


Përshëndetje, Habr.
Së fundmi unë rreth parametrave që ekipi ynë shpesh i përdor për Kafka Producer dhe Consumer, për t'u afruar pranë dërgesës së garantuar. Në këtë artikull dëshiroj të flas për mënyrën se si organizuam riciklimin e ngjarjeve, të marra nga Kafka, si rezultat i papjeshmërisë për kohë nga një sistem të jashtëm.
Aplikacionet moderne funksionojnë në një ambient shumë kompleks. Logjika e biznesit, e mbështjellë në një tech stack modern, duke funksionuar në një imazh Docker, i menaxhuar nga një orkestrator si Kubernetes ose OpenShift, dhe duke komunikuar me aplikacione të tjera ose zgjidhje enterprise përmes një zinxhiri ruterash fizikë dhe virtualë. Në një ambient të tillë gjithmonë diçka mund të prishet, prandaj riciklimi i ngjarjeve në rastin e papjeshmërisë së njërit prej sistemeve të jashtme është një pjesë e rëndësishme e proceseve tona të biznesit.
Si ishte para Kafka
Më parë në projekt ne përdornim IBM MQ për dërgimin asinkron të mesazheve. Kur ndodhte ndonjë gabim në procesin e funksionimit të shërbimit, mesazhi i marrë mund të vendosej në dead-letter-queue (DLQ) për shqyrtim manual. DLQ krijohej pranë radhës hyrëse, dhe zhvendosja e mesazheve ndodhte brenda IBM MQ.
Nëse gabimi kishte natyrë të përkohshme dhe ne mund ta përcaktonim këtë (p.sh., ResourceAccessException gjatë thirrjes HTTP ose MongoTimeoutException gjatë kërkesës në MongoDb), atëherë hyhej në strategjinë e ripërpjekjeve. Pavarësisht nga degëzimi i logjikës së aplikacionit, mesazhi origjinal zhvendosej ose në radhën sistematike për dërgesë të vonuar, ose në një aplikacion të veçantë që ishte bërë dikur për ripërsëritjen e mesazheve. Gjatë kësaj periudhe, në titullin e mesazhit ruheshin numri i ripërsëritjeve, i lidhur me intervalin e vonesës ose me fundin e strategjisë në nivel aplikacioni. Nëse arrijmë në fundin e strategjisë, por sistemi i jashtëm ende nuk është i aksesueshëm, mesazhi do të vendoset në DLQ për shqyrtim manual.
Kërkimi i zgjidhjes
, mund të gjenden këto . Nëse e përmbledhim, propozohet të krijohet një temë për çdo interval vonese dhe të zbatohen në anën e aplikacionit konsumatorët që do të lexojnë mesazhet me vonesën e nevojshme.
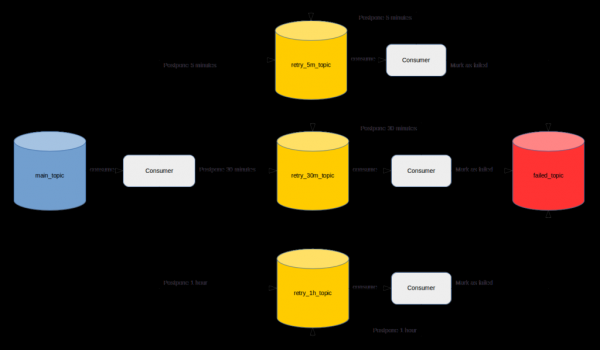
Pavarësisht numrit të madh të komenteve pozitive, duket se nuk është shumë e suksesshme. Në radhë të parë për shkak se zhvilluesi, përveç zbatimit të kërkesave të biznesit, do të duhet të kalojë shumë kohë në zbatimin e mekanizmit të përshkruar.
Për më tepër, nëse menaxhimi i aksesit është i aktivizuar në klasterin Kafka, do të duhet të kaloni një kohë për të krijuar temat dhe për të siguruar akseset e nevojshme për to. Përveç kësaj, do të jetë e nevojshme të përcaktohet parametrin e duhur retention.ms për çdo temë të riangazhimit, në mënyrë që mesazhet të dërgohen përsëri dhe të mos humbasin prej saj. Zbatimi dhe kërkesa për akses do të duhet të përsëritet për çdo shërbim ekzistues ose të ri.
Tani le të shikojmë se cilat mekanizma për përpunimin e përsëritur të mesazheve na ofron spring në përgjithësi dhe spring-kafka në veçanti. Spring-kafka ka një varësi transitive në spring-retry, e cila ofron abstrahqione për menaxhimin e politikave të ndryshme të BackOff. Ky është një mjet mjaft fleksibël, por një nga disavantazhet e saj të rëndësishme është ruajtja e mesazheve për riciklim në memorien e aplikacionit. Kjo do të thotë se rinisja e aplikacionit për shkak të një përditësimi ose gabimi gjatë operimit do të sjellë humbjen e të gjitha mesazheve që presin përpunim të përsëritur. Pasi ky pikë është kritik për sistemin tonë, ne nuk vendosëm ta shqyrtojmë më tej.
Vetë spring-kafka ofron disa realizime të ContainerAwareErrorHandler, për shembull , me anë të të cilit mund të përpunoni mesazhin më vonë, pa e lëvizur offset-in në rast të një gabimi. Duke filluar nga versioni spring-kafka 2.3, u bë e mundur të përcaktoni BackOffPolicy.
Ky qasje lejon që mesazhet e riprocesueshme të përjetojnë rinisjen e aplikacionit, por mekanizmi DLQ ende mungon. Ky është opsioni që ne zgjodhëm në fillim të vitit 2019, me optimizmin se DLQ nuk do të ishte e nevojshme (na ka përkufizuar dhe me të vërtetë nuk u desh për disa muaj shfrytëzimi të aplikacionit me këtë sistem riprocesimi). Gabimet përkohësore e shkaktuan aktivizimin e SeekToCurrentErrorHandler. Gabimet e tjera u regjistruan në log, shkaktuan zhvendosjen e offset, dhe përpunimi vazhdoi me mesazhin tjetër.
Zgjidhja përfundimtare
Realizimi, i bazuar në SeekToCurrentErrorHandler, na nxitën të zhvillojmë mekanizmin tonë për ricelësimin e mesazheve.
Në radhë të parë, ne dëshironim të shfrytëzonim përvojën ekzistuese dhe ta zgjeronim atë sipas logjikës së aplikacionit. Për një aplikacion me logjikë lineare, do të ishte optimale të ndalosh leximin e mesazheve të reja për një periudhë të vogël kohe, të caktuar në kuadër të strategjisë së ripërsëritjes. Për aplikacionet e tjera, do të dëshironim një pikë të vetme që do të sigurojë zbatimin e strategjisë së ripërsëritjes. Për më tepër, kjo pikë e vetme duhet të ketë funksionalitetin DLQ për të dy qasjet.
Strategjia e vetë ripërsëritjes duhet të ruhet në aplikacionin që është përgjegjës për marrjen e intervalit të ardhshëm në rast të një gabimi temporal.
Ndalimi i Consumer-it për aplikacionin me logjikë lineare
Kur punoni me spring-kafka, kodi për ndalimin e Consumer-it mund të duket paksa kështu:
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// te DLQ
}Në shembullin retryAt, është koha kur duhet të rifilloni përsëri MessageListenerContainer nëse ai është akoma në funksion. Rifillimi do të ndodhë në një thread të veçantë, i cili do të nisë në TaskScheduler, zbatimin e të cilit e ofron gjithashtu spring.
Vlera retryAt gjendet në këtë mënyrë:
- Kërkohet vlera e numëruesit të ripërsëritjeve.
- Pavarësisht nga vlera e numëruesit, kërkohet intervali aktual i vonesës në strategjinë e ripërsëritjeve. Strategjia shpallet në aplikacionin vetë, dhe për ruajtjen e saj ne zgjodhëm formatin JSON.
- Intervali i gjetur në masivin JSON përmban numrin e sekondave pas të cilave do të nevojitet të ripërsëritet përpunimi. Ky numër sekondash shtohet në kohën aktuale, duke formuar vlerën për retryAt.
- Nëse intervali nuk gjendet, vlera retryAt është null dhe mesazhi do të dërgohet në DLQ për shqyrtim manual.
Me këtë qasje, mbetet vetëm të ruhet numri i thirrjeve të përsëritura për çdo mesazh që është aktualisht në proces, për shembull në memorien e aplikacionit. Ruajtja e numrit të përpjekjeve në memorie nuk është kritike për këtë qasje, pasi aplikacioni me logjikë lineare nuk mund të kryejë përpunimin në tërësi. Ndryshe nga spring-retry, rindërtimi i aplikacionit nuk do të çojë në humbjen e të gjithë mesazheve për përsëritje, por thjesht do të rinisë strategjinë.
Kjo qasje ndihmon në lehtësimin e ngarkesës në sistemin e jashtëm, i cili mund të jetë i paaksesueshëm për shkak të një ngarkese shumë të lartë. Në fjalë të tjera, përveç përpunimit të përsëritur, ne arritëm implementimin e modelit. .
Në rastin tonë, pragu i gabimit është vetëm 1, dhe për të minimizuar pezullimin e sistemit për shkak të një ndërprerjeje të përkohshme rrjetore, ne përdorim një strategji shumë të detajuar për thirrjet e përsëritura me intervale të vogla vonesash. Kjo mund të mos jetë e përshtatshme për të gjithë aplikacionet e grupit të kompanive, prandaj raporti midis pragut të gabimit dhe madhësisë së intervalit duhet të përshtatet, duke u bazuar në karakteristikat e sistemit.
Një aplikacion i veçantë për përpunimin e mesazheve nga aplikacionet me logjikë të pacaktuar.
Ja një shembull kodi që dërgon një mesazh në një aplikacion të tillë (Retryer), i cili do të përsërisë dërgimin në temën DESTINATION kur të arrihet koha RETRY_AT:
public void retry(ConsumerRecord record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List arrayOfHeaders =
new ArrayList(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "backout"::getBytes);
}
ProducerRecord messageToSend =
new ProducerRecord(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
} Nga shembulli shihet se shumë informacione dërgohen në headra. Vlera RETRY_AT është e njëjtë si për mekanizmin e përsëritjes përmes ndalimit të Consumer-it. Përveç DESTINATION dhe RETRY_AT, ne dërgojmë:
- GROUP_ID, me të cilin grupojmë mesazhet për analizë manuale dhe thjeshtimin e kërkimit.
- ORIGINAL_PARTITION, për të përpjekur të ruajmë të njëjtin Consumer për riprocesim. Ky parametr mund të jetë null, në këtë rast do të merret një partition e re sipas çelësit record.key() të mesazhit origjinal.
- Vlera e përditësuar COUNTER, për të ndjekur strategjinë e rikthimeve.
- SEND_TO — konstanta që tregon nëse duhet të dërgohet mesazhi për ripërpunim kur të arrihet RETRY_AT, apo të vendoset në DLQ.
- REASON — arsyen pse përpunimi i mesazhit u ndërpre.
Retryer ruan mesazhet për ripërpunim dhe analizë manuale në PostgreSQL. Një detyrë aktivizohet nga timer-i, e cila gjen mesazhet me RETRY_AT të skaduar dhe i dërgon ato përsëri në partition ORIGINAL_PARTITION të temës DESTINATION me çelësin record.key().
Pas dërgimit, mesazhet fshihen nga PostgreSQL. Analiza manuale e mesazheve kryhet në një UI të thjeshtë, i cili ndërvepron me Retryer nëpërmjet REST API. Veçoritë e tij kryesore janë përsëritja ose fshirja e mesazheve nga DLQ, shikimi i informacionit për gabimin dhe kërkimi i mesazheve, për shembull sipas emrit të gabimit.
Duke qenë se në klasterët tanë është aktivizuar menaxhimi i aksesit, nevojitet të kërkohen veçmas akseset për temën që dëgjon Retryer, dhe të jepet mundësia që Retryer të shkruajë në temën DESTINATION. Kjo është e pakëndshme, por, ndryshe nga qasja me temën në interval, ne marrim një DLQ të plotë dhe një UI për menaxhimin e saj.
Ka raste kur tema hyrëse lexohet nga disa grupe të ndryshme konsumatorësh, aplikacionet e të cilëve implementojnë logjikë të ndryshme. Përsëritja e trajtimit të mesazhit përmes Retryer për një prej këtyre aplikacioneve do të çojë në një kopje në tjetrin. Për të mbrojtur veten nga kjo, ne krijojmë një temë të veçantë për përpunimin e përsëritur. Tema hyrëse dhe retry-tema mund të lexohen nga i njëjti Konsumator pa asnjë kufizim.
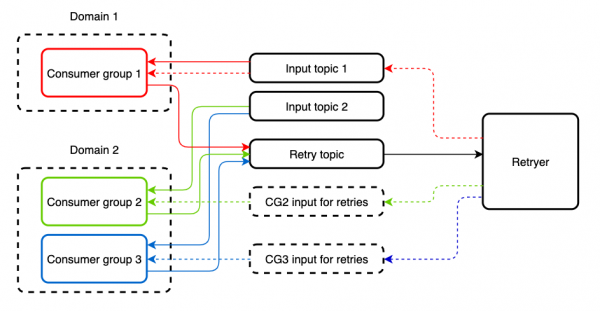
Në përfundim, ky qasje nuk ofron mundësi për një circuit breaker, megjithatë, mund të shtohet në aplikacion duke përdorur ose të reja , duke u mbuluar vendet e thirrjeve të shërbimeve të jashtme me abstraksione përkatëse. Për më tepër, shfaqet mundësia e zgjedhjes së strategjisë për patterns, që gjithashtu mund të jetë e dobishme. Për shembull, në spring-cloud-netflix, kjo mund të jetë një thread pool ose semafor.
Përfundim
Si rezultat, kemi marrë një aplikacion të veçantë që lejon përsëritjen e përpunimit të mesazhit në rast të papërfshirjes përkohësisht të ndonjë sistemi të jashtëm.
Një nga përfitimet kryesore të aplikacionit është se mund të përdoret nga sisteme të jashtme që punojnë në të njëjtin Kafka-cluster, pa nevojën për përmirësime të mëdha nga ana e tyre! Ky aplikacion do të ketë nevojë vetëm të aksesojë retry-temën, të plotësojë disa Kafka-header dhe të dërgojë mesazhin në Retryer. Nuk ka nevojë të ngrihet ndonjë infrastrukturë shtesë. Dhe për të ulur numrin e mesazheve që kalohen nga aplikacioni në Retryer dhe anasjelltas, ne ndamë aplikacionet me logjikë lineare dhe realizuam përpunimin e ripërsëritur përmes ndalimit të Consumer.
Burimi: habr.com
