


På vilka principer byggs ett idealiskt Data Warehouse?
Fokusera på affärsnytta och analys i avsaknad av standardkod. Hantera DWH som en kodbas: versionshantering, granskning, automatiserad testning och CI. Modulär, utbyggbar, öppen källkod och community. Användarvänlig dokumentation och beroendevisualisering (Data Lineage).
Mer om allt detta och om DBT:s roll i Big Data & Analytics-ekosystemet - välkommen till kat.
Hej alla
Artemy Kozyr är i kontakt. I mer än 5 år har jag arbetat med datalager, byggande av ETL/ELT, samt dataanalys och visualisering. Jag jobbar just nu i , jag undervisar på OTUS på en kurs , och idag vill jag dela med mig av en artikel som jag skrev i väntan på starten ny anmälan till kursen.
Kort recension
DBT-ramverket handlar om T i förkortningen ELT (Extract - Transform - Load).
Med tillkomsten av så produktiva och skalbara analytiska databaser som BigQuery, Redshift, Snowflake var det ingen idé att göra transformationer utanför Data Warehouse.
DBT laddar inte ner data från källor, men ger stora möjligheter att arbeta med data som redan har laddats in i Storaget (i Intern eller Extern Storage).
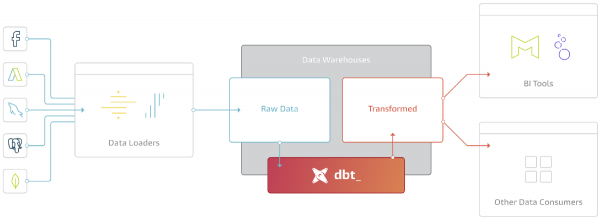
Huvudsyftet med DBT är att ta koden, kompilera den till SQL, köra kommandona i rätt sekvens i Repository.
DBT projektstruktur
Projektet består av kataloger och filer av endast 2 typer:
- Model (.sql) - en transformationsenhet uttryckt av en SELECT-fråga
- Konfigurationsfil (.yml) - parametrar, inställningar, tester, dokumentation
På grundnivå är arbetet uppbyggt enligt följande:
- Användaren förbereder modellkod i vilken bekväm IDE som helst
- Med hjälp av CLI lanseras modeller, DBT kompilerar modellkoden till SQL
- Den kompilerade SQL-koden exekveras i lagringen i en given sekvens (graf)
Så här kan körning från CLI se ut:
Allt är SELECT
Detta är en mördande funktion i ramverket för Data Build Tool. Med andra ord abstraherar DBT all kod som är associerad med att materialisera dina frågor i butiken (variationer från kommandona CREATE, INSERT, UPDATE, DELETE ALTER, GRANT, ...).
Vilken modell som helst innebär att man skriver en SELECT-fråga som definierar den resulterande datamängden.
I det här fallet kan transformationslogiken vara på flera nivåer och konsolidera data från flera andra modeller. Ett exempel på en modell som kommer att bygga en orderpresentation (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Vilka intressanta saker kan vi se här?
Först: Använde CTE (Common Table Expressions) - för att organisera och förstå kod som innehåller många transformationer och affärslogik
För det andra: Modellkod är en blandning av SQL och språk (mallspråk).
Exemplet använder en loop för för att generera beloppet för varje betalningsmetod som anges i uttrycket in. Funktionen används också ref — Möjligheten att referera till andra modeller inom koden:
- Under sammanställningen ref kommer att konverteras till en målpekare till en tabell eller vy i Storage
- ref låter dig bygga en modellberoendegraf
Exakt ger nästan obegränsade möjligheter till DBT. De mest använda är:
- If / else uttalanden - filial uttalanden
- För slingor
- Variabler
- Makro - skapa makron
Materialisering: Tabell, Vy, Inkrementell
Materialiseringsstrategi är ett tillvägagångssätt enligt vilket den resulterande uppsättningen av modelldata kommer att lagras i lagringen.
I grundläggande termer är det:
- Bord - fysiskt bord i Lagret
- Visa - visa, virtuell tabell i Storage
Det finns också mer komplexa materialiseringsstrategier:
- Inkrementell - inkrementell laddning (av stora faktatabeller); nya rader läggs till, ändrade rader uppdateras, raderade rader raderas
- Efemeral - modellen materialiseras inte direkt, utan deltar som CTE i andra modeller
- Alla andra strategier kan du lägga till själv
Förutom materialiseringsstrategier finns det möjligheter till optimering för specifika lagringar, till exempel:
- Snöflinga: Övergående tabeller, Sammanfogningsbeteende, Tabellklustring, Kopieringsbidrag, Säkra vyer
- rödförskjutning: Distkey, Sortkey (interfolierad, sammansatt), Sen bindande vyer
- BigQuery: Tabellpartitionering och klustring, sammanfogningsbeteende, KMS-kryptering, etiketter och taggar
- Gnista: Filformat (parkett, csv, json, orc, delta), partition_by, clustered_by, buckets, incremental_strategy
Följande lagringar stöds för närvarande:
- postgres
- rödförskjutning
- BigQuery
- Snöflinga
- Presto (delvis)
- Gnista (delvis)
- Microsoft SQL Server (gemenskapsadapter)
Låt oss förbättra vår modell:
- Låt oss göra fyllningen inkrementell (inkrementell)
- Låt oss lägga till segmenterings- och sorteringsnycklar för Redshift
-- Конфигурация модели:
-- Инкрементальное наполнение, уникальный ключ для обновления записей (unique_key)
-- Ключ сегментации (dist), ключ сортировки (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Этот фильтр будет применен только для инкрементального запуска
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Modellberoendegraf
Det är också ett beroendeträd. Det är också känt som DAG (Directed Acyclic Graph).
DBT bygger en graf baserad på konfigurationen av alla projektmodeller, eller snarare ref() länkar inom modeller till andra modeller. Med en graf kan du göra följande saker:
- Kör modeller i rätt ordning
- Parallellisering av skyltfönsterbildning
- Köra en godtycklig subgraf
Exempel på grafvisualisering:
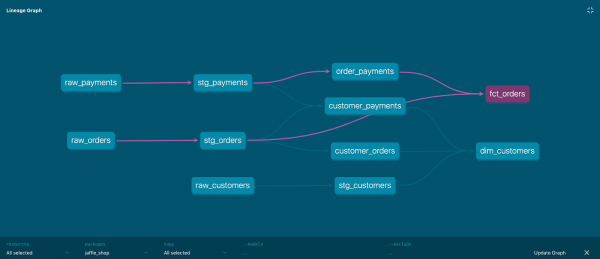
Varje nod i grafen är en modell, kanterna på grafen anges av uttrycket ref.
Datakvalitet och dokumentation
Förutom att generera själva modellerna låter DBT dig testa ett antal antaganden om den resulterande datamängden, till exempel:
- Inte Null
- Unik
- Referensintegritet - referensintegritet (exempelvis motsvarar kund_id i ordertabellen id i kundtabellen)
- Matchar listan över acceptabla värden
Det är möjligt att lägga till egna tester (anpassade datatester), som till exempel % avvikelse av intäkter med indikatorer från en dag, en vecka, en månad sedan. Alla antaganden formulerade som en SQL-fråga kan bli ett test.
På så sätt kan du fånga upp oönskade avvikelser och fel i data i Lagerfönstren.
När det gäller dokumentation tillhandahåller DBT mekanismer för att lägga till, versionsstyra och distribuera metadata och kommentarer på modell- och även attributnivåer.
Så här ser det ut att lägga till tester och dokumentation på konfigurationsfilnivå:
- name: fct_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique # проверка на уникальность значений
- not_null # проверка на наличие null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships: # проверка ссылочной целостности
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # проверка на допустимые значения
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
Och så här ser den här dokumentationen ut på den genererade webbplatsen:
Makron och moduler
Syftet med DBT är inte så mycket att bli en uppsättning SQL-skript, utan att ge användare ett kraftfullt och funktionsrikt sätt att bygga sina egna transformationer och distribuera dessa moduler.
Makron är uppsättningar av konstruktioner och uttryck som kan kallas som funktioner inom modeller. Makron låter dig återanvända SQL mellan modeller och projekt i enlighet med DRY (Don't Repeat Yourself) principen.
Makro exempel:
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
Och dess användning:
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- вызов макроса
from my_table
DBT kommer med en pakethanterare som tillåter användare att publicera och återanvända enskilda moduler och makron.
Detta innebär att kunna ladda och använda bibliotek som:
- : arbeta med datum/tid, surrogatnycklar, schematester, Pivot/Unpivot och andra
- Färdiga skyltfönstermallar för tjänster som t.ex и
- Bibliotek för specifika datalager, t.ex.
- — Modul för loggning av DBT-drift
En komplett lista över paket finns på .
Ännu fler funktioner
Här kommer jag att beskriva några andra intressanta funktioner och implementeringar som teamet och jag använder för att bygga ett Data Warehouse i .
Separation av runtime-miljöer DEV - TEST - PROD
Även inom samma DWH-kluster (inom olika system). Använd till exempel följande uttryck:
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
Denna kod säger bokstavligen: för miljöer dev, test, ci ta data endast för de senaste 3 dagarna och inte mer. Det vill säga att körning i dessa miljöer kommer att gå mycket snabbare och kräva mindre resurser. När du kör på miljö prod filtervillkoret kommer att ignoreras.
Materialisering med alternativ kolumnkodning
Redshift är en kolumnär DBMS som låter dig ställa in datakomprimeringsalgoritmer för varje enskild kolumn. Att välja optimala algoritmer kan minska diskutrymmet med 20-50 %.
Makro kommer att utföra kommandot ANALYSE COMPRESSION, skapa en ny tabell med de rekommenderade kolumnkodningsalgoritmerna, specificerade segmenteringsnycklar (dist_key) och sorteringsnycklar (sort_key), överföra data till den och, om nödvändigt, radera den gamla kopian.
Makrosignatur:
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List<String>,
dist_style=none|all|even,
dist_key=none|String) }}
Loggningsmodell körs
Du kan fästa krokar på varje exekvering av modellen, som kommer att exekveras före lansering eller omedelbart efter att skapandet av modellen är klar:
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
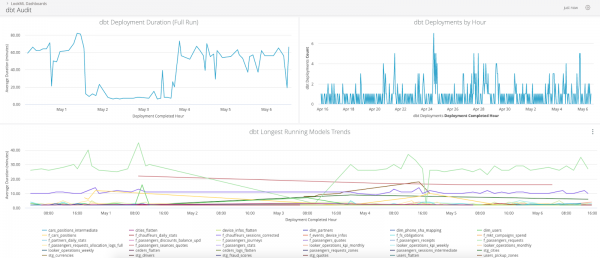
Loggningsmodulen låter dig registrera all nödvändig metadata i en separat tabell, som sedan kan användas för att granska och analysera flaskhalsar.
Så här ser instrumentpanelen ut baserat på loggdata i Looker:
Automatisering av lagringsunderhåll
Om du använder några tillägg av funktionaliteten för det använda förrådet, såsom UDF (User Defined Functions), är versionshantering av dessa funktioner, åtkomstkontroll och automatisk utrullning av nya utgåvor mycket bekvämt att göra i DBT.
Vi använder UDF i Python för att beräkna hash, e-postdomäner och bitmaskavkodning.
Ett exempel på ett makro som skapar en UDF i valfri exekveringsmiljö (dev, test, prod):
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
På Wheely använder vi Amazon Redshift, som är baserat på PostgreSQL. För Redshift är det viktigt att regelbundet samla in statistik på tabeller och frigöra diskutrymme - kommandona ANALYSE respektive VACUUM.
För att göra detta exekveras kommandon från makrot redshift_maintenance varje natt:
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
DBT moln
Det är möjligt att använda DBT som en tjänst (Managed Service). Ingår:
- Webb-IDE för utveckling av projekt och modeller
- Jobbkonfiguration och schemaläggning
- Enkel och bekväm åtkomst till loggar
- Webbplats med dokumentation av ditt projekt
- Ansluter CI (kontinuerlig integration)
Slutsats
Att förbereda och konsumera DWH blir lika trevligt och nyttigt som att dricka en smoothie. DBT består av Jinja, användartillägg (moduler), en kompilator, en executor och en pakethanterare. Genom att sätta ihop dessa element får du en komplett arbetsmiljö för ditt Data Warehouse. Det finns knappast ett bättre sätt att hantera transformation inom DWH idag.

De övertygelser som följs av utvecklarna av DBT är formulerade enligt följande:
- Kod, inte GUI, är den bästa abstraktionen för att uttrycka komplex analytisk logik
- Att arbeta med data bör anpassa bästa praxis inom mjukvaruteknik (Software Engineering)
- Kritisk datainfrastruktur bör kontrolleras av användargemenskapen som programvara med öppen källkod
- Inte bara analysverktyg utan även kod kommer i allt högre grad att bli Open Source-gemenskapens egendom
Dessa grundläggande övertygelser har skapat en produkt som används av över 850 företag idag, och de utgör grunden för många spännande tillägg som kommer att skapas i framtiden.
För den intresserade finns en video på en öppen lektion jag gav för några månader sedan som en del av en öppen lektion på OTUS - .
Förutom DBT och Data Warehousing, som en del av Data Engineer-kursen på OTUS-plattformen, undervisar mina kollegor och jag klasser i ett antal andra relevanta och moderna ämnen:
- Arkitektoniska koncept för Big Data-applikationer
- Öva med Spark and Spark Streaming
- Utforska metoder och verktyg för att ladda datakällor
- Bygga analytiska skyltfönster i DWH
- NoSQL-koncept: HBase, Cassandra, ElasticSearch
- Principer för övervakning och orkestrering
- Slutprojekt: sätta ihop alla färdigheter under mentorstöd
Länkar:
- — Officiell dokumentation
- — Recensionsartikel av en av författarna till DBT
- — YouTube, Inspelning av en öppen lektion i OTUS
- — Nästa öppna lektion är den 15 maj 2020
- —OTUS
- — En titt på framtiden för data och analys
- — Utvecklingen av analys och påverkan av öppen källkod
- — Principer för att bygga CI med hjälp av DBT
- — Övning, steg-för-steg-instruktioner för självständigt arbete
- — Github, utbildningsprojektkod
Källa: will.com
