

I den andra delen av artikeln om datorsystemsimulatorer kommer jag att fortsätta att prata i en enkel introduktionsform om datorsimulatorer, nämligen om fullplattformssimulering, som oftast stöter på den genomsnittliga användaren, samt om cykelmodellen och spåren, som är vanligare i utvecklarkretsar.

В Jag berättade vad simulatorer är i allmänhet, och även om modelleringsnivåerna. Baserat på den kunskapen föreslår jag att vi går lite djupare och pratar om fullplattformssimulering, hur man sätter ihop spår, vad man ska göra med dem senare, och även om mikroarkitekturemulering per cykel.
Fullständig plattformssimulator, eller "En i fält är ingen krigare"
Om du behöver undersöka funktionen hos en specifik enhet, till exempel ett nätverkskort, eller skriva firmware eller en drivrutin för den här enheten, kan en sådan enhet modelleras separat. Att använda den separat från resten av infrastrukturen är dock inte särskilt bekvämt. För att köra motsvarande drivrutin behöver du en central processor, minne, åtkomst till databussen etc. Dessutom kräver drivrutinen ett operativsystem (OS) och en nätverksstack. Dessutom kan en separat paketgenerator och svarsserver krävas.
En fullplattformssimulator skapar en miljö för att köra en komplett programvaruuppsättning, som inkluderar allt från BIOS och bootloader till själva operativsystemet och dess olika delsystem, såsom samma nätverksuppsättning, drivrutiner och applikationer på användarnivå. För att göra detta implementerar den programvarumodeller av de flesta datorenheter: processor och minne, disk, in- och utmatningsenheter (tangentbord, mus, skärm) och samma nätverkskort.
Nedan visas ett blockschema över x58-chipsetet från Intel. I en fullplattformsdatorsimulator på detta chipset är det nödvändigt att implementera de flesta av de listade enheterna, inklusive de som finns inuti IOH (Input/Output Hub) och ICH (Input/Output Controller Hub), vilka inte visas i detalj på blockschemat. Även om det, som praktiken visar, finns en hel del enheter som inte används av den programvara vi ska köra, behöver modeller av sådana enheter inte skapas.
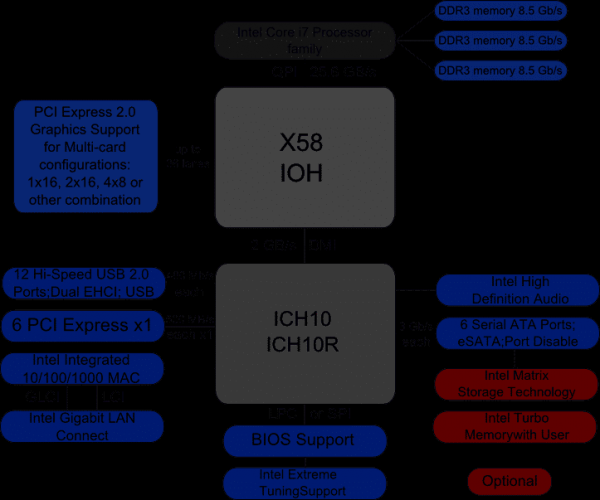
Oftast implementeras fullplattformssimulatorer på processorinstruktionsnivå (ISA, se ). Detta gör att du kan skapa själva simulatorn relativt snabbt och billigt. ISA-nivån är också bra eftersom den förblir mer eller mindre konstant, till skillnad från till exempel API/ABI-nivån, som ändras oftare. Dessutom tillåter implementeringen på instruktionsnivå att du kör den så kallade omodifierade binära programvaran, det vill säga köra redan kompilerad kod utan några ändringar, exakt som den används på riktig hårdvara. Med andra ord kan du göra en kopia ("dump") av hårddisken, ange den som en avbildning för modellen i fullplattformssimulatorn och - voilà! - operativsystemet och andra program laddas i simulatorn utan några ytterligare åtgärder.
Simulatorprestanda

Som nämnts ovan är processen att simulera hela systemet, dvs. alla dess enheter, ett ganska långsamt åtagande. Om man implementerar allt detta på en mycket detaljerad nivå, till exempel mikroarkitekturell eller logisk, kommer exekveringen att bli extremt långsam. Men instruktionsnivån är ett lämpligt val och gör att operativsystemet och programmen kan exekveras med hastigheter som är tillräckliga för att användaren bekvämt ska kunna interagera med dem.
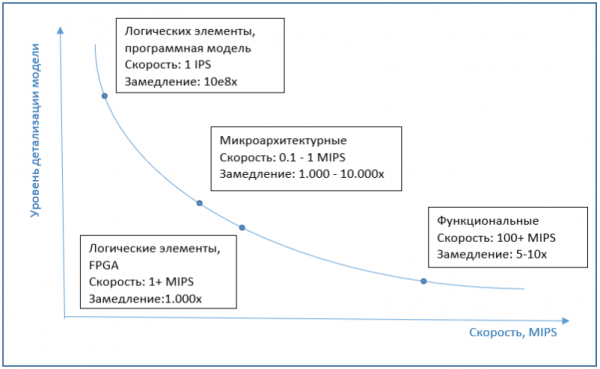
Det är här det vore lämpligt att beröra ämnet simulatorprestanda. Det mäts vanligtvis i IPS (instruktioner per sekund), eller mer exakt i MIPS (miljoner IPS), det vill säga antalet processorinstruktioner som körs av simulatorn på en sekund. Samtidigt beror simuleringens hastighet också på prestandan hos det system som själva simuleringen körs på. Därför kan det vara mer korrekt att tala om simulatorns "försämring" jämfört med det ursprungliga systemet.
De vanligaste fullplattformssimulatorerna på marknaden, samma QEMU, VirtualBox eller VmWare Workstation, har bra prestanda. Användaren kanske inte ens märker att arbetet utförs i en simulator. Detta händer på grund av den speciella virtualiseringsfunktionen som är implementerad i processorer, binära översättningsalgoritmer och andra intressanta saker. Allt detta är ett ämne för en separat artikel, men kortfattat är virtualisering en hårdvarufunktion hos moderna processorer som gör det möjligt för simulatorer att inte simulera instruktioner, utan att skicka dem för exekvering direkt till en riktig processor, om simulator- och processorarkitekturerna förstås är likartade. Binär översättning är översättningen av gästmaskinkod till värdkod och efterföljande exekvering på en riktig processor. Som ett resultat är simuleringen bara något långsammare, 5-10 gånger, och arbetar ofta med samma hastighet som ett verkligt system. Även om detta påverkas av många faktorer. Om vi till exempel vill simulera ett system med flera dussin processorer, kommer hastigheten omedelbart att sjunka med dessa flera dussin gånger. Å andra sidan stöder simulatorer som Simics i de senaste versionerna multiprocessorhårdvara och parallelliserar effektivt simulerade kärnor med riktiga processorkärnor.
Om vi pratar om hastigheten på mikroarkitektursimulering är den vanligtvis flera storleksordningar, ungefär 1000-10000 gånger långsammare än exekvering på en vanlig dator, utan simulering. Och implementeringar på nivån av logiska element är flera storleksordningar långsammare. Därför används FPGA som en emulator på denna nivå, vilket möjliggör en betydande ökning av produktiviteten.
Diagrammet nedan visar ett ungefärligt beroende av simuleringshastigheten på modellens detaljer.
Cykel-för-cykel-simulering
Trots den låga exekveringshastigheten är mikroarkitektursimulatorer ganska vanliga. Simulering av interna processorenheter är nödvändig för att exakt simulera exekveringstiden för varje instruktion. Detta kan orsaka förvirring - trots allt, verkar det som, varför inte bara ta och programmera exekveringstiden för varje instruktion. Men en sådan simulator kommer att fungera mycket oprecis, eftersom exekveringstiden för samma instruktion kan variera från anrop till anrop.
Det enklaste exemplet är en minnesåtkomstinstruktion. Om den begärda minnescellen är tillgänglig i cachen kommer exekveringstiden att vara minimal. Om cachen inte innehåller denna information (en "cachemiss") kommer detta att öka instruktionens exekveringstid avsevärt. Därför behövs en cachemodell för korrekt simulering. Cachemodellen räcker dock inte. Processorn kommer inte bara att vänta på att data ska tas emot från minnet om den inte finns i cachen. Istället kommer den att börja exekvera följande instruktioner och välja de som inte är beroende av resultatet av läsningen från minnet. Detta är den så kallade out-of-order-exekveringen (OOO), vilket är nödvändigt för att minimera processorns vilotid. Modellering av motsvarande processorblock hjälper till att ta hänsyn till allt detta vid beräkning av instruktionens exekveringstid. Bland dessa instruktioner som exekveras medan man väntar på resultatet av läsningen från minnet kan det finnas en villkorlig hoppoperation. Om resultatet av att exekvera villkoret är okänt för tillfället, stoppar processorn inte heller exekveringen, utan gör ett "antagande", exekverar motsvarande hopp och fortsätter att preemptivt exekvera instruktionerna från hopppunkten. Ett sådant block, kallat en grenprediktor, måste också implementeras i den mikroarkitekturella simulatorn.
Bilden nedan visar processorns huvudblock, det är inte nödvändigt att känna till dem, den ges endast för att visa komplexiteten i den mikroarkitekturella implementeringen.
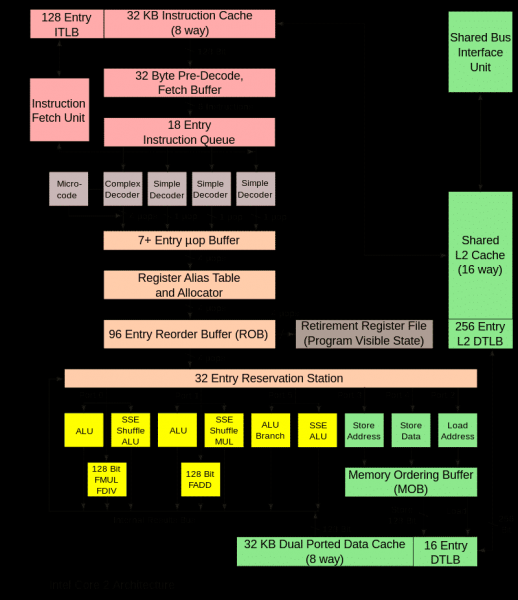
Funktionen hos alla dessa block i en verklig processor synkroniseras med speciella klocksignaler, och samma sak händer i modellen. En sådan mikroarkitektursimulator kallas cykelnoggrann. Dess huvudsyfte är att noggrant förutsäga prestandan hos den processor som utvecklas och/eller beräkna exekveringstiden för ett visst program, till exempel ett riktmärke. Om värdena är lägre än nödvändigt, kommer det att vara nödvändigt att förfina algoritmerna och processorblocken eller optimera programmet.
Som visas ovan är cykel-för-cykel-simulering mycket långsam, så den används endast när man studerar vissa moment i programdriften, där det är nödvändigt att känna till den verkliga hastigheten för programkörningen och uppskatta den framtida prestandan för enheten vars prototyp simuleras.
I det här fallet används en funktionell simulator för att simulera resten av programmets drifttid. Hur sker en sådan kombinerad användning i verkligheten? Först startas en funktionell simulator, på vilken operativsystemet och allt som behövs för att starta programmet som studeras laddas. Vi är trots allt inte intresserade av själva operativsystemet, inte heller av de inledande stegen av programmets start, dess konfiguration etc. Vi kan dock inte hoppa över dessa delar och omedelbart fortsätta med att köra programmet från mitten. Därför körs alla dessa preliminära steg på en funktionell simulator. Efter att programmet har körts till den punkt som är intressant för oss finns det två alternativ. Du kan ersätta modellen med en cykel-för-cykel-modell och fortsätta körningen. Simuleringsläget, som använder körbar kod (dvs. vanliga kompilerade programfiler), kallas körningsdriven simulering. Detta är det vanligaste simuleringsalternativet. Ett annat tillvägagångssätt är också möjligt - spårdriven simulering.
Spårbaserad simulering
Det består av två steg. Med hjälp av en funktionell simulator eller på ett verkligt system samlas en programåtgärdslogg in och skrivs till en fil. En sådan logg kallas ett spår. Beroende på vad som undersöks kan spåret innehålla körbara instruktioner, minnesadresser, portnummer och avbrottsinformation.
Nästa steg är att "spela upp" spåret, när cykelsimulatorn läser spåret och exekverar alla instruktioner som är skrivna i det. I slutet får vi exekveringstiden för denna del av programmet, såväl som olika egenskaper hos denna process, till exempel andelen cacheträffar.
En viktig egenskap vid arbete med spår är determinism, d.v.s. genom att köra simuleringen på det sätt som beskrivs ovan reproducerar vi samma handlingssekvens om och om igen. Detta gör det möjligt, genom att ändra modellens parametrar (storlekarna på cachen, buffertarna och köerna) och använda olika interna algoritmer eller justera dem, att studera hur den eller den parametern påverkar systemets prestanda och vilket alternativ som ger bäst resultat. Allt detta kan göras med en prototypenhetsmodell innan man skapar en riktig hårdvaruprototyp.
Komplexiteten i denna metod ligger i behovet av en preliminär körning av applikationen och insamling av spåret, samt den enorma storleken på filen med spåret. Fördelarna inkluderar att det räcker med att bara modellera den del av enheten eller plattformen som är av intresse, medan simulering genom exekvering vanligtvis kräver en fullständig modell.
Så, i den här artikeln tittade vi på funktionerna i fullplattformssimulering, pratade om implementeringshastigheten på olika nivåer, cykel-för-cykel-simulering och spår. I nästa artikel kommer jag att beskriva de viktigaste scenarierna för att använda simulatorer, både för personliga ändamål och ur utvecklingssynpunkt i stora företag.
Källa: will.com
