

Strukturimi i të dhënave të pa strukturuara me GROK
Nëse përdorni stekën Elastic (ELK) dhe jeni të interesuar për mapimin e regjistrimeve të përdoruesve nga Logstash në Elasticsearch, atëherë ky postim është për ju.

Steka ELK është një akronim për tre projekte me kod të hapur: Elasticsearch, Logstash dhe Kibana. Së bashku, ata formojnë një platformë për menaxhimin e regjistrimeve.
- Elasticsearch – është një sistem kërkimi dhe analize.
- Logstash – është një konveyer serveri për përpunimin e të dhënave, që merr të dhëna nga burime të shumta njëkohësisht, i transformon dhe pastaj i dërgon në një “depozitë”, siç është Elasticsearch.
- Kibana lejon përdoruesit të vizualizojnë të dhënat nëpërmjet diagrameve dhe grafikëve në Elasticsearch.
Beats u shfaq më vonë dhe është një dërgues i lehtë të dhënash. Hyrja e Beats transformoi Elk Stack në Elastic Stack, por kjo nuk është kryesore.
Ky artikull është kushtuar Grok, e cila është një funksion në Logstash që mund të transformojë regjistrimet tuaja para se ato të dërgohen në depo. Për qëllimet tona, do flas vetëm për përpunimin e të dhënave nga Logstash në Elasticsearch.

Grok është një filtr në Logstash, i cili përdoret për të analizuar të dhënat e paestructuruara në diçka të strukturuar dhe për kërkimin. Ai qëndron sipër shprehjeve të rregullta (regex) dhe përdor modele teksti për të përputhur vargjet në skedarët e regjistrit.
Siç do të shohim në seksionet në vazhdim, përdorimi i Grok ka një rëndësi të madhe kur bëhet fjalë për menaxhimin efektiv të regjistrave.
Pa Grok, të dhënat tuaja të regjistrave janë të paestructuruara.
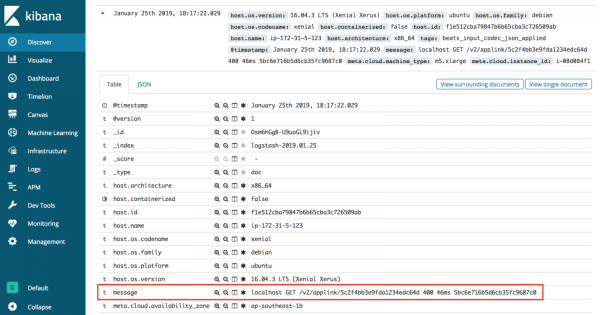
Pa Grok, kur regjistrat dërgohen nga Logstash në Elasticsearch dhe visualizohen në Kibana, ato shfaqen vetëm në vlerën e mesazhit.
Kërkimi i informacionit të rëndësishëm në këtë situatë është i vështirë, pasi të gjitha të dhënat e regjistrit ruhen në një çelës. Do të ishte më mirë nëse mesazhet e regjistrit ishin të organizuara më mirë.
Të dhëna të paestructuruara nga regjistrat
localhost GET /v2/applink/5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0Nëse e shqyrtoni me kujdes të dhënat e papërpunuara, do të shihni se ato në të vërtetë përbëhen nga pjesë të ndryshme, secila e ndarë me hapësirë.
Për zhvilluesit më me përvojë, ndoshta mund të kuptoni se çfarë do të thotë secili nga pjesët dhe se kjo është një mesazh log-u nga një thirrje API. Paraqitja e secilit element është e shpjeguar më poshtë.
Pamja e strukturuar e të dhënave tona
- localhost == ambient
- GET == metodë
- /v2/applink/5c2f4bb3e9fda1234edc64d == url
- 400 == statusi i përgjigjes
- 46ms == koha e përgjigjes
- 5bc6e716b5d6cb35fc9687c0 == id e përdoruesit
Siç e shohim në të dhënat e strukturuara, ka një rend për log-e të pa-strukturuara. Hapi tjetër është përpunimi programatik i të dhënave të papërpunuara. Këtu është ku Grok shkëlqen.
Shabllonat Grok
Shabllonat e integruara Grok
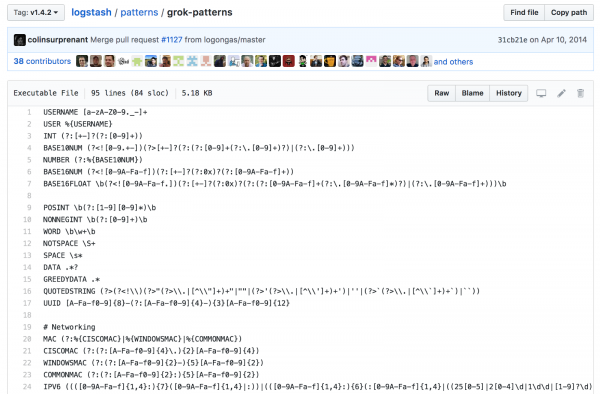
Logstash vjen me më shumë se 100 shabllone të integruara për strukturimin e të dhënave të pa-strukturuara. Definitivisht duhet ta shfrytëzoni këtë avantazh kur të jetë e mundur për log-e të zakonshme sistemore, si apache, linux, haproxy, aws dhe kështu me radhë.
Megjithatë, çfarë ndodh kur keni log-e përdoruesi, si në shembullin e mësipërm? Duhet të ndërtoni shabllo tuaj Grok.
Shabllonat Grok të personalizuara
Duhet të provoni për të ndërtuar shabllonin tuaj Grok. Unë përdora dhe .
Vini re se sintaksa e шаблонëve Grok ka këtë pamje: %{SYNTAX:SEMANTIC}
Gjëja e parë që provova ishte të kaloja në skedën Discover në debuggerin Grok. Mendova se do të ishte e shkëlqyer nëse ky mjet mund të gjeneronte automatikisht një шаблон Grok, por kjo nuk ishte shumë e dobishme, pasi ai gjeti vetëm dy përputhje.
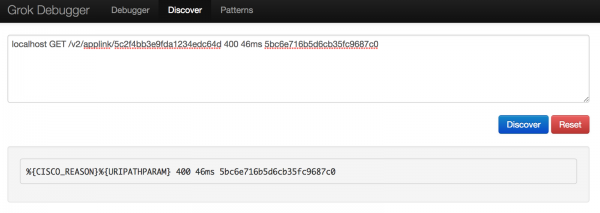
Duke përdorur këtë zbulim, fillova të krijoja шаблонin tim në debuggerin Grok, duke përdorur sintaksën që gjeta në faqen Github Elastic.
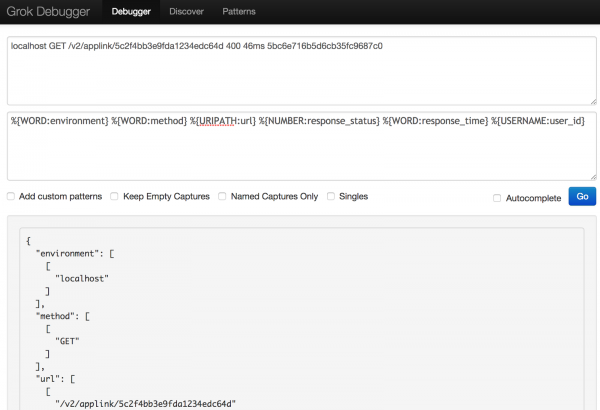
Pas disa eksperimentesh me sintaksat e ndryshme, më në fund arrita të strukturoja të dhënat e logut ashtu siç doja.
Linku për debuggerin Grok
Teksti origjinal:
localhost GET /v2/applink/5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0Pattern:
%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}Pas përfundimit
{
"environment": [
[
"localhost"
]
],
"method": [
[
"GET"
]
],
"url": [
[
"/v2/applink/5c2f4bb3e9fda1234edc64d"
]
],
"response_status": [
[
"400"
]
],
"BASE10NUM": [
[
"400"
]
],
"response_time": [
[
"46ms"
]
],
"user_id": [
[
"5bc6e716b5d6cb35fc9687c0"
]
]
}Me шаблонin Grok dhe të dhënat e përputhura, hapi i fundit është ta shtoj atë në Logstash.
Përditësimi i skedarit të konfigurimit Logstash.conf
Në serverin ku keni instaluar stakun ELK, shkoni te konfigurimi i Logstash:
sudo vi /etc/logstash/conf.d/logstash.confShtoni ndryshimet.
input {
file {
path => "/your_logs/*.log"
}
}
filter{
grok {
match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}"}
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}Pas ruajtjes së ndryshimeve, rindizni Logstash dhe kontrolloni statusin e tij për të siguruar që ai vazhdon të funksionojë.
sudo service logstash restart
sudo service logstash statusMë në fund, për të siguruar që ndryshimet kanë hyrë në fuqi, sigurohuni të rifreskoni indeksin Elasticsearch për Logstash në Kibana!
Me Grok, të dhënat tuaja nga log-e janë strukturuar!
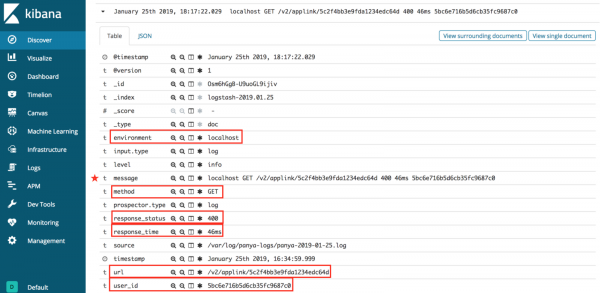
Siç e shohim, në imazhin më sipër, Grok është në gjendje të përputhë automatikisht të dhënat e log-ut me Elasticsearch. Kjo lehtëson menaxhimin e log-eve dhe kërkimin e informacionit të shpejtë. Në vend që të kërkoni në skedarët e logëve për debuggim, thjesht mund të filtroni atë që kërkoni, siç është mjedisi apo URL-ja.
Provoni të jepni Grok expressions një shans! Nëse keni një mënyrë tjetër për ta bërë këtë ose keni ndonjë problem me shembujt më sipër, thjesht lëreni një koment më poshtë për të më njoftuar.
Faleminderit për leximin — dhe ju lutem ndiqni meje këtu, në Medium, për artikuj më interesantë rreth inxhinierisë softuerike!
Burimet
P.S
Kanali Telegram për
Burimi: habr.com
