

Hej, Habr! Jag presenterar för din uppmärksamhet en översättning av artikeln av Adib Daw.
Om den rubriken inte får en liten rysning längs ryggraden bör du hoppa till nästa stycke eller besöka vår sida tillägnad – vi skulle vilja prata.
Vem vi är
Vi är ett team på fyra pingviner som älskar att koda och arbeta med hårdvara. På fritiden ansvarar vi för att driftsätta, underhålla och driva en flotta på över 4 7000 fysiska servrar. Linux, fördelade över 3 olika datacenter över hela USA.
Vi hade också möjlighet att göra detta 10 000 km från platser, från bekvämligheten av vårt eget kontor, som ligger en kort bilresa från stranden vid Medelhavet.
Skala problem
Även om det är vettigt för en startup att börja med att hosta sin infrastruktur i molnet på grund av den relativt låga initiala investeringen, beslutade vi på Outbrain att använda våra egna servrar. Vi gjorde detta eftersom kostnaderna för molninfrastruktur vida överstiger kostnaderna för att driva vår egen utrustning placerad i datacenter efter utveckling till en viss nivå. Dessutom ger din server högsta grad av kontroll och felsökningsmöjligheter.
När vi utvecklas finns alltid problem i närheten. Dessutom kommer de vanligtvis i grupp. Serverlivscykelhantering kräver ständig självförbättring för att kunna fungera korrekt i samband med den snabba ökningen av antalet servrar. Mjukvarumetoder för att hantera servergrupper i datacenter blir snabbt svårhanterliga. Att upptäcka, felsöka och mildra misslyckanden samtidigt som man möter QoS-standarder blir en fråga om att jonglera med extremt olika uppsättningar av hårdvara, varierande arbetsbelastningar, uppgraderingsdeadlines och andra trevliga saker som ingen vill oroa sig för.
Bemästra dina domäner
För att lösa många av dessa problem delade vi ner serverlivscykeln i Outbrain i dess huvudkomponenter och kallade dem domäner. Till exempel täcker en domän utrustningskrav, en annan täcker logistik relaterad till lagerlivscykeln och en tredje täcker kommunikation med fältpersonal. Det finns en annan som gäller observerbarhet av hårdvara, men vi kommer inte att beskriva alla punkter. Vårt mål var att studera och definiera domäner så att de kunde abstraheras med hjälp av kod. När en fungerande abstraktion väl har utvecklats överförs den till en manuell process som distribueras, testas och förfinas. Slutligen är domänen konfigurerad för att integreras med andra domäner via API:er, vilket bildar ett holistiskt, dynamiskt och ständigt utvecklande hårdvarulivscykelsystem som är utplacerbart, testbart och observerbart. Precis som alla våra andra produktionssystem.
Genom att använda detta tillvägagångssätt kunde vi lösa många problem korrekt - genom att skapa verktyg och automatisering.
Behöver domän
Även om e-post och kalkylblad var ett gångbart sätt att möta efterfrågan i början, var det inte en framgångsrik lösning, särskilt när antalet servrar och volymen av inkommande förfrågningar nådde en viss nivå. För att bättre organisera och prioritera inkommande förfrågningar inför snabb expansion var vi tvungna att använda ett biljettsystem som kunde erbjuda:
- Möjlighet att anpassa vyn av endast relevanta fält (enkelt)
- Öppna API:er (utbyggbara)
- Känd för vårt team (förstått)
- Integration med våra befintliga arbetsflöden (unified)
Eftersom vi använder Jira för att hantera våra sprints och interna uppgifter, bestämde vi oss för att skapa ett annat projekt som skulle hjälpa våra kunder att skicka in biljetter och spåra deras resultat. Genom att använda Jira för inkommande förfrågningar och för att hantera interna uppgifter kunde vi skapa en enda Kanban-tavla som gjorde det möjligt för oss att titta på alla processer som en helhet. Våra interna "klienter" såg bara förfrågningar om utrustning, utan att fördjupa sig i de mindre viktiga detaljerna för ytterligare uppgifter (som att förbättra verktyg, fixa buggar).
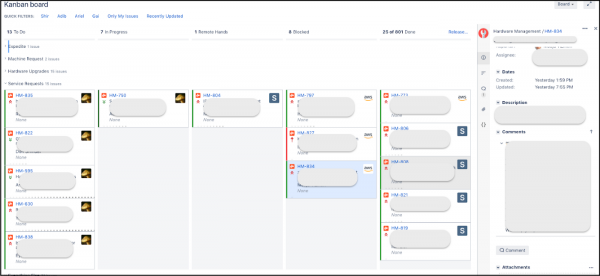
Kanban styrelse i Jira
Som en bonus gjorde det faktum att köer och prioriteringar nu var synliga för alla det möjligt att förstå "var i kön" en viss förfrågan fanns och vad som föregick den. Detta gjorde det möjligt för ägare att omprioritera sina egna förfrågningar utan att behöva kontakta oss. Dra det och det är det. Det gjorde det också möjligt för oss att övervaka och utvärdera våra SLA:er enligt förfrågningstyper baserat på mätvärdena genererade i Jira.
Equipment Lifecycle Domain
Försök att föreställa dig komplexiteten i att hantera hårdvaran som används i varje serverrack. Vad som är ännu värre är att många delar av hårdvara (RAM, ROM) kan flyttas från lagret till serverrummet och tillbaka. De misslyckas också eller skrivs av och ersätts och returneras till leverantören för utbyte/reparation. Allt detta måste meddelas samlokaliseringstjänstens anställda som är involverade i det fysiska underhållet av utrustningen. För att lösa dessa problem skapade vi ett internt verktyg som heter Floppy. Hans uppgift är:
- Hantering av kommunikation med fältpersonal, sammanställning av all information;
- Uppdatering av "lager"-data efter varje avslutat och verifierat utrustningsunderhållsjobb.
Lagret i sin tur visualiseras med Grafana, som vi använder för att plotta alla våra mätvärden. Därför använder vi samma verktyg för lagervisualisering och för andra produktionsbehov.
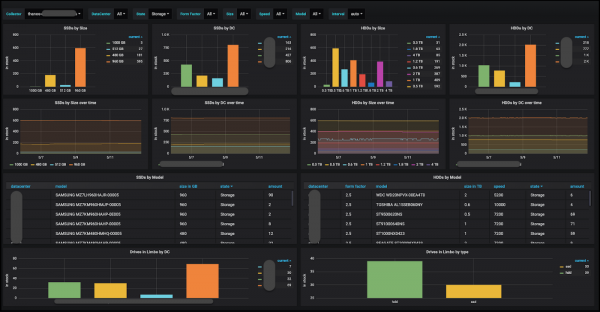 Kontrollpanel för lagerutrustning i Grafana
Kontrollpanel för lagerutrustning i Grafana
För serverenheter som är under garanti använder vi ett annat verktyg som vi kallar Dispatcher. Han:
- Samlar systemloggar;
- Genererar rapporter i det format som krävs av leverantören;
- Skapar en begäran från leverantören via API;
- Tar emot och lagrar applikationsidentifieraren för ytterligare spårning av dess framsteg.
När vårt krav har godkänts (vanligtvis inom kontorstid), skickas reservdelen till lämpligt datacenter och accepteras av personalen.
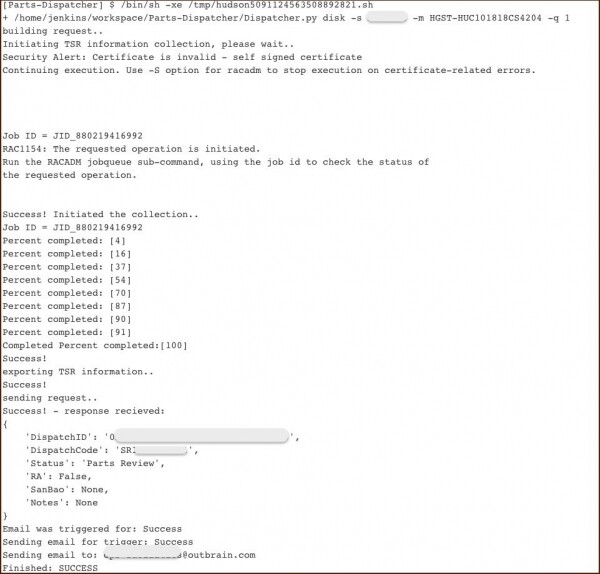
Jenkins konsolutgång
Kommunikationsdomän
För att hänga med i den snabba tillväxten av vår verksamhet, som kräver ständigt ökad kapacitet, var vi tvungna att anpassa vårt sätt att arbeta med tekniska specialister i lokala datacenter. Om uppskalningen till en början innebar att köpa nya servrar, så blev det efter ett konsolideringsprojekt (baserat på övergången till Kubernetes) något helt annat. Vår utveckling från att "lägga till rack" till "att återanvända servrar."
Att använda ett nytt tillvägagångssätt krävde också nya verktyg som gjorde det möjligt att interagera mer bekvämt med datacenterpersonal. Dessa verktyg krävdes för att:
- Enkelhet;
- Autonomi;
- Effektivitet;
- Pålitlighet.
Vi fick utesluta oss från kedjan och strukturera arbetet så att tekniker direkt kunde arbeta med serverutrustning. Utan vårt ingripande och utan att regelbundet ta upp alla dessa frågor gällande arbetsbelastning, arbetstider, utrustningstillgänglighet osv.
För att uppnå detta installerade vi iPads i varje datacenter. Efter anslutning till servern kommer följande att hända:
- Enheten bekräftar att den här servern verkligen kräver en del arbete;
- Applikationer som körs på servern stängs (vid behov);
- En uppsättning arbetsinstruktioner publiceras på en Slack-kanal som förklarar de steg som krävs;
- Efter avslutat arbete kontrollerar enheten riktigheten av serverns slutliga tillstånd;
- Startar om applikationer vid behov.
Dessutom förberedde vi även en Slack-bot för att hjälpa teknikern. Tack vare ett brett utbud av funktioner (vi utökade ständigt funktionaliteten) gjorde boten deras arbete enklare och gjorde vårt liv mycket enklare. På så sätt optimerade vi det mesta av processen med att återanvända och underhålla servrar, vilket eliminerade oss själva från arbetsflödet.
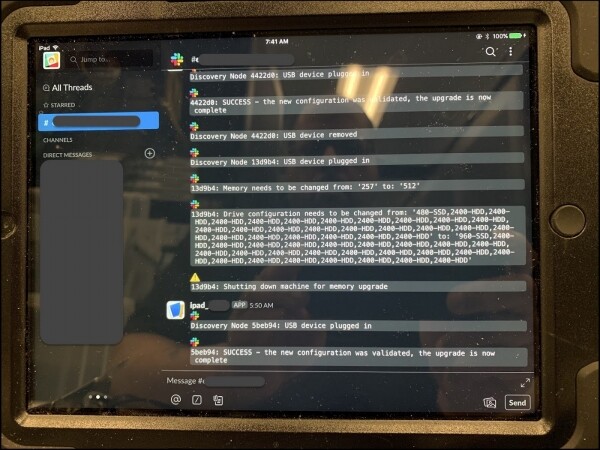
iPad i ett av våra datacenter
Hårdvarudomän
En tillförlitlig skalning av vår datacenterinfrastruktur kräver god insyn i varje komponent, till exempel:
- Detektering av hårdvarufel
- Serverstatus (aktiv, värd, zombie, etc.)
- Strömförbrukning
- Firmware version
- Analytics för hela den här verksamheten
Våra lösningar tillåter oss att fatta beslut om hur, var och när vi ska köpa utrustning, ibland till och med innan den faktiskt behövs. Genom att bestämma belastningsnivån på olika utrustningar kunde vi också uppnå en förbättrad resursallokering. I synnerhet energiförbrukning. Vi kan nu fatta välgrundade beslut om placeringen av en server innan den installeras i racket och ansluts till en strömkälla, under hela dess livscykel och fram till dess att den slutligen går i pension.
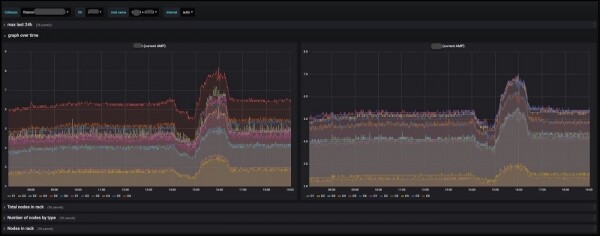
Energi Dashboard i Grafana
Och så dök COVID-19 upp...
Vårt team skapar teknologier som ger medieföretag och publicister online möjlighet att hjälpa besökare att hitta relevant innehåll, produkter och tjänster som kan vara av intresse för dem. Vår infrastruktur är utformad för att tjäna trafik som genereras när några spännande nyheter släpps.
Den intensiva mediebevakningen kring COVID-19, tillsammans med den ökade trafiken, innebar att vi brådskande behövde lära oss hur vi hanterar dessa påfrestningar. Dessutom måste allt detta göras under en global kris, när leveranskedjorna stördes och de flesta av personalen var hemma.
Men som vi sa, vår modell antar redan att:
- Utrustningen i våra datacenter är för det mesta fysiskt otillgänglig för oss;
- Vi utför nästan allt fysiskt arbete på distans;
- Arbetet utförs asynkront, autonomt och i stor skala;
- Vi möter efterfrågan på utrustning genom att använda metoden "bygga från delar" istället för att köpa ny utrustning;
- Vi har ett lager som gör att vi kan skapa något nytt, och inte bara utföra rutinmässiga reparationer.
De globala begränsningarna som hindrade många företag från att få fysisk tillgång till sina datacenter hade alltså liten inverkan på oss. Och när det gäller reservdelar och servrar, ja, vi försökte säkerställa en stabil drift av utrustningen. Men detta gjordes i syfte att förhindra eventuella incidenter när det plötsligt visar sig att någon hårdvara inte är tillgänglig. Vi såg till att våra reserver fylldes utan att sträva efter att möta nuvarande efterfrågan.
Sammanfattningsvis skulle jag vilja säga att vårt förhållningssätt till att arbeta i datacenterbranschen bevisar att det är möjligt att tillämpa principerna för god koddesign på den fysiska hanteringen av ett datacenter. Och kanske kommer du att tycka att det är intressant.
original:
Källa: will.com
