

Vi kommer att titta på hur Zabbix fungerar med TimescaleDB-databasen som backend. Vi visar dig hur du börjar från början och hur du migrerar från PostgreSQL. Vi kommer också att tillhandahålla jämförande prestandatester av de två konfigurationerna.

HighLoad++ Sibirien 2019. Tomsk Hall. 24 juni, 16:00. Avhandlingar och . Nästa HighLoad++-konferens kommer att hållas den 6 och 7 april 2020 i St. Petersburg. Detaljer och biljetter .
Andrey Gushchin (nedan – AG): – Jag är en ZABBIX teknisk supportingenjör (nedan kallad "Zabbix"), en utbildare. Jag har arbetat med teknisk support i mer än 6 år och har haft direkt erfarenhet av prestanda. Idag ska jag prata om prestandan som TimescaleDB kan ge jämfört med vanlig PostgreSQL 10. Dessutom en introduktionsdel om hur det fungerar i allmänhet.
De främsta produktivitetsutmaningarna: från datainsamling till datarensning
Till att börja med finns det vissa prestandautmaningar som varje övervakningssystem står inför. Den första produktivitetsutmaningen är att snabbt samla in och bearbeta data.

Ett bra övervakningssystem bör snabbt, i tid ta emot all data, bearbeta den enligt triggeruttryck, det vill säga bearbeta den enligt vissa kriterier (detta är olika i olika system) och spara den i en databas för att kunna använda dessa data i framtida.

Den andra prestandautmaningen är historiklagring. Lagra i en databas ofta och ha snabb och bekväm tillgång till dessa mätvärden som samlades in under en tidsperiod. Det viktigaste är att denna data är bekväm att få, använda den i rapporter, grafer, triggers, i vissa tröskelvärden, för varningar, etc.

Den tredje prestandautmaningen är historikrensning, det vill säga när du kommer till den punkt där du inte behöver lagra några detaljerade mätvärden som har samlats in under 5 år (även månader eller två månader). Vissa nätverksnoder togs bort, eller vissa värdar, mätvärdena behövs inte längre eftersom de redan är föråldrade och inte längre samlade in. Allt detta måste rengöras så att din databas inte blir för stor. Generellt sett är rensningshistoriken oftast ett allvarligt test för lagringen - det har ofta en mycket stark inverkan på prestandan.
Hur löser man cachningsproblem?
Jag kommer nu att prata specifikt om Zabbix. I Zabbix löses det första och andra anropet med hjälp av caching.

Datainsamling och bearbetning – Vi använder RAM för att lagra all denna data. Dessa data kommer nu att diskuteras mer i detalj.
Även på databassidan finns en del cachning för huvudval - för grafer och annat.
Cachning på sidan av själva Zabbix-servern: vi har ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Vad det är?

ConfigurationCache är huvudcachen där vi lagrar mätvärden, värdar, dataobjekt, triggers; allt du behöver för att bearbeta förbearbetning, samla in data, från vilka värdar du ska samla in, med vilken frekvens. Allt detta lagras i ConfigurationCache för att inte gå till databasen och skapa onödiga frågor. Efter att servern startar uppdaterar vi denna cache (skapar den) och uppdaterar den regelbundet (beroende på konfigurationsinställningarna).
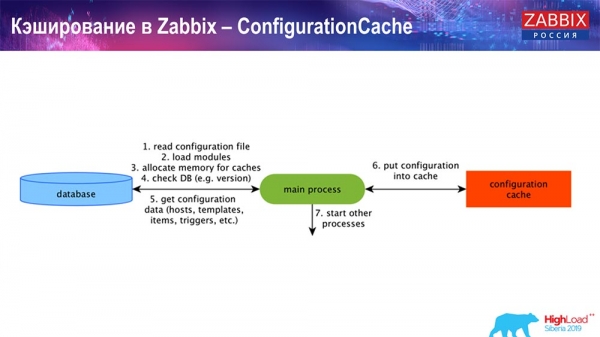
Cachar i Zabbix. Datainsamling
Här är diagrammet ganska stort:
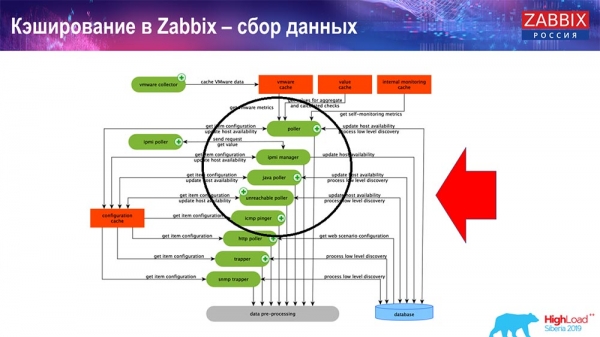
De viktigaste i schemat är dessa samlare:
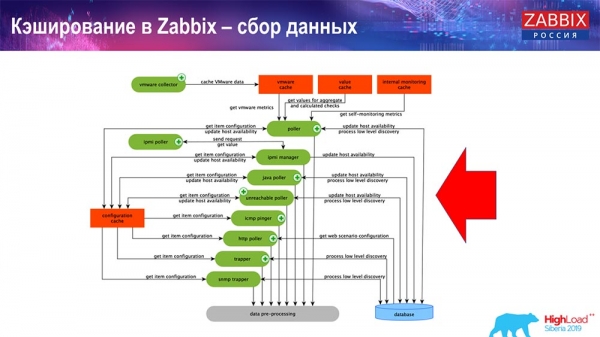
Det är själva monteringsprocesserna, olika ”pollare” som ansvarar för olika typer av sammanställningar. De samlar in data via icmp, ipmi och olika protokoll och överför allt till förbearbetning.
PreProcessing HistoryCache
Dessutom, om vi har beräknade dataelement (de som är bekanta med Zabbix vet), det vill säga beräknade, aggregerade dataelement, tar vi dem direkt från ValueCache. Jag ska berätta hur den fylls på senare. Alla dessa samlare använder ConfigurationCache för att ta emot sina jobb och skickar dem sedan vidare till förbearbetning.
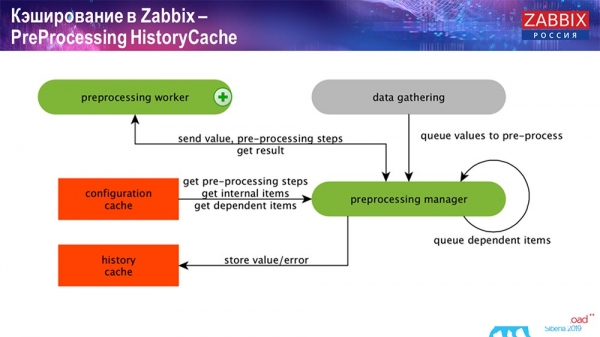
Förbearbetning använder också ConfigurationCache för att hämta förbearbetningssteg och bearbetar dessa data på olika sätt. Från och med version 4.2 har vi flyttat den till en proxy. Detta är mycket bekvämt, eftersom förbearbetningen i sig är en ganska svår operation. Och om du har en mycket stor Zabbix, med ett stort antal dataelement och en hög insamlingsfrekvens, så förenklar detta arbetet avsevärt.
Följaktligen, efter att vi har bearbetat denna data på något sätt med förbearbetning, sparar vi den i HistoryCache för att kunna bearbeta den vidare. Detta avslutar datainsamlingen. Vi går vidare till huvudprocessen.
History syncers arbete
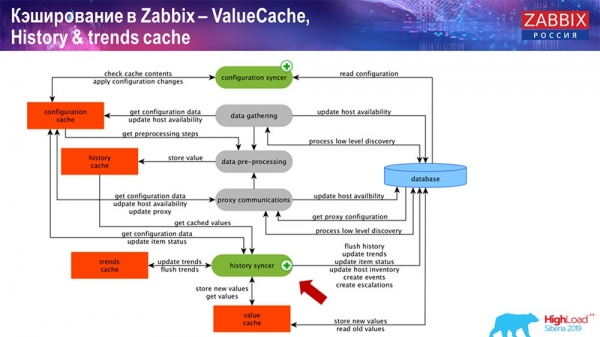
Huvudprocessen i Zabbix (eftersom det är en monolitisk arkitektur) är History syncer. Detta är huvudprocessen som specifikt handlar om atombehandlingen av varje dataelement, det vill säga varje värde:
- värdet kommer (det tar det från HistoryCache);
- kontrollerar i Configuration syncer: om det finns några triggers för beräkning - beräknar dem;
om det finns - skapar händelser, skapar eskalering för att skapa en varning, om nödvändigt enligt konfigurationen; - registrerar triggers för efterföljande bearbetning, aggregering; om du aggregerar under den senaste timmen och så vidare, kommer detta värde att komma ihåg av ValueCache för att inte gå till historiktabellen; Således fylls ValueCache med nödvändig data som är nödvändig för att beräkna triggers, beräknade element, etc.;
- sedan skriver History syncer all data till databasen;
- databasen skriver dem till disken - det är här bearbetningsprocessen slutar.
Databas. Cachning
På databassidan, när du vill se grafer eller några rapporter om händelser, finns det olika cacher. Men i denna rapport kommer jag inte att prata om dem.
För MySQL finns Innodb_buffer_pool, och ett gäng olika cacher som också kan konfigureras.
Men dessa är de viktigaste:
- shared_buffers;
- effektiv_cache_storlek;
- shared_pool.

För alla databaser sa jag att det finns vissa cacher som gör att du kan lagra i RAM den data som ofta behövs för frågor. De har sin egen teknik för detta.
Om databasprestanda
Följaktligen finns det en konkurrensutsatt miljö, det vill säga Zabbix-servern samlar in data och registrerar den. När den startas om läser den också från historiken för att fylla ValueCache och så vidare. Här kan du ha skript och rapporter som använder Zabbix API, som är byggt på ett webbgränssnitt. Zabbix API går in i databasen och tar emot nödvändig data för att få grafer, rapporter eller någon slags lista över händelser, senaste problem.
En mycket populär visualiseringslösning är också Grafana, som våra användare använder. Kan logga in direkt både via Zabbix API och via databasen. Det skapar också en viss konkurrens för att få fram data: en finare, bättre justering av databasen krävs för att följa den snabba leveransen av resultat och tester.

Rensa historik. Zabbix har hushållerska
Det tredje samtalet som används i Zabbix är att rensa historik med hjälp av Housekeeper. Housekeeper följer alla inställningar, det vill säga våra dataelement indikerar hur länge som ska lagras (i dagar), hur länge trender ska lagras och dynamiken i förändringar.
Jag pratade inte om TrendCache, som vi beräknar i farten: data kommer, vi aggregerar det under en timme (detta är oftast siffror för den senaste timmen), mängden är genomsnittlig/minimum och vi registrerar den en gång i timmen i tabell över förändringarnas dynamik ("Trender") . "Hushållerska" startar och raderar data från databasen med vanliga val, vilket inte alltid är effektivt.
Hur förstår man att det är ineffektivt? Du kan se följande bild på prestandagraferna för interna processer:
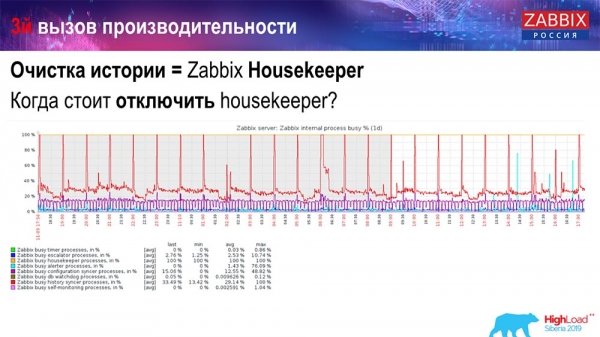
Din historiksynkronisering är ständigt upptagen (röd graf). Och den "röda" grafen som går överst. Detta är en "hushållerska" som startar och väntar på att databasen tar bort alla rader som den har angett.
Låt oss ta lite artikel-ID: du måste ta bort de senaste 5 tusen; givetvis genom index. Men vanligtvis är datasetet ganska stort - databasen läser fortfarande det från disken och lägger in det i cachen, och detta är en mycket dyr operation för databasen. Beroende på dess storlek kan detta leda till vissa prestandaproblem.
Du kan inaktivera Housekeeper på ett enkelt sätt - vi har ett bekant webbgränssnitt. Inställningar i Administration generellt (inställningar för "Hushållerska") vi inaktiverar intern hushållning för intern historik och trender. Följaktligen kontrollerar Housekeeper inte längre detta:

Vad kan du göra härnäst? Du stängde av den, dina grafer har planat ut... Vilka ytterligare problem kan uppstå i det här fallet? Vad kan hjälpa?
Partitionering (sektionering)
Vanligtvis konfigureras detta på olika sätt på varje relationsdatabas jag har listat. MySQL har sin egen teknologi. Men överlag är de väldigt lika när det kommer till PostgreSQL 10 och MySQL. Naturligtvis finns det många interna skillnader i hur det hela implementeras och hur det påverkar prestanda. Men i allmänhet leder skapandet av en ny partition ofta också till vissa problem.

Beroende på din inställning (hur mycket data du skapar på en dag) sätter de vanligtvis minimum - det här är 1 dag / batch och för "trender", förändringsdynamik - 1 månad / ny batch. Detta kan ändras om du har en mycket stor inställning.
Låt oss säga direkt om storleken på installationen: upp till 5 tusen nya värden per sekund (så kallade nvps) - detta kommer att betraktas som en liten "inställning". Genomsnitt - från 5 till 25 tusen värden per sekund. Allt som står ovan är redan stora och mycket stora installationer som kräver mycket noggrann konfiguration av databasen.
På mycket stora installationer kanske 1 dag inte är optimalt. Jag har personligen sett partitioner på MySQL på 40 gigabyte per dag (och det kan finnas fler). Detta är en mycket stor mängd data, vilket kan leda till vissa problem. Det måste minskas.
Varför behöver du partitionering?
Det som partitionering ger, tror jag att alla vet, är tabellpartitionering. Ofta är dessa separata filer på disk och span-förfrågningar. Den väljer en partition mer optimalt om den är en del av normal partitionering.
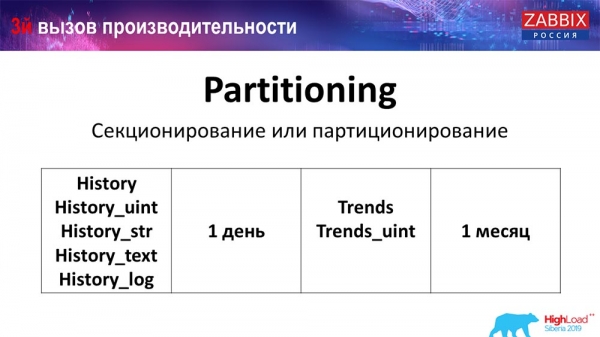
För Zabbix, i synnerhet, används det av intervall, efter intervall, det vill säga vi använder en tidsstämpel (ett vanligt tal, tid sedan epokens början). Du anger början på dagen/slutet på dagen, och detta är partitionen. Följaktligen, om du frågar efter data som är två dagar gammal, hämtas allt från databasen snabbare, eftersom du bara behöver ladda en fil i cachen och returnera den (istället för en stor tabell).

Många databaser gör också snabbare infogning (infogning i en underordnad tabell). Jag talar abstrakt för nu, men detta är också möjligt. Partitonering hjälper ofta.
Elasticsearch för NoSQL
Nyligen, i 3.4, implementerade vi en NoSQL-lösning. Lade till möjligheten att skriva i Elasticsearch. Du kan skriva vissa typer: du väljer - antingen skriv siffror eller några tecken; vi har strängtext, du kan skriva loggar till Elasticsearch... Följaktligen kommer webbgränssnittet också att komma åt Elasticsearch. Detta fungerar utmärkt i vissa fall, men för tillfället kan det användas.

TidsskalaDB. Hypertabeller
För 4.4.2 uppmärksammade vi en sak som TimescaleDB. Vad det är? Detta är en tillägg för PostgreSQL, det vill säga den har ett inbyggt PostgreSQL-gränssnitt. Dessutom låter detta tillägg dig arbeta mycket mer effektivt med tidsseriedata och ha automatisk partitionering. Vad det liknar:

Det här är hypertabell - det finns ett sådant koncept i Timescale. Det här är en hypertabell som du skapar, och den innehåller bitar. Chunks är partitioner, det här är underordnade tabeller, om jag inte har fel. Det är riktigt effektivt.
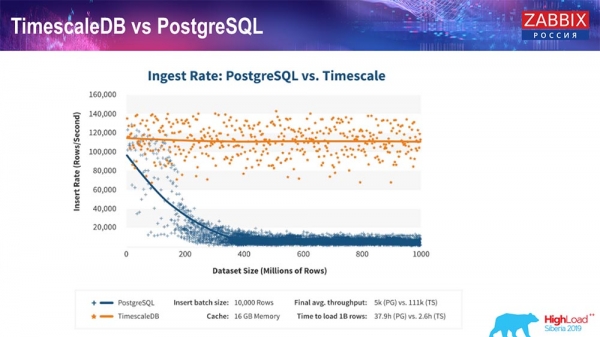
TimescaleDB och PostgreSQL
Som TimescaleDB-tillverkarna försäkrar använder de en mer korrekt algoritm för att bearbeta frågor, särskilt inlägg, vilket gör att de kan ha ungefär konstant prestanda med en ökande storlek på datasetinlägget. Det vill säga, efter 200 miljoner rader med Postgres börjar den vanliga sjunka väldigt mycket och tappar prestanda bokstavligen till noll, medan Timescale låter dig infoga inlägg så effektivt som möjligt med vilken mängd data som helst.
Hur installerar man TimescaleDB? Det är enkelt!
Det finns i dokumentationen, det beskrivs - du kan installera det från paket för alla... Det beror på de officiella Postgres-paketen. Kan kompileras manuellt. Det blev så att jag var tvungen att kompilera för databasen.
På Zabbix aktiverar vi helt enkelt Extention. Jag tror att de som använde Extention i Postgres... Du aktiverar helt enkelt Extention, skapar den för Zabbix-databasen som du använder.
Och det sista steget...
TidsskalaDB. Migrering av historiktabeller
Du måste skapa en hypertabell. Det finns en speciell funktion för detta – Skapa hypertabell. I den är den första parametern tabellen som behövs i den här databasen (för vilken du måste skapa en hypertabell).

Fältet för att skapa, och chunk_time_interval (detta är intervallet för chunks (partitioner som måste användas). 86 400 är en dag.
Migrate_data-parameter: Om du infogar till true kommer detta att migrera all aktuell data till förskapade bitar.
Jag har själv använt migrate_data - det tar ganska lång tid, beroende på hur stor din databas är. Jag hade över en terabyte - det tog över en timme att skapa. I vissa fall, under testningen, tog jag bort historiska data för text (history_text) och string (history_str) för att inte överföra dem - de var inte riktigt intressanta för mig.
Och vi gör den sista uppdateringen i vår db_extention: vi installerar timescaledb så att databasen och i synnerhet vår Zabbix förstår att det finns db_extention. Han aktiverar den och använder rätt syntax och frågor till databasen, med hjälp av de "funktioner" som är nödvändiga för TimescaleDB.
Serverkonfiguration
Jag använde två servrar. Den första servern är en ganska liten virtuell maskin, 20 processorer, 16 gigabyte RAM. Jag konfigurerade Postgres 10.8 på den:

Operativsystemet var Debian, filsystem – xfs. Jag gjorde minimala inställningar för att använda just den här databasen, förutom vad Zabbix själv kommer att använda. Zabbix-servern, PostgreSQL och load agents installerades också på den här maskinen.

Jag har använt 50 aktiva agenter som använder LoadableModule för att snabbt generera olika resultat. Det är de som genererade strängarna, siffrorna och så vidare. Jag fyllde databasen med mycket data. Inledningsvis innehöll konfigurationen 5 tusen dataelement per värd, och ungefär varje dataelement innehöll en trigger - för att detta skulle vara en riktig inställning. Ibland behöver du till och med mer än en trigger för att använda.

Jag reglerade uppdateringsintervallet och själva belastningen genom att inte bara använda 50 agenter (lägga till fler), utan även använda dynamiska dataelement och minska uppdateringsintervallet till 4 sekunder.
Utvärderingsprov. PostgreSQL: 36 tusen NVP
Den första lanseringen, den första installationen jag hade var på ren PostreSQL 10 på denna hårdvara (35 tusen värden per sekund). I allmänhet, som du kan se på skärmen, tar det bråkdelar av en sekund att infoga data - allt är bra och snabbt, SSD-enheter (200 gigabyte). Det enda är att 20 GB fylls upp ganska snabbt.
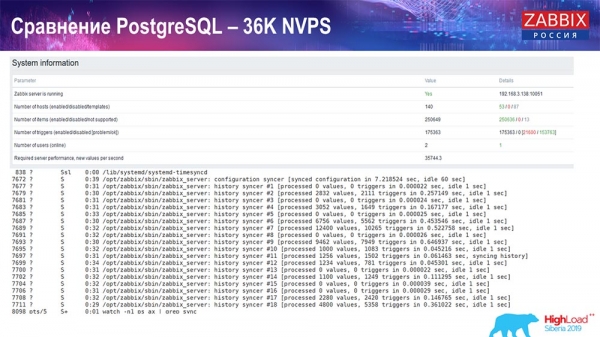
Det kommer att bli ganska många sådana grafer i framtiden. Detta är en standardinstrumentpanel för Zabbix-serverprestanda.
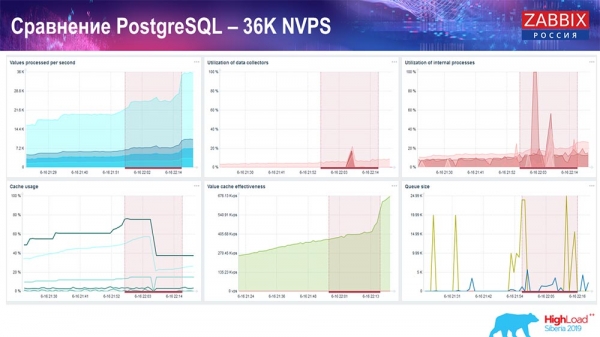
Den första grafen är antalet värden per sekund (blå, överst till vänster), 35 tusen värden i det här fallet. Detta (överst i mitten) är laddningen av byggprocesser, och detta (överst till höger) är laddningen av interna processer: historiksyncer och hushållerska, som här (längst ner i mitten) har varit igång ganska länge.
Den här grafen (längst ner i mitten) visar ValueCache-användning - hur många ValueCache-träffar för utlösare (flera tusen värden per sekund). En annan viktig graf är den fjärde (nederst till vänster), som visar användningen av HistoryCache, som jag pratade om, som är en buffert innan den infogas i databasen.
Utvärderingsprov. PostgreSQL: 50 tusen NVP
Därefter ökade jag belastningen till 50 tusen värden per sekund på samma hårdvara. När den laddades av hushållerskan, registrerades 10 tusen värden på 2-3 sekunder med beräkning. Vad som faktiskt visas i följande skärmdump:
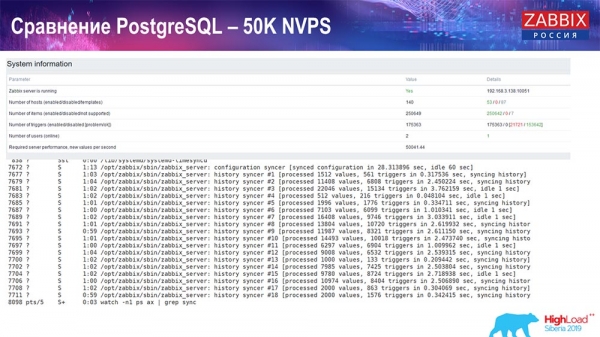
"Hushållerska" börjar redan störa arbetet, men generellt sett är belastningen på historiesänkare fortfarande på nivån 60% (tredje grafen, uppe till höger). HistoryCache börjar redan fyllas aktivt medan Housekeeper körs (nedre till vänster). Den var ungefär en halv gigabyte, 20 % full.
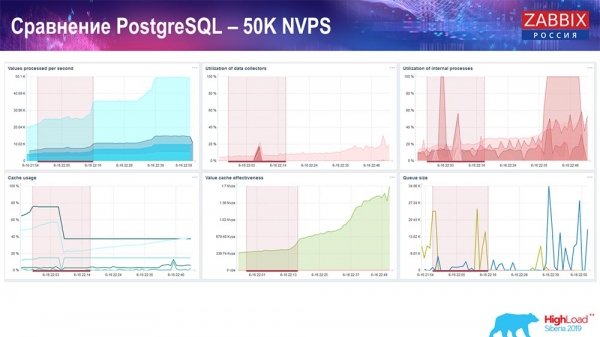
Utvärderingsprov. PostgreSQL: 80 tusen NVP
Sedan ökade jag det till 80 tusen värden per sekund:
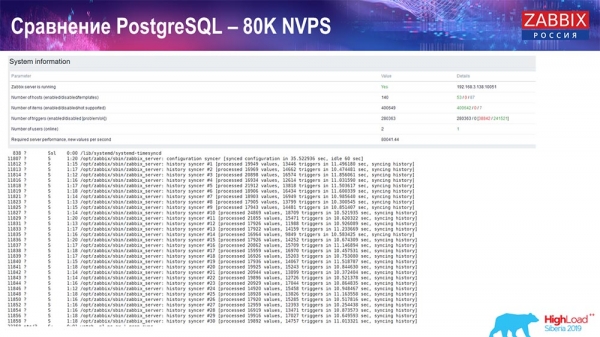
Det var ungefär 400 tusen dataelement, 280 tusen triggers. Insatsen, som du kan se, när det gäller belastningen av historiesänkor (det fanns 30 stycken) var redan ganska hög. Sedan ökade jag olika parametrar: historiksänkor, cache ... På den här hårdvaran började belastningen på historiksänkor att öka till det maximala, nästan "på hyllan" - följaktligen gick HistoryCache i en mycket hög belastning:
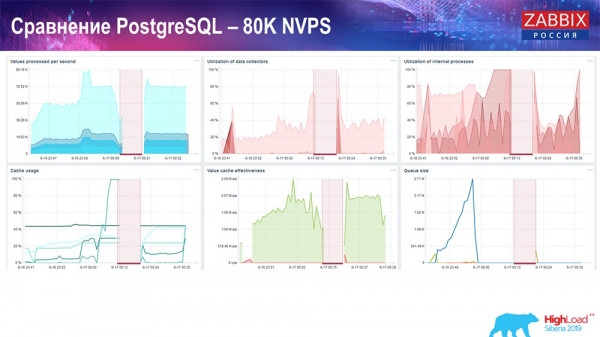
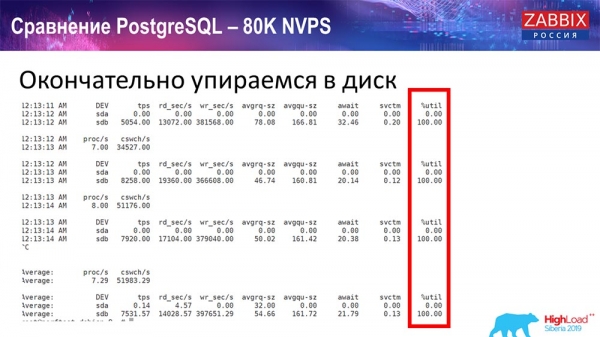
Hela denna tid övervakade jag alla systemparametrar (hur processorn används, RAM) och upptäckte att diskutnyttjandet var maximalt - jag uppnådde den maximala kapaciteten för denna disk på den här hårdvaran, på den här virtuella maskinen. "Postgres" började dumpa data ganska aktivt med sådan intensitet, och disken hade inte längre tid att skriva, läsa ...
Jag tog en annan server som redan hade 48 processorer och 128 gigabyte RAM:
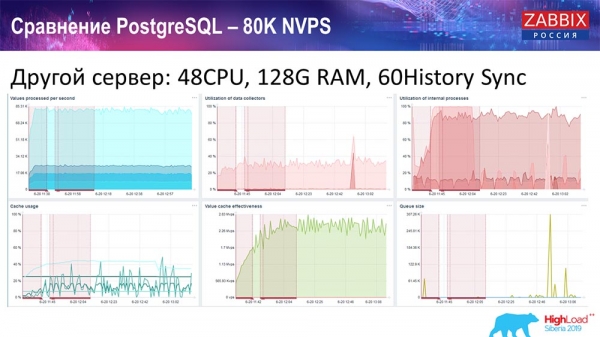
Jag "justerade" den också - installerade History syncer (60 stycken) och uppnådde acceptabel prestanda. I själva verket är vi inte "på hyllan", men detta är förmodligen gränsen för produktivitet, där det redan är nödvändigt att göra något åt det.
Utvärderingsprov. TidskalaDB: 80 tusen NVP
Min huvudsakliga uppgift var att använda TimescaleDB. Varje graf visar en dipp:
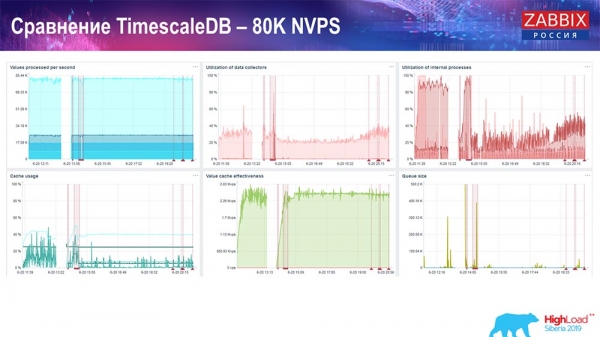
Dessa misslyckanden är just datamigrering. Efter det, i Zabbix-servern, förändrades laddningsprofilen för historiesänkare, som du kan se, mycket. Det låter dig infoga data nästan 3 gånger snabbare och använda mindre HistoryCache - följaktligen kommer du att få data levererad i tid. Återigen, 80 tusen värden per sekund är en ganska hög hastighet (naturligtvis inte för Yandex). Sammantaget är detta en ganska stor installation, med en server.
PostgreSQL prestandatest: 120 tusen NVP
Därefter ökade jag värdet på antalet dataelement till en halv miljon och fick ett beräknat värde på 125 tusen per sekund:
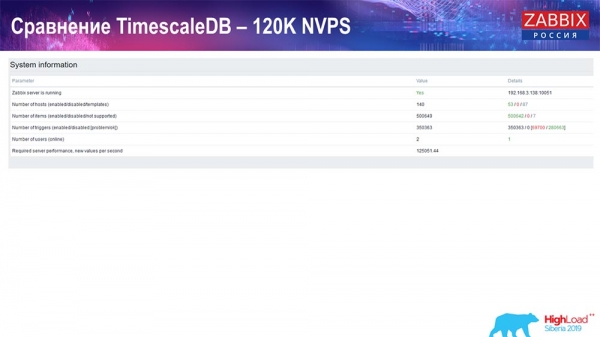
Och jag fick dessa grafer:
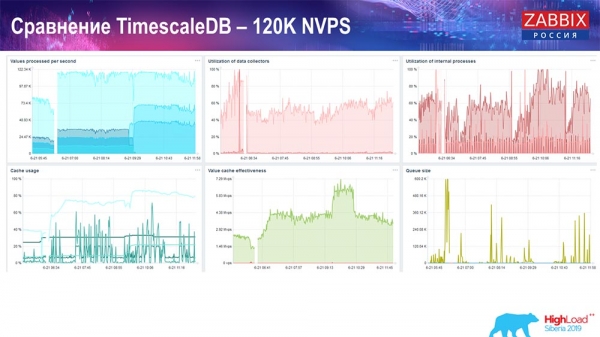
I princip är detta ett fungerande setup, det kan fungera ganska länge. Men eftersom jag bara hade en 1,5 terabyte disk använde jag den på ett par dagar. Det viktigaste är att det samtidigt skapades nya partitioner på TimescaleDB, och detta var helt obemärkt för prestanda, vilket inte kan sägas om MySQL.
Vanligtvis skapas partitioner på natten, eftersom detta i allmänhet blockerar insättning och arbete med tabeller och kan leda till försämring av tjänsten. I det här fallet är det inte så! Huvuduppgiften var att testa funktionerna i TimescaleDB. Resultatet blev följande siffra: 120 tusen värden per sekund.
Det finns också exempel i samhället:
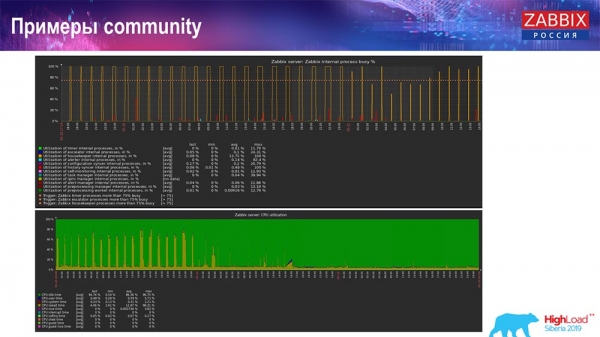
Personen slog också på TimescaleDB och belastningen på att använda io.weight sjönk på processorn; och användningen av interna processelement har också minskat på grund av införandet av TimescaleDB. Dessutom är det vanliga pannkaksdiskar, det vill säga en vanlig virtuell maskin på vanliga diskar (inte SSD)!
För vissa små inställningar som begränsas av diskprestanda är TimescaleDB enligt min mening en mycket bra lösning. Det gör att du kan fortsätta arbeta innan du migrerar till snabbare hårdvara för databasen.
Jag inbjuder er alla till våra evenemang: Konferens i Moskva, toppmöte i Riga. Använd våra kanaler - Telegram, forum, IRC. Om du har några frågor, kom till vårt skrivbord, vi kan prata om allt.
Publikens frågor
Fråga från publiken (nedan - A): - Om TimescaleDB är så lätt att konfigurera, och det ger en sådan prestandaboost, så kanske detta bör användas som en bästa praxis för att konfigurera Zabbix med Postgres? Och finns det några fallgropar och nackdelar med denna lösning, eller trots allt, om jag bestämde mig för att göra Zabbix för mig själv, kan jag enkelt ta Postgres, installera Timescale där direkt, använda den och inte tänka på några problem?

AG: – Ja, jag skulle säga att det här är en bra rekommendation: använd Postgres omedelbart med TimescaleDB-tillägget. Som jag redan sa, många bra recensioner, trots att denna "funktion" är experimentell. Men faktiskt tester visar att detta är en bra lösning (med TimescaleDB) och jag tror att den kommer att utvecklas! Vi övervakar hur denna förlängning utvecklas och kommer att göra ändringar vid behov.
Även under utvecklingen förlitade vi oss på en av deras välkända "funktioner": det var möjligt att arbeta med bitar lite annorlunda. Men sedan klippte de bort det i nästa release, och vi var tvungna att sluta lita på den här koden. Jag skulle rekommendera att du använder den här lösningen på många inställningar. Om du använder MySQL... För genomsnittliga inställningar fungerar vilken lösning som helst bra.
A: – På de sista graferna från samhället fanns det en graf med "Hushållerska":
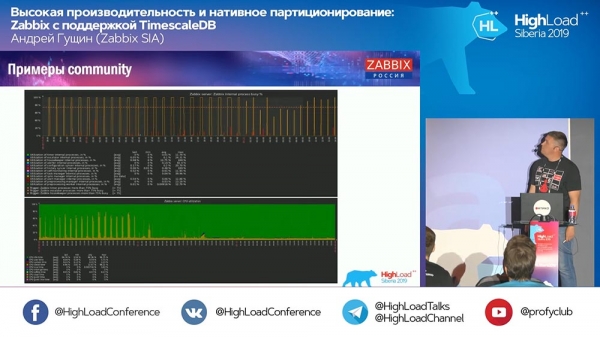
Han fortsatte att arbeta. Vad gör Housekeeper med TimescaleDB?
AG: – Nu kan jag inte säga säkert – jag ska titta på koden och berätta mer detaljerat. Den använder TimescaleDB-frågor för att inte ta bort bitar, utan för att på något sätt aggregera dem. Jag är inte redo att svara på den här tekniska frågan ännu. Vi får veta mer i montern idag eller imorgon.
A: – Jag har en liknande fråga – om utförandet av raderingsoperationen i Timescale.
A (svar från publiken): – När du raderar data från en tabell, om du gör det via delete, måste du gå igenom tabellen - radera, rensa, markera allt för framtida vakuum. I Timescale, eftersom du har bitar, kan du släppa. Grovt sett säger du helt enkelt till filen som är i big data: "Radera!"
Timescale förstår helt enkelt att en sådan bit inte längre existerar. Och eftersom den är integrerad i frågeplaneraren använder den krokar för att fånga dina villkor i utvalda eller andra operationer och förstår omedelbart att den här biten inte längre existerar - "Jag kommer inte att gå dit längre!" (data ej tillgängliga). Det är allt! Det vill säga, en tabellskanning ersätts av en binär filradering, så det går snabbt.
A: – Vi har redan berört ämnet icke-SQL. Såvitt jag förstår behöver Zabbix egentligen inte ändra data, och allt detta är ungefär som en logg. Går det att använda specialiserade databaser som inte kan ändra sin data, men samtidigt spara, ackumulera och distribuera mycket snabbare - Clickhouse, till exempel, något Kafka-likt?.. Kafka är också en logg! Är det möjligt att på något sätt integrera dem?
AG: – Avlastning kan göras. Vi har en viss "funktion" sedan version 3.4: du kan skriva alla historiska filer, händelser, allt annat till filer; och sedan skicka den till vilken annan databas som helst med någon hanterare. Faktum är att många omarbetar och skriver direkt till databasen. I farten skriver historiesänkare allt detta till filer, roterar dessa filer och så vidare, och du kan överföra detta till Clickhouse. Jag kan inte säga något om planerna, men kanske kommer ytterligare stöd för NoSQL-lösningar (som Clickhouse) att fortsätta.
A: – Generellt sett visar det sig att man helt kan bli av med postgres?
AG: – Den svåraste delen i Zabbix är förstås de historiska tabellerna, som skapar flest problem och händelser. I det här fallet, om du inte lagrar händelser under en lång tid och lagrar historiken med trender i någon annan snabblagring, så tror jag generellt att det inte kommer att vara några problem.
A: – Kan du uppskatta hur mycket snabbare allt kommer att fungera om du till exempel byter till Clickhouse?
AG: – Jag har inte testat det. Jag tror att åtminstone samma siffror kan uppnås helt enkelt, med tanke på att Clickhouse har sitt eget gränssnitt, men jag kan inte säga säkert. Det är bättre att testa. Allt beror på konfigurationen: hur många värdar du har och så vidare. Att infoga är en sak, men du måste också hämta denna data - Grafana eller något annat.
A: – Så vi talar om en jämlik kamp, och inte om den stora fördelen med dessa snabba databaser?
AG: – Jag tror att när vi integrerar kommer det att bli mer exakta tester.
A: – Vart tog gamla goda RRD vägen? Vad fick dig att byta till SQL-databaser? Till en början samlades alla mätvärden på RRD.
AG: – Zabbix hade RRD, kanske i en väldigt gammal version. Det har alltid funnits SQL-databaser – ett klassiskt tillvägagångssätt. Det klassiska tillvägagångssättet är MySQL, PostgreSQL (de har funnits väldigt länge). Vi använde nästan aldrig ett gemensamt gränssnitt för SQL- och RRD-databaser.


Några annonser 🙂
Tack för att du stannar hos oss. Gillar du våra artiklar? Vill du se mer intressant innehåll? Stöd oss genom att lägga en beställning eller rekommendera till vänner, , en unik analog av ingångsservrar, som uppfanns av oss för dig: (tillgänglig med RAID1 och RAID10, upp till 24 kärnor och upp till 40 GB DDR4).
Dell R730xd 2 gånger billigare i Equinix Tier IV datacenter i Amsterdam? Bara här i Nederländerna! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - från $99! Läs om
Källa: will.com
