

1. Data awal
Pabersihan data mangrupikeun salah sahiji tantangan anu disanghareupan ku tugas analisis data. Artikel ieu nampilkeun panemuan sareng solusi anu muncul tina ngarengsekeun masalah praktis analisis database pikeun itungan nilai kadaster. File sumber sayogi di dieu. .
File "Comparative model result.ods" parantos diulas dina "Appendix B. Results of determination KS 5. Information about the method for determination cadastral value 5.1 Comparative approach".
Tabel 1. Indikator statistik tina kumpulan data dina file "Comparative model result.ods"
Jumlah total widang, pcs. — 44
Jumlah total rékaman, pcs. — 365.490
Jumlah karakter: 101.714.693
Rata-rata jumlah karakter per postingan: 278,297
Simpangan baku karakter dina rékaman, pcs. — 15,510
Jumlah karakter minimum per entri: 198
Jumlah karakter maksimum per entri: 363
2. Bagian bubuka. Standar dasar
Nalika nganalisis database ieu, tugas anu muncul nyaéta nangtukeun sarat pikeun tingkat beberesih, sabab, sakumaha anu jelas pikeun sadayana, database ieu nyiptakeun akibat hukum sareng ékonomi pikeun pangguna. Salila prosésna, janten jelas yén teu aya sarat khusus pikeun tingkat beberesih data ageung anu parantos ditetepkeun. Nganalisis peraturan hukum ngeunaan masalah ieu, kuring nyimpulkeun yén sadayana dumasar kana kamampuan. Nyaéta, tugas khusus muncul, sumber inpormasi disusun pikeun tugas ieu, kumpulan data teras didamel, sareng, dumasar kana kumpulan data anu didamel, alat pikeun ngarengsekeun tugas dikembangkeun. Solusi anu dihasilkeun janten titik rujukan pikeun milih di antara alternatif. Ieu dipidangkeun dina Gambar 1.
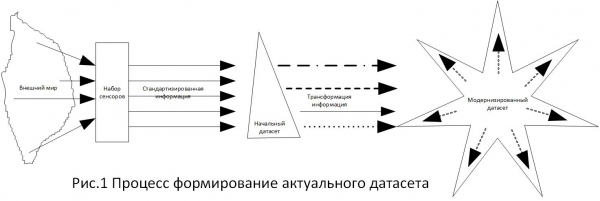
Kusabab, dina urusan nangtukeun standar naon waé, langkung saé ngandelkeun téknologi anu kabuktian, kuring milih sarat anu ditetepkeun dina dasar kriteria analisis , sabab kuring nganggap dokumén ieu anu paling lengkep ngeunaan masalah ieu. Sacara khusus, bagian dokumén ieu nyatakeun, "Perlu dicatet yén sarat integritas data lumaku sami pikeun data manual (kertas) sareng éléktronik." Kecap-kecap ieu sacara khusus aya hubunganana sareng konsép "bukti tinulis" dina Pasal 71 Kitab Undang-Undang Hukum Acara Perdata, Pasal 70 Kitab Undang-Undang Hukum Acara Administratif, Pasal 75 Kitab Undang-Undang Hukum Acara Arbitrase, sareng "bentuk tinulis" dina Pasal 84 Kitab Undang-Undang Hukum Acara Perdata.
Gambar 2 nampilkeun diagram formasi pendekatan kana jinis inpormasi dina yurisprudensi.
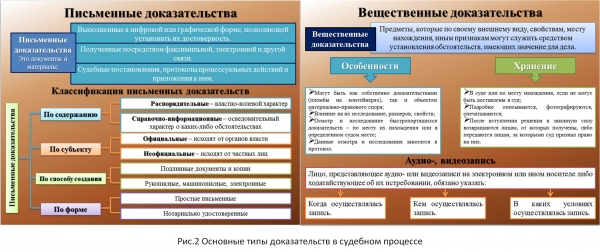
Gambar 2. Sumber .
Gambar 3 nunjukkeun mékanisme dina Gambar 1 pikeun tugas "Pituduh" anu kasebat di luhur. Ku ngabandingkeun ieu, gampang pikeun ningali yén pendekatan anu dianggo pikeun minuhan sarat integritas inpormasi dina peraturan sistem inpormasi modéren sacara signifikan diwatesanan dibandingkeun sareng konsép hukum inpormasi.
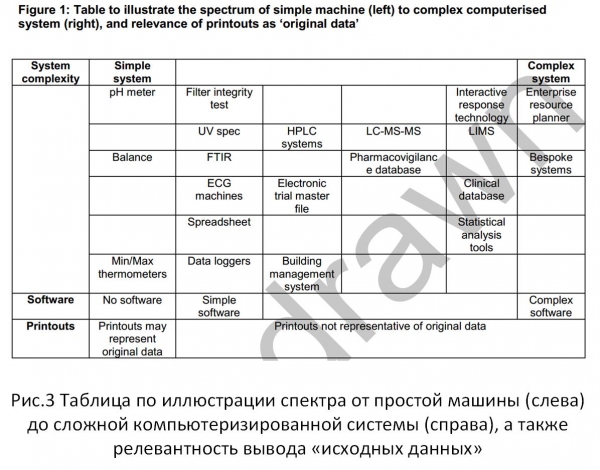
Gbr.3
Dina dokumén (Pituduh), tautan ka bagian téknis, kamampuan pikeun ngolah sareng nyimpen data, dikonfirmasi kalayan saé ku cutatan tina Bab 18.2. Basis data relasional: "Struktur file ieu sacara inheren langkung aman, sabab data disimpen dina format file ageung anu ngajaga hubungan antara data sareng metadata."
Intina mah, teu aya anu anéh ngeunaan pendekatan ieu—gumantung kana kamampuan téknis anu tos aya—sareng éta mangrupikeun prosés alami, sabab ékspansi konsép asalna tina kagiatan anu paling seueur ditalungtik: desain database. Nanging, di sisi anu sanés, norma hukum nuju muncul anu henteu ngamungkinkeun pikeun ngijinkeun kamampuan téknis sistem anu tos aya, contona: .

Gambar 4. Corong kamampuan téknis ().
Dina hal ieu, janten jelas yén sét data awal (Gambar 1) kedah dijaga heula sareng anu paling penting, sareng anu kadua janten dasar pikeun ngekstrak inpormasi tambahan tina éta. Salaku conto, kaméra lalu lintas aya di mana-mana, sareng sistem pamrosésan inpormasi nyaring palanggaran. Nanging, inpormasi anu sésana ogé tiasa ditawarkeun ka konsumen sanés, contona, pikeun ngawaskeun pamasaran pola aliran palanggan di pusat balanja. Ieu mangrupikeun sumber nilai tambah tambahan nalika nganggo Big Data. Bisa jadi pisan yén sét data anu dikumpulkeun ayeuna, di hareup, bakal gaduh nilai anu sami sareng édisi langka ti taun 1700-an ayeuna. Sabenerna, sét data samentawis sacara dasarna unik sareng teu mungkin diulang di hareup.
3. Bagian bubuka. Kriteria évaluasi
Salila pamrosésan, klasifikasi kasalahan ieu dikembangkeun.
1. Kelas kasalahan (dumasar kana GOST R 8.736-2011): a) kasalahan sistematis; b) kasalahan acak; c) kasalahan kotor.
2. Dumasar kana multiplisitas: a) monodistorsi; b) multidistorsi.
3. Dumasar kana kritisitas akibatna: a) kritis; b) teu kritis.
4. Dumasar kana sumber asal:
A) Téknis – kasalahan anu lumangsung nalika operasi alat. Ieu mangrupikeun kasalahan anu cukup umum pikeun sistem IoT, sistem anu kapangaruhan sacara signifikan ku kualitas sambungan sareng perangkat keras.
B) Kasalahan operator – kasalahan anu mimitian ti salah ketik operator nalika ngasupkeun nepi ka kasalahan dina spésifikasi téknis pikeun desain database.
B) Kasalahan pangguna – di dieu kasalahan pangguna mimitian ti "hilap ngarobih tata letak" dugi ka salah nganggap méter salaku suku.
5. Dipisahkeun kana kelas anu misah:
a) "tugas pamisah", nyaéta, rohangan sareng ":" (dina kasus urang) nalika diduplikasi;
b) kecap-kecap anu ditulis babarengan;
c) teu aya spasi saatos karakter layanan
d) sababaraha simbol simétris: (), "", "...".
Sacara gembleng, kalayan sistematisasi kasalahan basis data anu dipidangkeun dina Gambar 5, sistem koordinat anu cukup efektif dibentuk pikeun milarian kasalahan sareng ngembangkeun algoritma beberesih data pikeun conto ieu.
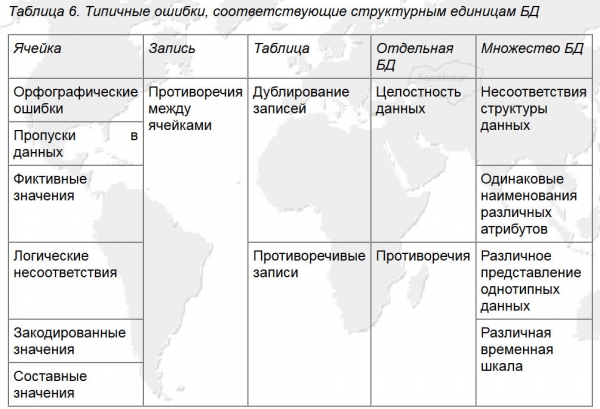
Gambar 5. Kasalahan has anu pakait sareng unit struktural database (Sumber: ).
Akurasi, Integritas Domain, Tipe Data, Konsistensi, Redundansi, Kalengkepan, Duplikasi, Kasaluyuan kana Aturan Bisnis, Kapastian Struktural, Anomali Data, Kajelasan, Tepat Waktu, Patuh kana Aturan Integritas Data. (Kaca 334. Dasar-dasar pergudangan data pikeun profesional IT / Paulraj Ponniah.—éd. ka-2)
Dipidangkeun kecap-kecap basa Inggris sareng tarjamahan mesin Rusia dina jero kurung.
Akurasi. Nilai anu disimpen dina sistem pikeun unsur data nyaéta nilai anu pas pikeun kajadian unsur data éta. Upami anjeun gaduh nami palanggan sareng alamat anu disimpen dina rékaman, maka alamat éta nyaéta alamat anu leres pikeun palanggan anu gaduh nami éta. Upami anjeun mendakan kuantitas anu dipesen salaku 1000 unit dina rékaman pikeun nomer pesenan 12345678, maka kuantitas éta mangrupikeun kuantitas anu akurat pikeun pesenan éta.
[Akurasi. Nilai anu disimpen dina sistem pikeun item data nyaéta nilai anu leres pikeun kajadian item data éta. Upami anjeun gaduh nami sareng alamat palanggan anu disimpen dina rékaman, maka alamat éta nyaéta alamat anu leres pikeun palanggan anu gaduh nami éta. Upami anjeun mendakan kuantitas anu dipesen salaku 1000 unit dina rékaman pikeun nomer pesenan 12345678, maka kuantitas ieu mangrupikeun kuantitas anu pasti pikeun pesenan éta.]
Integritas Domain. Nilai data tina hiji atribut aya dina rentang nilai anu diidinan sareng ditetepkeun. Conto umumna nyaéta nilai anu diidinan nyaéta "lalaki" sareng "awéwé" pikeun unsur data gender.
[Integritas Domain. Nilai data atribut aya dina rentang nilai anu ditetepkeun sareng tiasa ditampi. Conto umum nyaéta nilai anu tiasa ditampi "lalaki" sareng "awéwé" pikeun unsur data gender.]
Tipe Data. Nilai pikeun atribut data sabenerna disimpen salaku tipe data anu ditetepkeun pikeun atribut éta. Nalika tipe data tina widang nami toko ditetepkeun salaku "téks," sadaya conto widang éta ngandung nami toko anu dipidangkeun dina format téks sareng sanés kode numerik.
[Tipe Data. Nilai atribut data sabenerna disimpen salaku tipe data anu ditetepkeun pikeun atribut éta. Upami tipe data tina widang nami toko ditetepkeun salaku "téks," sadaya conto widang éta ngandung nami toko anu ditampilkeun salaku téks tinimbang salaku kode numerik.]
Konsistensi. Bentuk sareng eusi widang data sami di sababaraha sistem sumber. Upami kode produk pikeun produk ABC dina hiji sistem nyaéta 1234, maka kode pikeun produk ieu nyaéta 1234 dina unggal sistem sumber.
[Konsistensi. Bentuk sareng eusi widang data sami di sakumna sistem sumber. Upami kode produk pikeun produk ABC dina hiji sistem nyaéta 1234, maka kode pikeun produk éta nyaéta 1234 dina unggal sistem sumber.]
Redundansi. Data anu sami teu kénging disimpen di langkung ti hiji tempat dina hiji sistem. Upami, kusabab alesan efisiensi, hiji unsur data ngahaja disimpen di langkung ti hiji tempat dina hiji sistem, maka redundansi éta kedah diidentipikasi sareng diverifikasi sacara jelas.
[Redundansi. Data anu sami teu kedah disimpen di langkung ti hiji lokasi dina sistem. Upami, pikeun alesan efisiensi, hiji item data ngahaja disimpen di sababaraha lokasi dina sistem, redundansi éta kedah ditetepkeun sareng diverifikasi sacara jelas.]
Kalengkepan. Teu aya nilai anu leungit pikeun atribut anu dipasihkeun dina sistem. Salaku conto, dina file palanggan, kedah aya nilai anu valid pikeun kolom "state" pikeun unggal palanggan. Dina file pikeun detil pesenan, unggal rékaman detil pikeun pesenan kedah dieusi sacara lengkep.
[Kalengkepan. Sistem teu gaduh nilai anu leungit pikeun atribut ieu. Salaku conto, dina file palanggan, kedah aya nilai anu valid pikeun kolom "status" pikeun unggal palanggan. Dina file detail pesenan, unggal rékaman detail pesenan kedah dieusi sacara lengkep.]
Duplikasi. Duplikasi rékaman dina sistem parantos direngsekeun sapinuhna. Upami file produk dipikanyaho gaduh rékaman duplikat, maka sadaya rékaman duplikat pikeun unggal produk diidéntifikasi sareng rujukan silang didamel.
[Duplikat. Rékaman duplikat dina sistem bakal dihapus sagemblengna. Upami file produk dipikanyaho ngandung rékaman duplikat, sadaya rékaman duplikat pikeun unggal produk bakal diidéntifikasi sareng dirujuk silang.]
Saluyu sareng Aturan Bisnis. Nilai unggal item data nurut kana aturan bisnis anu parantos ditangtukeun. Dina sistem lélang, harga palu atanapi harga jual teu tiasa kirang ti harga cadangan. Dina sistem pinjaman bank, kasaimbangan pinjaman kedah salawasna positif atanapi nol.
[Patuh kana aturan bisnis. Nilai unggal unsur data saluyu sareng aturan bisnis anu tos ditetepkeun. Dina sistem lélang, harga palu atanapi harga jual teu kenging kirang ti harga cadangan. Dina sistem kiridit perbankan, kasaimbangan kiridit kedah salawasna positip atanapi nol.]
Katangtuan Struktural. Dimana waé hiji item data sacara alami tiasa disusun kana komponén individu, item éta kedah ngandung struktur anu ditetepkeun kalayan saé ieu. Salaku conto, nami individu sacara alami dibagi kana nami hareup, inisial tengah, sareng nami tukang. Nilai pikeun nami individu kedah disimpen salaku nami hareup, inisial tengah, sareng nami tukang. Ciri kualitas data ieu ngagampangkeun penegakan standar sareng ngirangan nilai anu leungit.
[Définisi Struktural. Upami hiji unsur data tiasa disusun sacara alami kana komponén anu béda, unsur éta kedah ngandung struktur anu ditetepkeun sacara jelas ieu. Salaku conto, nami jalma sacara alami dibagi kana nami hareup, inisial tengah, sareng nami tukang. Nilai pikeun nami individu kedah disimpen salaku nami hareup, inisial tengah, sareng nami tukang. Karakteristik kualitas data ieu ngagampangkeun aplikasi standar sareng ngirangan nilai anu leungit.]
Anomali Data. Hiji widang kedah dianggo ngan ukur pikeun tujuan anu ditetepkeun. Upami widang Alamat-3 ditetepkeun pikeun naon waé baris katilu alamat pikeun alamat anu panjang, maka widang ieu kedah dianggo ngan ukur pikeun ngarékam baris katilu alamat. Éta henteu kedah dianggo pikeun ngalebetkeun nomer telepon atanapi fax pikeun palanggan.
[Anomali Data: Widang ieu kedah dianggo ngan ukur pikeun tujuan anu ditetepkeun. Upami widang Alamat-3 ditetepkeun pikeun sagala kamungkinan baris alamat katilu pikeun alamat anu panjang, maka widang ieu ngan ukur kedah dianggo pikeun ngarékam baris alamat katilu. Éta henteu kedah dianggo pikeun ngalebetkeun nomer telepon atanapi fax pikeun palanggan.]
Kajelasan. Hiji unsur data bisa jadi mibanda sadaya ciri séjén tina data kualitas tapi upami pangguna henteu ngartos hartosna kalayan jelas, maka unsur data éta teu aya nilaina pikeun pangguna. Konvénsi penamaan anu leres ngabantosan ngajantenkeun unsur data kahartos kalayan saé ku pangguna.
[Kajelasan. Hiji unsur data bisa jadi mibanda sadaya ciri séjén tina data anu saé, tapi upami pangguna henteu ngartos hartosna sacara jelas, unsur data éta teu aya nilaina pikeun aranjeunna. Konvénsi penamaan anu leres ngabantosan ngajantenkeun unsur data gampang kahartos ku pangguna.]
Tepat waktu. Pangguna nangtukeun katepatan waktu data. Upami pangguna ngarepkeun data diménsi palanggan henteu langkung lami tibatan hiji dinten, parobihan kana data palanggan dina sistem sumber kedah diterapkeun kana gudang data unggal dinten.
[Pas waktuna. Pangguna nangtukeun kawaktuan data. Upami pangguna ngarepkeun data pangukuran palanggan henteu langkung ti hiji dinten, parobihan kana data palanggan dina sistem sumber kedah diterapkeun kana gudang data unggal dinten.]
Mangpaatna. Unggal unsur data dina gudang data kedah nyumponan sababaraha sarat tina pangumpulan pangguna. Unsur data tiasa akurat sareng kualitasna luhur, tapi upami teu aya nilaina pikeun pangguna, maka unsur data éta teu kedah aya dina gudang data.
[Kagunaan. Unggal item data dina gudang data kedah nyumponan sarat pangumpulan pangguna anu tangtu. Item data tiasa akurat sareng kualitasna luhur, tapi upami éta henteu masihan nilai ka pangguna, maka teu aya alesan pikeun item data éta aya dina gudang data.]
Patuh kana Aturan Integritas Data. Data anu disimpen dina database relasional sistem sumber kedah patuh kana aturan integritas éntitas sareng integritas rujukan. Tabel naon waé anu ngijinkeun null salaku konci primér henteu gaduh integritas éntitas. Integritas rujukan maksa ngadegna hubungan induk-anak kalayan leres. Dina hubungan palanggan-ka-pesenan, integritas rujukan mastikeun ayana palanggan pikeun unggal pesenan dina database.
Ngajaga integritas data. Data anu disimpen dina database relasional sistem sumber kedah nurut kana aturan integritas éntitas sareng referensial. Sagala tabel anu ngamungkinkeun konci primér null kakurangan integritas éntitas. Integritas referensial mastikeun yén hubungan induk-anak ditetepkeun kalayan leres. Dina hubungan pesenan palanggan, integritas referensial mastikeun ayana palanggan pikeun unggal pesenan dina database.
4. Kualitas beberesih data
Kualitas beberesih data mangrupikeun masalah anu rada nangtang dina big data. Nangtukeun tingkat beberesih data anu diperyogikeun pikeun tugas anu dipasihkeun mangrupikeun patarosan konci pikeun unggal analis data. Dina kalolobaan tugas ayeuna, unggal analis nangtukeun ieu pikeun dirina sorangan, sareng sigana mah jalma luar tiasa meunteun aspék solusi ieu. Nanging, pikeun tugas anu aya, patarosan ieu penting pisan, sabab reliabilitas data légal kedah caket kana hiji.
Mertimbangkeun téknologi uji coba perangkat lunak pikeun nangtukeun reliabilitas operasional. Aya langkung ti 100 modél ieu ayeuna. Seueur modél nganggo modél dumasar pamundut:
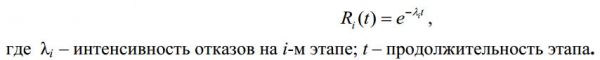
Gbr. Xnumx
Kuring mikir kieu: "Upami kasalahan anu dideteksi mangrupikeun kajadian anu sami sareng kagagalan dina modél ieu, kumaha carana kuring mendakan analog tina parameter t?" Kuring ngembangkeun modél ieu: Hayu urang bayangkeun yén waktos anu diperyogikeun ku panguji pikeun mariksa hiji rékaman nyaéta 1 menit (pikeun database anu dimaksud). Teras, pikeun mendakan sadaya kasalahan, aranjeunna peryogi 365.494 menit, nyaéta sakitar 3 taun 3 bulan damel. Sakumaha anu urang pahami, ieu mangrupikeun jumlah padamelan anu penting pisan, sareng biaya mariksa database bakal mahal pisan pikeun anu nyiptakeun database ieu. Dina réfléksi ieu, konsép ékonomi ngeunaan biaya muncul, sareng saatos analisis, kuring nyimpulkeun yén éta mangrupikeun alat anu cukup efektif. Dumasar kana hukum ékonomi: "Volume produksi (dina unit) dimana perusahaan ngahontal kauntungan maksimum aya dina titik dimana biaya marginal pikeun ngahasilkeun unit output anyar sami sareng harga anu tiasa ditampi ku perusahaan pikeun unggal unit anyar." Dumasar kana postulat yén mendakan unggal kasalahan salajengna meryogikeun langkung seueur rékaman anu kedah dipariksa, ieu mangrupikeun faktor biaya. Hartina, postulat anu diadopsi dina modél uji ngagaduhan harti fisik dina pola ieu: upami pikeun mendakan kasalahan ka-i diperyogikeun pikeun mariksa n rékaman, teras pikeun mendakan kasalahan (i+1) salajengna, anjeun kedah mariksa m rékaman sareng dina waktos anu sami n
- Nalika jumlah rékaman anu dipariksa sateuacan kasalahan anyar kapanggih janten stabil;
- Nalika jumlah rékaman anu dipariksa sateuacan kasalahan salajengna kapanggih bakal ningkat.
Pikeun nangtukeun nilai kritis, kuring ngarujuk kana konsép kalayakan ékonomi, anu dina hal ieu, nganggo konsép biaya sosial, tiasa dirumuskeun sapertos kieu: "Biaya pikeun ngabenerkeun kasalahan kedah ditanggung ku agén ékonomi anu tiasa ngalakukeun éta kalayan biaya anu paling handap." Urang gaduh hiji agén - hiji panguji anu nyéépkeun 1 menit pikeun mariksa hiji rékaman. Dina istilah moneter, kalayan panghasilan 6000 rubel per dinten, ieu bakal janten 12,2 rubel (sakitar ayeuna). Tetep nangtukeun sisi kadua tina kasaimbangan dina hukum ékonomi. Kuring alesan sapertos kieu. Kasalahan anu aya bakal meryogikeun anu kapangaruhan, nyaéta, nu boga properti, pikeun ngaluarkeun usaha pikeun ngabenerkeunana. Hayu urang anggap ieu meryogikeun 1 dinten tindakan (ngalebetkeun aplikasi, nampi dokumén anu dikoréksi). Teras, tina sudut pandang sosial, biaya na bakal sami sareng upah rata-rata sadinten. Rata-rata upah anu dikumpulkeun di Okrug Otonom Khanty-Mansi ku 73285 rubel atanapi 3053,542 rubel per dinten. Ku kituna, urang kéngingkeun nilai kritis anu sami sareng:
3053,542: 12,2 = 250,4 unit rékaman.
Ieu hartina, tina sudut pandang masarakat, upami panguji mariksa 251 rékaman sareng mendakan hiji kasalahan, éta sami sareng pangguna anu ngalereskeun kasalahan éta nyalira. Ku kituna, upami panguji nyéépkeun waktos anu sami pikeun mariksa 252 rékaman pikeun mendakan kasalahan salajengna, maka biaya pikeun ngalereskeunana kedah disalurkeun ka pangguna.
Pamarekan ieu disederhanakeun, sabab tina sudut pandang masarakat, perlu mertimbangkeun sadaya biaya tambahan anu dihasilkeun ku unggal spesialis, nyaéta, biaya kalebet pajak sareng kontribusi jaminan sosial. Nanging, modélna jelas. Hubungan ieu ngarah kana sarat ieu pikeun spesialis: spesialis IT kedah gaduh gaji anu langkung luhur tibatan rata-rata nasional. Upami gajina langkung handap tibatan gaji rata-rata calon pangguna database, aranjeunna kedah ngaudit sadayana database sacara pribadi.
Nalika nganggo kriteria anu dijelaskeun, sarat munggaran pikeun kualitas database kabentuk:
I(tr). Proporsi kasalahan kritis teu kedah ngaleuwihan 1/250,4 = 0,39938%. Rada kirang ti emas dina industri. Sareng dina istilah fisik, teu aya langkung ti 1459 éntri anu aya kasalahan.
Mundurna ékonomi.
Intina mah, ku cara ngantepkeun sajumlah kasalahan dina rékaman, masarakat satuju kana karugian ékonomi dina jumlah:
1459*3053,542 = 3.664.250 rubel.
Jumlah ieu ditangtukeun ku kanyataan yén masarakat kakurangan alat pikeun ngirangan biaya ieu. Ku kituna, upami aya anu ngembangkeun téknologi anu ngirangan jumlah rékaman anu ngagaduhan kasalahan janten, contona, 259, ieu ngamungkinkeun masarakat pikeun ngahémat:
1200*3053,542 = 3.664.250 rubel.
Tapi dina waktos anu sami, anjeunna tiasa nyuhunkeun, hayu urang sebutkeun, 1 juta rubel pikeun bakat sareng padamelanna.
Hartina, biaya sosial dikirangan ku:
3.664.250 – 1.000.000 = 2.664.250 rubel.
Intina mah, éfék ieu mangrupa nilai tambah tina panggunaan téknologi BigData.
Tapi penting pikeun dipertimbangkeun yén ieu mangrupikeun pangaruh sosial, sareng anu gaduh database nyaéta pamaréntah kotamadya. Panghasilan aranjeunna tina ngagunakeun properti anu kacatet dina database ieu, kalayan tingkat bunga 0,3%, nyaéta 2,778 milyar rubel per taun. Biaya ieu (4.455.118 rubel) henteu pati penting pikeun aranjeunna, sabab éta disalurkeun ka anu gaduh properti. Ku alatan éta, pamekar téknologi anu langkung saé dina BigData kedah nunjukkeun kamampuanana pikeun ngayakinkeun anu gaduh database, sareng hal-hal sapertos kitu meryogikeun bakat anu lumayan.
Dina conto ieu, algoritma penilaian kasalahan dipilih dumasar kana modél Schumann [2] pikeun uji reliabilitas perangkat lunak. Ieu dilakukeun kusabab panggunaanana anu nyebar dina jaringan sareng kamampuan pikeun kéngingkeun indikator statistik anu diperyogikeun. Metodologi ieu dicandak tina "Functional Stability of Information Systems" karya Yu. M. Monakhov (tingali spoiler dina Gambar 7-9).
Gambar 7 – 9 Metodologi modél Schumann


Bagian kadua tina bahan ieu nampilkeun conto beberesih data dimana hasil ngagunakeun modél Schumann diala.
Hayu atuh kuring nepikeun hasil anu diala:
Perkiraan jumlah kasalahan N = 3167 shN.
Parameter C, lambda sareng fungsi reliabilitas:
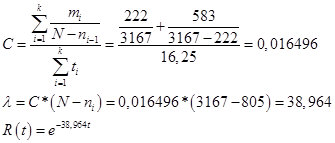
Gbr.17
Intina mah, lambda téh mangrupa indikator sabenerna tina laju kasalahan anu dideteksi dina unggal tahapan. Dina bagian kadua, perkiraan lambda nyaéta 42,4 kasalahan per jam, anu ampir sarua jeung indikator Schumann. Di luhur ditangtukeun yén laju deteksi kasalahan pamekar teu kedah kirang ti 1 kasalahan per 250,4 rékaman, kalayan hiji rékaman per menit anu dipariksa. Ku kituna, nilai lambda kritis pikeun modél Schumann nyaéta:
60 / 250,4 = 0,239617.
Hartina, kabutuhan pikeun ngalaksanakeun prosedur deteksi kasalahan kedah dilaksanakeun dugi ka lambda, tina 38,964 anu aya, turun ka 0,239617.
Atawa nepi ka indikator N (jumlah poténsi kasalahan) dikurangan n (jumlah kasalahan anu dikoréksi) nurun di handap ambang batas anu parantos urang anggo – 1459 pcs.
pustaka
- Monakov, Yu. M. stabilitas fungsi sistem informasi. Dina 3 bagian. Bagian 1. Reliabiliti software: buku ajar / Yu. M. Monakhov; Universitas kaayaan Vladimir. – Vladimir: universitas kaayaan Izdvo Vladimir, 2011. – 60 p. – ISBN 978-5-9984-0189-3.
- Martin L. Shooman, “Modél probabilistik pikeun prediksi reliabilitas perangkat lunak.”
- Dasar-dasar gudang data pikeun para profesional IT / Paulraj Ponniah.—éd. ka-2.
sumber: www.habr.com
