

Одноклассники је до недавно чувао око 50 ТБ података обрађених у реалном времену у СКЛ Сервер. За такав обим, скоро је немогуће обезбедити брз и поуздан, па чак и приступ центру података који је толерантан на грешке користећи СКЛ ДБМС. Обично се у таквим случајевима користи једно од НоСКЛ складишта, али не може се све пренети у НоСКЛ: неки ентитети захтевају АЦИД трансакцијске гаранције.
Ово нас је довело до употребе НевСКЛ складишта, односно ДБМС-а који обезбеђује толеранцију грешака, скалабилност и перформансе НоСКЛ система, али у исто време одржава АЦИД гаранције познате класичним системима. Радних индустријских система ове нове класе је мало, па смо такав систем сами имплементирали и пустили у комерцијални рад.
Како то функционише и шта се догодило - прочитајте испод реза.
Данас је месечна публика Одноклассника више од 70 милиона јединствених посетилаца. Ми највеће друштвене мреже на свету, и међу двадесетак сајтова на којима корисници проводе највише времена. ОК инфраструктура подноси веома велика оптерећења: више од милион ХТТП захтева у секунди по фронту. Делови серверске флоте од више од 8000 комада налазе се близу један другом – у четири московска дата центра, што омогућава да се између њих обезбеди кашњење мреже мање од 1 мс.
Користимо Цассандру од 2010. године, почевши од верзије 0.6. Данас постоји неколико десетина кластера у функцији. Најбржи кластер обрађује више од 4 милиона операција у секунди, а највећи складишти 260 ТБ.
Међутим, ово су све обични НоСКЛ кластери који се користе за складиштење података. Желели смо да заменимо главно конзистентно складиште, Мицрософт СКЛ Сервер, који се користи од оснивања Одноклассника. Складиште се састојало од више од 300 СКЛ Сервер Стандард Едитион машина, које су садржале 50 ТБ података – пословних субјеката. Ови подаци се мењају као део АЦИД трансакција и захтевају .
За дистрибуцију података кроз чворове СКЛ Сервера користили смо и вертикалне и хоризонталне (схардинг). Историјски гледано, користили смо једноставну шему дељења података: сваки ентитет је био повезан са токеном – функцијом ИД-а ентитета. Ентитети са истим токеном постављени су на исти СКЛ сервер. Однос мастер-детаил је имплементиран тако да су се токени главног и подређеног записа увек поклапали и били смештени на истом серверу. У друштвеној мрежи скоро сви записи се генеришу у име корисника, што значи да се сви кориснички подаци у оквиру једног функционалног подсистема чувају на једном серверу. То јест, пословна трансакција је скоро увек укључивала табеле са једног СКЛ сервера, што је омогућило да се обезбеди конзистентност података коришћењем локалних АЦИД трансакција, без потребе за коришћењем дистрибуиране АЦИД трансакције.
Захваљујући дијељењу и убрзању СКЛ-а:
- Не користимо ограничења страног кључа, пошто се приликом дељења ИД ентитета може налазити на другом серверу.
- Не користимо ускладиштене процедуре и окидаче због додатног оптерећења ЦПУ-а ДБМС-а.
- Не користимо ЈОИН-ове због свега наведеног и много насумичних читања са диска.
- Изван трансакције, користимо ниво изолације Реад Унцоммиттед да смањимо застоје.
- Вршимо само кратке трансакције (у просеку краће од 100 мс).
- Не користимо УПДАТЕ и ДЕЛЕТЕ у више редова због великог броја застоја - ажурирамо само један запис у исто време.
- Увек обављамо упите само на индексима – упит са пуним планом скенирања табеле за нас значи преоптерећење базе података и њен неуспех.
Ови кораци су нам омогућили да извучемо скоро максималне перформансе из СКЛ сервера. Међутим, проблеми су постајали све бројнији. Хајде да их погледамо.
Проблеми са СКЛ-ом
- Пошто смо користили самописно шардовање, додавање нових шардова су ручно радили администратори. Све ово време, скалабилне реплике података нису сервисирале захтеве.
- Како број записа у табели расте, брзина уметања и модификације се смањује приликом додавања индекса у постојећу табелу, брзина се смањује за фактор;
- Наличие в production небольшого количества Windows для SQL Server затрудняет управление инфраструктурой
Али главни проблем је
толеранција грешака
Класични СКЛ сервер има лошу толеранцију на грешке. Рецимо да имате само један сервер базе података, и он откаже једном у три године. За то време сајт не ради 20 минута, што је прихватљиво. Ако имате 64 сервера, онда сајт не ради једном у три недеље. А ако имате 200 сервера, онда сајт не ради сваке недеље. Ово је проблем.
Шта се може учинити да се побољша толеранција грешака СКЛ сервера? Википедија нас позива да градимо : где у случају квара било које компоненте постоји резервна.
Ово захтева флоту скупе опреме: бројна дуплирања, оптичко влакно, заједничко складиштење и укључивање резерве не функционише поуздано: око 10% прекидача се завршава кваром резервног чвора као воз иза главног чвора.
Али главни недостатак тако високо доступног кластера је нула доступност ако дата центар у којем се налази поквари. Одноклассники има четири дата центра и потребно је да обезбедимо рад у случају потпуног квара у једном од њих.
За ово бисмо могли користити репликација уграђена у СКЛ Сервер. Ово решење је много скупље због цене софтвера и пати од добро познатих проблема са репликацијом - непредвидивих кашњења трансакција са синхроном репликацијом и кашњења у примени репликација (и, као резултат тога, изгубљених модификација) са асинхроном репликацијом. Имплицитно чини ову опцију потпуно неприменљивом за нас.
Сви ови проблеми захтевали су радикално решење и почели смо да их детаљно анализирамо. Овде треба да се упознамо са оним што СКЛ Сервер углавном ради – трансакцијама.
Једноставна трансакција
Хајде да размотримо најједноставнију трансакцију, са становишта примењеног СКЛ програмера: додавање фотографије у албум. Албуми и фотографије чувају се у различитим плочама. Албум има јавни бројач фотографија. Затим се таква трансакција дели на следеће кораке:
- Закључавамо албум на кључ.
- Направите унос у табели са фотографијама.
- Ако фотографија има јавни статус, додајте бројач јавних фотографија у албум, ажурирајте унос и извршите трансакцију.
Или у псеудокоду:
TX.start("Albums", id);
Album album = albums.lock(id);
Photo photo = photos.create(…);
if (photo.status == PUBLIC ) {
album.incPublicPhotosCount();
}
album.update();
TX.commit();Видимо да је најчешћи сценарио пословних трансакција читање података из базе података у меморију сервера апликација, промена нечега и чување нових вредности назад у бази података. Обично у таквој трансакцији ажурирамо неколико ентитета, неколико табела.
Приликом извршавања трансакције може доћи до истовремене измене истих података из другог система. На пример, Антиспам може одлучити да је корисник на неки начин сумњив и због тога све фотографије корисника више не би требало да буду јавне, потребно их је послати на модерацију, што подразумева промену пхото.статуса на неку другу вредност и искључивање одговарајућих бројача. Очигледно, ако се ова операција деси без гаранција атомске примене и изолације конкурентских модификација, као у , онда резултат неће бити оно што је потребно - или ће бројач фотографија показати погрешну вредност, или неће све фотографије бити послате на модерацију.
Много сличног кода, којим се манипулише различитим пословним субјектима у оквиру једне трансакције, написано је током читавог постојања Одноклассника. На основу искуства миграција на НоСКЛ из Знамо да највећи изазов (и улагање времена) долази од развоја кода за одржавање конзистентности података. Стога смо сматрали да је главни захтев за ново складиште да буде обезбеђење стварних АЦИД трансакција за логику апликације.
Други, не мање важни, захтеви су били:
- Ако дата центар поквари, и читање и писање у ново складиште морају бити доступни.
- Одржавање тренутне брзине развоја. Односно, када се ради са новим спремиштем, количина кода треба да буде приближно иста, не би требало да постоји потреба за додавањем било чега у спремиште, развијањем алгоритама за решавање конфликата, одржавање секундарних индекса, итд.
- Брзина новог складишта морала је да буде прилично висока, како приликом читања података тако и приликом обраде трансакција, што је практично значило да академски ригорозна, универзална, али спора решења, као што је нпр. .
- Аутоматско скалирање у ходу.
- Користећи обичне јефтине сервере, без потребе за куповином егзотичног хардвера.
- Могућност развоја складишта од стране програмера компаније. Другим речима, приоритет је дат власничким решењима или решењима отвореног кода, по могућности у Јави.
Одлуке, одлуке
Анализирајући могућа решења, дошли смо до два могућа избора архитектуре:
Први је да узмете било који СКЛ сервер и примените потребну толеранцију грешака, механизам скалирања, кластер за превазилажење грешака, решавање сукоба и дистрибуиране, поуздане и брзе АЦИД трансакције. Ову опцију смо оценили као веома нетривијалну и радно интензивну.
Друга опција је да узмете готову НоСКЛ складиште са имплементираним скалирањем, кластером за превазилажење грешака, решавањем сукоба и сами имплементирајте трансакције и СКЛ. На први поглед, чак и задатак имплементације СКЛ-а, а да не помињемо АЦИД трансакције, изгледа као задатак који ће трајати годинама. Али онда смо схватили да је СКЛ скуп функција који користимо у пракси далеко од АНСИ СКЛ-а далеко од АНСИ СКЛ-а. Гледајући још ближе ЦКЛ, схватили смо да је прилично близу ономе што нам је потребно.
Касандра и ЦКЛ
Дакле, шта је занимљиво код Цассандре, које могућности има?
Прво, овде можете креирати табеле које подржавају различите типове података, можете да урадите СЕЛЕЦТ или УПДАТЕ на примарном кључу.
CREATE TABLE photos (id bigint KEY, owner bigint,…);
SELECT * FROM photos WHERE id=?;
UPDATE photos SET … WHERE id=?;Да би осигурала конзистентност података реплике, Цассандра користи . У најједноставнијем случају, то значи да када су три реплике истог реда постављене на различите чворове кластера, уписивање се сматра успешним ако је већина чворова (тј. два од три) потврдила успех ове операције писања . Подаци реда се сматрају доследним ако је, приликом читања, већина чворова испитана и потврђена. Дакле, са три реплике, потпуна и тренутна конзистентност података је загарантована ако један чвор откаже. Овај приступ нам је омогућио да применимо још поузданију шему: увек шаљите захтеве на све три реплике, чекајући одговор од две најбрже. Касни одговор треће реплике се у овом случају одбацује. Чвор који касни са одговором може имати озбиљне проблеме - кочнице, сакупљање смећа у ЈВМ-у, директно враћање меморије у језгру Линука, квар хардвера, прекид везе са мрежом. Међутим, то ни на који начин не утиче на пословање или податке клијента.
Приступ када контактирамо три чвора и добијемо одговор од два се зове : захтев за додатне реплике се шаље и пре него што „отпадне“.
Још једна предност Цассандре је Батцхлог, механизам који осигурава да се група измена које извршите или у потпуности примењује или уопште не примењује. Ово нам омогућава да решимо А у АЦИД - атомичност ван кутије.
Најближа ствар трансакцијама у Цассандри су тзв.„. Али оне су далеко од „правих“ АЦИД трансакција: у ствари, ово је прилика да се уради на подацима из само једног записа, користећи консензус користећи тежак Пакос протокол. Због тога је брзина таквих трансакција мала.
Оно што нам је недостајало у Касандри
Дакле, морали смо да имплементирамо стварне АЦИД трансакције у Цассандри. Користећи које бисмо лако могли да имплементирамо још две згодне карактеристике класичног ДБМС-а: доследне брзе индексе, који би нам омогућили да вршимо селекцију података не само по примарном кључу, и регуларни генератор монотоних ИД-ова који се аутоматски повећавају.
Шишарка
Тако је рођен нови ДБМС Шишарка, који се састоји од три типа серверских чворова:
- Складиштење – (скоро) стандардни Цассандра сервери одговорни за чување података на локалним дисковима. Како расте оптерећење и обим података, њихова количина се лако може скалирати на десетине и стотине.
- Координатори трансакција – обезбеђују извршење трансакција.
- Клијенти су сервери апликација који имплементирају пословне операције и покрећу трансакције. Таквих клијената може бити на хиљаде.
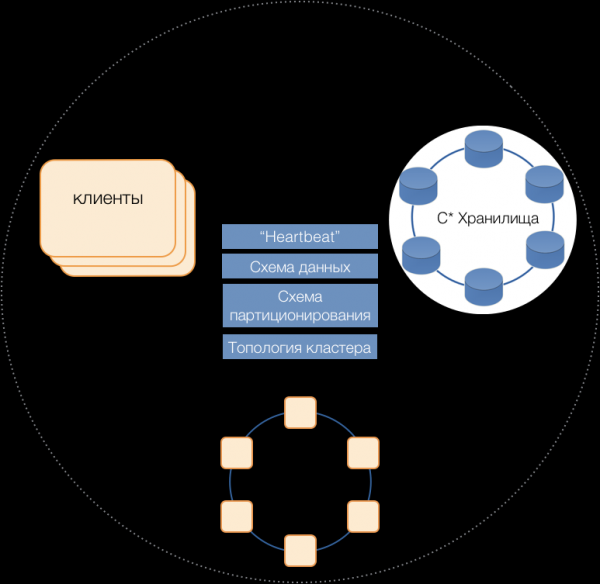
Сервери свих типова су део заједничког кластера, користе интерни Цассандра протокол за поруке да комуницирају једни са другима и за размену информација о кластерима. Уз Хеартбеат, сервери уче о међусобним кваровима, одржавају јединствену шему података – табеле, њихову структуру и репликацију; шема партиционисања, топологија кластера итд.
Клијенти
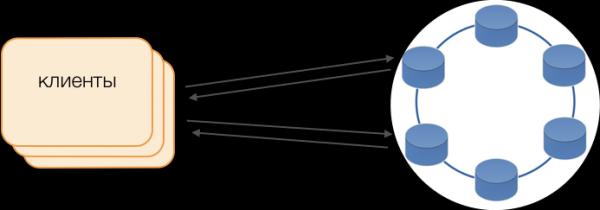
Уместо стандардних драјвера, користи се режим Фат Цлиент. Такав чвор не чува податке, али може да делује као координатор за извршење захтева, односно сам Клијент делује као координатор његових захтева: испитује реплике складишта и решава конфликте. Ово није само поузданије и брже од стандардног драјвера, који захтева комуникацију са удаљеним координатором, већ вам омогућава и контролу преноса захтева. Изван трансакције отворене на клијенту, захтеви се шаљу у ризнице. Ако је клијент отворио трансакцију, онда се сви захтеви у оквиру трансакције шаљу координатору трансакције.
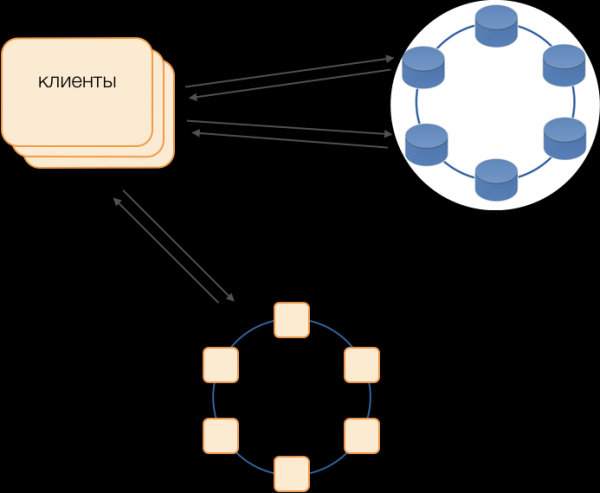
Ц*Оне Трансацтион Цоординатор
Координатор је нешто што смо имплементирали за Ц*Оне од нуле. Одговоран је за управљање трансакцијама, закључавањем и редоследом по којем се трансакције примењују.
За сваку сервисирану трансакцију, координатор генерише временску ознаку: свака следећа трансакција је већа од претходне. Пошто је Касандрин систем решавања сукоба заснован на временским ознакама (од два конфликтна записа, онај са најновијом временском ознаком се сматра актуелним), конфликт ће увек бити решен у корист наредне трансакције. Тако смо имплементирали - јефтин начин за решавање конфликата у дистрибуираном систему.
Браве
Да бисмо обезбедили изолацију, одлучили смо да користимо најједноставнији метод - песимистичке браве на основу примарног кључа записа. Другим речима, у трансакцији, запис прво мора бити закључан, тек онда прочитан, модификован и сачуван. Тек након успешног урезивања, запис се може откључати како би конкурентске трансакције могле да га користе.
Имплементација таквог закључавања је једноставна у недистрибуираном окружењу. У дистрибуираном систему постоје две главне опције: или имплементирати дистрибуирано закључавање на кластер, или дистрибуирати трансакције тако да трансакције које укључују исти запис увек опслужује исти координатор.
Пошто су у нашем случају подаци већ распоређени по групама локалних трансакција у СКЛ-у, одлучено је да се локалне групе трансакција доделе координаторима: један координатор обавља све трансакције са токенима од 0 до 9, други - са токенима од 10 до 19, и тако даље. Као резултат, свака од инстанци координатора постаје господар групе трансакција.
Затим се браве могу имплементирати у облику баналног ХасхМап-а у меморији координатора.
Грешке координатора
Пошто један координатор искључиво опслужује групу трансакција, веома је важно брзо утврдити чињеницу његовог неуспеха како би други покушај извршења трансакције истекао. Да бисмо ово учинили брзим и поузданим, користили смо потпуно повезан кворум Хеатбеат протокол:
Сваки центар података има најмање два координаторска чвора. Периодично, сваки координатор шаље поруку о откуцају срца другим координаторима и обавештава их о свом функционисању, као ио томе које поруке откуцаја срца је примио од којих координатора у кластеру последњи пут.
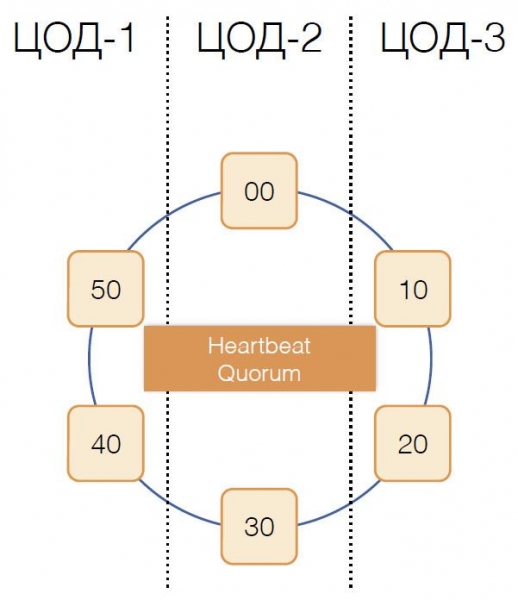
Примајући сличне информације од других као део својих срчаних порука, сваки координатор за себе одлучује који чворови кластера функционишу, а који не, водећи се принципом кворума: ако је чвор Кс примио информације од већине чворова у кластеру о нормалном пријем порука од чвора И, затим , И ради. И обрнуто, чим већина пријави недостајуће поруке са чвора И, онда је И одбио. Занимљиво је да ако кворум обавести чвор Кс да више не прима поруке од њега, онда ће сам чвор Кс сматрати да није успео.
Поруке откуцаја срца се шаљу високом фреквенцијом, око 20 пута у секунди, са периодом од 50 мс. У Јави је тешко гарантовати одговор апликације у року од 50 мс због упоредиве дужине пауза које изазива сакупљач смећа. Успели смо да постигнемо ово време одзива помоћу Г1 сакупљача смећа, који нам омогућава да наведемо циљ за трајање ГЦ пауза. Међутим, понекад, прилично ретко, паузе колектора прелазе 50 мс, што може довести до лажне детекције квара. Да се то не догоди, координатор не пријављује квар удаљеног чвора када нестане прва порука откуцаја срца, само ако је неколико нестало заредом Госпођа.
Али није довољно да се брзо схвати који чвор је престао да функционише. Морамо да урадимо нешто по том питању.
Резервација
Класична шема укључује, у случају неуспеха главног, започињање нових избора користећи један од алгоритми. Међутим, такви алгоритми имају добро познате проблеме са временском конвергенцијом и дужином самог изборног процеса. Успели смо да избегнемо таква додатна кашњења користећи шему замене координатора у потпуно повезаној мрежи:
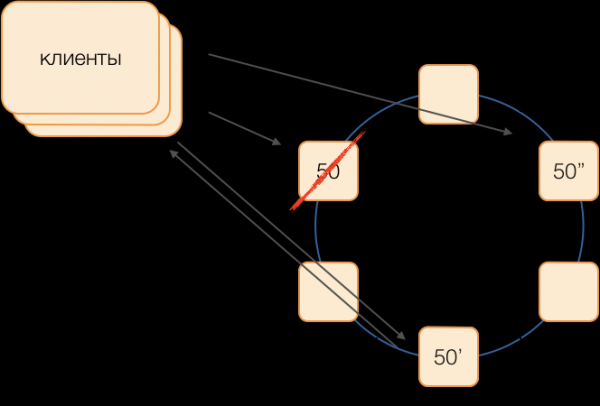
Рецимо да желимо да извршимо трансакцију у групи 50. Хајде да унапред одредимо шему замене, односно који чворови ће извршити трансакције у групи 50 у случају квара главног координатора. Наш циљ је да очувамо функционалност система у случају квара дата центра. Одредимо да ће прва резерва бити чвор из другог дата центра, а друга резерва ће бити чвор из трећег. Ова шема се бира једном и не мења се све док се топологија кластера не промени, односно док у њу не уђу нови чворови (што се дешава веома ретко). Процедура за избор новог активног мастера у случају квара старог увек ће бити следећа: прва резерва постаје активни мастер, а ако је престала да функционише, друга резерва постаје активни мастер.
Ова шема је поузданија од универзалног алгоритма, јер је за активирање новог мастера довољно утврдити квар старог.
Али како ће клијенти разумети који мајстор сада ради? Немогуће је послати информације хиљадама клијената за 50 мс. Могућа је ситуација када клијент пошаље захтев за отварање трансакције, још не знајући да овај мастер више не функционише, а захтев ће истећи. Да се то не би догодило, клијенти шпекулативно шаљу захтев за отварање трансакције мастеру групе и обе његове резерве одједном, али ће на овај захтев одговорити само онај који је тренутно активни мастер. Клијент ће обављати сву наредну комуникацију у оквиру трансакције само са активним мастером.
Бацкуп мастери стављају примљене захтеве за трансакције које нису њихове у ред нерођених трансакција, где се чувају неко време. Ако активни мастер умре, нови мастер обрађује захтеве за отварање трансакција из свог реда и одговара клијенту. Ако је клијент већ отворио трансакцију са старим мастером, онда се други одговор игнорише (и, очигледно, таква трансакција неће бити завршена и клијент ће је поновити).
Како трансакција функционише
Рецимо да је клијент послао захтев координатору да отвори трансакцију за тај и такав ентитет са тим и таквим примарним кључем. Координатор закључава овај ентитет и ставља га у табелу закључавања у меморији. Ако је потребно, координатор чита овај ентитет из складишта и похрањује резултирајуће податке у стању трансакције у меморији координатора.
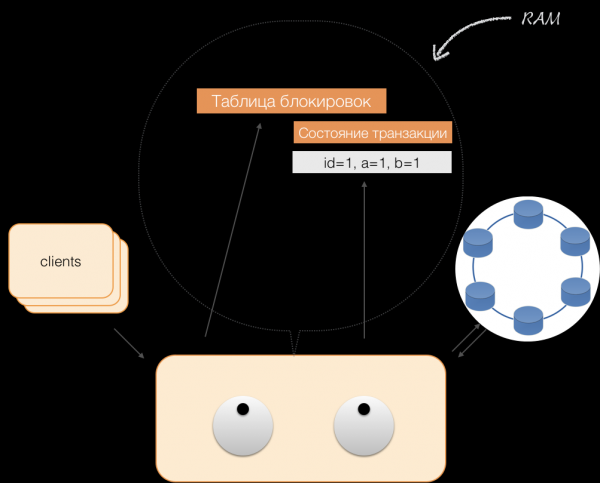
Када клијент жели да промени податке у трансакцији, он шаље захтев координатору да измени ентитет, а координатор смешта нове податке у табелу статуса трансакције у меморију. Овим је снимање завршено - нема снимања у меморији.
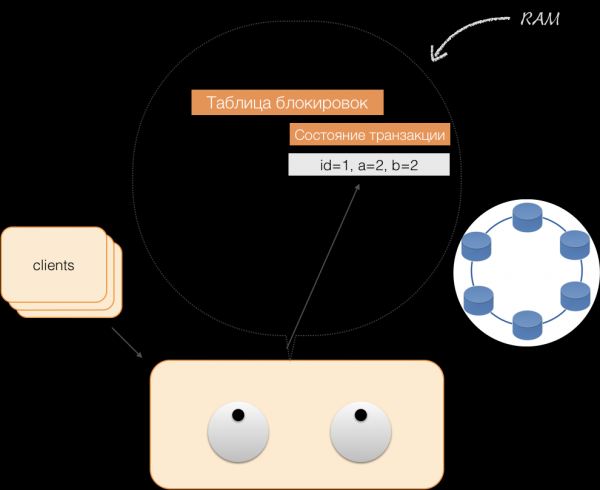
Када клијент захтева своје измењене податке као део активне трансакције, координатор делује на следећи начин:
- ако је ИД већ у трансакцији, онда се подаци узимају из меморије;
- ако у меморији нема ИД-а, онда се подаци који недостају читају из чворова за складиштење, комбинују са онима који су већ у меморији, а резултат се даје клијенту.
Дакле, клијент може да чита своје промене, али други клијенти не виде ове промене, јер се чувају само у меморији координатора, они се још увек не налазе у Цассандра чворовима.
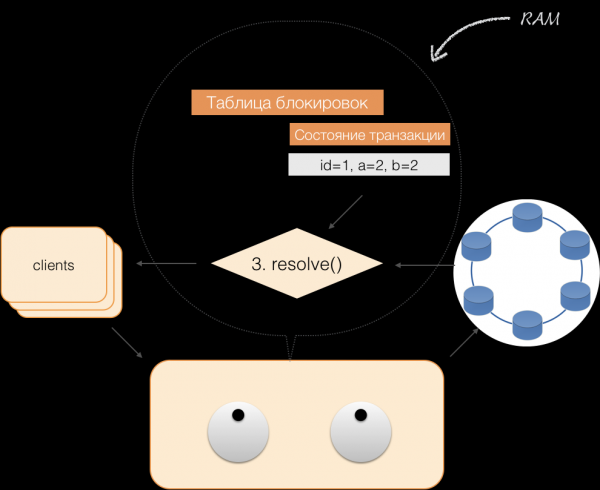
Када клијент пошаље урезивање, стање које је било у меморији услуге чува се од стране координатора у евидентираној групи и шаље се као евидентирана група у Цассандра складиште. Продавнице чине све што је потребно да осигурају да је овај пакет атомски (потпуно) примењен и враћају одговор координатору, који отпушта закључавање и потврђује успех трансакције клијенту.
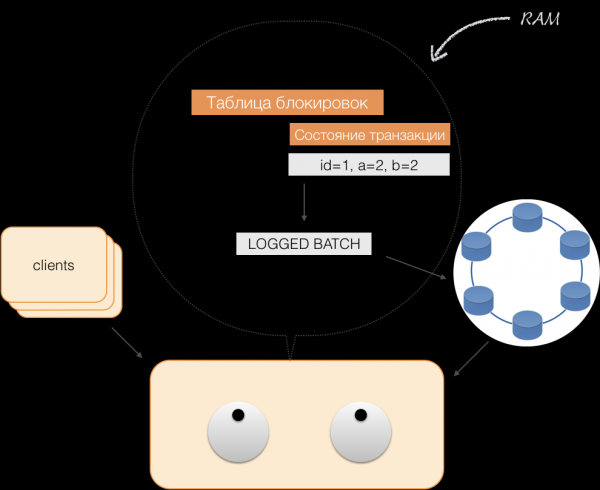
А да би се вратио, координатор треба само да ослободи меморију коју заузима стање трансакције.
Као резултат горе наведених побољшања, имплементирали смо АЦИД принципе:
- Атомицити. Ово је гаранција да ниједна трансакција неће бити делимично забележена у систему или ће све његове подоперације бити завршене, или ниједна неће бити завршена. Ми се придржавамо овог принципа кроз евидентирану групу у Цассандри.
- Доследност. Свака успешна трансакција, по дефиницији, бележи само валидне резултате. Ако се након отварања трансакције и извођења дела операција открије да је резултат неважећи, врши се враћање уназад.
- Изолација. Када се трансакција изврши, истовремене трансакције не би требало да утичу на њен исход. Конкурентне трансакције су изоловане коришћењем песимистичких брава на координатору. За читања ван трансакције, принцип изолације се посматра на нивоу Реад Цоммиттед.
- Постојаност. Без обзира на проблеме на нижим нивоима—замрачење система, квар хардвера—промене направљене успешно завршеном трансакцијом треба да остану сачуване када се операције наставе.
Читање по индексима
Узмимо једноставну табелу:
CREATE TABLE photos (
id bigint primary key,
owner bigint,
modified timestamp,
…)Има ИД (примарни кључ), власника и датум измене. Потребно је да направите врло једноставан захтев - изаберите податке о власнику са датумом промене „за последњи дан“.
SELECT *
WHERE owner=?
AND modified>?Да би се такав упит брзо обрадио, у класичном СКЛ ДБМС-у потребно је изградити индекс по колонама (власник, измењен). То можемо учинити прилично лако, пошто сада имамо гаранције АЦИД!
Индекси у Ц*Оне
Постоји изворна табела са фотографијама у којој је ИД записа примарни кључ.

За индекс, Ц*Оне креира нову табелу која је копија оригинала. Кључ је исти као индексни израз, а такође укључује примарни кључ записа из изворне табеле:
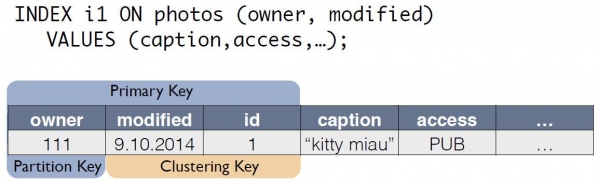
Сада се упит за „власник за последњи дан“ може преписати као избор из друге табеле:
SELECT * FROM i1_test
WHERE owner=?
AND modified>?Координатор аутоматски одржава конзистентност података на фотографијама изворне табеле и индексној табели и1. Само на основу шеме података, када се прими промена, координатор генерише и складишти промену не само у главној табели, већ иу копијама. Не врше се никакве додатне радње на табели индекса, евиденције се не читају и не користе се закључавања. То јест, додавање индекса не троши скоро никакве ресурсе и практично нема утицаја на брзину примене модификација.
Користећи АЦИД, били смо у могућности да имплементирамо индексе сличне СКЛ-у. Они су доследни, скалабилни, брзи, састављајући их и уграђени у ЦКЛ језик упита. Нису потребне промене у коду апликације да би се подржали индекси. Све је једноставно као у СКЛ-у. И што је најважније, индекси не утичу на брзину извршења модификација оригиналне табеле трансакција.
Шта се десило
Развили смо Ц*Оне пре три године и пустили га у комерцијалну употребу.
Шта смо на крају добили? Хајде да то проценимо на примеру подсистема за обраду и складиштење фотографија, једног од најважнијих типова података у друштвеној мрежи. Не говоримо о самим телима фотографија, већ о свим врстама мета-информација. Сада Одноклассники има око 20 милијарди таквих записа, систем обрађује 80 хиљада захтева за читање у секунди, до 8 хиљада АЦИД трансакција у секунди повезаних са модификацијом података.
Када смо користили СКЛ са фактором репликације = 1 (али у РАИД-у 10), метаинформације о фотографијама су биле ускладиштене на високо доступном кластеру од 32 машине које користе Мицрософт СКЛ Сервер (плус 11 резервних копија). Такође је додељено 10 сервера за чување резервних копија. Укупно 50 скупих аутомобила. Истовремено, систем је радио при називном оптерећењу, без резерве.
Након миграције на нови систем, добили смо фактор репликације = 3 - копију у сваком центру података. Систем се састоји од 63 Цассандра чвора за складиштење и 6 координационих машина, за укупно 69 сервера. Али ове машине су много јефтиније, њихова укупна цена је око 30% цене СКЛ система. Истовремено, оптерећење се одржава на 30%.
Са увођењем Ц*Оне, латенција се такође смањила: у СКЛ-у је операција писања трајала око 4,5 мс. У Ц*Оне - око 1,6 мс. Трајање трансакције је у просеку мање од 40 мс, урезивање се завршава за 2 мс, трајање читања и писања је у просеку 2 мс. 99. перцентил - само 3-3,1 мс, број тајм-аута је смањен за 100 пута - све због широко распрострањене употребе спекулација.
До сада је већина СКЛ Сервер чворова повучена из употребе, нови производи се развијају само помоћу Ц*Оне. Прилагодили смо Ц*Оне за рад у нашем облаку , што је омогућило да се убрза имплементација нових кластера, поједностави конфигурација и аутоматизује рад. Без изворног кода, ово би било много теже и гломазније.
Сада радимо на преношењу наших осталих складишних капацитета у облак – али то је сасвим друга прича.
Извор: ввв.хабр.цом
