

Inledning
 "Du måste springa så fort du kan bara för att stanna på plats,
"Du måste springa så fort du kan bara för att stanna på plats,
och för att komma någonstans måste du springa minst dubbelt så snabbt!”
(c) Alice i Underlandet
För en tid sedan blev jag ombedd att hålla en föreläsning analytiker vårt företag på temat design av datamodeller, för när vi sitter på projekt under en lång tid (ibland i flera år) tappar vi ur sikte vad som händer runt omkring oss i IT-teknikens värld. I vårt företag (det råkar vara så) använder många projekt inte NoSQL-databaser (åtminstone för nu), så i min föreläsning ägnade jag särskild uppmärksamhet åt dem med hjälp av exemplet HBase och försökte orientera presentationen av materialet till de som aldrig har använt dem har arbetat. I synnerhet illustrerade jag några av funktionerna i design av datamodeller med hjälp av ett exempel som jag läste för flera år sedan . När jag analyserade exempel jämförde jag flera alternativ för att lösa samma problem för att bättre kunna förmedla huvudidéerna till publiken.
Nyligen, "av ingenting att göra", ställde jag mig själv frågan (den långa majhelgen i karantän är särskilt gynnsam för detta), hur mycket kommer teoretiska beräkningar att motsvara praxis? Det är faktiskt så här idén till den här artikeln föddes. En utvecklare som har arbetat med NoSQL i flera dagar kanske inte lär sig något nytt av det (och kan därför direkt hoppa över halva artikeln). Men för analytikerFör de som ännu inte har arbetat nära NoSQL tror jag att det kommer att vara användbart för att få en grundläggande förståelse för funktionerna i att designa datamodeller för HBase.
Exempelanalys
Enligt min mening, innan du börjar använda NoSQL-databaser, måste du tänka noga och väga för- och nackdelar. Ofta kan problemet med största sannolikhet lösas med traditionella relationella DBMS. Därför är det bättre att inte använda NoSQL utan betydande skäl. Om du ändå bestämt dig för att använda en NoSQL-databas, bör du ta hänsyn till att designmetoderna här är något annorlunda. Speciellt några av dem kan vara ovanliga för dem som tidigare endast har sysslat med relationella DBMS:er (enligt mina observationer). Så i den "relationella" världen börjar vi vanligtvis med att modellera problemdomänen, och först då, om nödvändigt, avnormalisera modellen. I NoSQL vi bör omedelbart ta hänsyn till de förväntade scenarierna för att arbeta med data och initialisera data. Dessutom finns det ett antal andra skillnader, som kommer att diskuteras nedan.
Låt oss överväga följande "syntetiska" problem, som vi kommer att fortsätta arbeta med:
Det är nödvändigt att utforma en lagringsstruktur för listan över vänner till användare av något abstrakt socialt nätverk. För att förenkla kommer vi att anta att alla våra anslutningar är riktade (som på Instagram, inte Linkedin). Strukturen bör tillåta dig att effektivt:
- Svara på frågan om användare A läser användare B (läsmönster)
- Tillåt att lägga till/ta bort anslutningar vid prenumeration/avregistrering av användare A från användare B (dataändringsmall)
Naturligtvis finns det många alternativ för att lösa problemet. I en vanlig relationsdatabas skulle vi med största sannolikhet helt enkelt göra en tabell över relationer (eventuellt typiskt om vi till exempel behöver lagra en användargrupp: familj, arbete etc. som inkluderar denna "vän") och för att optimera åtkomsthastighet skulle lägga till index/partitionering. Med största sannolikhet skulle finalbordet se ut ungefär så här:
USER_ID
vän_id
Vasya
Petya
Vasya
Оля
nedan, för tydlighetens skull och för bättre förståelse, kommer jag att ange namn istället för ID
När det gäller HBase vet vi att:
- effektiv sökning som inte resulterar i en fullständig tabellskanning är möjlig uteslutande med nyckel
- i själva verket är det därför en dålig idé att skriva SQL-frågor till sådana databaser som är bekanta för många; tekniskt sett kan du naturligtvis skicka en SQL-fråga med Joins och annan logik till HBase från samma Impala, men hur effektivt blir det...
Därför är vi tvungna att använda användar-ID som nyckel. Och min första tanke om ämnet "var och hur man lagrar vänners ID-nummer?" kanske en idé att lagra dem i kolumner. Detta mest uppenbara och "naiva" alternativ kommer att se ut ungefär så här (låt oss kalla det Alternativ 1 (standard)för ytterligare referens):
RowKey
högtalare
Vasya
1: Petya
2: Olya
3: Dasha
Petya
1: Masha
2: Vasya
Här motsvarar varje linje en nätverksanvändare. Kolumnerna har namn: 1, 2, ... - enligt antalet vänner, och vänners ID lagras i kolumnerna. Det är viktigt att notera att varje rad kommer att ha olika antal kolumner. I exemplet i figuren ovan har en rad tre kolumner (1, 2 och 3), och den andra har bara två (1 och 2) - här använde vi själva två HBase-egenskaper som relationsdatabaser inte har:
- möjligheten att dynamiskt ändra sammansättningen av kolumner (lägg till en vän -> lägg till en kolumn, ta bort en vän -> ta bort en kolumn)
- olika rader kan ha olika kolumnsammansättningar
Låt oss kontrollera vår struktur för att uppfylla kraven för uppgiften:
- Läser data: för att förstå om Vasya prenumererar på Olya måste vi subtrahera hela raden med nyckeln RowKey = "Vasya" och sortera igenom kolumnvärdena tills vi "träffar" Olya i dem. Eller iterera genom värdena för alla kolumner, "träffa inte" Olya och returnera svaret False;
- Redigera data: lägga till en vän: för en liknande uppgift måste vi också subtrahera hela raden använda tangenten RowKey = “Vasya” för att beräkna det totala antalet vänner. Vi behöver det här totala antalet vänner för att bestämma numret på kolumnen där vi behöver skriva ner ID:t för den nya vännen.
- Ändra data: radera en vän:
- Behöver subtrahera hela raden med tangenten RowKey = “Vasya” och sortera igenom kolumnerna för att hitta den där vännen som ska raderas är registrerad;
- Därefter, efter att ha tagit bort en vän, måste vi "skifta" all data till en kolumn för att inte få "luckor" i deras numrering.
Låt oss nu utvärdera hur produktiva dessa algoritmer, som vi kommer att behöva implementera på sidan "villkorad applikation", kommer att vara, med . Låt oss beteckna storleken på vårt hypotetiska sociala nätverk som n. Då är det maximala antalet vänner en användare kan ha (n-1). Vi kan ytterligare försumma detta (-1) för våra syften, eftersom det inom ramen för användningen av O-symboler är oviktigt.
- Läser data: det är nödvändigt att subtrahera hela raden och iterera genom alla dess kolumner i gränsen. Detta innebär att den övre uppskattningen av kostnaderna kommer att vara ungefär O(n)
- Redigera data: lägga till en vän: för att bestämma antalet vänner måste du iterera genom alla kolumner i raden och sedan infoga en ny kolumn => O(n)
- Ändra data: radera en vän:
- Liknar att lägga till - du måste gå igenom alla kolumner i gränsen => O(n)
- Efter att ha tagit bort kolumnerna måste vi "flytta" dem. Om du implementerar detta "head-on" behöver du i gränsen upp till (n-1) operationer. Men här och vidare i den praktiska delen kommer vi att använda ett annat tillvägagångssätt, som kommer att implementera ett "pseudoskifte" för ett fast antal operationer - det vill säga konstant tid kommer att spenderas på det, oavsett n. Denna konstanta tid (O(2) för att vara exakt) kan försummas jämfört med O(n). Tillvägagångssättet illustreras i figuren nedan: vi kopierar helt enkelt data från den "sista" kolumnen till den som vi vill ta bort data från och tar sedan bort den sista kolumnen:

Totalt sett fick vi i alla scenarier en asymptotisk beräkningskomplexitet av O(n).
Du har säkert redan märkt att vi nästan alltid måste läsa hela raden från databasen, och i två fall av tre, bara för att gå igenom alla kolumner och räkna ut det totala antalet vänner. Därför, som ett försök till optimering, kan du lägga till en kolumn "räkning", som lagrar det totala antalet vänner för varje nätverksanvändare. I det här fallet kan vi inte läsa hela raden för att beräkna det totala antalet vänner, utan bara läsa en "count" kolumn. Det viktigaste är att inte glömma att uppdatera "count" när du manipulerar data. Den där. vi blir bättre Alternativ 2 (antal):
RowKey
högtalare
Vasya
1: Petya
2: Olya
3: Dasha
antal: 3
Petya
1: Masha
2: Vasya
antal: 2
Jämfört med det första alternativet:
- Läser data: för att få svar på frågan "Läser Vasya Olya?" ingenting har förändrats => O(n)
- Redigera data: lägga till en vän: Vi har förenklat infogningen av en ny vän, eftersom vi nu inte behöver läsa hela raden och iterera över dess kolumner, utan kan bara få värdet på kolumnen "räkna", etc. bestäm omedelbart kolumnnumret för att infoga en ny vän. Detta leder till en minskning av beräkningskomplexiteten till O(1)
- Ändra data: radera en vän: När vi tar bort en vän kan vi också använda den här kolumnen för att minska antalet I/O-operationer när vi "skiftar" data en cell till vänster. Men behovet av att iterera genom kolumnerna för att hitta den som behöver raderas kvarstår, så => O(n)
- Å andra sidan, nu när vi uppdaterar data måste vi uppdatera kolumnen "count" varje gång, men detta tar konstant tid, vilket kan försummas inom ramen för O-symboler
I allmänhet verkar alternativ 2 lite mer optimalt, men det är mer som "evolution istället för revolution." För att göra en "revolution" kommer vi att behöva Alternativ 3 (kol).
Låt oss vända allt "upp och ner": vi tilldelar kolumnnamn användar-ID! Vad som kommer att skrivas i själva kolumnen är inte längre viktigt för oss, låt det vara siffran 1 (i allmänhet kan användbara saker lagras där, till exempel gruppen "familj/vänner/etc."). Detta tillvägagångssätt kan överraska den oförberedda "lekmannen" som inte har någon tidigare erfarenhet av att arbeta med NoSQL-databaser, men det är just detta tillvägagångssätt som gör att du kan använda potentialen hos HBase i denna uppgift mycket mer effektivt:
RowKey
högtalare
Vasya
Petya: 1
Olya: 1
Dasha: 1
Petya
Masha: 1
Vasya: 1
Här får vi flera fördelar på en gång. För att förstå dem, låt oss analysera den nya strukturen och uppskatta beräkningskomplexiteten:
- Läser data: för att svara på frågan om Vasya prenumererar på Olya räcker det att läsa en kolumn "Olya": om den finns där är svaret sant, om inte - Falskt => O(1)
- Redigera data: lägga till en vän: Lägga till en vän: lägg bara till en ny kolumn "Vän-ID" => O(1)
- Ändra data: radera en vän: ta bara bort vän-ID-kolumnen => O(1)
Som du kan se är en betydande fördel med denna lagringsmodell att vi i alla scenarier vi behöver arbetar med endast en kolumn, och undviker att läsa hela raden från databasen och dessutom räkna upp alla kolumner i denna rad. Vi kunde stanna där, men...
Du kan bli förbryllad och gå lite längre på vägen för att optimera prestanda och minska I/O-operationer när du kommer åt databasen. Vad händer om vi lagrade den fullständiga relationsinformationen direkt i själva radnyckeln? Det vill säga, gör nyckeln sammansatt som userID.friendID? I det här fallet behöver vi inte ens läsa radens kolumner alls (Alternativ 4 (rad)):
RowKey
högtalare
Vasya.Petya
Petya: 1
Vasya.Olya
Olya: 1
Vasya.Dasha
Dasha: 1
Petya.Masha
Masha: 1
Petya.Vasya
Vasya: 1
Uppenbarligen kommer bedömningen av alla datamanipulationsscenarier i en sådan struktur, som i den tidigare versionen, att vara O(1). Skillnaden med alternativ 3 kommer enbart att ligga i effektiviteten av I/O-operationer i databasen.
Jo, den sista "bågen". Det är lätt att se att i alternativ 4 kommer radnyckeln att ha en variabel längd, vilket möjligen kan påverka prestandan (här kommer vi ihåg att HBase lagrar data som en uppsättning byte och rader i tabeller sorteras efter nyckel). Dessutom har vi en separator som kan behöva hanteras i vissa scenarier. För att eliminera detta inflytande kan du använda hash från userID och friendID, och eftersom båda hasharna kommer att ha en konstant längd kan du helt enkelt sammanfoga dem, utan en separator. Då kommer data i tabellen att se ut så här (Alternativ 5 (hash)):
RowKey
högtalare
dc084ef00e94aef49be885f9b01f51c01918fa783851db0dc1f72f83d33a5994
Petya: 1
dc084ef00e94aef49be885f9b01f51c0f06b7714b5ba522c3cf51328b66fe28a
Olya: 1
dc084ef00e94aef49be885f9b01f51c00d2c2e5d69df6b238754f650d56c896a
Dasha: 1
1918fa783851db0dc1f72f83d33a59949ee3309645bd2c0775899fca14f311e1
Masha: 1
1918fa783851db0dc1f72f83d33a5994dc084ef00e94aef49be885f9b01f51c0
Vasya: 1
Uppenbarligen kommer den algoritmiska komplexiteten att arbeta med en sådan struktur i de scenarier vi överväger att vara densamma som för alternativ 4 - det vill säga O(1).
Sammantaget, låt oss sammanfatta alla våra uppskattningar av beräkningskomplexitet i en tabell:
Lägger till en vän
Kollar på en vän
Ta bort en vän
Alternativ 1 (standard)
O (n)
O (n)
O (n)
Alternativ 2 (antal)
O (1)
O (n)
O (n)
Alternativ 3 (kolumn)
O (1)
O (1)
O (1)
Alternativ 4 (rad)
O (1)
O (1)
O (1)
Alternativ 5 (hash)
O (1)
O (1)
O (1)
Som du kan se verkar alternativ 3-5 vara det mest föredragna och teoretiskt säkerställer exekveringen av alla nödvändiga datamanipulationsscenarier i konstant tid. I villkoren för vår uppgift finns det inget uttryckligt krav på att skaffa en lista över alla användarens vänner, men i verkliga projektaktiviteter skulle det vara bra för oss, som bra analytiker, att "förutse" att en sådan uppgift kan uppstå och "sprid ett sugrör." Därför är mina sympatier på sidan av alternativ 3. Men det är ganska troligt att i ett verkligt projekt kunde denna begäran redan ha lösts på andra sätt, därför är det, utan en allmän vision av hela problemet, bättre att inte göra slutsatser.
Förberedelse av experimentet
Jag skulle vilja testa ovanstående teoretiska argument i praktiken – detta var målet med idén som uppstod under långhelgen. För att göra detta är det nödvändigt att utvärdera driftshastigheten för vår "villkorliga applikation" i alla beskrivna scenarier för att använda databasen, såväl som ökningen av denna tid med ökande storlek på det sociala nätverket (n). Målparametern som intresserar oss och som vi kommer att mäta under experimentet är den tid som den "villkorliga applikationen" spenderar för att utföra en "affärsoperation". Med "affärstransaktion" menar vi något av följande:
- Lägger till en ny vän
- Kontrollera om användare A är en vän till användare B
- Tar bort en vän
Med hänsyn till de krav som beskrivs i det inledande uttalandet, framträder verifieringsscenariot som följer:
- Dataregistrering. Generera slumpmässigt ett initialt nätverk av storlek n. För att komma närmare den "verkliga världen" är antalet vänner varje användare har också en slumpmässig variabel. Mät den tid under vilken vår "villkorliga applikation" skriver all genererad data till HBase. Dela sedan den resulterande tiden med det totala antalet tillagda vänner - så här får vi den genomsnittliga tiden för en "affärsverksamhet"
- Läser data. Skapa en lista över "personligheter" för varje användare som du behöver för att få svar på om användaren prenumererar på dem eller inte. Längden på listan = ungefär antalet av användarens vänner, och för hälften av de markerade vännerna ska svaret vara "Ja", och för den andra hälften - "Nej". Kontrollen utförs i sådan ordning att svaren "Ja" och "Nej" växlar (det vill säga i vartannat fall måste vi gå igenom alla kolumner på raden för alternativ 1 och 2). Den totala screeningstiden divideras sedan med antalet vänner som testats för att få den genomsnittliga screeningtiden per försöksperson.
- Radering av data. Ta bort alla vänner från användaren. Dessutom är raderingsordningen slumpmässig (det vill säga vi "blandar" den ursprungliga listan som användes för att registrera data). Den totala kontrolltiden divideras sedan med antalet vänner som tagits bort för att få den genomsnittliga tiden per check.
Scenarierna måste köras för vart och ett av de 5 datamodellalternativen och för olika storlekar av det sociala nätverket för att se hur tiden förändras när den växer. Inom ett n måste anslutningar i nätverket och listan över användare som ska kontrolleras naturligtvis vara lika för alla 5 alternativen.
För en bättre förståelse, nedan är ett exempel på genererad data för n= 5. Den skrivna "generatorn" producerar tre ID-ordböcker som utdata:
- den första är för insättning
- den andra är för kontroll
- tredje – för radering
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Som du kan se är alla ID:n som är större än 10 000 i ordboken för kontroll just de som säkert kommer att ge svaret Falskt. Infoga, kontrollera och radera "vänner" utförs exakt i den ordning som anges i ordboken.
Experimentet utfördes på en bärbar dator med Windows 10, där HBase kördes i en Docker-container och Python med Jupyter Notebook kördes i en annan. Docker tilldelades 2 CPU-kärnor och 2 GB RAM. All logik, inklusive simuleringen av "dummy-applikationen" och ramverket för att generera testdata och mäta tid, skrevs i Python. Biblioteket , för att beräkna hash (MD5) för alternativ 5 - hashlib
Med hänsyn till datorkraften hos en viss bärbar dator valdes en lansering för n = 10, 30, … experimentellt. 170 – när den totala drifttiden för hela testcykeln (alla scenarier för alla alternativ för alla n) var till och med mer eller mindre rimlig och passade under en tebjudning (i genomsnitt 15 minuter).
Här är det nödvändigt att göra en anmärkning att vi i detta experiment inte i första hand utvärderar absoluta prestationssiffror. Även en relativ jämförelse av olika två alternativ kanske inte är helt korrekt. Nu är vi intresserade av arten av förändringen i tid beroende på n, eftersom med hänsyn till ovanstående konfiguration av "testbänken" är det mycket svårt att få tidsuppskattningar "rensade" från påverkan av slumpmässiga och andra faktorer ( och en sådan uppgift var inte satt).
Experimentresultat
Det första testet är hur tiden för att fylla i vänlistan förändras. Resultatet finns i grafen nedan.
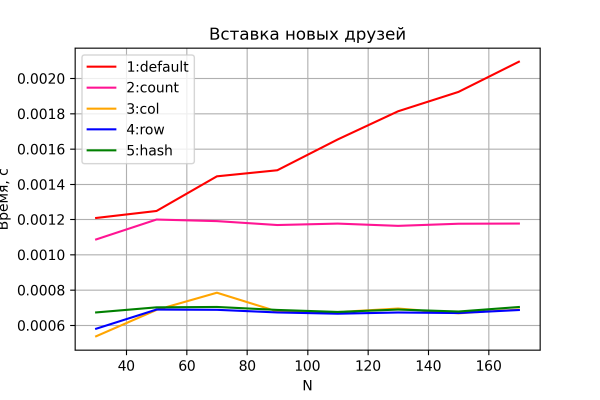
Alternativ 3-5, som förväntat, visar en nästan konstant "affärstransaktion" tid, som inte beror på tillväxten av nätverksstorleken och en oskiljbar skillnad i prestanda.
Alternativ 2 visar också konstant, men något sämre prestanda, nästan exakt 2 gånger i förhållande till alternativ 3-5. Och detta kan inte annat än glädjas, eftersom det korrelerar med teori - i denna version är antalet I/O-operationer till/från HBase exakt 2 gånger större. Detta kan fungera som ett indirekt bevis på att vår testbänk i princip ger god noggrannhet.
Alternativ 1 visar sig också, som väntat, vara det långsammaste och visar en linjär ökning av tiden som läggs på att lägga till varandra till nätverkets storlek.
Låt oss nu titta på resultatet av det andra testet.
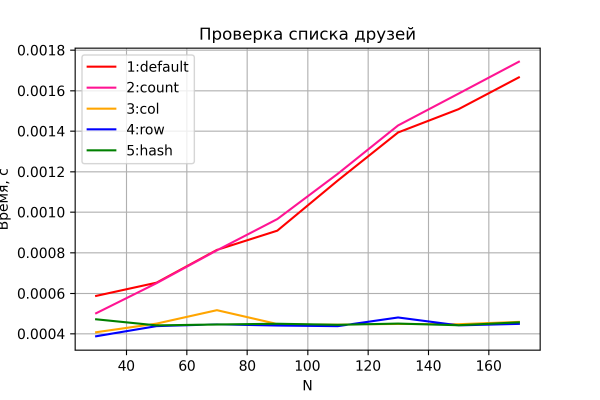
Alternativ 3-5 beter sig igen som förväntat - konstant tid, oberoende av nätverkets storlek. Alternativ 1 och 2 visar en linjär ökning av tiden när nätverksstorleken ökar och liknande prestanda. Dessutom visar sig alternativ 2 vara lite långsammare - uppenbarligen på grund av behovet av att korrekturläsa och bearbeta den extra "count"-kolumnen, som blir mer märkbar när n växer. Men jag kommer ändå att avstå från att dra några slutsatser, eftersom noggrannheten i denna jämförelse är relativt låg. Dessutom ändras dessa förhållanden (vilket alternativ, 1 eller 2, är snabbare) från löpning till löpning (med bibehållen karaktären av beroende och "gå hals och nacke").
Tja, den sista grafen är resultatet av borttagningstestning.
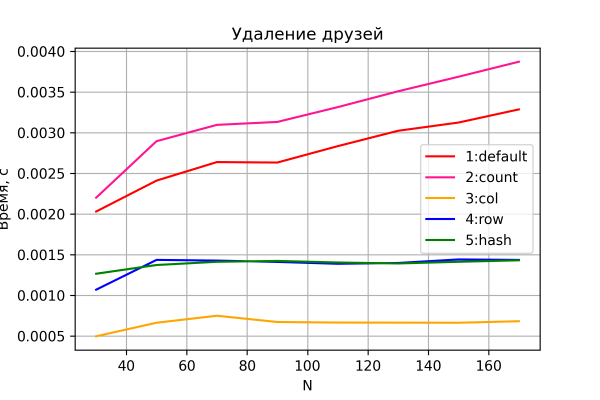
Återigen, inga överraskningar här. Alternativ 3-5 utför borttagning i konstant tid.
Dessutom, intressant nog, alternativ 4 och 5, till skillnad från de tidigare scenarierna, visar märkbart något sämre prestanda än alternativ 3. Uppenbarligen är radraderingsoperationen dyrare än kolumnraderingsoperationen, vilket generellt är logiskt.
Alternativ 1 och 2 visar som förväntat en linjär ökning av tiden. Samtidigt är alternativ 2 konsekvent långsammare än alternativ 1 - på grund av den extra I/O-operationen för att "underhålla" räknekolumnen.
Allmänna slutsatser av experimentet:
- Alternativ 3-5 visar större effektivitet när de drar fördel av HBase; Dessutom skiljer sig deras prestanda i förhållande till varandra med en konstant och beror inte på nätverkets storlek.
- Skillnaden mellan alternativ 4 och 5 registrerades inte. Men det betyder inte att alternativ 5 inte ska användas. Det är troligt att det experimentella scenariot som användes, med hänsyn till testbänkens prestandaegenskaper, inte gjorde det möjligt att detektera det.
- Typen av ökningen av den tid som krävs för att utföra "affärsverksamhet" med data bekräftade i allmänhet de tidigare erhållna teoretiska beräkningarna för alla alternativ.
Epilog
Dessa grova experiment bör inte tas som absolut sanning. Det finns många faktorer som inte togs med i beräkningen och som förvrängde resultaten (dessa fluktuationer är särskilt synliga i graferna för små nätverksstorlekar). Till exempel hastigheten på thrift, som används av happybase, volymen och implementeringsmetoden för logiken jag skrev i Python (jag kan inte påstå att koden skrevs optimalt eller effektivt utnyttjade alla komponenter), möjligen HBase-cachningsfunktioner och bakgrundsaktivitet. Windows 10 På min bärbara dator, etc. Sammantaget kan man dra slutsatsen att alla teoretiska antaganden har experimentellt bevisats vara giltiga. Eller åtminstone var det inte möjligt att motbevisa dem med en sådan direkt attack.
Sammanfattningsvis, rekommendationer till alla som precis har börjat designa datamodeller i HBase: abstrakt från tidigare erfarenhet av att arbeta med relationsdatabaser och kom ihåg "kommandona":
- När vi designar utgår vi från uppgiften och mönstren för datamanipulation, och inte från domänmodellen
- Effektiv åtkomst (utan full tabellskanning) – endast med nyckel
- Denormalisering
- Olika rader kan innehålla olika kolumner
- Dynamisk sammansättning av högtalare
Källa: will.com
