

Ju mer komplext systemet är, desto mer blir det övervuxet med alla typer av varningar. Och det finns ett behov av att reagera på samma varningar, samla dem och visualisera dem. Jag tror att detta är en situation som är bekant för många till nervositet.
Lösningen som kommer att diskuteras är inte den mest oväntade, men sökningen returnerar inte en fullfjädrad artikel om detta ämne.
Därför bestämde jag mig för att dela med mig av FunCorps erfarenhet och prata om hur tjänstgöringsprocessen är uppbyggd, vem som ringer, varför och hur man kan se på det hela.

Vad är PagerDuty?
Så för att lösa alla dessa problem började vi leta efter ett bekvämt verktyg. Efter lite letande valde vi PagerDuty. PD föreföll oss vara en ganska komplett och kortfattad lösning med ett stort antal integrationer och inställningar. Hur är hon?
Kort sagt, PagerDuty är en incidenthanteringsplattform som kan bearbeta inkommande incidenter genom olika integrationer, sätta upp tjänstgöringsorder och sedan larma tjänstgörande ingenjör beroende på nivån på incidenten (på en hög nivå - ett samtal, på en låg nivå - en push från applikationen/SMS).
Vem är vakthavande befäl?
Detta är förmodligen det första stället att börja sätta upp PD.
På FunCorp finns, liksom andra företag, en hederstjänst som vakthavande befäl. Den överförs från ingenjör till ingenjör en gång om dagen. Det finns en så kallad första och andra svarsrad på en varning från PagerDuty. Anta att en larm med hög prioritet anländer, och om det 10 minuter efter samtalet till vakthavande befäl från första linjen inte finns någon reaktion på den (dvs. den överförs inte till statusen bekräfta eller löst), går samtalet till den andra tjänstgörande ingenjör. Detta konfigureras i själva PagerDuty genom eskaleringspolicyer.
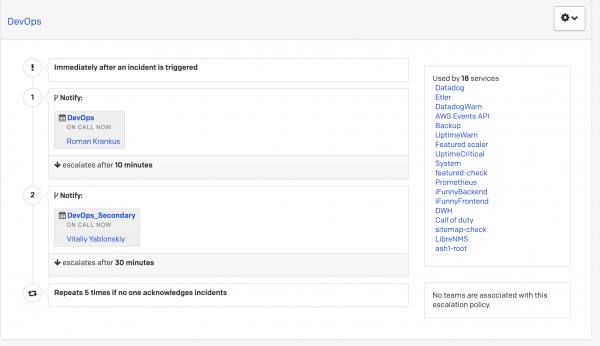
Om den andra vakthavande befäl inte svarar återgår aviseringen till huvud till vakthavande befäl.
Således kan alla inkommande högprioriterade varningar inte förbli obehandlade.
Låt oss nu se var incidenter kan komma ifrån.
Vilka integrationer använder vi?
PD tar emot många olika incidenter från olika tjänster. Vi har för närvarande cirka 25 sådana tjänster och för att bearbeta dem använder vi några färdiga integrationer.
- Prometheus
Det huvudsakliga systemet för insamling av mätvärden är Prometheus. Det har redan skrivits mycket om det på Habré, jag kan bara säga att vi har flera av dem för olika miljöer: en samlar in mätvärden från virtuella maskiner och hamnarbetare, en annan från Amazon-tjänster, den tredje från hårdvarumaskiner. Telegraf används främst som måttexportör.
- E-post
Även här tycker jag att allt framgår av titeln. Denna integration används för att skicka meddelanden från vissa skript som körs av cron. PD ger dig en viss adress som du skickar brev till. När du skapar en tjänst med sådan integration kan du ställa in prioriteringar, i vilken ordning inkommande incidenter kommer att behandlas, exakt hur man skapar en varning (för varje inkommande brev, för ett inkommande brev + en viss regel etc.).

- Slak
Enligt mig en mycket intressant integration. Det finns tillfällen då något händer men inte omfattas av incidenter. Därför lade vi till integration från Slack för att skapa en incident. Det vill säga att du kan skriva till företagets Slack /callofduty allt går långsamt och kommer snart att gå sönder och PD kommer att bearbeta det och skicka händelsen till vakthavande ingenjör.
Vi gör:

Vi ser:

- API
HTTP-integrering. Det finns faktiskt inget speciellt intressant här, bara en POST-förfrågan med en body i JSON-format. Till exempel, något intressant: vi använder det för extern övervakning med hjälp av . Denna tjänst kontrollerar tillgängligheten för våra webbplatser från olika delar av världen. I det fall vi får en oacceptabel svarskod (till exempel 502) skapas en incident och sedan följer allt kedjan som beskrivs ovan. StatusCake själv har förmågan att övervaka interna webbadresser, SSL-certifikat eller domänförfall.
- LibreNMS
Detta är ett annat övervakningssystem, du kan läsa mer om det på deras hemsida . Med dess hjälp övervakar vi nätverksgränssnitt och iDRAC från servrar.
Det fanns även integrationer som Datadog, CloudWatch. Du kan se mer om vad som hände dem .
Visualisering
Det huvudsakliga incidentrapporteringssystemet är Slack. Alla incidenter som kommer till PD skrivs till en speciell chatt, och om deras status ändras visas detta även i chatten.
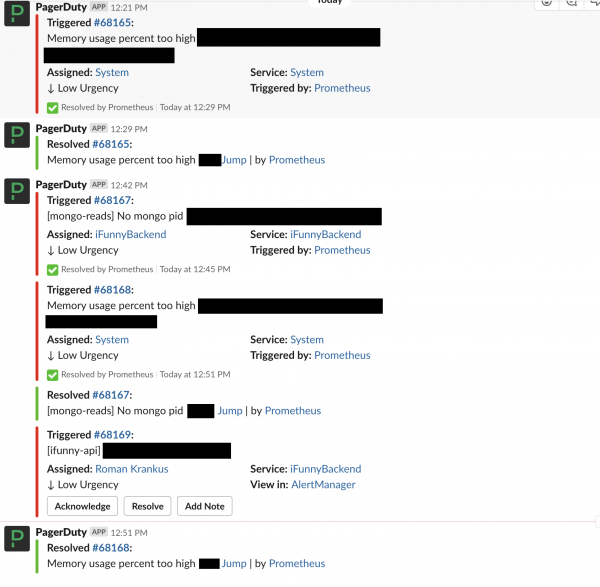
När möjligheten dök upp att visa användbar data på skärmarna på monitorer som hängde i taket insåg vi plötsligt att vi (på devops-avdelningen) inte hade något att visa på dem. Det finns en underbar Grafana, men den täcker inte allt, och anställda reagerar på varningar, inte diagram.
Efter en grundlig men misslyckad sökning på GitHub efter en kortfattad och informativ "tavla" för PD, bestämde vi oss för att skriva vår egen - bara med det vi behövde. Även om det till en början fanns en idé att visa själva PD-gränssnittet såg det ännu mer obekvämt ut.
Allt du behöver göra för att skriva det är att skaffa en nyckel från en PD med skrivskyddade rättigheter.
Och det här är vad vi fick:
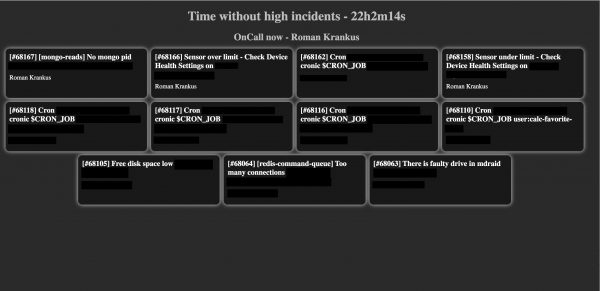
Skärmen visar de aktuella öppna incidenterna, namnet på den nuvarande tjänstgörande ingenjören från det valda schemat och tiden utan en högprioriterad incident (panelen med en högprioriterad incident kommer att markeras i rött).
.
Som ett resultat fick vi en bekväm instrumentpanel för att se alla våra incidenter. Jag blir glad om några av er tycker att vår erfarenhet är användbar.
Källa: will.com
