


Efekti i fryrjes së tabelave dhe indekseve (bloat) është i njohur gjerësisht dhe nuk ndodh vetëm në Postgres. Ekzistojnë mënyra për ta luftuar atë “nga fabrika” siç janë VACUUM FULL ose CLUSTER, por ato bllokojnë tabelat gjatë punës dhe prandaj nuk mund të përdoren gjithmonë.
Në këtë artikull do të ketë pak teori mbi atë se si ndodh bloat, si mund të luftohet, mbi kufizimet e vonuara dhe mbi problemet që ato sjellin në përdorimin e zgjerimit pg_repack.
Ky artikull është shkruar mbi bazën e në PgConf.Russia 2020.
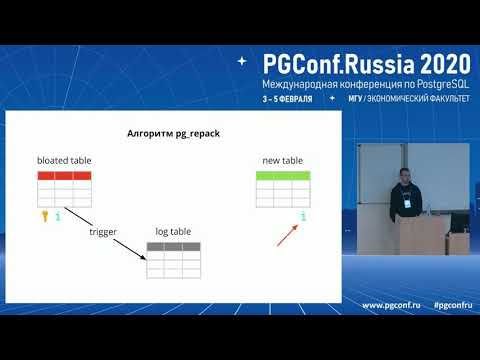
Pse ndodh bloat
Postgres bazohet në një model me shumë versione (). Thelbi i tij është se çdo rresht në tabelë mund të ketë disa versionet, ndërsa transaksionet shohin jo më shumë se një nga këto versione, por nuk është e nevojshme që të jetë e njëjta. Kjo lejon disa transaksione të punojnë njëkohësisht dhe të mos ndikojnë pothuajse fare në njëra-tjetrën.
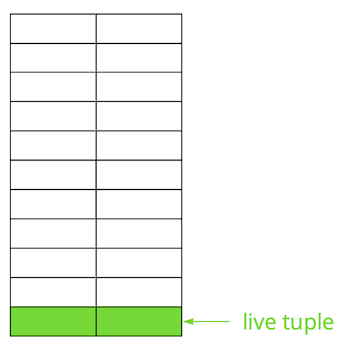
Është e qartë se të gjitha këto versione duhet të ruhen. Postgres punon me kujtesën në mënyrë faqesh dhe faqeja është minimumi i të dhënave që mund të lexohet nga disku ose të shkruhet. Le të shqyrtojmë një shembull të vogël për të kuptuar se si ndodh kjo.
Supozoni se kemi një tabelë, në të cilën kemi shtuar disa të dhëna. Në faqen e parë të skedarit, ku ruhen tabelat, janë shfaqur të dhëna të reja. Këto janë versione të drejtpërdrejta të rreshtave, të cilat janë në dispozicion për transaksione të tjera pas komitimit (për thjeshtësi, le të supozojmë se niveli i izolimit është Read Committed).
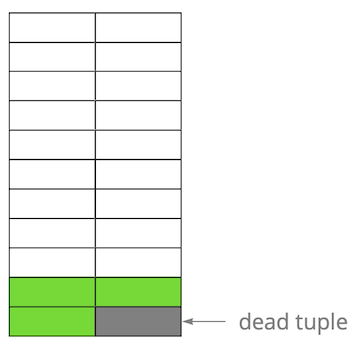
Më pas, ne përditësuam një nga regjistrimet dhe kështu e shënuam versionin e vjetër si të pavlefshëm.
Hap pas hapi, duke përditësuar dhe fshirë versionet e rreshtave, ne fituam një faqe në të cilën rreth gjysma e të dhënave janë “mbetje”. Këto të dhëna nuk shihen nga asnjë transaksion.
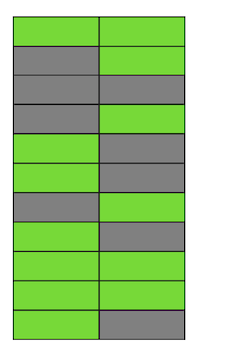
Në Postgres ekziston një mekanizëm , i cili pastron versionet e pavlefshme dhe liçon hapësirë për të dhëna të reja. Por nëse ai nuk është konfiguruar mjaft agresivisht ose është i zënë duke punuar me tabela të tjera, atëherë “të dhënat mbetje” mbeten, dhe na duhet të përdorim faqe të tjera për të dhëna të reja.
Në shembullin tonë, në një moment të caktuar, tabela do të përbëhet nga katër fqinj, por të dhënat aktive në të do të kenë vetëm gjysmën. Si rezultat, kur kërkojmë në tabelë, ne do të lexojmë shumë më tepër të dhëna se sa është e nevojshme.
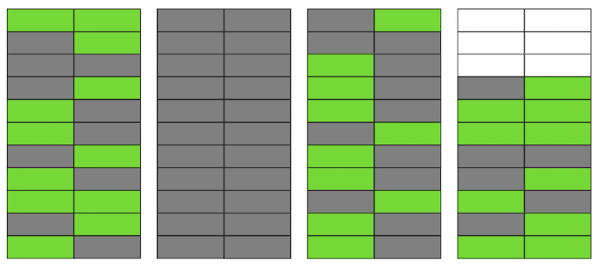
Edhe nëse VACUUM heq të gjitha versionet e panevojshme të rreshtave tani, situata nuk do të përmirësohet ndjeshëm. Do të kemi hapësirë të lirë në faqe ose madje faqe të tëra për rreshta të rinj, por ne ende do të lexojmë më shumë të dhëna sesa duhet.
Për më tepër, nëse një faqe krejtësisht e zbrazët (e dyta në shembullin tonë) do të ishte në fund të skedarit, atëherë VACUUM do ta kishte prerë atë. Por tani ajo ndodhet në mes, kështu që nuk mund të bëjmë asgjë me të.
Kur numri i këtyre faqeve të zbrazëta ose shumë të shëmtuar bëhet i madh, çka quhet bloat, kjo fillon të ndikojë në performancën.
E gjithë ajo që u përshkrua më lart është mekanika e shfaqjes së bloat në tabela. Në inde ndodh më ose më pak në të njëjtën mënyrë.
A kam unë bloat?
Ka disa mënyra për të përcaktuar nëse keni bloat. Ideja e parë është përdorimi i statistikave të brendshme të Postgres, të cilat përmbajnë informacion të përafërt mbi numrin e rreshtave në tabela, numrin e rreshtave "të gjallë" etj. Në internet mund të gjeni shumë variacione të skenarëve të gatshëm. Ne morëm si bazë nga PostgreSQL Ekspertët, të cilët mund të vlerësojnë bloat-in e tabelave së bashku me toast dhe bloat-in e indekseve btree. Sipas përvojës sonë, pasiguria e tij është rreth 10-20%.
Një tjetër mënyrë është të përdorësh zgjatjen , e cila lejon të shikohet brenda faqeve dhe të marrë një vlerësim si dhe një vlerë të saktë të bloat-it. Por në rastin e fundit, do të duhet të skanohet e gjithë tabela.
Një vlerë të vogël bloat, deri në 20%, e konsiderojmë të pranueshme. Ajo mund të merret si një analog i fillfactor për dhe . Me 50% e lartë mund të fillojnë problemet me performancën.
Mënyrat për të luftuar bloat-in
Në Postgres ka disa mënyra për të luftuar bloat-in "nga kutia", megjithatë ato nuk janë gjithmonë të përshtatshme për të gjithë.
Konfiguroni AUTOVACUUM-in që bloat-i të mos ndodhë. Dhe më saktësisht, që të mbetet në një nivel të pranueshëm për ju. Mund të duket si një këshillë “kapiteni”, por në realitet nuk është gjithmonë e lehtë të arrihet. Për shembull, nëse keni një zhvillim aktiv me ndryshime të rregullta në skemën e të dhënave ose ndodhin disa migrime të të dhënave. Si pasojë, profili juaj i ngarkesës mund të ndryshojë shpesh dhe, si rregull, ai është i ndryshëm për tabela të ndryshme. Kështu, ju nevojitet të punoni vazhdimisht pak përpara dhe të përshtatni AUTOVACUUM për profilin që ndryshon të secilës tabelë. Por është e qartë se nuk është e lehtë ta bëni këtë.
Një tjetër shkak i zakonshëm për përkatësinë e AUTOVACUUM për të përpunuar tabelat është pranija e transaksioneve të gjata, të cilat nuk i lejojnë atij të pastruar të dhënat sepse ato janë të aksesueshme për këto transaksione. Këtu rekomandimi është gjithashtu i qartë – të eliminohen transaksionet 'në pritje' dhe të minimizohet koha e transaksioneve aktive. Por nëse ngarkesa e aplikacionit tuaj është një hibrid OLAP dhe OLTP, mund të keni njëkohësisht shumë përditësime të shpeshta dhe kërkesa të shkurtra, si dhe operacione të gjata – për shembull, ndërtimi i ndonjë raporti. Në një situatë të tillë, ka kuptim të mendoni për shpërndarjen e ngarkesës në baza të ndryshme, gjë që do të lejojë optimizimin më të hollë të secilës prej tyre.
Një shembull tjetër – edhe nëse profili është homogjen, por DB është nën një ngarkesë shumë të lartë, atëherë edhe AUTOVACUUM më agresiv mund të mos përballojë, dhe bloat do të vazhdojë të shfaqet. Shkëmbimi (vertikal ose horizontal) është zgjidhja e vetme.
Si duhet të veproni në situatën kur AUTOVACUUM e keni konfiguruar, por bloat vazhdon të rritet.
Ekipa VACUUM FULL riorganizojnë përmbajtjen e tabelave dhe indekseve dhe lënë vetëm të dhënat e aktualizuara. Për eliminimin e bloat, ajo funksionon perfekt, por gjatë ekzekutimit të saj merret një bllokim ekskluziv në tabelë (AccessExclusiveLock), i cili nuk lejon të ekzekutohen kërkesat për këtë tabelë, përfshirë edhe select. Nëse mund të përballoni ndalimin e shërbimit tuaj ose një pjese të tij për një kohë (nga dhjetëra minuta deri në disa orë në varësi të madhësisë së DB-së dhe harduerit tuaj), atëherë kjo është alternativa më e mirë. Ne, për fat të keq, nuk arrijmë ta ndjekim VACUUM FULL brenda kohës së planifikuar për mirëmbajtje, prandaj ky opsion nuk na përshtatet.
Ekipa CLUSTER gjithashtu riorganizojnë përmbajtjen e tabelave, siç bën VACUUM FULL, ndërsa lejon të specifikoni një indeks, sipas të cilit të dhënat do të renditen fizikisht në disk (por në të ardhmen për rreshta të rinj rendi nuk është i garantuar). Në disa raste kjo është një optimizim i mirë për një sërë kërkesash – me leximin e disa regjistrave sipas indeksit. Disavantazhi i komandës është i njëjtë me atë të VACUUM FULL – ajo bllokon tabelën gjatë punës.
Ekipa REINDEX përngjan me dy të mëparshmet, por kryen rimodelimin e një indeksi të caktuar ose të gjitha indekseve të tabelës. Bllokimet janë pak më të dobëta: ShareLock mbi tabelë (pengon modifikimet, por lejon ekzekutimin e select) dhe AccessExclusiveLock mbi indeksin e rimodeluar (bllokon kërkesat që përdorin këtë indeks). Megjithatë, në versionin e 12-të të Postgres është shtuar parametri , i cili lejon rimodelimin e indeksit pa bllokuar shtimin, ndryshimin ose fshirjen e regjistrimeve në mënyrëparalele.
Në versionet e mëparshme të Postgres, mund të arrihet një rezultat që është i ngjashëm me REINDEX CONCURRENTLY, përmes . Ai lejon krijimin e një indeksi pa bllokim të rreptë (ShareUpdateExclusiveLock, i cili nuk pengon kërkesat paralele), pastaj të zëvendësohet indeksi i vjetër me të riun dhe të fshihet indeksi i vjetër. Kjo lejon elimimin e bloat-it të indekseve, pa penguar funksionimin e aplikacionit tuaj. Është e rëndësishme të mbani parasysh se gjatë rimodelimit të indekseve do të ketë një ngarkesë shtesë në sistemin e diskut.
Kështu, nëse për indekset egzistojnë mënyra për të eliminuar bloat “në ngrohje”, për tabelat këto nuk ekzistojnë. Këtu hyjnë në lojë zgjerime të ndryshme të jashtme: (më parë pg_reorg), , dhe të tjera. Në këtë artikull nuk do t'i krahasoj dhe do flas vetëm për pg_repack, të cilin, pas disa përshtatjeve, e përdorim tek ne.
Si funksionon pg_repack

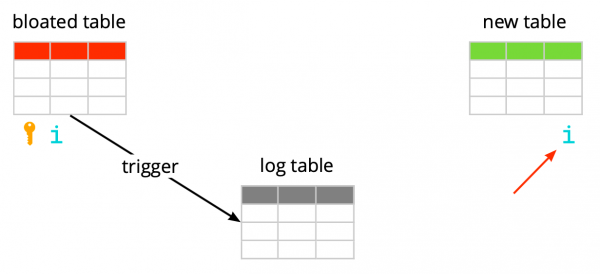
Supozoni se kemi një tabelë të zakonshme – me indekse, kufizime dhe, fatkeqësisht, me bloat. Hapi i parë pg_repack krijon një tabelë regjistrimi për të ruajtur të dhënat mbi të gjitha ndryshimet gjatë punës. Një trigger do të përgjojë këto ndryshime për çdo insert, update dhe delete. Pastaj krijohet një tabelë, e ngjashme me origjinalen në strukturë, por pa indekse dhe kufizime, për të mos ngadalësuar procesin e futur të dhënash.
Më pas pg_repack transferon të dhënat në tabelën e re nga e vjetra, duke filtruar automatikisht të gjitha rreshtat e pavlefshëm, dhe pastaj krijon indekse për tabelën e re. Gjatë gjithë këtyre operacioneve, në tabelën e regjistrimit akumulohet ndryshime.
Hapi i ardhshëm është të transferoni ndryshimet në tabelën e re. Transferimi kryhet në disa iteracione, dhe kur në tabelën e logut mbeten më pak se 20 regjistrime, pg_repack merr një bllokim të rreptë, transferon të dhënat e fundit dhe zëvendëson tabelën e vjetër me të reja në tabelat sistemike të Postgres. Ky është një moment i vetëm dhe shumë i shkurtër, kur nuk do të jeni në gjendje të punoni me tabelën. Pas kësaj, tabela e vjetër dhe tabela e logut fshihen, duke liruar hapësirë në sistemin e skedarëve. Procesi ka përfunduar.
Teoria duket mjaft mirë, çfarë ndodh në praktikë? E kemi testuar pg_repack pa ngarkesë dhe nën ngarkesë, kemi kontrolluar funksionimin e saj në rast të ndalimit të parakohshëm (thjesht me Ctrl+C). Të gjitha testet rezultuan pozitive.
Shkuam në prodhim — dhe këtu gjithçka shkoi ndryshe nga sa priteshim.
Blin i parë në prodhim
Në klasterin e parë morëm një gabim lidhur me shkeljen e kufizimit unik:
$ ./pg_repack -t tablename -o id
INFO: po ripaketon tabelën "tablename"
ERROR: kërkesa dështoi:
ERROR: vlera e çelësit të dyfishtë shkel kufizimin unik "index_16508"
DETAIL: Çelësi (id, index)=(100500, 42) ekziston tashmë.
Ky kyçim kishte emrin auto-gjeneruar index_16508 – e krijoi pg_repack. Nga atributet që e përbëjnë, ne identifikuam "kufizimin" tonë, që i përputhet. Problemi është se kjo nuk është një kufizim krejtësisht i zakonshëm, por i vonuar (), dmth verifikimi i tij ndodhi më vonë se komanda sql, gjë që çon në pasoja të papritura.
Kufizimet e vonuara: përse janë të nevojshme dhe si funksionojnë
Pak teori për kufizimet e vonuara.
Le të shqyrtojmë një shembull të thjeshtë: ne kemi një tabelë reference automjetesh me dy atribute – emrin dhe rendin e automjetit në referencë.
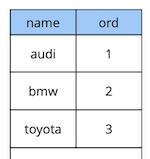
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Supozoni se na duhen të ndërronim automjetet e parë dhe të dytë vendet. Zgjidhja "në mënyrë të drejtpërdrejtë" – përditësoni vlerën e parë në të dytën, dhe të dytën në të parën:
begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Por gjatë ekzekutimit të këtij kodi, ne do të marrim një shkelje të pritshme të kufizimit, sepse rendi i vlerave në tabelë është unik:
[23305] ERROR: vlera e çelësit të dyfishtë shkel kufizimin unik “uk_cars”
Detaj: Çelësi (ord)=(2) ekziston tashmë.
Si të bëjmë ndryshe? Opsioni i parë: të shtojmë një zëvendësim shtesë për rendin, që me siguri nuk ekziston në tabelë, për shembull “-1”. Në programim, kjo njihet si “këmbimi i vlerave të dy variablave përmes një të tretë”. E vetmja mangësi e këtij metodi është përditësimi shtesë.
Opsioni i dytë: riprojektimi i tabelës për të përdorur një lloj të dhënash me pikë lëvizëse për rendin, në vend të numrave të plotë. Kështu, kur përditësohet një vlerë nga 1 në 2.5, regjistrimi i parë automatikisht “do të pozicionohet” mes të dytit dhe të tretit. Ky zgjidhje funksionon, por ka dy kufizime. Së pari, nuk do t'ju përshtatet nëse vlera përdoret diku në ndërfaqe. Së dyti, në varësi të saktësisë së llojit të dhënash, do të keni një numër të kufizuar mundësish për vendosje, deri në rifreskimin e vlerave të të gjithë regjistrave.
Opsioni i tretë: të bëjmë kufizimin të vonuar, në mënyrë që të kontrollohet vetëm në momentin e angazhimit:
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);Pasi logjika e kërkesës sonë fillestare garanton se deri në momentin e angazhimit të gjitha vlerat janë unike, ajo do të kryhet me sukses.
Shembulli i diskutuar më lart, sigurisht, është shumë sintetik, por shpreh idenë. Në aplikacionin tonë ne përdorim kufizime të vonuara për të zbatuar logjikën që menaxhon zgjidhjen e konflikteve kur përdoruesit punojnë njëkohësisht me objektet-widget në tablonë e përbashkët. Përdorimi i kufizimeve të tilla na lejon ta thjeshtojmë pak kodin e aplikacionit.
Në përgjithësi, në varësi të tipi të kufizimit në Postgres, ekzistojnë tre nivele granulariteti për verifikimin e tyre: niveli i rreshtit, transaksionit dhe shprehjes.
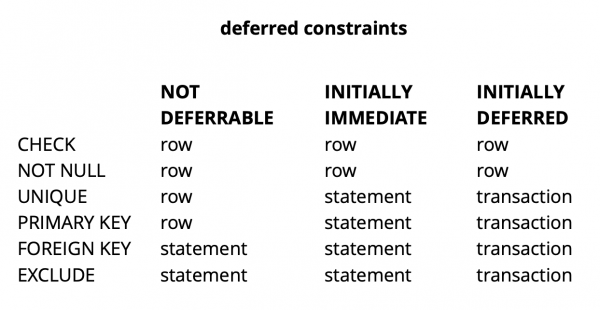
Burimi:
CHECK dhe NOT NULL gjithmonë kontrollohen në nivelin e rreshtit, për kufizimet e tjera, siç duket nga tabela, ka mundësi të ndryshme. Mund të lexoni më shumë për këtë .
Nëse përmbledhim shkurt, kufizimet e vonuara në disa situata ofrojnë një kod më të lexueshëm dhe më pak komandë. Megjithatë, për këtë paguajmë me një proces më të komplikuar debugimi, pasi momenti i shfaqjes së gabimit dhe momenti kur merrni informacion për të janë të ndara në kohë. Një problem tjetër i mundshëm lidhet me faktin se planifikuesi nuk është gjithmonë në gjendje të ndërrmarë një plan optimal nëse në kërkesë përfshihet një kufizim i vonuar.
Përmirësimi i pg_repack
Kemi kuptuar se çfarë janë kufizimet e vonuara, por si lidhen ato me problemin tonë? Le të rikujtojmë gabimin që ne morëm më parë:
$ ./pg_repack -t tablename -o id
INFO: po ripaketon tabelën "tablename"
ERROR: kërkesa dështoi:
ERROR: vlera e çelësit të dyfishtë shkel kufizimin unik "index_16508"
DETAIL: Çelësi (id, index)=(100500, 42) ekziston tashmë.Ai shfaqet në momentin e kopjimit të të dhënave nga tabela log në tabelën e re. Ky duket i çuditshëm, pasi të dhënat në tabelën log komitohen së bashku me të dhënat e tabelës origjinale. Nëse ato i përmbushin kufizimet e tabelës origjinale, si mund të shkelin të njëjtat kufizime në të re?
Siç duket, rrënja e problemit është në hapin paraprak të punës së pg_repack, në të cilin krijohen vetëm indekset, por jo kufizimet: në tabelën e vjetër kishte një kufizim unik, ndërsa në të re është krijuar një indeks unik në vend të tij.
Ë rëndësishme të theksohet se, nëse kufizimi është i zakonshëm dhe jo i vonuar, atëherë indeksi unik i krijuar në vend të tij është i barabartë me këtë kufizim, pasi kufizimet unike në Postgres zbatohen përmes krijimit të një indeksi unik. Por në rastin e një kufizimi të vonuar, sjellja nuk është e njëjtë, sepse indeksi nuk mund të jetë i vonuar dhe gjithmonë kontrollohet në momentin e ekzekutimit të komandës SQL.
Pra, thelbi i problemit qëndron në 'vonimin' e verifikimit: në tabelën fillestare ndodh në momentin e komitimit, ndërsa në të re njoftohet në momentin e ekzekutimit të komandës SQL. Kështu që ne duhet ta bëjmë që verifikimet të kryhen në mënyrë të njëjtë në të dy rastet: ose gjithmonë të vonuara, ose gjithmonë menjëherë.
Kështu, cilat ide kemi pasur.
Krijo një indeks, të ngjashëm me të vonuar.
Ideja e parë është të kryhen të dyja verifikimet në modin e menjëhershëm. Kjo mund të krijojë disa false positive përjashtime të kufizimit, por nëse ato janë të pakta, nuk duhet ta ndikojnë punën e përdoruesve, pasi për ta, këto konflikte janë një situatë normale. Ato ndodhin, për shembull, kur dy përdorues fillojnë së bashku të redaktojnë të njëjtin widget, dhe klienti i përdoruesit të dytë nuk arrin të marrë informacionin se widgeti është bllokuar për redaktim nga përdoruesi i parë. Në këtë situatë, serveri i përgjigjet përdoruesit të dytë me një refuzim, dhe klienti i tij anulon ndryshimet dhe bllokon widgetin. Pak më vonë, kur përdoruesi i parë përfundon redaktimin, përdoruesi i dytë do të marrë informacionin se widgeti nuk është më bllokuar dhe do të mund të përsërisë veprimin e tij.

Për të siguruar që verifikimet të jenë gjithmonë në mod të menjëhershëm, ne kemi krijuar një indeks të ri, të ngjashëm me kufizimin origjinal të vonuar:
CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
-- run pg_repack
DROP INDEX CONCURRENTLY uk_tablename__immediate;Në mjedisin e testit morëm vetëm disa gabime të pritura. Sukses! Kemi nisur përsëri pg_repack në prodhim dhe kemi marrë 5 gabime në klusterin e parë për një orë punë. Ky është një rezultat i pranueshëm. Megjithatë, në klusterin e dytë, numri i gabimeve u rrit ndjeshëm dhe na duhej të ndalonim pg_repack.
Pse ndodhi kështu? Shkaku i gabimeve varet nga numri i përdoruesve që punojnë njëkohësisht me të njëjtin widget. Duke parë, në atë moment, të dhënat që ruanin në klusterin e parë kishin shumë më pak ndryshime konkurruese se në të tjerët, dmth. thjesht na “ndodhi fat”.
Ideja nuk funksionoi. Në atë moment ne panë dy opsione të tjera: të rishkruanim kodin tonë aplikativ për të hequr dorë nga kufizimet e vonuara, ose të “mësonim” pg_repack të punonte me to. Zgjedhëm opsionin e dytë.
Të zëvendësojmë indeksat në tavolinën e re me kufizimet e vonuara nga tavolina origjinale.
Qëllimi i përmirësimit ishte i qartë – nëse tavolina origjinale ka një kufizim të vonuar, atëherë për të rejën duhet të krijohet një kufizim i tillë, e jo një indeks.
Për të verifikuar ndryshimet tona, ne shkruam një test të thjeshtë:
- tabela me kufizim të vonuar dhe një shënim;
- ndërhyjmë në cikël për të futur të dhëna që shkaktojnë konflikt me shënimin ekzistues;
- bëjmë update – të dhënat tashmë nuk shkaktojnë konflikt;
- komitojmë ndryshimet.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;Versioni origjinal i pg_repack gjithmonë binte në insertin e parë, versioni i përmirësuar funksionoi pa probleme. Shkëlqyer.
Shkëlqejnë për prodhim dhe përsëri marrim një gabim në të njëjtën fazë të kopjimit të të dhënave nga tabela e logut në të re:
$ ./pg_repack -t tablename -o id
INFO: po ripaketon tabelën "tablename"
ERROR: kërkesa dështoi:
ERROR: vlera e çelësit të dyfishtë shkel kufizimin unik "index_16508"
DETAIL: Çelësi (id, index)=(100500, 42) ekziston tashmë.Situata klasike: në ambientet e testimit gjithçka funksionon, ndërsa në prodhim – jo?!
APPLY_COUNT dhe kufiri i dy batch-eve
Kemi filluar të analizojmë kodin saktësisht rresht pas rreshti dhe zbuluam një moment të rëndësishëm: transferimi i të dhënave nga tabela e logut në të re ndodh me batçe, konstanta APPLY_COUNT tregon madhësinë e batch-it:
for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue; /* mund të ketë ende disa tuple, përsëritni. */
...
}Problemi është se të dhënat e transaksionit origjinal, ku disa operacione mund të shkelin potencialisht kufirin, gjatë transferimit mund të bien në kufirin e dy grupeve – gjysma e komandave do të komitohen në grupin e parë, ndërsa gjysma tjetër në të dytin. Dhe këtu si të vijë: nëse komandat në grupin e parë nuk shkelin asgjë, atëherë është në rregull, por nëse shkelin – ndodh një gabim.
APPLY_COUNT është 1000 të dhëna, që shpjegon pse testet tona kaluan me sukses – ata nuk mbulonin rastin “e kufirit të grupeve”. Ne përdorëm dy komanda – insert dhe update, kështu që gjithsej 500 transaksione me dy komanda gjithmonë ishin vendosur në grup dhe ne nuk kemi hasur probleme. Pas shtimit të update të dytë, përmirësimi ynë nuk funksionoi më:
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id; -- një përmirësim më tepër
COMMIT;
END;
END LOOP;Pra, detyra e ardhshme është të sigurohet që të dhënat nga tabela origjinale, të cilat u ndryshuan në një transaksion, të kalojnë në tabelën e re gjithashtu brenda një transaksioni.
Heqja dorë nga batching
Sërish kishim dy mundësi zgjidhjeje. E para: le të heqim dorë plotësisht nga ndarja në blloqe dhe të bëjmë transferimin e të dhënave me një transaksion. Në favor të kësaj zgjidhjeje fliste thjeshtësia – ndryshimet e kërkuara në kod janë minimale (përveç kësaj, në versionet më të vjetra, pg_reorg funksiononte pikërisht kështu). Por ka një problem — krijojmë një transaksion të gjatë, dhe kjo, siç u tha më parë, është një kërcënim për shfaqjen e bloat-it të ri.
Zgjidhja e dytë është më e komplikuar, por ndoshta më e saktë: të krijojmë një kolonë në tabelën e log-ut me identifikatorin e transaksionit që shtoi të dhënat në tabelë. Kështu, gjatë kopjimit të të dhënave, ne mund t'i grupojmë ato sipas këtij atributi dhe të garantojmë që ndryshimet e lidhura do të transferohen së bashku. Batch-i do të formohet nga disa transaksione (ose një të madhe) dhe madhësia e tij do të varihojë në varësi të sasisë së të dhënave që janë modifikuar në këto transaksione. Është e rëndësishme të theksohet se, për shkak se të dhënat e transaksioneve të ndryshme hynë në tabelën e log-ut në rend të rastit, nuk do të mund të lexohet më sekuencialisht, siç ishte më parë. seqscan për çdo kërkesë me filtrimin sipas tx_id është shumë e shtrenjtë, nevojitet një indeks, por ai do ta ngadalësojë gjithashtu metodën për shkak të kostove shtesë për përditësimin e tij. Në përgjithësi, si gjithmonë, është e nevojshme të sakrifikohet diçka.
Pra ndaj, ne vendosëm të fillojmë me opsionin e parë, si më të thjeshtë. Së pari, duhej të kuptonim nëse një transaksion i gjatë do të ishte një problem real. Duke qenë se transferimi kryesor i të dhënave nga tabela e vjetër në atë të re ndodh gjithashtu në një transaksion të gjatë, çështja u transformua në “sa shumë do ta zgjasim këtë transaksion?” Kohëzgjatja e transaksionit të parë varet kryesisht nga madhësia e tabelës. Kohëzgjatja e re varet nga sa shumë ndryshime do të grumbullohen në tabelë gjatë kohës së transferimit të të dhënave, pra nga intensiteti i ngarkesës. Prova e pg_repack u realizua gjatë ngarkesës minimale në shërbim, dhe volumi i ndryshimeve ishte shumë i vogël në krahasim me volumin fillestar të tabelës. Ne vendosëm se mund ta injorojmë kohën e transaksionit të ri (për krahasim mesatarisht është 1 orë dhe 2-3 minuta).
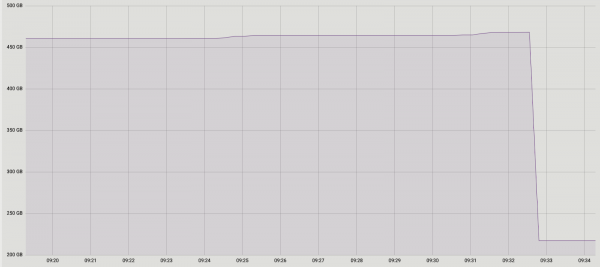
Eksperimentet ishin pozitive. Aktivizimi në prodhim gjithashtu. Për ilustër, një imazh me madhësinë e një nga bazat pas kryerjes:
Nëse ky zgjidhje na përshtatet plotësisht, nuk vendosëm ta provojmë një të dytë, por po shqyrtojmë mundësinë e diskutimit me zhvilluesit e zgjatimeve. Ndryshimi ynë aktual, fatkeqësisht, ende nuk është gati për botim, pasi zgjidhëm vetëm problemin me kufizimet e veçanta të vonuara, dhe për një patch të plotë nevojitet të bëhet mbështetje për lloje të tjera. Shpresojmë se do të mund ta realizojmë këtë në të ardhmen.
Ndoshta keni pyetur se përse u angazhuam në këtë histori me modifikimin e pg_repack në vend që të përdornim, për shembull, alternativa të tjera? Në një moment, ne gjithashtu mendojmë për këtë, por përvoja pozitive e përdorimit të tij më parë, në tabela pa kufizime të vonuara, na motivoi të provonim të kuptonim thelbin e problemit dhe ta zgjidhim atë. Për më tepër, përdorimi i zgjidhjeve të tjera gjithashtu kërkon kohë për të kryer teste, prandaj vendosëm që fillimisht të përpiqemi të zgjidhim problemin në të, dhe nëse e kuptojmë se nuk do të mund ta bëjmë këtë brenda një kohe të arsyeshme, atëherë do të fillojmë të shqyrtojmë alternativat.
Përfundimet
Çfarë mund të rekomandojmë mbi përvojën tonë personale:
- Monitoroni bloat-in tuaj. Në bazë të të dhënave të monitorimit, do të kuptoni sa mirë është konfigurimi i autovacuum.
- Konfiguroni AUTOVACUUM për të mbajtur bloat-in në nivele të pranueshme.
- Nëse bloat-i vazhdon të rritet dhe nuk mund ta luftoni me mjetet "nga kutia", mos u friksoni nga përdorimi i zgjerimeve të jashtme. E rëndësishme është të testoni gjithçka mirë.
- Mos u friksoni të përshtatni zgjidhjet e jashtme sipas nevojave tuaja — ndonjëherë kjo mund të jetë më efektive dhe madje më e thjeshtë se sa të ndryshoni kodin tuaj.
Burimi: habr.com
