

Moln är som en magisk låda - du frågar vad du behöver, och resurserna dyker upp från ingenstans. Virtuella maskiner, databaser, nätverk - allt detta tillhör bara dig. Det finns andra molnhyresgäster, men i ditt universum är du den enda härskaren. Du är säker på att du alltid kommer att få de resurser som krävs, du tar inte hänsyn till någon och du bestämmer självständigt hur nätverket kommer att se ut. Hur fungerar denna magi som gör att molnet elastiskt allokerar resurser och helt isolerar hyresgäster från varandra?
AWS-molnet är ett mega-superkomplext system som har utvecklats evolutionärt sedan 2006. En del av denna utveckling skedde Vasily Pantyukhin - Amazon Web Services Architect. Som arkitekt får han en inblick i inte bara slutresultatet, utan också på de utmaningar som AWS övervinner. Ju större förståelse för hur systemet fungerar, desto större förtroende. Därför kommer Vasily att dela med sig av AWS molntjänsters hemligheter. Nedan är designen av fysiska AWS-servrar, elastisk databasskalbarhet, en anpassad Amazon-databas och metoder för att öka prestanda på virtuella maskiner samtidigt som de sänker deras pris. Kunskap om Amazons arkitektoniska tillvägagångssätt hjälper dig att använda AWS-tjänster mer effektivt och kan ge dig nya idéer för att bygga dina egna lösningar.
Om talaren: Vasily Pantyukhin () började som Unix-administratör på .ru-företag, arbetade med stor Sun Microsystem-hårdvara i 6 år och predikade en datacentrerad värld på EMC i 11 år. Det utvecklades naturligt till privata moln och flyttade 2017 till offentliga. Nu ger han tekniska råd för att hjälpa till att leva och utvecklas i AWS-molnet.
Friskrivningsklausul: allt nedan är Vasilys personliga åsikt och kanske inte sammanfaller med Amazon Web Services position. Rapporten som artikeln bygger på finns tillgänglig på vår YouTube-kanal.
Varför pratar jag om Amazon-enheten?
Min första bil hade en manuell växellåda. Det var fantastiskt på grund av känslan av att jag kunde köra bilen och ha fullständig kontroll över den. Jag gillade också att jag åtminstone ungefär förstod principen för dess funktion. Naturligtvis föreställde jag mig att lådans struktur var ganska primitiv - ungefär som en växellåda på en cykel.

Allt var toppen, förutom en sak - fast i bilköer. Det verkar som att du sitter och inte gör någonting, men du växlar hela tiden, trycker på kopplingen, gasar, bromsar - det gör dig verkligen trött. Trafikstockningsproblemet löstes delvis när familjen skaffade en automatbil. Under körningen hann jag tänka på något och lyssna på en ljudbok.
Ett annat mysterium dök upp i mitt liv, eftersom jag helt slutade förstå hur min bil fungerar. En modern bil är en komplex enhet. Bilen anpassar sig samtidigt till dussintals olika parametrar: gastryckning, broms, körstil, vägkvalitet. Jag förstår inte hur det fungerar längre.
När jag började arbeta på Amazons moln var det också ett mysterium för mig. Bara detta mysterium är en storleksordning större, eftersom det finns en förare i bilen, och i AWS finns det miljoner av dem. Alla användare styr samtidigt, trycker på gasen och bromsar. Det är fantastiskt att de går dit de vill – det är ett mirakel för mig! Systemet anpassar, skalar och anpassar sig automatiskt efter varje användare så att det verkar för honom som om han är ensam i detta universum.
Magin försvann lite när jag senare kom att jobba som arkitekt på Amazon. Jag såg vilka problem vi står inför, hur vi löser dem och hur vi utvecklar tjänster. Med ökad förståelse för hur systemet fungerar infinner sig mer förtroende för tjänsten. Så jag vill dela med mig av en bild på vad som finns under huven på AWS-molnet.
Vad ska vi prata om
Jag valde ett diversifierat tillvägagångssätt - jag valde ut 4 intressanta tjänster som är värda att prata om.
Serveroptimering. Efemära moln med en fysisk gestaltning: fysiska datacenter där det finns fysiska servrar som brummar, värmer upp och blinkar med ljus.
Serverlösa funktioner (Lambda) är förmodligen den mest skalbara tjänsten i molnet.
Databasskalning. Jag ska berätta om hur vi bygger våra egna skalbara databaser.
Nätverksskalning. Den sista delen där jag kommer att öppna enheten i vårt nätverk. Detta är en underbar sak - varje molnanvändare tror att han är ensam i molnet och inte ser andra hyresgäster alls.
Notera. Den här artikeln kommer att diskutera serveroptimering och databasskalning. Vi kommer att överväga nätverksskalning i nästa artikel. Var finns de serverlösa funktionerna? En separat utskrift publicerades om dem "" Den talar om flera olika skalningsmetoder, och diskuterar i detalj Firecracker-lösningen - en symbios av de bästa egenskaperna hos en virtuell maskin och behållare.
Servrar
Molnet är flyktigt. Men denna flyktiga natur har fortfarande en fysisk förkroppsligande – servrar. Ursprungligen var deras arkitektur klassisk. En standard x86-chipset, nätverkskort, Linux, Xen-hypervisorn som de virtuella maskinerna kördes på.
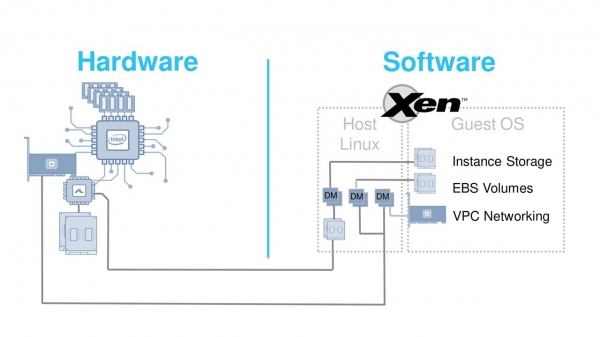
2012 klarade denna arkitektur sina uppgifter ganska bra. Xen är en bra hypervisor, men den har en stor nackdel. Han har fått nog hög overhead för enhetsemulering. När nya, snabbare nätverkskort eller SSD-enheter blir tillgängliga, blir denna omkostnad för hög. Hur ska man hantera detta problem? Vi bestämde oss för att arbeta på två fronter samtidigt - optimera både hårdvara och hypervisor. Uppgiften är mycket allvarlig.
Optimering av hårdvara och hypervisor
Att göra allt på en gång och göra det bra fungerar inte. Vad "bra" var var också oklart initialt.
Vi bestämde oss för att ta ett evolutionärt tillvägagångssätt - vi ändrar en viktig del av arkitekturen och sätter den i produktion.
Vi kliver på varje rake, lyssnar på klagomål och förslag. Sedan ändrar vi en annan komponent. Så, i små steg, ändrar vi radikalt hela arkitekturen baserat på feedback från användare och support.
Förvandlingen började 2013 med det mest komplexa – nätverket. I С3 Exempelvis lades ett speciellt nätverksacceleratorkort till standardnätverkskortet. Den var ansluten bokstavligen med en kort loopback-kabel på frontpanelen. Det är inte vackert, men det syns inte i molnet. Men direkt interaktion med hårdvara förbättrade fundamentalt jitter och nätverksgenomströmning.
Därefter beslutade vi att förbättra tillgången till blockdatalagring EBS - Elastic Block Storage. Det är en kombination av nätverk och lagring. Svårigheten är att medan Network Accelerator-kort fanns på marknaden, fanns det inget alternativ att helt enkelt köpa Storage Accelerator-hårdvara. Så vi vände oss till en startup Annapurna Labs, som utvecklade speciella ASIC-chips åt oss. De gjorde det möjligt för fjärranslutna EBS-volymer att monteras som NVMe-enheter.
I fall C4 vi löste två problem. Den första är att vi implementerade en grund för framtiden med lovande, men ny på den tiden, NVMe-teknik. För det andra avlastade vi den centrala processorn avsevärt genom att överföra behandlingen av förfrågningar till EBS till ett nytt kort. Det blev bra, så nu är Annapurna Labs en del av Amazon.
I november 2017 insåg vi att det var dags att byta själva hypervisorn.
Den nya hypervisorn utvecklades baserat på modifierade KVM-kärnmoduler.
Det gjorde det möjligt att i grunden minska omkostnaderna för enhetsemulering och arbeta direkt med nya ASIC:er. Instanser С5 var de första virtuella maskinerna med en ny hypervisor som kördes under huven. Vi döpte honom Nitro.
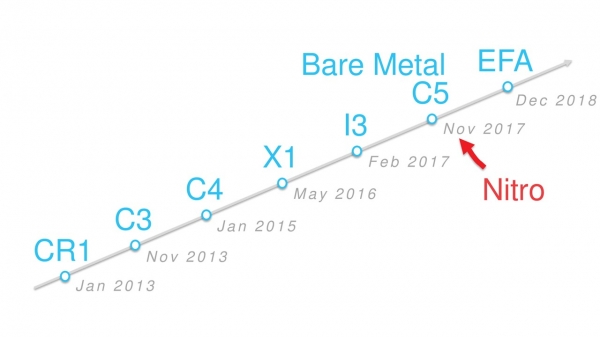 Utveckling av instanser på tidslinjen.
Utveckling av instanser på tidslinjen.
Alla nya typer av virtuella maskiner som har dykt upp sedan november 2017 körs på denna hypervisor. Bare Metal-instanser har ingen hypervisor, men de kallas också Nitro, eftersom de använder specialiserade Nitro-kort.
Under de kommande två åren översteg antalet typer av Nitro-instanser ett par dussin: A1, C5, M5, T3 och andra.

Instanstyper.
Hur moderna Nitro-maskiner fungerar
De har tre huvudkomponenter: Nitro-hypervisorn (diskuterat ovan), säkerhetschippet och Nitro-korten.
Säkerhetschip integreras direkt i moderkortet. Den kontrollerar många viktiga funktioner, som att kontrollera laddningen av värdoperativsystemet.
Nitro kort – Det finns fyra typer av dem. Alla är utvecklade av Annapurna Labs och är baserade på vanliga ASIC:er. En del av deras firmware är också vanligt.
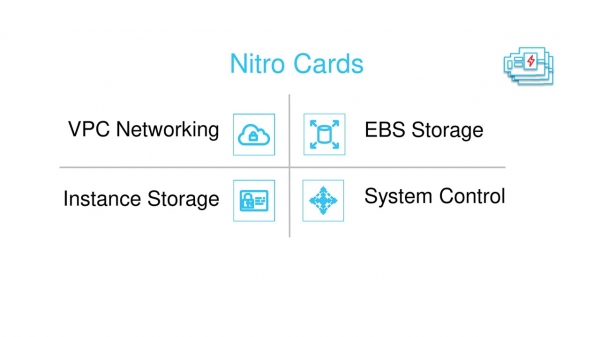
Fyra typer av Nitro-kort.
Ett av korten är designat för att fungera med nätverkVPC. Detta är vad som syns i virtuella maskiner som ett nätverkskort ENA - Elastisk nätverksadapter. Den kapslar också in trafik när den överförs genom ett fysiskt nätverk (vi kommer att prata om detta i den andra delen av artikeln), kontrollerar Security Groups brandvägg och ansvarar för routing och andra nätverkssaker.
Vissa kort fungerar med blocklagring EBS och diskar som är inbyggda i servern. De visas för gästens virtuella maskin som NVMe-adaptrar. De är också ansvariga för datakryptering och diskövervakning.
Systemet med Nitro-kort, hypervisor och säkerhetschip är integrerat i ett SDN-nätverk eller Mjukvarudefinierat nätverk. Ansvarig för att hantera detta nätverk (Control Plane) kontrollkort.
Naturligtvis fortsätter vi att utveckla nya ASIC:er. Till exempel, i slutet av 2018 släppte de Inferentia-chippet, som låter dig arbeta mer effektivt med maskininlärningsuppgifter.

Inferentia Machine Learning Processor-chip.
Skalbar databas
En traditionell databas har en skiktad struktur. För att förenkla avsevärt särskiljs följande nivåer.
- SQL — klient- och förfrågningsansvariga arbetar med det.
- Avsättningar transaktioner – allt är klart här, ACID och allt det där.
- cachelagring, som tillhandahålls av buffertpooler.
- Skogsavverkning — ger arbete med redo-loggar. I MySQL kallas de Bin Logs, i PosgreSQL - Write Ahead Logs (WAL).
- Förvaring – direkt inspelning till disk.
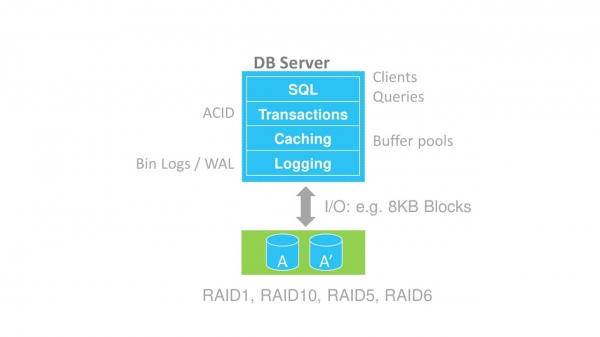
Databasstruktur i lager.
Det finns olika sätt att skala databaser: sharding, Shared Nothing-arkitektur, delade diskar.
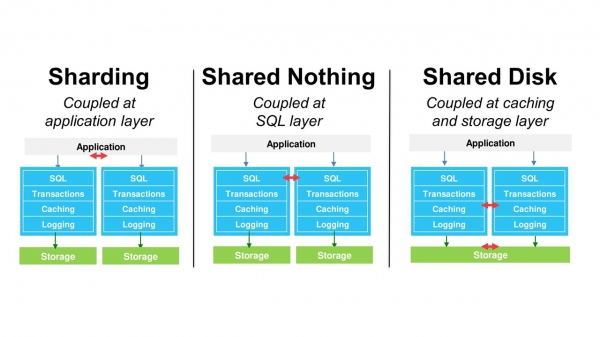
Alla dessa metoder upprätthåller dock samma monolitiska databasstruktur. Detta begränsar skalningen avsevärt. För att lösa detta problem utvecklade vi vår egen databas − Amazon-Aurora. Den är kompatibel med MySQL och PostgreSQL.
Amazon-Aurora
Den huvudsakliga arkitektoniska idén är att separera lagrings- och loggningsnivåerna från huvuddatabasen.
När vi blickar framåt kommer jag att säga att vi också gjorde cachningsnivån oberoende. Arkitekturen upphör att vara en monolit, och vi får ytterligare frihetsgrader i att skala enskilda block.
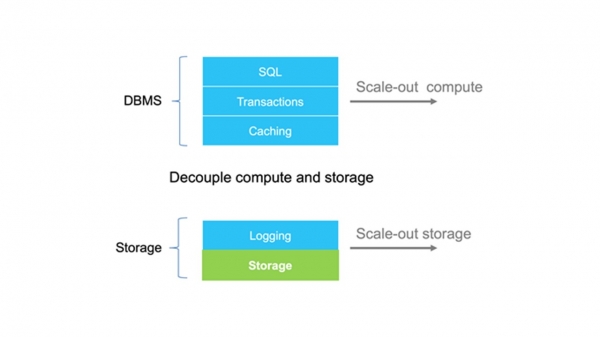
Loggnings- och lagringsnivåerna är separata från databasen.
En traditionell DBMS skriver data till ett lagringssystem i form av block. På Amazon Aurora skapade vi smart lagring som kan tala språk gör om loggar. Inuti förvandlar lagringen loggar till datablock, övervakar deras integritet och säkerhetskopierar automatiskt.
Detta tillvägagångssätt låter dig implementera sådana intressanta saker som kloning. Det fungerar i grunden snabbare och mer ekonomiskt på grund av att det inte kräver att man skapar en fullständig kopia av all data.
Lagringsskiktet är implementerat som ett distribuerat system. Den består av ett mycket stort antal fysiska servrar. Varje redo-logg bearbetas och sparas samtidigt sex knop. Detta säkerställer dataskydd och lastbalansering.
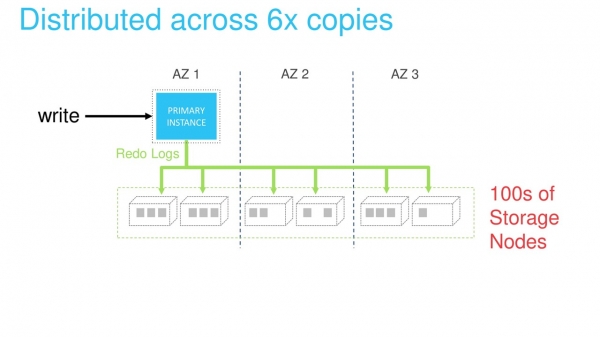
Lässkalning kan uppnås med lämpliga repliker. Distribuerad lagring eliminerar behovet av synkronisering mellan huvuddatabasinstansen, genom vilken vi skriver data, och de återstående replikerna. Uppdaterad data är garanterat tillgänglig för alla repliker.
Det enda problemet är att cachelagra gamla data på läsrepliker. Men detta problem håller på att lösas överföring av alla redo-loggar till repliker över det interna nätverket. Om loggen finns i cachen markeras den som felaktig och skrivs över. Om den inte finns i cachen slängs den helt enkelt.
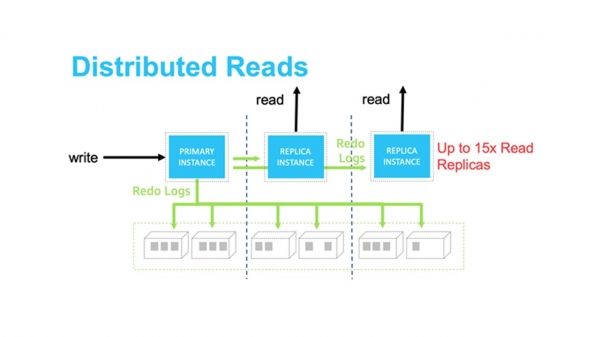
Vi ordnade förvaringen.
Hur man skalar DBMS-nivåer
Här är horisontell skalning mycket svårare. Så låt oss gå nerför stigen klassisk vertikal skalning.
Låt oss anta att vi har en applikation som kommunicerar med DBMS via en masternod.
När vi skalar vertikalt tilldelar vi en ny nod som kommer att ha fler processorer och minne.
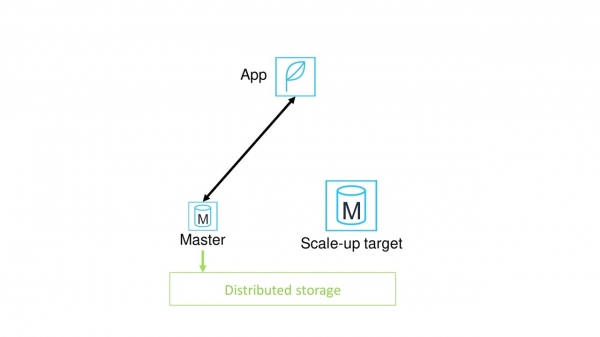
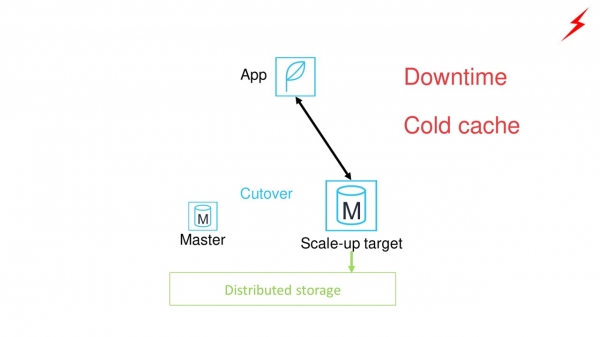
Därefter byter vi applikationen från den gamla huvudnoden till den nya. Problem uppstår.
- Detta kommer att kräva betydande stilleståndstid.
- Den nya huvudnoden kommer att ha kall cache. Databasprestanda kommer att vara maximal först efter att cachen har värmts upp.
Hur kan man förbättra situationen? Ställ in en proxy mellan applikationen och huvudnoden.
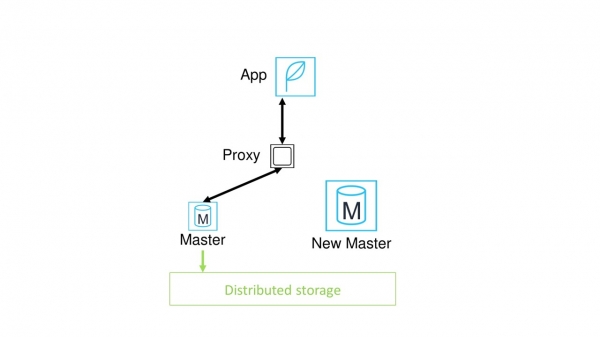
Vad kommer detta att ge oss? Nu behöver inte alla applikationer omdirigeras manuellt till den nya noden. Bytet kan göras under en proxy och är i grunden snabbare.
Det verkar som att problemet är löst. Men nej, vi lider fortfarande av behovet av att värma upp cachen. Dessutom har ett nytt problem dykt upp - nu är proxyn en potentiell punkt för misslyckande.
Slutlig lösning med Amazon Aurora serverlös
Hur löste vi dessa problem?
Lämnade en proxy. Detta är inte en separat instans, utan en hel distribuerad flotta av proxyservrar genom vilka applikationer ansluter till databasen. I händelse av fel kan vilken som helst av noderna bytas ut nästan omedelbart.
Lade till en pool av varma noder i olika storlekar. Därför, om det är nödvändigt att allokera en ny nod av större eller mindre storlek, är den omedelbart tillgänglig. Du behöver inte vänta på att den ska laddas.
Hela skalningsprocessen styrs av ett speciellt övervakningssystem. Övervakning övervakar ständigt tillståndet för den aktuella huvudnoden. Om den till exempel upptäcker att processorbelastningen har nått ett kritiskt värde, meddelar den poolen av varma instanser om behovet av att allokera en ny nod.
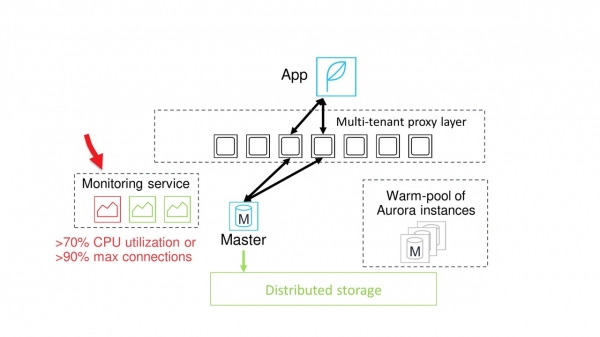
Distribuerade fullmakter, varma instanser och övervakning.
En nod med den kraft som krävs är tillgänglig. Buffertpooler kopieras till den, och systemet börjar vänta på ett säkert ögonblick för att byta.
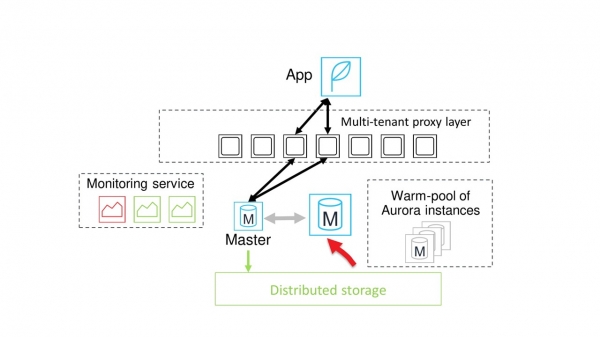
Vanligtvis kommer ögonblicket att byta ganska snabbt. Då avbryts kommunikationen mellan proxyn och den gamla huvudnoden, alla sessioner växlas till den nya noden.
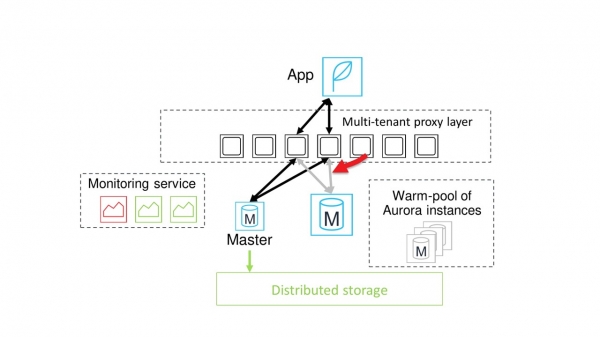
Arbetet med databasen återupptas.
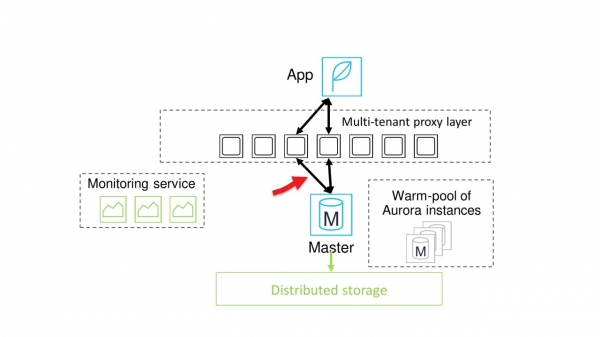
Grafen visar att upphängningen verkligen är mycket kort. Den blå grafen visar belastningen och de röda stegen visar skalningsmomenten. Kortvariga nedgångar i den blå grafen är just den korta fördröjningen.
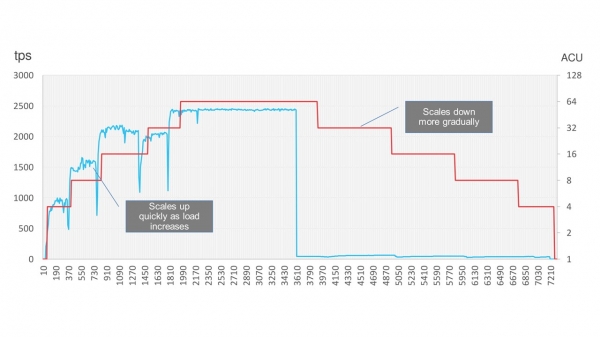
Amazon Aurora låter dig förresten helt spara pengar och stänga av databasen när den inte används, till exempel på helger. Efter att ha stoppat belastningen minskar DB gradvis sin effekt och stängs av under en tid. När lasten kommer tillbaka kommer den att stiga mjukt igen.
I nästa del av berättelsen om Amazon-enheten kommer vi att prata om nätverksskalning. Prenumerera och håll utkik så att du inte missar artikeln.
På Vasily Pantyukhin kommer att ge en rapport "" Vilka designmönster för distribuerade system används av Amazon-utvecklare, vad är orsakerna till tjänstefel, vad är cellbaserad arkitektur, Constant Work, Shuffle Sharding - det kommer att bli intressant. Mindre än en månad kvar till konferensen - . 24 oktober slutlig prishöjning.
Källa: will.com
