

Всем привет, меня зовут Александр, и я Data Quality инженер, который занимается проверкой данных на предмет их качества. В этой статье речь пойдёт о том, как я к этому пришёл и почему в 2020 году это направление тестирования оказалось на гребне волны.

Мировой тренд
Сегодняшний мир переживает очередную технологическую революцию, одним из аспектов которой является использование всевозможными компаниями накопленных данных для раскрутки собственного маховика продаж, прибылей и пиара. Представляется, что именно наличие хороших (качественных) данных, а также умелых мозгов, которые смогут из них делать деньги (правильно обработать, визуализировать, построить модели машинного обучения и т. п.), стали сегодня ключом к успеху для многих. Если 15-20 лет назад плотной работой с накоплением данных и их монетизацией занимались в основном крупные компании, то сегодня это удел практически всех здравомыслящих.
В связи с этим несколько лет назад все порталы, посвящённые поиску работы по всему миру, стали переполняться вакансиями Data Scientists, так как все были уверены, что, получив себе в штат такого специалиста, можно построить супермодель машинного обучения, предсказать будущее и совершить «квантовый скачок» для компании. Со временем люди поняли, что такой подход почти нигде не работает, так как далеко не все данные, которые попадают в руки такого рода специалистам, пригодны для обучения моделей.
И начались запросы от Data Scientists: «Давайте купим ещё данных у этих и у тех.…», «Нам не хватает данных…», «Нужно ещё немного данных и желательно качественных…». Основываясь на этих запросах, стали выстраиваться многочисленные взаимодействия между компаниями, владеющими тем или иным набором данных. Естественно, это потребовало технической организации этого процесса — подсоединиться к источнику данных, выкачать их, проверить, что они загружены в полном объёме и т. п. Количество таких процессов стало расти, и на сегодняшний день мы получили огромную потребность в другого рода специалистах — Data Quality инженерах — тех кто следил бы за потоком данных в системе (data pipelines), за качеством данных на входе и на выходе, делал бы выводы об их достаточности, целостности и прочих характеристиках.
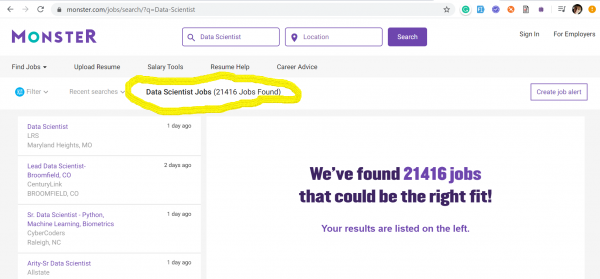
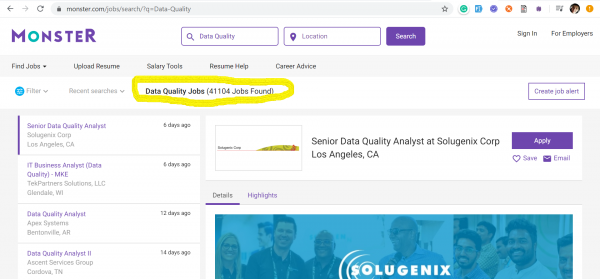
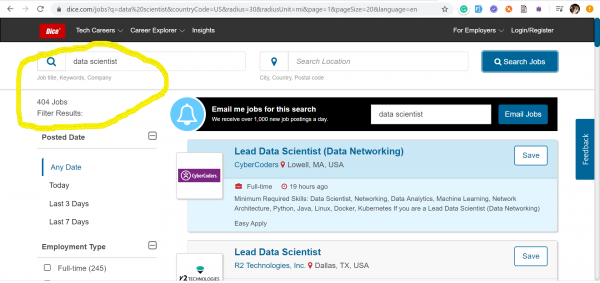
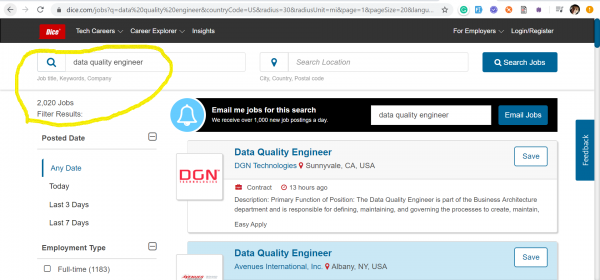
Тренд на Data Quality инженеров пришёл к нам из США, где в разгар бушующей эры капитализма никто не готов проигрывать битву за данные. Ниже я представил скриншоты с двух самых популярных сайтов поиска работы в США: dhe — на которых отображены данные по состоянию на 17 марта 2020 года по количеству размещенных вакансий полученных, по ключевым словам: Data Quality и Data Scientist.
Data Scientists – 21416 вакансий
Data Quality – 41104 вакансии
Data Scientists – 404 вакансии
Data Quality – 2020 вакансий
Очевидно, что эти профессии никоим образом не конкурируют друг с другом. Скриншотами я просто хотел проиллюстрировать текущую ситуацию на рынке труда в плане запросов на Data Quality инженеров, которых сейчас требуется сильно больше, чем Data Scientists.
В июне 2019 года EPAM, реагируя на потребности современного ИТ-рынка, выделил Data Quality направление в отдельную практику. Data Quality инженеры в ходе своей повседневной работы управляют данными, проверяют их поведение в новых условиях и системах, контролируют релевантность данных, их достаточность и актуальность. При всём при этом, в практическом смысле Data Quality инженеры действительно немного времени посвящают классическому функциональному тестированию, НО это сильно зависит от проекта (пример я приведу далее).
Обязанности Data Quality инженера не ограничиваются только рутинными ручными/автоматическими проверками на «nulls, count и sums» в таблицах БД, а требуют глубокого понимания бизнес нужд заказчика и, соответственно, способностей трансформировать имеющиеся данные в пригодную бизнес-информацию.
Теория Data Quality

Для того чтобы наиболее полно себе представить роль такого инженера, давайте разберёмся, что же такое Data Quality в теории.
Data Quality — один из этапов Data Management (целый мир, который мы оставим вам на самостоятельное изучение) и отвечает за анализ данных по следующим критериям:
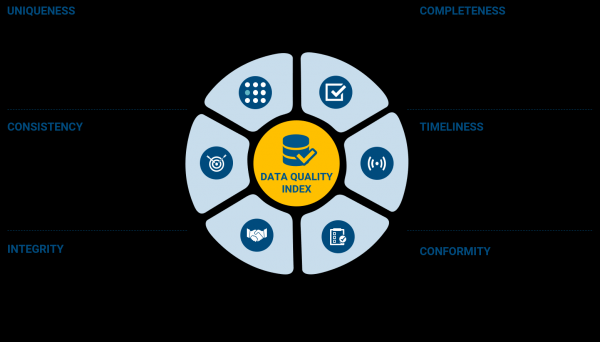
Думаю, не стоит расшифровывать каждый из пунктов (в теории называются «data dimensions»), они вполне хорошо описаны на картинке. Но сам процесс тестирования не подразумевает строгое копирование этих признаков в тест-кейсы и их проверку. В Data Quality, как и в любом другом виде тестирования, необходимо прежде всего отталкиваться от требований по качеству данных, согласованных с участниками проекта, принимающими бизнес-решения.
В зависимости от проекта Data Quality инженер может выполнять разные функции: от обыкновенного тестировщика-автоматизатора с поверхностной оценкой качества данных, до человека, проводящего их глубокое профилирование по вышеуказанным признакам.
Очень подробное описание процессов Data Management, Data Quality и смежных отлично описаны в книге под названием «DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition». Очень рекомендую данную книгу как вводную в этой тематике (ссылку на нее найдете в конце статьи).
Моя история
В ИТ-индустрии я прошёл путь от Junior тестировщика в продуктовых компаниях до Lead Data Quality Engineer в компании EPAM. Уже примерно года через два работы в качестве тестировщика у меня было твёрдое убеждение в том, что я делал абсолютно все виды тестирования: регрессионное, функциональное, стрессовое, стабильности, безопасности, UI и т. д. — и перепробовал большое количество инструментов тестирования, поработав при этом на трёх языках программирования: Java, Scala, Python.
Оглядываясь назад, я понимаю, почему набор моих профессиональных навыков оказался столь разнообразен — я участвовал в проектах, завязанных на работе с данными, большими и маленькими. Именно это привело меня в мир большого количества инструментов и возможностей для роста.
Чтобы оценить многообразие инструментов и возможностей получения новых знаний и навыков, достаточно просто взглянуть на картинку ниже, на которой изображены самые популярные из них в мире «Data & AI».

Такого рода иллюстрации составляет ежегодно один из известных венчурных капиталистов Matt Turck, выходец из разработки ПО. Вот на его блог и , где он работает партнёром.
Особенно быстро я профессионально рос, когда я был единственным тестировщиком на проекте, или, по крайней мере, в начале проекта. Именно в такой момент приходится отвечать за весь процесс тестирования, и у тебя нет возможности отступить, только вперёд. Поначалу это пугало, однако теперь мне очевидны все плюсы такого испытания:
- Ты начинаешь общаться со всей командой как никогда, так как нету никакого прокси для общения: ни тест-менеджера, ни коллег тестировщиков.
- Погружение в проект становится невероятно глубоким, и ты владеешь информацией обо всех компонентах как в общем, так и в подробностях.
- Разработчики не смотрят на тебя как на «того парня из тестирования, который непонятно чем занимается», а скорее, как на равного, производящего невероятную выгоду для команды своими автотестами и предвидением появления багов в конкретном узле продукта.
- Как результат — ты более эффективен, более квалифицирован, более востребован.
По мере разрастания проекта в 100% случаев я становился наставником для вновь пришедших на него тестировщиков, обучал их и передавал те знания, которым научился сам. При этом, в зависимости от проекта, я не всегда получал от руководства специалистов по авто тестированию высочайшего уровня и была необходимость либо обучать их автоматизации (для желающих), либо создавать инструменты для использования ими в повседневных активностях (инструменты генерации данных и их загрузки в систему, инструмент для проведения нагрузочного тестирования/тестирования стабильности «по-быстренькому» и т.п.).
Пример конкретного проекта
К сожалению, в силу обязательств о неразглашении я не могу подробно рассказывать о проектах, на которых я работал, однако приведу примеры типичных задач Data Quality Engineer на одном из проектов.
Суть проекта — реализовать платформу для подготовки данных для обучения на их основе моделей машинного обучения. Заказчиком была крупная фармацевтическая компания из США. Технически это был кластер , поднимающийся на инстансах, с несколькими микросервисами и лежащим в основе Open Source проектом компании EPAM — , адаптированным под нужды конкретного заказчика (сейчас проект перерожден в ). ETL-процессы были организованы при помощи и перемещали данные из системы заказчика в Buckets. Далее на платформу деплоился докер образ модели машинного обучения, которая обучалась на свежих данных и по REST API интерфейсу выдавала предсказания, интересующие бизнес и решающие конкретные задачи.
Визуально всё выглядело примерно так:
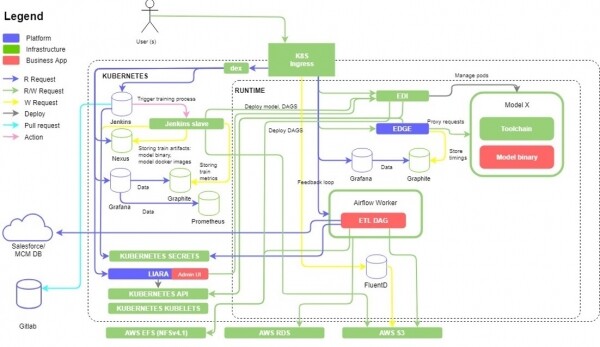
Функционального тестирования на этом проекте было предостаточно, а учитывая скорость разработки фичей и необходимости поддержания темпов релизного цикла (двухнедельные спринты), необходимо было сразу задумываться об автоматизации тестирования самых критичных узлов системы. Большая часть самой платформы с Kubernetes основой покрывалась автотестами, реализованными на + Python, но поддерживать и расширять их также было нужно. Кроме того, для удобства заказчика, был создан GUI для управления моделями машинного обучения, задеплоенными на кластер, а также возможность указать откуда и куда необходимо перенести данные для обучения моделей. Это обширное дополнение повлекло за собой расширение автоматизированных функциональных проверок, которые по большей части делались через REST API вызовы и небольшое количество end-2-end UI-тестов. Примерно на экваторе всего этого движения к нам присоединился ручной тестировщик, который отлично справлялся с приёмочным тестированием версий продукта и общением с заказчиком по поводу приёмки очередного релиза. Кроме того, за счёт появления нового специалиста мы смогли документировать нашу работу и добавить несколько очень важных ручных проверок, которые было трудно сразу автоматизировать.
И наконец, после того как мы добились стабильности от платформы и GUI надстройкой над ней мы приступили к построению ETL pipelines при помощи Apache Airflow DAGs. Автоматизированная проверка качества данных осуществлялась при помощи написания специальных Airflow DAGs которые проверяли данные по результатам работы ETL процесса. В рамках этого проекта нам повезло, и заказчик предоставил нам доступ к обезличенным наборам данных, на которых мы и тестировались. Проверяли данные построчно на соответствие типам, наличие битых данных, общее количество записей до и после, сравнение произведенных ETL-процессом преобразований по агрегации, изменению названий колонок и прочего. Кроме того, эти проверки были масштабированы на разные источники данных, например кроме SalesForce ещё и на MySQL.
Проверки конечного качества данных осуществлялись уже на уровне S3, где они хранились и были в состоянии ready-to-use для обучения моделей машинного обучения. Для получения данных из конечного CSV файла, лежащего на S3 Bucket и их валидации, был написан код с использованием .
Также со стороны заказчика было требование на хранение части данных в одном S3 Bucket’e, части в другом. Для этого также потребовалось писать дополнительные проверки, контролирующие достоверность такой сортировки.
Обобщённый опыт по другим проектам
Пример самого обобщённого перечня активностей Data Quality инженера:
- Подготовить тестовые данные (валидныеневалидныебольшиемаленькие) через автоматизированный инструмент.
- Загрузить подготовленный набор данных в исходный источник и проверить его готовность к использованию.
- Запустить ETL-процессы по обработке набора данных из исходного хранилища в окончательное или промежуточное с применением определённого набора настроек (в случае возможности задать конфигурируемые параметры для ETL-задачи).
- Верифицировать обработанные ETL-процессом данные на предмет их качества и соответствие бизнес-требованиям.
При этом основной акцент проверок должен приходиться не только на то, что поток данных в системе в принципе отработал и дошёл до конца (что является частью функционального тестирования), а по большей части на проверку и валидацию данных на предмет соответствия ожидаемым требованиям, выявления аномалий и прочего.
Mjetet
Одной из техник такого контроля за данными может быть организация цепных проверок на каждой стадии обработки данных, так называемый в литературе «data chain» — контроль данных от источника до пункта финального использования. Такого рода проверки чаще всего реализуются за счёт написания проверяющих SQL-запросов. Понятное дело, что такие запросы должны быть максимально легковесными и проверяющими отдельные куски качества данных (tables metadata, blank lines, NULLs, Errors in syntax — другие требуемые проверки атрибуты).
В случае регрессионного тестирования, в котором используются уже готовые (неизменяемыенезначительно изменяемые) наборы данных, в коде автотестов могут храниться уже готовые шаблоны проверки данных на соответствие качеству (описания ожидаемых метаданных таблиц; строчных выборочных объектов, которые могут выбираться случайно в ходе теста, и прочее).
Также в ходе тестирования приходится писать тестовые ETL-процессы, при помощи таких фреймворков как Apache Airflow, или вовсе black-box cloud инструмент типа , и прочее. Это обстоятельство заставляет тест-инженера погрузиться в принципы работы вышеуказанных инструментов и ещё более эффективно как проводить функциональное тестирование (например, существующих на проекте ETL-процессов), так и использовать их для проверки данных. В частности, для Apache Airflow имеются уже готовые операторы для работы с популярными аналитическими базами данных, например . Самый базовый пример его использования уже изложен , поэтому не буду повторяться.
Кроме готовых решений, никто не запрещает вам реализовывать свои техники и инструменты. Это не только будет пользой для проекта, но и для самого Data Quality Engineer, который тем самым прокачает свой технический кругозор и навыки кодирования.
Как это работает на реальном проекте
Хорошей иллюстрацией последних абзацев про «data chain», ETL и вездесущие проверки является следующий процесс с одного из реальных проектов:
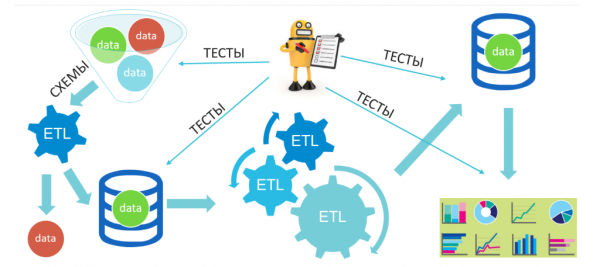
Здесь во входную «воронку» нашей системы попадают разные данные (естественно, нами и подготовленные): валидные, невалидные, смешанные и т. п., потом они фильтруются и попадают в промежуточное хранилище, затем их снова ждёт ряд преобразований и помещение в конечное хранилище, из которого, в свою очередь, и будет производится аналитика, построение витрин данных и поиск бизнес-инсайтов. В такой системе мы, не проверяя функционально работу ETL-процессов, фокусируемся на качестве данных до и после преобразований, а также на выходе в аналитику.
Резюмируя вышесказанное, вне зависимости от мест, где я работал, везде был вовлечён в Data-проекты, которые объединяли следующие черты:
- Только через автоматизацию можно проверить некоторые кейсы и достичь приемлемого для бизнеса релизного цикла.
- Тестировщик на таком проекте — один из самых уважаемых членов команды, так как приносит огромную пользу каждому из участников (ускорение тестирования, хорошие данные у Data Scientist, выявление дефектов на ранних этапах).
- Неважно на своём железе вы работаете или в облаках — все ресурсы абстрагированы в кластер типа Hortonworks, Cloudera, Mesos, Kubernetes и т. п.
- Проекты строятся на микросервисном подходе, преобладают распределённые и параллельные вычисления.
Отмечу, что, занимаясь тестированием в области Data Quality, специалист по тестированию смещает свой профессиональный фокус на код продукта и используемых инструментов.
Отличительные особенности Data Quality тестирования
Кроме того, для себя я выделил следующие (сразу оговорюсь ОЧЕНЬ обобщённые и исключительно субъективные) отличительные черты тестирования в Data (Big Data) проектах (системах) и других направлениях:

Linqe të dobishme
- Теория: .
- EPAM
- Рекомендуемые материалы для начинающего Data Quality инженера:
- Бесплатный курс на Stepik: .
- Курс на LinkedIn Learning: .
- Статьи:
- ;
- ;
- ;
- Video:
- ;
- ;
Përfundimi
Data Quality — это очень молодое перспективное направление, быть частью которого означает быть частью некоего стартапа. Попав в Data Quality, вы окунётесь в большое количество современных востребованных технологий, но самое главное — перед вами откроются огромные возможности для генерирования и реализаций своих идей. Вы сможете использовать подход постоянного улучшения не только на проекте, но и для себя, непрерывно развиваясь как специалист.
Burimi: habr.com
