

Kohët e fundit ju thashë se si, duke përdorur receta standarde nga baza e të dhënave PostgreSQL. Sot do të flasim se si regjistrimi mund të bëhet në mënyrë më efikase në bazën e të dhënave pa përdorur asnjë "përdredhje" në konfigurim - thjesht duke organizuar saktë rrjedhat e të dhënave.

#1. Seksionimi
Një artikull se si dhe pse ia vlen të organizohet ka qenë tashmë, këtu do të flasim për praktikën e aplikimit të disa qasjeve brenda tonë .
"Gjërat e ditëve të shkuara..."
Fillimisht, si çdo MVP, projekti ynë filloi nën një ngarkesë mjaft të lehtë - monitorimi u krye vetëm për dhjetë serverët më kritikë, të gjitha tabelat ishin relativisht kompakte... Por me kalimin e kohës, numri i hosteve të monitoruar bëhej gjithnjë e më shumë. , dhe edhe një herë ne u përpoqëm të bënim diçka me një nga tavolina me madhësi 1.5 TB, kuptuam se megjithëse ishte e mundur të vazhdonim të jetonim kështu, ishte shumë e papërshtatshme.
Kohët ishin pothuajse si kohët epike, versione të ndryshme të PostgreSQL 9.x ishin të rëndësishme, kështu që të gjitha ndarjet duhej të bëheshin "me dorë" - përmes trashëgimia e tabelës dhe nxitësit rrugëzim me dinamik EXECUTE.
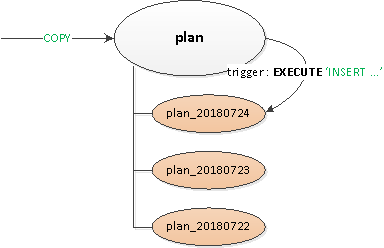
Zgjidhja që rezulton doli të ishte mjaft universale saqë mund të përkthehej në të gjitha tabelat:
- U deklarua një tabelë e zbrazët e prindërve "header", e cila përshkruante të gjitha indekset dhe nxitësit e nevojshëm.
- Regjistrimi nga këndvështrimi i klientit është bërë në tabelën "rrënjë" dhe duke përdorur brenda shkasja e rrugëzimit
BEFORE INSERTrekordi u fut "fizikisht" në seksionin e kërkuar. Nëse nuk kishte ende një gjë të tillë, ne kapëm një përjashtim dhe... - … duke përdorur është krijuar bazuar në shabllonin e tabelës mëmë seksion me një kufizim në datën e dëshiruarnë mënyrë që kur merren të dhënat, leximi kryhet vetëm në të.
PG10: përpjekja e parë
Por ndarja përmes trashëgimisë historikisht nuk ka qenë e përshtatshme për t'u marrë me një rrjedhë aktive të shkrimit ose një numër të madh ndarjesh fëmijësh. Për shembull, mund të kujtoni se algoritmi për zgjedhjen e seksionit të kërkuar kishte kompleksiteti kuadratik, që funksionon me 100+ seksione, e kuptoni vetë se si...
Në PG10 kjo situatë u optimizua shumë duke zbatuar mbështetje . Prandaj, ne u përpoqëm menjëherë ta aplikonim menjëherë pas migrimit të ruajtjes, por...
Siç doli pas gërmimit nëpër manual, tabela e ndarë në mënyrë origjinale në këtë version është:
- nuk mbështet përshkrimet e indeksit
- nuk mbështet nxitësit në të
- nuk mund të jetë "pasardhës" i askujt
- nuk mbështesin
INSERT ... ON CONFLICT - nuk mund të gjenerojë një seksion automatikisht
Pasi morëm një goditje të dhimbshme në ballë me një grabujë, kuptuam se do të ishte e pamundur të bëhej pa modifikuar aplikacionin dhe shtynim kërkimet e mëtejshme për gjashtë muaj.
PG10: shansi i dytë
Pra, filluam të zgjidhim problemet që lindën një nga një:
- Sepse shkakton dhe
ON CONFLICTNe zbuluam se na duheshin ende aty-këtu, kështu që bëmë një fazë të ndërmjetme për t'i zgjidhur ato tabelë proxy. - U largova nga "rutimi" në shkas - domethënë nga
EXECUTE. - E nxorën veçmas tabelë shabllon me të gjithë indeksetnë mënyrë që ata të mos jenë të pranishëm as në tabelën proxy.
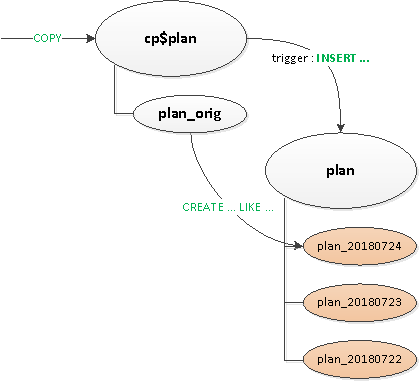
Më në fund, pas gjithë kësaj, ne ndamë tabelën kryesore në mënyrë origjinale. Krijimi i një seksioni të ri i është lënë ende ndërgjegjes së aplikacionit.
Fjalorët “Shërrim”.
Si në çdo sistem analitik, kemi pasur edhe ne "fakte" dhe "prerje" (fjalor). Në rastin tonë, në këtë cilësi ata vepruan, p.sh. pyetje të ngjashme të ngadalta ose vetë teksti i pyetjes.
"Faktet" u ndanë çdo ditë për një kohë të gjatë tashmë, kështu që ne fshimë me qetësi seksionet e vjetruara dhe ato nuk na shqetësonin (logët!). Por kishte një problem me fjalorët...
Për të mos thënë se kishte shumë, por përafërsisht 100 TB "fakte" rezultuan në një fjalor 2.5 TB. Nuk mund të fshish asgjë nga një tabelë e tillë, nuk mund ta ngjeshësh në kohën e duhur dhe shkrimi në të gradualisht u bë më i ngadalshëm.
Si një fjalor... në të, çdo hyrje duhet të paraqitet saktësisht një herë... dhe kjo është e saktë, por!.. Askush nuk na pengon të kemi një fjalor të veçantë për çdo ditë! Po, kjo sjell një tepricë të caktuar, por lejon:
- shkruaj/lexo më shpejt për shkak të madhësisë më të vogël të seksionit
- konsumoni më pak memorie duke punuar me indekse më kompakte
- ruaj më pak të dhëna për shkak të aftësisë për të hequr shpejt të vjetruarat
Si rezultat i të gjithë kompleksit të masave Ngarkesa e CPU-së u ul me ~30%, ngarkesa e diskut me ~50%:
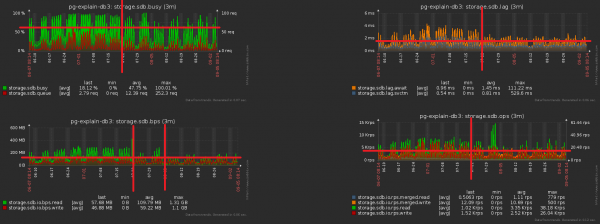
Në të njëjtën kohë, ne vazhduam të shkruanim saktësisht të njëjtën gjë në bazën e të dhënave, vetëm me më pak ngarkesë.
#2. Evolucioni dhe rifaktorimi i bazës së të dhënave
Kështu u vendosëm me atë që kemi çdo ditë ka seksionin e vet me të dhëna. Në fakt, CHECK (dt = '2018-10-12'::date) — dhe ekziston një çelës ndarjeje dhe kushti që një rekord të bjerë në një seksion specifik.
Meqenëse të gjitha raportet në shërbimin tonë janë ndërtuar në kontekstin e një date specifike, indekset për to që nga "kohët e pandara" kanë qenë të gjitha llojet (Serveri, Data, Modeli i planit), (Serveri, Data, nyja e planit), (Data, Klasa e gabimit, Serveri), ...
Por tani ata jetojnë në çdo seksion kopjet tuaja çdo indeks i tillë... Dhe brenda çdo seksioni data është konstante... Rezulton se tani jemi në çdo indeks të tillë thjesht futni një konstante si një nga fushat, që rrit si volumin e tij ashtu edhe kohën e kërkimit për të, por nuk sjell asnjë rezultat. E lanë grabujën për vete, oops...

Drejtimi i optimizimit është i qartë - i thjeshtë hiqni fushën e datës nga të gjitha indekset në tavolina të ndara. Duke pasur parasysh vëllimet tona, fitimi është rreth 1 TB/javë!
Tani le të theksojmë se ky terabyte ende duhej të regjistrohej disi. Domethënë edhe ne disku tani duhet të ngarkojë më pak! Kjo foto tregon qartë efektin e marrë nga pastrimi, të cilit i kushtuam një javë:
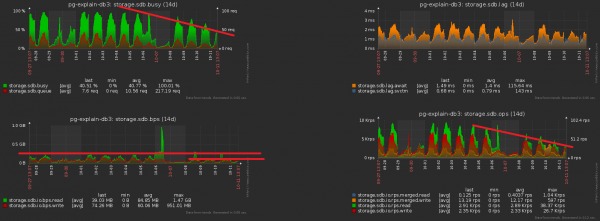
#3. "Përhapja" e ngarkesës së pikut
Një nga problemet më të mëdha të sistemeve të ngarkuara është sinkronizimi i tepërt disa operacione që nuk e kërkojnë atë. Ndonjëherë "sepse ata nuk e vunë re", ndonjëherë "ishte më e lehtë ashtu", por herët a vonë duhet ta heqësh qafe atë.
Le të zmadhojmë foton e mëparshme dhe të shohim që kemi një disk "pompa" nën ngarkesë me amplitudë të dyfishtë midis mostrave ngjitur, gjë që qartë "statistikisht" nuk duhet të ndodhë me një numër të tillë operacionesh:
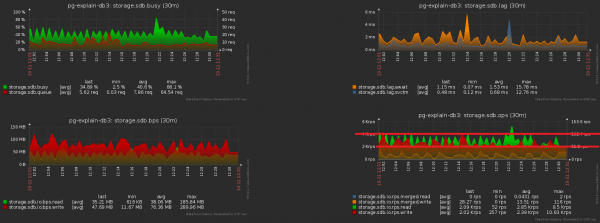
Kjo është mjaft e lehtë për t'u arritur. Tashmë kemi filluar monitorimin gati 1000 serverë, secila përpunohet nga një fije logjike e veçantë, dhe çdo thread rivendos informacionin e grumbulluar që do të dërgohet në bazën e të dhënave në një frekuencë të caktuar, diçka si kjo:
setInterval(sendToDB, interval)Problemi këtu qëndron pikërisht në faktin se të gjitha fijet fillojnë afërsisht në të njëjtën kohë, kështu që koha e dërgimit të tyre pothuajse gjithmonë përkojë "deri në pikën". Oops #2...
Për fat të mirë, kjo është mjaft e lehtë për t'u rregulluar, duke shtuar një përmbledhje "të rastësishme". sipas kohës:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Ne ruajmë atë që na nevojitet
Problemi i tretë tradicional i ngarkesës është nuk ka cache ku është ai mund të jetë.
Për shembull, ne bëmë të mundur analizimin në aspektin e nyjeve të planit (të gjitha këto Seq Scan on users), por menjëherë mendoni se ata janë, në pjesën më të madhe, të njëjta - harruan.
Jo, sigurisht, asgjë nuk është shkruar përsëri në bazën e të dhënave, kjo ndërpret këmbëzën me INSERT ... ON CONFLICT DO NOTHING. Por këto të dhëna ende arrijnë në bazën e të dhënave dhe janë të panevojshme lexim për të kontrolluar për konflikt duhet të bëjnë. Oops #3...
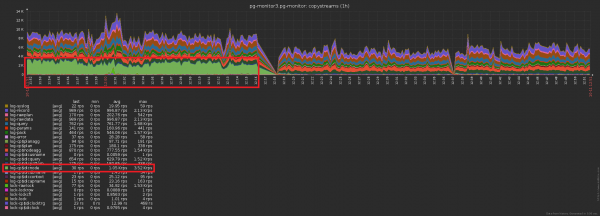
Dallimi në numrin e regjistrimeve të dërguara në bazën e të dhënave para/pas aktivizimit të cachimit është i dukshëm:
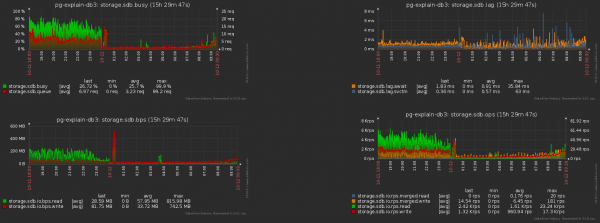
Dhe kjo është rënia shoqëruese e ngarkesës së ruajtjes:
Në total
"Terabyte-në-ditë" thjesht tingëllon e frikshme. Nëse bëni gjithçka siç duhet, atëherë kjo është vetëm 2^40 bajt / 86400 sekonda = ~ 12.5 MB/sqë mbanin edhe vidhat IDE të desktopit. 🙂
Por seriozisht, edhe me një "anje" dhjetëfish të ngarkesës gjatë ditës, mund të përmbushni lehtësisht aftësitë e SSD-ve moderne.

Burimi: www.habr.com
