

Ju rendojë të njiheni me përmbledhjen e diskutimit të Nikolai Samokhvalovit "Qasja industriale në tuningun e PostgreSQL: eksperimente mbi bazat e të dhënave"
Shared_buffers = 25% – është shumë apo pak? Apo ndoshta është perfekt? Si mund ta kuptoni nëse kjo – një rekomandim mjaft i vjetër – i përshtatet rastit tuaj konkret?
Ka ardhur koha të afrohemi me çështjen e përcaktimit të parametrave postgresql.conf "si të rritur". Jo me anë të "autotunerëve" të verbër apo këshillave të vjetra nga artikuj dhe blogje, por mbi bazën e:
- eksperimenteve të sakta mbi DB, të realizuara automatikisht, në numra të mëdhenj dhe në kushte sa më afër "luftës",
- njohjes së thellë të veçorive të funksionimit të DBMS dhe OS.
Duke përdorur Nancy CLI (), ne do të shqyrtojmë një shembull konkret – të famshmit shared_buffers – në situata të ndryshme, në projekte të ndryshme dhe do të përpiqemi të kuptojmë se si të përcaktojmë konfigurimin optimal për infrastrukturën tonë, DB dhe ngarkesën.

Do të flasim për eksperimente mbi bazat e të dhënave. Kjo është një histori që vazhdon për më shumë se gjashtë muaj.

Pak të dhëna për veten time. Kam mbi 14 vjet përvojë me Postgres. Kam themeluar disa kompani në rrjetet sociale. Kudo është përdorur dhe përdoret Postgres.
Gjithashtu, grupi RuPostgres në Meetup, vendi i dytë në botë. Po afrohemi ngadalë drejt 2000 personave. RuPostgres.org.
Dhe në shumë konferenca, duke përfshirë Highload, unë jam përgjegjës për bazat e të dhënave, veçanërisht Postgres që nga fillimi.

Dhe në vitet e fundit kam rinisur praktikën time të këshillimit për Postgres në 11 zona orare nga këtu.

Dhe kur e bëra këtë disa vite më parë, pata një ndalesë të dukshme në punën manuale me Postgres, ndoshta që nga viti 2010. U habitëm se sa pak kishin ndryshuar ditët e punës së DBA-ve, sa shumë punë manuale ende është e nevojshme. Dhe menjëherë mendova se diçka nuk shkon, duhet të automatizohet më shumë.
Dhe për shkak se kjo ndodhte kryesisht në distancë, shumica e klientëve ishin në cloud. Dhe tashmë shumë është automatizuar, kjo është e qartë. Për këtë do të flasim më vonë. Kjo do të thotë se gjithçka kyçej në një ide, që duhet të kemi një mori instrumentesh, pra një platformë, e cila do të automatizonte pothuajse të gjitha veprimet e DBA-ve, në mënyrë që të mund të menaxhonim një numër të madh bazash.

Në këtë diskutim nuk do të ketë:
- „Fletët argjendi” dhe deklarata si – vendosni 8 GB ose 25% shared_buffers dhe do t'ju shkojë mirë. Për shared_buffers nuk do të flitet shumë.
- Hardcore „thellësi”.

Po çfarë do të ketë?
- Do të jenë parime optimizimi që ne i aplikojmë dhe i zhvillojmë. Do të jenë çdo lloj ideje që na lind në rrugë dhe një mori instrumentesh që krijojmë kryesisht në Open Source, pra ne krijojmë një bazë në Open Source. Për më tepër, kemi bileta, të gjithë komunikimi është praktikisht në Open Source. Mund të shihni se çfarë po bëjmë tani, çfarë do të jetë në versionin e ardhshëm, etj.
- Do të ketë gjithashtu disa përvoja mbi përdorimin e këtyre parimeve dhe këtyre instrumenteve në një sërë kompanish: nga fillestarë të vegjël deri tek kompani të mëdha.

Si zhvillohet gjithçka kjo?

Së pari, detyra kryesore e DBA-së përveç sigurisë së krijimit të instanceve, përhapjes së kopjeve të rezervës etj., është identifikimi i ngushticave dhe optimizimi i performancës.
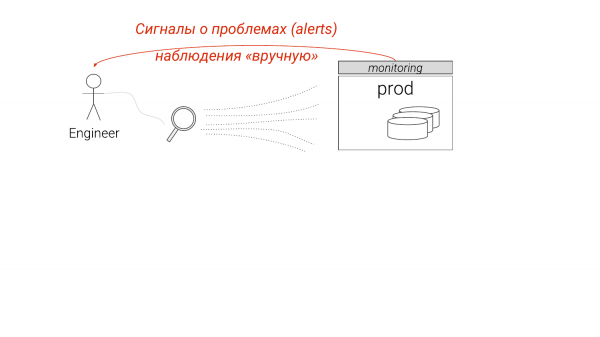
Tani, kjo është strukturuar kështu. Ne shikojmë monitorimin, shohim diçka, na mungojnë disa detaje. Fillojmë të hetojmë më në thellësi, zakonisht me duar dhe kuptojmë se çfarë duhet të bëjmë kështu ose ashtu.
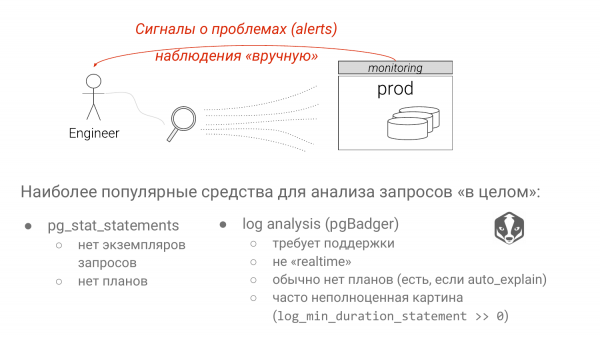
Dhe ka dy qasje. Pg_stat_statements – zgjidhja standarde për identifikimin e kërkesave të ngadalta. Dhe analiza e logëve të Postgres me pgBadger.
Çdo qasje ka të meta të rënda. Në qasjen e parë ne hedhim të gjitha parametrat. Dhe nëse ne shohim grupe SELECT * FROM table where kolona është e barabartë me simbolin "?" ose "$" që nga versione Postgres 10. Ne nuk e dimë – bëhet fjalë për një skanim indeksi apo një skanim sekondar. Vërtet varet shumë nga parametri. Nëse shton një vlerë të rrallë, do të jetë skanim indeksi. Nëse fut një vlerë që përfshin 90% të tabelës, do të jetë skanim sekondar, sepse Postgres di statistikën. Dhe kjo është një mangësi e madhe e pg_stat_statements, megjithatë disa punë po zhvillohen.
Analiza e logëve ka mangësinë më të madhe që nuk mund të lejoni "log_min_duration_statement = 0", si rregull. Dhe për këtë do të flasim gjithashtu. Për këtë arsye, nuk e shihni tërë pamjen. Dhe një kërkesë që është shumë e shpejtë, mund të konsumojë një sasi të madhe burimesh, por ju nuk do ta shihni atë, sepse është nën pragun tuaj.
Si i zgjidhin DBA-të problemet e gjetura?
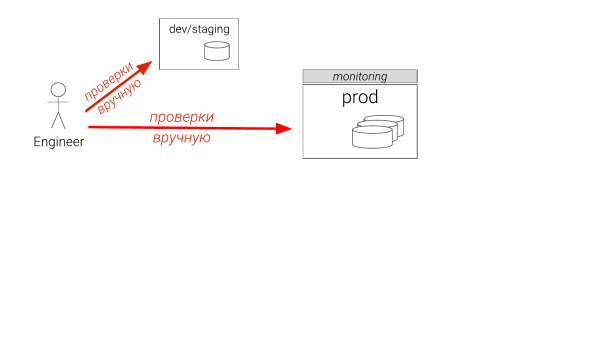
Për shembull, gjetëm një problem. Çfarë bëhet zakonisht? Nëse jeni zhvillues, do të bëni diçka në ndonjë instance që nuk është aq i madh. Nëse jeni DBA, keni staging. Dhe ai mund të jetë vetëm një. Dhe është pas me gjashtë muaj. Dhe mendoni se do të shkoni në production. Edhe DBA të përvojshëm kontrollojnë pastaj në production, në replikë. Dhe ndonjëherë krijojnë një indeks të përkohshëm, e kontrollojnë nëse ndihmon, e heqin dhe ia dorëzojnë zhvilluesve për ta futur në skedarët e migrimit. Kjo është çfarë po ndodh tani. Dhe kjo është e keqe.
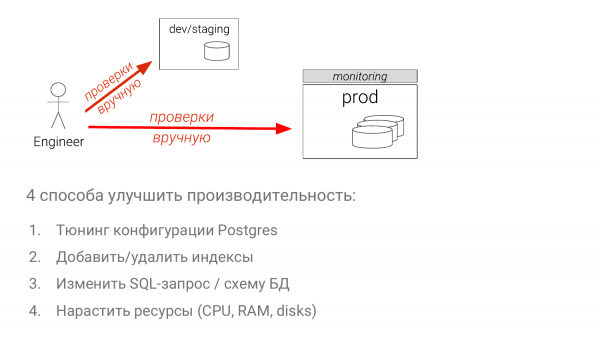
- Të optimizoni konfigurimet.
- Të optimizoni grupin e indekseve.
- Të ndryshoni krijimin e SQL (kjo është mënyra më e vështirë).
- Të shtoni kapacitet (mënyra më e lehtë në shumicën e rasteve).

Me këto gjëra ka shumë për të bërë. Ka shumë mundësi në Postgres. Duhet të dini shumë. Ka shumë indekse në Postgres, falë organizatorëve të kësaj konference. Dhe të gjitha këto duhet të dihen, dhe pikërisht kjo i jep ndjesinë atyre që nuk janë DBA se ata merren me magji të zezë. Pra, duhet të kaloni rreth 10 vjet për të filluar të kuptoni të gjitha këto siç duhet.
Dhe unë jam luftëtar kundër kësaj magjie të zezë. Dua të bëj gjithçka në mënyrë që të ketë teknologji, e jo intuitë në të gjitha këto.
Shembuj nga jeta

Këtë e kam vëzhguar në të paktën dy projekte, përfshirë të mien. Një postim i ri në blog na tregon se vlera 1 000 për default_statistict_target – është e mirë. Mirë, le të provojmë në production.

Dhe këtu ne, duke përdorur mjetin tonë dy vjet më vonë me eksperimente mbi bazat e të dhënave për të cilat po flasim sot, mund të krahasojmë çfarë ka qenë dhe çfarë është bërë.
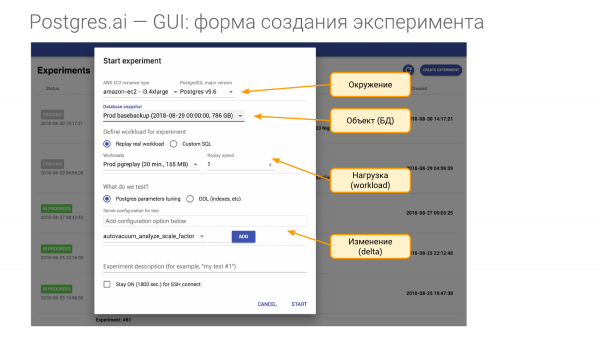
Dhe për këtë na nevojitet të krijojmë një eksperiment. Ai përbëhet nga katër pjesë.
- E para – është mjedisi. Na nevojitet harduer. Dhe kur shkoj në ndonjë kompani dhe lidh një kontratë, unë them që të më japin harduerin e njëjtë si në production. Për secilin nga Master-at tuaja, më nevojitet të paktën një harduer i tillë. Qoftë kjo një makinë virtuale instance në Amazon ose në Google, ose më nevojitet pikërisht një harduer i njëjtë. Pra, dua ta riprodhoj mjedisin. Dhe në konceptin e mjedisit përfshijmë versionin kryesor të Postgres.
- Pjesa e dytë – është objekti i hulumtimeve tona. Kjo është baza e të dhënave. Ajo mund të krijohet në disa mënyra. Unë do të tregoj si.
- Pjesa e tretë – është ngarkesa. Ky është momenti më i komplikuar.
- Dhe pjesa e katërt – është ajo që ne kontrollojmë, pra çfarë do të krahasojmë. Le të themi, mund të ndryshojmë një ose disa parametra në konfigurim, ose mund të krijojmë një indeks dhe kështu me radhë.
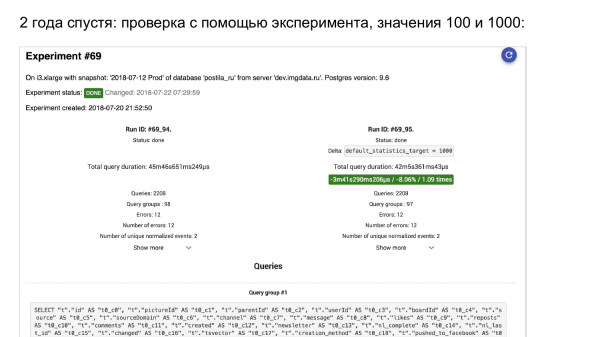
Ne fillojmë eksperimentin. Ja pg_stat_statements. Nga e majta – ajo që ishte. Nga e djathta – sidomos si është bërë.
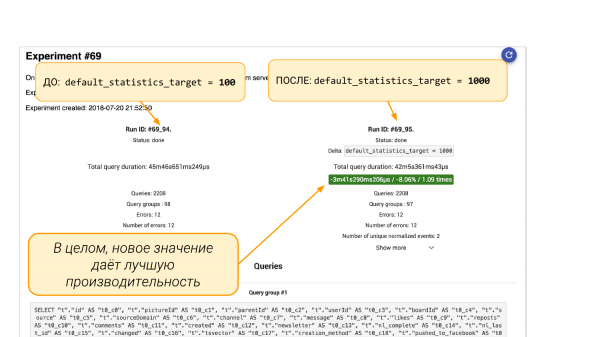
Nga e majta default_statistics_target = 100, nga e djathta = 1 000. Shohim se na ndihmoi. Në 8% gjithçka është përmirësuar.
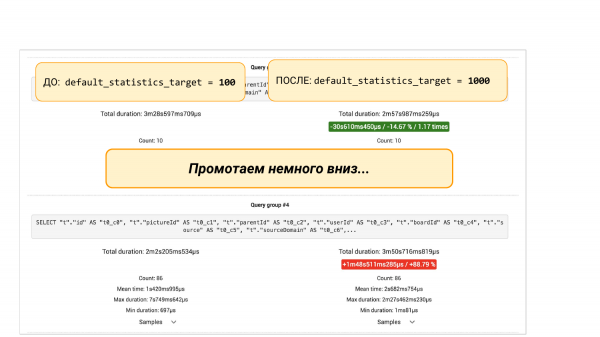
Por nëse rrokullisim poshtë, do të ketë grupe kërkesash nga pgBadger ose nga pg_stat_statements. Këtu ka dy variante. Ne do të shohim që ndonjë kërkesë ka rënë me 88%. Dhe këtu është një qasje inxhinierike. Ne mund të thellojmë më tej, sepse na intereson, pse ra. Duhet të kuptojmë se çfarë ndodhi me statistikën. Pse më shumë bakete në statistikë çojnë në një rezultat më të keq.
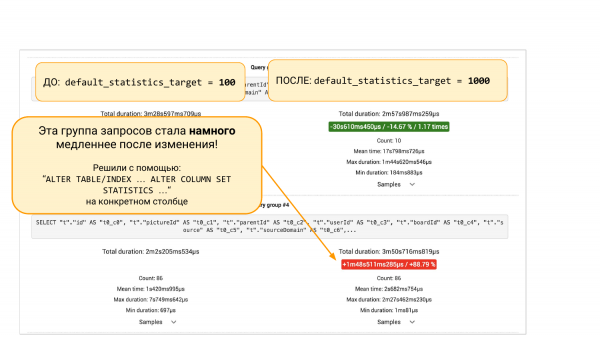
Ose mund të mos thellohemi, por të bëjmë "ALTER TABLE … ALTER COLUMN" dhe t'i kthejmë sërish 100 bakete në statistikën e kësaj kolone. Dhe më tej, me një eksperiment, ne mund të sigurohemi se kjo zgjidhje ndihmoi. Kjo është qasje inxhinierike, që na ndihmon të shohim imazhin dhe të marrim vendime mbi të dhëna, dhe jo mbi intuitë.


Pak shembuj nga fusha të tjera. Në testime ka CI-testime për shumë vite. Dhe asnjë projekt tashmë në mendjen e shëndoshë nuk do të ekzistojë pa teste automatike.
Në fusha të tjera: në aviacion, në automobilizëm, kur testojmë aerodinamikën, ne gjithashtu kemi mundësinë të bëjmë eksperimente. Nuk do të hedhim ndonjë gjë të hartuar menjëherë në hapësirë ose nuk do të nxjerrim ndonjë makinë menjëherë në rrugë. Për shembull, ka një tunel aerodinamik.
Nga vëzhgimet në fusha të tjera, ne mund të nxjerrim përfundime.

Së pari, kemi një mjedis të specializuar. Ai është afër production, por nuk është afër. Karakteristika kryesore është se duhet të jetë i lirë, i riprodhueshëm dhe maksimalisht i automatizuar. Dhe gjithashtu duhet të kemi mjete speciale për një analizë të detajuar.
Shumë mundësi, kur hedhim avionin dhe flasim, në kemi më pak mundësi për të studiuar çdo milimetër të sipërfaqes së krahut, sesa kemi në tunelin aerodinamik. Ne kemi më shumë mjete për diagnostikim. Mund të lejojmë veten të vendosim më shumë peshë, që nuk mund ta vendosim në avion ndërsa fluturojmë. Po ashtu edhe me Postgres. Në disa raste, mund të aktivizojmë regjistrimin e plotë të kërkesave gjatë eksperimenteve. Dhe ne nuk duam ta bëjmë këtë në production. Ndoshta madje këtë do ta aktivizojmë me planet duke përdorur auto_explain.
Dhe siç thashë, niveli i lartë i automatizimit do të thotë që ne e shtypëm butonin dhe e kemi përsëritur. Kështu duhet të jetë që të ketë shumë eksperimente, që të jetë në fluks.
Nancy CLI – baza e "laboratorit të DB"

Dhe ja çfarë kemi bërë. Domethënë, për këto ide kam folur në qershor, gati një vit më parë. Dhe ne tashmë kemi në Open Source atë që quhet Nancy CLI. Ky është themeli për ndërtimin e laboratorit të bazës së të dhënave.
— Kjo është në Open Source, në Gitlab. Mund ta shikoni, mund ta provoni. Kam lënë një lidhje në slidet. Mund të klikoni dhe atje do të jetë për të gjitha parametrat.
Sigurisht, aty ka shumë që janë ende në zhvillim. Ka shumë ide. Por kjo është diçka që ne e aplikojmë në përditshmëri. Dhe kur na vjen një ide – a çfarë ndodh kur fshihet 40 000 000 rreshta dhe gjithçka përfundon në IO, ne mund të kryejmë një eksperiment dhe të shohim më në detaje, për të kuptuar çfarë po ndodh dhe pastaj të përpiqemi ta rregullojmë atë në moment. Domethënë, ne bëjmë një eksperiment. Për shembull, ndryshojmë diçka dhe shohim çfarë rezultati merrim. Dhe ne e bëjmë këtë jo në prodhim. Kjo është thelbi i ideve.
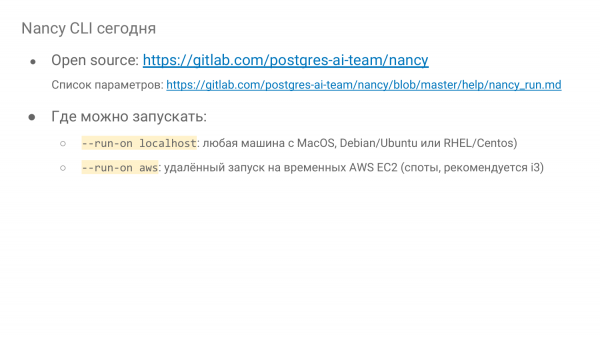
Ku mund të funksionojë kjo? Mund të funksionojë lokalisht, domethënë mund ta bëni kudo, mund ta nisni edhe në MacBook. Duhet Docker, le të nisim. Dhe gjithë kjo. Mund ta nisim në ndonjë instancë në harduer, ose në një makinë virtuale, kudo.
Dhe ka gjithashtu mundësinë për ta nisur nga larg në Amazon në EC2 Instance, në spot. Dhe kjo është një mundësi shumë e shkëlqyer. Për shembull, dje ne kryem mbi 500 eksperimentet në instancën i3, duke filluar nga më e vogla dhe duke përfunduar me i3-16-xlarge. Dhe na kushtuan 500 eksperimente 64 dollarë. Çdo njëra zgjati 15 minuta. Domethënë, për shkak se aty përdoren spotet, kjo është shumë e lirë – zbritje 70%, tarifimi për sekondë nga Amazon. Mund të bëni shumë. Mund të kryeni një studim të vërtetë.
Dhe tri versione kryesore të Postgres mbështeten. Nuk është aq e vështirë të përshtatni disa të vjetra dhe versionin e ri 12 gjithashtu.

Objektin mund ta përcaktojmë në tri mënyra. Këto janë:
- Dump/sql-file.
- Mënyra kryesore – është kloni i drejtorisë PGDATA. Në përgjithësi merret nga serveri i backup-it. Nëse keni backup-e binarë të mira, mund të bëni klona atje. Nëse keni cloud, atëherë kjo do të bëhet nga kompania cloud si Amazon ose Google. Kjo është mënyra kryesore për klonat e prodhimit real. Në këtë mënyrë ne po e zbatojmë.
- Dhe mënyra e fundit është e përshtatshme për hulumtime, kur dëshirojmë të kuptojmë se si funksionon diçka në Postgres. Kjo është pgbench. Mund të gjeneroni me ndihmën e pgbench. Kjo është thjesht një zgjedhje "db-pgbench". I thoni atij se çfarë shkalle. Dhe gjithçka do të gjenerohet në cloud, siç thuhet.

Dhe ngarkesa:
- Ngarkesën mund ta ekzekutojmë në një rrjedhë SQL. Kjo është mënyra më primitive.
- Ose mund të emulojmë ngarkesën. Dhe emulimi mund të bëhet kryesisht në këtë mënyrë. Duhet të mbledhim të gjitha log-et. Dhe kjo është e dhimbshme. Do të tregoj pse. Dhe me ndihmën e pgreplay, që është i integruar në Nancy.
- Ose një alternativë tjetër. E ashtuquajtura ngarkesë artizanal, që ne e bëjmë me disa përpjekje. Duke analizuar ngarkesën tonë aktuale në sistemin aktiv, ne tërheqim grupet kryesore të kërkesave. Dhe me ndihmën e pgbench mund të emulojmë këtë ngarkesë në laborator.

- Ose ndoshta duam të ekzekutojmë ndonjë SQL, domethënë kontrollojmë migrimin, krijojmë një indeks, përfundojmë një ANALAZE. Dhe shohim çfarë ndodhi para dhe pas vakuumit. Në përgjithësi, çdo SQL.
- Ose ne në konfigurim ndryshojmë një ose disa parametra. Mund të themi që të kontrollojmë, për shembull, 100 vlera në Amazon për bazën tonë një terabajt. Dhe pas disa orësh do të keni rezultatin. Në përgjithësi, baza e të dhënave një terabajt do të zgjerohet për disa orë. Por në zhvillim ka njollë, kemi mundësi serike, domethënë mund të përdorni rendin e njëjtë të pgdata në të njëjtin server dhe të kontrolloni. Postgres do të rindezë, cache-et do të fshihen. Dhe mund të provoni ngarkesën.

- Vjen një direktorë, në të cilën ka shumë skedarë, duke filluar nga snapshot-et pgstat***. Dhe aty më e rëndësishmja – janë pg_stat_statements, pg_stat_kcacke. Këto janë dy zgjerime që analizojnë kërkesat. Dhe pg_stat_bgwriter përmban jo vetëm statistikën e pgwriter, por gjithashtu informacion për checkpoint dhe si backend-at vetë shtyjnë buferat e ndotura. Dhe gjithçka është interesante për t'u parë. Për shembull, kur e konfiguroni shared_buffers, është shumë interesante të shihni sa shumë janë kaluar.
- Po ashtu vijnë log-et e Postgres. Dy log-e – log-u i përgatitjes dhe log-u i ekzekutimit të ngarkesës.
- Tipar relativisht i ri – janë FlameGraphs.
- Po të njëjtën mënyrë, nëse keni përdorur pgreplay ose pgbench opsionet e ngarkesës, do të keni daljen e tyre natyrale. Dhe do të shihni latencën dhe TPS-in. Do t'ju ndihmojë të kuptoni si i kanë parë ato.
- Informacion në lidhje me sistemin.
- Kontrolli bazik i CPU-së dhe IO. Kjo është më shumë për instancat EC2 në Amazon, kur dëshironi të ekzekutoni 100 instanca të njëjta dhe të ekzekutoni 100 teste të ndryshme, do të keni 10,000 eksperimente. Dhe duhet të siguroheni që të mos përfshiheni me një instancë të dëmtuar që dikush tjetër e ka shkarkuar. Në këtë pajisje, të tjerë janë aktivizuar dhe juve ju mbetet pak burim. Të tilla rezultate është më mirë t'i hidhni poshtë. Dhe pikërisht me ndihmën e sysbench nga Aleksei Kopytov, realizojmë disa kontrole të shkurtra, të cilat vijnë dhe mund të krahasohen me të tjerët, pra do të kuptoni si sillet CPU dhe si sillet IO.

Çfarë është e komplikuar teknikisht përmes shembujve të ndryshëm të kompanive?

Supozoni se dëshirojmë të ripërsërisim ngarkesën reale me ndihmën e skedarëve të log. Një ide e shkëlqyer nëse është shkruar në Open Source pgreplay. Ne e përdorim. Por, për të punuar mirë, duhet të aktivizoni regjistrimin e plotë të kërkesave me parametra dhe kohë.
Ka disa vështirësi sa i përket kohëzgjatjes dhe timestamp-eve. Ne do ta lemë këtë për momentin. Pyetja kryesore është – a mund ta lejoni këtë apo jo?

Problemi është se kjo mund të mos jetë e disponueshme. Duhet të kuptoni së pari se çfarë lloj fluksi do të shkruhet në log. Nëse keni pg_stat_statements, mund të përdorni këtë pyetje (linku do të jetë i disponueshëm në slidet) për të kuptuar se sa shumë byte do të shkruhen për sekondë.
Shikojmë në gjatësi të pyetjes. Në këtë rast injorojmë faktin se nuk ka parametra, por e dimë gjatësi e pyetjes dhe e dimë sa herë për sekondë ajo është ekzekutuar. Kështu, mund të bëjmë një vlerësim se sa byte do të shkruhet për sekondë. Mund të gabojmë dy herë, por rendi do ta kuptojmë me siguri në këtë mënyrë.
Mund të shohim që kjo pyetje ekzekutohet 802 herë në sekondë. Dhe shohim se bytes_per sec – 300 kB/s do të shkruhen plus minus. Dhe, zakonisht, ne mund ta lejojmë një fluks të tillë.

Por! Problemi është se ka sisteme të ndryshme regjistrimi. Dhe, në përgjithësi, njerëzit zakonisht kanë «syslog».
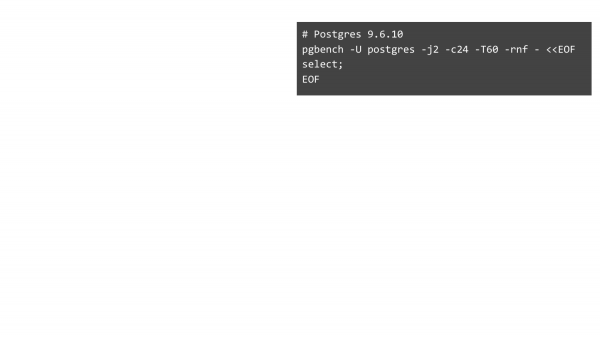
Dhe nëse keni syslog, mund të ndodheni me një pamje të tillë. Do të marrim pgbench, do të aktivizojmë regjistrimin e kërkesave dhe do të shikojmë se çfarë ndodh.
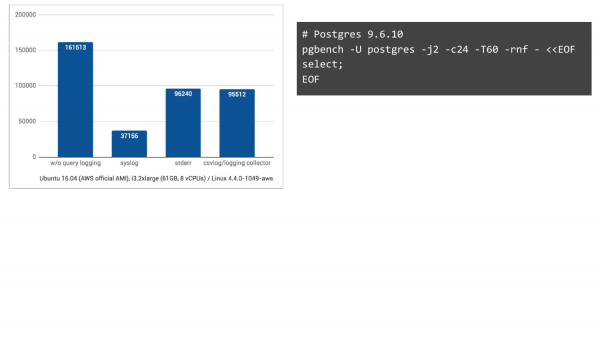
Pa regjistrim – ky është kolona e majtë. Ne kishim 161,000 TPS. Me syslog – kjo në Ubuntu 16.04 në Amazon rezulton 37,000 TPS. Dhe nëse ne ndryshojmë në dy metoda të tjera regjistrimi, situata është shumë më e mirë. Pra, prisnim që do të bjerë, por jo kaq shumë.
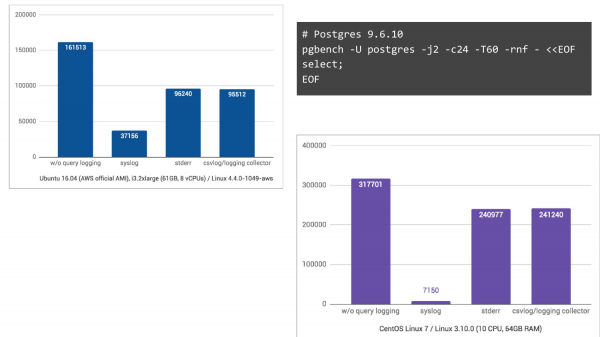
Ndërsa në CentOS 7, ku merr pjesë edhe journald, regjistrimi i logeve në formatin binar për kërkime më të lehta, atje ndodh një situatë katastrofike, me 44 herë rënie në TPS.
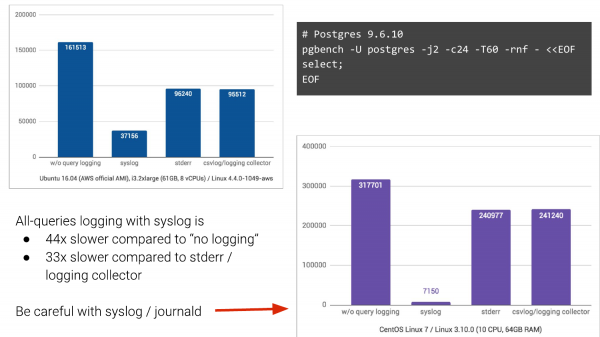
Dhe kjo është diçka me të cilën përballen njerëzit. Dhe shpesh në kompanitë, veçanërisht në ato të mëdha, është shumë e vështirë të ndryshohet diçka. nëse mund të largoheni nga syslog, atëherë shkoni.

- Vlerësoni IOPS-in dhe fluksin e shkrimit.
- Kontrolloni sistemin tuaj të regjistrimit.
- Nëse ngarkesa e parashikuar është tepër e lartë, konsideroni mundësinë e kampionimit.

Ne kemi pg_stat_statements. Siç thashë, ai duhet të jetë patjetër. Dhe mund të marrim dhe të përshkruajmë çdo grup kërkesash në një skedar të veçantë. Pastaj mund të përdorim një veçori shumë të rehatshme në pgbench – mundësinë për të futur disa skedare përmes opsionit «-f».
Ai kupton shumë «-f». Dhe mund të themi me ndihmën e «@» në fund, se cila është përqindja për secilin skedar. Pra, mund të themi se ky do të ekzekutohet në 10% të rasteve, ndërsa ky në 20%. Dhe kjo do të na afrojë më afër asaj që shohim në prodhim.

Si do të kuptojmë se çfarë ka në prodhim? Cila është përqindja dhe çfarë? Këtu pak dalim nga tema. Kemi edhe një produkt tjetër . Gjithashtu një bazë në Open Source. Dhe ne tani po e zhvillojmë me përkushtim.
Ai lindi për disa arsye të tjera. Për shkak të faktit që monitorimi është i pamjaftueshëm. Pra, ju erdhni, shikoni bazën, shikoni problemet që ka. Dhe, në përgjithësi, ju bëni një kontrolle shëndeti. Nëse jeni një DBA me përvojë, ju bëni një kontroll shëndeti. Shikoni përdorimin e indekseve, etj. Nëse keni OKmeter, atëherë shkëlqyer. Ky është një monitorim fantastik për Postgres. OKmeter.io – ju lutemi, installoni atë, gjithçka është bërë shumë mirë atje. Ai është me pagesë.
Nëse nuk e keni, zakonisht nuk keni shumë. Në monitorim zakonisht kemi CPU, IO dhe këtë me kusht, dhe asgjë më shumë. Por na nevojitet më shumë. Na nevojitet të shohim si funksionon avtokorrigjimi, si funksionon pikënisja, në io duhet të ndahen pikënisja nga bgwriter dhe nga backend-et etj.
Problemi është se kur ndihmon një kompani të madhe, ata nuk mund të implementojnë diçka shpejt. Nuk mund të blejnë shpejt OKmeter-in. Mbase do ta blejnë pas gjashtë muajsh. Nuk mund të instalohet ndonjë paketë shpejt.
Na kemi erdhi ideja se na nevojitet një mjet i veçantë, i cili nuk kërkon ndonjë instalim, pra nuk keni nevojë të instaloni asgjë në prodhim. E vendosni në laptopin tuaj, ose në serverin e vëzhgimit, nga ku do ta lanconi. Dhe ai do të analizojë shumë gjëra: sistemin operativ, sistemin e skedarëve, dhe vetë Postgres, duke bërë disa kërkesa të lehta, të cilat mund t'i dërgoni direkt në prodhim dhe asgjë nuk do të dështojë.
Ne e quajtam atë Postgres-checkup. Nëse flasim në terma mjekësorë, kjo është një kontroll i rregullt i shëndetit. Nëse e shohim nga perspektiva automobilistike, kjo është si një kontroll teknik. Ju bëni kontrollin teknik për makinën tuaj çdo gjashtë muaj apo një herë në vit, në varësi të markës. Po, a bëni kontroll teknik për bazën tuaj? Kjo është, a bëni kërkime të thella rregullisht? Kjo është e nevojshme. Nëse bëni backup, atëherë bëni edhe një kontroll, kjo është po aq e rëndësishme.
Dhe ne kemi një mjet të tillë. Ai ka filluar të zhvillohet aktivisht vetëm për tre muaj. Ai është ende i ri, por ka shumë funksionalitete.

Mblidhni grupet më "të influencueshme" të kërkesave - raporti K003 në Postgres-checkup.
Dhe aty ka një grup raportesh K. Një grup raportesh të tillë. Tani ka tre raporte. Dhe ka një raport të tillë K003. Aty është maja nga pg_stat_statements, e renditur sipas total_time.
Kur ne rendisim sipas total_time grupet e kërkesave, ne shohim një grup në krye, i cili ngarkon sistemin tonë më së shumti, pra konsumon më shumë burime. Pse e quaj grupet e kërkesave? Sepse ne e kemi hequr parametrin. Këto nuk janë më kërkesa, por grupe kërkesash, pra ato janë të abastraktuara.
Dhe nëse ne do të optimizojmë nga lart poshtë, do t'i lehtësojmë burimet tona dhe do ta shtyjmë momentin kur na duhen përmirësime. Ky është një mënyrë e shkëlqyer për të kursyer para.
Mund të mos jetë mënyra më e mirë për të kujdesur për përdoruesit, sepse ndoshta ne nuk i shohim rastet e rralla, por shumë të bezdisshme, kur dikush pret 15 sekonda. Në total ato janë aq të rralla sa që ne nuk i shohim, por ne jemi duke u marrë me burimet.

Çfarë ndodhi në këtë tabelë? Bëmë dy snapshot-e. Postgres_checkup do t'ju bëjë diferencën për çdo metrikë: për total-time, calls, rows, shared_blks_read, etj. E gjitha, diferenca është llogaritur. Një problem i madh me pg_stat_statements është se ai nuk mban mend kur u resetua. Nëse pg_stat_database mban mend, pg_stat_statements nuk mban mend. Ju shihni atje numrin 1,000,000, por nuk e dimë se nga e kemi llogaritur.
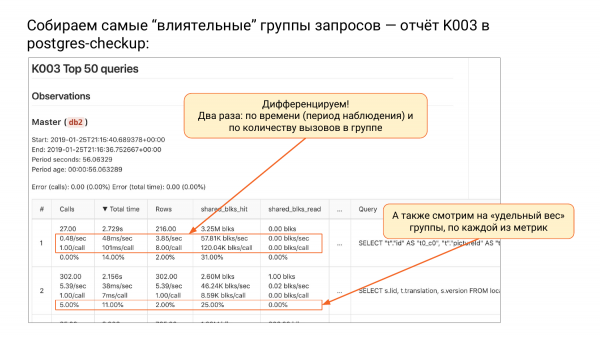
Por këtu ne e dimë, këtu kemi dy snapshot-e. Ne e dimë që diferenca ka qenë në këtë rast 56 sekonda. Një interval shumë i vogël. E renditëm sipas total_time. Dhe më pas mund të diferencojmë, pra ne i ndajmë të gjitha metrikat sipas kohës së gjatë. Nëse ne e ndajmë secilën metrikë me kohën e gjatë, do të kemi numrin e thirrjeve për sekondë.
Më pas total_time për sekondë – kjo është metrika ime e preferuar. Ajo matet në sekonda, në sekondë, pra sa sekonda iu desh sistemit tonë për të ekzekutuar këtë grup kërkesash në sekondë. Nëse ju shihni atje më shumë se një sekondë në sekondë, kjo do të thotë se ju kishit nevojë për më shumë se një bërthamë. Kjo është një metrikë shumë e mirë. Ju mund të kuptoni se ky person, për shembull, ka nevojë për të paktën tre bërthama.
Kjo është noviteti ynë, nuk kam parë asnjëherë diçka të tillë. Vëreni – kjo është diçka shumë e thjeshtë – sekonda në sekondë. N sometimes, kur CPU është 100 %, ju keni gjysmë ore në sekondë, pra ju keni kaluar gjysmë ore vetëm me këto kërkesa.
Më pas shohim rreshta në sekondë. Ne e dimë se sa rreshta janë kthyer në sekondë.
Dhe më pas është gjithashtu diçka interesante. Sa shared_buffers kemi lexuar në sekondë nga shared_buffers. Goditjet tashmë ishin atje, ndërsa rreshtat i morëm nga memorieja e sistemit operativ, ose nga disku. Opcioni i parë është i shpejtë, ndërsa i dyti, ndoshta është i shpejtë, ndoshta jo, varet nga situata.
Dhe mënyra e dytë e diferencimit – ne ndajmë numrin e kërkesave në këtë grup. Në kolonën e dytë gjithmonë do të keni një kërkesë për të ndarë me kërkesën. Dhe më pas është interesante – sa milisekonda ishte në këtë kërkesë. Ne e dimë se si sillet mesatarisht kjo kërkesë. 101 milisekonda nevojiteshin për çdo kërkesë. Kjo është një metrikë tradicionale që na nevojitet për kuptimin.
Sa rreshta ktheu çdo kërkesë në mesatare. Ne shohim se grupi kthen 8. Sa mesatarisht mori dhe lexoi nga cache. Ne shohim se gjithçka është e ruajtur në memory. Goditje të përgjithshme për grupin e parë.
Dhe substrati i katërt në çdo rresht – është përqindja e përgjithshme. Ne kemi thirrje. Le ta themi, në 1,000,000. Dhe ne mund të kuptojmë se çfarë kontributi sjell ky grup. Ne shohim se në këtë rast grupi i parë kontribuon më pak se 0,01%. Kjo është, ajo është kaq e ngadalshme sa që ne nuk e shohim në pamjen e përgjithshme. Ndërsa grupi i dytë – 5% nga thirrjet. Kjo është, 5% e të gjitha thirrjeve janë nga grupi i dytë.
Është gjithashtu interesante për total_time. Për grupin e parë të kërkesave, harxhuam 14% të gjithë kohës së punës. Ndërsa për të dytin – 11% etj.
Nuk do të hyj në detaje, por aty ka nuanca. Ne nxjerrim një gabim në sipërfaqe, sepse kur krahasojmë, snapshotet mund të lëkunden, dmth disa kërkesa mund të humbasin dhe në të dytin nuk mund të jenë më të pranishme, ndërsa disa mund të shfaqen të reja. Dhe aty ne llogarisim gabimin. Nëse shihni 0, atëherë është mirë. Nuk ka gabime. Nëse treguesi i gabimeve është deri në 20%, është OK.

Më pas kthehemi në temën tonë. Ne duhet të konceptojmë workload. Shkojmë nga lart poshtë derisa të mbledhim 80% ose 90%. Zakonisht kjo është 10-20 grupe. Dhe bëmë skedarët për pgbench. Atje përdorim random. Ndonjëherë, për fat të keq, kjo nuk funksionon. Dhe në Postgres 12 do të ketë më shumë mundësi për të përdorur këtë qasje.
Më pas kështu ne mbledhim 80-90% në total_time. Çfarë të vendosim më pas pas «@»? Ne shohim thirrjet, shohim sa përqindje dhe kuptojmë se këtu duhet të kemi kaq përqindje. Nga këto përqindje ne mund të kuptojmë se si të balancojmë secilin nga skedarët. Pas kësaj ne përdorim pgbench dhe fillojmë të punojmë.
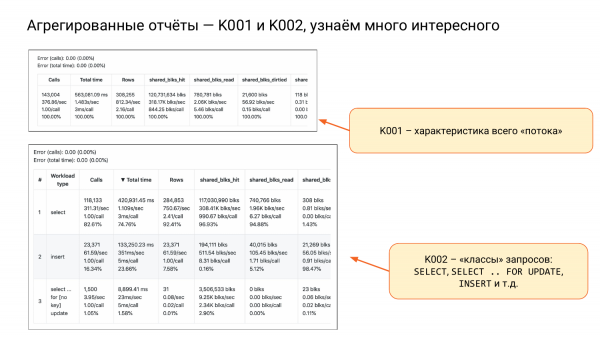
Ka gjithashtu K001 dhe K002.
K001 – është një varg i madh me katër nënvargje. Kjo është karakteristika e gjithë ngarkesës sonë. Shihni kolonën e dytë dhe nënvargun e dytë. Ne shohim se rreth një sekond në sekondë, dmth nëse do të ketë dy bërthama, do të jetë mirë. Do të ketë rreth 75% ngarkesë. Dhe kështu do të funksionojë. Nëse kemi 10 bërthama, do të jemi plotësisht të qetë. Kështu mund të vlerësojmë burimet.
K002 – këto i quaj klasat e kërkesave, dmth SELECT, INSERT, UPDATE, DELETE. Dhe veçmas SELECT FOR UPDATE, sepse ai bllokon.
Dhe këtu mund të përfundojmë se SELECT të zakonshmet lexuese – 82% e të gjitha thirrjeve, por në të njëjtën kohë – 74% në total_time. Pra, ato thirren shpesh, por konsumojnë më pak burime.
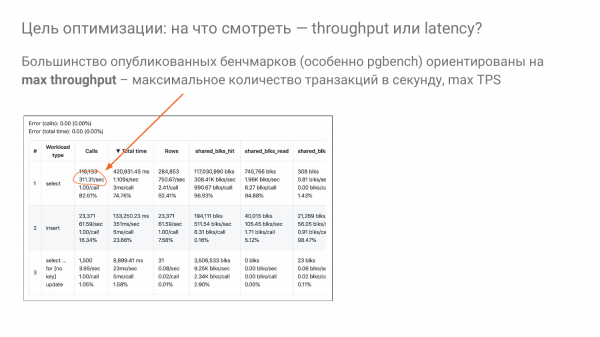
Dhe kthehemi në pyetjen: «Si të përshtatim saktësisht shared_buffers?». Vërej që shumica e benchmarking-ve janë ndërtuar mbi idenë – le të shohim se cili do të jetë throughput, dmth cili do të jetë kapaciteti. Ajo zakonisht matet në TPS ose QPS.
Dhe ne mundohemi të nxjerrim sa më shumë transaksione në sekondë nga makina me parametrat e tuningut. Këtu saktësisht 311 në sekondë për select.

Por askush nuk shkon në punë dhe për të rikthyer shtëpinë me makinë me shpejtësi maksimale. Kjo është e budallallëk. Ashtu është dhe me bazat e të dhënave. Ne nuk duhet të ecim me shpejtësi maksimale, askush nuk e bën këtë. Askush nuk jeton në production që ka 100% CPU. Megjithatë, ndoshta dikush jeton, por kjo nuk është e mirë.
Ideja është që zakonisht ne ecim në 20% të mundësive, preferohet të mos kalojmë 50%. Dhe ne mundohemi të optimizojmë kohën e përgjigjes për përdoruesit tanë, së pari. Pra, duhet të manovrojmë dorët tona për të pasur latency minimale në 20% shpejtësi, në parim. Kjo është një ide që ne gjithashtu mundohemi ta përdorim në eksperimentet tona.
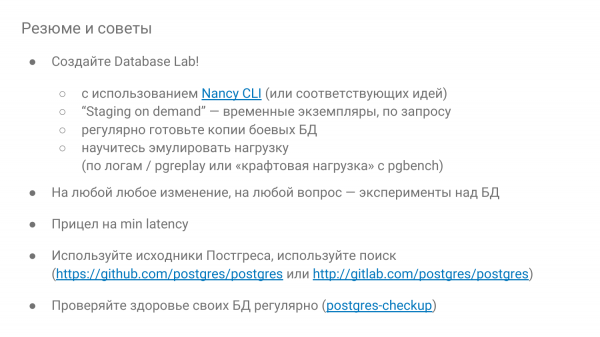
Dhe në përfundim, rekomandimet:
- Sigurisht, bëni Database Lab.
- Sa më shumë që të jetë e mundur, bëni on demand, që të krijohet për një periudhë – luani dhe pastaj hidhni. Nëse keni në oblake, kjo është e natyrshme, dmth, keni shumë standing.
- Jini kureshtarë. Dhe nëse diçka nuk shkon, kontrolloni me eksperimente se si sillet. Nancy mund të jetë përdorur për të mësuar veten, për të verifikuar si funksionon baza.
- Dhe qëndroni të fokusuar në kohën minimale të përgjigjes.
- Dhe mos kini frikë nga burimet e Postgres. Kur punoni me burimet, duhet të dini anglisht. Atje ka shumë komente, gjithçka është shpjeguar.
- Dhe kontrolloni shëndetin e bazës rregullisht, të paktën një herë në tre muaj me duar, ose Postgres-checkup.

Pyetje
Faleminderit shumë! Një gjë shumë interesante.
Dy gjëra.
Po, dy gjëra. Por unë nuk e kuptova plotësisht. Kur punojmë me Nancy, a mund të rregullojmë vetëm një parameter apo një grup të tërë?
Ne kemi parameterin e dëlta-konfigurimit. Mund të sjellësh sa më shumë të duash njëherësh. Por duhet të kuptosh, kur ndryshon shumë gjëra, mund të jesh në një përfundim të gabuar.
Po. Pse e pyeta? Sepse është e vështirë të kryesh eksperimente kur ke vetëm një parameter. E rregullon atë, e ke parë si punon. E vendos atë. Pastaj fillon me tjetrin.
Mund të rregullohen njëherësh, por varet nga situata, natyrisht. Por më mirë është të kontrollosh një ide. Dje na erdhi një ide. Kemi patur një situatë shumë të ngjashme. Kishim dy konfigurime. Dhe nuk mund të kuptonim pse kishte një diferencë të madhe. Dhe erdhi ideja që të përdorim dykahësinë, për të kuptuar në radhë dhe për të gjetur se çfarë është ndryshe. Mund të bëjmë menjëherë gjysmën e parametrave të njëjtë, pastaj një të katërtin, etj. Të gjitha fleksibel.
Dhe ka një pyetje tjetër. Projekti është i ri, në zhvillim. Dokumentacioni është tashmë i gatshëm, ka një përshkrim të detajuar?
E kam bërë lidhjen në përshkrimin e parametrave. Kjo është aty. Por ka shumë gjëra që akoma mungojnë. Po kërkoj njerëz të ngjashëm. I gjej kur kam paraqitje. Kjo është shumë e mrekullueshme. Disa tashmë po punojnë me mua, disa ndihmuan dhe bënë diçka. Dhe nëse jeni të interesuar për këtë temë, lutem jepni komentet tuaja – çfarë mungon.
Kur të realizojmë laboratorin, ndoshta do të kemi përgjigje. Do ta shohim. Faleminderit!
Përshëndetje! Faleminderit për prezantimin! Vura re që ka mbështetje për Amazon. A është planifikuar mbështetje për GSP?
Një pyetje e mirë. Kemi filluar punën. Dhe për momentin e kemi pezulluar, sepse duam të kursejmë. Pra, ka mbështetje përmes run on localhost. Ju mund të krijoni vetë një instance dhe të punoni lokal. Për më tepër, ne ashtu e bëjmë. Në Getlab e bëj kështu, atje në GSP. Por për të realizuar një orkestrim të tillë nuk shohim ende sens, sepse Google nuk ka oferta të lira. Aty ka ??? instances, por ato kanë kufizime. Së pari, ata gjithmonë kanë vetëm 70% zbritje dhe nuk mund të luani me çmimin. Ne rrisim çmimin e spoteve me 5-10% për të ulur probabilitetin që t'ju nxjerrin jashtë. Domethënë, me spote ju kurseni, por mund t'ju marrin në çdo moment. Nëse vendosni një çmim pak më të lartë se të tjerët, mund t'ju vrasin më vonë. Google ka një specifik tjetër krejtësisht. Dhe ka një kufizim që nuk është i mirë – ata jetojnë vetëm 24 orë. E ndonjëherë ne duam të bëjmë eksperimente për 5 ditë. Por me spote kjo mund të bëhet, spote ndonjëherë jetojnë për muaj.
Përshëndetje! Faleminderit për prezantimin! Përmendët për checkup. Si llogaritni gabimet stat_statements?
Pyetje shumë e mirë. Mund të tregoj dhe shpjegoj shumë detajisht. Në shkurt – ne shikojmë si evoluon grupi i kërkesave: sa u shkëput dhe sa u shfaqen të reja. Pastaj shikojmë dy metri: total_time dhe calls, prandaj ka dy gabime. Shikojmë gjithashtu, cila është kontributi i grupeve të shkëputura. Ka dy nëngrupe: të larguara dhe të ardhura. Shikojmë, cila është kontributi i tyre në përgjithësinë.
A nuk keni frikë se ajo mund të rrotullohet dy-tre herë gjatë kohës midis snapshot-ve?
Domethënë, ata u regjistruan përsëri ose si?
Për shembull, kjo kërkesë është shtypur një herë, pastaj erdhi përsëri dhe u shtyp, pastaj përsëri erdhi dhe u shtyp. Dhe ju keni bërë disa llogaritje, dhe ku janë të gjithë ata?
Pyetje e mirë, duhet të shohim.
Unë kam bërë një gjë të ngjashme. Sigurisht më e thjeshtë, e kam bërë vetëm. Por më duhej të shlyej, të bëj një reset stat_statements dhe të orientohem në momentin e snapshot, që atje të ketë një pjesë përkatëse, që përsëri nuk është arritur në kufirin e maksimalit sa stat_statements mund të grumbullohen. Dhe unë orientohem, që me gjasë nuk është zhdukur asgjë.
Po-po.
Por si mund ta bësh ndryshe në mënyrë të besueshme, nuk e kuptoj.
Më vjen keq, nuk e mbaj mend saktësisht – a përdorim tekstin e kërkesës apo queryid me pg_stat_statements dhe në atë orientohemi. Nëse orientohemi në queryid, atëherë teorikisht po krahasonim gjëra të krahasueshme.
Jo, ai mund të shtypet disa herë midis snapshot-ve dhe të vijë përsëri.
Me këtë id?
Po.
Ne do ta studiojmë këtë. Pyetje e mirë. Duhet ta studiojmë. Por për momentin, ajo që shohim është ose shkruhet 0...
Sigurisht, ky është një rast i rrallë, por jam tronditur kur mësova se stat_statements mund të shtypet.
Në Pg_stat_statements mund të ketë shumë gjëra. Ndeshim se nëse keni track_utility = e aktivizuar, atëherë kurset gjithashtu regjistrohen.
Po, sigurisht.
Dhe nëse keni java hibernate, që është rastësor, atëherë fillon të bllokohet tabela e hasheve. Dhe sapo të fikni një aplikacion shumë të ngarkuar, ju mbeteni me 50-100 grupe. Dhe aty gjithçka bëhet më shumë-më pak e stabilizuar. Një nga mënyrat për të luftuar këtë është të rrisni pg_stat_statements.max.
Po, por duhet të dini, sa. Dhe duhet të mbani ndjekje. Unë e bëj kështu. Domethënë, unë kam pg_stat_statements.max. Dhe shikoj që në momentin e snapshot nuk kam arritur më shumë se 70%. Mirë, domethënë nuk kemi humbur asgjë. Bëjmë reset. Dhe grumbullojmë përsëri. Nëse në snapshot-in tjetër është nën 70, atëherë me gjasë përsëri nuk kemi humbur asgjë.
Po. Në mënyrë të paracaktuar tani janë 5,000. Dhe shumë njerëz mjaftojnë me këtë.
Zakonisht – po.
Video:

P.S. Nga vetja do të shtoja se nëse në Postgres ka të dhëna konfidenciale dhe nuk duhet të hyjnë në ambientin e testimit, atëherë mund të përdorni . Schemi është përafërsisht si vijon:
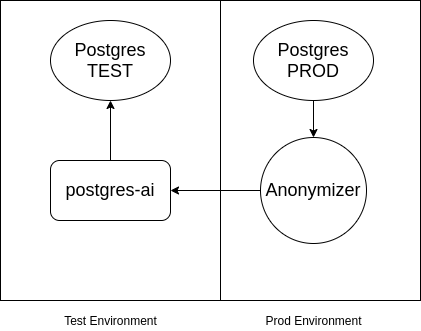
Burimi: habr.com
