


Në këtë artikull do t'ju tregoj se si të konfiguroni një ambient për mësimin e makinerive brenda 30 minutash, të krijoni një rrjet nervor për njohjen e imazheve dhe më pas ta ekzekutoni atë në një procesor grafik (GPU).
Së pari, le të përcaktojmë se çfarë është një rrjet nervor.
Në rastin tonë, kjo është një model matematikor, si dhe një realizim të tij programor ose harduerik, i ndërtuar sipas parimeve të organizimit dhe funksionimit të rrjeteve biologjike nervore — rrjeteve të qelizave nervore të një organizmi të gjallë. Ky koncept ka lindur gjatë studimit të proceseve në tru dhe përpjekjeve për të modeluar këto procese.
Rrjetet nervore nuk programohen në kuptimin e zakonshëm të fjalës, ato mësohen. Mundësia e të mësuarit është një nga avantazhet kryesore të rrjeteve nervore krahasuar me algoritmet tradicionale. Teknikisht, mësimi përfshin gjetjen e koeficientëve të lidhjeve midis neuronëve. Gjatë procesit të të mësuarit, rrjeti nervor është në gjendje të zbulojë lidhje komplekse midis të dhënave hyrëse dhe dalëse, si dhe të kryejë përmbledhje.
Nga pikëpamja e mësimit të makinave, rrjeti nervor paraqet një rast të veçantë të metodave të njohjes së modeleve, analizës diskriminuese, metodave të klasterizimit dhe metodave të tjera.
Pajisjet
Fillimisht le të merremi me pajisjet. Na nevojitet një server me një sistem operativ Linux të instaluar. Pajisjet për funksionimin e sistemeve të mësimit të makinave kërkojnë të jenë mjaft të fuqishme dhe si pasojë të shtrenjta. Atëherë, ata që nuk kanë një makinë të mirë në duar, rekomandoj të shikoni ofertat e ofruesve të mjeteve kriptuese. Serveri i nevojshëm mund të merret me qira shpejt dhe të paguani vetëm për kohën e përdorimit.
Në projektet ku nevojitet krijimi i rrjeteve nervore, unë përdor servera nga një nga ofruesit e mjeteve kriptuese rusë. Kompania ofron servera cloud për mësimin e makinave me procesorë grafikë të fuqishëm (GPU) Tesla V100 nga NVIDIA. Nëse flasim shkurtimisht: përdorimi i një serveri me GPU mund të jetë deri në disa herë më efektiv (më i shpejtë) se një server i ngjashëm në kosto ku për llogaritjet përdoret CPU (procesori qendror që të gjithë e njohin mirë). Kjo arrihet përmes veçorive të arkitekturës GPU, e cila është më e shpejtë në llogaritjet.
Për të zbatuar shembujt e përshkruar më poshtë, ne kemi marrë me qira një server të tillë për disa ditë:
- Disk SSD 150 GB
- RAM 32 GB
- Procesori Tesla V100 16 Gb me 4 bërthama
Në makinë na instaluan Ubuntu 18.04.
Instaloni ambientin
Tani do të instalojmë në server gjithçka e nevojshme për punë. Meqë artikulli ynë është kryesisht për fillestarët, do të flas për disa momente që do t'u vijnë në ndihmë atyre.
Shumë punë gjatë konfigurimit të ambientit kryhet përmes komandës në linjë. Shumica e përdoruesve përdorin Windows si sistem operativ punues. Konsola standarde në këtë OS lë për të dëshiruar. Prandaj, ne do të përdorim një zhvillues të përshtatshëm. . Shkarko mini versionin dhe ekzekuto Cmder.exe. Më pas është e nevojshme të lidheni me serverin përmes protokollit SSH:
ssh root@server-ip-or-hostnameNë vend të server-ip-or-hostname, vendosni adresën IP ose emrin DNS të serverit tuaj. Më pas, futni fjalëkalimin dhe me një lidhje të suksesshme duhet të marrim një mesazh të tillë.
Mirë se vini në Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)Gjuha kryesore për zhvillimin e modeleve ML është Python. Dhe platforma më popullore për përdorimin e tij në Linux është .
Do ta instalojmë atë në serverin tonë.
Fillojmë me përditësimin e menaxherit lokal të paketave:
sudo apt-get updateInstaloni curl (programin e komandës):
sudo apt-get install curlShkarkoni versionin më të fundit të Anaconda Distribution:
cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.shFilloni instalimin:
bash Anaconda3-2019.10-Linux-x86_64.shGjatë procesit të instalimit, do t'ju kërkohet të konfirmoni marrëveshjen e licencës. Pas një instalimi të suksesshëm, duhet të shihni këtë:
Faleminderit që e instaluat Anaconda3!Për zhvillimin e modeleve ML tani janë krijuar shumë framework-e, ne punojmë me framework-et më të njohura: dhe .
Përdorimi i një framework-u ndihmon për të rritur shpejtësinë e zhvillimit dhe për të përdorur mjete të gatshme për detyra standarde.
Në këtë shembull do të punojmë me PyTorch. Do ta instalojmë atë:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorchTani na nevojitet të nisnim Jupyter Notebook — një mjet i njohur për specialistët e ML për zhvillim. Ai lejon të shkruani kod dhe menjëherë të shihni rezultatet e ekzekutimit të tij. Jupyter Notebook është pjesë e Anaconda dhe tashmë është instaluar në serverin tonë. Duhet të lidhemi me të nga sistemi ynë desktop.
Për këtë, së pari ne do ta nisnim Jupyter në server duke treguar portin 8080:
jupyter notebook --no-browser --port=8080 --allow-rootMë pas, hapim një skedë tjetër në konsolën tonë Cmder (menyja e sipërme — Dialogu i ri i konsolës) dhe lidhim përmes portit 8080 me serverin përmes SSH:
ssh -L 8080:localhost:8080 root@server-ip-or-hostnameDhe, gjatë futjes së komandës së parë do të na ofrohen lidhjet për të hapur Jupyter në shfletuesin tonë:
Për të aksesuar notebook-un, hapni këtë skedar në një shfletues:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Ose kopjoni dhe ngjitni një nga këto URL:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
ose http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Do të përdorim lidhjen për localhost:8080. Kopjoni rrugën e plotë dhe ngjitni në shiritin e adresës së shfletuesit tuaj lokal. Do të hapet Jupyter Notebook.
Krijojmë një notebook të ri: New — Notebook — Python 3.
Do të verifikojmë funksionimin e duhur të të gjithëve komponentëve që kemi instaluar. Do të fusim në Jupyter një shembuj kodi PyTorch dhe do të fillojmë ekzekutimin (butoni Run):
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Rezultati duhet të jetë pak a shumë si ky:
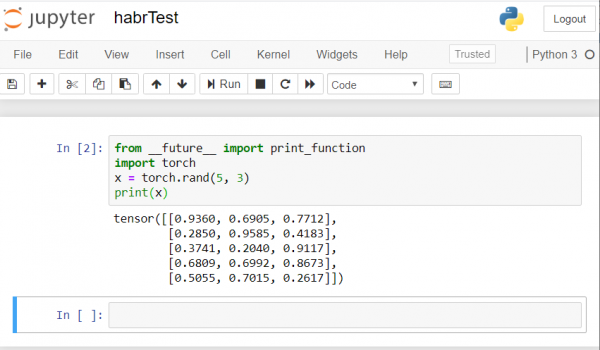
Nếu gið çfarë do të keni një rezultat të tillë — do të thotë se kemi konfiguruar gjithçka në mënyrë të saktë dhe tani mund të fillojmë zhvillimin e rrjetit nervor!
Krijojmë një rrjet nervor
Ne do të krijojmë një rrjet nervor për njohjen e imazheve. Si bazë do të marrim këtë .
Për trajnimin e rrjetit do të përdorim një set të dhënash publik të quajtur CIFAR10. Ai ka klasat: "avion", "makinë", "zgërdhime", "mace", "deer", "qen", "kurë", "kalë", "anije", "kamion". Imaginat në CIFAR10 kanë përmasat 3x32x32, dmth imazhe ngjyrë 3-kanalësh me përmasa 32×32 piksele.

Për punë do të përdorim paketën e krijuar të PyTorch për punë me imazhe — torchvision.
Ne do të kryejmë hapat e mëposhtëm në rend:
- Shkarkimi dhe normalizimi i grupeve të të dhënave të trajnimit dhe testimit
- Përcaktimi i rrjetit nervor
- Trajnimi i rrjetit me të dhënat e trajnimit
- Testimi i rrjetit me të dhënat e testimit
- Rivendosim trajnimin dhe testimin duke përdorur GPU
E gjithë kodi më poshtë do të ekzekutohet në Jupyter Notebook.
Shkarkimi dhe normalizimi i CIFAR10
Kopjoni dhe ekzekutoni në Jupyter kodin e mëposhtëm:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')Përgjigja duhet të jetë e tillë:
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verifiedLe të nxjerrim disa imazhe trajnimi për verifikim:
import matplotlib.pyplot as plt
import numpy as np
# funksionet për të treguar një imazh
def imshow(img):
img = img / 2 + 0.5 # zhbllokohet
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# tregoni disa imazhe trajnimi rastësore
dataiter = iter(trainloader)
images, labels = dataiter.next()
# shfaqni imazhet
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Përcaktimi i rrjetit nervor
Të shohim fillimisht si funksionon rrjeti nervor për njohjen e imazheve. Ky është një rrjet i thjeshtë me lidhje të drejtpërdrejta. Ai merr të dhënat e input-it, i kalon ato përmes disa shtresave njëra pas tjetrës, dhe më në fund, nxjerr rezultatet.
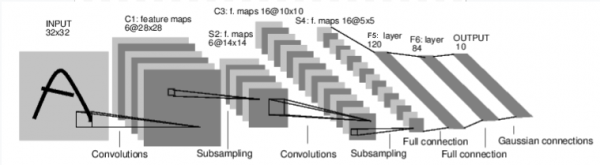
Le të krijojmë një rrjet të ngjashëm në ambientin tonë:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Po ashtu do të përcaktojmë funksionin e humbjes dhe optimizuesin
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)Trajnimi i rrjetit me të dhënat e trajnimit
Fillojmë trajnimin e rrjetit tonë nervor. Vërej se pasi ta nisni këtë kod për ekzekutim, do të duhet të prisni një kohë deri në përfundimin e punës. Mua më ka zënë 5 minuta. Trajnimi i rrjetit kërkon kohë.
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# merrni inputet; të dhënat janë një listë e [inputeve, etiketave]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# përpara + prapa + optimizoni
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, ] humbje: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Trajnimi përfundoi')
Do të marrim një rezultat të tillë:
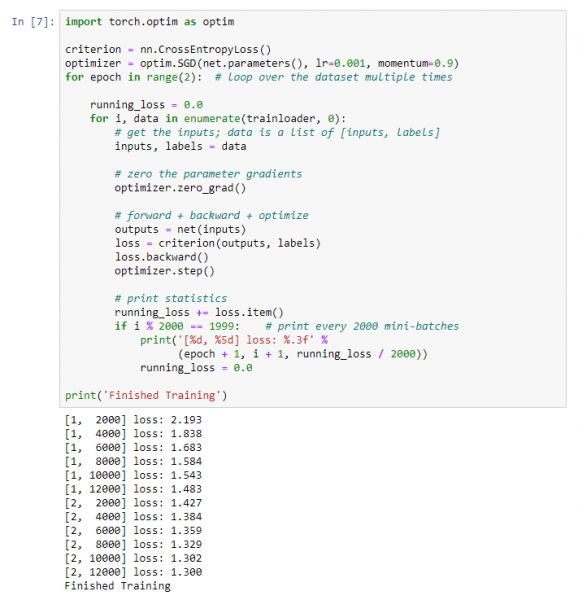
Ruajmë modelin tonë të trajnuar:
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)Testimi i rrjetit me të dhënat e testimit
Kemi trajnuar rrjetin duke përdorur setin e të dhënave të trajnimit. Por na duhet të kontrollojmë, a e ka mësuar rrjeti ndonjë gjë.
Ne do ta një provë duke parashikuar etiketën e klasës që prodhon rrjeti nervor dhe duke e verifikuar atë për saktësi. Nëse parashikimi është i saktë, ne e shtojmë mostrat në listën e parashikimeve të sakta.
Le të shohim një imazh nga grupi i testimit:
dataiter = iter(testloader)
imazhet, etiketat = dataiter.next()
# printo imazhet
imshow(torchvision.utils.make_grid(imazhet))
print('Të Vërtetat: ', ' '.join('%5s' % classes[etiketat[j]] për j në range(4))) 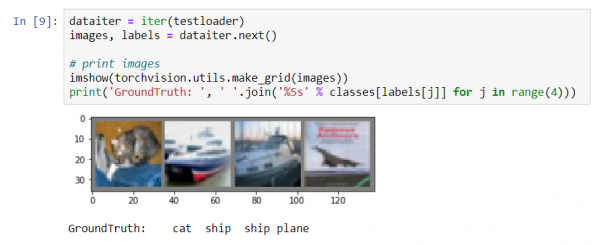
Tani do të kërkojmë nga rrjeti nervor të na tregojë se çfarë është në këto imazhe:
net = Net()
net.load_state_dict(torch.load(PATH))
rezultatet = net(imazhet)
_, parashikuar = torch.max(rezultatet, 1)
print('Parashikuar: ', ' '.join('%5s' % classes[parashikuar[j]]
për j në range(4)))
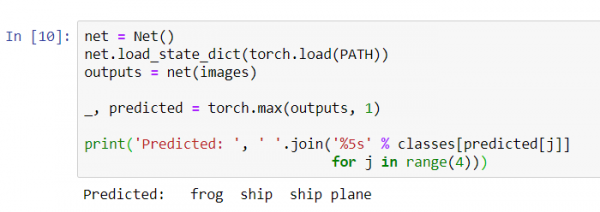
Rezultatet duken mjaft të mira: rrjeti ka identifikuar saktë tre figura nga katër.
Le të shohim se si rrjeti funksionon në të gjithë grupin e të dhënave.
saktë = 0
total = 0
me torch.no_grad():
për të dhënat në testloader:
imazhet, etiketat = të dhënat
rezultatet = net(imazhet)
_, parashikuar = torch.max(rezultatet.data, 1)
total += etiketat.size(0)
saktë += (parashikuar == etiketat).sum().item()
print('Saktësia e rrjetit në 10000 imazhe testuese: %d %%' % (
100 * saktë / total)) 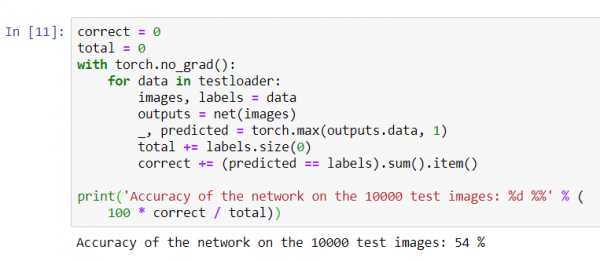
Duket se rrjeti di diçka dhe funksionon. Nëse do të përcaktonte klasat rastësisht, saktësia do të ishte 10%.
Tani le të shohim se cilat klasa përcakton më mirë rrjeti:
class_correct = list(0. për i në range(10))
class_total = list(0. për i në range(10))
me torch.no_grad():
për të dhënat në testloader:
imazhet, etiketat = të dhënat
rezultatet = net(imazhet)
_, parashikuar = torch.max(rezultatet, 1)
c = (parashikuar == etiketat).squeeze()
për i në range(4):
etiketë = etiketat[i]
class_correct[etiketë] += c[i].item()
class_total[etiketë] += 1
për i në range(10):
print('Saktësia e %5s : %%' % (
classes[i], 100 * class_correct[i] / class_total[i])) 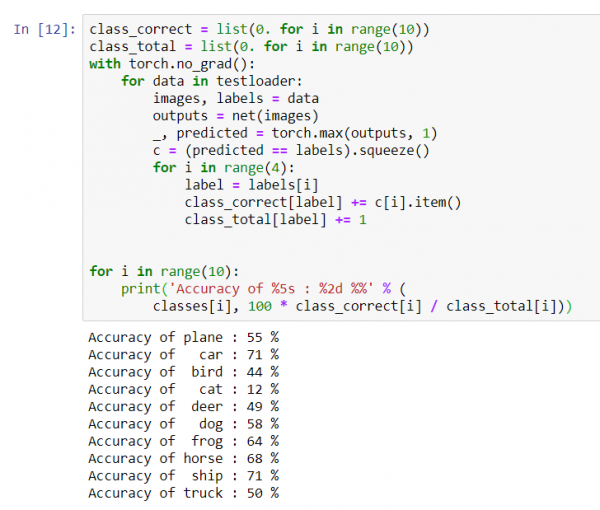
Duket se rrjeti identifikon më mirë makinat dhe anijet: 71% saktësi.
Pra, rrjeti funksionon. Tani do të provojmë ta transferojmë funksionimin e tij në kartën grafike (GPU) dhe të shohim se çfarë do të ndryshojë.
Trajnimi i rrjetit nervor në GPU
Së pari, do të shpjegoj shkurtimisht se çfarë është CUDA. CUDA (Compute Unified Device Architecture) është një platformë për llogaritje paralele, e zhvilluar nga NVIDIA, për llogaritje të përgjithshme në kartat grafike (GPU). Me CUDA, zhvilluesit mund të përshpejtojnë ndjeshëm aplikacionet llogaritëse duke shfrytëzuar kapacitetet e kartave grafike. Në serverin tonë që kemi blerë, kjo platformë është tashmë e instaluar.
Le të përcaktojmë së pari GPU-në tonë si pajisjen e parë të dukshme cuda.
device = torch.device("cuda:0" nëse torch.cuda.is_available() përndryshe "cpu")
# Duke supozuar se jemi në një makinë CUDA, ky duhet të printojë një pajisje CUDA:
print(device) 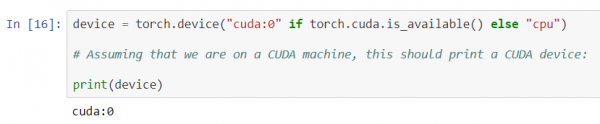
Dërgojmë rrjetin në GPU:
net.to(device)Po ashtu do të duhet të dërgojmë hyrjet dhe objektivat në çdo hap në GPU:
inputet, etiketat = të dhënat[0].to(device), të dhënat[1].to(device)Le të fillojmë rinovimin e rrjetit tashmë në GPU:
import torch.optim si optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
për epokë në range(2): # kaloni mbi grupin e të dhënave disa herë
running_loss = 0.0
për i, të dhënat në enumerate(trainloader, 0):
# merrni hyrjet; të dhënat janë një listë e [hyrjeve, etiketave]
inputet, etiketat = të dhënat[0].to(device), të dhënat[1].to(device)
# zeros gradiencat e parametrave
optimizer.zero_grad()
# përparësia + prapavshtim + optimizim
rezultatet = net(inputet)
humbja = criterion(rezultatet, etiketat)
humbja.backward()
optimizer.step()
# printo statistikën
running_loss += humbja.item()
nëse i % 2000 == 1999: # printo çdo 2000 mini-batch
print('[%d, ] humbja: %.3f' %
(epokë + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Përfundoi Trajnimi')Këtë herë trajnimi i rrjetit zgjati rreth 3 minuta. Të kujtojmë se ky hap në një procesor të zakonshëm zgjati 5 minuta. Diferenca nuk është e rëndësishme, kjo ndodh sepse rrjeti ynë nuk është aq i madh. Duke përdorur grupe të mëdha për trajnimin, diferenca midis shpejtësisë së punës së GPU dhe procesorit tradicional do të rritet.
Kjo duket se është e gjitha. Çfarë kemi arritur të bëjmë:
- Ne shqyrtuam se çfarë është GPU dhe zgjedhëm serverin në të cilin ai është instaluar;
- Ne konfigurua ambientin e programit për krijimin e rrjetit nervor;
- Ne krijuam një rrjet nervor për njohjen e imazheve dhe e stërvitëm atë;
- Ne ritëm trajnimin e rrjetit duke përdorur GPU dhe morëm një përshpejtim në shpejtësi.
Do të ishte kënaqësi të përgjigjem në pyetje në komentet.
Burimi: habr.com
