

По роду деятельности приходится сталкиваться с ситуациями, когда разработчик пишет запрос и думает «база умная, сама со всем справится!«
В некоторых случаях (частично от незнания возможностей БД, частично от преждевременных оптимизаций) такой подход приводит к появлению «франкенштейнов».
Сначала приведу пример такого запроса:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Чтобы предметно оценивать качество запроса, давайте создадим некий произвольный набор данных:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
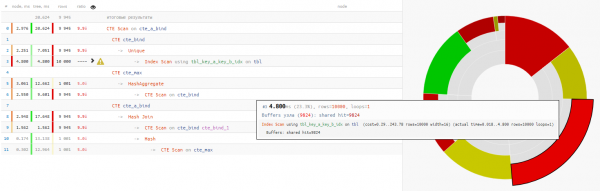
Оказывается, само чтение данных заняло меньше четверти всего времени выполнения запроса:
Разбираем по косточкам
Пристально посмотрим на запрос, и озадачимся:
- Зачем тут WITH RECURSIVE, если никаких рекурсивных CTE — нету?
- Зачем группировать min/max-значения в отдельной CTE, если потом они все равно привязываются к оригинальной выборке?
+25% времени - Зачем использовать в конце повторную начитку из предыдущей CTE через безусловный ‘SELECT * FROM’?
+14% времени
В данном случае нам еще сильно повезло, что для соединения был выбран Hash Join, а не Nested Loop, поскольку тогда мы получили бы не один-единственный проход CTE Scan, а 10K!
немного о CTE ScanТут надо вспомнить, что CTE Scan является аналогом Seq Scan — то есть никакой индексации, а только полный перебор, который потребовал бы 10K x 0.3ms = 3000ms при циклах по cte_max ose 1K x 1.5ms = 1500ms при циклах по cte_bind!
Собственно, а что хотели получить-то в результате? Ага, обычно именно такой вопрос и посещает где-то на 5й минуте разбора «трехэтажных» запросов.
Мы хотели для каждой уникальной ключевой пары вывести min/max из группы по key_a.
Так воспользуемся же для этого :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 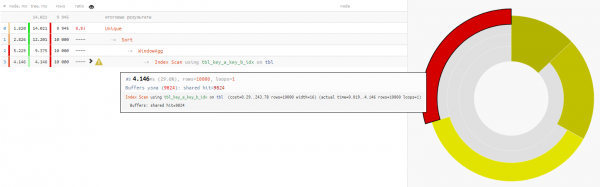
Поскольку чтение данных в обоих вариантах занимает одинаково примерно 4-5ms, то весь наш выигрыш по времени -32% — это в чистом виде нагрузка, убранная с CPU базы, если такой запрос выполняется достаточно часто.
В общем, не стоит базу заставлять «круглое — носить, квадратное — катать».
Burimi: habr.com
