


Ne jemi në Badoo duke monitoruar vazhdimisht teknologjitë më të reja dhe po vlerësojmë nëse ia vlen t'i përdorim ato në sistemin tonë. Një nga këto kërkime që dëshirojmë të ndajnë me komunitetin është për Loki — një sistem për agregimin e log-eve.
Loki është një zgjidhje për ruajtjen dhe shikimin e log-eve, gjithashtu ky stak ofron një sistem fleksibël për analizimin dhe dërgimin e të dhënave në Prometheus. Në maj doli një përmirësim i ri, i cili po promovohet aktivisht nga krijuesit. Na ka interesuar se çfarë di të bëjë Loki, cilat mundësi ofron dhe deri në çfarë shkalle mund të jetë një alternativë për ELK — stakun që po përdorim tani.
Çfarë është Loki
Grafana Loki është një grup komponentësh për një sistem të plotë të punës me log-e. Ndryshe nga sistemet e tjera të ngjashme, Loki bazohet në idenë që të indeksohen vetëm metadatet e log-eve — etiketat (ashtu si në Prometheus), ndërsa log-et vetë kompresohen afër në blloqe të veçanta.
,
Para se kalojmë në përshkrimin e asaj që mund të bëjmë me Loki, dua të shpjegoj se çfarë nënkuptohet me "ideja për të indeksuar vetëm metadatën". Le të krahasojmë qasjen e Loki-t me qasjen e indeksimit në zgjidhjet tradicionale, si Elasticsearch, duke marrë si shembull një rresht nga log-et nginx:
172.19.0.4 - - [01/Jun/2020:12:05:03 +0000] "GET /purchase?user_id=75146478&item_id=34234 HTTP/1.1" 500 8102 "-" "Stub_Bot/3.0" "0.001"Sistemet tradicionale analizojnë rreshtin në tërësi, duke përfshirë fushat me një numër të madh vlerash unike user_id dhe item_id, dhe ruajnë gjithçka në indekse të mëdha. Avantazhi i kësaj qasje është se mund të kryhen kërkesa të komplikuara shpejt, pasi pothuajse të dhënat janë në indeks. Por për këtë duhet të paguhet çmimi që indeksi bëhet i madh, gjë që rezulton në kërkesa për memorie. Në përfundim, indeksi i plotë i log-eve është krahasues në madhësinë me vetë log-et. Për të kërkuar shpejt në të, indeksi duhet të ngarkohet në memorie. Dhe sa më shumë log-e që kemi, aq më shpejt rritet indeksi dhe aq më shumë memorie konsumon.
Qasja Loki kërkon që të nxirren vetëm të dhënat e nevojshme nga vargu, numri i të cilave është i vogël. Në këtë mënyrë, ne marrim një indeks të vogël dhe mund të kërkojmë të dhënat duke filtruar ato sipas kohës dhe fushave të indeksuara, dhe më pas skanojmë të mbeturat me shprehje të rregullta ose kërkimin e nënfjalëve. Procesi duket se nuk është më i shpejti, por Loki e ndan kërkesën në disa pjesë dhe i ekzekuton ato paralelisht, duke përpunuar një sasi të madhe të dhënash në një kohë të shkurtër. Numri i shard-eve dhe kërkesave paralel në to është i konfiguruar; kështu, sasia e të dhënave që mund të përpunohet në një njësisë kohe është në varësi lineare nga numri i burimeve të ofruara.
Ky kompromis midis një indeksi të shpejtë të madh dhe një indeksi të vogël me përmasë të plotë paralele lejon Loki të kontrollojë kostot e sistemit. Ai mund të konfigurohet dhe zgjerrohet në mënyrë fleksibile sipas nevojave.
Staku Loki përbëhet nga tri komponentë: Promtail, Loki dhe Grafana. Promtail mbledh logjet, i përpunon dhe i dërgon në Loki. Loki i ruan ato. Grafana mund të kërkojë të dhëna nga Loki dhe t'i shfaqë ato. Në përgjithësi, Loki nuk përdoret vetëm për ruajtjen e logjeve dhe kërkimin në to. I gjithë staku ofron mundësi të mëdha për përpunimin dhe analizën e të dhënave që vijnë, duke përdorur mënyrën e Prometheus.
Përshkrimi i procesit të instalimit mund të gjendet .
Kërkoni në loge
Kërkimi në logje mund të bëhet në një ndërfaqe speciale Grafana — Explorer. Për kërkesat përdoret gjuha LogQL, e cila është shumë e ngjashme me PromQL, e cila përdoret në Prometheus. Në parim, mund të merren parasysh si një grep i shpërndarë.
Ndërfaqja e kërkimit duket kështu:
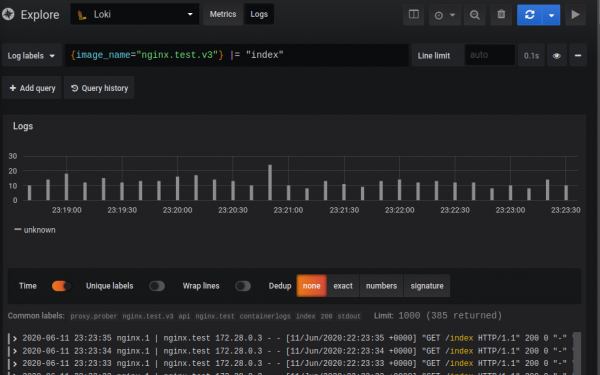
Kërkesa përbëhet nga dy pjesë: selector dhe filter. Selector është kërkimi në metadatë të indeksuara (etiketat) që janë caktuar logjeve, ndërsa filter është stringu i kërkimit ose regex-i me ndihmën e të cilit filtrohen regjistrimet e përcaktuara nga selector-i. Në shembullin e dhënë: Në kllapa janë selector-i, gjithçka që ndodhet pas — është filter.
{image_name="nginx.promtail.test"} |= "index"Për shkak të parimit të punës së Loki, nuk është e mundur të bëhen kërkesa pa selector, por etiketat mund të bëhen sa më të përgjithshme të jetë e mundur.
Seletori është vlera çelës-vlerë në kllapa të kallëzuara. Mund të kombinoni selektorët dhe të vendosni kushte të ndryshme kërkimi, duke përdorur operatorë =, != ose shprehje të rregullta:
{instance=~"kafka-[23]",name!="kafka-dev"}
// Do të gjejë logët me etiketën instance, që kanë vlerën kafka-2, kafka-3, dhe do të përjashtojë dev Filtri është një tekst ose regex, i cili do të filtrojë të dhënat e marra nga selektori.
Ekziston mundësia e marrjes së grafikeve ad-hoc për të dhënat e marra në mënyrën metrics. Për shembull, mund të mësoni frekuencën e shfaqjes në logët nginx të një regjistrimi që përmban vargun index:
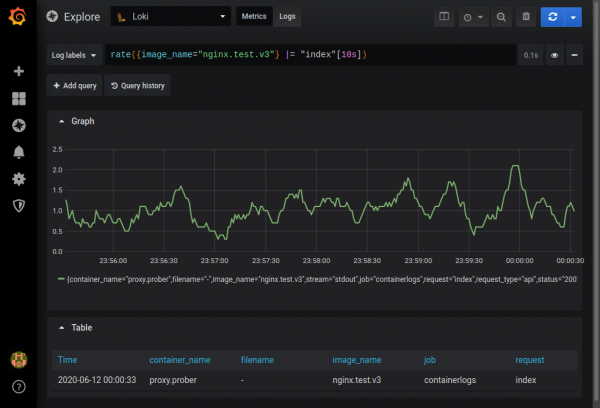
Përshkrimi i plotë i mundësive mund të gjendet në dokumentacion. .
Parseimi i logëve
Ekzistojnë disa mënyra për të mbledhur logët:
- Me ndihmën e Promtail, komponentit standard të stack-ut për mbledhjen e logëve.
- Direkt nga kontejneri docker me anë të
- Përdorni Fluentd ose Fluent Bit, të cilat dërgojnë të dhëna në Loki. Në kundërshtim me Promtail, ato kanë parser të gatshëm praktikisht për çdo lloj logu dhe munden gjithashtu të përballen me logët shumëlinjëshe.
Zakonisht për parse përdoret Promtail. Ai bën tri gjëra:
- Gjen burimet e të dhënave.
- I ngjiti atyre etiketa.
- Dërgon të dhënat në Loki.
Aktualisht, Promtail mund të lexojë log-ët nga skedarët lokalë dhe nga systemd journal. Ai duhet të instalohet në çdo makinë nga e cila mblidhen log-ët.
Ekziston integrimi me Kubernetes: Promtail automatikisht përmes Kubernetes REST API merr informacion për gjendjen e klasterit dhe mbledh log-ët nga ndeshja, shërbimi ose pod-i, duke i shtuar menjëherë etiketat bazuar në metadata nga Kubernetes (emri i pod-it, emri i skedarit etj.).
Gjithashtu, mund të shtoni etiketat në bazë të të dhënave nga log-u përmes Pipeline. Pipeline i Promtail mund të përbëhet nga katër lloje fazash. Më shumë detaje - në , këtu do të theksoj disa nuanca.
- Fazat e analizës. Kjo është faza RegEx dhe JSON. Në këtë fazë ne nxjerrim të dhëna nga log-ët në atë që quhet extracted map. Mund të nxjerrim nga JSON, duke kopjuar thjesht fushat që na duhen në extracted map, ose përmes shprehjeve të rregullta (RegEx), ku në extracted map përputhen grupet e emërtuara. Mapa e nxjerrë është një depo të dhënash në formatin key-value, ku key është emri i fushës dhe value është vlera e saj nga log-ët.
- Fazat e transformimit. Kjo fazë ka dy mundësi: transform, ku ne përcaktojmë rregullat e transformimit, dhe source — burimi i të dhënave për transformim nga extracted map. Nëse në extracted map nuk ka një fushë të tillë, ajo do të krijohet. Në këtë mënyrë, mund të krijohen etiketa që nuk bazohen në extracted map. Në këtë fazë, mund të manipulojmë të dhënat në extracted map, duke përdorur një mjaft të fuqishëm . Për më tepër, duhet të mbani mend se extracted map ngarkohet plotësisht gjatë analizimit, që jep mundësinë, për shembull, të kontrolloni vlerën në të: “{{if .tag}vlera e tag ekziston{end}}”. Template mbështet kushte, cikle dhe disa funksione për strings, si Replace dhe Trim.
- Fazat e veprimit. Në këtë fazë mund të bëjmë diçka me të nxjerra:
- Krijo një etiketë nga të dhënat e nxjerra, që do të indeksohet nga Loki.
- Ndrysho apo vendos kohën e ngjarjes nga logu.
- Ndrysho të dhënat (tekstin e logut), që do të shkojnë te Loki.
- Krijo metrikat.
- Fazat e filtrimit. Fazë match, në të cilën mund të dërgojmë në /dev/null regjistrimet që nuk na nevojiten, ose t'i drejtojmë ato për përpunim të mëtejshëm.
Do të tregoj me shembuj të përpunimit të logeve të zakonshme nginx, se si mund të analizojmë loget me ndihmën e Promtail.
Për testin, do të përdorim një pamje të modifikuar të nginx-proxy jwilder/nginx-proxy:alpine dhe një demon të vogël, i cili di të pyesë veten me HTTP. Demonit i janë caktuar disa endpoint-e, të cilat ai mund të japë përgjigje me madhësi të ndryshme, me status të ndryshëm HTTP dhe me vonesa të ndryshme.
Do t'i mbledhim loget nga kontejnerët docker, të cilët mund të gjenden në rrugën /var/lib/docker/containers//-json.log
Në docker-compose.yml konfigurojmë Promtail dhe tregon rrugën e konfigurimit:
promtail:
image: grafana/promtail:1.4.1
// ...
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- promtail-data:/var/lib/promtail/positions
- ${PWD}/promtail/docker.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
// ...
Shtojmë në promtail.yml rrugën për loget (në konfigurim ka një opsion "docker", i cili bën të njëjtën gjë me një rresht, por kjo nuk do të ishte aq e qartë):
scrape_configs:
- job_name: containers
static_configs:
labels:
job: containerlogs
__path__: /var/lib/docker/containers/*/*log # për linux vetëmKur të aktivizojmë të tillë konfigurim, loget do të arrijnë në Loki nga të gjithë kontejnerët. Për ta shmangur këtë, ndryshojmë cilësimet e nginx për provë në docker-compose.yml — shtojmë logimin e fushës tag:
proxy:
image: nginx.test.v3
//…
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}"Përditësojmë promtail.yml dhe konfiguroni Pipeline. Në hyrje marrim logjet e këtij lloji:
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] \"GET \/api\/index HTTP\/1.1\" 200 0 \"-\" \"Stub_Bot\/0.1\" \"0.096\"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.66740443Z"}
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] \"GET \/200 HTTP\/1.1\" 200 0 \"-\" \"Stub_Bot\/0.1\" \"0.000\"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.702925272Z"}Faza e Pipeline:
- json:
shprehjet:
stream: stream
attrs: attrs
tag: attrs.tagNxjerrim nga JSON-i hyrës fushat stream, attrs, attrs.tag (nëse ekzistojnë) dhe i vendosim ato në hartën e nxjerrë.
- regex:
shprehja: ^(?P<image_name>([^|]+))|(?P<container_name>([^|]+))$
burimi: "tag"Nëse arritëm të vendosim fushën tag në hartën e nxjerrë, atëherë me ndihmën e regex-it nxjerrim emrat e imazhit dhe kontejnerit.
- etiketa:
image_name:
container_name:Caktojmë etiketat. Nëse në të dhënat e nxjerra gjejmë çelësat image_name dhe container_name, atëherë vlerat e tyre do t'u caktohen etiketave përkatëse.
- përputhje:
selektori: '{job="docker",container_name="",image_name=""}'
veprimi: dropHeqim të gjitha logjet që nuk kanë gjetur etiketat e vendosur image_name dhe container_name.
- përputhje:
selektori: '{image_name="nginx.promtail.test"}'
fazat:
- json:
shprehjet:
rreshti: logPër të gjitha log-et që kanë image_name të barabartë me nginx.promtail.test, kemi nxjerrë nga log-u burimor fushën log dhe e kemi vendosur në hartën e nxjerrjes me çelësin row.
- regex:
# shtyp ngjyrat e forego-ut
shprehja: .+nginx.+|.+[0m(?P[a-z_.-]+) +(?P.+)
burimi: logrowPastrojmë të dhënat hyrëse duke përdorur shprehje të rregullta dhe nxjerrim nginx virtual host-in dhe rreshtin e log-ut nginx.
- regex:
burimi: nginxlog
shprehja: ^(?P[w.]+) - (?P[^ ]*) [(?P[^ ]+).*] "(?P[^ ]*) (?P[^ ]*) (?P[^ ]*)" (?P[d]+) (?P[d]+) "(?P[^"]*)" "(?P[^"]*)"( "(?P[d.]+)")?Po e parsim log-un nginx me shprehje të rregullta.
- regex:
burimi: request_url
shprehja: ^.+.(?Pjpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|pdf|txt|tar|wav|bmp|rtf|js|flv|swf|html|htm)$
- regex:
burimi: request_url
shprehja: ^/photo/(?P[^/?.]+).*$
- regex:
burimi: request_url
shprehja: ^/api/(?P[^/?.]+).*$Shkruajmë request_url. Me ndihmën e regex-it, përcaktojmë qëllimin e kërkesës: për statikën, për fotot, për API-në dhe vendosim në hartën e nxjerrjes çelësin përkatës.
- template:
burimi: request_type
template: "{{if .photo}}photo{{else if .static_type}}static{{else if .api_request}}api{{else}}other{{end}}"Me anë të operatorëve kushtorë në Template kontrollojmë fushat e instaluara në hartën e nxjerrë dhe vendosim për fushën request_type vlerat e nevojshme: photo, static, API. Caktojmë other, nëse nuk arritëm. Tani request_type përmban llojin e kërkesës.
- etiketat:
api_request:
virtual_host:
request_type:
status:Vendosim etiketat api_request, virtual_host, request_type dhe statusin (statusi HTTP) në bazë të asaj që arritëm të vendosim në hartën e nxjerrë.
- dalja:
burimi: nginx_log_rowNdryshojmë daljen. Tani në Loki shkon logu nginx i pastruar nga harta e nxjerrë.
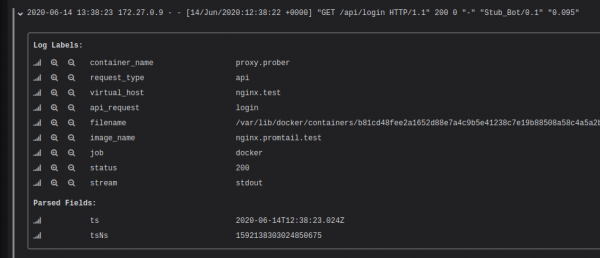
Pas aktivizimit të konfigurimit të dhënë, mund të shihni që çdo regjistrim i është caktuar etiketa në bazë të të dhënave nga logu.
Duhet të kemi parasysh se nxjerrja e etiketave me shumë vlera (cardinality) mund të ngadalësojë ndjeshëm funksionimin e Loki. Pra, nuk është e rekomandueshme të vendosni në indeks, për shembull, user_id. Më shumë rreth kësaj lexoni në artikullin “”. Por kjo nuk do të thotë se nuk mund të kërkohet për user_id pa indekse. Duhet të përdoren filtrat gjatë kërkimit (“grep” mbi të dhënat), ndërsa indeksi shërben si identifikues i rrjedhës.
Vizualizimi i logëve
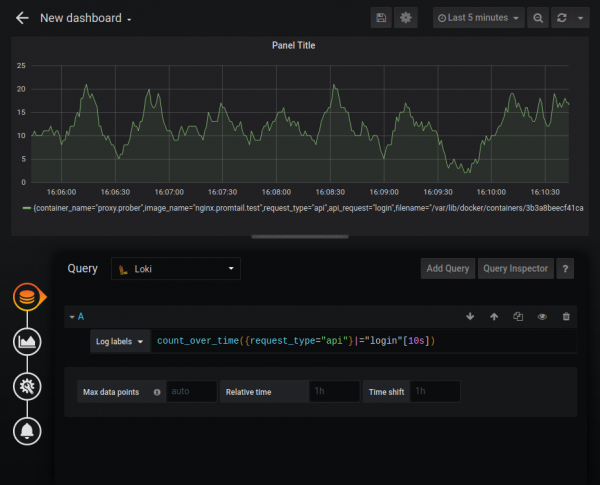
Loki mund të shërbejë si burim të dhënash për grafikat Grafana, duke përdorur LogQL. Janë të mbështetura funksionet e mëposhtme:
- rate — numri i regjistrimeve për sekondë;
- count over time — numri i regjistrimeve brenda një periudhe të caktuar.
Ekzistojnë gjithashtu funksione agreguese si Sum, Avg dhe të tjera. Mund të krijoni grafika mjaft të ndërlikuara, për shembull, grafika e numrit të gabimeve HTTP:
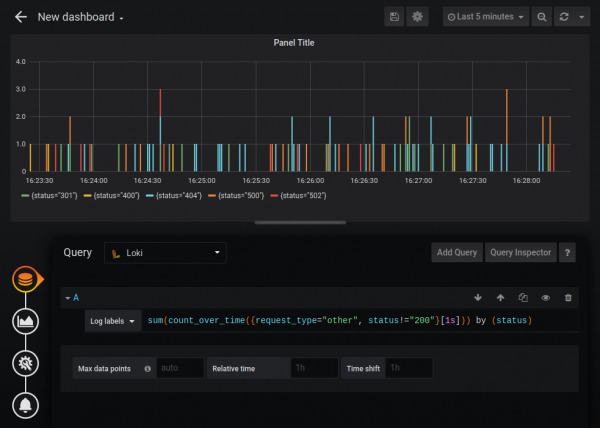
Burimi standard i të dhënave Loki është pak i kufizuar në funksionalitet krahasuar me burimin e të dhënave Prometheus (për shembull, nuk mund të ndryshoni legjendën), por Loki mund të lidhet si një burim me llojin Prometheus. Nuk jam i sigurt nëse kjo është një sjellje e dokumentuar, por, sipas përgjigjes së zhvilluesve "" është plotësisht e ligjshme, dhe Loki është plotësisht i përputhshëm me PromQL.
Shtojmë Loki si burim të dhënash me llojin Prometheus dhe e shkruajmë URL-në /loki:

Dhe mund të krijojmë grafika, ashtu si në rastin kur do të punonim me metrika nga Prometheus:
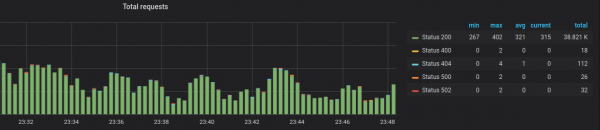
Mendoj se ndryshimi në funksionalitet është i përkohshëm dhe zhvilluesit do ta korrigjojnë këtë në të ardhmen.
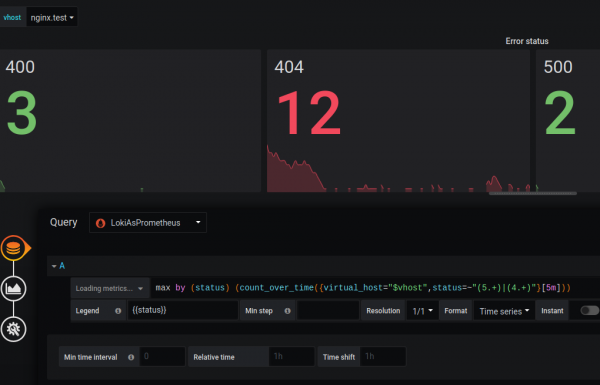
Metricat
Në Loki është e mundur të nxirren metrika numerike nga logët dhe t'i dërgohen në Prometheus. Për shembull, në logun nginx ndodhet numri i byte-ve për përgjigje, si dhe, me një modifikim të caktuar të formatit standard të logut, koha në sekonda që kërkohet për përgjigje. Këto të dhëna mund të nxirren dhe të dërgohen në Prometheus.
Shtojmë një seksion tjetër në promtail.yml:
- match:
selector: '{request_type="api"}'
stages:
- metrics:
http_nginx_response_time:
type: Histogram
description: "koha e përgjigjes në ms"
source: response_time
config:
buckets: [0.010,0.050,0.100,0.200,0.500,1.0]
- match:
selector: '{request_type=~"static|photo"}'
stages:
- metrics:
http_nginx_response_bytes_sum:
type: Counter
description: "shuma e byte-ve të përgjigjes"
source: bytes_out
config:
action: add
http_nginx_response_bytes_count:
type: Counter
description: "numri i byte-ve të përgjigjes"
source: bytes_out
config:
action: incOpsioni lejon mundësinë për të caktuar dhe përditësuar metrikat në bazë të të dhënave nga mapa e nxjerrë. Këto metrika nuk dërgohen në Loki — ato shfaqen në Promtail /metrics endpoint. Prometheus duhet të konfigurohet në mënyrë që të marrë të dhënat e marra në këtë fazë. Në shembullin e dhënë për request_type="api" ne mbledhim një histogramë metrikë. Me këtë lloj metrikash është e lehtë të marrim percentilat. Për statikët dhe fotot mbledhim shumën e byte-ve dhe numrin e rreshtave, në të cilët kemi marrë byte, për të llogaritur vlerën mesatare.
Për më shumë detaje mbi metrikat, lexoni .
Hapim portin në Promtail:
promtail:
image: grafana/promtail:1.4.1
container_name: monitoring.promtail
expose:
- 9080
ports:
- "9080:9080"Sigurohemi që metrikat me prefixin promtail_custom të shfaqen:
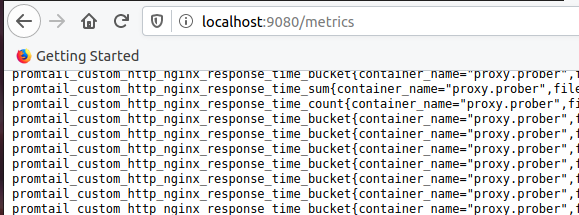
Konfigurojmë Prometheus. Shtojmë punën promtail:
- job_name: 'promtail'
scrape_interval: 10s
static_configs:
- targets: ['promtail:9080']Dhe vizatojmë grafikun:
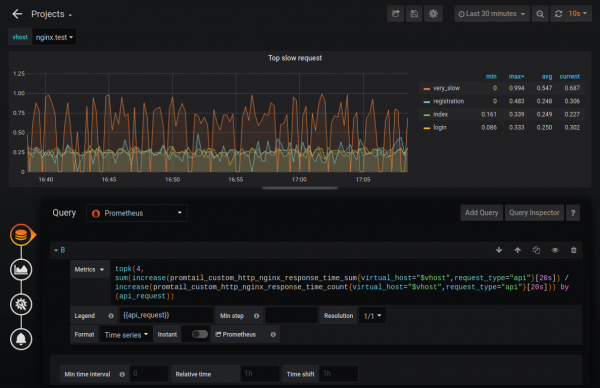
Kështu mund të mësojmë, për shembull, katër kërkesat më të ngadalta. Po ashtu, mbi këto metrika mund të organizojmë monitorimin.
Shkallëzimi
Loki mund të funksionojë në mënyrë të vetme (kodi i vetëm) ose në modalitetin e shardimit (modaliteti horizontal i shkallëzueshmërisë). Në rastin e dytë, ai mund të ruajë të dhënat në re, duke ruajtur chunks dhe indekset ndaras. Në versionin 1.5 është realizuar mundësia e ruajtjes në një vend, por për momentin nuk rekomandohet përdorimi i saj në prodhim.
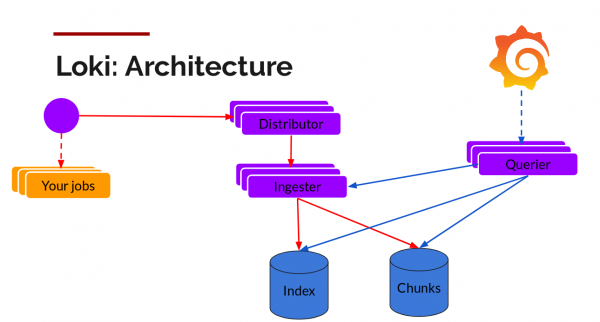
Chunks mund të ruhen në një ruajtje të përputhshme me S3, ndërsa indekset duhet të ruhen në baza të dhënash horizontalisht të shkallëzueshme: Cassandra, BigTable ose DynamoDB. Pjesët tjera të Loki — Distributors (për regjistrim) dhe Querier (për kërkesa) — janë pa gjendje dhe gjithashtu shkallëzohen horizontalisht.
Në konferencën DevOpsDays Vancouver 2019, një nga pjesëmarrësit, Callum Styan, tha se me Loki projekti i tij kishte petabytes logësh me një indeks më pak se 1% nga madhësia totale: “”.
Krahasimi i Loki dhe ELK
Madhësia e indeksit
Për testimin e madhësisë së indeksit të fituar, mora logët nga kontejneri nginx, për të cilin ishte konfiguruar Pipeline, i përmendur më lart. Skedari me logët përmbante 406 624 rreshta me një volum total prej 109 MB. Logët u gjeneruan për një orë, rreth 100 shënime në sekondë.
Shembuj të dy rreshtave nga logu:

Gjatë indeksimit në ELK, kjo dha një madhësi indeksi prej 30.3 MB:
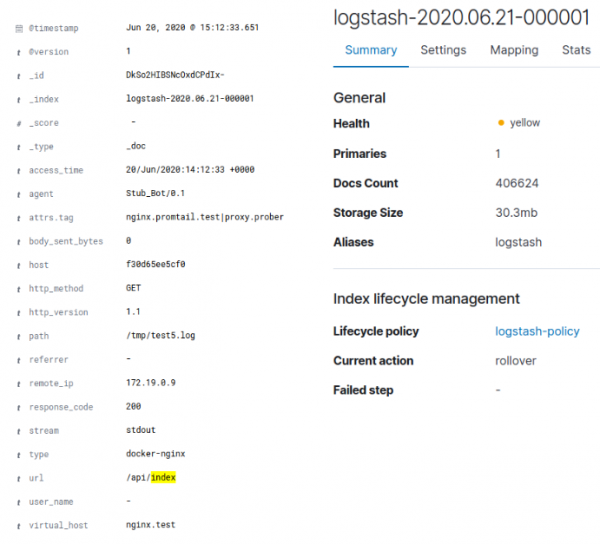
Në rastin e Loki, kjo dha rreth 128 Kb indeksi dhe rreth 3,8 Mb të dhënash në blloqe. Vlen të theksohet se logu ishte prodhuar në mënyrë artificiale dhe nuk kishte shumë larmishmëri të të dhënave. Kompresimi i thjeshtë gzip në logun origjinal të Docker-it me të dhëna jepte një kompresim prej 95,4%, dhe duke marrë parasysh se në Loki dërgohej vetëm logu i pastruar i nginx, kompresimi deri në 4 Mb është i shpjegueshëm. Numri total i vlerave unike për etiketat Loki ishte 35, që shpjegon madhësinë e vogël të indeksit. Për ELK, logu gjithashtu ishte pastruar. Pra, Loki e kompresoi të dhënat origjinale me 96%, ndërsa ELK me 70%.
Konsumi i memories
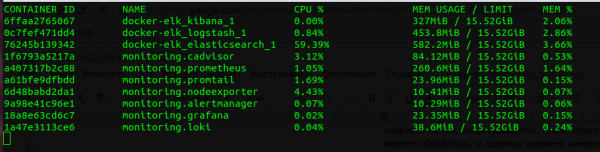
Nëse krahasojmë të gjithë stack-un e Prometheus dhe ELK, Loki "han" disa herë më pak. Është e qartë se shërbimi në Go konsumon më pak sesa shërbimi në Java, dhe krahasimi i madhësisë së JVM Heap të Elasticsearch me memorien e dedikuar për Loki është i pavend, por megjithatë vlen të theksohet se Loki përdor shumë më pak memorie. Avantazhi i tij në CPU nuk është aq i dukshëm, por gjithashtu është prezent.
Shpejtësia
Loki përpiqet të 'ha' logët më shpejt. Shpejtësia varet nga shumë faktorë — cila janë logët, sa komplekse janë formatet tona për parsing, rrjeti, disku etj. — por ajo është padyshim më e lartë se ELK (në testin tim, rreth dy herë). Kjo shpjegohet nga fakti se Loki shpenzon shumë më pak të dhëna për indeksim dhe, për pasojë, kalon më pak kohë në procesin e indeksimit. Megjithatë, për sa i përket shpejtësisë së kërkimit, situata është e kundërt: Loki ngadalëson dukshëm me të dhëna mbi disa gigabajt, ndryshe nga ELK, ku shpejtësia e kërkimit nuk varet nga madhësia e të dhënave.
Kërkoni në loge
Loki ndjeshëm i nënshtrohet ELK në kapacitetin e kërkimit të logëve. Grep me shprehje të rregullta është një gjë e fortë, por ai është më pak se një bazë të dhënash e rritur. Mungesa e kërkesave range, agregimi vetëm mbi etiketa, pamundësia për të kërkuar pa etiketa — të gjitha këto na kufizojnë në kërkimin e informacionit të interesit në Loki. Kjo nuk do të thotë se me ndihmën e Loki nuk mund të gjejmë asgjë, por përcakton fluksin e punës me logët, ku fillimisht identifikoni problemin në grafikat e Prometheus dhe pastaj, përmes këtyre etiketave, kërkoni për atë që ndodhi në logë.
Interfaci
Së pari, është e bukur (më falni, nuk mund të rezistoja). Grafana ka një ndërfaqe shumë të këndshme, por Kibana është shumë më funksionale.
Avantazhet dhe disavantazhet e Loki
Nga avantazhet, mund të përmendet se Loki integret me Prometheus, kështu që metrikat dhe alarmin i marrim gati nga fabrika. Është e përshtatshme për mbledhjen dhe ruajtjen e logeve me Kubernetes Pods, pasi ka zbulim shërbimi të trashëguar nga Prometheus dhe automatikisht ngjesh etiketa.
Nga disavantazhet - dokumentacioni i dobët. Disa gjëra, si për shembull karakteristikat dhe mundësitë e Promtail, i zbulova vetëm gjatë studimit të kodit, falë që është open-source. Një disavantazh tjetër janë mundësitë e dobëta të analizimit. Për shembull, Loki nuk është në gjendje të analizojë loge me shumë rreshta. Po ashtu, një nga disavantazhet është se Loki është një teknologji relativisht e re (lëshimi 1.0 ishte në nëntor 2019).
Përfundimi
Loki është një teknologji 100% e interesantë, e cila është e përshtatshme për projekte të vogla dhe të mesme, duke lejuar zgjidhjen e shumë problemeve që lidhen me aggregimin e logeve, kërkimin në loge, monitorimin dhe analizën e logeve.
Ne përdorim Loki në Badoo, sepse kemi një stack ELK që na përshtatet dhe që, për shumë vite, është mbushur me zgjidhje të ndryshme të personalizuara. Për ne, sfida është kërkimi në loge. Duke pasur gati 100 GB loge në ditë, është e rëndësishme të jemi në gjendje të gjejmë gjithçka, dhe pak më shumë, dhe ta bëjmë këtë shpejt. Për ndërtimin e grafikëve dhe monitorimin, ne përdorim zgjidhje të tjera të specializuara për ne dhe të integruara mes tyre. Stack-u Loki ka përfitime të dukshme, por nuk do të na japë më shumë se çfarë kemi, dhe avantazhet e tij me siguri nuk do të justifikojnë kostot e migrimit.
Dhe megjithëse pas hulumtimit u kuptua se nuk mund të përdorim Loki, shpresojmë se ky post do t'ju ndihmojë në zgjedhjen tuaj.
Repoziatori me kodin e përdorur në artikull ndodhet .
Burimi: habr.com
