

Përshëndetje, Habr!
В свете текущих событий из-за коронавируса ряд интернет-сервисов стал получать увеличенную нагрузку. Например, , так как не хватило мощностей. И далеко не всегда можно ускорить сервер, просто добавив более мощное оборудование, однако запросы клиентов обрабатывать надо (или они уйдут к конкурентам).
В этой статье я кратко расскажу о популярных практиках, которые позволят сделать быстрый и отказоустойчивый сервис. Однако из возможных схем разработки я отобрал только те, которыми сейчас легко воспользоваться. Для каждого пункта у вас или есть уже готовые библиотеки, или есть возможность решить задачу с помощью облачной платформы.
Горизонтальное масштабирование
Самый простой и всем известный пункт. Условно, наиболее часто встречаются две схемы распределения нагрузки — горизонтальное и вертикальное масштабирования. вы позволяете сервисам работать параллельно, тем самым распределяя нагрузку между ними. вы заказываете более мощные серверы или оптимизируете код.
Для примера я возьму абстрактное облачное хранилище файлов, то есть некоторый аналог OwnCloud, OneDrive и так далее.
Стандартная картинка подобной схемы ниже, однако она лишь демонстрирует сложность системы. Ведь нам необходимо как-то синхронизовать сервисы. Что будет, если с планшета пользователь сохранил файл, а потом хочет его посмотреть с телефона?
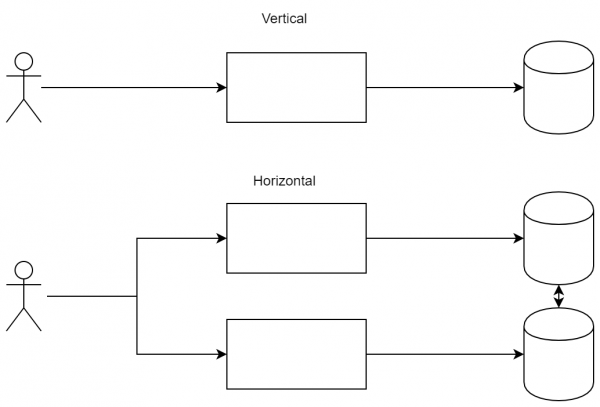
Разница между подходами: в вертикальном масштабировании мы готовы наращивать мощность узлов, а в горизонтальном — добавлять новые узлы, чтобы распределить нагрузку.
CQRS
довольно важный паттерн, так как он позволяет разным клиентам не только подключаться к разным сервисам, но и также получать одинаковые потоки событий. Его бонусы не столь очевидны для простого приложения, однако он крайне важен (и прост) для нагруженного сервиса. Его суть: входящие и исходящие потоки данных не должны пересекаться. То есть вы не можете отправить запрос и ожидать ответ, вместо этого вы отправляете запрос в сервис A, однако получаете ответ в сервисе Б.
Первый бонус этого подхода — возможность разрыва соединения (в широком смысла этого слова) в процессе выполнения долгого запроса. Для примера возьмем более-менее стандартную последовательность:
- Клиент отправил запрос на сервер.
- Сервер запустил долгую обработку.
- Сервер ответил клиенту результатом.
Представим, что в пункте 2 произошел обрыв связи (или сеть переподключилась, или пользователь перешёл на другую страницу, оборвав соединение). В этом случае серверу будет сложно отправить ответ пользователю с информацией, что именно обработалось. Применяя CQRS, последовательность будет немного иной:
- Клиент подписался на обновления.
- Клиент отправил запрос на сервер.
- Сервер ответил «запрос принят».
- Сервер ответил результатом через канал из пункта «1».
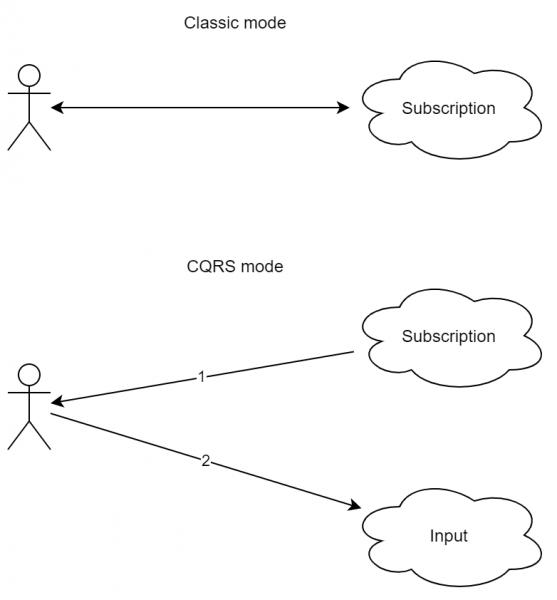
Как видно, схема чуть более сложная. Более того, интуитивный подход request-response здесь отсутствует. Однако как видно, обрыв связи в процессе обработки запроса не приведет к ошибке. Более того, если на самом деле пользователь подключен к сервису с нескольких устройств (например, с мобильного телефона и с планшета), можно сделать так, чтобы ответ приходил на оба устройства.
Что интересно, код обработки входящих сообщений становится одинаковым (не на 100%) как для событий, на которые повлиял сам клиент, так и для остальных событий, в том числе от других клиентов.
Однако в реальности мы получаем дополнительные бонусы в связи с тем, что однонаправленный поток можно обрабатывать в функциональном стиле (используя RX и аналоги). И вот это уже серьезный плюс, так как по сути приложение можно сделать полностью реактивным, причем еще с применением функционального подхода. Для жирных программ это может существенно сэкономить ресурсы на разработку и поддержку.
Если объединить этот подход с горизонтальным масштабированием, то бонусом мы получаем возможность отправлять запросы на один сервер, а получать ответы от другого. Таким образом, клиент может сам выбирать удобный для него сервис, а система внутри всё равно сможет корректным образом обработать события.
Event Sourcing
Как вы знаете, одной из основных особенностей распределенной системы является отсутствие общего времени, общей критической секции. Для одного процесса вы можете сделать синхронизацию (на тех же мьютексах), внутри которой вы уверены, что никто больше не выполняет этот код. Однако для распределенной системы подобное опасно, так как на это потребуются накладные расходы, а также убьется вся прелесть масштабирования — всё равно все компоненты будут ждать одного.
Отсюда получаем важный факт — быструю распределенную систему нельзя синхронизовать, ибо тогда мы уменьшим производительность. С другой стороны, зачастую нам необходима определенная согласованность компонентов. И для этого можно использовать подход с , где гарантируется, что в отсутствие изменений данных через какой-то промежуток времени после последнего обновления («в конечном счёте») все запросы будут возвращать последнее обновлённое значение.
Важно понимать, что для классических баз данных довольно часто применяется , где каждый узел владеет одинаковой информацией (подобное часто достигается в случае, когда транзакция считается установленной только после ответа второго сервера). Здесь есть некоторые послабления из-за уровней изоляции, однако общая суть остается той же — вы можете жить в полностью согласованном мире.
Однако вернемся к изначальной задаче. Если часть системы может быть построена с , то можно построить следующую схему.
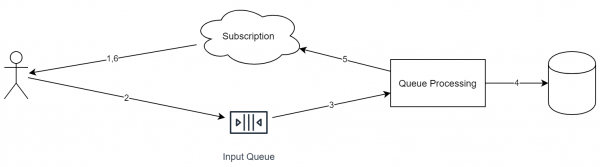
Важные особенности этого подхода:
- Каждый входящий запрос помещается в одну очередь.
- В процессе обработки запроса сервис может также помещать задачи в другие очереди.
- У каждого входящего события есть идентификатор (который необходим для дедупликации).
- Очередь идеологически работает по схеме "append only". Из неё нельзя удалять элементы или переставлять их.
- Очередь работает по схеме FIFO (извините за тавтологию). Если необходимо сделать параллельное выполнение, то следует в одном из этапов перекладывать объекты в разные очереди.
Напомню, что мы рассматриваем случай онлайн файлового хранилища. В этом случае система будет выглядеть, примерно, так:
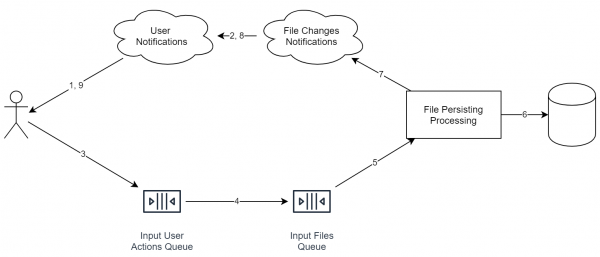
Важно, что сервисы на диаграмме не обязательно означают отдельный сервер. Даже процесс может быть один и тот же. Важно другое: идеологически эти вещи разделены таким образом, чтобы можно было легко применить горизонтальное масштабирование.
А для двух пользователей схема будет выглядеть так (сервисы, предназначенные разным пользователям, обозначены разным цветом):
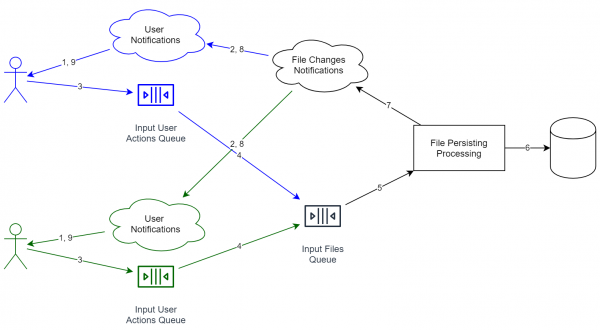
Бонусы от подобной комбинации:
- Сервисы обработки информации разделены. Очереди также разделены. Если нам потребуется увеличить пропускную способность системы, то надо всего лишь запустить больше сервисов на большем числе серверов.
- Когда мы получаем информацию от пользователя, нам не обязательно дожидаться полного сохранения данных. Наоборот, нам достаточно ответить «ок», а потом постепенно начать работу. Заодно очередь сглаживает пики, так как добавление нового объекта происходит быстро, а полного прохода по всему циклу пользователю ждать не обязательно.
- Для примера я добавил сервис дедупликации, который пытается объединять одинаковые файлы. Если он долго работает в 1% случаев, клиент этого практически не заметит (см. выше), что является большим плюсом, так как от нас уже не требуется стопроцентная скорость и надежность.
Однако сразу же видны и минусы:
- У нашей системы пропала строгая согласованность. Это значит, что если, например, подписаться к разным сервисам, то теоретически можно получить разное состояние (так как один из сервисов может не успеть принять уведомление от внутренней очереди). Как еще одно следствие, у системы теперь нет общего времени. То есть нельзя, например, сортировать все события просто по времени прихода, так как часы между серверами могут не быть синхронными (более того, одинаковое время на двух серверах — это утопия).
- Никакие события нельзя теперь просто откатить (как можно было бы сделать с базой данных). Вместо этого необходимо добавить новое событие — , который будет менять последнее состояние на необходимое. Как пример из схожей области: без перезаписи истории (что плохо в ряде случаев) в git нельзя откатить коммит, однако можно сделать специальный , который по сути просто вернет старое состояние. Однако в истории сохранится и ошибочный коммит, и rollback.
- Схема данных может меняться от релиза к релизу, однако старые события теперь не получится обновить на новый стандарт (так как события в принципе нельзя менять).
Как видно, Event Sourcing отлично уживается с CQRS. Более того, реализовать систему с эффективными и удобными очередями, однако без разделения потоков данных, уже само по себе сложно, ведь придется добавлять точки синхронизации, которые будут нивелировать весь положительный эффект от очередей. Применяя оба подхода сразу, необходимо незначительно скорректировать код работы программы. В нашем случае, при отправке файла на сервер, в ответе приходит только «ок», что значит лишь, что «операция добавления файла сохранена». Формально, это не означает, что данные уже доступны на других устройствах (например, сервис дедупликации может перестраивать индекс). Однако через некоторое время клиенту придет уведомление в стиле «файл Х сохранен».
Как результат:
- Число статусов отправки файлов увеличивается: вместо классического «файл отправлен» мы получаем два: «файл добавлен в очередь на сервере» и «файл сохранен в хранилище». Последнее означает, что другие устройства уже могут начать получать файл (с поправкой на то, что очереди работают с разной скоростью).
- Из-за того, что информация об отправке теперь приходит по разным каналам, нам необходимо придумывать решения, чтобы получать статус обработки файла. Как следствие из этого: в отличие от классического request-response, клиент может быть перезапущен в процессе обработки файла, однако статус этой самой обработки будет корректен. Причем этот пункт работает, по сути, из коробки. Как следствие: мы теперь более толерантны к отказам.
Sharding
Как уже описывалось выше, в системах с event sourcing отсутствует строгая согласованность. А значит мы можем использовать несколько хранилищ без какой-либо синхронизации между ними. Приближаясь к нашей задаче, мы можем:
- Разделять файлы по типам. Например, картинки/видео можно декодировать и выбирать более эффективный формат.
- Разделять аккаунты по странам. Из-за многих законов подобное может потребоваться, однако эта схема архитектуры дает подобную возможность автоматически
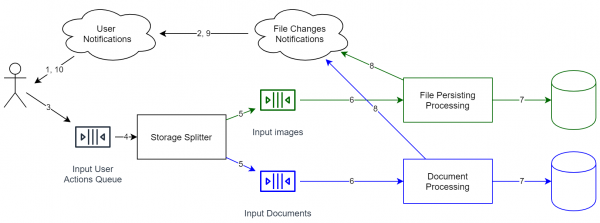
Если вы хотите перенести данные из одного хранилища в другое, то здесь уже стандартными средствами не обойтись. К сожалению, в таком случае необходимо остановить очередь, сделать миграцию, а потом запустить её. В общем случае «на лету» данные не перенести, однако, если очередь событий хранится полностью, и у вас есть слепки предыдущих состояний хранилища, то мы можем перепроиграть события следующим образом:
- В Event Source каждое событие имеет свой идентификатор (в идеале — не уменьшающийся). А значит в хранилище мы можем добавить поле — id последнего обработанного элемента.
- Дублируем очередь, чтобы все события могли обрабатываться для нескольких независимых хранилищ (первое — это то, в котором уже сейчас хранятся данные, а второе — новое, однако пока пустое). Вторая очередь, естественно, пока не обрабатывается.
- Запускаем вторую очередь (то есть начинаем перепроигрывание событий).
- Когда новая очередь будет относительно пуста (т.е. средняя разница во времени между добавлением элемента и его же извлечением будет приемлема), можно начинать переключать читателей на новое хранилище.
Как видно, у нас в системе как не было, так и нет строгой согласованности. Есть только eventual constistency, то есть гарантия того, что события обрабатываются в одинаковом порядке (однако, возможно, с разной задержкой). И, пользуясь этим, мы можем сравнительно легко перенести данные без остановки системы на другой конец земного шара.
Таким образом, продолжая наш пример про онлайн хранилище для файлов, подобная архитектура уже дает нам ряд бонусов:
- Мы можем перемещать объекты ближе к пользователям, причем динамическим образом. Тем самым можно повысить качество сервиса.
- Мы можем хранить часть данных внутри компаний. Например, Enterprise пользователи зачастую требуют хранить их данные в подконтрольных датацентрах (во избежание утечек данных). За счет sharding мы можем влегкую это поддержать. И задача еще упрощается, если у заказчика есть совместимое облако (например, ).
- А самое важное — мы можем этого не делать. Ведь для начала нас вполне бы устроило одно хранилище для всех аккаунтов (чтобы побыстрее начать работать). И ключевая особенность этой системы — хоть она и расширяема, на начальном этапе она достаточно проста. Просто не надо сразу писать код, работающий с миллионом отдельных независимых очередей и т.д. Если понадобится, то это можно сделать в будущем.
Static Content Hosting
Этот пункт может показаться совсем очевидным, однако он все равно необходим для более-менее стандартного нагруженного приложения. Его суть проста: весь статический контент раздается не с того же сервера, где находится приложение, а со специальных, выделенных именно под это дело. Как следствие, эти операции выполняются быстрее (условный nginx отдает файлы и оперативнее, и менее затратно, чем Java-сервер). Плюс архитектура CDN () позволяет располагать наши файлы ближе к конечным пользователям, что положительно сказывается на удобстве работы с сервисом.
Самый простой и стандартный пример статического контента — это набор скриптов и картинок для сайта. С ними всё просто — они известны заранее, далее архив выгружается на CDN серверы, откуда раздаются конечным пользователям.
Однако на деле для статического контента можно применить подход чем-то похожий на лямбда архитектуру. Вернемся к нашей задаче (онлайн хранилище файлов), в которой нам необходимо раздавать файлы пользователям. Самое простое решение в лоб — сделать сервис, который для каждого запроса пользователя делает все необходимые проверки (авторизация и тд), а потом скачивает файл непосредственно с нашего хранилища. Главный минус такого подхода — статический контент (а файл с определенной ревизией, по сути, является статическим контентом) раздается тем же сервером, что и содержит бизнес-логику. Вместо этого, можно сделать следующую схему:
- Сервер выдает URL для скачивания. Он может быть вида file_id + key, где key — мини-цифровая подпись, дающая право на доступ к ресурсу на ближайшие сутки.
- Раздачей файла занимается простой nginx со следующими опциями:
- Кэширование контента. Так как этот сервис может находиться на отдельном сервере, мы оставили себе задел на будущее с возможностью хранить все последние скачанные файлы на диске.
- Проверка ключа в момент создания соединения
- Опционально: потоковая обработка контента. Например, если мы сжимаем все файлы в сервисе, то можно сделать разархивирование непосредственно в этом модуле. Как следствие: IO операции сделаны там, где им самое место. Архиватор на Java легко будет выделять много лишней памяти, однако переписывать сервис с бизнес-логикой на условные Rust/C++ может оказаться тоже неэффективным. В нашем же случае используются разные процессы (или даже сервисы), а потому можно довольно эффективно разделить бизнес логику и IO операции.
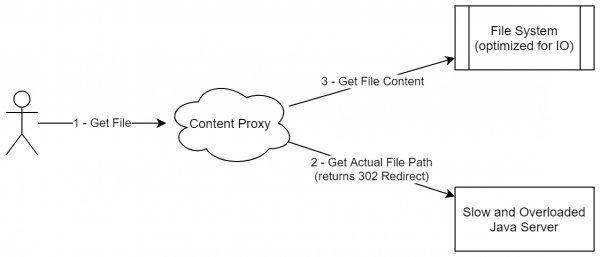
Подобная схема не очень похожа на раздачу статического контента (так как мы не выгружаем весь пакет статики куда-то), однако в реальности подобный подход именно и занимается раздачей неизменяемых данных. Более того, эту схему можно обобщать и на другие случаи, когда контент не просто статический, а может быть представлен в виде набора неизменяемых и неудаляемых блоков (хотя они и могут добавляться).
Как еще пример (для закрепления): если вы работали с Jenkins/TeamCity, то знаете, что оба решения написаны на Java. Оба они представляют собой Java-процесс, который занимается как оркестрацией билдов, так и менеджментом контента. В частности, у них обоих есть задачи вида "передать файл/папку с сервера". Как пример: выдача артефактов, передача исходного кода (когда агент не скачивает код напрямую из репозитория, а за него это делает сервер), доступ к логам. Все эти задачи отличаются нагрузкой на IO. То есть получается, что сервер, отвечающий за сложную бизнес-логику, заодно должен уметь эффективно проталкивать через себя большие потоки данных. И что самое интересное, подобную операцию можно сделегировать тому же nginx’у по ровно той же схеме (разве что в запрос следует добавлять ключ данных).
Однако если вернуться к нашей системе, то получается подобная схема:
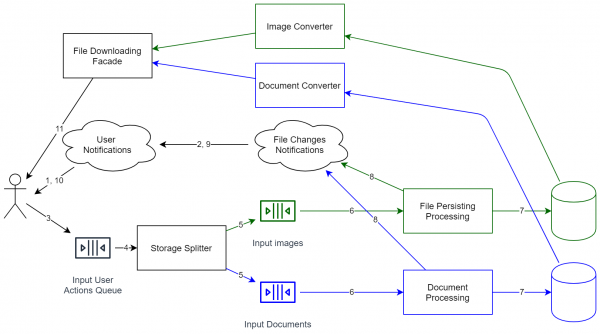
Как видно, система радикально усложнилась. Теперь это не просто мини-процесс, который хранит файлы локально. Теперь требуется уже не самая простая поддержка, контроль за версиями API и т.д. Поэтому после того, как все диаграммы нарисованы, лучше всего детально оценить, стоит ли расширяемость подобных затрат. Однако если вы хотите иметь возможность расширять систему (в том числе и для работы с еще большим числом пользователей), то придется пойти на подобные решения. Зато, как результат, система архитектурна готова к увеличению нагрузки (практически каждый компонент можно клонировать для горизонтального масштабирования). Систему можно обновлять без её остановки (просто-напросто некоторые операции незначительно затормозятся).
Как я уже говорил в самом начале, сейчас ряд интернет-сервисов стал получать увеличенную нагрузку. И некоторые из них просто стали прекращать правильно работать. По сути системы отказали именно в тот момент, когда бизнес как раз должен делать деньги. То есть вместо отложенной доставки, вместо предложения клиентам «распланируйте поставку на ближайшие месяцы», система просто сказала «идите к конкурентам». Собственно, это и есть цена низкой производительности: потери произойдут именно тогда, когда прибыль была бы наивысшей.
Përfundimi
Все эти подходы были известны и раньше. Тот же VK давно уже использует идею Static Content Hosting для выдачи картинок. Куча онлайн-игр используют Sharding схему для разделения игроков по регионам или же для разделения игровых локаций (если сам мир единый). Event Sourcing подход активно используется в электронной почте. Большинство приложений трейдеров, где непрерывно приходят данные, на самом деле построены на CQRS подходе, чтобы иметь возможность фильтровать получаемые данные. Ну и горизонтально масштабирование достаточно давно применяется во многих сервисах.
Однако, что самое важное, все эти паттерны стало очень легко применять в современных приложениях (если они к месту, конечно). Облака предлагают Sharding и горизонтальное масштабирование сразу, что намного легче, чем заказывать разные выделенные серверы в разных датацентрах самостоятельно. CQRS стал намного легче хотя бы из-за развития библиотек, таких как RX. Лет 10 назад редкий web сайт смог бы поддержать такое. Event Sourcing настраивается тоже невероятно легко за счет уже готовых контейнеров с Apache Kafka. Лет 10 назад это было бы инновацией, сейчас это обыденность. Аналогично и с Static Content Hosting: из-за более удобных технологий (в том числе и потому, что есть подробная документация и большая база ответов), подобный подход стал еще более простым.
Как итог, реализация ряда довольно сложных архитектурных паттернов теперь стала намного проще, а значит к ней лучше заранее присмотреться. Если в десятилетнем приложении отказались от одного из решений выше по причине высокой цены внедрения и эксплуатации, то теперь, в новом приложении, или же после рефакторинга, можно сделать сервис, который архитектурно уже будет как расширяемым (с точки зрения производительности), так и готовым к новым запросам от клиентов (например, для локализации персональных данных).
И самое важное: не используйте, пожалуйста, эти подходы, если у вас простое приложение. Да, они красивые и интересные, однако для сайта с пиковым посещением в 100 человек зачастую можно обойтись классическим монолитом (по крайней мере снаружи, внутри всё можно разбить на модули и т.д.).
Burimi: habr.com
