

Det närmade sig nyår. Barn över hela landet hade redan skickat brev till jultomten eller önskat sig presenter, och deras huvudsakliga leverantör – en av de stora återförsäljarna – förberedde sig för försäljningens storhetstid. I december ökade belastningen på deras datacenter flera gånger. Därför beslutade företaget att modernisera datacentret och ta i drift flera dussin nya servrar för att ersätta utrustning vars livslängd närmade sig sitt slut. Vid denna tidpunkt slutar sagan mot bakgrund av virvlande snöflingor, och en thriller börjar.

Utrustningen anlände till plats flera månader före försäljningstoppen. Driftavdelningen vet naturligtvis hur och vad som ska konfigureras på servrarna för att sätta dem i produktion. Men vi behövde automatisera detta och eliminera den mänskliga faktorn. Dessutom byttes servrarna ut innan vi migrerade en uppsättning SAP-system som var avgörande för företaget.
Lanseringen av de nya servrarna var strikt bunden till deadline. Och att flytta dem innebar att både leveransen av en miljard gåvor och migreringen av system äventyrades. Inte ens ett team bestående av Frost och jultomten kunde ändra datumet – SAP-systemet för lagerhantering kan bara migreras en gång om året. Från 31 december till 1 januari slutar återförsäljarens enorma lager, totalt 20 fotbollsplaner, att fungera i 15 timmar. Och detta är enda gången systemet flyttas. Vi hade ingen rätt att göra ett misstag med lanseringen av servrarna.
Låt mig förtydliga direkt: min berättelse återspeglar den typ av verktyg och konfigurationshanteringsprocess som vårt team använder.
Konfigurationshanteringskomplexet består av flera nivåer. Nyckelkomponenten är CMS-systemet. I industriell drift skulle avsaknaden av en av nivåerna oundvikligen leda till obehagliga mirakel.
Hantera OS-installation
Den första nivån är ett system för att hantera installationen av operativsystem på fysiska och virtuella servrar. Det skapar grundläggande operativsystemkonfigurationer och eliminerar den mänskliga faktorn.
Med detta system fick vi standardiserade och lämpliga serverinstanser med operativsystem för vidare automatisering. Vid "hällningen" fick de en minimiuppsättning lokala användare och publika SSH-nycklar, samt en konsekvent operativsystemkonfiguration. Vi kunde tillförlitligt hantera servrar via CMS och var säkra på att det "nedanför", på OS-nivå, inte fanns några överraskningar.
Det slutgiltiga målet för installationshanteringssystemet är att automatiskt konfigurera servrar från BIOS/firmware-nivå till operativsystemet. Mycket här beror på hårdvaran och konfigurationsuppgifterna. För heterogen hårdvara kan du överväga Om all hårdvara kommer från en och samma leverantör är det ofta mer praktiskt att använda färdiga hanteringsverktyg (till exempel HP ILO Amplifier, DELL OpenManage, etc.).
För att installera operativsystemet på fysiska servrar använde vi det välkända Cobbler, som har en uppsättning installationsprofiler som överenskommits med drifttjänsten. När en ny server lades till i infrastrukturen kopplade ingenjören serverns MAC-adress till den önskade profilen i Cobbler. Vid uppstart över nätverket för första gången fick servern en tillfällig adress och ett nytt operativsystem. Sedan överfördes den till mål-VLAN/IP-adresseringen och fortsatte att arbeta där. Visst, att byta VLAN tar tid och kräver godkännande, men det ger ytterligare skydd mot oavsiktlig installation av servern i en produktionsmiljö.
Vi skapade virtuella servrar baserade på mallar som förberetts med Hashicorp Packer. Anledningen var densamma: att förhindra eventuella mänskliga fel under installationen av operativsystemet. Men till skillnad från fysiska servrar tillåter Packer att man inte använder PXE, nätverksstart och VLAN-växling. Detta gjorde det enklare och enklare att skapa virtuella servrar.
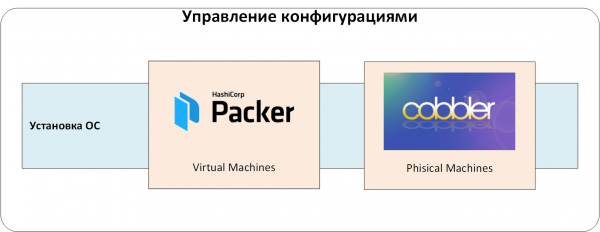
Bild 1. Hantera installationen av operativsystem.
Hemlighetshantering
Alla konfigurationshanteringssystem innehåller data som borde vara dolda för vanliga användare, men som behövs för att förbereda system. Dessa är lösenord för lokala användare och servicekonton, certifikatnycklar, alla möjliga API-tokens etc. De kallas vanligtvis "hemligheter".
Om du inte från början bestämmer var och hur du ska lagra dessa hemligheter, är följande lagringsmetoder sannolikt, beroende på hur strikta informationssäkerhetskraven är:
- direkt i konfigurationshanteringskoden eller i filer i repositoriet;
- i specialiserade konfigurationshanteringsverktyg (t.ex. Ansible Vault);
- i CI/CD-system (Jenkins/TeamCity/GitLab/etc.) eller i konfigurationshanteringssystem (Ansible Tower/Ansible AWX);
- Hemligheter kan också överföras med hjälp av "manuell kontroll". De placeras till exempel på en specifik plats och används sedan av konfigurationshanteringssystem;
- olika kombinationer av ovanstående.
Varje metod har sina egna nackdelar. Den främsta är avsaknaden av policyer för hemlig åtkomst: det är omöjligt eller svårt att avgöra vem som kan använda vissa hemligheter. En annan nackdel är avsaknaden av åtkomstgranskning och en fullständig livscykel. Hur kan man snabbt ersätta till exempel en offentlig nyckel som finns skriven i koden och i ett antal relaterade system?
Vi använde ett centraliserat hemlighetsarkiv, HashiCorp Vault. Detta gjorde det möjligt för oss att:
- Skydda dina hemligheter. De är krypterade, och även om någon får åtkomst till Vault-databasen (till exempel genom att återställa den från en säkerhetskopia) kommer de inte att kunna läsa hemligheterna som lagras där;
- organisera policyer för hemlig åtkomst. Användare och applikationer har endast åtkomst till hemligheter som "tilldelats" dem;
- granska åtkomst till hemligheter. Alla åtgärder med hemligheter registreras i granskningsloggen för valvet;
- organisera en fullständig "livscykel" för att arbeta med hemligheter. De kan skapas, återkallas, sätta ett utgångsdatum, etc.
- enkelt integrera med andra system som behöver tillgång till hemligheter;
- och även använda end-to-end-kryptering, engångslösenord för operativsystemet och databasen, certifikat från auktoriserade center etc.
Nu går vi vidare till det centrala autentiserings- och auktoriseringssystemet. Det var möjligt att klara sig utan det, men att administrera användare i många tillhörande system är alltför enkelt. Vi konfigurerade autentisering och auktorisering via LDAP-tjänsten. Annars skulle vi i samma valv kontinuerligt behöva utfärda och hålla reda på autentiseringstokens för användare. Och att ta bort och lägga till användare skulle bli en uppgift "skapade/tog jag bort det här kontot överallt?".
Vi lägger till ytterligare en nivå i vårt system: hantering av hemligheter och central autentisering/auktorisering:
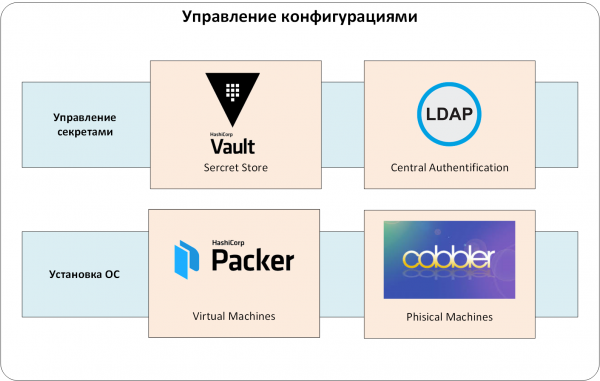
Bild 2. Hemlighetshantering.
Konfigurationshantering
Vi kom till kärnan – CMS-systemet. I vårt fall är det en kombination av Ansible och Red Hat Ansible AWX.
Istället för Ansible kan du använda Chef, Puppet eller SaltStack. Vi valde Ansible baserat på flera kriterier.
- För det första är det universalitet. En uppsättning färdiga moduler för hantering Och om den saknas kan du söka på GitHub och Galaxy.
- För det andra finns det inget behov av att installera och underhålla agenter på den hanterade utrustningen, bevisa att de inte stör belastningen och bekräfta avsaknaden av "bokmärken".
- För det tredje har Ansible en låg tröskel för inträde. En kompetent ingenjör skriver en fungerande handbok bokstavligen redan första dagen de arbetar med produkten.
Men Ansible ensamt räckte inte för oss i en industriell miljö. Annars hade det varit många problem med åtkomstbegränsningar och granskning av administratörers åtgärder. Hur begränsar man åtkomsten? Varje avdelning behövde trots allt hantera (läs: köra Ansibles playbook) "sin" uppsättning servrar. Hur tillåter man att specifika Ansibles playbooks endast körs av vissa anställda? Eller hur spårar man vem som körde playbooken utan att skapa flera lokala konton på servrar och utrustning som kör Ansible?
Red Hat löser lejonparten av sådana problem , eller dess uppströmsprojekt med öppen källkod Det är därför vi valde det för kunden.
Och ytterligare en beskrivning av vårt CMS-system. Ansibles playbook bör lagras i kodhanteringssystem. För oss är det .
Så själva konfigurationerna hanteras av Ansible/Ansible AWX/GitLab-paketet (se Fig. 3). Självklart är AWX/GitLab integrerade med det enhetliga autentiseringssystemet, och Ansibles playbook är integrerad med HashiCorp Vault. Konfigurationer kommer endast in i produktionsmiljön via Ansible AWX, som anger alla "spelregler": vem kan konfigurera vad, var man kan hämta konfigurationshanteringskoden för CMS, etc.
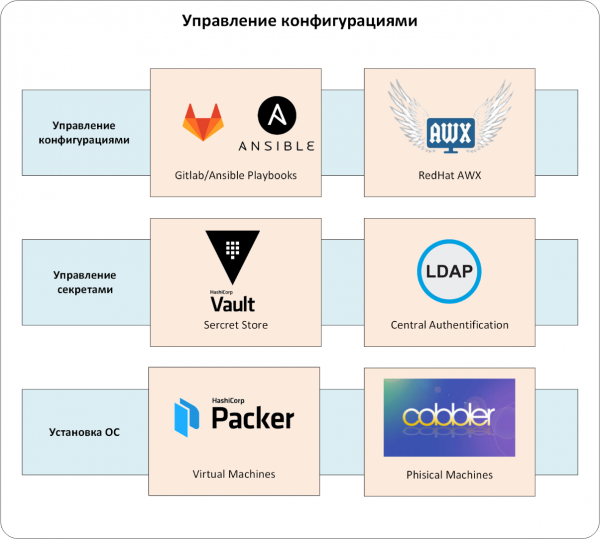
Bild 3. Konfigurationshantering.
Testhantering
Vår konfiguration är i kod. Så vi måste spela efter samma regler som mjukvaruutvecklare. Vi var tvungna att organisera processerna för utveckling, kontinuerlig testning, leverans och tillämpning av konfigurationskod till produktionsservrar.
Om detta inte görs omedelbart kommer rollerna som skrivits för konfigurationen antingen att upphöra att stödjas och modifieras, eller att upphöra att lanseras i produktion. Boten mot denna plåga är känd, och den har bevisat sin betydelse i detta projekt:
- varje roll täcks av enhetstester;
- tester körs automatiskt närhelst det sker en ändring i koden som hanterar konfigurationer;
- Ändringar i konfigurationshanteringskoden skickas endast till produktionsmiljön efter att alla tester och kodgranskningar har slutförts.
Kodutveckling och konfigurationshantering blev lugnare och mer förutsägbar. För att organisera kontinuerlig testning använde vi GitLab CI/CD-verktyg, och som ett ramverk för att organisera tester tog vi .
Närhelst det sker en ändring i konfigurationshanteringskoden anropar GitLab CI/CD Molecule:
- den kontrollerar kodens syntax,
- startar en Docker-container,
- tillämpar den modifierade koden på den skapade behållaren,
- kontrollerar rollen för idempotens och kör tester för denna kod (granulariteten här är på nivån för ansible-rollen, se figur 4).
Vi levererade konfigurationer till produktionsmiljön med hjälp av Ansible AWX. Driftingenjörerna tillämpade konfigurationsändringar med hjälp av fördefinierade mallar. AWX "begärde" automatiskt den senaste versionen av koden från GitLabs huvudgren varje gång den tillämpades. På så sätt uteslöt vi användningen av otestad eller föråldrad kod i produktionsmiljön. Naturligtvis kom koden bara till huvudgrenen efter testning, granskning och godkännande.
Figur 4. Automatisk testning av roller i GitLab CI/CD.
Det finns ett annat problem relaterat till driften av produktionssystem. I verkligheten är det mycket svårt att göra ändringar i konfigurationen enbart via CMS-koden. Det finns nödsituationer där en ingenjör måste ändra konfigurationen "här och nu", utan att vänta på att koden ska redigeras, testas, godkännas etc.
Som ett resultat orsakar manuella ändringar konfigurationsavvikelser på identisk hårdvara (till exempel har HA-klusternoder olika sysctl-inställningskonfigurationer). Eller så skiljer sig den faktiska konfigurationen på hårdvaran från den som anges i CMS-koden.
Därför kontrollerar vi, utöver kontinuerlig testning, produktionsmiljöer för konfigurationsavvikelser. Vi valde det enklaste alternativet: att köra CMS-konfigurationskoden i "dry run"-läge, dvs. utan att tillämpa ändringar, men med meddelande om alla avvikelser mellan den planerade och verkliga konfigurationen. Vi implementerade detta genom att regelbundet köra alla Ansible-playbooks med alternativet "--check" på produktionsservrar. Som alltid ansvarar Ansible AWX för att köra och hålla playbooken uppdaterad (se figur 5):
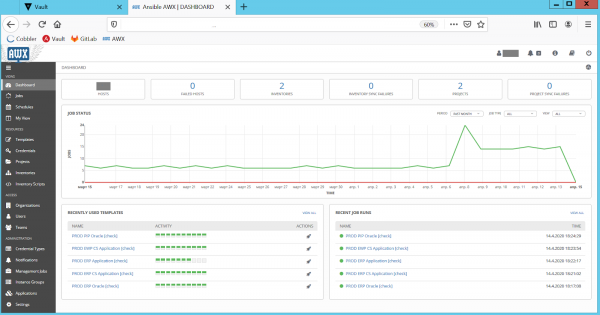
Bild 5. Kontrollerar konfigurationsavvikelser i Ansible AWX.
Efter kontrollerna skickar AWX en avvikelserapport till administratörerna. De undersöker den problematiska konfigurationen och åtgärdar den sedan via justerade playbooks. På så sätt upprätthåller vi konfigurationen i produktionsmiljön och CMS:et är alltid uppdaterat och synkroniserat. Detta eliminerar obehagliga "mirakel" när CMS-koden tillämpas på "produktions"-servrar.
Vi har nu ett betydande testlager bestående av Ansible AWX/GitLab/Molecule (Figur 6).
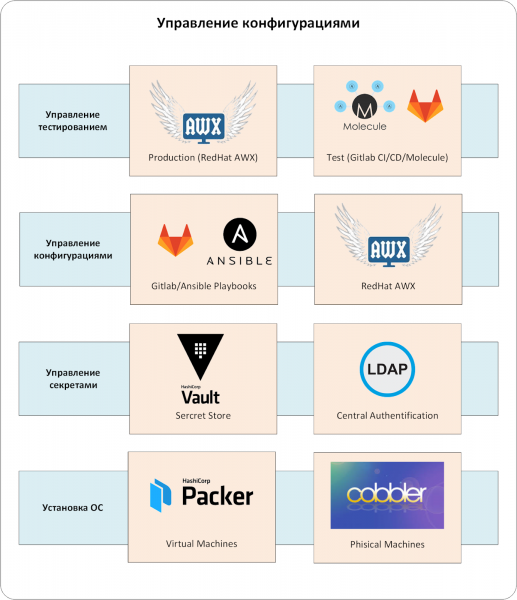
Bild 6. Testhantering.
Är det komplicerat? Jag argumenterar inte. Men ett sådant komplext konfigurationshanteringssystem har blivit ett uttömmande svar på många frågor relaterade till automatisering av serverkonfiguration. Nu har återförsäljaren alltid en strikt definierad konfiguration för typiska servrar. CMS:et, till skillnad från en ingenjör, kommer inte att glömma att lägga till nödvändiga inställningar, skapa användare och utföra dussintals eller hundratals obligatoriska inställningar.
Det finns ingen "hemlig kunskap" i server- och miljöinställningar idag. Alla nödvändiga funktioner återspeglas i handboken. Ingen mer kreativitet och vaga instruktioner: "Installera det som ett vanligt Oracle, men du behöver registrera ett par sysctl-inställningar och lägga till användare med det nödvändiga UID:t. Fråga killarna från drift, de vet.".
Möjligheten att upptäcka konfigurationsavvikelser och åtgärda dem tidigt ger sinnesro. Utan ett konfigurationshanteringssystem ser detta oftast annorlunda ut. Problemen ackumuleras tills de en dag "skjuter igång" i produktionen. Sedan gör de en utvärdering, kontrollerar och åtgärdar konfigurationer. Och cykeln upprepas igen.
Och naturligtvis har vi snabbat upp lanseringen av servrar från några dagar till timmar.
Och på självaste nyårsafton, när barn glatt packade upp presenter och vuxna önskade sig något under klockspelet, migrerade våra ingenjörer SAP-systemet till nya servrar. Till och med jultomten säger att de bästa miraklen är väl förberedda.
P.S. Vårt team stöter ofta på att kunder vill lösa konfigurationshanteringsuppgifter så enkelt som möjligt. Helst, som genom magi – med ett enda verktyg. Men i livet är allt mer komplicerat (ja, återigen, de hade inga magiska lösningar): man måste skapa en hel process med hjälp av verktyg som är praktiska för kundens team.
Författare: Sergey Artemov, avdelningsarkitekt "Jet Infosystems"
Källa: will.com
