

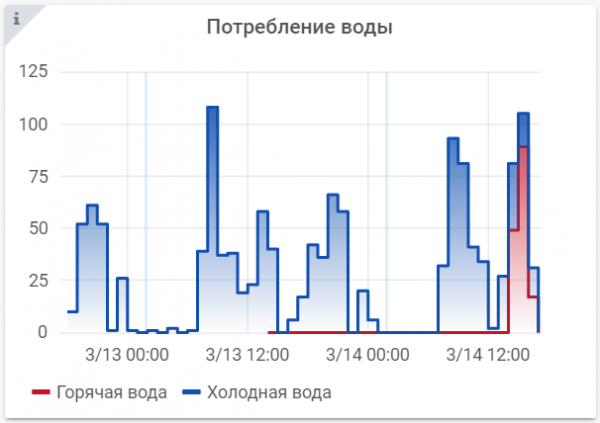
Varje gång jag får betalt för el och vatten blir jag förvånad – förbrukar min familj verkligen så mycket? Tja, ja, badrummet har ett golvvärme och en panna, men de brinner inte hela tiden. Vi verkar också spara vatten (även om vi också gillar att plaska runt i badrummet). För flera år sedan jag redan и till ett smart hem, men det var där saker och ting fastnade. Vi har först nu kommit igång med att analysera konsumtion, vilket är vad den här artikeln faktiskt handlar om.
Jag bytte nyligen till Home Assistant som mitt smarta hemsystem. En av anledningarna var just möjligheten att organisera insamlingen av en stor mängd data med möjligheten att bekvämt konstruera olika typer av grafer.
Informationen som beskrivs i den här artikeln är inte ny; alla dessa saker under olika såser har redan beskrivits på Internet. Men varje artikel beskriver vanligtvis bara ett tillvägagångssätt eller aspekt. Jag var tvungen att jämföra alla dessa metoder och själv välja den lämpligaste. Artikeln ger fortfarande ingen heltäckande information om datainsamling, utan är en slags sammanfattning av hur jag gjorde. Så konstruktiv kritik och förslag på förbättringar är välkomna.
Problem uttalande
Så målet med dagens övning är att få vackra grafer över vatten- och elförbrukning:
- Varje timme i 2 dagar
- Dagligen i 2 veckor
- (valfritt) veckovis och månadsvis
Det finns några svårigheter med detta:
- Standarddiagramkomponenter är vanligtvis ganska dåliga. I bästa fall kan du bygga ett linjediagram punkt för punkt.
Om du letar tillräckligt noga kan du hitta tredjepartskomponenter som utökar kapaciteten hos standarddiagrammet. För en hemassistent är detta i princip en bra och vacker komponent , men det är också något begränsat:
- Det är svårt att ställa in parametrarna för ett stapeldiagram över stora intervall (stapelns bredd ställs in i bråkdelar av en timme, vilket innebär att intervall längre än en timme kommer att anges i bråktal)
- Du kan inte lägga till olika enheter i en graf (till exempel temperatur och luftfuktighet, eller kombinera ett stapeldiagram med en linje)
- Hemassistenten använder inte bara som standard den mest primitiva SQLite-databasen (och jag, en hantlangare, kunde inte hantera installationen av MySQL eller Postgres), utan data lagras inte på det mest optimala sättet. Så, till exempel, varje gång du ändrar även den minsta digitala parametern i en parameter, skrivs en enorm json på cirka en kilobyte till databasen
{"entity_id": "sensor.water_cold_hourly", "old_state": {"entity_id": "sensor.water_cold_hourly", "state": "3", "attributes": {"source": "sensor.water_meter_cold", "status": "collecting", "last_period": "29", "last_reset": "2020-02-23T21:00:00.022246+02:00", "meter_period": "hourly", "unit_of_measurement": "l", "friendly_name": "water_cold_hourly", "icon": "mdi:counter"}, "last_changed": "2020-02-23T19:05:06.897604+00:00", "last_updated": "2020-02-23T19:05:06.897604+00:00", "context": {"id": "aafc8ca305ba4e49ad4c97f0eddd8893", "parent_id": null, "user_id": null}}, "new_state": {"entity_id": "sensor.water_cold_hourly", "state": "4", "attributes": {"source": "sensor.water_meter_cold", "status": "collecting", "last_period": "29", "last_reset": "2020-02-23T21:00:00.022246+02:00", "meter_period": "hourly", "unit_of_measurement": "l", "friendly_name": "water_cold_hourly", "icon": "mdi:counter"}, "last_changed": "2020-02-23T19:11:11.251545+00:00", "last_updated": "2020-02-23T19:11:11.251545+00:00", "context": {"id": "0de64b8af6f14bb9a419dcf3b200ef56", "parent_id": null, "user_id": null}}}Jag har ganska många sensorer (temperatursensorer i varje rum, vatten- och elmätare), och en del genererar även ganska mycket data. Till exempel genererar enbart elmätaren SDM220 ungefär ett dussin värden var 10-15:e sekund, och jag skulle vilja installera ungefär 8 sådana mätare. Det finns också en hel massa parametrar som beräknas utifrån andra sensorer. Den där. alla dessa värden kan enkelt blåsa upp databasen med 100-200 MB dagligen. Om en vecka kommer systemet knappt att röra sig, och om en månad kommer flashenheten att dö (när det gäller en typisk hemassistentinstallation på en Raspberry PI), och att lagra data under ett helt år är uteslutet.
- Om du har tur kan din mätare själv räkna förbrukningen. Du kan vända dig till mätaren när som helst och fråga vilken tid det ackumulerade förbrukningsvärdet är. I regel ger alla elmätare som har digitalt gränssnitt (RS232/RS485/Modbus/Zigbee) denna möjlighet.
Det är värre om enheten helt enkelt kan mäta någon momentan parameter (till exempel momentan effekt eller ström), eller helt enkelt generera pulser var X wattimme eller liter. Sedan måste du fundera på hur och med vad du ska integrera det och var du ska samla värde. Det finns en risk att missa nästa rapport av någon anledning, och riktigheten i systemet som helhet väcker frågor. Du kan naturligtvis anförtro allt detta till ett smart hemsystem som hemassistent, men ingen har avbrutit punkten om antalet poster i databasen, och det kommer inte att vara möjligt att polla sensorer mer än en gång i sekunden (a begränsning av hemassistentarkitekturen).
Tillvägagångssätt 1
Låt oss först se vad hemassistenten tillhandahåller direkt. Att mäta förbrukning över en period är en mycket eftertraktad funktionalitet. Naturligtvis implementerades det för länge sedan i form av en specialiserad komponent - utility_meter.
Kärnan i komponenten är att den internt skapar ett variabelt current_accumulated_value och återställer det efter en angiven period (timme/vecka/månad). Komponenten själv övervakar ingångsvariabeln (värdet av någon sensor), abonnerar på förändringar i värdet - du får bara det färdiga resultatet. Denna sak beskrivs på bara några rader i konfigurationsfilen
utility_meter:
water_cold_hour_um:
source: sensor.water_meter_cold
cycle: hourly
water_cold_day_um:
source: sensor.water_meter_cold
cycle: daily
Här är sensor.water_meter_cold det aktuella mätarvärdet i liter som jag får av mqtt. Designen skapar 2 nya sensorer water_cold_hour_um och water_cold_day_um, som ackumulerar tim- och dagliga avläsningar och återställer dem till noll efter att perioden har löpt ut. Här är en graf över timbatteriet för en halv dag.
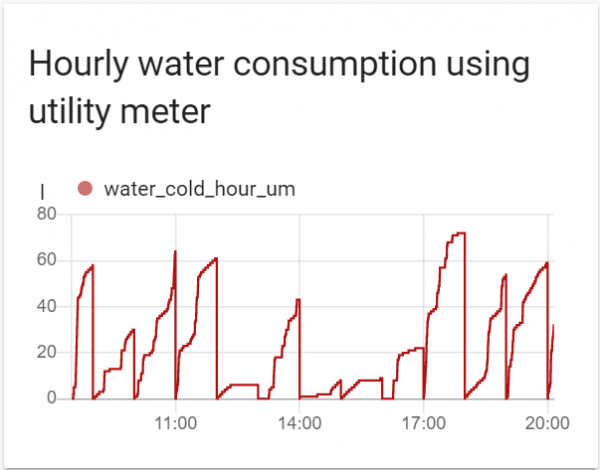
Koden för tim- och dagliga diagram för lovelace-UI ser ut så här:
- type: history-graph
title: 'Hourly water consumption using vars'
hours_to_show: 48
entities:
- sensor.water_hour
- type: history-graph
title: 'Daily water consumption using vars'
hours_to_show: 360
entities:
- sensor.water_day
Faktum är att problemet med detta tillvägagångssätt ligger i denna algoritm. Som jag redan nämnt, för varje ingångsvärde (aktuell mätarställning för varje nästa liter) genereras 1kb poster i databasen. Varje nyttomätare genererar också ett nytt värde, som också läggs till basen. Om jag vill samla in avläsningar varje timme/dag/vecka/månad, och för flera vattenhöjare, och lägga till ett paket elmätare så blir det mycket data. Tja, mer exakt finns det inte mycket data, men eftersom hemassistenten skriver en massa onödig information till databasen kommer storleken på databasen att växa med stormsteg. Jag är rädd att ens uppskatta storleken på basen för vecko- och månadsdiagram.
Dessutom löser inte mätaren i sig problemet problemet. Grafen över värdena som produceras av verktygsmätaren är en monotont ökande funktion som återställs till 0 varje timme. Vi behöver ett förbrukningsdiagram som är begripligt för användaren, som visar hur många liter som förbrukats under perioden. Standardhistoria-grafkomponenten kan inte göra detta, men minigrafkorts externa komponent kan hjälpa oss.
Detta är kortkoden för lovelace-UI:
- aggregate_func: max
entities:
- color: var(--primary-color)
entity: sensor.water_cold_hour_um
group_by: hour
hours_to_show: 48
name: "Hourly water consumption aggregated by utility meter"
points_per_hour: 1
show:
graph: bar
type: 'custom:mini-graph-card'Förutom standardinställningar som sensornamn, graftyp, färg (jag gillade inte standardorange), är det viktigt att notera 3 inställningar:
- group_by:hour — grafen kommer att genereras med staplarna i linje med början av timmen
- points_per_hour: 1 - en stapel för varje timme
- Och viktigast av allt, aggregate_func: max - ta maxvärdet inom varje timme. Det är denna parameter som förvandlar sågtandsgrafen till staplar
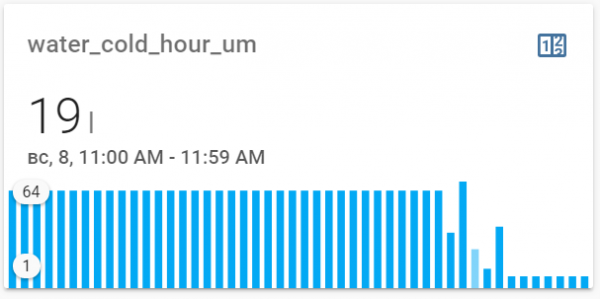
Var inte uppmärksam på raden med kolumner till vänster - det här är standardbeteendet för komponenten om det inte finns några data. Men det fanns inga data - jag aktiverade bara datainsamling av mätare för ett par timmar sedan bara för den här artikelns skull (jag kommer att beskriva mitt nuvarande tillvägagångssätt nedan).
På den här bilden ville jag visa att ibland fungerar datavisningen till och med och staplarna reflekterar faktiskt de korrekta värdena. Men det är inte allt. Av någon anledning visar den valda kolumnen för perioden 11-12 på morgonen 19 liter, även om vi på den tandade grafen lite högre för samma period från samma sensor ser en förbrukning på 62 liter. Antingen finns det en bugg eller så är händerna sneda. Men jag förstår fortfarande inte varför data till höger bröts - förbrukningen där var normal, vilket också syns från den tandiga grafen.
I allmänhet kunde jag inte uppnå rimligheten i detta tillvägagångssätt - grafen visar nästan alltid någon form av kätteri.
Liknande kod för dagtidssensorn.
- aggregate_func: max
entities:
- color: var(--primary-color)
entity: sensor.water_cold_day_um
group_by: interval
hours_to_show: 360
name: "Daily water consumption aggregated by utility meter"
points_per_hour: 0.0416666666
show:
graph: bar
type: 'custom:mini-graph-card'
Observera att parametern group_by är inställd på intervall, och parametern points_per_hour reglerar allt. Och däri ligger ett annat problem med den här komponenten - points_per_hour fungerar bra på diagram på en timme eller mindre, men det suger på större intervall. Så för att få en kolumn på en dag var jag tvungen att ange värdet 1/24=0.04166666. Jag pratar inte ens om vecko- och månadsdiagram.
Tillvägagångssätt 2
Medan jag fortfarande förstår hemassistenten stötte jag på den här videon:

En vän samlar in förbrukningsdata från flera typer av Xiaomi-uttag. Hans uppgift är lite enklare - visa helt enkelt förbrukningsvärdet för idag, igår och för månaden. Inga scheman krävs.
Låt oss lämna åt sidan diskussioner om manuell integrering av momentana effektvärden - jag skrev redan ovan om "noggrannheten" i detta tillvägagångssätt. Det är inte klart varför han inte använde de ackumulerade förbrukningsvärdena, som redan samlats in av samma butik. Enligt min åsikt kommer integration inuti hårdvaran att fungera bättre.
Från videon kommer vi att ta tanken på att manuellt räkna förbrukningen under en period. Killen räknar bara värdena för idag och igår, men vi kommer att gå längre och försöka rita en graf. Kärnan i den föreslagna metoden i mitt fall är följande.
Låt oss skapa ett variabelvärde_i_timmens_start, där vi kommer att registrera de aktuella mätaravläsningarna
Med hjälp av timern, i slutet av timmen (eller i början av nästa) beräknar vi skillnaden mellan den aktuella avläsningen och den som lagras i början av timmen. Denna skillnad kommer att vara förbrukningen för den aktuella timmen - vi kommer att spara värdet i sensorn, och i framtiden kommer vi att bygga en graf baserad på detta värde.
Du måste också "återställa" variabeln value_at_beginning_of_hour genom att skriva det aktuella räknarvärdet där.
Allt detta kan göras genom hemassistenten själv.
Du kommer att behöva skriva lite mer kod än i den tidigare metoden. Låt oss först skapa samma "variabler". Utanför lådan har vi inte den "variable" enheten, men vi kan använda tjänsterna från mqtt-mäklaren. Vi kommer att skicka värden dit med flaggan retain=true - detta sparar värdet inuti mäklaren, och det kan dras därifrån när som helst, även när hemassistenten startas om. Jag gjorde tim- och dagsräknare på en gång.
- platform: mqtt
state_topic: "test/water/hour"
name: water_hour
unit_of_measurement: l
- platform: mqtt
state_topic: "test/water/hour_begin"
name: water_hour_begin
unit_of_measurement: l
- platform: mqtt
state_topic: "test/water/day"
name: water_day
unit_of_measurement: l
- platform: mqtt
state_topic: "test/water/day_begin"
name: water_day_begin
unit_of_measurement: lAll magi sker i automatiseringen, som går varje timme respektive varje natt.
- id: water_new_hour
alias: water_new_hour
initial_state: true
trigger:
- platform: time_pattern
minutes: 0
action:
- service: mqtt.publish
data:
topic: "test/water/hour"
payload_template: >
{{ (states.sensor.water_meter_cold.state|int) - (states.sensor.water_hour_begin.state|int) }}
retain: true
- service: mqtt.publish
data:
topic: "test/water/hour_begin"
payload_template: >
{{ states.sensor.water_meter_cold.state }}
retain: true
- id: water_new_day
alias: water_new_day
initial_state: true
trigger:
- platform: time
at: "00:00:00"
action:
- service: mqtt.publish
data:
topic: "test/water/day"
payload_template: >
{{ (states.sensor.water_meter_cold.state|int) - (states.sensor.water_day_begin.state|int) }}
retain: true
- service: mqtt.publish
data:
topic: "test/water/day_begin"
payload_template: >
{{ states.sensor.water_meter_cold.state }}
retain: trueBåda automatiseringarna utför 2 åtgärder:
- Beräkna värdet för ett intervall som skillnaden mellan start- och slutvärden
- Uppdatera basvärdet för nästa intervall
Konstruktionen av grafer i detta fall löses med den vanliga historiegrafen:
- type: history-graph
title: 'Hourly water consumption using vars'
hours_to_show: 48
entities:
- sensor.water_hour
- type: history-graph
title: 'Daily water consumption using vars'
hours_to_show: 360
entities:
- sensor.water_dayDet ser ut så här:
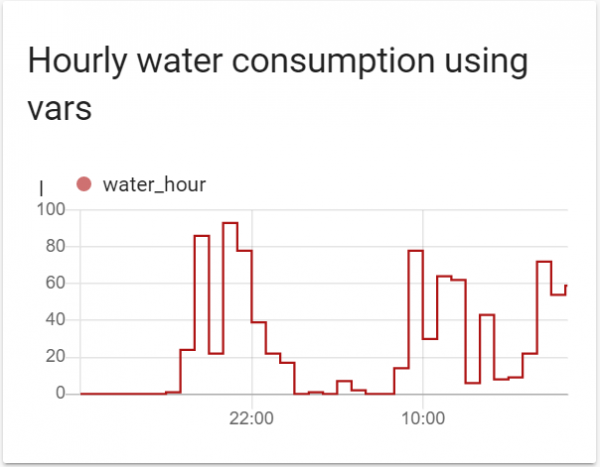
I princip är detta redan vad som behövs. Fördelen med denna metod är att data genereras en gång per intervall. De där. endast 24 poster per dag för ett timdiagram.
Tyvärr löser detta fortfarande inte det allmänna problemet med en växande bas. Om jag vill ha en månatlig förbrukningsgraf måste jag lagra data i minst ett år. Och eftersom hemassistenten endast tillhandahåller en inställning av lagringstid för hela databasen, innebär det att ALL data i systemet måste lagras under ett helt år. Till exempel, på ett år förbrukar jag 200 kubikmeter vatten, vilket betyder att det innebär 200000 XNUMX poster i databasen. Och om du tar hänsyn till andra sensorer, blir siffran i allmänhet oanständig.
Tillvägagångssätt 3
Lyckligtvis har smarta människor redan löst detta problem genom att skriva databasen InfluxDB. Denna databas är speciellt optimerad för att lagra tidsbaserad data och är idealisk för att lagra värden för olika sensorer. Systemet tillhandahåller också ett SQL-liknande frågespråk som låter dig extrahera värden från databasen och sedan aggregera dem på olika sätt. Slutligen kan olika data lagras för olika tider. Till exempel kan avläsningar som ofta ändras, som temperatur eller luftfuktighet, lagras i bara ett par veckor, medan den dagliga vattenförbrukningen kan lagras under ett helt år.
Förutom InfluxDB uppfann smarta människor även Grafana, ett system för att rita grafer baserat på data från InfluxDB. Grafana kan rita olika typer av grafer, anpassa dem i detalj och, viktigast av allt, dessa grafer kan "anslutas" till lovelace-UI-hemassistenten.
Bli inspirerad и . Artiklarna beskriver i detalj processen med att installera och koppla InfluxDB och Grafana till hemassistenten. Jag kommer att fokusera på att lösa mitt specifika problem.
Så, först och främst, låt oss börja lägga till räknarvärdet i influxDB. En del av hemassistentens konfiguration (i det här exemplet kommer jag att ha kul med inte bara kallt utan också varmt vatten):
influxdb:
host: localhost
max_retries: 3
default_measurement: state
database: homeassistant
include:
entities:
- sensor.water_meter_hot
- sensor.water_meter_coldLåt oss inaktivera att spara samma data i den interna hemassistentdatabasen för att inte blåsa upp den igen:
recorder:
purge_keep_days: 10
purge_interval: 1
exclude:
entities:
- sensor.water_meter_hot
- sensor.water_meter_coldLåt oss nu gå till InfluxDB-konsolen och konfigurera vår databas. I synnerhet måste du konfigurera hur länge viss data kommer att lagras. Detta regleras av den sk. retention policy - detta liknar databaser inom en huvuddatabas, där varje intern databas har sina egna inställningar. Som standard lagras all data i en lagringspolicy som kallas autogen; denna data kommer att lagras i en vecka. Jag skulle vilja att timdata bevaras i en månad, veckodata bevaras i ett år och månadsdata aldrig raderas. Låt oss skapa en lämplig lagringspolicy
CREATE RETENTION POLICY "month" ON "homeassistant" DURATION 30d REPLICATION 1
CREATE RETENTION POLICY "year" ON "homeassistant" DURATION 52w REPLICATION 1
CREATE RETENTION POLICY "infinite" ON "homeassistant" DURATION INF REPLICATION 1Nu, i själva verket, är det huvudsakliga tricket dataaggregering med hjälp av kontinuerlig fråga. Detta är en mekanism som automatiskt kör en fråga med angivna intervall, aggregerar data för denna fråga och lägger till resultatet i ett nytt värde. Låt oss titta på ett exempel (jag skriver i en kolumn för läsbarhet, men i verkligheten var jag tvungen att ange det här kommandot på en rad)
CREATE CONTINUOUS QUERY cq_water_hourly ON homeassistant
BEGIN
SELECT max(value) AS value
INTO homeassistant.month.water_meter_hour
FROM homeassistant.autogen.l
GROUP BY time(1h), entity_id fill(previous)
ENDDetta kommando:
- Skapar en kontinuerlig fråga med namnet cq_water_cold_hourly i hemassistentdatabasen
- Begäran kommer att utföras varje timme (tid(1h))
- Begäran kommer att skrapa alla data från mätningens homeassistant.autogen.l (liter), inklusive kall- och varmvattenavläsningar
- Den aggregerade informationen kommer att grupperas efter entity_id, vilket ger oss separata värden för kallt och varmt vatten
- Eftersom literräknaren är en monotont ökande sekvens inom varje timme, kommer det att vara nödvändigt att ta maxvärdet, så aggregering kommer att utföras av funktionen max(värde)
- Det nya värdet kommer att skrivas till homeassistant.month.water_meter_hour, där månad är namnet på lagringspolicyn med en lagringstid på en månad. Dessutom kommer data om kallt och varmt vatten att spridas i separata poster med motsvarande entity_id och värde i värdefältet
På natten eller när ingen är hemma är det ingen vattenförbrukning, och därför finns det inga nya poster i homeassistant.autogen.l. För att undvika att sakna värden i vanliga frågor kan du använda fyll (föregående). Detta kommer att tvinga InfluxDB att använda värdet för den senaste timmen.
Tyvärr har kontinuerlig sökning en egenhet: fill(föregående)-tricket fungerar inte och poster skapas helt enkelt inte. Dessutom är detta något slags oöverstigligt problem . Vi kommer att ta itu med det här problemet senare, men låt fill(föregående) vara i den kontinuerliga frågan - det stör inte.
Låt oss kolla vad som hände (du måste naturligtvis vänta ett par timmar):
> select * from homeassistant.month.water_meter_hour group by entity_id
...
name: water_meter_hour
tags: entity_id=water_meter_cold
time value
---- -----
...
2020-03-08T01:00:00Z 370511
2020-03-08T02:00:00Z 370513
2020-03-08T05:00:00Z 370527
2020-03-08T06:00:00Z 370605
2020-03-08T07:00:00Z 370635
2020-03-08T08:00:00Z 370699
2020-03-08T09:00:00Z 370761
2020-03-08T10:00:00Z 370767
2020-03-08T11:00:00Z 370810
2020-03-08T12:00:00Z 370818
2020-03-08T13:00:00Z 370827
2020-03-08T14:00:00Z 370849
2020-03-08T15:00:00Z 370921
Observera att värdena i databasen lagras i UTC, så denna lista skiljer sig med 3 timmar - 7am-värdena i InfluxDB-utgången motsvarar 10am-värdena i graferna ovan. Observera också att mellan 2 och 5 finns det helt enkelt inga poster - detta är samma funktion för kontinuerlig sökning.
Som du kan se är det aggregerade värdet också en monotont ökande sekvens, endast inmatningar sker mer sällan - en gång i timmen. Men detta är inget problem - vi kan skriva en annan fråga som kommer att hämta rätt data för grafen.
SELECT difference(max(value))
FROM homeassistant.month.water_meter_hour
WHERE entity_id='water_meter_cold' and time >= now() -24h
GROUP BY time(1h), entity_id
fill(previous)Jag ska dechiffrera:
- Från databasen homeassistant.month.water_meter_hour kommer vi att extrahera data för entity_id='water_meter_cold' för den sista dagen (tid >= nu() -24h).
- Som jag redan nämnt kan vissa poster saknas i sekvensen homeassistant.month.water_meter_hour. Vi kommer att återskapa denna data genom att köra en fråga med GROUP BY time(1h). Denna tidsfyllning (föregående) kommer att fungera som förväntat och genererar de saknade data (funktionen tar det tidigare värdet)
- Det viktigaste i denna begäran är skillnadsfunktionen, som beräknar skillnaden mellan timmärken. Det fungerar inte på egen hand och kräver en aggregeringsfunktion. Låt detta vara max() som användes tidigare.
Utföranderesultatet ser ut så här
name: water_meter_hour
tags: entity_id=water_meter_cold
time difference
---- ----------
...
2020-03-08T02:00:00Z 2
2020-03-08T03:00:00Z 0
2020-03-08T04:00:00Z 0
2020-03-08T05:00:00Z 14
2020-03-08T06:00:00Z 78
2020-03-08T07:00:00Z 30
2020-03-08T08:00:00Z 64
2020-03-08T09:00:00Z 62
2020-03-08T10:00:00Z 6
2020-03-08T11:00:00Z 43
2020-03-08T12:00:00Z 8
2020-03-08T13:00:00Z 9
2020-03-08T14:00:00Z 22
2020-03-08T15:00:00Z 72Från 2 till 5 på morgonen (UTC) fanns ingen konsumtion. Ändå kommer frågan att returnera samma förbrukningsvärde tack vare fill(föregående), och skillnadsfunktionen kommer att subtrahera detta värde från sig själv och utdata blir 0, vilket är exakt vad som krävs.
Allt som återstår är att bygga en graf. För att göra detta, öppna Grafana, öppna någon befintlig (eller skapa en ny) instrumentpanel och skapa en ny panel. Diagraminställningarna blir så här.
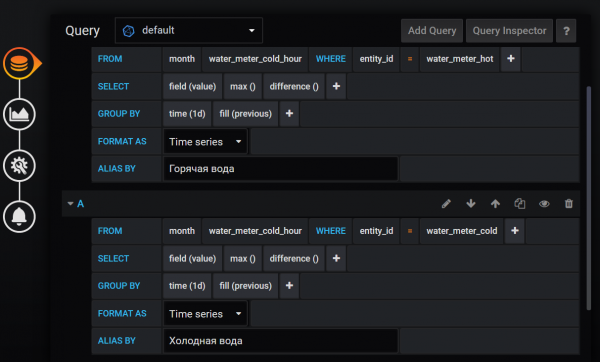
Jag kommer att visa kall- och varmvattendata på samma graf. Begäran är exakt densamma som jag beskrev ovan.
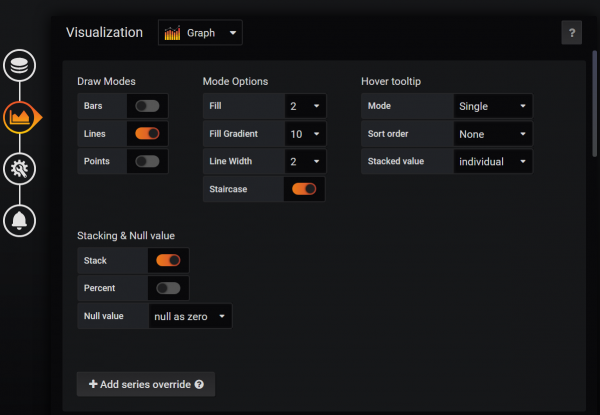
Displayparametrar ställs in enligt följande. För mig blir det en graf med linjer, som går i steg (trappor). Jag ska förklara Stack-parametern nedan. Det finns ett par fler visningsalternativ nedan, men de är inte så intressanta.
För att lägga till det resulterande diagrammet till hemassistenten måste du:
- avsluta diagramredigeringsläget. Av någon anledning erbjuds de korrekta diagramdelningsinställningarna endast från instrumentpanelsidan
- Klicka på triangeln bredvid diagramnamnet och välj dela från menyn
- I fönstret som öppnas, gå till inbäddningsfliken
- Avmarkera det aktuella tidsintervallet - vi ställer in tidsintervallet via URL
- Välj önskat ämne. I mitt fall är det lätt
- Kopiera den resulterande webbadressen till inställningskortet för lovelace-UI
- type: iframe
id: graf_water_hourly
url: "http://192.168.10.200:3000/d-solo/rZARemQWk/water?orgId=1&panelId=2&from=now-2d&to=now&theme=light"
Observera att tidsintervallet (senaste 2 dagarna) ställs in här och inte i instrumentpanelens inställningar.
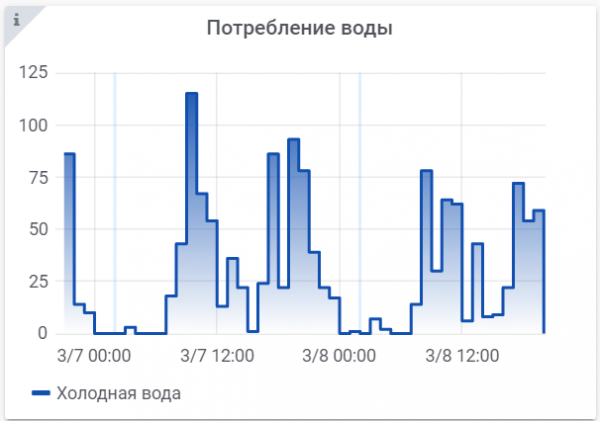
Grafen ser ut så här. Jag har inte använt varmt vatten under de senaste 2 dagarna, så bara kallvattendiagrammet ritas.
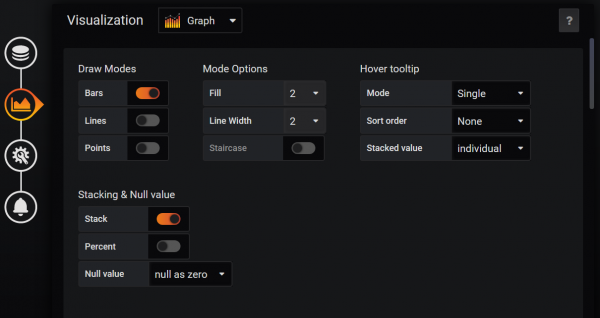
Jag har fortfarande inte själv bestämt vilken graf jag gillar bäst, ett linjesteg eller riktiga staplar. Därför ska jag helt enkelt ge ett exempel på ett dagligt konsumtionsdiagram, bara denna gång i staplar. Frågor är konstruerade på liknande sätt som de som beskrivs ovan. Visningsalternativen är:
Den här grafen ser ut så här:
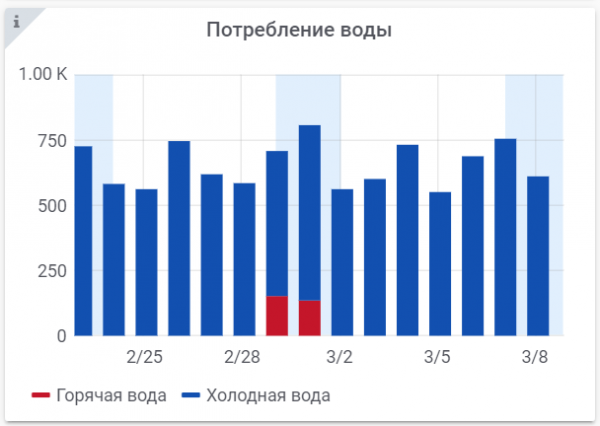
Så om Stack-parametern. I denna graf ritas en kolonn med kallt vatten ovanpå en kolonn med varmt vatten. Den totala höjden motsvarar den totala förbrukningen av kallt och varmvatten för perioden.
Alla grafer som visas är dynamiska. Du kan föra musen över den intressanta punkten och se detaljerna och värdet vid en specifik punkt.
Tyvärr blev det ett par fluga i salvan. På ett stapeldiagram (till skillnad från ett diagram med steglinjer) är mitten av stapeln inte mitt på dagen, utan klockan 00:00. De där. den vänstra halvan av kolumnen ritas i stället för föregående dag. Så graferna för lördag och söndag är ritade något till vänster om den blåaktiga zonen. Tills jag kom på hur jag skulle besegra den.
Ett annat problem är oförmågan att arbeta ordentligt med månatliga intervaller. Faktum är att längden på timmen/dagen/veckan är fast, men månadens längd är olika varje gång. InfluxDB kan bara fungera med lika intervall. Hittills har mina hjärnor räckt till att ställa in ett fast intervall på 30 dagar. Ja, grafen kommer att flyta lite under hela året och staplarna kommer inte exakt att motsvara månaderna. Men eftersom jag är intresserad av den här saken helt enkelt som en displaymätare, är jag okej med det.
Jag ser minst två lösningar:
- Ge upp på månatliga diagram och begränsa dig till veckovisa. 52 veckobarer för året ser ganska bra ut
- Betrakta månadskonsumtionen själv som metod nr 2, och använd grafana endast för vackra grafer. Det blir en ganska exakt lösning. Du kan till och med lägga över grafer för det senaste året för jämförelse - grafana kan också göra det.
Slutsats
Jag vet inte varför, men jag är besatt av den här typen av grafer. De visar att livet är i full gång och allt förändras. Igår var det mycket, idag är det lite, imorgon blir det något annat. Allt som återstår är att arbeta med hushållsmedlemmar kring ämnet konsumtion. Men även med nuvarande aptit förvandlas bara en stor och obegriplig siffra på inbetalningskorten redan till en ganska förståelig bild av konsumtionen.
Trots min nästan 20-åriga karriär som programmerare hade jag praktiskt taget ingen kontakt med databaser. Att installera en extern databas verkade därför vara något så abstrut och obegripligt. Ändrade allt — det visade sig att montering av ett lämpligt verktyg görs med ett par klick, och med ett specialiserat verktyg blir uppgiften att rita diagram lite lättare.
I rubriken nämnde jag elförbrukning. Tyvärr kan jag för närvarande inte tillhandahålla några grafer. En SDM120-meter dog för mig, och den andra är glitchy när den nås via Modbus. Detta påverkar dock inte ämnet för denna artikel på något sätt - graferna kommer att konstrueras på samma sätt som för vatten.
I den här artikeln presenterade jag de tillvägagångssätt som jag själv provat. Det finns säkert några andra sätt att organisera datainsamling och visualisering som jag inte vet om. Berätta för mig om det i kommentarerna, jag kommer att vara mycket intresserad. Jag tar gärna emot konstruktiv kritik och nya idéer. Jag hoppas att materialet som presenteras också kommer att hjälpa någon.
Källa: will.com
