


Здраво свима! Моје име је Дмитриј Самсонов и радим као главни систем администратор у Однокласницима. Имамо преко 7 физичких сервера, 11 контејнера у нашем облаку и 200 апликација, које у различитим конфигурацијама формирају 700 различитих кластера. Велика већина сервера ради CentOS 7.
14. августа 2018. објављена је информација о рањивости ФрагментСмацк
() и СегментСмацк (). То су рањивости са вектором мрежног напада и прилично високим резултатом (7.5), што прети ускраћивањем услуге (ДоС) због исцрпљивања ресурса (ЦПУ). Исправка кернела за ФрагментСмацк тада није била предложена, штавише, изашла је много касније од објављивања информација о рањивости. Да би се елиминисао СегментСмацк, предложено је ажурирање кернела. Сам пакет ажурирања је објављен истог дана, остало је само да се инсталира.
Не, ми уопште нисмо против ажурирања кернела! Међутим, постоје нијансе...
Како ажурирамо кернел у производњи
Генерално, ништа компликовано:
- Преузмите пакете;
- Инсталирајте их на више сервера (укључујући сервере који хостују наш облак);
- Уверите се да ништа није сломљено;
- Уверите се да су сва стандардна подешавања кернела примењена без грешака;
- Сачекајте неколико дана;
- Проверите перформансе сервера;
- Пребаците примену нових сервера на ново језгро;
- Ажурирајте све сервере по дата центру (један по један центар података да бисте минимизирали ефекат на кориснике у случају проблема);
- Поново покрените све сервере.
Поновите за све гране језгара које имамо. Тренутно је:
- Залихе CentOS 7 3.10 - за већину редовних сервера;
- Ванила 4.19 - за наше , јер нам треба БФК, ББР, итд.;
- Елрепо кернел-мл 5.2 - фор , јер се 4.19 некада понашао нестабилно, али су потребне исте карактеристике.
Као што сте могли да претпоставите, поновно покретање хиљада сервера траје најдуже. Пошто нису све рањивости критичне за све сервере, поново покрећемо само оне који су директно доступни са Интернета. У облаку, да не бисмо ограничили флексибилност, не везујемо екстерно доступне контејнере за појединачне сервере са новим кернелом, већ рестартујемо све хостове без изузетка. На срећу, тамо је процедура једноставнија него код обичних сервера. На пример, контејнери без стања могу једноставно да се пребаце на други сервер током поновног покретања.
Међутим, посла има још много, и може потрајати неколико недеља, а ако има проблема са новом верзијом и до неколико месеци. Нападачи то веома добро разумеју, па им је потребан план Б.
ФрагментСмацк/СегментСмацк. Заобилазно решење
На срећу, за неке рањивости постоји такав план Б и зове се Заобилазно решење. Најчешће се ради о промени подешавања кернела/апликације која може да минимизира могући ефекат или потпуно елиминише искоришћавање рањивости.
У случају ФрагментСмацк/СегментСмацк ово решење:
«Можете да промените подразумеване вредности од 4МБ и 3МБ у нет.ипв4.ипфраг_хигх_тхресх и нет.ипв4.ипфраг_лов_тхресх (и њихове парњаке за ипв6 нет.ипв6.ипфраг_хигх_тхресх и нет.ипв6.ипфраг_лов_тхресх или 256 кБ) на и 192 кБ ниже. Тестови показују мале до значајне падове у употреби ЦПУ-а током напада у зависности од хардвера, подешавања и услова. Међутим, може доћи до извесног утицаја на перформансе због ипфраг_хигх_тхресх=262144 бајтова, пошто само два фрагмента од 64К могу истовремено да стану у ред за поновно састављање. На пример, постоји ризик да се апликације које раде са великим УДП пакетима покваре'.
Сами параметри описано на следећи начин:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Немамо велике УДП-ове на производним услугама. Нема фрагментираног саобраћаја на ЛАН-у; постоји фрагментиран саобраћај на ВАН-у, али није значајан. Нема знакова - можете да покренете заобилазно решење!
ФрагментСмацк/СегментСмацк. Прва крв
Први проблем на који смо наишли био је тај што су контејнери у облаку понекад применили нова подешавања само делимично (само ипфраг_лов_тхресх), а понекад их уопште нису применили – једноставно су се срушили на почетку. Није било могуће стабилно репродуковати проблем (сва подешавања су примењена ручно без икаквих потешкоћа). Разумевање зашто се контејнер руши на почетку такође није тако лако: грешке нису пронађене. Једно је било сигурно: враћање подешавања уназад решава проблем са рушењем контејнера.
Зашто није довољно применити Сисцтл на хосту? Контејнер живи у сопственој наменској мрежи Намеспаце, барем тако у контејнеру може да се разликује од домаћина.
Како се тачно Сисцтл подешавања примењују у контејнеру? Пошто су наши контејнери непривилеговани, нећете моћи да промените ниједну Сисцтл поставку уласком у сам контејнер – једноставно немате довољно права. За покретање контејнера, наш облак је у то време користио Доцкер (сада ). Параметри новог контејнера су прослеђени Доцкер-у преко АПИ-ја, укључујући неопходна Сисцтл подешавања.
Приликом претраживања верзија, показало се да Доцкер АПИ није вратио све грешке (барем у верзији 1.10). Када смо покушали да покренемо контејнер преко „доцкер рун“, коначно смо видели бар нешто:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Вредност параметра није важећа. Али зашто? А зашто не важи само понекад? Испоставило се да Доцкер не гарантује редослед примене Сисцтл параметара (најновија тестирана верзија је 1.13.1), па је понекад ипфраг_хигх_тхресх покушавао да се подеси на 256К када је ипфраг_лов_тхресх још увек био 3М, односно горња граница је била нижа од доње границе, што је довело до грешке.
У то време смо већ користили сопствени механизам за реконфигурисање контејнера након покретања (замрзавање контејнера након и извршавање команди у именском простору контејнера преко ), а овом делу смо додали и писање Сисцтл параметара. Проблем је решен.
ФрагментСмацк/СегментСмацк. Прва крв 2
Пре него што смо имали времена да разумемо употребу Воркароунд-а у облаку, почеле су да стижу прве ретке жалбе корисника. У то време је прошло неколико недеља од почетка коришћења Воркароунд-а на првим серверима. Првобитна истрага је показала да су притужбе стизале на поједине сервисе, а не на све сервере ових сервиса. Проблем је поново постао крајње неизвестан.
Прво смо покушали да вратимо Sysctl подешавања, али то није имало ефекта. Разне манипулације подешавањима сервера и апликације такође нису помогле. Рестартовање је помогло. Рестартујте за Linux колико неприродно, толико и нормално стање за рад са Windows У стара времена. Радило је, међутим, а ми смо то приписали „грешци језгра“ приликом примене нових Sysctl подешавања. Колико смо само били глупи...
Три недеље касније проблем се поновио. Конфигурација ових сервера је била прилично једноставна: Нгинк у режиму прокси/балансирања. Нема пуно саобраћаја. Нова уводна напомена: сваким даном се повећава број 504 грешке на клијентима (). Графикон приказује број од 504 грешке дневно за ову услугу:
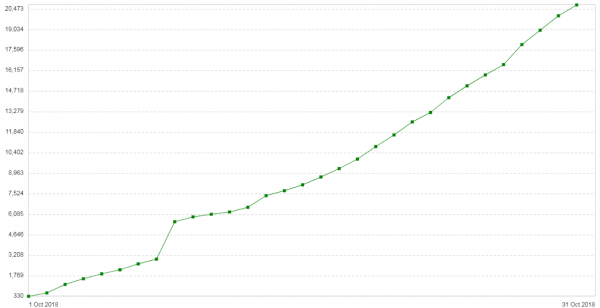
Све грешке су о истом бацкенду - о оном који је у облаку. Графикон потрошње меморије за фрагменте пакета на овој позадини изгледао је овако:
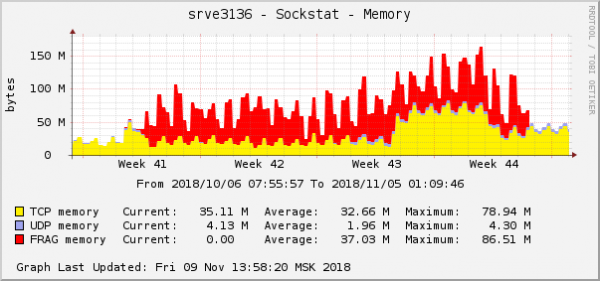
Ово је једна од најочигледнијих манифестација проблема у графовима оперативног система. У облаку је, у исто време, решен још један мрежни проблем са поставкама КоС (Контрола саобраћаја). На графикону потрошње меморије за фрагменте пакета, изгледало је потпуно исто:
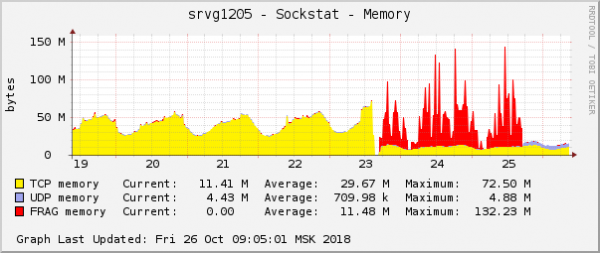
Претпоставка је била једноставна: ако изгледају исто на графиконима, онда имају исти разлог. Штавише, било какви проблеми са овом врстом меморије су изузетно ретки.
Суштина решеног проблема је била да смо користили фк планер пакета са подразумеваним поставкама у КоС-у. Подразумевано, за једну везу, омогућава вам да додате 100 пакета у ред, а неке везе су, у ситуацијама недостатка канала, почеле да затварају ред до краја. У овом случају, пакети се одбацују. У тц статистици (тц -с кдисц) то се може видети овако:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
„464545 фловс_плимит“ су пакети одбачени због прекорачења ограничења реда за једну везу, а „испуштено 464545“ је збир свих испуштених пакета овог планера. Након повећања дужине реда на 1 хиљаду и поновног покретања контејнера, проблем је престао да се јавља. Можете се завалити и попити смоотхие.
ФрагментСмацк/СегментСмацк. Ласт Блоод
Прво, неколико месеци након што су објављене рањивости језгра, коначно је објављена исправка за FragmentSmack (сетите се, августовска објава је објавила само исправку за SegmentSmack), што нам је дало прилику да одустанемо од Workaround-а, који нам је изазвао доста проблема. Већ смо мигрирали неке сервере на нови језгро током овог периода, а сада смо морали да почнемо од нуле. Зашто смо ажурирали језгро, а да нијесмо чекали исправку за FragmentSmack? Чињеница је да се процес заштите од ових рањивости поклопио (и спојио) са процесом ажурирања самог Workaround-а. CentOS (што траје чак и дуже него ажурирање самог језгра). Осим тога, SegmentSmack је опаснија рањивост, а исправка за њу је била одмах доступна, тако да је ионако имало смисла. Међутим, једноставно ажурирање језгра CentOS нисмо могли због рањивости FragmentSmack-а која се појавила током CentOS Верзија 7.5 је поправљена тек у верзији 7.6, тако да смо морали да зауставимо ажурирање на 7.5 и поново почнемо са ажурирањем на 7.6. И ово се дешава.
Друго, ретке жалбе корисника на проблеме су нам се вратиле. Сада већ поуздано знамо да су сви повезани са отпремањем фајлова са клијената на неки од наших сервера. Штавише, веома мали број отпремања од укупне масе прошао је преко ових сервера.
Као што се сећамо из горње приче, враћање Сисцтл-а није помогло. Поновно покретање је помогло, али привремено.
Сумње у вези са Сисцтл-ом нису отклоњене, али је овога пута било потребно прикупити што више информација. Такође је постојао велики недостатак могућности да се проблем уплоад-а репродукује на клијенту како би се прецизније проучило шта се дешава.
Анализа свих доступних статистика и логова није нас приближила разумевању шта се дешавало. Постојао је акутни недостатак способности да се репродукује проблем како би се „осетила” одређена веза. Коначно, програмери су, користећи посебну верзију апликације, успели да постигну стабилну репродукцију проблема на тестном уређају када су повезани преко Ви-Фи мреже. Ово је био искорак у истрази. Клијент се повезао са Нгинк-ом, који је проксијао позадину, што је била наша Јава апликација.
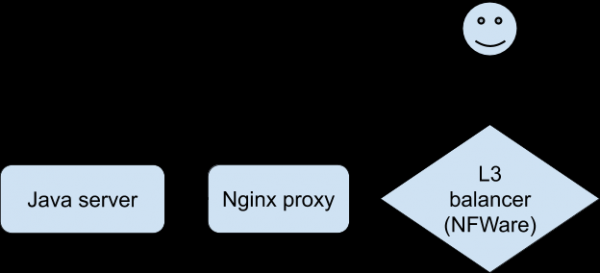
Дијалог за проблеме је био овакав (поправљен на страни Нгинк проксија):
- Клијент: захтев за добијање информација о преузимању датотеке.
- Јава сервер: одговор.
- Клијент: ПОСТ са датотеком.
- Јава сервер: грешка.
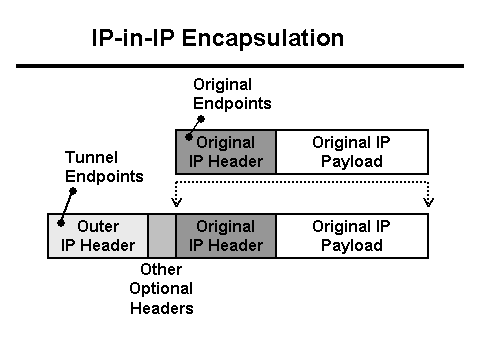
Истовремено, Јава сервер уписује у дневник да је од клијента примљено 0 бајтова података, а Нгинк прокси пише да је захтев трајао више од 30 секунди (30 секунди је временско ограничење клијентске апликације). Зашто је временско ограничење и зашто 0 бајтова? Из ХТТП перспективе, све функционише како треба, али изгледа да ПОСТ са датотеком нестаје са мреже. Штавише, нестаје између клијента и Нгинк-а. Време је да се наоружате Тцпдумпом! Али прво морате да разумете конфигурацију мреже. Нгинк проки стоји иза Л3 балансера . Тунелирање се користи за испоруку пакета из Л3 балансера на сервер, који додаје своја заглавља пакетима:
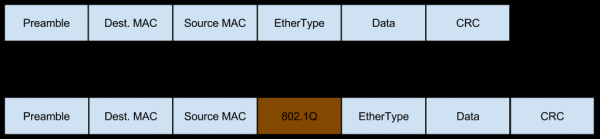
У овом случају, мрежа долази до овог сервера у облику саобраћаја означеног Влан-ом, који такође додаје сопствена поља пакетима:
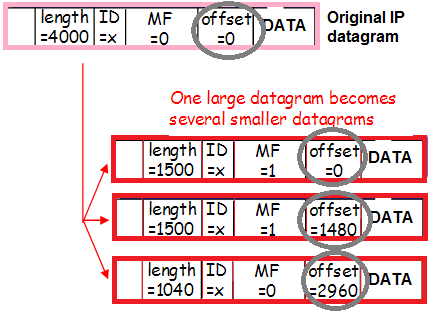
И овај саобраћај такође може бити фрагментиран (онај исти мали проценат долазног фрагментираног саобраћаја о којем смо говорили када смо процењивали ризике од Воркароунд-а), што такође мења садржај заглавља:
Још једном: пакети су инкапсулирани са Влан ознаком, енкапсулирани тунелом, фрагментирани. Да бисмо боље разумели како се то дешава, хајде да пратимо руту пакета од клијента до Нгинк проксија.
- Пакет стиже до Л3 балансера. За исправно рутирање унутар центра података, пакет се инкапсулира у тунел и шаље на мрежну картицу.
- Пошто се заглавља пакет + тунел не уклапају у МТУ, пакет се исече на фрагменте и шаље у мрежу.
- Прекидач после Л3 балансера, када прими пакет, додаје му Влан таг и шаље га даље.
- Прекидач испред Нгинк проксија види (на основу подешавања порта) да сервер очекује Влан-инкапсулиран пакет, па га шаље таквог какав јесте, без уклањања Влан ознаке.
- Linux прима фрагменте појединачних пакета и лепи их у један велики пакет.
- Затим пакет стиже до Влан интерфејса, где се са њега уклања први слој - Влан инкапсулација.
- Онда Linux шаље га на тунелски интерфејс, где се са њега уклања још један слој - тунелска енкапсулација.
Тешкоћа је да се све ово проследи као параметри у тцпдумп.
Почнимо од краја: да ли постоје чисти (без непотребних заглавља) ИП пакети од клијената, са уклоњеном енкапсулацијом влан-а и тунела?
tcpdump host <ip клиента>
Не, није било таквих пакета на серверу. Дакле, проблем мора постојати раније. Да ли постоје пакети са уклоњеном само Влан инкапсулацијом?
tcpdump ip[32:4]=0xx390x2xx
0кк390к2кк је ИП адреса клијента у хексадецималном формату.
32:4 — адреса и дужина поља у које је уписана СЦР ИП у пакету тунела.
Адреса поља је морала бити изабрана грубом силом, пошто на Интернету пишу о 40, 44, 50, 54, али тамо није било ИП адресе. Такође можете погледати један од пакета у хек (параметар -кк или -КСКС у тцпдумп) и израчунати ИП адресу коју знате.
Да ли постоје фрагменти пакета без уклоњених Влан и Туннел енкапсулације?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Ова магија ће нам показати све фрагменте, укључујући и последњи. Вероватно се иста ствар може филтрирати по ИП-у, али нисам покушао, јер таквих пакета нема много, а они који су ми били потребни лако су се нашли у општем току. Ево их:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 У 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), дужина 62: (tos 0x0, ttl 63, ИД 53652, офсет 1480, заставице [нема], прото IPIP (4), дужина 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........А....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x Е..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0к0040: 881д ц4б6 0000 0000 0000 0000 0000 ............
Ово су два фрагмента једног пакета (исти ИД 53652) са фотографијом (на првом пакету се види реч Екиф). Због чињенице да постоје пакети на овом нивоу, али не у спојеном облику у думпима, проблем је очигледно у монтажи. Коначно постоје документарни докази о томе!
Декодер пакета није открио никакве проблеме који би спречили изградњу. Пробао овде: . У почетку, када покушате да нешто убаците тамо, декодеру се не свиђа формат пакета. Испоставило се да постоје два додатна октета између Срцмаца и Етхертипе-а (није везано за информације о фрагментима). Након њиховог уклањања, декодер је почео да ради. Међутим, није показивало никакве проблеме.
Шта год да се каже, ништа друго није пронађено осим оних Сисцтл. Остало је само да се пронађе начин да се идентификују проблеми сервери како би се разумеле размере и одлучиле о даљим акцијама. Потребан бројач је пронађен довољно брзо:
netstat -s | grep "packet reassembles failed”
Такође је у снмпд-у под ОИД=1.3.6.1.2.1.4.31.1.1.16.1 ().
„Број грешака које је открио алгоритам за поновно састављање ИП адресе (из било ког разлога: истекло време, грешке, итд.)“
Међу групом сервера на којима је проблем проучаван, на два се овај бројач повећавао брже, на два спорије, а на још два се уопште није повећавао. Поређењем динамике овог бројача са динамиком ХТТП грешака на Јава серверу откривена је корелација. То јест, бројило би се могло пратити.
Веома је важно имати поуздан индикатор проблема како бисте могли тачно да утврдите да ли враћање Сисцтл-а помаже, јер из претходне приче знамо да се то не може одмах разумети из апликације. Овај индикатор би нам омогућио да идентификујемо све проблематичне области у производњи пре него што их корисници открију.
Након враћања Сисцтл-а, грешке у праћењу су престале, чиме је доказан узрок проблема, као и чињеница да враћање помаже.
Вратили смо подешавања фрагментације на друге сервере, где је дошло до новог надгледања, а негде смо доделили чак и више меморије за фрагменте него што је претходно било подразумевано (ово је била УДП статистика, чији делимични губитак није био приметан на општој позадини) .
Најважнија питања
Зашто су пакети фрагментирани на нашем Л3 балансеру? Већина пакета који долазе од корисника до балансера су СИН и АЦК. Величине ових пакета су мале. Али пошто је удео таквих пакета веома велик, на њиховој позадини нисмо приметили присуство великих пакета који су почели да се фрагментирају.
Разлог је била покварена конфигурациона скрипта на серверима са Влан интерфејсима (у то време у производњи је било веома мало сервера са означеним саобраћајем). Адвмсс нам омогућава да пренесемо клијенту информацију да пакети у нашем правцу треба да буду мање величине, тако да након причвршћивања заглавља тунела на њих не морају да буду фрагментисани.
Зашто Сисцтл враћање није помогло, али поновно покретање јесте? Враћање Сисцтл-а је променило количину меморије доступне за спајање пакета. У исто време, очигледно је сама чињеница преливања меморије за фрагменте довела до успоравања веза, што је довело до тога да су фрагменти дуго одлагани у реду. То јест, процес је ишао у циклусима.
Рестарт је обрисао меморију и све се вратило у ред.
Да ли је било могуће без Решења? Да, али постоји велики ризик да корисници остану без услуге у случају напада. Наравно, коришћење Воркароунд-а је резултирало разним проблемима, укључујући и успоравање једног од сервиса за кориснике, али ипак сматрамо да су радње биле оправдане.
Велико хвала Андреју Тимофејеву () за помоћ у спровођењу истраге, као и Алексеју Креневу () - за титански рад ажурирања Centos и језгра сервера. У овом случају, процес је морао бити поново покренут неколико пута, што је резултирало трајањем више месеци.
Извор: ввв.хабр.цом
