

Kujdesi për operacionet, bufferat që sjellin…
Do të shqyrtojmë disa qasje universale për optimizimin e kërkesave në PostgreSQL përmes një kërkese të vogël. Të përdoren ato apo jo — është zgjedhja juaj, por ia vlen të jeni të informuar për to.
Në ndonjë version të ardhshëm të PG, situata mund të ndryshojë me "inteligjencën" e planifikuesit, por për 9.4/9.6 ajo duket përafërsisht e njëjtë siç janë këtu shembujt.
Do të marrë një kërkesë mjaft reale:
SELECT
TRUE
FROM
"Dokument" d
INNER JOIN
"DokumentRrëfyes" doc_ex
USING("@Dokument")
INNER JOIN
"TipiDokumentit" t_doc ON
t_doc."@TipiDokumentit" = d."TipiDokumentit"
WHERE
(d."Lënda3" = 19091 or d."Punonjësi" = 19091) AND
d."$Kthimi" IS NULL AND
d."Fshier" IS NOT TRUE AND
doc_ex."Statusi"[1] IS TRUE AND
t_doc."TipiDokumentit" = 'PlanPunes'
LIMIT 1; për emrat e tabelave dhe fushaveNë lidhje me emrat "rusë" të fushave dhe tabelave, mund të keni mendime të ndryshme, por kjo është çështje shije. Pasi që nuk kemi zhvillues të huaj, dhe PostgreSQL na lejon të jepni emra madje edhe me hieroglifë, për sa kohë që janë të rrethuara me thonjëza, ne preferojmë të emërojmë objektet në mënyrë të qartë dhe të kuptueshme, në mënyrë që të mos ketë keqkuptime.
Le të shohim planin e marrë:
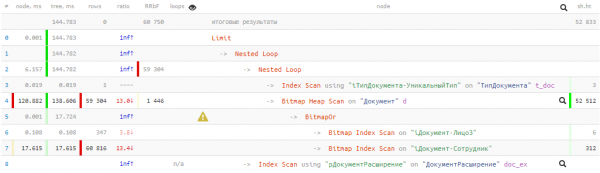
144ms dhe gati 53K buffer — do të thotë më shumë se 400MB të dhënash! Dhe do të kemi fat nëse të gjitha ato do të ishin në cache në momentin e kërkesës tonë, përndryshe ajo do të zgjasë disa herë më gjatë kur të lexojmë nga disku.
Algoritmi është më i rëndësishëm se gjithçka!
Për të optimizuar ndonjë kërkesë, së pari duhet të kuptojmë çfarë duhet të bëjë ajo.
Të lëmë jashtë kësaj artikulli zhvillimin e strukturës së DB-së, dhe të pajtohemi që ne mund ta riformatojmë kërkesën dhe/ose të aplikojmë disa indekse.
Kështu, kërkesa:
— kontrollon ekzistencën e ndonjë dokumenti
— në gjendjen e nevojshme dhe të një tipi të caktuar
— ku autori ose realizuesi është punonjësi ynë i nevojshëm
JOIN + LIMIT 1
Shpeshherë, zhvilluesit e preferojnë të shkruajnë një kërkesë ku fillimisht lidhen shumë tabela, dhe pastaj nga gjithë ato mbetet vetëm një regjistrim. Por më e lehta për zhvilluesin — nuk do të thotë më efektive për DB-në.
Në rastin tonë kishte vetëm 3 tabela — dhe çfarë efekti…
Le të fillojmë duke eliminuar lidhjen me tabelën "TipDokumenti", ndërkohë që i tregojmë DB-së se regjistrimi i tipit tonë është unik (ne e dimë, por planifikuesi ende nuk e ka kuptuar):
ME T SI (
ZGJIDHJA
"@LlojiDokumentit"
NGA
"LlojiDokumentit"
KU
"LlojiDokumentit" = 'Plani i Punës'
KUFIZO 1
)
...
KU
d."LlojiDokumentit" = (TABELA T)
...Po, nëse tabela/CTE përbëhet nga një fushë e vetme me një regjistër vetëm, mund ta shkruajmë edhe kështu në PG, në vend të
d."LlojiDokumentit" = (ZGJIDH "@LlojiDokumentit" NGA T KUFIZO 1)Llogaritjet «lenjase» në kërkesat PostgreSQL
BitmapOr vs UNION
Në disa raste, Bitmap Heap Scan do të na kushtojë shumë — për shembull, në situatën tonë, ku mjaft regjistra bien nën kushtin e kërkuar. E kemi marrë këtë për shkak të kushtit OR, i transformuar në BitmapOr-operimin në plan.
Le të kthehemi te detyra fillestare — duhet të gjejmë regjistrin që i përgjigjet ndonjërit nga kushtet — do të thotë nuk ka nevojë të kërkojmë të gjitha 59K regjistrat për të dy kushtet. Ekziston një mënyrë për të përfunduar një kusht, dhe për të kaluar te tjetri vetëm kur për të parin nuk gjendet asgjë. Një konstrukcion i tillë do na ndihmojë:
(
ZGJIDHJA
...
KUFIZO 1
)
UNION ALL
(
ZGJIDHJA
...
KUFIZO 1
)
KUFIZO 1LIMIT 1 garanton që kërkimi do të mbyllet sapo të gjendet regjistri i parë. Dhe nëse ai gjendet në blokun e parë, ekzekutimi i dytë nuk do të kryhet (nuk ekzekutohet kurrë në plan).
«Fshehim nën CASE» kushtet e komplikuara
Një moment shumë i pakëndshëm në kërkesën origjinale është kontrolli i gjendjes në tabelën e lidhur «DokumentZgjerimi». Pavarësisht nga vërtetësia e kushteve të tjera në shprehje (për shembull, d.«Fshirë» NUK ËSHTË E VERTETË), ky lidhje kryhet gjithmonë dhe «kushton burime». Më shumë ose më pak do të shpenzohen - varet nga volumi i kësaj tabele.
Por mund të modifikojmë kërkesën në mënyrë që kërkimi i regjistrit të lidhur të ndodhte vetëm kur kjo është në të vërtetë e nevojshme:
SELECT
...
FROM
"Dokument" d
WHERE
... /*kusht index*/ DHE
CASE
KUR "$Draft" ËSHTË NULL DHE "Fshirë" NUK ËSHTË E VERTETË ATËHERË (
SELECT
"Gjendja"[1] ËSHTË E VERTETË
FROM
"DokumentZgjerimi"
WHERE
"@Dokument" = d."@Dokument"
)
FUND Pasi nga tabela e lidhur nuk na duhen asnjë nga fushat, atëherë kemi mundësinë ta kthejmë JOIN në kusht sipas nënkërkese.
Lërini fushat e indeksuara «jashtë» CASE, kushtet e thjeshta i përfshijmë në bllokun WHEN — dhe tani kërkesa «e rëndë» ekzekutohet vetëm kur kalojmë në THEN.
Mënyra ime «Të gjitha»
Krijojmë kërkesën përfundimtare me të gjitha mekanizmat e përshkruar më sipër:
ME T SI (
ZGJIDH
"@TipiDokumenti"
NGA
"TipiDokumentit"
KU
"TipiDokumentit" = 'Plani i Punës'
)
(
ZGJIDH
E VERTETË
NGA
"Dokumenti" d
KU
("Persona3", "TipiDokumentit") = (19091, (TABELA T)) DHE
RASTI
KUR "$Draft" ËSHTE NULL DHE "Fshirë" NUK ËSHTE E VERTETË atëherë (
ZGJIDH
"G状态"[1] ËSHTE E VERTETË
NGA
"DokumentiZgjatje"
KU
"@Dokumenti" = d."@Dokumenti"
)
FUND
KUFIZO 1
)
BASHKOHUNI TË GJITHA
(
ZGJIDH
E VERTETË
NGA
"Dokumenti" d
KU
("TipiDokumentit", "Punonjësi") = ((TABELA T), 19091) DHE
RASTI
KUR "$Draft" ËSHTE NULL DHE "Fshirë" NUK ËSHTE E VERTETË atëherë (
ZGJIDH
"G状态"[1] ËSHTE E VERTETË
NGA
"DokumentiZgjatje"
KU
"@Dokumenti" = d."@Dokumenti"
)
FUND
KUFIZO 1
)
KUFIZO 1;Përshtatëm [për] indeksat
Syri i zakonshëm vuri re se kushtet e indeksuara në nënblloqet UNION pak ndryshojnë — kjo është sepse tashmë kemi indeksat e duhur në tabelë. Nëse nuk do të kishte, atëherë do të ishte e nevojshme të krijohej: Dokumenti(Faqe3, LlojiDokumentit) dhe Dokumenti(LlojiDokumentit, Punonjësi).
rreth rendit të fushave në kushtet ROWSipas planifikuesit, natyrisht, mund të shkruhet dhe (A, B) = (constA, constB), dhe (B, A) = (constB, constA). Por gjatë regjistrimit në rendin e fushave në indeks, një kërkesë e tillë është thjesht më e lehtë për debug.
Çfarë ka në plan?
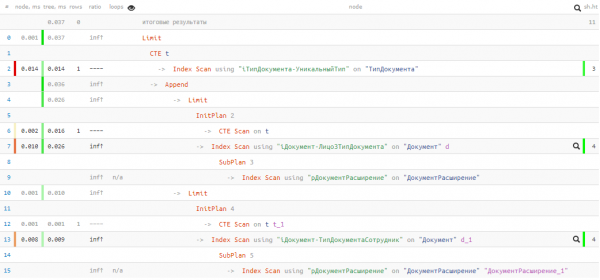
Fatkeqësisht, nuk patëm fat, dhe në bllokun e parë UNION nuk u gjet asgjë, prandaj i dyti ndoqi megjithatë për ekzekutim. Por edhe kështu — vetëm 0.037ms dhe 11 buffers!
Ne rritëm shpejtësinë e kërkesës dhe reduktuam "shkarkimin" e të dhënave në memorie në disa mijëra herë, duke përdorur metoda mjaft të thjeshta — një rezultat i shkëlqyer për një kopje të vogël. 🙂
Burimi: habr.com
