


Jag stötte på följande typ av problem. Det är nödvändigt att implementera en datalagringsbehållare som tillhandahåller följande funktionalitet:
- infoga nytt element
- ta bort element med serienummer
- få element efter ordningsnummer
- data lagras i sorterad form
Data läggs ständigt till och tas bort, strukturen måste säkerställa snabb drifthastighet. Först försökte jag implementera en sådan sak med hjälp av standardbehållare från std. Den här vägen kröntes inte med framgång och förståelsen kom att jag behövde genomföra något själv. Det enda som kom att tänka på var att använda ett binärt sökträd. Eftersom det uppfyller kravet på snabb infogning, radering och lagring av data i sorterad form. Allt som återstår är att ta reda på hur man indexerar alla element och räknar om indexen när trädet ändras.
struct node_s {
data_t data;
uint64_t weight; // вес узла
node_t *left;
node_t *right;
node_t *parent;
};Artikeln kommer att innehålla fler bilder och teori än kod. Koden kan ses på länken nedan.
Vikt
För att uppnå detta genomgick trädet en liten modifiering, ytterligare information lades till om vikt nod. Nodens vikt är antal ättlingar till denna nod + 1 (vikten av ett enda element).
Funktion för att få nodvikt:
uint64_t bntree::get_child_weight(node_t *node) {
if (node) {
return node->weight;
}
return 0;
}Vikten av arket är motsvarande lika med 0.
Låt oss sedan gå vidare till en visuell representation av ett exempel på ett sådant träd. svart nodnyckeln kommer att visas i färg (värdet kommer inte att visas, eftersom detta inte är nödvändigt), röd — knutvikt, grön — nodindex.
När vårt träd är tomt är dess vikt 0. Låt oss lägga till ett rotelement till det:
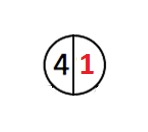
Trädets vikt blir 1, rotelementets vikt blir 1. Rotelementets vikt är trädets vikt.
Låt oss lägga till några fler element:
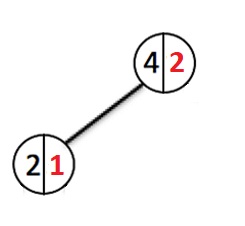
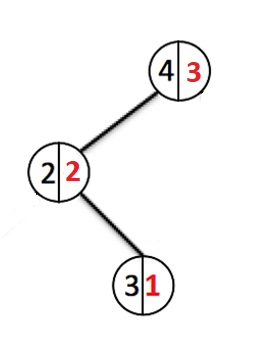
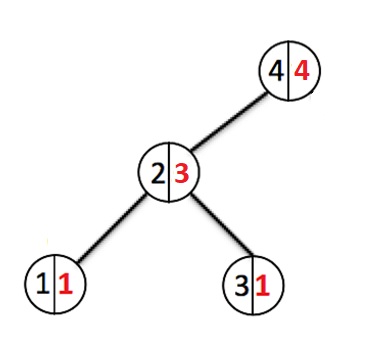
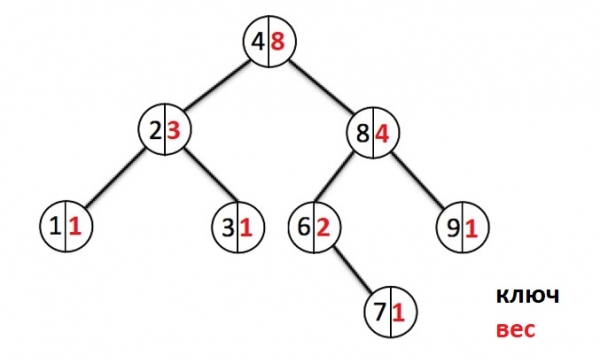
Varje gång ett nytt element läggs till går vi ner i noderna och ökar vikträknaren för varje passerad nod. När en ny nod skapas tilldelas den en vikt 1. Om en nod med en sådan nyckel redan existerar, kommer vi att skriva över värdet och gå tillbaka till roten och avbryta förändringarna i vikten för alla noder som vi har passerat.
Om en nod tas bort, går vi ner och minskar vikten av de passerade noderna.
Index
Låt oss nu gå vidare till hur man indexerar noder. Noder lagrar inte explicit sitt index, det beräknas utifrån nodernas vikt. Om de lagrade sitt index skulle det krävas O (n) dags att uppdatera indexen för alla noder efter varje ändring i trädet.
Låt oss gå vidare till en visuell representation. Vårt träd är tomt, låt oss lägga till den första noden till det:
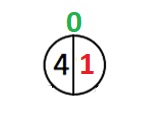
Den första noden har ett index 0, och nu är 2 fall möjliga. I det första kommer indexet för rotelementet att ändras, i det andra kommer det inte att ändras.
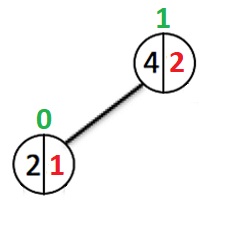
Vid roten väger det vänstra underträdet 1.
Andra fallet:
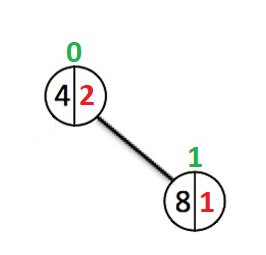
Rotens index ändrades inte eftersom vikten av dess vänstra underträd förblev 0.
Indexet för en nod beräknas som vikten av dess vänstra underträd + antalet som skickas från föräldern. Vad är detta nummer?, Detta är indexräknaren, initialt är den lika med 0, därför att roten har ingen förälder. Sen beror allt på var vi går ner till vänster barn eller höger. Om till vänster läggs ingenting till räknaren. Om vi lägger till indexet för den aktuella noden till den högra.
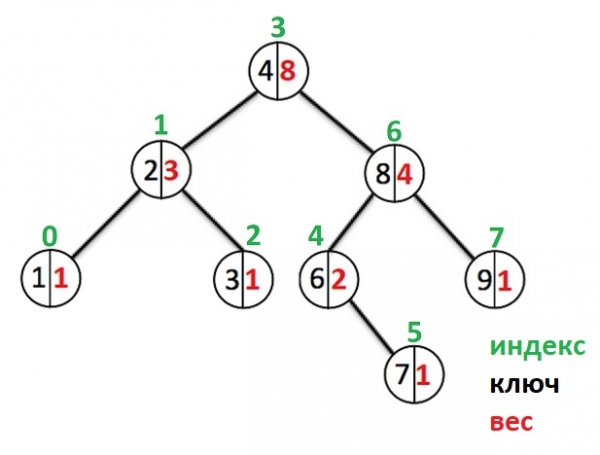
Till exempel hur indexet för ett element med nyckel 8 (det högra underordnade av roten) beräknas. Detta är "Root Index" + "vikten av vänster underträd av nod med nyckel 8" + "1" == 3 + 2 + 1 == 6
Indexet för elementet med nyckel 6 kommer att vara "Root Index" + 1 == 3 + 1 == 4
Följaktligen tar det tid att hämta och ta bort ett element per index O (log n), för för att få det önskade elementet måste vi först hitta det (gå ner från roten till detta element).
djup
Baserat på vikten kan du även beräkna trädets djup. Nödvändigt för att balansera.
För att göra detta måste vikten av den aktuella noden avrundas till det första talet till potensen 2 som är större än eller lika med den givna vikten och ta den binära logaritmen från den. Detta kommer att ge oss trädets djup, förutsatt att det är balanserat. Trädet är balanserat efter att ett nytt element har satts in. Jag kommer inte att ge en teori om hur man balanserar träd. Källkoderna ger en balanserande funktion.
Kod för omvandling av vikt till djup.
/*
* Возвращает первое число в степени 2, которое больше или ровно x
*/
uint64_t bntree::cpl2(uint64_t x) {
x = x - 1;
x = x | (x >> 1);
x = x | (x >> 2);
x = x | (x >> 4);
x = x | (x >> 8);
x = x | (x >> 16);
x = x | (x >> 32);
return x + 1;
}
/*
* Двоичный логарифм от числа
*/
long bntree::ilog2(long d) {
int result;
std::frexp(d, &result);
return result - 1;
}
/*
* Вес к глубине
*/
uint64_t bntree::weight_to_depth(node_t *p) {
if (p == NULL) {
return 0;
}
if (p->weight == 1) {
return 1;
} else if (p->weight == 2) {
return 2;
}
return this->ilog2(this->cpl2(p->weight));
}Resultat av
- införande av ett nytt element sker i O (log n)
- radering av ett element med serienummer sker i O (log n)
- erhållande av ett element genom serienummer sker i O (log n)
Fart O (log n) Vi betalar för att all data lagras i sorterad form.
Jag vet inte var en sådan struktur kan vara användbar. Bara ett pussel för att återigen förstå hur träd fungerar. Tack för din uppmärksamhet.
referenser
Projektet innehåller testdata för att kontrollera drifthastigheten. Trädet håller på att fyllas 1000000 element. Och det finns en sekventiell radering, infogning och hämtning av element 1000000 en gång. Det är 3000000 operationer. Resultatet visade sig vara ganska bra ~ 8 sekunder.
Källa: will.com
