

Vi funderade på att skapa ett övervakningssystem när vi bildade produktteamen. Det blev tydligt att vår verksamhet – vår verksamhet – inte passar in i dessa team. Varför är det så?
Saken är den att alla våra team är uppbyggda kring separata informationssystem, mikrotjänster och frontends, så teamen ser inte hela systemets övergripande hälsa. De kanske till exempel inte vet hur en liten del i den djupa backend-miljön påverkar frontend-miljön. Deras intressen är begränsade till de system som deras system är integrerat med. Om teamet och dess tjänst A nästan inte alls är kopplade till tjänst B, då är en sådan tjänst nästan osynlig för teamet.
Vårt team arbetar i sin tur med system som är mycket nära integrerade med varandra: det finns många kopplingar mellan dem, det är en mycket stor infrastruktur. Och webbutikens arbete är beroende av alla dessa system (som vi för övrigt har ett stort antal av).
Så det visar sig att vår avdelning inte tillhör något team, utan är lite separat. I hela den här historien är vår uppgift att på ett komplext sätt förstå hur informationssystem fungerar, deras funktionalitet, integrationer, programvara, nätverk, hårdvara och hur allt detta är kopplat till varandra.
Plattformen som våra webbutiker fungerar på ser ut så här:
- främre
- mellankontoret
- back-office
Hur gärna vi än skulle vilja det är det inte möjligt för alla system att fungera smidigt och felfritt. Problemet ligger återigen i antalet system och integrationer – med ett sådant antal som vårt är vissa incidenter oundvikliga, trots testkvaliteten. Dessutom både inom ett separat system och när det gäller deras integration. Och det är nödvändigt att övervaka hela plattformens tillstånd på ett heltäckande sätt, och inte bara någon separat del av den.
Helst bör övervakningen av hela plattformens hälsa automatiseras. Och vi kom fram till övervakning som en oundviklig del av denna process. Ursprungligen byggdes den endast för frontdelen, medan nätverkare, programvaru- och hårdvaruadministratörer hade och har sina egna lagerbaserade övervakningssystem. Alla dessa personer övervakade övervakningen endast på sin egen nivå, ingen hade heller en heltäckande förståelse.
Om till exempel en virtuell maskin kraschar är det i de flesta fall bara administratören som ansvarar för hårdvaran och den virtuella maskinen som vet om det. I sådana fall såg frontend-teamet själva applikationen kraschen, men de hade ingen data om den virtuella maskinkraschen. Men administratören kan veta vem kunden är och ha en ungefärlig uppfattning om vad som körs på den virtuella maskinen, förutsatt att det är någon form av stort projekt. Han vet troligtvis inte om små projekt. I vilket fall som helst måste administratören gå till ägaren, fråga vad som fanns på den här maskinen, vad som behöver återställas och vad som behöver ändras. Och om något riktigt allvarligt gick sönder, så gick det i cirklar – eftersom ingen såg systemet som helhet.
I slutändan påverkar sådana olikartade berättelser hela frontend-systemet, användarna och vår kärnverksamhet – onlineförsäljning. Eftersom vi inte ingår i team, utan är engagerade i driften av alla e-handelsapplikationer i webbutiken, tog vi oss an uppgiften att skapa ett omfattande övervakningssystem för e-handelsplattformen.
Systemstruktur och stack
Vi började med att identifiera flera övervakningslager för våra system, över vilka vi skulle behöva samla in mätvärden. Och allt detta behövde kombineras, vilket vi gjorde i det första steget. Nu, i det här skedet, slutför vi en samling av mätvärden av högsta kvalitet över alla våra lager för att bygga en korrelation och förstå hur system påverkar varandra.
Bristen på omfattande övervakning i de inledande skedena av applikationslanseringen (eftersom vi började bygga den när de flesta systemen var i drift) ledde till att vi hade en betydande teknisk skuld i att sätta upp övervakningen av hela plattformen. Vi hade inte råd att fokusera på att sätta upp övervakningen av ett enskilt informationssystem och utarbeta övervakningen för det i detalj, eftersom de andra systemen skulle förbli utan övervakning under en tid. För att lösa detta problem definierade vi en lista över de mest nödvändiga mätvärdena för att bedöma informationssystemets tillstånd i lager och började implementera den.
Så bestämde de sig för att äta elefanten i bitar.
Vårt system består av:
- hårdvara;
- operativsystem;
- programvara;
- UI-delar i övervakningsapplikationen;
- affärsmått;
- integrationsapplikationer;
- informationssäkerhet;
- nätverk;
- trafikbalanserare.
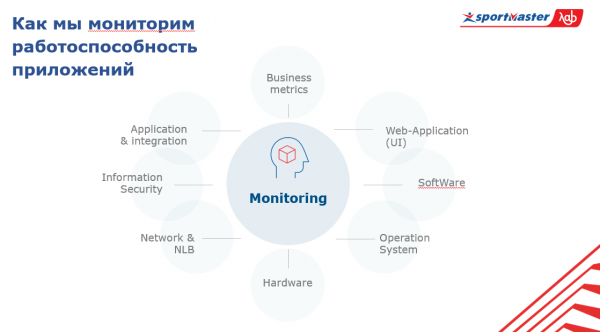
I centrum för detta system står övervakningen av sig själv. För att förstå hela systemets tillstånd i allmänhet behöver man veta vad som händer med applikationer på alla dessa lager och i kontexten av hela uppsättningen applikationer.
Så, angående stacken.
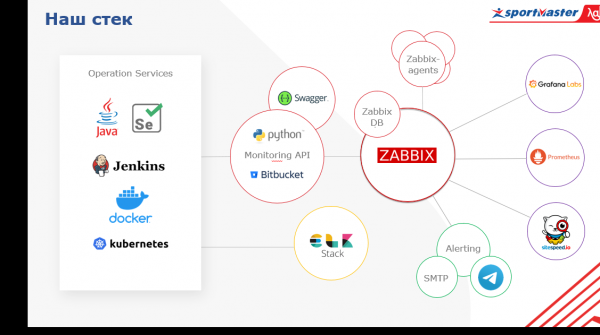
Vi använder programvara med öppen källkod. I centrum har vi Zabbix, som vi främst använder som ett varningssystem. Alla vet att det är idealiskt för infrastrukturövervakning. Vad menas här? Just de lågnivåmått som varje företag som underhåller sitt eget datacenter har (och Sportmaster har sina egna datacenter) - servertemperatur, minnesstatus, raid, mätvärden för nätverksenheter.
Vi integrerade Zabbix med Telegram Messenger och Microsoft Teams, som används aktivt i team. Zabbix täcker själva nätverket, hårdvara och delvis mjukvara, men detta är inte ett universalmedel. Vi berikar denna data från vissa andra tjänster. Till exempel, på hårdvarunivå ansluter vi direkt via API till vårt virtualiseringssystem och samlar in data.
Vad mer. Förutom Zabbix använder vi Prometheus, vilket gör att vi kan övervaka mätvärden i en dynamisk applikationsmiljö. Det vill säga att vi kan ta emot applikationsmätvärden via en HTTP-slutpunkt och inte oroa oss för vilka mätvärden vi ska ladda upp till den och vilka inte. Baserat på dessa data kan vi bearbeta analytiska frågor.
Datakällor för andra lager, såsom affärsmått, är indelade i tre komponenter.
För det första är detta externa affärssystem, Google Analytics, vi samlar in mätvärden från loggar. Från dem får vi data om aktiva användare, konverteringar och allt annat som rör verksamheten. För det andra är detta ett UI-övervakningssystem. Det bör diskuteras mer i detalj.
Vi började en gång med manuell testning och det utvecklades till automatiserade tester av funktionalitet och integrationer. Utifrån det skapade vi övervakning, lämnade bara huvudfunktionaliteten och knöt det till markörer som är maximalt stabila och inte ändras ofta över tid.
Den nya teamstrukturen innebär att all applikationsaktivitet är stängd för produktteamen, så vi slutade med ren testning. Istället skapade vi UI-övervakning från tester, skrivna i Java, Selenium och Jenkins (används som ett system för uppstart och rapportgenerering).
Vi hade många tester, men till slut bestämde vi oss för att gå huvudvägen, de övergripande mätvärdena. Och om vi har många specifika tester kommer det att vara svårt att upprätthålla datans relevans. Varje efterföljande release kommer att orsaka avsevärda problem för hela systemet, och vi kommer bara att fixa det. Därför har vi bundit oss till mycket grundläggande saker som sällan förändras, och övervakar bara dem.
Slutligen, för det tredje, är datakällan ett centraliserat loggsystem. Vi använder Elastic Stack för loggar, och sedan kan vi hämta denna data till vårt övervakningssystem för affärsmätningar. Utöver allt detta fungerar vår egen övervaknings-API-tjänst, skriven i Python, som frågar efter tjänster via API och tar data från dem till Zabbix.
En annan viktig egenskap hos övervakning är visualisering. Vi bygger den med Grafana som grund. Bland andra visualiseringssystem utmärker den sig genom att du kan visualisera mätvärden från olika datakällor på instrumentpanelen. Vi kan samla in övergripande mätvärden för en webbutik, till exempel antalet beställningar som gjorts under den senaste timmen, från DBMS, prestandamätvärden för operativsystemet som webbutiken körs på, från Zabbix, och mätvärden för instanserna av denna applikation - från Prometheus. Och allt detta kommer att finnas på en instrumentpanel. Tydlig och lättillgänglig.
Jag vill påpeka angående säkerheten – vi håller just nu på att färdigställa systemet, som vi sedan kommer att integrera med det globala övervakningssystemet. Enligt min mening är de största problemen som e-handeln står inför inom informationssäkerhet relaterade till bottar, parsers och brute force. Detta måste övervakas, eftersom allt detta kan påverka både driften av våra applikationer och vårt rykte ur ett affärsperspektiv kritiskt. Och vi lyckas med dessa uppgifter med den valda stacken.
En annan viktig punkt är att applikationsnivån samlas in av Prometheus. Den är också integrerad med Zabbix. Och vi har även sitespeed, en tjänst som låter oss se parametrar som vår sidladdningshastighet, flaskhalsar, sidrendering, skriptladdning etc., den är också integrerad via API. Så våra mätvärden samlas in i Zabbix, och följaktligen larmar vi också därifrån. Alla larm skickas för närvarande till de huvudsakliga sändningsmetoderna (för närvarande är dessa e-post och telegram, vi har nyligen även anslutit MS Teams). Planerna är att uppgradera larmfunktionen till ett sådant tillstånd att smarta bots fungerar som en tjänst och tillhandahåller övervakningsinformation till alla intresserade produktteam.
För oss är mätvärden viktiga inte bara för enskilda informationssystem, utan även för generella mätvärden över hela den infrastruktur som applikationer använder: kluster fysiska servrar, som kör virtuella maskiner, trafikbalanserare, nätverksbelastningsbalanserare, själva nätverket och bandbreddsutnyttjande. Plus mätvärden för våra egna datacenter (vi har flera av dem, och infrastrukturen är ganska stor).
Fördelarna med vårt övervakningssystem är att vi med dess hjälp kan se prestandaläget för alla system, vi kan bedöma deras påverkan på varandra och på gemensamma resurser. Och i slutändan låter det oss planera resurser, vilket också är vårt ansvarsområde. Vi hanterar serverresurser - en pool inom e-handel, vi driftsätter och avvecklar ny utrustning, köper in ny utrustning, genomför en granskning av resursutnyttjandet etc. Varje år planerar team nya projekt, utvecklar sina system, och det är viktigt för oss att förse dem med resurser.
Och med hjälp av mätvärden ser vi tendensen för resursförbrukning i våra informationssystem. Och redan utifrån dem kan vi planera något. På virtualiseringsnivå samlar vi in data och ser information om den tillgängliga mängden resurser i datacenters kontext. Och redan inuti datacentret kan vi se både utnyttjande och faktisk distribution, förbrukning av resurser. Dessutom både med fristående servrar, och virtuella maskiner och kluster av fysiska servrar, på vilka alla dessa virtuella maskiner snurrar snabbt.
Utsikter
Nu har vi kärnan i systemet klar som helhet, men det finns fortfarande tillräckligt med punkter som behöver arbetas med. Som ett minimum är detta ett informationssäkerhetslager, men det är också viktigt att komma åt nätverket, utveckla varningar och lösa korrelationsproblemet. Vi har många lager och system, och varje lager har många fler mätvärden. Det visar sig vara en matrjosjka i samma grad som en matrjosjka.
Vår uppgift är att i slutändan göra rätt varningar. Till exempel, om det fanns ett problem med hårdvaran, återigen med en virtuell maskin, och det fanns en viktig applikation, och tjänsten inte säkerhetskopierades på något sätt. Vi får veta att den virtuella maskinen har dött. Då kommer affärsstatistik att varna: användare har försvunnit någonstans, det finns ingen konvertering, användargränssnittet i gränssnittet är inte tillgängligt, programvara och tjänster har också dött.
I det här scenariot kommer vi att få spam från varningar, och detta passar inte in i formatet för ett korrekt övervakningssystem. Frågan om korrelation uppstår. Därför bör vårt övervakningssystem helst säga: "Grabbar, er fysiska maskin dog, och med den den här applikationen och dessa mätvärden", med hjälp av en varning istället för att ursinnigt bombardera oss med hundratals varningar. Det bör rapportera det viktigaste - orsaken, vilket bidrar till att problemet snabbt kan lösas på grund av dess lokalisering.
Vårt system för aviseringar och larmhantering är uppbyggt kring en dygnet runt-öppen hotline. Alla larm som anses vara ett måste och som ingår i checklistan överförs dit. Varje larm måste ha en beskrivning: vad som hände, vad det faktiskt betyder, vad det påverkar. Och även en länk till instrumentpanelen och instruktioner om vad man ska göra i detta fall.
Det handlar om kraven för att skapa en varning. Situationen kan sedan utvecklas i två riktningar – antingen finns det ett problem som måste lösas, eller så finns det ett fel i övervakningssystemet. Men i vilket fall som helst måste man gå och lista ut det.
I genomsnitt får vi nu ungefär hundra varningar per dag, med tanke på att varningskorrelationen ännu inte är korrekt konfigurerad. Och om vi behöver utföra tekniskt arbete och vi tvingar bort något, ökar deras antal flera gånger.
Förutom att övervaka de system vi driver och samla in mätvärden som vi anser vara viktiga, tillåter övervakningssystemet oss att samla in data för produktteam. De kan påverka sammansättningen av mätvärden inom de informationssystem vi övervakar.
Vår kollega kan komma och be om att lägga till några mätvärden som är användbara för både oss och teamet. Eller, till exempel, kanske teamet inte har tillräckligt med de grundläggande mätvärden som vi har, de behöver spåra några specifikt. I Grafana skapar vi ett utrymme för varje team och ger administratörsrättigheter. Om teamet behöver dashboards och de själva inte kan/vet hur man gör detta, hjälper vi dem också.
Eftersom vi står utanför flödet av att skapa teamvärden, deras releaser och planering, kommer vi gradvis till slutsatsen att releaserna av alla system är sömlösa och kan rullas ut dagligen utan att samordna med oss. Och det är viktigt för oss att spåra dessa releaser, eftersom de potentiellt kan påverka applikationens drift och orsaka att något går sönder, och detta är avgörande. För att hantera releaser använder vi Bamboo, varifrån vi tar emot data via API och kan se vilka releaser som släpptes i vilka informationssystem och deras status. Och viktigast av allt - vid vilken tidpunkt. Vi sätter releasemarkörer på de viktigaste kritiska mätvärdena, vilket är visuellt mycket indikativt vid problem.
På så sätt kan vi se sambandet mellan nya utgåvor och framväxande problem. Huvudtanken är att förstå hur systemet fungerar på alla nivåer, snabbt lokalisera problemet och åtgärda det lika snabbt. Det händer trots allt ofta att mest tid inte läggs på att lösa problemet, utan på att hitta orsaken.
Och i den här riktningen vill vi i framtiden fokusera på proaktivitet. Helst vill vi veta om ett annalkande problem i förväg, och inte i efterhand, för att kunna förebygga det och inte lösa det. Ibland finns det falska positiva resultat i övervakningssystemet, både på grund av mänskliga fel och på grund av förändringar i applikationen. Och vi arbetar med detta, felsöker och försöker varna användare som använder det hos oss innan några manipulationer med övervakningssystemet, eller för att utföra dessa aktiviteter under det tekniska fönstret.
Så, systemet har varit igång sedan tidig vår ... och det visar en rejäl vinst. Naturligtvis är detta inte den slutgiltiga versionen, vi kommer att implementera många fler användbara saker. Men just nu, med ett så stort antal integrationer och applikationer, kan man verkligen inte klara sig utan övervakningsautomation.
Om du också övervakar stora projekt med ett betydande antal integrationer, skriv i kommentarerna vilken mirakellösning du hittade för detta.
Källa: will.com
