


SciPy (shqiptohet byrek sai) është një paketë aplikacioni matematikor i bazuar në shtesën Numpy Python. Me SciPy, seanca juaj interaktive e Python bëhet e njëjta shkencë e plotë e të dhënave dhe mjedisi kompleks i prototipit të sistemit si MATLAB, IDL, Octave, R-Lab dhe SciLab. Sot dua të flas shkurtimisht se si të përdorim disa algoritme të mirënjohura optimizimi në paketën scipy.optimize. Ndihmë më e detajuar dhe më e përditësuar për përdorimin e funksioneve mund të merret gjithmonë duke përdorur komandën help() ose duke përdorur Shift+Tab.
Paraqitje
Për të shpëtuar veten dhe lexuesit nga kërkimi dhe leximi i burimeve parësore, lidhjet me përshkrimet e metodave do të jenë kryesisht në Wikipedia. Si rregull, ky informacion është i mjaftueshëm për të kuptuar metodat në terma të përgjithshëm dhe kushtet për zbatimin e tyre. Për të kuptuar thelbin e metodave matematikore, ndiqni lidhjet për botime më autoritare, të cilat mund të gjenden në fund të çdo artikulli ose në motorin tuaj të preferuar të kërkimit.
Pra, moduli scipy.optimize përfshin zbatimin e procedurave të mëposhtme:
- Minimizimi i kushtëzuar dhe i pakushtëzuar i funksioneve skalare të disa variablave (minim) duke përdorur algoritme të ndryshme (Nelder-Mead simplex, BFGS, gradientët e konjuguar të Njutonit, и )
- Optimizimi global (për shembull: , )
- Minimizimi i mbetjeve (katroret më të vogla) dhe algoritmet e përshtatjes së kurbës duke përdorur katrorët më të vegjël jolinearë (kurve_përshtatje)
- Minimizimi i funksioneve skalar të një ndryshoreje (minim_scalar) dhe kërkimi i rrënjëve (root_scalar)
- Zgjidhës shumëdimensionale të sistemit të ekuacioneve (rrënjë) duke përdorur algoritme të ndryshme (hibrid Powell, ose metodat në shkallë të gjerë si p.sh ).
Në këtë artikull do të shqyrtojmë vetëm artikullin e parë nga e gjithë kjo listë.
Minimizimi i pakushtëzuar i një funksioni skalar të disa variablave
Funksioni minimal nga paketa scipy.optimize ofron një ndërfaqe të përgjithshme për zgjidhjen e problemeve të minimizimit të kushtëzuar dhe të pakushtëzuar të funksioneve skalare të disa variablave. Për të demonstruar se si funksionon, do të na duhet një funksion i përshtatshëm i disa variablave, të cilët do t'i minimizojmë në mënyra të ndryshme.
Për këto qëllime, funksioni Rosenbrock i variablave N është i përsosur, i cili ka formën:

Përkundër faktit se funksioni Rosenbrock dhe matricat e tij Jacobi dhe Hessian (derivatet e parë dhe të dytë, përkatësisht) janë përcaktuar tashmë në paketën scipy.optimize, ne do ta përcaktojmë vetë.
import numpy as np
def rosen(x):
"""The Rosenbrock function"""
return np.sum(100.0*(x[1:]-x[:-1]**2.0)**2.0 + (1-x[:-1])**2.0, axis=0)Për qartësi, le të vizatojmë në 3D vlerat e funksionit Rosenbrock të dy variablave.
Kodi i vizatimit
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
from matplotlib import cm
from matplotlib.ticker import LinearLocator, FormatStrFormatter
# Настраиваем 3D график
fig = plt.figure(figsize=[15, 10])
ax = fig.gca(projection='3d')
# Задаем угол обзора
ax.view_init(45, 30)
# Создаем данные для графика
X = np.arange(-2, 2, 0.1)
Y = np.arange(-1, 3, 0.1)
X, Y = np.meshgrid(X, Y)
Z = rosen(np.array([X,Y]))
# Рисуем поверхность
surf = ax.plot_surface(X, Y, Z, cmap=cm.coolwarm)
plt.show()
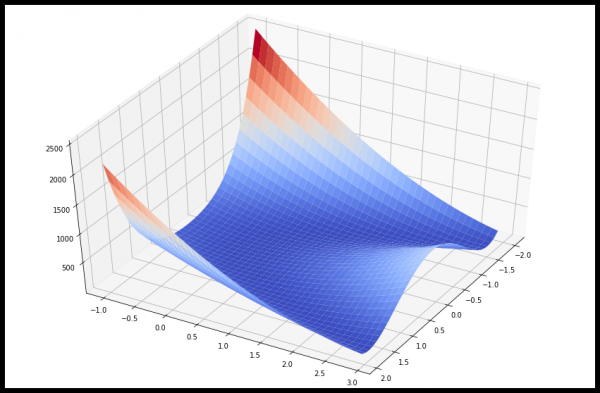
Duke ditur paraprakisht se minimumi është 0 në  , le të shohim shembuj se si të përcaktohet vlera minimale e funksionit Rosenbrock duke përdorur procedura të ndryshme scipy.optimize.
, le të shohim shembuj se si të përcaktohet vlera minimale e funksionit Rosenbrock duke përdorur procedura të ndryshme scipy.optimize.
Metoda Simplex Nelder-Mead
Le të jetë një pikë fillestare x0 në hapësirën 5-dimensionale. Le të gjejmë pikën minimale të funksionit Rosenbrock më afër tij duke përdorur algoritmin (algoritmi specifikohet si vlera e parametrit të metodës):
from scipy.optimize import minimize
x0 = np.array([1.3, 0.7, 0.8, 1.9, 1.2])
res = minimize(rosen, x0, method='nelder-mead',
options={'xtol': 1e-8, 'disp': True})
print(res.x)Optimization terminated successfully.
Current function value: 0.000000
Iterations: 339
Function evaluations: 571
[1. 1. 1. 1. 1.]Metoda Simplex është mënyra më e thjeshtë për të minimizuar një funksion të përcaktuar qartë dhe mjaft të qetë. Nuk kërkon llogaritjen e derivateve të një funksioni, mjafton të specifikohen vetëm vlerat e tij. Metoda Nelder-Mead është një zgjedhje e mirë për problemet e thjeshta të minimizimit. Megjithatë, duke qenë se nuk përdor vlerësime të gradientit, mund të duhet më shumë kohë për të gjetur minimumin.
Metoda Powell
Një tjetër algoritëm optimizimi në të cilin llogariten vetëm vlerat e funksionit është . Për ta përdorur atë, duhet të vendosni metodën = 'powell' në funksionin minimal.
x0 = np.array([1.3, 0.7, 0.8, 1.9, 1.2])
res = minimize(rosen, x0, method='powell',
options={'xtol': 1e-8, 'disp': True})
print(res.x)Optimization terminated successfully.
Current function value: 0.000000
Iterations: 19
Function evaluations: 1622
[1. 1. 1. 1. 1.]Algoritmi Broyden-Fletcher-Goldfarb-Shanno (BFGS).
Për të marrë konvergjencë më të shpejtë në një zgjidhje, procedura përdor gradientin e funksionit objektiv. Gradienti mund të specifikohet si funksion ose të llogaritet duke përdorur diferencat e rendit të parë. Në çdo rast, metoda BFGS zakonisht kërkon më pak thirrje funksionesh sesa metoda simplex.
Le të gjejmë derivatin e funksionit Rosenbrock në formë analitike:


Kjo shprehje është e vlefshme për derivatet e të gjitha variablave përveç të parës dhe të fundit, të cilat përkufizohen si:


Le të shohim funksionin Python që llogarit këtë gradient:
def rosen_der (x):
xm = x [1: -1]
xm_m1 = x [: - 2]
xm_p1 = x [2:]
der = np.zeros_like (x)
der [1: -1] = 200 * (xm-xm_m1 ** 2) - 400 * (xm_p1 - xm ** 2) * xm - 2 * (1-xm)
der [0] = -400 * x [0] * (x [1] -x [0] ** 2) - 2 * (1-x [0])
der [-1] = 200 * (x [-1] -x [-2] ** 2)
return derFunksioni i llogaritjes së gradientit specifikohet si vlera e parametrit jac të funksionit minimal, siç tregohet më poshtë.
res = minimize(rosen, x0, method='BFGS', jac=rosen_der, options={'disp': True})
print(res.x)Optimization terminated successfully.
Current function value: 0.000000
Iterations: 25
Function evaluations: 30
Gradient evaluations: 30
[1.00000004 1.0000001 1.00000021 1.00000044 1.00000092]Algoritmi i gradientit të konjuguar (Njuton)
Algoritmi është një metodë e modifikuar e Njutonit.
Metoda e Njutonit bazohet në përafrimin e një funksioni në një zonë lokale me një polinom të shkallës së dytë:

ku  është matrica e derivateve të dyta (matrica Hessian, Hessian).
është matrica e derivateve të dyta (matrica Hessian, Hessian).
Nëse Hessian-i është i përcaktuar pozitiv, atëherë minimumi lokal i këtij funksioni mund të gjendet duke barazuar gradientin zero të formës kuadratike me zero. Rezultati do të jetë shprehja:

Hessian-i i kundërt llogaritet duke përdorur metodën e gradientit të konjuguar. Një shembull i përdorimit të kësaj metode për të minimizuar funksionin Rosenbrock është dhënë më poshtë. Për të përdorur metodën Newton-CG, duhet të specifikoni një funksion që llogarit Hessian.
Hessian i funksionit Rosenbrock në formë analitike është i barabartë me:


ku  и
и  , përcaktoni matricën
, përcaktoni matricën  .
.
Elementet e mbetur jozero të matricës janë të barabartë me:




Për shembull, në një hapësirë pesë-dimensionale N = 5, matrica Hessian për funksionin Rosenbrock ka formën e një brezi:

Kodi që llogarit këtë Hessian së bashku me kodin për minimizimin e funksionit Rosenbrock duke përdorur metodën e gradientit të konjuguar (Newton):
def rosen_hess(x):
x = np.asarray(x)
H = np.diag(-400*x[:-1],1) - np.diag(400*x[:-1],-1)
diagonal = np.zeros_like(x)
diagonal[0] = 1200*x[0]**2-400*x[1]+2
diagonal[-1] = 200
diagonal[1:-1] = 202 + 1200*x[1:-1]**2 - 400*x[2:]
H = H + np.diag(diagonal)
return H
res = minimize(rosen, x0, method='Newton-CG',
jac=rosen_der, hess=rosen_hess,
options={'xtol': 1e-8, 'disp': True})
print(res.x)Optimization terminated successfully.
Current function value: 0.000000
Iterations: 24
Function evaluations: 33
Gradient evaluations: 56
Hessian evaluations: 24
[1. 1. 1. 0.99999999 0.99999999]Një shembull me përcaktimin e funksionit të produktit të hesianit dhe një vektor arbitrar
Në problemet e botës reale, llogaritja dhe ruajtja e të gjithë matricës Hessian mund të kërkojë kohë dhe burime të konsiderueshme memorie. Në këtë rast, në fakt nuk ka nevojë të specifikoni vetë matricën Hessian, sepse procedura e minimizimit kërkon vetëm një vektor të barabartë me produktin e hesianit me një vektor tjetër arbitrar. Kështu, nga pikëpamja llogaritëse, është shumë e preferueshme të përcaktohet menjëherë një funksion që kthen rezultatin e produktit të Hessian-it me një vektor arbitrar.
Konsideroni funksionin hess, i cili merr vektorin e minimizimit si argument të parë dhe një vektor arbitrar si argument të dytë (së bashku me argumentet e tjera të funksionit që do të minimizohet). Në rastin tonë, llogaritja e produktit të funksionit Hessian të Rosenbrock me një vektor arbitrar nuk është shumë e vështirë. Nëse p është një vektor arbitrar, pastaj produkti  duket si:
duket si:

Funksioni që llogarit produktin e hesianit dhe një vektor arbitrar kalohet si vlerë e argumentit hessp në funksionin minimizues:
def rosen_hess_p(x, p):
x = np.asarray(x)
Hp = np.zeros_like(x)
Hp[0] = (1200*x[0]**2 - 400*x[1] + 2)*p[0] - 400*x[0]*p[1]
Hp[1:-1] = -400*x[:-2]*p[:-2]+(202+1200*x[1:-1]**2-400*x[2:])*p[1:-1]
-400*x[1:-1]*p[2:]
Hp[-1] = -400*x[-2]*p[-2] + 200*p[-1]
return Hp
res = minimize(rosen, x0, method='Newton-CG',
jac=rosen_der, hessp=rosen_hess_p,
options={'xtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 24
Function evaluations: 33
Gradient evaluations: 56
Hessian evaluations: 66Algoritmi i rajonit të besimit të gradientit të konjuguar (Newton)
Kushtëzimi i dobët i matricës Hessian dhe drejtimet e gabuara të kërkimit mund të bëjnë që algoritmi i gradientit të konjuguar të Njutonit të jetë joefektiv. Në raste të tilla, i jepet përparësi (besim-rajon) gradientët e konjuguar të Njutonit.
Shembull me përkufizimin e matricës Hessian:
res = minimize(rosen, x0, method='trust-ncg',
jac=rosen_der, hess=rosen_hess,
options={'gtol': 1e-8, 'disp': True})
print(res.x)Optimization terminated successfully.
Current function value: 0.000000
Iterations: 20
Function evaluations: 21
Gradient evaluations: 20
Hessian evaluations: 19
[1. 1. 1. 1. 1.]Shembull me funksionin e prodhimit të hesianit dhe një vektor arbitrar:
res = minimize(rosen, x0, method='trust-ncg',
jac=rosen_der, hessp=rosen_hess_p,
options={'gtol': 1e-8, 'disp': True})
print(res.x)Optimization terminated successfully.
Current function value: 0.000000
Iterations: 20
Function evaluations: 21
Gradient evaluations: 20
Hessian evaluations: 0
[1. 1. 1. 1. 1.]Metodat e tipit Krylov
Ashtu si metoda e besimit-ncg, metodat e tipit Krylov janë të përshtatshme për zgjidhjen e problemeve në shkallë të gjerë, sepse ato përdorin vetëm produkte matricë-vektoriale. Thelbi i tyre është të zgjidhin një problem në një rajon besimi të kufizuar nga një nënhapësirë e cunguar Krylov. Për probleme të pasigurta, është më mirë të përdoret kjo metodë, pasi përdor një numër më të vogël përsëritjesh jolineare për shkak të numrit më të vogël të produkteve matricë-vektor për nënproblem, krahasuar me metodën e besimit-ncg. Për më tepër, zgjidhja e nënproblemit kuadratik gjendet më saktë sesa përdorimi i metodës trust-ncg.
Shembull me përkufizimin e matricës Hessian:
res = minimize(rosen, x0, method='trust-krylov',
jac=rosen_der, hess=rosen_hess,
options={'gtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 19
Function evaluations: 20
Gradient evaluations: 20
Hessian evaluations: 18
print(res.x)
[1. 1. 1. 1. 1.]
Shembull me funksionin e prodhimit të hesianit dhe një vektor arbitrar:
res = minimize(rosen, x0, method='trust-krylov',
jac=rosen_der, hessp=rosen_hess_p,
options={'gtol': 1e-8, 'disp': True})
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 19
Function evaluations: 20
Gradient evaluations: 20
Hessian evaluations: 0
print(res.x)
[1. 1. 1. 1. 1.]
Algoritmi për zgjidhjen e përafërt në rajonin e besimit
Të gjitha metodat (Newton-CG, trust-ncg dhe trust-krylov) janë të përshtatshme për zgjidhjen e problemeve në shkallë të gjerë (me mijëra variabla). Kjo është për shkak të faktit se algoritmi themelor i gradientit të konjuguar nënkupton një përcaktim të përafërt të matricës Hessian inverse. Zgjidhja gjendet në mënyrë të përsëritur, pa zgjerim të qartë të hesianit. Meqenëse ju duhet vetëm të përcaktoni një funksion për produktin e një Hessian dhe një vektor arbitrar, ky algoritëm është veçanërisht i mirë për të punuar me matrica të rralla (diagonale të brezit). Kjo siguron kosto të ulëta të memories dhe kursime të konsiderueshme në kohë.
Për problemet e mesme, kostoja e ruajtjes dhe faktorizimit të Hessian-it nuk është kritike. Kjo do të thotë se është e mundur të merret një zgjidhje në më pak përsëritje, duke zgjidhur pothuajse saktësisht nënproblemet e rajonit të besimit. Për ta bërë këtë, disa ekuacione jolineare zgjidhen në mënyrë iterative për çdo nënproblem kuadratik. Një zgjidhje e tillë zakonisht kërkon 3 ose 4 zbërthime Cholesky të matricës Hessian. Si rezultat, metoda konvergon në më pak përsëritje dhe kërkon më pak llogaritje të funksionit objektiv sesa metodat e tjera të zbatuara të rajonit të besimit. Ky algoritëm nënkupton vetëm përcaktimin e matricës së plotë Hessian dhe nuk mbështet aftësinë për të përdorur funksionin e produktit të Hessian dhe një vektor arbitrar.
Shembull me minimizimin e funksionit Rosenbrock:
res = minimize(rosen, x0, method='trust-exact',
jac=rosen_der, hess=rosen_hess,
options={'gtol': 1e-8, 'disp': True})
res.xOptimization terminated successfully.
Current function value: 0.000000
Iterations: 13
Function evaluations: 14
Gradient evaluations: 13
Hessian evaluations: 14
array([1., 1., 1., 1., 1.])Ndoshta do të ndalemi atje. Në artikullin tjetër do të përpiqem të tregoj gjërat më interesante për minimizimin e kushtëzuar, zbatimin e minimizimit në zgjidhjen e problemeve të përafrimit, minimizimin e një funksioni të një ndryshoreje, minimizuesit arbitrarë dhe gjetjen e rrënjëve të një sistemi ekuacionesh duke përdorur scipy.optimize paketë.
Burimi:
Burimi: www.habr.com
