

Белешка. трансл.: Овај чланак, који је написао Гало Наваро, који је на позицији главног софтверског инжењера у европској компанији Адевинта, представља фасцинантно и поучно „истраживање“ у области инфраструктурних операција. Његов оригинални наслов је мало проширен у преводу из разлога који аутор објашњава на самом почетку.
Напомена аутора: Изгледа као овај пост много више пажње него што се очекивало. И даље добијам љуте коментаре да је наслов чланка погрешан и да су неки читаоци тужни. Разумем разлоге за ово што се дешава, стога, упркос ризику да покварим целу интригу, желим одмах да вам кажем о чему се ради у овом чланку. Занимљива ствар коју сам видео док тимови мигрирају на Кубернетес је да кад год се појави проблем (као што је повећано кашњење након миграције), прва ствар за коју се криви Кубернетес, али се онда испостави да оркестратор заправо није кривити. Овај чланак говори о једном таквом случају. Његово име понавља узвик једног од наших програмера (касније ћете видети да Кубернетес нема никакве везе са тим). Овде нећете наћи изненађујућа открића о Кубернетес-у, али можете очекивати неколико добрих лекција о сложеним системима.
Пре неколико недеља, мој тим је мигрирао једну микроуслугу на основну платформу која је укључивала ЦИ/ЦД, рунтиме засновано на Кубернетесу, метрике и друге погодности. Овај потез је био пробне природе: планирали смо да га узмемо за основу и пренесемо још око 150 услуга у наредним месецима. Сви они су одговорни за рад неких од највећих онлајн платформи у Шпанији (Инфојобс, Фотоцаса, итд.).
Након што смо апликацију поставили на Кубернетес и преусмерили део саобраћаја на њу, чекало нас је алармантно изненађење. Кашњење (латентност) захтеви у Кубернетесу били су 10 пута већи него у ЕЦ2. Уопштено говорећи, било је потребно или пронаћи решење за овај проблем, или напустити миграцију микросервиса (и, можда, читавог пројекта).
Зашто је кашњење толико веће у Кубернетесу него у ЕЦ2?
Да бисмо пронашли уско грло, прикупили смо метрику дуж целе путање захтева. Наша архитектура је једноставна: АПИ гатеваи (Зуул) прокси сервере шаље захтеве микросервисним инстанцама у ЕЦ2 или Кубернетес-у. У Кубернетес-у користимо НГИНКС Ингресс Цонтроллер, а позадине су обични објекти попут са ЈВМ апликацијом на Спринг платформи.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Чинило се да је проблем повезан са почетним кашњењем у позадини (означио сам проблематичну област на графикону као "кк"). На ЕЦ2, одговор апликације је трајао око 20 мс. У Кубернетесу се кашњење повећало на 100-200 мс.
Брзо смо одбацили могуће осумњичене у вези са променом времена извршавања. ЈВМ верзија остаје иста. Проблеми са контејнеризацијом такође нису имали никакве везе са тим: апликација је већ успешно радила у контејнерима на ЕЦ2. Лоадинг? Али приметили смо велике латенције чак и при 1 захтеву у секунди. Могле би се занемарити и паузе за одвоз смећа.
Један од наших Кубернетес администратора се запитао да ли апликација има спољне зависности јер су ДНС упити изазивали сличне проблеме у прошлости.
Хипотеза 1: Резолуција ДНС имена
За сваки захтев, наша апликација приступа АВС Еластицсеарцх инстанци један до три пута у домену као што је elastic.spain.adevinta.com. У нашим контејнерима , тако да можемо да проверимо да ли тражење домена заиста траје дуго.
ДНС упити из контејнера:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecСлични захтеви из једне од ЕЦ2 инстанци где је апликација покренута:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecУзимајући у обзир да је тражење трајало око 30 мс, постало је јасно да је ДНС резолуција приликом приступа Еластицсеарцх-у заиста доприносила повећању латенције.
Међутим, ово је било чудно из два разлога:
- Већ имамо гомилу Кубернетес апликација које комуницирају са АВС ресурсима без великог кашњења. Шта год да је разлог, он се посебно односи на овај случај.
- Знамо да ЈВМ ради ДНС кеширање у меморији. На нашим сликама, ТТЛ вредност је уписана
$JAVA_HOME/jre/lib/security/java.securityи подесите на 10 секунди:networkaddress.cache.ttl = 10. Другим речима, ЈВМ би требало да кешира све ДНС упите 10 секунди.
Да бисмо потврдили прву хипотезу, одлучили смо да прекинемо позивање ДНС-а на неко време и видимо да ли је проблем нестао. Прво смо одлучили да поново конфигуришемо апликацију тако да комуницира директно са Еластицсеарцх-ом преко ИП адресе, а не преко имена домена. Ово би захтевало промене кода и нову примену, тако да смо једноставно мапирали домен на његову ИП адресу /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comСада је контејнер добио ИП скоро одмах. Ово је резултирало одређеним побољшањем, али смо били само мало ближе очекиваним нивоима кашњења. Иако је рјешавање ДНС-а дуго трајало, прави разлог нам је ипак измицао.
Дијагностика преко мреже
Одлучили смо да анализирамо саобраћај из контејнера користећи tcpdumpда видите шта се тачно дешава на мрежи:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Затим смо послали неколико захтева и преузели њихов снимак (kubectl cp my-service:/capture.pcap capture.pcap) за даљу анализу у .
У ДНС упитима није било ништа сумњиво (осим једне ситнице о којој ћу касније). Али било је одређених необичности у начину на који је наша служба обрадила сваки захтев. Испод је снимак екрана који показује да је захтев прихваћен пре него што одговор почне:
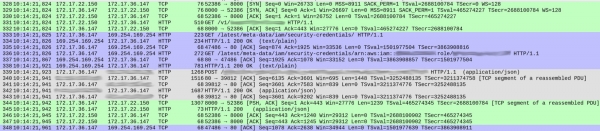
У првој колони су приказани бројеви пакета. Ради јасноће, различите ТЦП токове сам означио бојама.
Зелени ток, почевши од пакета 328, показује како је клијент (172.17.22.150) успоставио ТЦП везу са контејнером (172.17.36.147). Након почетног руковања (328-330), донео је пакет 331 HTTP GET /v1/.. — долазни захтев нашој служби. Цео процес је трајао 1 мс.
Сиви ток (из пакета 339) показује да је наша услуга послала ХТТП захтев инстанци Еластицсеарцх (нема ТЦП руковања јер користи постојећу везу). Ово је трајало 18 мс.
За сада је све у реду, а времена отприлике одговарају очекиваним кашњењима (20-30 мс мерено од клијента).
Међутим, плави део траје 86 мс. Шта се дешава у њему? Са пакетом 333, наша услуга је послала ХТТП ГЕТ захтев /latest/meta-data/iam/security-credentials, а одмах након њега, преко исте ТЦП везе, други ГЕТ захтев за /latest/meta-data/iam/security-credentials/arn:...
Открили смо да се то понавља са сваким захтевом током праћења. ДНС резолуција је заиста мало спорија у нашим контејнерима (објашњење за овај феномен је прилично занимљиво, али ћу га сачувати за посебан чланак). Испоставило се да су узрок дугих кашњења позиви сервису АВС метаподатака инстанце на сваки захтев.
Хипотеза 2: непотребни позиви АВС-у
Обе крајње тачке припадају . Наш микросервис користи ову услугу док покреће Еластицсеарцх. Оба позива су део основног процеса ауторизације. Крајња тачка којој се приступа на првом захтеву издаје ИАМ улогу повезану са инстанцом.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleДруги захтев тражи од друге крајње тачке привремене дозволе за ову инстанцу:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Клијент може да их користи кратко време и мора периодично да прибавља нове сертификате (пре него што се Expiration). Модел је једноставан: АВС често ротира привремене кључеве из безбедносних разлога, али клијенти могу да их кеширају на неколико минута како би надокнадили смањење перформанси повезано са добијањем нових сертификата.
АВС Јава СДК би требало да преузме одговорност за организовање овог процеса, али се то из неког разлога не дешава.
Након претраживања проблема на ГитХуб-у, наишли смо на проблем . Помогла нам је да одредимо правац у коме ћемо даље „копати“.
АВС СДК ажурира сертификате када се појави један од следећих услова:
- Рок трајања (
Expiration) Пасти уEXPIRATION_THRESHOLD, тврдо кодирано на 15 минута. - Прошло је више времена од последњег покушаја обнове сертификата
REFRESH_THRESHOLD, тврдо кодирано 60 минута.
Да бисмо видели стварни датум истека сертификата које добијамо, покренули смо горње цУРЛ команде и из контејнера и из ЕЦ2 инстанце. Испоставило се да је период важења сертификата примљеног из контејнера много краћи: тачно 15 минута.
Сада је све постало јасно: за први захтев наша служба је добила привремене сертификате. Пошто нису важили дуже од 15 минута, АВС СДК би одлучио да их ажурира на накнадни захтев. И то се дешавало са сваким захтевом.
Зашто је рок важења сертификата постао краћи?
Метаподаци АВС инстанце су дизајнирани да раде са ЕЦ2 инстанцама, а не са Кубернетес-ом. С друге стране, нисмо желели да мењамо интерфејс апликације. За ово смо користили - алат који, користећи агенте на сваком Кубернетес чвору, омогућава корисницима (инжењерима који постављају апликације у кластер) да доделе ИАМ улоге контејнерима у подовима као да су ЕЦ2 инстанце. КИАМ пресреће позиве сервису метаподатака АВС инстанце и обрађује их из своје кеш меморије, након што их је претходно примио од АВС-а. Са становишта примене, ништа се не мења.
КИАМ испоручује краткорочне сертификате под. Ово има смисла с обзиром на то да је просечан животни век капсуле краћи од ЕЦ2 инстанце. Подразумевани период важења сертификата .
Као резултат тога, ако поставите обе подразумеване вредности једну на другу, настаје проблем. Сваки сертификат дат апликацији истиче након 15 минута. Међутим, АВС Јава СДК приморава да се обнови било који сертификат који има мање од 15 минута пре истека.
Као резултат тога, привремени сертификат је приморан да се обнавља са сваким захтевом, што подразумева неколико позива АВС АПИ-ју и узрокује значајно повећање латенције. У АВС Јава СДК смо пронашли , који помиње сличан проблем.
Испоставило се да је решење једноставно. Једноставно смо реконфигурисали КИАМ да захтева сертификате са дужим периодом важења. Када се то догодило, захтеви су почели да притичу без учешћа АВС Метадата услуге, а кашњење је пало на чак ниже нивое него у ЕЦ2.
Налази
На основу нашег искуства са миграцијама, један од најчешћих извора проблема нису грешке у Кубернетесу или другим елементима платформе. Такође не решава никакве фундаменталне недостатке у микросервисима које преносимо. Проблеми се често јављају једноставно зато што спајамо различите елементе.
Комбинујемо сложене системе који никада раније нису били у интеракцији, очекујући да ће заједно формирати један, већи систем. Авај, што више елемената, више простора за грешке, то је већа ентропија.
У нашем случају, велико кашњење није резултат грешака или лоших одлука у Кубернетес-у, КИАМ-у, АВС Јава СДК-у или нашој микросервиси. То је био резултат комбиновања две независне подразумеване поставке: једне у КИАМ-у, друге у АВС Јава СДК-у. Узето одвојено, оба параметра имају смисла: активна политика обнављања сертификата у АВС Јава СДК-у и кратак период важења сертификата у КАИМ-у. Али када их спојите, резултати постају непредвидиви. Два независна и логична решења не морају имати смисла када се комбинују.
ПС од преводиоца
Можете сазнати више о архитектури КИАМ услужног програма за интеграцију АВС ИАМ-а са Кубернетес-ом на од његових твораца.
Прочитајте и на нашем блогу:
- «";
- «";
- «";
- «'.
Извор: ввв.хабр.цом
