

Mirembrema Emri im është Danil Lipovoy, ekipi ynë në Sbertech filloi të përdorë HBase si një ruajtje për të dhënat operative. Gjatë studimit të tij, është grumbulluar përvoja që kam dashur të sistemoj dhe përshkruaj (shpresojmë se do të jetë e dobishme për shumë njerëz). Të gjitha eksperimentet e mëposhtme u kryen me versionet HBase 1.2.0-cdh5.14.2 dhe 2.0.0-cdh6.0.0-beta1.
- Arkitektura e përgjithshme
- Shkrimi i të dhënave në HBASE
- Leximi i të dhënave nga HBASE
- Memoria e të dhënave
- Përpunimi i grupit të të dhënave MultiGet/MultiPut
- Strategjia për ndarjen e tabelave në rajone (ndarje)
- Toleranca e gabimeve, kompaktimi dhe lokaliteti i të dhënave
- Cilësimet dhe performanca
- Testimi i stresit
- Gjetjet
1. Arkitektura e përgjithshme
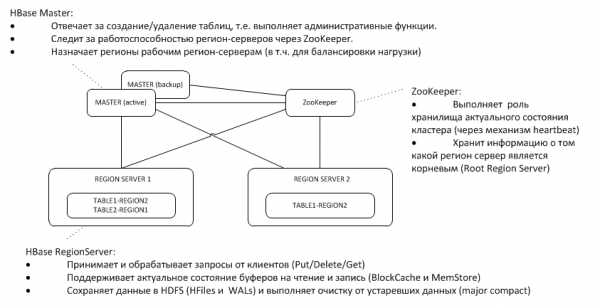
Masteri rezervë dëgjon rrahjet e zemrës së atij aktiv në nyjen ZooKeeper dhe, në rast zhdukjeje, merr përsipër funksionet e masterit.
2. Shkruani të dhënat në HBASE
Së pari, le të shohim rastin më të thjeshtë - shkrimi i një objekti me vlerë kyçe në një tabelë duke përdorur put(rowkey). Klienti duhet së pari të zbulojë se ku ndodhet serveri i rajonit rrënjë (RRS), i cili ruan tabelën hbase:meta. Ai e merr këtë informacion nga ZooKeeper. Pas së cilës ai hyn në RRS dhe lexon tabelën hbase:meta, nga e cila nxjerr informacion se cili RegionServer (RS) është përgjegjës për ruajtjen e të dhënave për një rresht të caktuar në tabelën me interes. Për përdorim në të ardhmen, tabela meta ruhet nga klienti dhe për këtë arsye thirrjet pasuese shkojnë më shpejt, direkt në RS.
Tjetra, RS, pasi ka marrë një kërkesë, para së gjithash e shkruan atë në WriteAheadLog (WAL), e cila është e nevojshme për rikuperim në rast të një përplasjeje. Më pas i ruan të dhënat në MemStore. Ky është një buffer në memorie që përmban një grup të renditur çelësash për një rajon të caktuar. Një tabelë mund të ndahet në rajone (ndarje), secila prej të cilave përmban një grup të ndarë çelësash. Kjo ju lejon të vendosni rajone në serverë të ndryshëm për të arritur performancë më të lartë. Megjithatë, pavarësisht qartësisë së kësaj deklarate, do të shohim më vonë se kjo nuk funksionon në të gjitha rastet.
Pas vendosjes së një hyrjeje në MemStore, klientit i kthehet një përgjigje se hyrja është ruajtur me sukses. Sidoqoftë, në realitet ai ruhet vetëm në një tampon dhe futet në disk vetëm pasi të ketë kaluar një periudhë e caktuar kohore ose kur mbushet me të dhëna të reja.
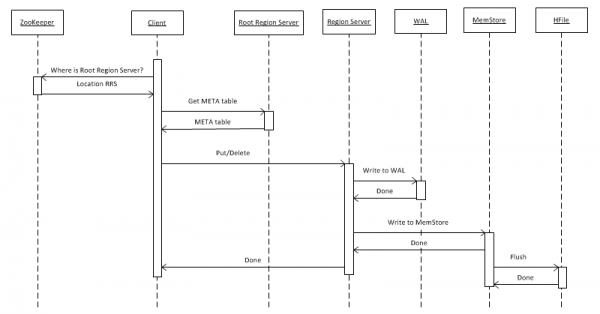
Kur kryeni operacionin "Fshi", të dhënat nuk fshihen fizikisht. Ato thjesht shënohen si të fshira, dhe vetë shkatërrimi ndodh në momentin e thirrjes së funksionit kompakt madhor, i cili përshkruhet më në detaje në paragrafin 7.
Skedarët në formatin HFile grumbullohen në HDFS dhe herë pas here hapet procesi i vogël kompakt, i cili thjesht bashkon skedarë të vegjël në më të mëdhenj pa fshirë asgjë. Me kalimin e kohës, kjo kthehet në një problem që shfaqet vetëm kur lexoni të dhëna (ne do t'i kthehemi kësaj pak më vonë).
Përveç procesit të ngarkimit të përshkruar më sipër, ekziston një procedurë shumë më efektive, e cila është ndoshta ana më e fortë e kësaj baze të dhënash - BulkLoad. Qëndron në faktin se ne formojmë në mënyrë të pavarur HFiles dhe i vendosim në disk, gjë që na lejon të shkallëzojmë në mënyrë të përsosur dhe të arrijmë shpejtësi shumë të mira. Në fakt, kufizimi këtu nuk është HBase, por aftësitë e harduerit. Më poshtë janë rezultatet e nisjes në një grup të përbërë nga 16 RegionServers dhe 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads), versioni HBase 1.2.0-cdh5.14.2.
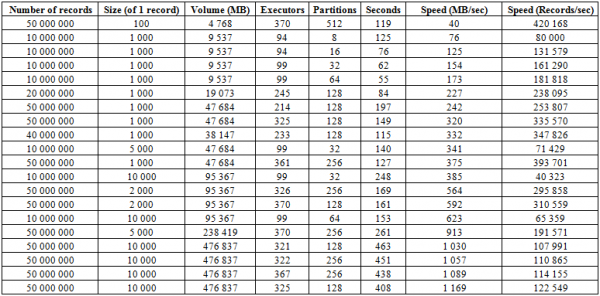
Këtu mund të shihni se duke rritur numrin e ndarjeve (rajoneve) në tabelë, si dhe ekzekutuesit e Spark, marrim një rritje të shpejtësisë së shkarkimit. Gjithashtu, shpejtësia varet nga vëllimi i regjistrimit. Blloqet e mëdha japin një rritje në MB/sek, blloqet e vogla në numrin e regjistrimeve të futura për njësi të kohës, të gjitha gjërat e tjera janë të barabarta.
Ju gjithashtu mund të filloni të ngarkoni në dy tabela në të njëjtën kohë dhe të merrni dyfishin e shpejtësisë. Më poshtë mund të shihni se shkrimi i blloqeve 10 KB në dy tabela njëherësh ndodh me një shpejtësi prej rreth 600 MB/sek në secilën (gjithsej 1275 MB/sek), që përkon me shpejtësinë e shkrimit në një tabelë 623 MB/sek (shih Nr. 11 më sipër)

Por ekzekutimi i dytë me rekorde prej 50 KB tregon se shpejtësia e shkarkimit po rritet pak, gjë që tregon se po i afrohet vlerave kufi. Në të njëjtën kohë, duhet të keni parasysh se praktikisht nuk ka asnjë ngarkesë të krijuar në vetë HBASE, gjithçka që kërkohet prej saj është që së pari të jepni të dhëna nga hbase:meta, dhe pasi të rreshtoni HFiles, rivendosni të dhënat e BlockCache dhe ruani MemStore buffer në disk, nëse nuk është bosh.
3. Leximi i të dhënave nga HBASE
Nëse supozojmë se klienti i ka tashmë të gjitha informacionet nga hbase:meta (shih pikën 2), atëherë kërkesa shkon drejtpërdrejt në RS ku ruhet çelësi i kërkuar. Së pari, kërkimi kryhet në MemCache. Pavarësisht nëse ka të dhëna atje apo jo, kërkimi kryhet gjithashtu në buferin BlockCache dhe, nëse është e nevojshme, në HFiles. Nëse të dhënat janë gjetur në skedar, ato vendosen në BlockCache dhe do të kthehen më shpejt në kërkesën tjetër. Kërkimi në HFile është relativisht i shpejtë falë përdorimit të filtrit Bloom, d.m.th. pasi të ketë lexuar një sasi të vogël të dhënash, ai menjëherë përcakton nëse ky skedar përmban çelësin e kërkuar dhe nëse jo, atëherë kalon në atë tjetër.
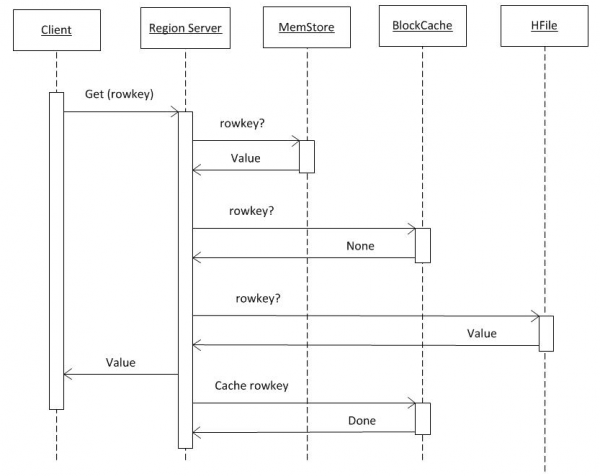
Pasi ka marrë të dhëna nga këto tre burime, RS gjeneron një përgjigje. Në veçanti, ai mund të transferojë disa versione të gjetura të një objekti në të njëjtën kohë nëse klienti kërkon versionim.
4. Memoria e të dhënave
Buferët MemStore dhe BlockCache zënë deri në 80% të memories RS të alokuar në grumbull (pjesa tjetër është e rezervuar për detyrat e shërbimit RS). Nëse mënyra tipike e përdorimit është e tillë që proceset shkruajnë dhe lexojnë menjëherë të njëjtat të dhëna, atëherë ka kuptim të reduktohet BlockCache dhe të rritet MemStore, sepse Kur shkrimi i të dhënave nuk futet në cache për lexim, BlockCache do të përdoret më rrallë. Buferi BlockCache përbëhet nga dy pjesë: LruBlockCache (gjithmonë në grumbull) dhe BucketCache (zakonisht jashtë grumbullit ose në një SSD). BucketCache duhet të përdoret kur ka shumë kërkesa leximi dhe ato nuk përshtaten në LruBlockCache, gjë që çon në punën aktive të Mbledhësve të mbeturinave. Në të njëjtën kohë, nuk duhet të prisni një rritje rrënjësore të performancës nga përdorimi i cache-it të leximit, por ne do t'i kthehemi kësaj në paragrafin 8
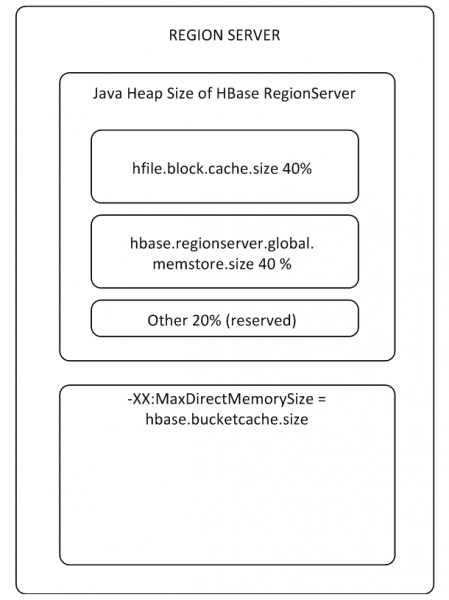
Ekziston një BlockCache për të gjithë RS, dhe ka një MemStore për çdo tabelë (një për çdo familje kolone).
Si në teori, kur shkruhet, të dhënat nuk futen në cache dhe në të vërtetë, parametrat e tillë CACHE_DATA_ON_WRITE për tabelën dhe "Cache DATA on Write" për RS janë vendosur në false. Megjithatë, në praktikë, nëse i shkruajmë të dhënat në MemStore, pastaj i hedhim në disk (duke e pastruar atë), më pas e fshijmë skedarin që rezulton, pastaj duke ekzekutuar një kërkesë marrë do t'i marrim me sukses të dhënat. Për më tepër, edhe nëse e çaktivizoni plotësisht BlockCache dhe mbushni tabelën me të dhëna të reja, pastaj rivendosni MemStore në disk, i fshini dhe i kërkoni nga një seancë tjetër, ato do të merren përsëri nga diku. Pra, HBase ruan jo vetëm të dhëna, por edhe mistere misterioze.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Parametri "Cache DATA on Read" është vendosur në false. Nëse keni ndonjë ide, mirëpriteni ta diskutoni atë në komente.
5. Përpunimi i grupit të të dhënave MultiGet/MultiPut
Përpunimi i kërkesave të vetme (Get/Put/Delete) është një operacion mjaft i shtrenjtë, kështu që nëse është e mundur, duhet t'i kombinoni ato në një Listë ose Listë, e cila ju lejon të merrni një rritje të konsiderueshme të performancës. Kjo është veçanërisht e vërtetë për funksionin e shkrimit, por kur lexoni ekziston gracka e mëposhtme. Grafiku më poshtë tregon kohën për të lexuar 50 regjistrime nga MemStore. Leximi është kryer në një fije dhe boshti horizontal tregon numrin e çelësave në kërkesë. Këtu mund të shihni se kur rritet në një mijë çelësa në një kërkesë, koha e ekzekutimit bie, d.m.th. shpejtësia rritet. Megjithatë, me modalitetin MSLAB të aktivizuar si parazgjedhje, pas këtij pragu fillon një rënie radikale e performancës dhe sa më e madhe të jetë sasia e të dhënave në regjistrim, aq më e gjatë është koha e funksionimit.
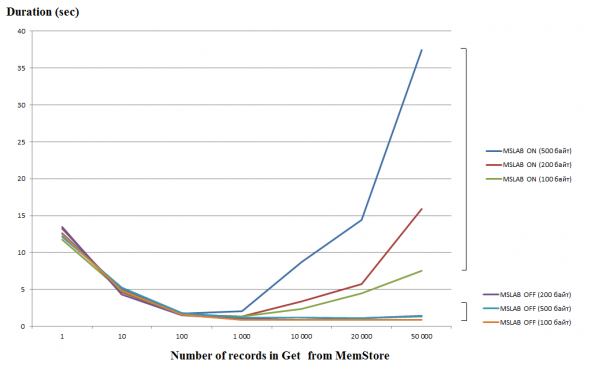
Testet u kryen në një makinë virtuale, 8 bërthama, versioni HBase 2.0.0-cdh6.0.0-beta1.
Modaliteti MSLAB është krijuar për të reduktuar fragmentimin e grumbullit, i cili ndodh për shkak të përzierjes së të dhënave të gjeneratës së re dhe të vjetër. Si zgjidhje, kur aktivizohet MSLAB, të dhënat vendosen në qeliza relativisht të vogla (copa) dhe përpunohen në copa. Si rezultat, kur vëllimi në paketën e kërkuar të të dhënave tejkalon madhësinë e caktuar, performanca bie ndjeshëm. Nga ana tjetër, fikja e këtij modaliteti gjithashtu nuk është e këshillueshme, pasi do të çojë në ndalesa për shkak të GC gjatë momenteve të përpunimit intensiv të të dhënave. Një zgjidhje e mirë është rritja e vëllimit të qelizës në rastin e shkrimit aktiv nëpërmjet vendosjes në të njëjtën kohë me leximin. Vlen të përmendet se problemi nuk ndodh nëse, pas regjistrimit, ekzekutoni komandën flush, e cila rivendos MemStore në disk, ose nëse ngarkoni duke përdorur BulkLoad. Tabela më poshtë tregon se pyetjet nga MemStore për të dhëna më të mëdha (dhe të njëjtën sasi) rezultojnë në ngadalësime. Megjithatë, duke rritur masën, ne e kthejmë kohën e përpunimit në normale.
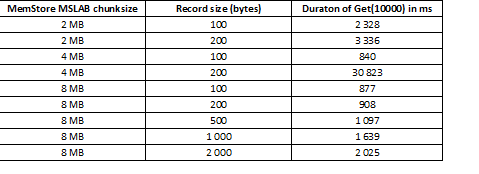
Përveç rritjes së madhësisë, ndarja e të dhënave sipas rajonit ndihmon, d.m.th. ndarje tavoline. Kjo rezulton në më pak kërkesa që vijnë në çdo rajon dhe nëse ato përshtaten në një qelizë, përgjigja mbetet e mirë.
6. Strategjia për ndarjen e tabelave në rajone (ndarje)
Meqenëse HBase është një ruajtje me vlerë kyçe dhe ndarja kryhet me çelës, është jashtëzakonisht e rëndësishme të ndahen të dhënat në mënyrë të barabartë në të gjitha rajonet. Për shembull, ndarja e një tabele të tillë në tre pjesë do të rezultojë në ndarjen e të dhënave në tre rajone:
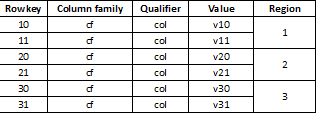
Ndodh që kjo të çojë në një ngadalësim të mprehtë nëse të dhënat e ngarkuara më vonë duken si, për shembull, vlera të gjata, shumica prej tyre fillojnë me të njëjtën shifër, për shembull:
1000001
1000002
...
1100003
Meqenëse çelësat ruhen si një grup bytesh, ata do të fillojnë të gjithë njësoj dhe do t'i përkasin të njëjtit rajon #1 që ruan këtë varg çelësash. Ka disa strategji ndarjeje:
HexStringSplit – E kthen çelësin në një varg të koduar heksadecimal në rangun "00000000" => "FFFFFFFF" dhe duke e mbushur në të majtë me zero.
UniformSplit – E kthen çelësin në një grup bajtësh me kodim heksadecimal në intervalin "00" => "FF" dhe duke e mbushur në të djathtë me zero.
Përveç kësaj, mund të specifikoni çdo gamë ose grup çelësash për ndarje dhe konfigurim të ndarjes automatike. Sidoqoftë, një nga qasjet më të thjeshta dhe më efektive është UniformSplit dhe përdorimi i lidhjes hash, për shembull çifti më i rëndësishëm i bajteve nga ekzekutimi i çelësit përmes funksionit CRC32 (kyç i rreshtit) dhe vetë tastit të rreshtit:
hash + rowkey
Pastaj të gjitha të dhënat do të shpërndahen në mënyrë të barabartë nëpër rajone. Gjatë leximit, dy bajtët e parë thjesht hidhen dhe çelësi origjinal mbetet. RS kontrollon gjithashtu sasinë e të dhënave dhe çelësave në rajon dhe, nëse tejkalohen kufijtë, i ndan automatikisht ato në pjesë.
7. Toleranca e gabimeve dhe lokaliteti i të dhënave
Meqenëse vetëm një rajon është përgjegjës për çdo grup çelësash, zgjidhja e problemeve që lidhen me përplasjet ose çaktivizimin e RS është ruajtja e të gjitha të dhënave të nevojshme në HDFS. Kur RS bie, master e zbulon këtë përmes mungesës së një rrahje zemre në nyjen ZooKeeper. Më pas cakton rajonin e shërbyer në një RS tjetër dhe meqenëse HFiles ruhen në një sistem skedari të shpërndarë, pronari i ri i lexon ato dhe vazhdon të shërbejë të dhënat. Sidoqoftë, meqenëse disa nga të dhënat mund të jenë në MemStore dhe nuk kanë pasur kohë për të hyrë në HFiles, WAL, i cili ruhet gjithashtu në HDFS, përdoret për të rivendosur historinë e operacioneve. Pasi të zbatohen ndryshimet, RS është në gjendje t'u përgjigjet kërkesave, por lëvizja çon në faktin se disa nga të dhënat dhe proceset që i shërbejnë ato përfundojnë në nyje të ndryshme, d.m.th. lokaliteti është në rënie.
Zgjidhja e problemit është ngjeshja e madhe - kjo procedurë zhvendos skedarët në ato nyje që janë përgjegjëse për to (ku ndodhen rajonet e tyre), si rezultat i së cilës gjatë kësaj procedure ngarkesa në rrjet dhe disqe rritet ndjeshëm. Megjithatë, në të ardhmen, qasja në të dhëna do të përshpejtohet dukshëm. Përveç kësaj, major_compaction kryen bashkimin e të gjithë skedarëve HFile në një skedar brenda një rajoni dhe gjithashtu pastron të dhënat në varësi të cilësimeve të tabelës. Për shembull, mund të specifikoni numrin e versioneve të një objekti që duhet të ruhet ose jetëgjatësinë pas së cilës objekti fshihet fizikisht.
Kjo procedurë mund të ketë një efekt shumë pozitiv në funksionimin e HBase. Figura më poshtë tregon se si performanca u degradua si rezultat i regjistrimit aktiv të të dhënave. Këtu mund të shihni se si 40 threads shkruan në një tabelë dhe 40 threads lexojnë njëkohësisht të dhënat. Fijet e shkrimit gjenerojnë gjithnjë e më shumë skedarë HFile, të cilat lexohen nga fijet e tjera. Si rezultat, gjithnjë e më shumë të dhëna duhet të hiqen nga memoria dhe përfundimisht GC fillon të funksionojë, gjë që praktikisht paralizon të gjithë punën. Nisja e ngjeshjes së madhe çoi në pastrimin e mbeturinave që rezultojnë dhe rivendosjen e produktivitetit.
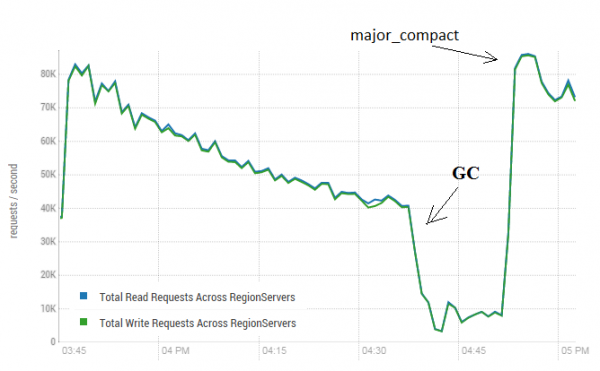
Testi u krye në 3 DataNodes dhe 4 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). Versioni HBase 1.2.0-cdh5.14.2
Vlen të përmendet se ngjeshja e madhe u lançua në një tabelë "live", në të cilën të dhënat u shkruan dhe lexoheshin në mënyrë aktive. Kishte një deklaratë në internet se kjo mund të çonte në një përgjigje të pasaktë gjatë leximit të të dhënave. Për të kontrolluar, u nis një proces që gjeneroi të dhëna të reja dhe i shkroi ato në një tabelë. Pas së cilës menjëherë lexova dhe kontrollova nëse vlera që rezulton përkonte me atë që ishte shkruar. Ndërkohë që ky proces po funksiononte, ngjeshja e madhe u krye rreth 200 herë dhe nuk u regjistrua asnjë dështim i vetëm. Ndoshta problemi shfaqet rrallë dhe vetëm gjatë ngarkesës së lartë, kështu që është më e sigurt të ndaloni proceset e shkrimit dhe leximit siç është planifikuar dhe të kryeni pastrimin për të parandaluar tërheqje të tilla të GC.
Gjithashtu, ngjeshja e madhe nuk ndikon në gjendjen e MemStore; për ta hedhur atë në disk dhe për ta kompaktuar, duhet të përdorni flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Cilësimet dhe performanca
Siç është përmendur tashmë, HBase tregon suksesin e saj më të madh aty ku nuk ka nevojë të bëjë asgjë, kur ekzekuton BulkLoad. Megjithatë, kjo vlen për shumicën e sistemeve dhe njerëzve. Megjithatë, ky mjet është më i përshtatshëm për ruajtjen e të dhënave në masë në blloqe të mëdha, ndërsa nëse procesi kërkon kërkesa të shumta konkurruese për lexim dhe shkrim, përdoren komandat Get and Put të përshkruara më sipër. Për të përcaktuar parametrat optimalë, lëshimet u kryen me kombinime të ndryshme të parametrave dhe cilësimeve të tabelës:
- 10 fije u nisën njëkohësisht 3 herë me radhë (le ta quajmë këtë një bllok fijesh).
- Koha e funksionimit të të gjitha fijeve në një bllok ishte mesatare dhe ishte rezultati përfundimtar i funksionimit të bllokut.
- Të gjitha fijet punuan me të njëjtën tabelë.
- Përpara çdo fillimi të bllokut të fillit, kryhej një ngjeshje e madhe.
- Çdo bllok kryente vetëm një nga operacionet e mëposhtme:
-Vendos
-Marr
— Merr+Vendos
- Çdo bllok kreu 50 përsëritje të funksionimit të tij.
- Madhësia e bllokut të një rekord është 100 byte, 1000 bytes ose 10000 bytes (të rastësishme).
- Blloqet u lëshuan me numra të ndryshëm të çelësave të kërkuar (ose një çelës ose 10).
- Blloqet u ekzekutuan nën cilësime të ndryshme të tabelës. Parametrat e ndryshuar:
— BlockCache = aktivizuar ose fikur
— BlockSize = 65 KB ose 16 KB
- Ndarjet = 1, 5 ose 30
— MSLAB = aktivizuar ose çaktivizuar
Pra, blloku duket si ky:
a. Modaliteti MSLAB u aktivizua/fik.
b. U krijua një tabelë për të cilën u vendosën parametrat e mëposhtëm: BlockCache = true/asnjë, BlockSize = 65/16 Kb, Ndarja = 1/5/30.
c. Kompresimi u vendos në GZ.
d. 10 threads u nisën njëkohësisht duke bërë operacione 1/10 put/get/get+put në këtë tabelë me regjistrime prej 100/1000/10000 byte, duke kryer 50 pyetje me radhë (çelësat e rastësishëm).
e. Pika d u përsërit tri herë.
f. Koha e funksionimit të të gjitha fijeve ishte mesatare.
Të gjitha kombinimet e mundshme janë testuar. Është e parashikueshme që shpejtësia do të bjerë me rritjen e madhësisë së rekordit, ose që çaktivizimi i caching-ut do të shkaktojë ngadalësim. Megjithatë, qëllimi ishte të kuptonim shkallën dhe rëndësinë e ndikimit të secilit parametër, kështu që të dhënat e mbledhura u futën në hyrjen e një funksioni të regresionit linear, i cili bën të mundur vlerësimin e rëndësisë duke përdorur statistikat t. Më poshtë janë rezultatet e blloqeve që kryejnë operacionet Put. Set i plotë i kombinimeve 2*2*3*2*3 = 144 opsione + 72 tk. disa janë bërë dy herë. Prandaj, ka 216 vrapime në total:
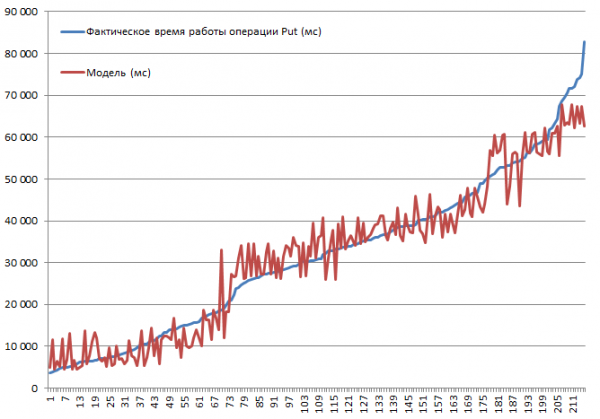
Testimi u krye në një mini-grup të përbërë nga 3 DataNodes dhe 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads). Versioni HBase 1.2.0-cdh5.14.2.
Shpejtësia më e lartë e futjes prej 3.7 sekondash u arrit me modalitetin MSLAB të çaktivizuar, në një tabelë me një ndarje, me BlockCache të aktivizuar, BlockSize = 16, regjistrime 100 bajt, 10 copë për paketë.
Shpejtësia më e ulët e futjes prej 82.8 sek është marrë me modalitetin MSLAB të aktivizuar, në një tabelë me një ndarje, me BlockCache të aktivizuar, BlockSize = 16, regjistrime prej 10000 bajt, 1 secila.
Tani le të shohim modelin. Ne shohim cilësinë e mirë të modelit të bazuar në R2, por është absolutisht e qartë se ekstrapolimi është kundërindikuar këtu. Sjellja aktuale e sistemit kur parametrat ndryshojnë nuk do të jetë lineare; ky model nuk nevojitet për parashikime, por për të kuptuar se çfarë ka ndodhur brenda parametrave të dhënë. Për shembull, këtu shohim nga kriteri i Studentit se parametrat BlockSize dhe BlockCache nuk kanë rëndësi për operacionin Put (i cili në përgjithësi është mjaft i parashikueshëm):

Por fakti që rritja e numrit të ndarjeve çon në një ulje të performancës është disi i papritur (e kemi parë tashmë ndikimin pozitiv të rritjes së numrit të ndarjeve me BulkLoad), megjithëse i kuptueshëm. Së pari, për përpunim, duhet të gjeneroni kërkesa në 30 rajone në vend të një, dhe vëllimi i të dhënave nuk është i tillë që kjo të sjellë një fitim. Së dyti, koha totale e funksionimit përcaktohet nga RS më e ngadaltë, dhe duke qenë se numri i DataNodes është më i vogël se numri i RS-ve, disa rajone kanë lokalitet zero. Epo, le të shohim pesë vendet më të mira:

Tani le të vlerësojmë rezultatet e ekzekutimit të blloqeve Get:

Numri i ndarjeve ka humbur rëndësinë, gjë që ndoshta shpjegohet me faktin se të dhënat ruhen mirë në memorie dhe cache-i i lexuar është parametri më domethënës (statistikisht). Natyrisht, rritja e numrit të mesazheve në një kërkesë është gjithashtu shumë e dobishme për performancën. Rezultatet më të mira:

Epo, më në fund, le të shohim modelin e bllokut që u krye fillimisht merrni dhe më pas vendosim:

Të gjithë parametrat janë të rëndësishëm këtu. Dhe rezultatet e drejtuesve:

9. Testimi i ngarkesës
Epo, më në fund do të lëshojmë një ngarkesë pak a shumë të mirë, por është gjithmonë më interesante kur ke diçka për të krahasuar. Në faqen e internetit të DataStax, zhvilluesi kryesor i Cassandra, ekziston NT të një numri të ruajtjeve NoSQL, duke përfshirë versionin HBase 0.98.6-1. Ngarkimi u krye nga 40 fije, madhësia e të dhënave 100 bajt, disqe SSD. Rezultati i testimit të operacioneve Read-Modify-Write tregoi rezultatet e mëposhtme.
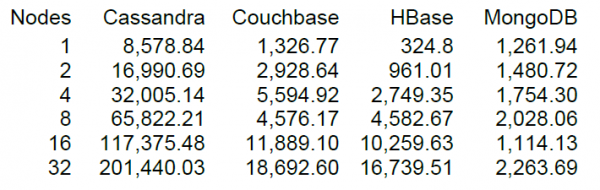
Me sa kuptoj unë, leximi u krye në blloqe prej 100 rekordesh dhe për 16 nyje HBase, testi DataStax tregoi një performancë prej 10 mijë operacionesh në sekondë.
Është fat që grupi ynë ka edhe 16 nyje, por nuk është shumë “fat” që secili ka 64 bërthama (threads), ndërsa në testin DataStax janë vetëm 4. Nga ana tjetër, ata kanë disqe SSD, ndërsa ne HDD. ose më shumë versioni i ri i përdorimit të HBase dhe CPU gjatë ngarkesës praktikisht nuk u rrit ndjeshëm (vizualisht me 5-10 përqind). Sidoqoftë, le të përpiqemi të fillojmë të përdorim këtë konfigurim. Cilësimet e parazgjedhura të tabelës, leximi kryhet në intervalin kryesor nga 0 në 50 milion në mënyrë të rastësishme (d.m.th., në thelb të reja çdo herë). Tabela përmban 50 milionë regjistrime, të ndara në 64 ndarje. Çelësat hashohen duke përdorur crc32. Cilësimet e tabelës janë të paracaktuara, MSLAB është i aktivizuar. Duke nisur 40 thread-e, çdo thread lexon një grup prej 100 çelësash të rastësishëm dhe menjëherë shkruan 100 bajt të gjeneruar përsëri në këta çelësa.
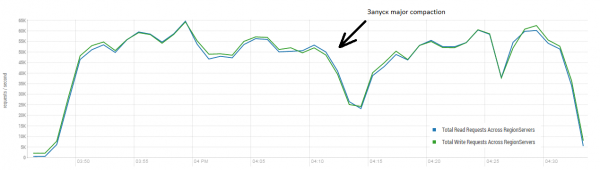
Stand: 16 DataNode dhe 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). Versioni HBase 1.2.0-cdh5.14.2.
Rezultati mesatar është më afër 40 mijë operacione në sekondë, gjë që është dukshëm më e mirë se në testin DataStax. Sidoqoftë, për qëllime eksperimentale, ju mund të ndryshoni pak kushtet. Nuk ka gjasa që e gjithë puna të kryhet ekskluzivisht në një tryezë, dhe gjithashtu vetëm në çelësa unikë. Le të supozojmë se ekziston një grup i caktuar "i nxehtë" i çelësave që gjeneron ngarkesën kryesore. Prandaj, le të përpiqemi të krijojmë një ngarkesë me regjistrime më të mëdha (10 KB), gjithashtu në grupe prej 100, në 4 tabela të ndryshme dhe duke kufizuar gamën e çelësave të kërkuar në 50 mijë. Grafiku i mëposhtëm tregon nisjen e 40 threads, çdo thread lexon një grup prej 100 çelësash dhe menjëherë shkruan 10 KB rastësisht në këta çelësa.
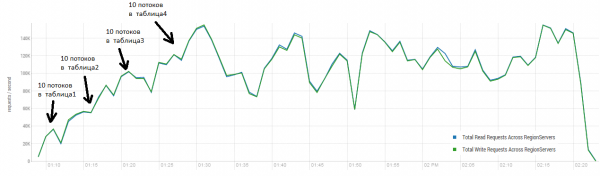
Stand: 16 DataNode dhe 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). Versioni HBase 1.2.0-cdh5.14.2.
Gjatë ngarkesës, ngjeshja e madhe u nis disa herë, siç tregohet më sipër, pa këtë procedurë, performanca gradualisht do të degradohet, megjithatë, ngarkesa shtesë lind edhe gjatë ekzekutimit. Tërheqjet shkaktohen nga arsye të ndryshme. Ndonjëherë temat mbaronin së punuari dhe kishte një pauzë gjatë rinisjes, ndonjëherë aplikacionet e palëve të treta krijonin një ngarkesë në grup.
Leximi dhe shkrimi menjëherë është një nga skenarët më të vështirë të punës për HBase. Nëse bëni vetëm kërkesa për vendosje të vogla, për shembull 100 bajt, duke i kombinuar në pako me 10-50 mijë copë, mund të merrni qindra mijëra operacione në sekondë, dhe situata është e ngjashme me kërkesat vetëm për lexim. Vlen të theksohet se rezultatet janë rrënjësisht më të mira se ato të marra nga DataStax, mbi të gjitha për shkak të kërkesave në blloqe prej 50 mijë.
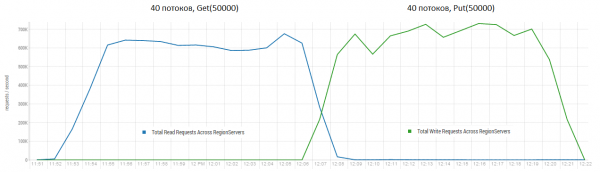
Stand: 16 DataNode dhe 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 threads). Versioni HBase 1.2.0-cdh5.14.2.
10. Konkluzione
Ky sistem është i konfiguruar mjaft fleksibël, por ndikimi i një numri të madh parametrash mbetet ende i panjohur. Disa prej tyre u testuan, por nuk u përfshinë në grupin e testimit që rezultoi. Për shembull, eksperimentet paraprake treguan një rëndësi të parëndësishme të një parametri të tillë si DATA_BLOCK_ENCODING, i cili kodon informacionin duke përdorur vlera nga qelizat fqinje, gjë që është e kuptueshme për të dhënat e krijuara rastësisht. Nëse përdorni një numër të madh objektesh të kopjuara, fitimi mund të jetë i rëndësishëm. Në përgjithësi, mund të themi se HBase jep përshtypjen e një baze të dhënash mjaft serioze dhe të mirëmenduar, e cila mund të jetë mjaft produktive kur kryeni operacione me blloqe të mëdha të dhënash. Sidomos nëse është e mundur të ndahen në kohë proceset e leximit dhe të shkrimit.
Nëse ka diçka sipas mendimit tuaj që nuk është bërë e ditur sa duhet, jam gati t'ju tregoj më në detaje. Ju ftojmë të ndani përvojën tuaj ose të diskutoni nëse nuk jeni dakord me diçka.
Burimi: www.habr.com
