

När IPv4-adresser blir uttömda står många telekomoperatörer inför behovet av att ge sina kunder nätverksåtkomst med hjälp av adressöversättning. I den här artikeln kommer jag att berätta hur du kan få Carrier Grade NAT-prestanda på råvaruservrar.
Lite historia
Ämnet om utmattning av IPv4-adressutrymme är inte längre nytt. Vid något tillfälle dök väntelistor upp i RIPE, sedan uppstod börser där adressblock handlades och affärer slöts för att hyra dem. Så småningom började telekomoperatörer tillhandahålla Internetaccesstjänster med hjälp av adress- och portöversättning. Vissa lyckades inte få tillräckligt många adresser för att utfärda en "vit" adress till varje abonnent, medan andra började spara pengar genom att vägra köpa adresser på andrahandsmarknaden. Tillverkare av nätverksutrustning stödde denna idé, eftersom denna funktion kräver vanligtvis ytterligare tilläggsmoduler eller licenser. Till exempel, i Junipers linje av MX-routrar (förutom de senaste MX104 och MX204), kan du utföra NAPT på ett separat MS-MIC-servicekort, Cisco ASR1k kräver en CGN-licens, Cisco ASR9k kräver en separat A9K-ISM-100-modul och en A9K-CGN-licens -LIC till honom. Generellt sett kostar nöjet mycket pengar.
IPTables
NAT-implementering kräver inga specialiserade datorresurser; den kan hanteras av generella processorer, som de som finns i vilken hemmarouter som helst. På telekomoperatörsnivå kan denna uppgift utföras med hjälp av standardservrar som kör FreeBSD (ipfw/pf) eller GNU/Linux (iptables). Vi kommer inte att titta på FreeBSD, eftersom jag slutade använda det operativsystemet för ett tag sedan, så låt oss hålla oss till GNU/Linux.
Att aktivera adressöversättning är inte alls svårt. Först måste du registrera en regel i iptables i nat-tabellen:
iptables -t nat -A POSTROUTING -s 100.64.0.0/10 -j SNAT --to <pool_start_addr>-<pool_end_addr> --persistent
Operativsystemet kommer att ladda modulen nf_conntrack, som kommer att övervaka alla aktiva anslutningar och utföra nödvändiga omvandlingar. Det finns flera subtiliteter här. För det första, eftersom vi talar om NAT på skalan av en telekomoperatör, är det nödvändigt att justera timeouts, för med standardvärden kommer storleken på översättningstabellen snabbt att växa till katastrofala värden. Nedan är ett exempel på inställningarna jag använde på mina servrar:
net.ipv4.ip_forward = 1
net.ipv4.ip_local_port_range = 8192 65535
net.netfilter.nf_conntrack_generic_timeout = 300
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 600
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 45
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 60
net.netfilter.nf_conntrack_icmpv6_timeout = 30
net.netfilter.nf_conntrack_icmp_timeout = 30
net.netfilter.nf_conntrack_events_retry_timeout = 15
net.netfilter.nf_conntrack_checksum=0
Och för det andra, eftersom standardstorleken på översättningstabellen inte är utformad för att fungera under en teleoperatörs villkor, måste den ökas:
net.netfilter.nf_conntrack_max = 3145728
Det är också nödvändigt att öka antalet hinkar för hashtabellen som lagrar alla sändningar (detta är ett alternativ i modulen nf_conntrack):
options nf_conntrack hashsize=1572864
Efter dessa enkla manipulationer erhålls en fullt fungerande design som kan sända ett stort antal klientadresser till en pool av externa adresser. Prestandan för denna lösning lämnar dock mycket övrigt att önska. I mina första försök att använda GNU/Linux För NAT (cirka 2013) kunde jag få prestanda på runt 7 Gbit/s vid 0.8 Mpps på en enda server (Xeon E5-1650v2). Sedan dess har GNU-kärnans nätverksstack/Linux Många optimeringar gjordes, och prestandan för en enda server på samma hårdvara ökade till nästan 18–19 Gbit/s vid 1.8–1.9 Mpps (dessa var maxvärdena), men efterfrågan på trafik som hanterades av en enda server växte mycket snabbare. I slutändan utvecklades lastbalanseringsscheman för olika servrar, men allt detta ökade komplexiteten i installation, underhåll och upprätthållande av kvaliteten på de tillhandahållna tjänsterna.
NFT-tabeller
Nuförtiden är en fashionabel trend inom mjukvaruväskor att använda DPDK och XDP. Det har skrivits många artiklar om detta ämne, många olika tal har hållits och kommersiella produkter dyker upp (till exempel SKAT från VasExperts). Men med tanke på de begränsade programmeringsresurserna hos telekomoperatörer är det ganska problematiskt att skapa någon "produkt" baserad på dessa ramverk på egen hand. Det kommer att bli mycket svårare att använda en sådan lösning i framtiden, särskilt diagnostiska verktyg måste utvecklas. Till exempel kommer standard tcpdump med DPDK inte att fungera bara så, och det kommer inte att "se" paket som skickas tillbaka till ledningarna med XDP. Mitt i allt prat om ny teknik för att skicka paketvidarebefordran till användarutrymmet gick de obemärkt förbi и Pablo Neira Ayuso, underhållare av iptables, om utvecklingen av flödesavlastning i nftables. Låt oss ta en närmare titt på denna mekanism.
Huvudtanken är att om routern skickade paket från en session i båda riktningarna av flödet (TCP-sessionen gick in i ETABLISHED-tillståndet), så finns det inget behov av att skicka efterföljande paket av denna session genom alla brandväggsregler, eftersom alla dessa kontroller kommer fortfarande att sluta med att paketet överförs vidare till routing. Och vi behöver faktiskt inte välja en rutt - vi vet redan till vilket gränssnitt och till vilken värd vi behöver skicka paket inom denna session. Allt som återstår är att lagra denna information och använda den för routing i ett tidigt skede av paketbearbetningen. När du utför NAT är det nödvändigt att dessutom lagra information om ändringar i adresser och portar som översatts av modulen nf_conntrack. Ja, naturligtvis, i det här fallet slutar olika poliser och annan information och statistiska regler i iptables att fungera, men inom ramen för uppgiften med en separat stående NAT eller till exempel en gräns är detta inte så viktigt, eftersom tjänsterna är fördelade över enheter.
konfiguration
För att använda denna funktion behöver vi:
- Använd en färsk kärna. Trots att själva funktionaliteten dök upp i kärnan 4.16, var den under ganska lång tid väldigt "rå" och orsakade regelbundet kärnpanik. Allt stabiliserades runt december 2019, när LTS-kärnorna 4.19.90 och 5.4.5 släpptes.
- Skriv om iptables-regler i nftables-format med en ganska ny version av nftables. Fungerar exakt i version 0.9.0
Om allt i princip är klart med den första punkten, är det viktigaste att inte glömma att inkludera modulen i konfigurationen under monteringen (CONFIG_NFT_FLOW_OFFLOAD=m), då kräver den andra punkten förklaring. nftables regler beskrivs helt annorlunda än i iptables. avslöjar nästan alla punkter, det finns också speciella regler från iptables till nftables. Därför kommer jag bara att ge ett exempel på hur man ställer in NAT och flow offload. En liten legend till exempel: , - Det här är nätverksgränssnitten genom vilka trafik passerar; i verkligheten kan det finnas fler än två av dem. , — start- och slutadressen för intervallet av "vita" adresser.
NAT-konfigurationen är mycket enkel:
#! /usr/sbin/nft -f
table nat {
chain postrouting {
type nat hook postrouting priority 100;
oif <o_if> snat to <pool_addr_start>-<pool_addr_end> persistent
}
}
Med flödesavlastning är det lite mer komplicerat, men ganska förståeligt:
#! /usr/sbin/nft -f
table inet filter {
flowtable fastnat {
hook ingress priority 0
devices = { <i_if>, <o_if> }
}
chain forward {
type filter hook forward priority 0; policy accept;
ip protocol { tcp , udp } flow offload @fastnat;
}
}
Det är faktiskt hela upplägget. Nu kommer all TCP/UDP-trafik att falla in i fastnat-tabellen och bearbetas mycket snabbare.
Resultat
För att tydliggöra hur mycket snabbare detta är, bifogar jag en skärmdump av belastningen på två riktiga servrar, med samma hårdvara (Xeon E5-1650v2), konfigurerade identiskt, med samma kärna. Linux, men utför NAT i iptables (NAT4) och i nftables (NAT5).
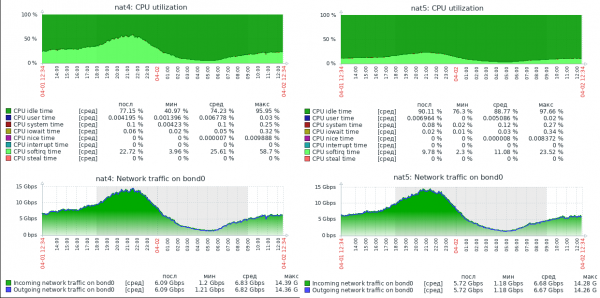
Det finns ingen graf över paket per sekund i skärmdumpen, men i laddningsprofilen för dessa servrar är den genomsnittliga paketstorleken runt 800 byte, så värdena når upp till 1.5Mpps. Som du kan se har servern med nftables en enorm prestandareserv. För närvarande bearbetar den här servern upp till 30Gbit/s vid 3Mpps och klarar tydligt den fysiska nätverksbegränsningen på 40Gbps, samtidigt som den har lediga CPU-resurser.
Jag hoppas att detta material kommer att vara användbart för nätverksingenjörer som försöker förbättra prestanda på sina servrar.
Källa: will.com
