

Прим. перев.: это перевод публичного постмортема из инженерного блога компании . В нем описывается проблема с conntrack в Kubernetes-кластере, которая привела к частичному простою некоторых сервисов продакшна.
Данная статья может быть полезной тем, кто хочет узнать немного больше о постмортемах или предотвратить некоторые потенциальные проблемы с DNS в будущем.

Это не DNS
Не может быть что это DNS
Это был DNS
Немного о постмортемах и процессах в Preply
В постмортеме описывается сбой в работе или какое-либо событие в продашкне. Постмортем включает в себя хронологию событий, описание воздействия на пользователя, первопричину, действия и извлеченные уроки.
На еженедельных совещаниях с пиццей, в кругу технической команды, мы делимся различной информаций. Одной из важнейшних частей таких совещаний являются постмортемы, которые чаще всего сопровождаются презентацией со слайдами и более глубоким анализом произошедшего инцидента. Несмотря на то, что мы не «хлопаем» после постмортемов, мы стараемся развивать культуру «без упреков» (). Мы верим в то, что написание и представление постмортемов может помочь нам (и не только) в предотвращении подобных инцидентов в будущем, именно поэтому мы и делимся ими.
Лица, вовлеченные в инцидент, должны чувствовать, что они могут подробно рассказать о нем, не опасаясь наказания или возмездия. Никакого порицания! Написание постмортема — это не наказание, а возможность обучения для всей компании.
Проблемы с DNS в Kubernetes. Постмортем
Data: 28.02.2020
Shkruar nga: Амет У., Андрей С., Игорь К., Алексей П.
Статус: Законченный
Shkurtimisht: Частичная недоступность DNS (26 мин) для некоторых сервисов в Kubernetes-кластере
Влияние: 15000 событий потеряно для сервисов A, B и C
Первопричина: Kube-proxy не смог корректно удалить старую запись из таблицы conntrack, поэтому некоторые сервисы все еще пытались соединиться к несуществующим подам
E0228 20:13:53.795782 1 proxier.go:610] Failed to delete kube-system/kube-dns:dns endpoint connections, error: error deleting conntrack entries for UDP peer {100.64.0.10, 100.110.33.231}, error: conntrack command returned: ...Триггер: Из-за низкой нагрузки внутри Kubernetes-кластера, CoreDNS-autoscaler уменьшил количество подов в деплойменте с трех до двух
Zgjidhja: Очередной деплой приложения инициировал создание новых нод, CoreDNS-autoscaler добавил больше подов для обслуживания кластера, что спровоцировало перезапись таблицы conntrack
Обнаружение: Prometheus мониторинг обнаружил большое количество 5xx ошибок для сервисов A, B и C и инициировал звонок дежурным инженерам

5xx ошибки в Kibana
Veprime
Действие
Tipo
Ответственный
Detyra
Отключить автоскейлер для CoreDNS
предотвр.
Амет У.
DEVOPS-695
Установить кеширующий DNS-сервер
уменьш.
Макс В.
DEVOPS-665
Настроить мониторинг conntrack
предотвр.
Амет У.
DEVOPS-674
Извлеченные уроки
Что пошло хорошо:
- Мониторинг сработал четко. Реакция была быстрой и организованной
- Мы не уперлись ни в какие лимиты на нодах
Что было не так:
- Все еще неизвестная реальная первопричина, похоже на в conntrack
- Все действия исправляют только последствия, не первопричину (баг)
- Мы знали, что рано или поздно у нас могут быть проблемы с DNS, но не приоритизировали задачи
Где нам повезло:
- Очередной деплой затриггерил CoreDNS-autoscaler, который перезаписал таблицу conntrack
- Данный баг затронул только часть сервисов
Хронология (EET)
Время
Действие
22:13
CoreDNS-autoscaler уменьшил число подов с трех до двух
22:18
Дежурные инженеры стали получать звонки от системы мониторинга
22:21
Дежурные инженеры начали выяснять причину ошибок
22:39
Дежурные инженеры начали откатывать один из последних сервисов на предыдущую версию
22:40
5xx ошибки перестали появляться, ситуация стабилизировалась
- Время до обнаружения: 4 мин
- Время до совершения действий: 21 мин
- Время до исправления: 1 мин
Informacione shtesë
- Loget e CoreDNS:
I0228 20:13:53.507780 1 event.go:221] Event(v1.ObjectReference{Kind:"Deployment", Namespace:"kube-system", Name:"coredns", UID:"2493eb55-3dc0-11ea-b3a2-02bb48f8c230", APIVersion:"apps/v1", ResourceVersion:"132690686", FieldPath:""}): type: 'Normal' reason: 'ScalingReplicaSet' Scaled down replica set coredns-6cbb6646c9 to 2 - Ссылки на Kibana (вырезано), Grafana (вырезано)
Для минимизации использования процессора, ядро Linux использует такую штуку как conntrack. Если кратко, то это утилита, которая содержит список NAT-записей, которые хранятся в специальной таблице. Когда следующий пакет приходит из того же пода в тот же под что и раньше, конечный IP-адрес не будет рассчитан заново, а будет взят из таблицы conntrack.
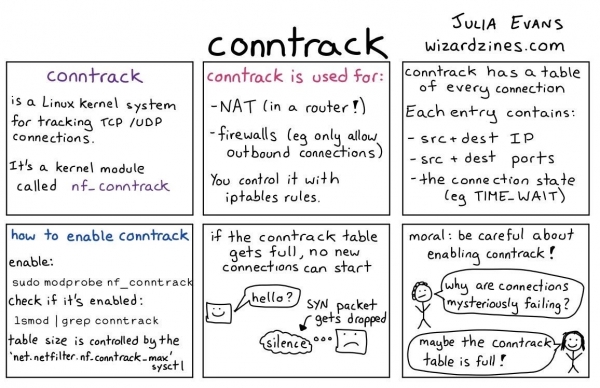
Как работает conntrack
Përfundimet
Это был пример одного из наших постмортемов с некоторыми полезными ссылками. Конкретно в этой статье мы делимся информацией, которая может быть полезна другим компаниям. Вот почему мы не боимся совершать ошибок и вот почему мы сделать один из наших постмортемов публичным. Вот еще несколько интересных публичных постмортемов:
- GitLab:
- Dropbox:
- Spotify:
- Множество других из и репозитория
- Po ashtu публичного постмортема с SRE Book
Burimi: habr.com
