

Alla pratar om utvecklings- och testprocesser, personalutbildning, ökad motivation, men dessa processer räcker inte till när en minuts driftstopp kostar astronomiska summor pengar. Vad ska man göra när man genomför finansiella transaktioner under ett strikt SLA? Hur ökar man tillförlitligheten och feltoleransen hos sina system, utan att ta utveckling och testning ur ekvationen?

Nästa HighLoad++-konferens kommer att hållas den 6-7 april 2020 i St. Petersburg. Detaljer och biljetter via 9 november, 18:00. HighLoad++ Moskva 2018, Delhi + Kolkata-hallen. Sammanfattningar och .
Evgeny Kuzovlev (nedan – EK): - Vänner, hej! Jag heter Evgeniy Kuzovlev. Jag kommer från EcommPay, en specifik avdelning - EcommPay IT, en IT-avdelning inom en företagsgrupp. Och idag ska vi prata om driftstopp - hur man undviker dem, hur man minimerar deras konsekvenser om man inte kan undvika dem. Ämnet är: "Vad ska man göra när en minuts driftstopp kostar 100 000 dollar"? Om vi blickar framåt är våra siffror jämförbara.
Vad gör EcommPay IT?
Vilka är vi? Varför står jag här framför er? Varför har jag rätt att berätta vad som helst för er här? Och vad ska vi diskutera mer i detalj här?
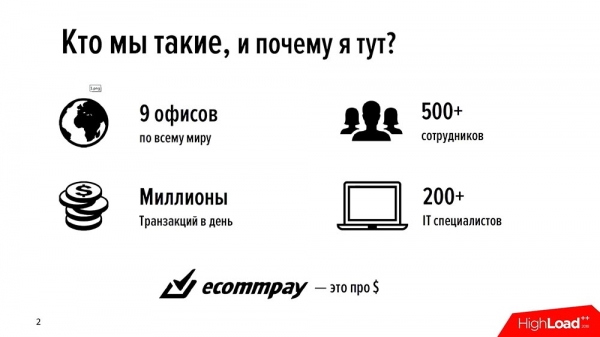
EcommPay-koncernen är en internationell inlösare. Vi hanterar betalningar över hela världen – i Ryssland, Europa, Sydostasien (över hela världen). Vi har 9 kontor, totalt 500 anställda, och ungefär hälften av dem är IT-specialister. Allt vi gör, allt vi tjänar pengar på, har vi gjort själva.
Vi skrev alla våra produkter själva (och vi har en hel del av dem – i vår serie av stora IT-produkter har vi ungefär 16 olika komponenter); vi skriver dem själva, vi utvecklar dem själva. Och för närvarande genomför vi ungefär en miljon transaktioner om dagen (miljoner – det är nog rätt ord). Vi är ett ganska ungt företag – vi är bara ungefär sex år gamla.
För 6 år sedan var det en startup, när killarna kom med företaget. De var enade av idén (det fanns inget annat än idén), och vi körde. Som alla startups körde vi snabbare... För oss var snabbhet viktigare än kvalitet.
Vid någon tidpunkt stannade vi upp: vi insåg att vi inte längre kunde leva med den hastigheten och kvaliteten och att vi behövde prioritera kvalitet först och främst. Vid den tidpunkten bestämde vi oss för att skriva en ny plattform som skulle vara korrekt, skalbar och pålitlig. Vi började skriva den här plattformen (vi började investera, utveckla och testa), men vid någon tidpunkt insåg vi att utveckling och testning inte tillät oss att nå en ny nivå av servicekvalitet.
Du tillverkar en ny produkt, du sätter den i produktion, men ändå, någonstans, kommer något att gå fel. Och idag ska vi prata om hur man når en ny kvalitetsnivå (hur vi gjorde det, om vår erfarenhet), och ta bort utveckling och testning ur ekvationen; vi ska prata om vad som är tillgängligt för driften - vad driften kan göra själv, vad den kan erbjuda testning för att påverka kvaliteten.
Stilleståndstider. Utnyttjandets budord.
Alltid den viktigaste hörnstenen, det vi faktiskt ska prata om idag är driftstopp. Ett skrämmande ord. Om vi har driftstopp är allt dåligt för oss. Vi springer för att få upp den, administratörerna håller servern – Gud förbjude att den faller, som de sjunger i den där sången. Det är det vi ska prata om idag.

När vi började ändra våra tillvägagångssätt formulerade vi fyra budord. Jag har presenterat dem på bilderna:
Dessa budord är ganska enkla:

- Identifiera problemet snabbt.
- Bli av med det ännu snabbare.
- Hjälp till att förstå orsaken (senare, för utvecklare).
- Och standardisera metoder.
Låt mig rikta er uppmärksamhet mot punkt nummer 2. Vi löser inte problemet. Att lösa det är sekundärt. Det primära för oss är att användaren skyddas från problemet. Det kommer att existera i en isolerad miljö, men denna miljö kommer inte att kontakta honom på något sätt. Vi kommer faktiskt att gå igenom dessa fyra problemgrupper (vissa mer detaljerat, vissa mindre detaljerat). Jag kommer att berätta vad vi använder, vilken erfarenhet vi har av lösningar.
Felsökning: När inträffar de och vad ska man göra åt dem?
Men vi börjar i fel ordning, vi börjar med punkt nummer 2 – hur blir man snabbt av med problemet? Det finns ett problem – vi måste eliminera det. ”Vad ska vi göra åt det?” – huvudfrågan. Och när vi började fundera på hur vi skulle eliminera problemet, utvecklade vi några krav för oss själva som elimineringen av problemen skulle följa.

För att formulera dessa krav bestämde vi oss för att ställa oss frågan: "När har vi problem?" Och problem, som det visade sig, uppstår i fyra fall:

- Maskinvarufel.
- Fel på externa tjänster.
- Ändra programvaruversionen (samma distribution).
- Explosiv tillväxt av last.
Vi ska inte prata om de två första. Hårdvarufel löses helt enkelt: du måste ha allt duplicerat. Om det är diskar måste diskarna monteras i RAID, om det är en server måste servern dupliceras, om du har en nätverksinfrastruktur måste du installera en andra kopia av nätverksinfrastrukturen, det vill säga du tar och duplicerar. Och om något går fel byter du till säkerhetskopieringskapacitet. Det är svårt att säga något mer här.
Det andra är att externa tjänster inte fungerar. För de flesta system är detta inte alls ett problem, men inte för oss. Eftersom vi behandlar betalningar är vi en aggregator som står mellan användaren (som anger sina kortuppgifter) och banker, betalningssystem (Visa, MasterCard, Mira, etc.). Våra externa tjänster (betalningssystem, banker) tenderar att misslyckas. Varken vi eller du (om du har sådana tjänster) kan påverka detta.
Vad ska man göra då? Det finns två alternativ. För det första, om möjligt, bör man på något sätt duplicera den här tjänsten. Till exempel, om vi kan, överför vi trafik från en tjänst till en annan: till exempel behandlar vi kort via Sberbank, Sberbank har problem - vi överför trafik [villkorligt] till Raiffeisen. Det andra vi kan göra är att mycket snabbt märka ett fel i externa tjänster, och därför kommer vi att prata om svarshastigheten i nästa del av rapporten.
Faktum är att vi från dessa fyra specifikt kan påverka ändringen av programvaruversioner - vidta åtgärder som leder till en förbättring i samband med distributioner och i samband med explosiv tillväxt av belastningen. Det gjorde vi faktiskt. Här, återigen, en liten anmärkning ...
Av dessa fyra problem löses flera omedelbart om du har ett moln. Om du befinner dig i molnen från Microsoft Azure, Ozon, använder våra moln, från Yandex eller Mail, så blir åtminstone hårdvarufelet deras problem och allt blir omedelbart bra för dig i samband med hårdvarufelet.
Vi är ett lite ovanligare företag. Här pratar alla om Kubernetes, om moln – vi har varken Kubernetes eller moln. Men vi har rack med hårdvara i många datacenter, och vi är tvungna att leva på den här hårdvaran, vi är tvungna att vara ansvariga för allt detta. Därför kommer vi att prata i detta sammanhang. Så, om problemen. De två första är utelämnade.
Ändra programvaruversionen. Grunderna
Våra utvecklare har inte tillgång till produktion. Varför det? Vi är PCI DSS-certifierade, och våra utvecklare har helt enkelt inte rätt att gå i produktion. Det är allt, punkt slut. Absolut. Därför upphör utvecklingsansvaret exakt i det ögonblick då utvecklaren har överfört builden för release.

Vår andra grund som vi har, som också hjälper oss mycket, är avsaknaden av unik odokumenterad kunskap. Jag hoppas att ni har detsamma. För om ni inte har det kommer ni att få problem. Problem kommer att uppstå när denna unika odokumenterade kunskap inte finns närvarande vid rätt tidpunkt på rätt plats. Låt oss säga att du har en person som vet hur man distribuerar en specifik komponent – personen är inte där, hen är på semester eller sjuk – det är allt, ni har problem.
Och den tredje grunden kom vi fram till. Vi kom fram till den genom smärta, blod, tårar – vi kom fram till slutsatsen att alla våra byggen innehåller fel, även om de är felfria. Vi bestämde själva: när vi driftsätter något, när vi rullar något i produktion – har vi en byggen med fel. Vi utformade de krav som vårt system måste uppfylla.
Krav för att ändra programvaruversionen
Det finns tre av dessa krav:

- Vi måste snabbt återställa utplaceringen.
- Vi måste minimera effekterna av en misslyckad implementering.
- Och vi måste kunna driftsättas snabbt parallellt.
I den ordningen! Varför? För det första är hastighet inte viktigt när man driftsätter en ny version, utan det är viktigt att snabbt kunna backa och ha minimal påverkan om något går fel. Men om du har en uppsättning versioner i produktion där det visar sig att det finns ett fel (helt oväntat, det skedde ingen driftsättning, men felet finns där) – bryr du dig om hastigheten på nästa driftsättning. Vad gjorde vi för att uppfylla dessa krav? Vi använde följande metod:
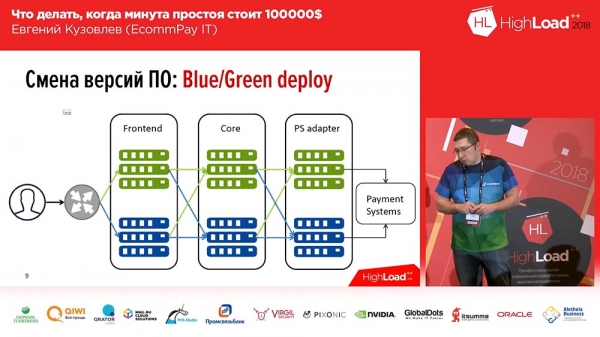
Det är ganska välkänt, vi har inte uppfunnit det alls – det är Blue/Green deploy. Vad är det? Du bör ha en kopia för varje grupp av servrar där dina applikationer finns. Kopian är "varm": det finns ingen trafik på den, men denna trafik kan när som helst skickas till denna kopia. Denna kopia innehåller den tidigare versionen. Och vid driftsättningstillfället rullar du ut koden till den inaktiva kopian. Sedan växlar du en del av trafiken (eller all) till den nya versionen. För att ändra trafikflödet från den gamla versionen till den nya behöver du alltså bara göra en sak: du behöver ändra balanseraren i uppströms, ändra riktningen – från en uppströms till en annan. Detta är mycket bekvämt och löser problemet med snabb växling, snabb återställning.Här är lösningen på den andra frågan – minimering: du kan bara skicka en del av din trafik (låt oss säga 2%) till en ny rad, till en rad med en ny kod. Och dessa 2% är inte 100%! Om du förlorar 100% av trafiken på grund av en misslyckad distribution – det är skrämmande, om du förlorar 2% av trafiken – det är obehagligt, men det är inte skrämmande. Dessutom kommer användarna troligtvis inte ens att märka detta, eftersom i vissa fall (inte alla) samma användare, efter att ha tryckt på F5, kommer till en annan, fungerande version.
Blå/grön driftsättning. Routing
Det är dock inte så enkelt som att ”implementera Blå/Grön”... Alla våra komponenter kan delas in i tre grupper:
- detta är användargränssnittet (betalningssidorna som våra kunder ser);
- processorkärna;
- adapter för att arbeta med betalningssystem (banker, MasterCard, Visa, etc.).
Och här finns en nyans – nyansen ligger i routingen mellan linjerna. Om man helt enkelt byter 100 % av trafiken har man inte dessa problem. Men om man vill byta 2 % börjar man ställa frågor: "Hur gör man detta?" Det enklaste, rakt på sak: man kan ställa in ett slumpmässigt urval, Round Robin i nginx, och man har 2 % till vänster, 98 % till höger. Men detta är inte alltid lämpligt.
Till exempel, i vårt fall interagerar användaren med systemet med mer än en förfrågan. Detta är normalt: 2, 3, 4, 5 förfrågningar – era system kan vara desamma. Och om det är viktigt för dig att alla användarförfrågningar kommer till samma rad där den första förfrågan kom, eller (andra punkten) alla användarförfrågningar kommer till en ny rad efter byte (han kunde ha börjat arbeta med systemet tidigare, innan bytet), då passar inte denna slumpmässiga fördelning dig. Då finns det följande alternativ:
Det första alternativet, det enklaste, baseras på klientens grundläggande parametrar (IP-hash). Du har en IP-adress och du delar den åt vänster och höger med IP-adressen. Då fungerar det andra fallet jag beskrev för dig. När driftsättningen har skett kan användaren redan börja arbeta med ditt system, och från driftsättningsögonblicket kommer alla förfrågningar att gå till den nya raden (till samma, låt oss säga).Om detta av någon anledning inte passar dig och du måste skicka förfrågningar till den rad där användarens ursprungliga förfrågan kom ifrån, har du två alternativ...
Det första alternativet: du kan välja en betald nginx+. Den har en mekanism som kallas Sticky sessions, som, på användarens första begäran, sätter upp en session för användaren och binder den till en eller annan uppströms plattform. Alla efterföljande förfrågningar från användaren inom sessionens livslängd skickas till samma uppströms plattform där sessionen ställdes in.Detta fungerade inte för oss eftersom vi redan hade vanlig nginx. Att byta till nginx+ är inte så att det är dyrt, det var bara lite smärtsamt för oss och inte riktigt rätt. Till exempel fungerade inte Sticky Sessions för oss av den enkla anledningen att Sticky Sessions inte tillåter routing baserat på "Either-Or". Där kan du ange vad Sticky Sessions gör, till exempel via IP eller via IP och cookies eller via postparameter, men "Either-Or" är mer komplicerat.
Det är därför vi kom fram till det fjärde alternativet. Vi tog nginx på "steroider" (detta är openresty) - det är samma nginx, som dessutom stöder inkludering av "last scripts". Du kan skriva ett "last script", skjuta det till "openresty", och detta "last script" kommer att köras när en användarförfrågan kommer.
Och vi skrev faktiskt ett sådant skript, satte oss själva "openrest" och i det här skriptet går vi igenom 6 olika parametrar genom sammankoppling "Eller". Beroende på närvaron av den eller den parametern vet vi att användaren kom till en eller annan sida, till en eller annan rad.
Blå/grön utplacering. Fördelar och nackdelar
Naturligtvis skulle det förmodligen kunna göras lite enklare (med samma "Stick Sessions"), men vi har också denna nyans, att inte bara användaren interagerar med oss inom ramen för en bearbetning av en transaktion... Utan betalningssystem interagerar också med oss: efter att vi bearbetat transaktionen (genom att skicka en begäran till betalningssystemet) får vi en coolback.
Och låt oss säga, om vi inom vår krets kan skicka användarens IP-adress i alla förfrågningar och dela upp användare baserat på IP-adressen, då kommer vi inte att säga till samma Visa: "Grabbar, vi är ett sånt retroföretag, vi är lite internationella (på webbplatsen och i Ryssland)... Men snälla, skicka oss användarens IP-adress i ett extra fält, ert protokoll är standardiserat"! Naturligtvis kommer de inte att hålla med.
Så det fungerade inte för oss - vi skapade openresty. Följaktligen fick vi detta med routing:Blå/grön implementering har följaktligen de fördelar jag nämnde, och nackdelar.
Det finns två nackdelar:
- du behöver bry dig om routing;
- Den andra stora nackdelen är kostnaden.
Ni behöver dubbelt så många servrar, ni behöver dubbelt så många driftsresurser, ni behöver lägga ner dubbelt så mycket ansträngning på att underhålla hela djurparken.
Förresten, bland fördelarna finns en annan sak som jag inte nämnt tidigare: du har en reserv i händelse av belastningstillväxt. Om du har en explosionsartad belastningstillväxt, ett stort antal användare har kommit till dig, så inkluderar du helt enkelt den andra raden i 50/50-fördelningen - och du har omedelbart x2 servrar i ditt kluster tills du löser problemet med att ha fler servrar.
Hur gör man en snabb utplacering?
Vi har pratat om hur man löser problemet med minimering och snabb återställning, men frågan kvarstår: "Hur distribuerar man snabbt?"
Här är allt kort och enkelt.- Ni måste ha ett CD-system (Continuous Delivery) – ni klarar er inte utan det. Om ni har en server kan ni driftsätta manuellt. Vi har ungefär ett och ett halvt tusen servrar och ett och ett halvt tusen manuellt, det är klart – vi kan sätta en avdelning av den här hallens storlek bara för driftsättning.
- Implementeringen bör ske parallellt. Om din implementering är sekventiell är allt fel. En server är bra, du kommer att distribuera ett och ett halvt tusen servrar hela dagen.
- Återigen, för hastighetens skull är detta förmodligen inte nödvändigt. Vid driftsättning monteras projektet vanligtvis. Du har ett webbprojekt, det finns en frontend-del (du skapar ett webbpaket där, bygger npm - något liknande), och den här processen är i princip kort - 5 minuter, men dessa 5 minuter kan vara kritiska. Det är därför vi till exempel inte gör det på det här sättet: vi tog bort dessa 5 minuter, vi driftsätter artefakter.
Vad är en artefakt? En artefakt är en kompilerad build där hela assemblerdelen redan är färdigställd. Vi lagrar denna artefakt i ett artefaktarkiv. Vi använde två sådana arkiv samtidigt - Nexus och nu jFrog Artifactory. Vi använde initialt Nexus eftersom vi började öva på detta tillvägagångssätt i Java-applikationer (det passade väl för detta). Sedan lade vi några applikationer skrivna i PHP där; och Nexus var inte längre lämpligt, och det är därför vi valde jFrog Artefactory, som kan artikulera nästan allt. Vi kom till och med till den punkt att vi lagrar våra egna binära paket i detta artefaktarkiv, som vi kompilerar för servrar.
Explosiv tillväxt av last
Vi pratade om att ändra programvaruversionen. Nästa sak vi har är en explosiv ökning av belastningen. Här förstår jag nog att en explosiv ökning av belastningen inte är helt rätt sak…
Vi skrev ett nytt system – det är serviceinriktat, modernt, vackert, arbetare överallt, köer överallt, asynkronitet överallt. Och i sådana system kan data gå igenom olika flöden. För den första transaktionen kan den 1:a, 3:e, 10:e arbetaren vara involverad, för den andra transaktionen – den 2:a, 4:e, 5:e. Och idag, låt oss säga, på morgonen har du ett dataflöde som involverar de tre första arbetarna, och på kvällen ändras det plötsligt, och allt involverar de andra tre arbetarna.
Och här visar det sig att du på något sätt måste skala upp arbetarna, du måste på något sätt skala upp dina tjänster, men samtidigt inte tillåta resursöverskott.
Vi definierade kraven för oss själva. Dessa krav är ganska enkla: det ska finnas Service Discovery, parametrisering – allt är standard för att bygga sådana skalbara system, förutom en punkt – resursavskrivning. Vi sa att vi inte är redo att avskriva resurser så att servrarna värmer luften. Vi tog "Consul", vi tog "Nomad", som hanterar våra arbetare.Varför är detta ett problem för oss? Låt mig backa lite. Vi har för närvarande cirka 70 betalningssystem bakom oss. På morgonen går trafiken genom Sberbank, sedan sjunker Sberbank till exempel, och vi byter till ett annat betalningssystem. Vi hade 100 arbetare före Sberbank, och efter det behöver vi snabbt rekrytera 100 arbetare till ett annat betalningssystem. Och det är önskvärt att allt detta sker utan mänsklig inblandning. För om det finns mänsklig inblandning borde det finnas en ingenjör där dygnet runt som bara ska göra detta, eftersom sådana fel, när det finns 24 system bakom dig, händer regelbundet.
Så vi tittade på Nomad, som har en öppen IP, och skrev vår egen grej, Scale-Nomad – ScaleNo, som gör ungefär så här: den övervakar kötillväxten och minskar eller ökar antalet arbetare beroende på dynamiken i köförändringen. När vi gjorde det tänkte vi: "Kanske borde vi använda öppen källkod för det?" Sedan tittade vi på det – det är så enkelt som två kopek.
Vi har inte gjort det öppen källkod än, men om du efter rapporten, efter att ha insett att du behöver något sådant, plötsligt får ett behov av det, mina kontakter finns på sista bilden – skriv till mig. Om minst 3-5 personer ansluter sig till oss – kommer vi att göra det öppen källkod.
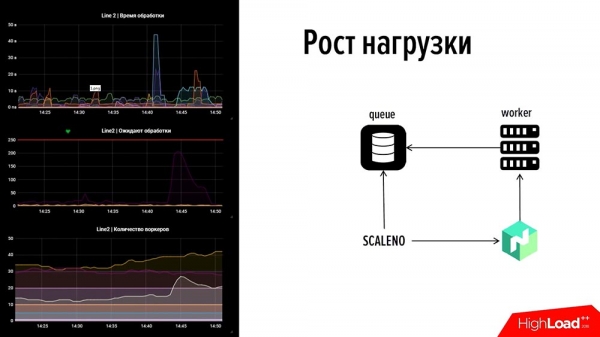
Hur fungerar det? Nu får vi se! Framåtblickande: på vänster sida finns en del av vår övervakning: detta är en rad, högst upp är händelsens bearbetningstid, i mitten är antalet transaktioner, längst ner är antalet arbetare.Om du tittar så finns det ett fel i den här bilden. I den övre grafen kraschade en av graferna på 45 sekunder – ett av betalningssystemen gick ner. Trafiken visades också i 2 minuter och kön började växa på ett annat betalningssystem, där det inte fanns några arbetare (vi utnyttjade inte resurserna – tvärtom utnyttjade vi resurserna korrekt). Vi ville inte värma upp oss – det fanns ett minimumantal, cirka 5–10 arbetare, men de klarade inte av det.
Den sista grafen visar en "puckel", vilket bara visar att "Scaleno" har fördubblat detta tal. Och sedan, när grafen sjönk lite, minskade den lite - antalet arbetare ändrades automatiskt. Det är så det här fungerar. Vi pratade om punkt #2 - "Hur man snabbt blir av med orsaker".
Övervakning. Hur identifierar man snabbt ett problem?
Nu är den första punkten: "Hur identifierar vi problemet snabbt?" Övervakning! Vi behöver snabbt förstå vissa saker. Vilka saker behöver vi snabbt förstå?
Tre saker!- Vi måste snabbt förstå och snabbt förstå hur våra egna resurser presterar.
- Vi måste snabbt förstå fel och övervaka prestandan hos system som är externa för oss.
- Den tredje punkten är att identifiera logiska fel. Det är när systemet fungerar för dig, allt är bra enligt alla indikatorer, men något går fel.
Här kommer jag nog inte att berätta så mycket som är så coolt. Jag ska vara Kapten Obvious. Vi letade efter vad som fanns på marknaden. Vi hade ett "roligt zoo". Det här är zooet vi har nu:
Vi använder Zabbix för att övervaka hårdvara, för att övervaka de viktigaste serverindikatorerna. Vi använder OkMeter för databaser. Vi använder Grafana och Prometheus för alla andra indikatorer som inte passar de två första, och vissa av dem med Grafana och Prometheus, och vissa av dem med Grafana med Influx och Telegraf.För ett år sedan ville vi använda New Relic. Det är en cool grej, den kan göra allt. Men hur mycket den än kan göra allt är den också dyr. När vi växte till en volym på 1,5 tusen servrar kom en leverantör till oss och sa: "Låt oss skriva ett kontrakt för nästa år." Vi tittade på priset och sa: "Nej, det gör vi inte." Nu vägrar vi New Relic, vi har ungefär 15 servrar kvar under New Relic-övervakning. Priset visade sig vara helt orimligt.
Och det finns ett verktyg som vi själva implementerade – det är Debugger. Först kallade vi det ”Bagger”, men sedan kom en engelsklärare förbi, skrattade vilt och döpte om det till ”Debugger”. Vad är det? Det är ett verktyg som faktiskt på 15–30 sekunder på varje komponent, som en ”svart låda” i systemet, kör tester för komponentens övergripande prestanda.
Om det till exempel är en extern sida (betalningssida) öppnar han den helt enkelt och tittar på hur den ska se ut. Om den bearbetas utlöser han en testtransaktion – ser till att denna "transaktion" går igenom. Om det är en koppling till betalningssystem utlöser vi en testförfrågan där vi kan, och ser till att allt är bra hos oss.
Vilka indikatorer är viktiga att övervaka?
Vad övervakar vi huvudsakligen? Vilka indikatorer är viktiga för oss?
- Svarstid/RPS på frontpanelerna är en mycket viktig indikator. Den reagerar omedelbart på att något är fel med dig.
- Antalet meddelanden som bearbetats i alla köer.
- Antal arbetare.
- Grundläggande mått på korrekthet.
Den sista punkten är "affärer", "affärs"-mått. Om du vill övervaka samma sak måste du definiera ett eller två mått som är de viktigaste indikatorerna för dig. Vårt mått är genomströmning (förhållandet mellan antalet lyckade transaktioner och det totala transaktionsflödet). Om något förändras i det under ett intervall på 5-10-15 minuter, då har vi problem (om det förändras dramatiskt).
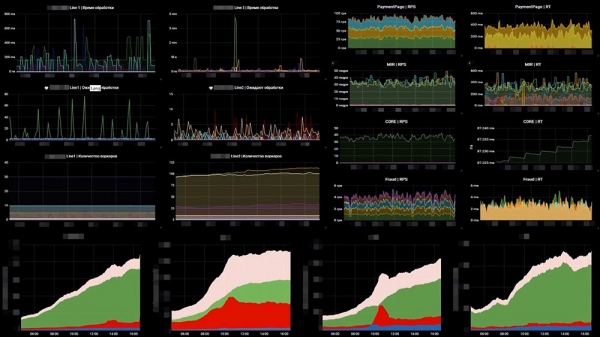
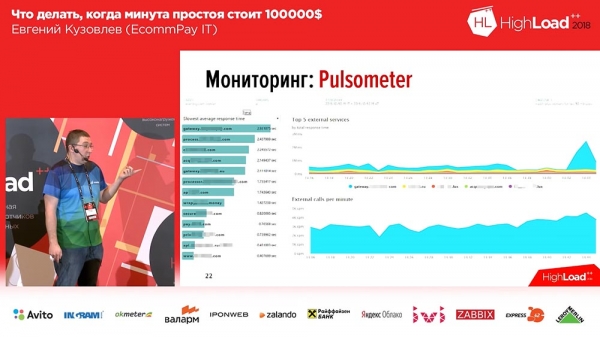
Så här ser det ut för oss är ett exempel på en av våra tavlor:
På vänster sida finns sex grafer, dessa visar antalet arbetare respektive antalet meddelanden i köer längs raderna. På höger sida finns RPS och RTS. Nedanför finns samma "affärs"-mått. Och på "affärs"-måttet kan vi direkt se att något gick fel på de två mittersta graferna… Det var bara ytterligare ett system som kraschade, vilket ligger bakom oss.Det andra vi var tvungna att göra var att övervaka fallet för externa betalningssystem. Här tog vi OpenTracing – en mekanism, ett standardparadigm som möjliggör spårning av distribuerade system; och ändrade det lite. Standardparadigmet för OpenTracing säger att vi bygger ett spår av varje enskild begäran. Vi behövde inte detta, och vi lindade in det i ett sammanfattande, aggregeringsspår. Vi skapade ett verktyg som låter oss spåra hastigheten på systemen bakom oss.
Diagrammet visar att ett av betalningssystemen började svara inom 3 sekunder – vi har problem. Samtidigt kommer den här saken att reagera när problemen uppstår, med intervall på 20–30 sekunder.Och den tredje klassen av övervakningsfel som finns är logisk övervakning.
Ärligt talat visste jag inte vad jag skulle rita på den här bilden, eftersom vi letat länge på marknaden efter något som skulle passa oss. Vi hittade ingenting, så vi fick göra det själva.
Vad menar jag med logisk övervakning? Tänk dig: du skapar ett system för dig själv (till exempel en klon av Tinder); du skapade det, lanserade det. En framgångsrik chef Vasya Pupkin installerade det på sin telefon, ser en tjej där, gillar henne... och liken går inte till tjejen - liken går till säkerhetsvakten Mikhalych från samma affärscenter. Chefen går ner för trappan och undrar sedan: "Varför ler den här säkerhetsvakten Mikhalych så trevligt mot honom"?I sådana situationer... För oss låter den här situationen lite annorlunda, eftersom (skrev jag) det är en sådan ryktesförlust som indirekt leder till ekonomiska förluster. Vi har den motsatta situationen: vi kan drabbas av direkta ekonomiska förluster – till exempel om vi genomförde en transaktion som framgångsrik, men den misslyckades (eller vice versa). Vi var tvungna att skriva vårt eget verktyg som spårar antalet framgångsrika transaktioner dynamiskt över ett tidsintervall baserat på affärsindikatorer. Vi hittade ingenting på marknaden! Det är precis den idén jag ville förmedla. Det finns inget på marknaden som löser den här typen av problem.
Det här handlade om hur man snabbt identifierar ett problem.
Hur man fastställer orsakerna till utplacering
Den tredje gruppen av uppgifter som vi löser är efter att vi har identifierat problemet, efter att vi har blivit av med det, vore det bra att förstå orsaken till utvecklingen, för testning och göra något åt det. Följaktligen behöver vi undersöka, vi behöver skapa loggar.
Om vi pratar om loggar (främsta orsaken är loggar), så finns huvuddelen av våra loggar i ELK-stacken – nästan alla har det så. För vissa kanske inte i ELK, men om man skriver loggar i gigabyte, så kommer man förr eller senare till ELK. Vi skriver dem i terabyte.
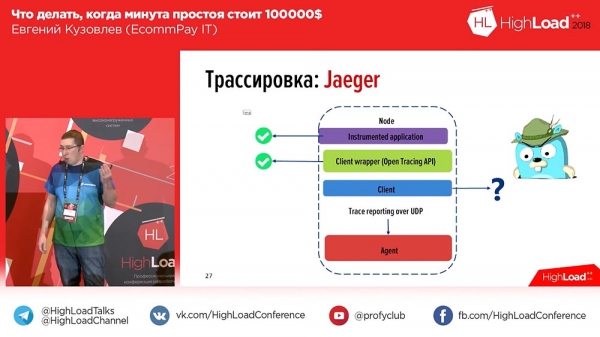
Det finns ett problem här. Vi fixade det, korrigerade felet för användaren, började gräva, vad som fanns där, klättrade in i Kibana, angav transaktions-ID:t där och fick den här loggen (visar mycket). Och i den här loggen är absolut ingenting tydligt. Varför? För att det inte är tydligt vilken del som refererar till vilken arbetare, vilken del som refererar till vilken komponent. Och i det ögonblicket insåg vi att vi behövde spårning - samma OpenTracing som jag pratade om.Vi funderade på det för ett år sedan, vände vår uppmärksamhet mot marknaden, och där fanns två verktyg – Zipkin och Jaeger. Jaeger är i själva verket en ideologisk efterträdare, en ideologisk efterträdare till Zipkin. Allt är bra i Zipkin, förutom att det inte kan aggregera, inte kan inkludera loggar i spårning, bara tidsspårning. Och Jaeger stödde detta.
Vi tittade på "Eger": man kan instrumentera applikationer, man kan skriva i API (API-standarden för PHP vid den tiden var dock inte godkänd - det var för ett år sedan, och nu har den blivit godkänd), men det fanns absolut ingen klient. "Okej", tänkte vi, och skrev vår egen klient. Vad fick vi? Ungefär så här ser det ut:
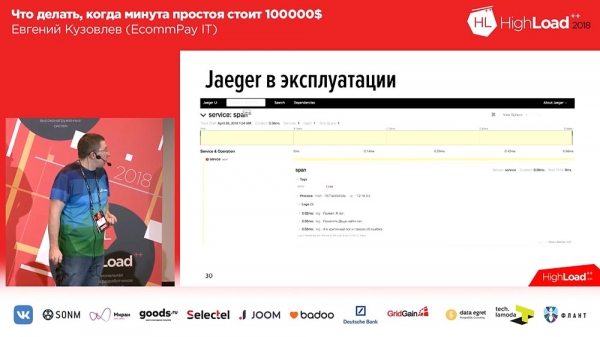
I "Eger" skapas spann för varje meddelande. Det vill säga, när en användare öppnar systemet ser hen ett eller två block för varje inkommande förfrågan (1-2-3 - lika många inkommande förfrågningar från användaren som det fanns block). För att göra det enklare för användarna har vi lagt till taggar i loggarna och tidsspårningen. Följaktligen, i händelse av ett fel, kommer vår applikation att markera loggen med motsvarande Error-tagg. Du kan filtrera efter Error-taggen och endast spann som innehåller detta block med felet kommer att visas. Så här ser det ut om vi expanderar spannet:
Inuti intervallet finns en uppsättning spår. I det här fallet är det tre testspår, och det tredje spåret berättar att ett fel inträffade. Samtidigt ser vi här ett tidsspår: vi har en tidsskala högst upp, och vi ser med vilket tidsintervall den eller den loggen registrerades.Följaktligen gick det bra för oss. Vi skrev vårt eget tillägg, och vi gjorde det till öppen källkod. Om du vill arbeta med spårning, om du vill arbeta med "Eger" i PHP - finns vårt tillägg, välkommen att använda, som de säger:
För oss är den här tillägget en klient för OpenTracing API, skapad som en php-tillägg, det vill säga att du behöver assemblera det och installera systemet under det. För ett år sedan fanns det inget annat. Nu finns det andra klienter som är som komponenter. Här är det upp till dig: antingen laddar du ner komponenter med composer, eller så använder du tillägget, bestämmer du själv.Företagsstandarder
Vi pratade om de tre budorden. Det fjärde budet handlar om att standardisera tillvägagångssätt. Vad handlar det om? Det handlar om detta:
Varför används ordet "företag" här? Inte för att vi är ett stort eller byråkratiskt företag, nej! Jag ville använda ordet "företag" här i sammanhanget att varje företag, varje produkt, borde ha sina egna standarder, inklusive din. Vilka standarder har vi?- Vi har en utplaceringsordning. Vi rör oss inte någonstans utan den, vi kan inte. Vi utplacerar ungefär 60 gånger i veckan, det vill säga vi utplacerar nästan konstant. Samtidigt finns det till exempel i vår utplaceringsordning ett tabu mot utplacering på fredagar – i princip utplacerar vi inte.
- Vi kräver dokumentation. Ingen ny komponent går i produktion utan dokumentation, även om den skapats av våra RnD-tekniker. Vi kräver att de tillhandahåller driftsättningsinstruktioner, en övervakningskarta och en grov beskrivning (som programmerare kan skriva) av hur komponenten fungerar och hur man felsöker den.
- Vi löser inte orsaken till problemet, utan problemet – det jag redan har sagt. Det är viktigt för oss att skydda användaren från problem.
- Vi har toleranser. Till exempel betraktar vi det inte som driftstopp om vi förlorat 2 % av trafiken under två minuter. I princip räknas inte detta med i vår statistik. Om det är mer i procent eller tid räknar vi det redan.
- Och vi skriver alltid obduktioner. Vad som än händer oss, varje situation där något gick fel i produktionen, kommer det att återspeglas i obduktionen. En obduktion är ett dokument där du skriver ner vad som hände, en detaljerad tidpunkt, vad du gjorde för att åtgärda det och (detta är ett obligatoriskt block!) vad du kommer att göra för att förhindra att detta händer i framtiden. Detta är obligatoriskt, nödvändigt för efterföljande analys.
Vad anses vara driftstopp?
Vad ledde allt detta till?Detta ledde till att (vi hade vissa stabilitetsproblem, detta passade varken våra kunder eller oss) under de senaste 6 månaderna har vår stabilitetsindikator varit 99,97. Man kan säga att det inte är särskilt mycket. Ja, vi har något att sträva efter. Av denna indikator är ungefär hälften stabiliteten hos vår webbapplikationsbrandvägg, som ligger framför oss och används som en tjänst, men kunderna bryr sig inte om detta.
Vi har lärt oss att sova på natten. Äntligen! För sex månader sedan kunde vi inte. Och med tanke på resultaten vill jag göra en kommentar. Igår kväll kom det en fantastisk rapport om kärnreaktorns kontrollsystem. Om de som skrev det här systemet lyssnar på mig, glöm vad jag sa om att "2 % är inte stilleståndstid". För er är 2 % stilleståndstid, även om det är i två minuter!"
Det var allt för nu! Dina frågor.
Om balanserare och databasmigrering
Fråga från publiken (nedan kallad B): – God kväll. Tack så mycket för en sådan administratörsrapport! En kort fråga, om era balanserare. Ni nämnde att ni har en WAF, det vill säga, som jag förstår det, använder ni någon extern balanserare…
EG: – Nej, vi använder våra egna tjänster som en balanseringsmekanismen. I det här fallet är WAF uteslutande ett DDoS-skyddsverktyg för oss.
PÅ: – Kan du säga några ord om balanserare?
EG: - Som jag redan sagt, detta är en grupp servrar i OpenResty. Vi har nu 5 grupper av dem, reserverade, som svarar exklusivt... det vill säga en server där OpenResty är installerat exklusivt, den hanterar bara proxytrafik. För att förstå hur mycket vi stöder: vårt vanliga trafikflöde är nu flera hundra megabit. De klarar sig, de gör bra ifrån sig, de anstränger sig inte ens.
PÅ: - Också en enkel fråga. Här är blå/grön implementering. Och vad gör ni till exempel med migreringar från databasen?
EG: – Bra fråga! I Blue/Green-distributionen har vi separata köer för varje rad. Det vill säga, om vi pratar om händelseköer som överförs från arbetare till arbetare, finns det separata köer för den blå linjen och den gröna linjen. Om vi pratar om själva databasen har vi begränsat den så mycket vi kunnat, vi har flyttat nästan allt till köer, i databasen lagrar vi bara transaktionsstacken. Och transaktionsstacken är densamma för alla rader. Med databasen i detta sammanhang: vi separerar den inte i blå och grön, eftersom båda versionerna av koden måste veta vad som händer med transaktionen.
Vänner, jag har ytterligare ett litet pris att sporra er till – en bok. Och jag måste ge det till den bästa frågan.
PÅ: - Hej. Tack för rapporten. Här är frågan. Ni övervakar betalningar, ni övervakar de tjänster ni kommunicerar med... Men hur övervakar ni att en person på något sätt hamnat på er betalningssida, gjort en betalning och att projektet krediterat hen med pengar? Det vill säga, hur övervakar ni att säljaren är tillgänglig och accepterat ert återuppringning?
EG: – För oss är ”handlaren” i det här fallet exakt samma externa tjänst som betalningssystemet. Vi övervakar hastigheten på ”handlarens” svar.
Om databaskryptering
PÅ: - Hej. Jag har en något relaterad fråga. Ni har känsliga uppgifter enligt PCI DSS. Jag undrar hur ni lagrar PAN:er i köer, som ni behöver vidarebefordra till? Använder ni någon kryptering? Och därav den andra frågan: enligt PCI DSS är det nödvändigt att regelbundet kryptera om databasen vid ändringar (avskedande av administratörer etc.) - hur händer detta med tillgängligheten?
EG: – En utmärkt fråga! För det första lagrar vi inte PAN i köer. Vi har i princip inte rätt att lagra PAN någonstans i öppen form, så vi använder en speciell tjänst (vi kallar den "Keydemon") – det här är en tjänst som bara gör en sak: den accepterar ett meddelande som indata och returnerar ett krypterat meddelande. Och vi lagrar allt med detta krypterade meddelande. Följaktligen är längden på vår nyckel under en kilobyte, så den är verkligen seriös och pålitlig.PÅ: – Behöver du 2 kilobyte nu?
EG: – Det känns som igår var det 256... Var annars?!
Följaktligen är detta det första. Och för det andra, den lösning som finns, den stöder omkrypteringsproceduren - det finns två par "keks" (nycklar), som ger "deks" som krypterar (nyckel - dessa är nycklar, dek - är derivat av nycklar som krypterar). Och om proceduren initieras (det händer regelbundet, från 3 månader till ± några) laddar vi ett nytt par "keks", och vi har omkryptering av data. Vi har separata tjänster som river ut all data, krypterar den på ett nytt sätt; data har en identifierare för nyckeln som de krypteras med lagrad i närheten. Följaktligen, så snart vi krypterar data med nya nycklar, raderar vi de gamla nycklarna.
Ibland måste betalningar göras manuellt…
PÅ: - Det vill säga, om en återbetalning för någon transaktion har kommit, kommer ni att dekryptera den med den gamla nyckeln för tillfället?
EG: - Ja.
PÅ: - Sedan en liten fråga till. När ett fel, fall eller en incident inträffar är det nödvändigt att genomföra transaktionen manuellt. En sådan situation uppstår.
EG: – Ja, det händer.
PÅ: - Varifrån får du dessa uppgifter? Eller går du manuellt till den här lagringsanläggningen själv?
EG: – Nej, det är ju klart – vi har ett slags backoffice-system som innehåller ett gränssnitt för vår support. Om vi inte vet transaktionens status (till exempel förrän betalningssystemet har gått ut) – vet vi inte det a priori, det vill säga att vi tilldelar den slutliga statusen först när vi är helt säkra. I det här fallet ger vi transaktionen en särskild status för manuell bearbetning. På morgonen nästa dag, så snart supporten får information om att den och den transaktionen finns kvar i betalningssystemet, bearbetar de dem manuellt i det här gränssnittet.
PÅ: – Jag har ett par frågor. En av dem gäller fortsättningen av PCI DSS-zonen: hur tar man ut loggar från deras kontur? Den här frågan beror på att utvecklaren kunde ha lagt vad som helst i loggarna! Den andra frågan: hur rullar man ut snabbkorrigeringar? Manuellt i databasen – det är ett alternativ, men det kan finnas gratis snabbkorrigeringar – hur fungerar det där? Och den tredje frågan är förmodligen relaterad till RTO, RPO. Er tillgänglighet var 99,97, nästan fyra nior, men som jag förstår det har ni ett andra datacenter, och ett tredje datacenter, och ett femte datacenter… Hur hanterar ni deras synkronisering, replikering, allt annat?EG: – Låt oss börja med det första. Den första frågan handlade om loggar? När vi skriver loggar finns det ett lager som maskerar all känslig data. Det tittar på masken och ytterligare fält. Följaktligen kommer våra loggar ut med redan maskerad data och en PCI DSS-struktur. Detta är en av de regelbundna uppgifterna som tilldelas testavdelningen. De är skyldiga att kontrollera varje uppgift, inklusive de loggar de skriver, och detta är en av de regelbundna uppgifterna under kodgranskningen, för att kontrollera att utvecklaren inte har skrivit ner något. Efterföljande verifiering av detta utförs regelbundet av informationssäkerhetsavdelningen ungefär en gång i veckan: loggar för den senaste dagen tas selektivt, och de körs genom en speciell skanner-analysator från testservrarna för att kontrollera allt detta.
Angående snabbkorrigeringar. Detta ingår i våra distributionsregler. Vi har en separat punkt om snabbkorrigeringar. Vi anser att vi driftsätter snabbkorrigeringar dygnet runt när vi behöver det. Så snart versionen är kompilerad, så snart den körs, så snart vi har en artefakt - har vi en jourhavande systemadministratör från supporten, och han driftsätter den när det behövs.Ungefär "fyra nior". Den siffra vi har nu, den uppnåddes verkligen, och vi strävade efter den på ett annat datacenter. Nu har vi ett andra datacenter, och vi börjar routa mellan dem, och frågan om replikering mellan datacenter är egentligen en icke-trivial fråga. Vi försökte lösa det då på olika sätt: vi försökte använda samma "Tarantula" - det fungerade inte för oss, jag ska berätta det direkt. Därför kom vi till den punkt att vi gör en beställning för "sens" manuellt. Faktum är att varje applikation i vårt asynkrona läge för den nödvändiga synkroniseringen "ändras - klar" körs mellan datacenter.
PÅ: - Om du har en andra, varför har inte en tredje dykt upp? För Split-brain är ingen än...
EG: – Och vi har ingen "Split-brain". Eftersom varje applikation körs av en multimaster spelar det ingen roll för oss vilket center förfrågan kom till. Vi är beredda på att om ett av våra datacenter går ner (vi räknar med detta) och byter till det andra datacentret mitt i en användares förfrågan, är vi beredda att förlora den här användaren, visserligen; men dessa kommer att vara väldigt få, absolut få.
PÅ: – God kväll. Tack för rapporten. Du pratade om din felsökare, som kör vissa testtransaktioner i produktion. Berätta nu om testtransaktioner! Hur djupt går den?
EG: - Den går igenom hela komponentens cykel. För komponenten är det ingen skillnad mellan en testtransaktion och en livetransaktion. Och ur logikens synvinkel är det helt enkelt ett separat projekt i systemet, på vilket endast testtransaktioner körs.
PÅ: - Var klipper du av den? Kärnan skickades...
EG: – Vi är för ”Kor” i det här fallet för testtransaktioner... Vi har ett sådant koncept som routing: ”Kor” vet vilket betalningssystem den ska skicka till – vi skickar till ett falskt betalningssystem, som helt enkelt ger en http-retur och det är allt.
PÅ: – Snälla, säg mig, är din applikation skriven som en enda stor monolit, eller har du delat upp den i några tjänster eller till och med mikrotjänster?
EG: – Vi har förstås ingen monolit, vi har en tjänsteorienterad applikation. Vi skämtar om att vi har en tjänst gjord av monoliter – de är egentligen ganska stora. Det är svårt att kalla dem mikrotjänster, men det här är tjänster inom vilka distribuerade maskinarbetare arbetar.
Om tjänsten på servern är komprometterad…
PÅ: – Sedan har jag nästa fråga. Även om det vore en monolit, sa du ändå att du har många av dessa snabbservrar, alla bearbetar i princip data, och frågan är: "Om en av snabbservrarna eller en applikation, någon enskild länk, komprometteras, har de någon form av åtkomstkontroll? Vilka av dem kan göra vad? Vem ska man kontakta, för vilka data?"
EG: – Ja, definitivt. Säkerhetskraven är ganska allvarliga. För det första har vi öppna dataflöden, och bara de portar genom vilka vi förväntar oss trafikflöde. Om en komponent kommunicerar med en databas (säg med Muskul) via 5-4-3-2, kommer bara 5-4-3-2 att vara öppen för den, och andra portar, andra riktningar för trafikflödet, kommer inte att vara tillgängliga. Dessutom måste vi förstå att det i vår produktion finns cirka 10 olika säkerhetskonturer. Och även om applikationen på något sätt komprometterades, Gud förbjude, kommer angriparen inte att kunna komma åt serverhanteringskonsolen, eftersom detta är en annan nätverkssäkerhetszon.PÅ: – Och i det här sammanhanget är jag mer intresserad av det faktum att man har vissa kontrakt med tjänster – vad de kan göra, genom vilka ”åtgärder” de kan kontakta varandra... Och i ett normalt flöde begär vissa specifika tjänster en viss rad, en lista med ”åtgärder” på en annan. De kontaktar inte andra i en normal situation, och de har andra ansvarsområden. Om en av dem komprometteras, kommer den att kunna hämta ”åtgärderna” för den tjänsten?..
EG: – Jag förstår. Om kommunikation överhuvudtaget var tillåten i en normal situation med en annan server, så ja. Enligt SLA-avtalet övervakar vi inte att man bara får de första 3 "åtgärderna", och 4 "åtgärder" är inte tillåtna. Detta är förmodligen överdrivet för oss, eftersom vi redan i princip har ett 4-nivås skyddssystem för konturerna. Vi föredrar att skydda oss med konturer, och inte på insidans nivå.
Hur Visa, MasterCard och Sberbank fungerar
PÅ: – Jag vill förtydliga punkten kring att byta användare från ett datacenter till ett annat. Såvitt jag vet fungerar Visa och MasterCard med det binära synkrona protokollet 8583, det finns blandningar där. Och jag ville veta, är detta en direkt växling mellan Visa och MasterCard eller före betalningssystemen, före bearbetningen?
EG: – Detta är före mixarna. Våra mixar finns i ett och samma datacenter.
PÅ: – Grovt sett har ni en kopplingspunkt?
EG: - Visa och MasterCard - ja. Helt enkelt för att Visa och MasterCard kräver ganska stora investeringar i infrastruktur för att ingå separata kontrakt för att ta emot ett andra par mixar, till exempel. De är reserverade inom ett datacenter, men om, Gud förbjude, vårt datacenter där mixarna för anslutning till Visa och MasterCard finns dör, då kommer vår anslutning till Visa och MasterCard att försvinna...
PÅ: – Hur kan de reserveras? Jag vet att Visa i princip bara tillåter att en anslutning upprätthålls!
EG: – De levererar utrustningen själva. I vilket fall som helst fick vi utrustning som är helt säkerhetskopierad internt.
PÅ: - Så stativet är från deras Connects Orange?..
EG: - Ja.
PÅ: – Och hur är det med det här fallet: om ert datacenter försvinner, hur fortsätter ni att använda det? Eller upphör trafiken helt enkelt?
EG: – Nej. I det här fallet kommer vi helt enkelt att byta trafik till en annan kanal, vilket naturligtvis blir dyrare för oss, dyrare för kunderna. Men trafiken kommer inte att gå via vår direkta anslutning till Visa, MasterCard, utan via en villkorad Sberbank (väldigt överdrivet).
Jag ber så hemskt mycket om ursäkt om jag har förolämpat Sberbanks anställda. Men enligt vår statistik är Sberbank den ryska bank som oftast faller. Det går inte en månad utan att något faller i Sberbank.

Några annonser 🙂
Tack för att du stannar hos oss. Gillar du våra artiklar? Vill du se mer intressant innehåll? Stöd oss genom att lägga en beställning eller rekommendera till vänner, , en unik analog av ingångsservrar, som uppfanns av oss för dig: (tillgänglig med RAID1 och RAID10, upp till 24 kärnor och upp till 40 GB DDR4).
Dell R730xd 2 gånger billigare i Equinix Tier IV datacenter i Amsterdam? Bara här i Nederländerna! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - från $99! Läs om



















Källa: will.com
