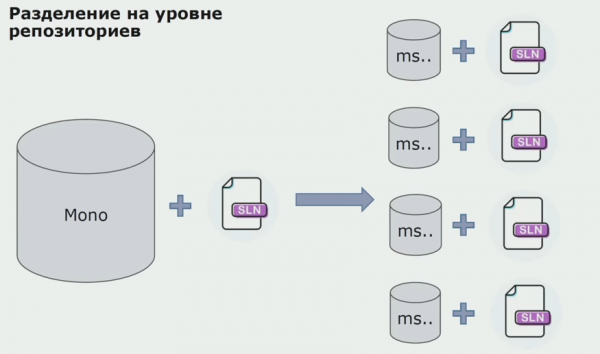
Shërbimet tona filluan të referojnë paketat e infrastrukturës së brendshme në të njëjtën mënyrë si ato të jashtme. Ne shkarkojmë bibliotekat e jashtme nga Nuget. Për të punuar me Artifactory, ku vendosëm këto paketa, përdorëm dy menaxherë paketash. Në depo të vogla kemi përdorur edhe Nuget. Në magazinat me shërbime të shumta, ne përdorëm Paket, i cili siguron më shumë konsistencë të versionit midis moduleve.
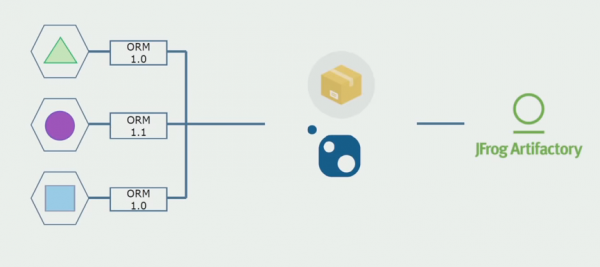
Kështu, duke punuar në kodin burimor, duke ndryshuar pak arkitekturën dhe duke ndarë depot, ne i bëjmë shërbimet tona më të pavarura.
Probleme infrastrukturore
Shumica e anëve negative të kalimit në mikroshërbime janë të lidhura me infrastrukturën. Ju do të keni nevojë për vendosje të automatizuar, do t'ju duhen biblioteka të reja për të drejtuar infrastrukturën.
Instalim manual në mjedise
Fillimisht, ne e instaluam zgjidhjen për mjedise me dorë. Për të automatizuar këtë proces, ne krijuam një tubacion CI/CD. Ne zgjodhëm procesin e dërgimit të vazhdueshëm sepse vendosja e vazhdueshme nuk është ende e pranueshme për ne nga pikëpamja e proceseve të biznesit. Prandaj, dërgimi për funksionim kryhet duke përdorur një buton, dhe për testim - automatikisht.
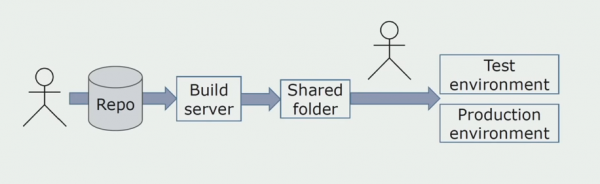
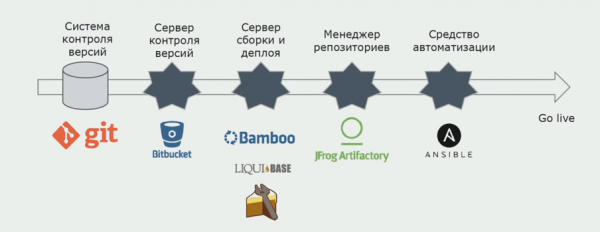
Ne përdorim Atlassian, Bitbucket për ruajtjen e kodit burimor dhe Bamboo për ndërtimin. Na pëlqen të shkruajmë skripta ndërtimi në Cake sepse është i njëjtë me C#. Paketat e gatshme vijnë në Artifactory, dhe Ansible kalon automatikisht në serverët e testimit, pas së cilës ato mund të testohen menjëherë.
Prerje të veçanta
Në një kohë, një nga idetë e monolitit ishte të siguronte prerje të përbashkëta. Ne gjithashtu duhej të kuptonim se çfarë të bënim me regjistrat individualë që janë në disqe. Regjistrat tanë janë shkruar në skedarë teksti. Ne vendosëm të përdorim një pirg standard ELK. Ne nuk i shkruam ELK direkt përmes ofruesve, por vendosëm që të modifikonim regjistrat e tekstit dhe të shkruanim ID-në e gjurmës në to si identifikues, duke shtuar emrin e shërbimit, në mënyrë që këto regjistra të mund të analizoheshin më vonë.
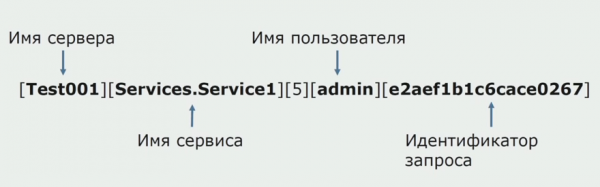
Me Filebeat ne jemi në gjendje të mbledhim regjistrat tanë nga serverat, pastaj transformojini ato, përdorni Kibana-n për të ndërtuar pyetje në UI dhe shikoni se si është drejtuar thirrja midis shërbimeve. ID-të e gjurmimit janë shumë të dobishme për këtë.
Testimi dhe korrigjimi i shërbimeve të lidhura
Fillimisht, ne nuk e kuptuam plotësisht se si të korrigjojmë shërbimet që po zhvillohen. Gjithçka ishte e thjeshtë me monolit; ne e drejtuam atë në një makinë lokale. Në fillim ata u përpoqën të bënin të njëjtën gjë me mikroshërbimet, por ndonjëherë për të nisur plotësisht një mikroshërbim duhet të lëshoni disa të tjerë, dhe kjo është e papërshtatshme. Kuptuam se duhet të kalojmë në një model ku lëmë në makinën lokale vetëm shërbimin ose shërbimet që duam të korrigjojmë. Shërbimet e mbetura përdoren nga serverët që përputhen me konfigurimin me prod. Pas korrigjimit, gjatë testimit, për çdo detyrë, vetëm shërbimet e ndryshuara lëshohen në serverin e testimit. Kështu, zgjidhja testohet në formën në të cilën do të shfaqet në prodhim në të ardhmen.
Ka serverë që ekzekutojnë vetëm versionet e prodhimit të shërbimeve. Këta serverë nevojiten në rast incidentesh, për të kontrolluar dorëzimin përpara vendosjes dhe për trajnime të brendshme.
Ne kemi shtuar një proces testimi të automatizuar duke përdorur bibliotekën e njohur Specflow. Testet ekzekutohen automatikisht duke përdorur NUnit menjëherë pas vendosjes nga Ansible. Nëse mbulimi i detyrës është plotësisht automatik, atëherë nuk ka nevojë për testim manual. Edhe pse ndonjëherë kërkohet ende testim manual shtesë. Ne përdorim etiketat në Jira për të përcaktuar se cilat teste duhet të ekzekutohen për një problem specifik.
Për më tepër, nevoja për testim të ngarkesës është rritur; më parë ajo kryhej vetëm në raste të rralla. Ne përdorim JMeter për të ekzekutuar teste, InfluxDB për t'i ruajtur ato dhe Grafana për të ndërtuar grafikët e procesit.
Çfarë kemi arritur?
Së pari, ne hoqëm qafe konceptin e "lëshimit". Kanë ikur publikimet monstruoze dymujore kur ky kolos u vendos në një mjedis prodhimi, duke ndërprerë përkohësisht proceset e biznesit. Tani ne vendosim shërbime mesatarisht çdo 1,5 ditë, duke i grupuar sepse ato hyjnë në funksion pas miratimit.
Nuk ka dështime fatale në sistemin tonë. Nëse lëshojmë një mikroshërbim me një gabim, atëherë funksionaliteti i lidhur me të do të prishet dhe të gjitha funksionet e tjera nuk do të preken. Kjo përmirëson shumë përvojën e përdoruesit.
Ne mund të kontrollojmë modelin e vendosjes. Ju mund të zgjidhni grupe shërbimesh veçmas nga pjesa tjetër e zgjidhjes, nëse është e nevojshme.
Përveç kësaj, ne kemi reduktuar ndjeshëm problemin me një radhë të madhe përmirësimesh. Tani kemi ekipe të veçanta produktesh që punojnë me disa nga shërbimet në mënyrë të pavarur. Procesi Scrum tashmë është një përshtatje e mirë këtu. Një ekip i caktuar mund të ketë një Pronar produkti të veçantë që i cakton detyra.
Përmbledhje
- Mikroshërbimet janë të përshtatshme për dekompozimin e sistemeve komplekse. Në këtë proces, ne fillojmë të kuptojmë se çfarë është në sistemin tonë, çfarë kontekstesh të kufizuara ekzistojnë, ku qëndrojnë kufijtë e tyre. Kjo ju lejon të shpërndani saktë përmirësimet midis moduleve dhe të parandaloni konfuzionin e kodit.
- Mikroshërbimet ofrojnë përfitime organizative. Shpesh flitet për to vetëm si arkitekturë, por çdo arkitekturë nevojitet për të zgjidhur nevojat e biznesit dhe jo më vete. Prandaj, mund të themi se mikroshërbimet janë të përshtatshme për zgjidhjen e problemeve në ekipe të vogla, duke pasur parasysh që Scrum është shumë popullor tani.
- Ndarja është një proces përsëritës. Ju nuk mund të merrni një aplikacion dhe thjesht ta ndani atë në mikroshërbime. Produkti që rezulton nuk ka gjasa të jetë funksional. Kur kushtojmë mikroshërbime, është e dobishme të rishkruhet trashëgimia ekzistuese, domethënë ta kthejmë atë në kod që na pëlqen dhe që plotëson më mirë nevojat e biznesit për sa i përket funksionalitetit dhe shpejtësisë.
Një paralajmërim i vogël: Kostot e kalimit në mikroshërbime janë mjaft të konsiderueshme. U desh shumë kohë për të zgjidhur vetëm problemin e infrastrukturës. Pra, nëse keni një aplikacion të vogël që nuk kërkon shkallëzim specifik, përveç nëse keni një numër të madh klientësh që konkurrojnë për vëmendjen dhe kohën e ekipit tuaj, atëherë mikroshërbimet mund të mos jenë ato që ju nevojiten sot. Është mjaft e shtrenjtë. Nëse e filloni procesin me mikroshërbime, atëherë kostot fillimisht do të jenë më të larta sesa nëse filloni të njëjtin projekt me zhvillimin e një monoliti.
P.S. Një histori më emocionale (dhe sikur për ju personalisht) - sipas .
Ja versioni i plotë i raportit.
Burimi: www.habr.com
