

Përshëndetje të gjithëve! Unë jam zhvillues backend, krijoj mikrosherbime në Java + Spring. Punoj në një nga ekipet e zhvillimit të produkteve të brendshme në kompaninë Tinkoff.

Në ekipin tonë shpesh lind pyetja e optimizimit të kërkesave në baza të dhënash. Gjithmonë dëshirojmë që gjithçka të jetë pak më e shpejtë, por nuk është gjithmonë e mundur të arrijmë rezultate të mira vetëm me indekse të menduara mirë — duhet të kërkojmë rrugë alternative. Gjatë një nga këtyre kërkimeve të mia për optimizime të arsyeshme gjatë punës me bazat e dhënash, e gjeta , autor i librit SQL Performance Explained. Ky është ai lloj i rrallë i blogeve, ku mund të lexoni të gjitha artikujt pa ndërprerje.
Dua të përkthej për ju një artikull të vogël nga Markus. Mund ta quajmë këtë një manifesto në njëfarë mënyre, e cila synon tërheqë vëmendjen për një problem të vjetër, por që vazhdon të jetë aktual në lidhje me performancën e operacionit offset sipas standardit SQL.
Në disa vende do të shtoj shpjegime dhe vërejtje nga autori. Të gjitha këto vende do të shënohen si “pr.” për një qartësi më të madhe.
Një hyrje e vogël
Mendoj se shumë njerëz e dinë se sa problematike dhe ngadalësuese është puna me selektorët faqorë përmes ofsetit. Por a e dini se mund të zëvendësohet mjaft thjesht me një ndërtim më të fuqishëm?
Pra, fjala kyç ofset tregon se baza duhet të anashkalohet të dhënat e para n në kërkesë. Megjithatë, baza ende duhet të lexojë këto të dhëna të para n nga disku, në rendin e caktuar (shënim: të aplikohet renditja nëse është caktuar), dhe vetëm pas kësaj do të jetë e mundur të kthehen të dhënat duke filluar nga n+1 dhe më pas. E veçanta është se problemi nuk është në zbatimin specifik në DBMS, por në përkufizimin fillestar sipas standardit:
…rreshtat së pari renditen sipas <klauzolës order by> dhe pastaj kufizohen duke hequr numrin e rreshtave të especificuar në <klauzolën result offset> nga fillimi…
-SQL:2016, Pjesa 2, 4.15.3 Të dhëna të nxjerra (shënim: aktualisht standardi më i përdorur)
Pika kryesore këtu është se ofset merr një parametër të vetëm - numri i të dhënave që duhet anashkaluar, dhe kjo është. Duke ndjekur një përkufizim të tillë, DBMS mund vetëm të nxjerrë të gjitha të dhënat dhe pastaj të heqë ato të panevojshme. Është shqetësuese se një përkufizim i tillë i ofsetit e detyron sistemin të kryejë punë të tepërta. Dhe kjo nuk ka rëndësi nëse është SQL apo NoSQL.
Pak pak dhimbje
Problemet me offset nuk përfundojnë këtu, dhe ja përse. Nëse mes leximit të dy faqeve të të dhënave nga disku, një operacion tjetër shton një regjistrim të ri, çfarë do të ndodhë në këtë rast?
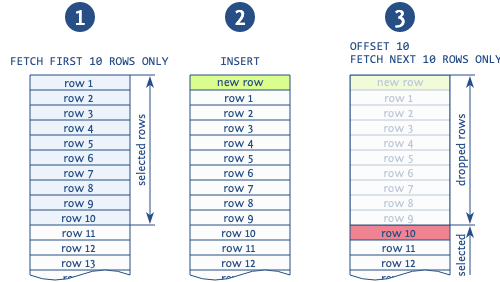
Kur përdoret offset për të anashkaluar regjistrimet nga faqet e mëparshme, në situatën e shtimit të një regjistrimi të ri mes operacioneve të leximit të faqeve të ndryshme, shumë probabilisht do të merrni kopje të dyfishta (shënim: kjo është e mundur kur lexojmë në mënyrë të faqeve duke përdorur konstrukcionin order by, atëherë një regjistrim i ri mund të futet në mes të rezultatit tonë).
Ilustrimi tregon qartë një situatë të tillë. Baza lexon 10 regjistrimet e para, pas së cilës shtohet një regjistrim i ri që zhvendos të gjitha regjistrimet e lexuara për 1. Më pas, baza merr një faqe të re nga 10 regjistrimet e ardhshme dhe fillon jo nga e 11-ta, siç duhet, por nga e 10-ta, duke kopjuar këtë regjistrim. Ka edhe anomali të tjera që lidhen me përdorimin e këtij shprehjeje, por kjo është më e zakonshmja.
Siç e kemi kuptuar, kjo nuk është një problem i një DBMS ose i realizimeve të tij. Problemi qëndron në përcaktimin e pagesës sipas standardit SQL. Ne i komunikojmë DBMS-së se cila faqe duhet të merret ose sa shumë regjistra të injorohet. Baza e të dhënave thjesht nuk është në gjendje të optimizojë këtë kërkesë, pasi ka shumë pak informacion.
Është e rëndësishme të sqarojmë se kjo nuk është një problem i një fjalëkyçi specifik, por më shumë i semantikës së kërkesës. Ka disa sintaksa identike në problematikë:
- Fjalëkyçi offset, siç u përmend më parë.
- Konstruksioni i dy fjalëkyçeve limit [offset] (megjithëse vetë limit nuk është aq keq).
- Filtrimi sipas kufijve të poshtëm, i ndërtuar mbi numërimin e rreshtave (p.sh., row_number(), rownum etj.).
Të gjithë këta shprehje thjesht tregojnë sa rreshta duhet të injorohen, pa asnjë informacion ose kontekst shtesë.
Më tej në këtë artikull, fjalëkyçi offset përdoret si një përmbledhje e të gjitha këtyre varianteve.
Jeta pa OFFSET
Tani imagjinoni se si do të ishte bota jonë pa të gjitha këto probleme. Duket se jeta pa offset nuk është aq e komplikuar: me një selektim mund të zgjedhim vetëm ato rreshta që nuk kemi parë ende (shënim: pra, ato që nuk ishin në faqen e kaluar), duke përdorur një kusht në where.
Në këtë rast, ne themelohemi në faktin se selekset ekzekutohen mbi një shumëzim të renditur (ajo e vjetër e njohur order by). Të qenit me një shumës të tillë, ne mund të përdorim një filtrë të thjeshtë për të nxjerrë vetëm ato të dhëna që ndodhen pas regjistrimit të fundit të faqes paraprake:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYKjo është e gjithë parimi i këtij qasje. Sigurisht, kur renditja bëhet sipas shumë kolonash, gjithçka bëhet edhe më argëtuese, por ideja mbetet e njëjtë. Është e rëndësishme të vërehet se kjo konstruksion është e zbatueshme në shumë -zgjidhje.
Ky mënyrë quhet metoda seek ose paginimi me çelës. Ajo zgjidh problemin me rezultatet e lëvizshme (shënim: situata me regjistrimin mes leximeve të faqeve, e përshkruar më parë) dhe, sigurisht, ajo që na pëlqen të gjithëve, punon më shpejt dhe më stabil se offset klasik. Stabiliteti qëndron në faktin se koha e përpunimit të kërkesës nuk rritet proporcionalisht me numrin e tabelës së kërkuar (shënim: nëse dëshiron të mësosh më shumë rreth funksionimit të qasjeve të ndryshme për paginimin, mundesh . Gjithashtu atje mund të gjeni benchmarke krahasuese për metode të ndryshme).
Një nga slidet , paginimi me çelësa, sigurisht, nuk është gjithfuqishëm — ai ka kufizimet e tij. Më e rëndësishmja — nuk ka mundësi të lexosh faqe rastësore (shënim: jo njëpasnjëshëm). Megjithatë, në epokën e skrollimit të pafund (shënim: në frontend), kjo nuk është ndonjë problem i madh. Caktimi i numrit të faqes për të klikuar — në çdo rast është një zgjidhje e keqe gjatë zhvillimit të UI (shënim: mendimi i autorit të artikullit).
Por çfarë ndodh me mjetet?
Paginimi me çelë shpesh nuk është i përshtatshëm për shkak të mungesës së mbështetjes instrumentale për këtë metodë. Shumica e mjeteve të zhvillimit, përfshirë kuadrot e ndryshme, nuk ofrojnë mundësinë se si do të kryhet pikërisht paginimi.
Situata përkeqësohet nga fakti se metoda e përshkruar kërkon mbështetje të plotë në teknologjitë e përdorura — duke filluar nga DBMS dhe duke përfunduar me ekzekutimin e kërkesave AJAX në shfletues gjatë skrollimit të pafund. Në vend që të tregohet vetëm numri i faqes, tani do të duhet të specifikohen një grup çelësh për të gjitha faqet njëherësh.
Megjithatë, numri i kuadrove që mbështesin paginimin me çelë po rritet ngadalë. Ja çfarë ka deri më tani:
- për Java;
- për Ruby;
- dhe për Django;
- për Python;
- — API kriteresh për realizimet e JPA;
- për Perl;
- , мапер для Node.js .
(Shënim: disa lidhje u hoqën për shkak se, në momentin e përkthimit, disa biblioteka nuk ishin përditësuar që nga vitet 2017-2018. Nëse jeni të interesuar, mund të shikoni burimin origjinal.)
Pikërisht në këtë moment na duhet ndihma juaj. Nëse ju jeni duke zhvilluar ose mbajtur një kornizë që ndonjëherë përdor paginimin, ju lutem, unë ju ftoj, unë ju lutem të bëni mbështetje natyrore për paginimin mbi çelësa. Nëse keni pyetje ose ju nevojitet ndihmë, do të përgëzohem të ndihmoj (, , ) (shënim: nga përvoja ime e komunikimit me Markus, mund të them se ai me të vërtetë i qaset me entuziazëm për të përhapur këtë temë).
Nëse ju përdorni zgjidhje të gatshme, që mendoj se meritojnë mbështetje për paginimin mbi çelësa, krijoni një kërkesë ose madje ofroni një zgjidhje të gatshme, nëse është e mundur. Mund të tregoni gjithashtu një lidhje me këtë artikull.
Përfundimi
Arsyeja pse një qasje kaq e thjeshtë dhe e dobishme, si paginimi mbi çelësa, është pak e përhapur, nuk është se është e komplikuar në implementimin teknik ose kërkon ndonjë përpjekje të madhe. Arsyeja kryesore është se shumica janë ambientuar të shohin dhe të punojnë me offset — një qasje e tillë është e diktuar nga vetë standardi.
Si pasojë, pak njerëz po mendojnë për të ndryshuar qasjen ndaj paginimit, dhe për këtë arsye mbështetje instrumentale nga kornizat dhe bibliotekat po zhvillohet ngadalë. Prandaj, nëse ideja dhe qëllimi i paginimit pa offset ju janë afër, — ndihmoni për ta përhapur!
Burimi:
Autori: Markus Winand
Burimi: habr.com
