

Vad skulle kunna tvinga ett så stort företag som Lamoda, med en strömlinjeformad process och dussintals sammankopplade tjänster, att väsentligt ändra sitt synsätt? Motivationen kan vara helt annorlunda: från lagstiftning till önskan att experimentera som är inneboende hos alla programmerare.
Men det betyder inte att du inte kan räkna med ytterligare förmåner. Sergey Zaika kommer att berätta exakt vad du kan vinna om du implementerar det händelsedrivna API:et på Kafka (). Det kommer definitivt också att pratas om stora skott och intressanta upptäckter – experimentet klarar sig inte utan dem.
Friskrivningsklausul: Den här artikeln är baserad på material från ett möte som Sergey höll i november 2018 på HighLoad++. Lamodas liveupplevelse av att arbeta med Kafka lockade lyssnare inte mindre än andra reportage på schemat. Vi tycker att detta är ett utmärkt exempel på att du alltid kan och bör hitta likasinnade, och arrangörerna av HighLoad++ kommer att fortsätta att försöka skapa en atmosfär som främjar detta.
Om processen
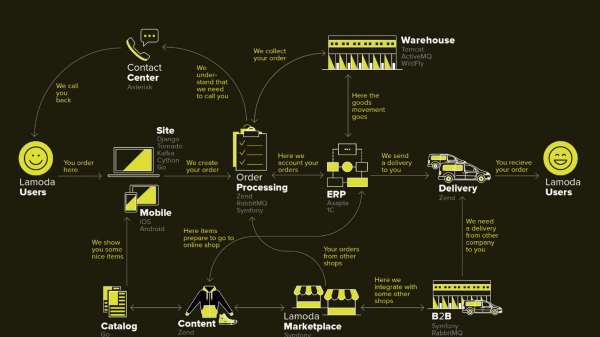
Lamoda är en stor e-handelsplattform som har ett eget kontaktcenter, leveranstjänst (och många affiliates), en fotostudio, ett enormt lager och allt detta körs på sin egen mjukvara. Det finns dussintals betalningsmetoder, b2b-partners som kan använda vissa eller alla av dessa tjänster och vill veta uppdaterad information om sina produkter. Dessutom verkar Lamoda i tre länder förutom Ryska federationen och där är allt lite annorlunda. Totalt finns det förmodligen mer än hundra sätt att konfigurera en ny order, som måste behandlas på sitt eget sätt. Allt detta fungerar med hjälp av dussintals tjänster som ibland kommunicerar på icke-uppenbara sätt. Det finns även ett centralt system vars huvudansvar är orderstatus. Vi kallar henne BIR, jag jobbar med henne.
Återbetalningsverktyg med händelsestyrt API
Ordet händelsestyrt är ganska hackigt, lite längre kommer vi att definiera mer i detalj vad som menas med detta. Jag börjar med sammanhanget där vi bestämde oss för att prova den händelsedrivna API-metoden i Kafka.

I vilken butik som helst, förutom beställningar som kunderna betalar för, finns det tillfällen då butiken är skyldig att returnera pengar för att produkten inte passade kunden. Detta är en relativt kort process: vi klargör informationen vid behov och överför pengarna.
Men returen blev mer komplicerad på grund av förändringar i lagstiftningen och vi var tvungna att implementera en separat mikrotjänst för den.

Vår motivation:
- Lag FZ-54 – kort sagt, lagen kräver rapportering till skattekontoret om varje monetär transaktion, vare sig det är en retur eller ett kvitto, inom en ganska kort SLA på några minuter. Vi som e-handelsföretag bedriver ganska mycket verksamhet. Rent tekniskt innebär detta nytt ansvar (och därmed en ny tjänst) och förbättringar i alla inblandade system.
- BIR split är ett internt projekt inom företaget för att befria BOB från ett stort antal icke-kärnansvar och minska dess övergripande komplexitet.
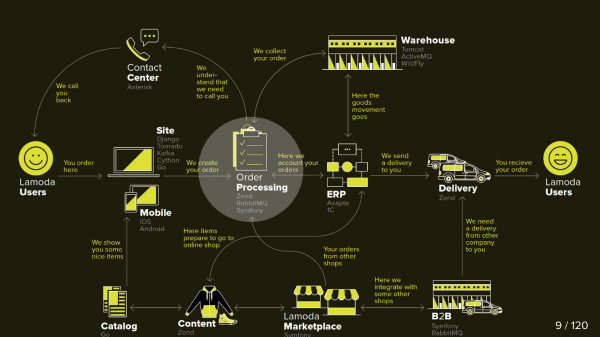
Detta diagram visar de viktigaste Lamoda-systemen. Nu är de flesta fler en konstellation av 5-10 mikrotjänster runt en krympande monolit. De växer långsamt, men vi försöker göra dem mindre, för att distribuera fragmentet som valts i mitten är skrämmande - vi kan inte tillåta att det faller. Vi tvingas reservera alla byten (pilar) och ta hänsyn till att någon av dem kan visa sig vara otillgänglig.
BOB har också ganska många växlar: betalningssystem, leveranssystem, aviseringssystem m.m.
Tekniskt sett är BIR:
- ~150k rader kod + ~100k rader med tester;
- php7.2 + Zend 1 & Symfony Components 3;
- >100 API:er & ~50 utgående integrationer;
- 4 länder med egen affärslogik.
Att distribuera BOB är dyrt och smärtsamt, mängden kod och problem som det löser är sådan att ingen kan lägga allt i huvudet. I allmänhet finns det många skäl att förenkla det.
Returprocess
Inledningsvis är två system involverade i processen: BIR och Payment. Nu dyker två till:
- Fiskaliseringstjänst, som ska ta hand om problem med skattereglering och kommunikation med externa tjänster.
- Refund Tool, som helt enkelt innehåller nya utbyten för att inte blåsa upp BIR.
Nu ser processen ut så här:
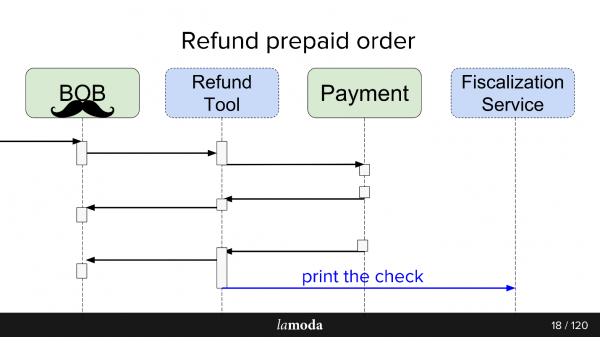
- BIR får en begäran om återbetalning.
- BIR pratar om detta återbetalningsverktyg.
- Återbetalningsverktyget säger till Betalning: "Gå tillbaka pengarna."
- Betalning returnerar pengarna.
- Återbetalningsverktyget och BOB synkroniserar status med varandra, för för närvarande behöver de båda det. Vi är ännu inte redo att helt byta till Återbetalningsverktyget, eftersom BOB har ett användargränssnitt, rapporter för redovisning och i allmänhet mycket data som inte kan överföras så enkelt. Du måste sitta på två stolar.
- Begäran om skattereglering försvinner.
Som ett resultat gjorde vi en slags evenemangsbuss på Kafka - evenemangsbuss, på vilken allt började. Hurra, nu har vi en enda punkt av misslyckande (sarkasm).
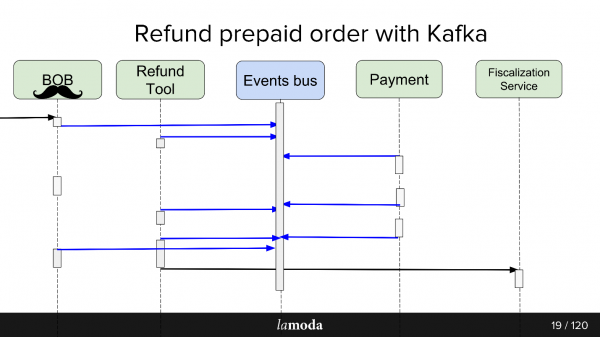
För- och nackdelarna är ganska uppenbara. Vi gjorde en buss, vilket gör att nu är all service beroende av den. Detta förenklar designen, men introducerar en enda felpunkt i systemet. Kafka kommer att krascha, processen kommer att stoppa.
Vad är ett händelsestyrt API
Ett bra svar på denna fråga finns i rapporten av Martin Fowler (GOTO 2017) .
Kortfattat vad vi gjorde:
- Avsluta alla asynkrona växlar via lagring av händelser. Istället för att informera alla intresserade konsumenter om en statusändring över nätverket, skriver vi ett event om en statusändring till en centraliserad lagring, och konsumenter som är intresserade av ämnet läser allt som framgår därifrån.
- Händelsen i det här fallet är ett meddelande (anmälningar) att något har förändrats någonstans. Till exempel har orderstatusen ändrats. En konsument som är intresserad av vissa uppgifter som följer med statusändringen och som inte ingår i anmälan kan själv ta reda på dess status.
- Det maximala alternativet är fullfjädrad event sourcing, statlig överföring, i vilket fall innehåller all information som behövs för bearbetning: varifrån den kom och vilken status den gick till, exakt hur data ändrades etc. Frågan är bara genomförbarheten och mängden information som du har råd att lagra.
Som en del av lanseringen av återbetalningsverktyget använde vi det tredje alternativet. Denna förenklade händelsebearbetning eftersom det inte fanns något behov av att extrahera detaljerad information, plus det eliminerade scenariot där varje ny händelse genererar en skur av klargörande få-förfrågningar från konsumenter.
Återbetalningsverktygstjänst inte laddad, så Kafka är mer en smak av pennan där än en nödvändighet. Jag tror inte att om återbetalningstjänsten blev ett högbelastningsprojekt skulle företagen vara nöjda.
Asynkront utbyte SOM ÄR
För asynkrona utbyten använder PHP-avdelningen vanligtvis RabbitMQ. Vi samlade in uppgifterna för begäran, satte dem i kö och konsumenten av samma tjänst läste den och skickade den (eller skickade den inte). För själva API:et använder Lamoda aktivt Swagger. Vi designar ett API, beskriver det i Swagger och genererar klient- och serverkod. Vi använder också en något förbättrad JSON RPC 2.0.
På vissa ställen används ESB-bussar, vissa lever på activeMQ, men i allmänhet, RabbitMQ - standard.
Async exchange TO BE
Vid utformning av utbyte via evenemangsbuss kan en analogi spåras. Vi beskriver på liknande sätt framtida datautbyte genom händelsestrukturbeskrivningar. Yaml-formatet, vi fick göra kodgenereringen själva, generatorn skapar DTO:er enligt specifikationen och lär klienter och servrar att arbeta med dem. Generation går in på två språk - golang och php. Detta hjälper till att hålla biblioteken konsekventa. Generatorn är skriven i golang, varför den fick namnet gogi.
Event-sourcing på Kafka är en typisk sak. Det finns en lösning från den huvudsakliga företagsversionen av Kafka Confluent , en lösning från våra domänbröder Zalando. Vår motivation att börja med vanilj Kafka - detta innebär att lämna lösningen fri tills vi slutligen bestämmer oss för om vi ska använda den överallt, och även lämna oss själva utrymme för manöver och förbättringar: vi vill ha stöd för våra JSON RPC 2.0, generatorer för två språk och låt oss se vad mer.
Det är ironiskt att även i ett så lyckligt fall, när det finns en ungefär liknande verksamhet, Zalando, som gjorde en ungefär liknande lösning, kan vi inte använda den effektivt.
Det arkitektoniska mönstret vid lanseringen är följande: vi läser direkt från Kafka, men skriver bara genom event-bus. Det finns mycket klart att läsa i Kafka: mäklare, balanserare, och det är mer eller mindre redo för horisontell skalning, det här ville jag behålla. Vi ville slutföra inspelningen genom en Gateway aka Events-bus, och här är varför.
Event-buss
Eller en eventbuss. Detta är helt enkelt en tillståndslös http-gateway, som tar på sig flera viktiga roller:
- Producerar validering — vi kontrollerar att evenemangen uppfyller våra specifikationer.
- Event master system, det vill säga detta är det huvudsakliga och enda systemet i företaget som svarar på frågan om vilka händelser med vilka strukturer som anses giltiga. Validering involverar helt enkelt datatyper och uppräkningar för att strikt specificera innehåll.
- Hash funktion för sönderdelning - Kafkas meddelandestruktur är nyckel-värde och med hjälp av hash av nyckel beräknas det var den ska placeras.
Varför
Vi arbetar i ett stort företag med en strömlinjeformad process. Varför ändra något? Det här är ett experiment, och vi förväntar oss att skörda flera fördelar.
1:n+1 utbyten (en till många)
Kafka gör det väldigt enkelt att koppla nya konsumenter till API:et.
Låt oss säga att du har en katalog som du behöver hålla uppdaterad i flera system samtidigt (och i några nya). Tidigare uppfann vi ett paket som implementerade set-API, och huvudsystemet informerades om konsumentadresser. Nu skickar mastersystemet uppdateringar till ämnet, och alla som är intresserade läser det. Ett nytt system har dykt upp - vi registrerade det för ämnet. Ja, även bunt, men enklare.
När det gäller återbetalningsverktyget, som är en del av BIR, är det bekvämt för oss att hålla dem synkroniserade genom Kafka. Betalning säger att pengarna returnerades: BIR, RT fick reda på detta, ändrade deras status, Fiscalization Service fick reda på detta och utfärdade en check.
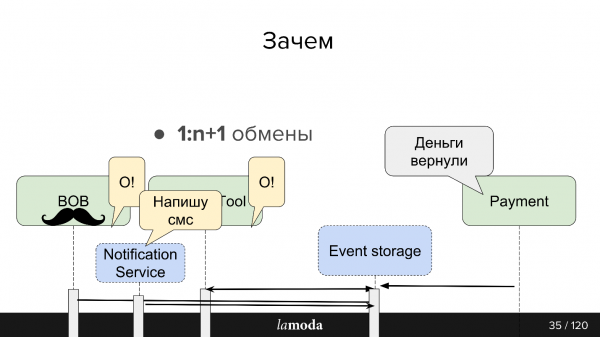
Vi har planer på att skapa en enhetlig aviseringstjänst som skulle meddela kunden om nyheter angående hans beställning/returer. Nu är detta ansvar fördelat mellan systemen. Det kommer att räcka för oss att lära aviseringstjänsten att fånga relevant information från Kafka och svara på den (och inaktivera dessa meddelanden i andra system). Inga nya direktbyten kommer att krävas.
Datadriven vård
Information mellan system blir transparent - oavsett vilket "jävla företag" du har och oavsett hur fyllig din eftersläpning är. Lamoda har en Data Analytics-avdelning som samlar in data från system och sätter den i en återanvändbar form, både för företag och för intelligenta system. Kafka låter dig snabbt ge dem mycket data och hålla informationsflödet uppdaterat.
Replikeringslogg
Meddelanden försvinner inte efter att ha lästs, som i RabbitMQ. När en händelse innehåller tillräckligt med information för bearbetning har vi en historik över de senaste ändringarna av objektet och, om så önskas, möjligheten att tillämpa dessa ändringar.
Lagringsperioden för replikeringsloggen beror på intensiteten av att skriva till detta ämne; Kafka låter dig flexibelt ställa in gränser för lagringstid och datavolym. För intensiva ämnen är det viktigt att alla konsumenter hinner läsa informationen innan den försvinner, även vid kortvarig inoperabilitet. Det går oftast att lagra data för enheter av dagar, vilket är tillräckligt för stöd.
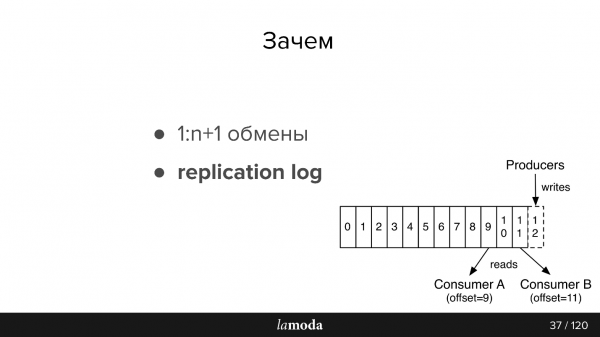
Därefter en liten återberättelse av dokumentationen, för de som inte är bekanta med Kafka (bilden är också från dokumentationen)
AMQP har köer: vi skriver meddelanden till en kö för konsumenten. Vanligtvis behandlas en kö av ett system med samma affärslogik. Om du behöver meddela flera system kan du lära applikationen att skriva till flera köer eller konfigurera utbyte med fanout-mekanismen, som klonar dem själv.
Kafka har en liknande abstraktion ämne, där du skriver meddelanden, men de försvinner inte efter läsning. Som standard, när du ansluter till Kafka, får du alla meddelanden och har möjlighet att spara där du slutade. Det vill säga att du läser sekventiellt, du får inte markera meddelandet som läst, utan spara id från vilket du sedan kan fortsätta läsa. Id:t du slog dig på kallas offset, och mekanismen är commit offset.
Följaktligen kan olika logik implementeras. Till exempel har vi BIR i 4 fall för olika länder - Lamoda är i Ryssland, Kazakstan, Ukraina, Vitryssland. Eftersom de distribueras separat har de lite olika konfigurationer och sin egen affärslogik. Vi anger i meddelandet vilket land det avser. Varje BOB-konsument i varje land läser med olika groupId, och om meddelandet inte gäller dem hoppar de över det, d.v.s. ger omedelbart offset +1. Om samma ämne läses av vår betalningstjänst gör det det med en separat grupp, och därför skärs inte förskjutningar.
Eventkrav:
- Datafullständighet. Jag skulle vilja att evenemanget har tillräckligt med data så att det kan behandlas.
- Integritet. Vi delegerar till Events-bus verifieringen att händelsen är konsekvent och att den kan behandla den.
- Ordningen är viktig. Vid ett återvändande tvingas vi arbeta med historien. Med aviseringar är beställningen inte viktig, om det är homogena aviseringar blir mejlen densamma oavsett vilken beställning som kom först. Vid återbetalning finns en tydlig process, om vi ändrar beställningen uppstår undantag, återbetalningen skapas eller behandlas inte – vi hamnar i en annan status.
- Konsistens. Vi har en butik och nu skapar vi event istället för ett API. Vi behöver ett sätt att snabbt och billigt överföra information om nya evenemang och ändringar av befintliga till våra tjänster. Detta uppnås genom en gemensam specifikation i ett separat git-förråd och kodgeneratorer. Därför samordnas klienter och servrar i olika tjänster.
Kafka i Lamoda
Vi har tre Kafka-installationer:
- Loggar;
- FoU;
- Event-buss.
Idag talar vi bara om den sista punkten. På event-bus har vi inte särskilt stora installationer - 3 mäklare (servrar) och endast 27 ämnen. Som regel är ett ämne en process. Men detta är en subtil punkt, och vi kommer att beröra den nu.
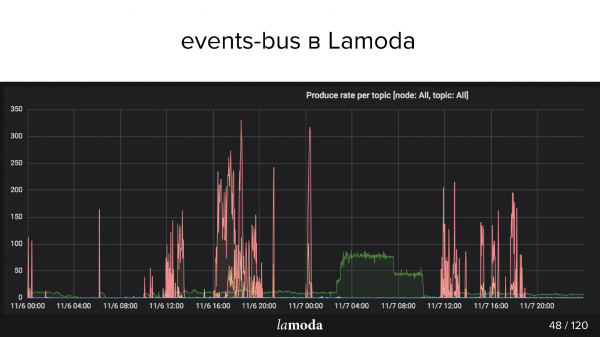
Ovan är rps-grafen. Återbetalningsprocessen är markerad med en turkos linje (ja, den på X-axeln), och den rosa linjen är uppdateringsprocessen för innehåll.
Lamoda-katalogen innehåller miljontals produkter och uppgifterna uppdateras hela tiden. Vissa kollektioner går ur mode, nya släpps för att ersätta dem och nya modeller dyker ständigt upp i katalogen. Vi försöker förutse vad som kommer att vara intressant för våra kunder imorgon, så vi köper hela tiden nya saker, fotograferar dem och uppdaterar montern.
Rosa toppar är produktuppdateringar, det vill säga förändringar i produkter. Det kan ses att killarna tog bilder, tog bilder och så igen! — laddade ett paket med händelser.
Lamoda Events användningsfall
Vi använder den konstruerade arkitekturen för följande operationer:
- Returstatusspårning: uppmaning och statusspårning från alla inblandade system. Betalning, status, fiskalisering, aviseringar. Här testade vi tillvägagångssättet, gjorde verktyg, samlade alla buggar, skrev dokumentation och berättade för våra kollegor hur de skulle använda det.
- Uppdatering av produktkort: konfiguration, metadata, egenskaper. Ett system läser (vilket visas) och flera skriver.
- Mejla, push och sms: beställningen har hämtats, beställningen har anlänt, returen har accepterats, etc., det finns många av dem.
- Lager, lagerförnyelse — kvantitativ uppdatering av artiklar, bara siffror: ankomst till lagret, retur. Det är nödvändigt att alla system som är kopplade till att reservera varor fungerar med de senaste uppgifterna. För närvarande är aktieuppdateringssystemet ganska komplicerat; Kafka kommer att förenkla det.
- Dataanalys (FoU-avdelningen), ML-verktyg, analys, statistik. Vi vill att information ska vara transparent – Kafka lämpar sig väl för detta.
Nu den mer intressanta delen om de stora gupp och intressanta upptäckter som har inträffat under de senaste sex månaderna.
Designproblem
Låt oss säga att vi vill göra en ny sak – till exempel överföra hela leveransprocessen till Kafka. Nu är en del av processen implementerad i Orderbehandling i BIR. Det finns en statusmodell bakom överföringen av en beställning till leveranstjänsten, flyttning till ett mellanlager och så vidare. Det finns en hel monolit, till och med två, plus ett gäng API:er dedikerade till leverans. De vet mycket mer om leverans.
Dessa verkar vara liknande områden, men orderhanteringen i BIR och fraktsystemet har olika status. Till exempel skickar vissa budtjänster inte mellanstatus, utan bara de sista: "levererat" eller "förlorat". Andra rapporterar tvärtom mycket detaljerat om varurörelser. Alla har sina egna valideringsregler: för vissa är e-postmeddelandet giltigt, vilket betyder att det kommer att behandlas; för andra är det inte giltigt, men beställningen kommer fortfarande att behandlas eftersom det finns ett telefonnummer för kontakt, och någon kommer att säga att en sådan beställning inte kommer att behandlas alls.
Dataström
I Kafkas fall uppstår frågan om att organisera dataflödet. Denna uppgift innebär att välja en strategi baserad på flera punkter; låt oss gå igenom dem alla.
I ett ämne eller i olika?
Vi har en händelsespecifikation. I BOB skriver vi att en sådan och en sådan beställning måste levereras, och anger: beställningsnumret, dess sammansättning, några SKU:er och streckkoder osv. När varorna kommer till lagret kommer leveransen att kunna ta emot status, tidsstämplar och allt som behövs. Men då vill vi få uppdateringar om denna data i BIR. Vi har en omvänd process för att ta emot data från leverans. Är detta samma händelse? Eller är detta ett separat utbyte som förtjänar ett eget ämne?
Troligtvis kommer de att vara väldigt lika, och frestelsen att skapa ett ämne är inte ogrundad, eftersom ett separat ämne betyder separata konsumenter, separata konfigurationer, en separat generation av allt detta. Men inte ett faktum.
Nytt fält eller nytt evenemang?
Men om du använder samma händelser uppstår ett annat problem. Till exempel kan inte alla leveranssystem generera den typ av DTO som BOB kan generera. Vi skickar id:t till dem, men de sparar det inte eftersom de inte behöver det, och ur utgångspunkten för att starta evenemangsbussprocessen är detta fält obligatoriskt.
Om vi inför en regel för händelsebuss att detta fält är obligatoriskt, så tvingas vi sätta ytterligare valideringsregler i BOB eller i starthändelsehanteraren. Validering börjar spridas över hela tjänsten - detta är inte särskilt bekvämt.
Ett annat problem är frestelsen till stegvis utveckling. Vi får höra att något måste läggas till evenemanget, och kanske, om vi tänker efter, borde det ha varit ett separat evenemang. Men i vårt schema är en separat händelse ett separat ämne. Ett separat ämne är hela processen som jag beskrev ovan. Utvecklaren är frestad att helt enkelt lägga till ett annat fält till JSON-schemat och återskapa det.
När det gäller återbetalningar kom vi fram till händelsen på ett halvår. Vi hade en meta-händelse som heter återbetalningsuppdatering, som hade ett typfält som beskrev vad den här uppdateringen faktiskt var. På grund av detta hade vi "underbara" switchar med validerare som berättade för oss hur man validerar denna händelse med den här typen.
Eventversionering
För att validera meddelanden i Kafka kan du använda , men det var nödvändigt att omedelbart lägga på den och använda Confluent. I vårt fall måste vi vara försiktiga med versionshantering. Det kommer inte alltid att vara möjligt att läsa om meddelanden från replikeringsloggen eftersom modellen har "gått". I grund och botten visar det sig att bygga versioner så att modellen är bakåtkompatibel: gör till exempel ett fält tillfälligt valfritt. Om skillnaderna är för stora börjar vi skriva i ett nytt ämne och överför klienter när de har läst klart det gamla.
Garanterad läsordning av partitioner
Ämnen inuti Kafka är uppdelade i partitioner. Detta är inte särskilt viktigt när vi utformar enheter och börser, men det är viktigt när vi bestämmer hur vi ska konsumera och skala det.
I det vanliga fallet skriver du ett ämne i Kafka. Som standard används en partition och alla meddelanden i detta ämne går till den. Och konsumenten läser följaktligen dessa meddelanden sekventiellt. Låt oss säga att vi nu behöver utöka systemet så att meddelanden läses av två olika konsumenter. Om du till exempel skickar SMS kan du säga till Kafka att göra en extra partition, och Kafka kommer att börja dela upp meddelandena i två delar - hälften här, hälften här.
Hur delar Kafka upp dem? Varje meddelande har en text (där vi lagrar JSON) och en nyckel. Du kan bifoga en hash-funktion till denna nyckel, som avgör vilken partition meddelandet ska hamna i.
I vårt fall med återbetalningar är detta viktigt, om vi tar två partitioner så finns det en chans att en parallellkonsument behandlar den andra händelsen innan den första och det blir problem. Hashfunktionen ser till att meddelanden med samma nyckel hamnar i samma partition.
Händelser vs kommandon
Detta är ett annat problem vi stött på. Händelse är en viss händelse: vi säger att något hände någonstans (något_hände), till exempel att en vara avbröts eller en återbetalning inträffade. Om någon lyssnar på dessa händelser kommer återbetalningsenheten att skapas enligt "artikel annullerad", och "återbetalning inträffade" kommer att skrivas någonstans i inställningarna.
Men vanligtvis, när du designar händelser, vill du inte skriva dem förgäves - du litar på att någon kommer att läsa dem. Det finns en stor frestelse att skriva inte något_hände (artikel_avbruten, återbetalning_återbetald), utan något_bör_göras. Varan är till exempel redo att returneras.
Å ena sidan föreslår det hur evenemanget kommer att användas. Å andra sidan låter det mycket mindre som ett vanligt händelsenamn. Dessutom är det inte långt härifrån till kommandot do_something. Men du har ingen garanti för att någon läser denna händelse; och om du läser den, då läser du den framgångsrikt; och om du läste det framgångsrikt, då gjorde du något, och det där var framgångsrikt. I samma ögonblick som en händelse blir göra_något, blir feedback nödvändig, och det är ett problem.

I asynkront utbyte i RabbitMQ, när du läser meddelandet, gå till http, du har ett svar - åtminstone att meddelandet togs emot. När du skriver till Kafka finns det ett meddelande som du skrivit till Kafka, men du vet inget om hur det behandlades.
Därför var vi i vårt fall tvungna att införa en responshändelse och sätta upp bevakning så att om så många händelser skickades så skulle samma antal responshändelser komma in efter den och den tiden. Om detta inte händer, så verkar något ha gått fel. Om vi till exempel skickade händelsen "item_ready_to_refund", förväntar vi oss att en återbetalning kommer att skapas, pengarna kommer att returneras till kunden och händelsen "money_refunded" kommer att skickas till oss. Men detta är inte säkert, så övervakning behövs.
nyanser
Det finns ett ganska uppenbart problem: om du läser från ett ämne sekventiellt, och du har något dåligt budskap, kommer konsumenten att falla och du kommer inte längre. Du behöver stoppa alla konsumenter, commit offset ytterligare för att fortsätta läsa.
Vi visste om det, vi räknade med det, och ändå hände det. Och detta hände för att händelsen var giltig ur händelse-buss synvinkel, händelsen var giltig ur applikationsvaliderarens synvinkel, men den var inte giltig ur PostgreSQL synvinkel, eftersom i vårt enda system MySQL med UNSIGNED INT, och i det nyskrivna hade systemet PostgreSQL bara med INT. Hans storlek är lite mindre, och ID:n passade inte. Symfony dog med ett undantag. Vi fångade naturligtvis undantaget eftersom vi förlitade oss på det och skulle begå denna offset, men innan dess ville vi öka problemräknaren, eftersom meddelandet bearbetades utan framgång. Räknarna i detta projekt finns också i databasen, och Symfony har redan stängt kommunikationen med databasen, och det andra undantaget dödade hela processen utan en chans att begå offset.
Tjänsten låg kvar en tid - lyckligtvis är det inte så illa med Kafka, eftersom meddelandena finns kvar. När arbetet är återställt kan du läsa klart dem. Det är bekvämt.
Kafka har förmågan att ställa in en godtycklig offset genom verktyg. Men för att göra detta måste du stoppa alla konsumenter - i vårt fall, förbered en separat release där det inte kommer att finnas några konsumenter, omplaceringar. Sedan i Kafka kan du flytta offset genom verktyg, och meddelandet kommer att gå igenom.
En annan nyans - replikeringslogg vs rdkafka.so - är relaterat till detaljerna i vårt projekt. Vi använder PHP, och i PHP kommunicerar som regel alla bibliotek med Kafka genom rdkafka.so-förrådet, och då finns det någon form av omslag. Kanske är det våra personliga svårigheter, men det visade sig att det inte är så lätt att bara läsa om en del av det vi redan hade läst. I allmänhet var det mjukvaruproblem.
Återgå till detaljerna för att arbeta med partitioner, det är skrivet direkt i dokumentationen konsumenter >= ämnespartitioner. Men jag fick reda på detta mycket senare än jag hade velat. Om du vill skala och ha två konsumenter behöver du minst två partitioner. Det vill säga, om du hade en partition i vilken 20 tusen meddelanden hade samlats och du skapade en ny, kommer antalet meddelanden inte att jämnas ut snart. Därför, för att ha två parallella konsumenter, måste du hantera partitioner.
övervakning
Jag tror att sättet vi övervakar det kommer att bli ännu tydligare vilka problem det finns i det befintliga tillvägagångssättet.
Vi beräknar till exempel hur många produkter i databasen som nyligen har ändrat status, och följaktligen borde händelser ha inträffat baserat på dessa ändringar, och vi skickar detta nummer till vårt övervakningssystem. Sedan från Kafka får vi det andra numret, hur många händelser som faktiskt spelades in. Självklart ska skillnaden mellan dessa två siffror alltid vara noll.
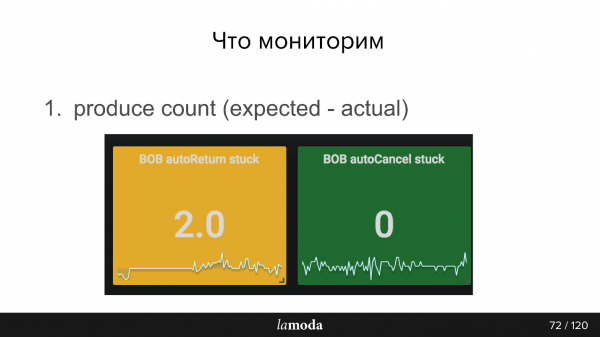
Dessutom måste du övervaka hur producenten mår, om event-buss mottagna meddelanden och hur konsumenten mår. Till exempel, i diagrammen nedan, går Refund Tool bra, men BIR har helt klart några problem (blå toppar).
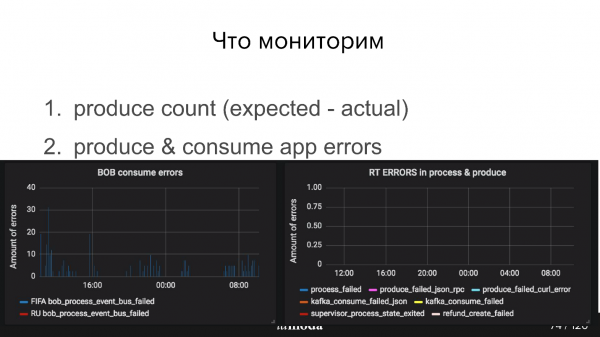
Jag har redan nämnt konsumentgruppsfördröjning. Grovt sett är detta antalet olästa meddelanden. Generellt sett arbetar våra konsumenter snabbt, så eftersläpningen brukar vara 0, men ibland kan det bli en kortvarig topp. Kafka kan göra detta direkt, men du måste ställa in ett visst intervall.
Det finns ett projekt som ger dig mer information om Kafka. Den använder helt enkelt konsumentgruppens API för att ge status för hur den här gruppen mår. Förutom OK och Failed finns en varning, och du kan få reda på att dina konsumenter inte klarar av produktionstakten – de hinner inte korrekturläsa det som står. Systemet är ganska smart och lätt att använda.
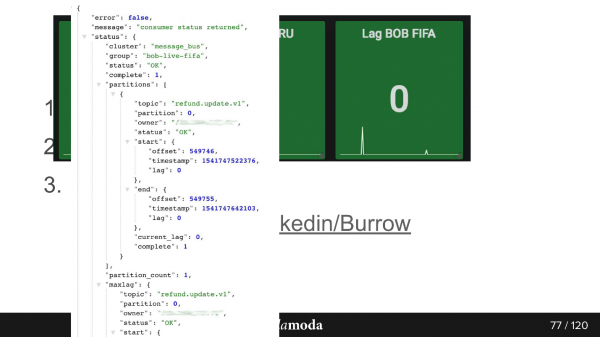
Så här ser API-svaret ut. Här är gruppen bob-live-fifa, partition refund.update.v1, status OK, fördröjning 0 - den sista slutliga offset så och så.
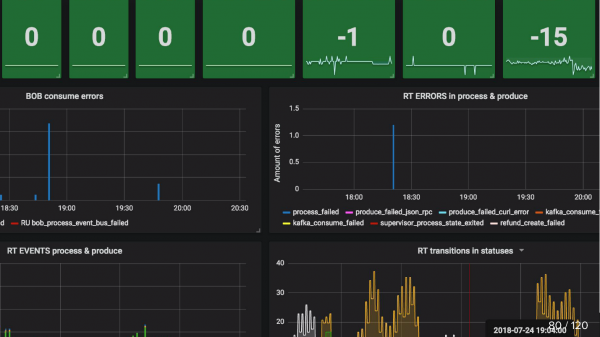
övervakning updated_at SLA (fastnat) Jag har redan nämnt. Till exempel har produkten ändrats till status att den är redo för retur. Vi installerar Cron, som säger att om det här objektet inte har gått till återbetalning inom 5 minuter (vi returnerar pengar via betalningssystem mycket snabbt), så gick något definitivt fel, och detta är definitivt ett fall för support. Därför tar vi helt enkelt Cron, som läser sådana saker, och om de är större än 0, så skickar den en varning.
För att sammanfatta, att använda händelser är bekvämt när:
- information behövs av flera system;
- resultatet av bearbetningen är inte viktigt;
- det är få evenemang eller små evenemang.
Det verkar som att artikeln har ett väldigt specifikt ämne - asynkron API på Kafka, men i samband med det skulle jag vilja rekommendera en massa saker på en gång.
Först, nästa vi måste vänta till november, i april kommer det att finnas en version av St. Petersburg, och i juni kommer vi att prata om hög belastning i Novosibirsk.
För det andra är författaren till rapporten, Sergei Zaika, medlem av programkommittén för vår nya konferens om kunskapshantering . Konferensen är en dag, kommer att äga rum den 26 april, men dess program är mycket intensivt.
Och det blir i maj и (med DevOpsConf inkluderat) - du kan också föreslå ditt ämne där, prata om din upplevelse och klaga på dina fyllda kottar.
Källa: will.com
