


Netflix är ledande på marknaden för internet-tv – företaget som skapade och aktivt utvecklar detta segment. Netflix är känt inte bara för sin stora katalog av filmer och TV-program som är tillgängliga från nästan alla hörn av planeten och alla enheter med skärm, utan också för sin robusta infrastruktur och unika ingenjörskultur.
Netflix illustrativa exempel på deras tillvägagångssätt för att utveckla och stödja komplexa system presenterades på DevOops 2019. — Utvecklingschef på Netflix. Examen från fakulteten för beräkningsmatematik och cybernetik vid Nizjnij Novgorods statliga universitet. Lobachevsky, Sergey är en av de första ingenjörerna i Open Connect - CDN-teamet på Netflix. Han byggde system för övervakning och analys av videodata, lanserade den populära internethastighetstesttjänsten FAST.com och har de senaste åren arbetat med att optimera internetförfrågningar för att Netflix-appen ska fungera så snabbt som möjligt för användarna.
Rapporten fick utmärkta recensioner från konferensdeltagarna, och vi har förberett en textversion åt dig.

I sin rapport talade Sergej i detalj
- om vad som påverkar fördröjningen av internetförfrågningar mellan klienten och servern;
- hur man kan minska denna fördröjning;
- hur man designar, underhåller och övervakar feltoleranta system;
- hur man uppnår resultat på kort tid och med minimal risk för verksamheten;
- hur man analyserar resultat och lär sig av misstag.
Svar på dessa frågor behövs inte bara av de som arbetar i stora företag.
De principer och tekniker som presenteras bör vara kända till och praktiserade av alla som utvecklar och stöder internetprodukter.
Följande är en berättelse ur talarens perspektiv.
Vikten av internethastighet
Hastigheten på internetförfrågningar är direkt relaterad till verksamheten. Tänk på shoppingvärlden: Amazon år 2009 , att en fördröjning på 100 ms resulterar i en försäljningsförlust på 1 %.
Det finns fler och fler mobila enheter, och mobila webbplatser och applikationer följer dem. Om det tar längre tid än 3 sekunder för din sida att ladda förlorar du ungefär hälften av dina användare. MED Google tar hänsyn till hur snabbt din sida laddas i sökresultaten: ju snabbare sidan är, desto högre upp i Googles position.
Anslutningshastighet är också viktig i finansinstitut där latens är avgörande. År 2015, Hibernia Networks en kabel värd 400 miljoner dollar mellan New York och London för att minska latensen mellan städerna med 6 ms. Tänk dig 66 miljoner dollar för 1 ms latensreducering!
Enligt , anslutningshastigheter över 5 Mbps påverkar inte längre direkt laddningshastigheten för en typisk webbplats. Det finns dock ett linjärt samband mellan anslutningslatens och sidladdningshastighet:
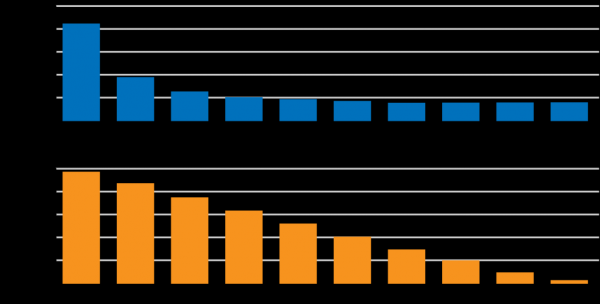
Netflix är dock inte en typisk produkt. Effekten av latens och hastighet på användaren är ett aktivt område för analys och utveckling. Det finns appinläsning och innehållsval som påverkas av latens, men inläsning av statiska objekt och streaming påverkas också av anslutningshastigheten. Att analysera och optimera viktiga faktorer som påverkar användarupplevelsen är ett aktivt utvecklingsområde för flera team på Netflix. Ett av målen är att minska latensen för förfrågningar mellan Netflix-enheter och molninfrastrukturen.
I det här föredraget kommer vi att fokusera specifikt på att minska latens med hjälp av Netflix-infrastrukturen som exempel. Låt oss ta en praktisk titt på hur man kan närma sig design, utveckling och drift av komplexa distribuerade system och lägga tid på innovation och resultat, snarare än att diagnostisera driftsproblem och haverier.
Inuti Netflix
Tusentals olika enheter stöder Netflix-appar. De utvecklas av fyra olika team, som vart och ett skapar separata klientversioner för Android, iOS, TV och webbläsare. Vi arbetar också hårt med att förbättra och anpassa användarupplevelsen och kör hundratals A/B-tester parallellt.
Personalisering stöds av hundratals mikrotjänster i AWS-molnet som tillhandahåller personlig data för användaren, förfrågningshantering, telemetri, stordata och kodning. Trafikvisualiseringen ser ut så här:
Till vänster finns ingångspunkten, och sedan fördelas trafiken mellan flera hundra mikrotjänster som stöds av olika backend-team.
En annan viktig komponent i vår infrastruktur är Open Connect CDN, som levererar statiskt innehåll till slutanvändaren – videor, bilder, kod för klienter etc. CDN finns på anpassade servrar (OCA – Open Connect Appliance). Inuti finns matriser av SSD- och HDD-diskar som kör optimerad FreeBSD, med NGINX och en uppsättning tjänster. Vi designar och optimerar hårdvaru- och mjukvarukomponenter på ett sådant sätt att en sådan CDN-server kan skicka så mycket data som möjligt till användare.
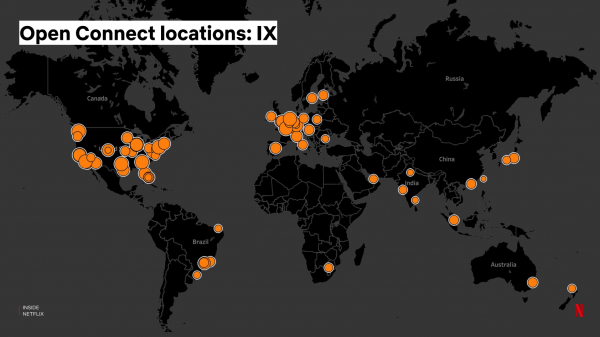
"Väggen" för dessa servrar på Internet eXchange (IX) ser ut så här:

Internet Exchange gör det möjligt för internetleverantörer och innehållsleverantörer att "ansluta" till varandra för att utbyta data mer direkt på internet. Det finns ungefär 70–80 Internet Exchange-punkter runt om i världen där våra servrar är installerade, och vi hanterar deras installation och underhåll själva:
Dessutom tillhandahåller vi servrar direkt till internetleverantörer, som de installerar i sina nätverk, vilket förbättrar lokaliseringen av Netflix-trafik och streamingkvaliteten för användarna:
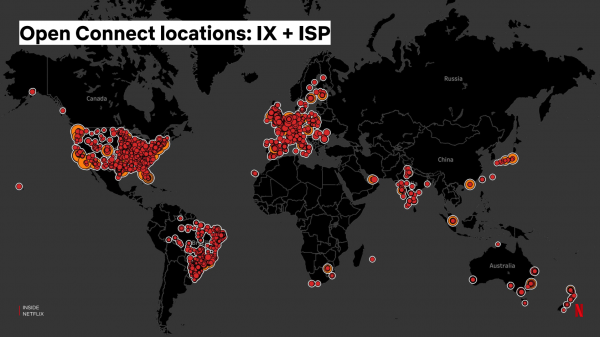
AWS-tjänsterna ansvarar för att skicka videoförfrågningar från klienter till CDN-servrar, samt konfigurera själva servrarna – uppdatera innehåll, programkod, inställningar etc. För det senare byggde vi också ett stamnätverk som ansluter servrar på Internet Exchange-platser till AWS. Stamnätet är ett globalt nätverk av fiberoptiska kablar och routrar som vi kan designa och konfigurera baserat på våra behov.
På , vår CDN-infrastruktur levererar ungefär ⅛ av världens internettrafik under rusningstid och ⅓ av trafiken i Nordamerika, där Netflix har funnits längst. Imponerande siffror, men för mig är en av de mest fantastiska prestationerna att hela CDN-systemet utvecklas och stöds av ett team på färre än 150 personer.
Ursprungligen var CDN-infrastrukturen utformad för att leverera videodata. Men med tiden insåg vi att vi också kunde använda det för att optimera dynamiska förfrågningar från klienter i AWS-molnet.
Om internethastighetsökning
Idag har Netflix tre AWS-regioner, och latensen för förfrågningar till molnet beror på hur långt kunden befinner sig från närmaste region. Samtidigt har vi många CDN-servrar som används för att leverera statiskt innehåll. Finns det något sätt att använda den här infrastrukturen för att snabba upp dynamiska frågor? Tyvärr är det inte möjligt att cachelagra dessa förfrågningar – API:erna är personliga och varje resultat är unikt.
Låt oss skapa en proxy på CDN-servern och börja skicka trafik genom den. Kommer det att bli snabbare?
Materialdel
Låt oss komma ihåg hur nätverksprotokoll fungerar. Idag använder den mesta internettrafiken HTTP, som förlitar sig på de lägre protokollen TCP och TLS. För att en klient ska kunna ansluta till en server gör den en handskakning, och för att upprätta en säker anslutning måste klienten utbyta meddelanden med servern tre gånger och minst en gång till för att överföra data. Med en tur-och-retur-latens (RTT) på 100 ms tar det 400 ms att ta emot den första databiten:
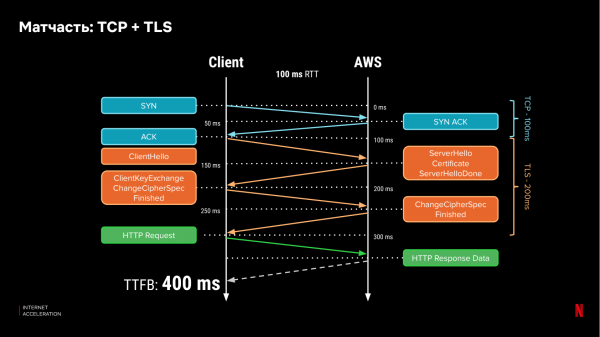
Om vi placerar certifikaten på en CDN-server kan vi avsevärt minska "handskakningstiden" mellan klienten och servern om CDN:et är närmare varandra. Låt oss anta att latensen till CDN-servern är 30 ms. Sedan tar det 220 ms att ta emot den första biten:
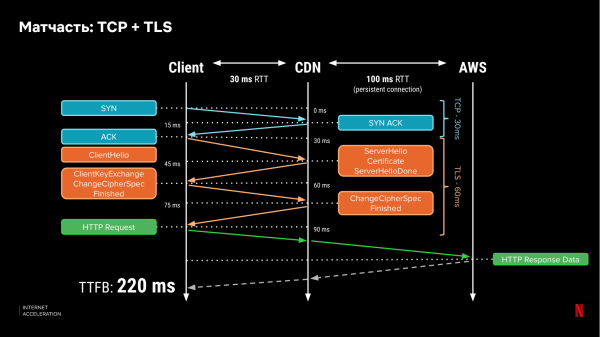
Men fördelarna slutar inte där. När en anslutning har upprättats ökar TCP överbelastningsfönstret (mängden information som kan överföras parallellt över anslutningen). Om ett datapaket går förlorat, minskar klassiska TCP-protokollimplementeringar (som TCP New Reno) det öppna "fönstret" med hälften. Tillväxten av överbelastningsfönstret, och hastigheten för dess återhämtning från förlust, beror återigen på fördröjningen (RTT) till servern. Om den här anslutningen bara går till CDN-servern kommer återställningen att gå snabbare. Paketförlust är dock vanligt förekommande, särskilt i trådlösa nätverk.
Internetbandbredden kan vara minskad, särskilt under rusningstid på grund av trafik från användare, vilket kan leda till trafikstockningar. På internet finns det dock inget sätt att prioritera vissa frågor framför andra. Prioritera till exempel små, latenskänsliga förfrågningar framför "tunga" dataströmmar som belastar nätverket. Men i vårt fall tillåter vårt eget stamnätverk oss att göra detta på en del av förfrågningsvägen – mellan CDN och molnet, och vi kan konfigurera det helt. Det är möjligt att prioritera små och latenskänsliga paket, och att större dataströmmar anländer lite senare. Ju närmare klienten CDN:et är, desto effektivare är det.
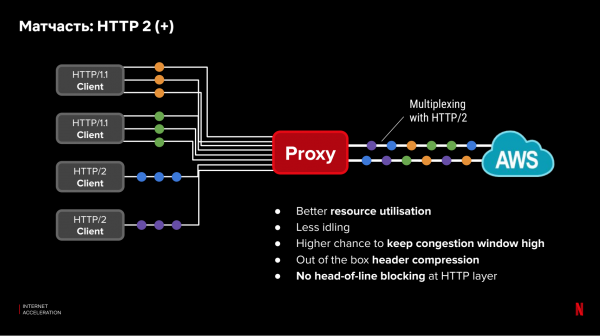
Protokoll på applikationsnivå (OSI nivå 7) påverkar också fördröjningen. Nya protokoll som HTTP/2 låter dig optimera prestandan för parallella förfrågningar. Vi har dock Netflix-klienter med äldre enheter som inte stöder nya protokoll. Inte alla klienter kan uppdateras eller konfigureras optimalt. Samtidigt finns det fullständig kontroll mellan CDN-proxyn och molnet och möjligheten att använda nya, optimala protokoll och inställningar. Den ineffektiva delen med gamla protokoll kommer endast att fungera mellan klienten och CDN-servern. Dessutom kan vi multiplexa förfrågningar på en redan etablerad anslutning mellan CDN och molnet, vilket förbättrar anslutningsutnyttjandet på TCP-nivå:
Vi mäter
Även om teorin lovar förbättringar, så skyndar vi oss inte att lansera systemet i produktion direkt. Istället måste vi först bevisa att idén kommer att fungera i praktiken. För att göra detta behöver du svara på flera frågor:
- СкоростьKommer proxyn att vara snabbare?
- Надежностьkommer den att gå sönder oftare?
- KomplexitetHur integrerar man med applikationer?
- KostnadHur mycket kostar det att installera ytterligare infrastruktur?
Låt oss i detalj granska vårt tillvägagångssätt för att bedöma den första punkten. Resten hanteras på liknande sätt.
För att analysera förfrågningshastigheten vill vi få data för alla användare, inte lägga ner mycket tid på utveckling och inte avbryta produktionen. Det finns flera tillvägagångssätt för detta:
- RUM, eller passiv frågemätning. Vi mäter exekveringstiden för aktuella förfrågningar från användare och säkerställer full användartäckning. Nackdel - inte särskilt stabil signal på grund av många faktorer, såsom olika förfrågningsstorlekar, bearbetningstid på servern och klienten. Dessutom är det inte möjligt att testa en ny konfiguration utan att det påverkar produktionen.
- Laboratorietester. Speciella servrar och infrastruktur som simulerar klienter. Med deras hjälp utför vi nödvändiga tester. På så sätt får vi full kontroll över mätresultaten och en tydlig signal. Men det finns ingen fullständig täckning av enheter och användarplatser (särskilt inte med en världsomspännande service och support för tusentals enhetsmodeller).
Hur kan vi kombinera fördelarna med båda metoderna?
Vårt team hittade en lösning. Vi skrev en liten kodsnutt – ett exempel – som vi bäddade in i vår applikation. Med sonder kan vi göra helt kontrollerade nätverkstester från våra enheter. Det fungerar så här:
- Strax efter att vi laddat ner appen och slutfört den första aktiviteten startar vi våra testversioner.
- Klienten gör en begäran till servern och får ett test"recept". Ett recept är en lista med URL:er till vilka en HTTP-förfrågan ska göras. Dessutom konfigurerar receptet förfrågningsparametrar: fördröjningar mellan förfrågningar, mängden begärd data, HTTP-rubriker etc. Samtidigt kan vi testa flera olika recept parallellt – när en konfigurationsförfrågan görs bestämmer vi slumpmässigt vilket recept som ska utfärdas.
- Teststarttiden väljs så att den inte kommer i konflikt med aktiv användning av nätverksresurser på klienten. I huvudsak väljs en tidpunkt då klienten inte är aktiv.
- Efter att ha mottagit receptet gör klienten förfrågningar till var och en av URL:erna parallellt. Begäran till var och en av adresserna kan upprepas – de så kallade "pulserna". Vid den första pulsen mäter vi hur lång tid det tog att upprätta en anslutning och ladda ner data. På den andra pulsen mäter vi tiden det tar att ladda ner data över en redan etablerad anslutning. Innan den tredje kan vi lägga till en fördröjning och mäta hastigheten för att upprätta en återanslutning, etc.
Under testet mäter vi alla parametrar som enheten kan erhålla:
- DNS-frågetid;
- Tid för upprättande av TCP-anslutning;
- TLS-anslutningens upprättningstid;
- tid för att ta emot den första databyten;
- total laddningstid;
- statusresultatkod.
- När alla pulser är slutförda laddar exemplet ner resultaten av alla mätningar för analys.
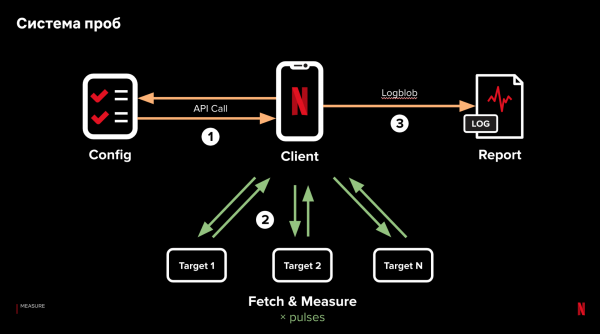
Nyckelpunkterna är minimalt beroende av klientsideslogik, serversidesdatabehandling och mätning av parallella förfrågningar. På så sätt kan vi isolera och testa effekten av olika faktorer som påverkar frågeprestanda, variera dem inom ett enda recept och få resultat från riktiga klienter.
Denna infrastruktur har visat sig användbar för mer än bara prestandaanalys av frågor. Vi har för närvarande 14 aktiva recept, över 6000 XNUMX prover per sekund, tar emot data från världens alla hörn och har full täckning av enheter. Om Netflix skulle köpa en liknande tjänst från en tredje part skulle det kosta miljontals dollar per år, med mycket sämre täckning.
Testteori i praktiken: Prototyp
Med ett sådant system kunde vi utvärdera effektiviteten hos CDN-proxyservrar vad gäller förfrågningslatens. Nu behöver du:
- skapa en proxyprototyp;
- värd för en prototyp på ett CDN;
- avgöra hur klienter ska dirigeras till en proxy på en specifik CDN-server;
- jämför prestanda med AWS-frågor utan proxy.
Uppgiften är att utvärdera effektiviteten av den föreslagna lösningen så snabbt som möjligt. Vi valde Go för att implementera prototypen på grund av dess bra nätverksbibliotek. På varje CDN-server installerade vi proxyprototypen som en statisk binärfil för att minimera beroenden och förenkla integrationen. I den initiala implementeringen använde vi standardkomponenter så mycket som möjligt och mindre modifieringar för HTTP/2-anslutningspoolning och förfrågningsmultiplexering.
För att lastbalansera över AWS-regioner använde vi en geografisk DNS-databas, samma som används för att lastbalansera klienter. För att välja en CDN-server för en klient använder vi TCP Anycast för servrar i Internet Exchange (IX). I det här alternativet använder vi en IP-adress för alla CDN-servrar, och klienten kommer att dirigeras till CDN-servern med minst antal IP-hopp. I CDN-servrar installerade av internetleverantörer (ISP) har vi inte kontroll över routern för att konfigurera TCP Anycast, så vi använder , som hänvisar kunder till internetleverantörer för videostreaming.
Så vi har tre typer av sökvägar för begäran: till molnet via det öppna internet, via en CDN-server i IX, eller via en CDN-server som finns hos internetleverantören. Vårt mål är att förstå vilken väg som är bättre och vad fördelen med proxyservrar är jämfört med hur förfrågningar dirigeras i produktion. För att göra detta använder vi ett testsystem enligt följande:
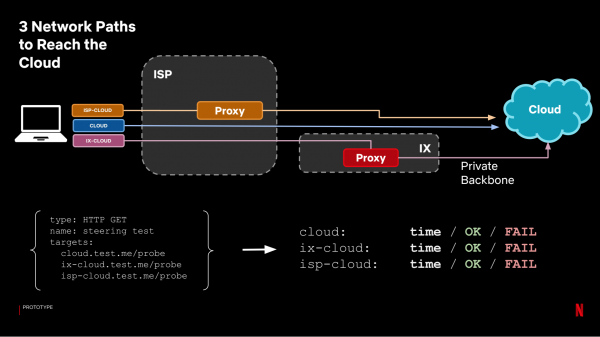
Varje väg blir ett separat mål, och vi tittar på den tid vi får. För analys kombinerar vi proxyresultat i en grupp (vi väljer den bästa tiden mellan IX och ISP-proxy) och jämför med tiden för förfrågningar till molnet utan proxy:
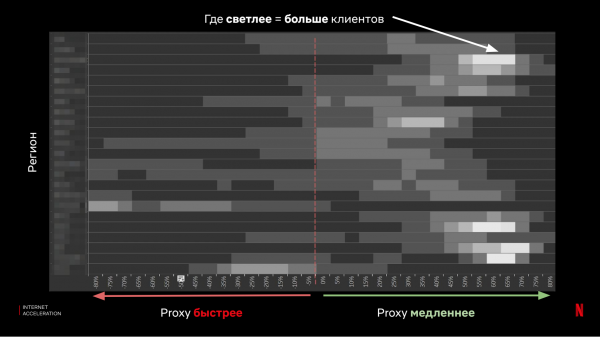
Som ni kan se var resultaten blandade – i de flesta fall ger proxyn bra acceleration, men det finns också ett tillräckligt antal klienter för vilka situationen kommer att förvärras avsevärt.
Till slut gjorde vi några viktiga saker:
- Vi uppskattade den förväntade prestandan för förfrågningar från klienter till molnet via CDN-proxy.
- Vi fick data från riktiga kunder, från alla typer av enheter.
- Vi insåg att teorin inte var 100 % bekräftad och att det ursprungliga erbjudandet med CDN-proxy inte skulle fungera för oss.
- Vi tog inga risker – vi ändrade inte produktionskonfigurationer för kunder.
- Ingenting var trasigt.
Prototyp 2.0
Så, tillbaka till ritbordet och vi upprepar processen igen.
Tanken är att vi istället för en 100% proxy kommer att bestämma den snabbaste vägen för varje klient och skicka förfrågningar dit – det vill säga att vi kommer att göra det som kallas klientstyrning.
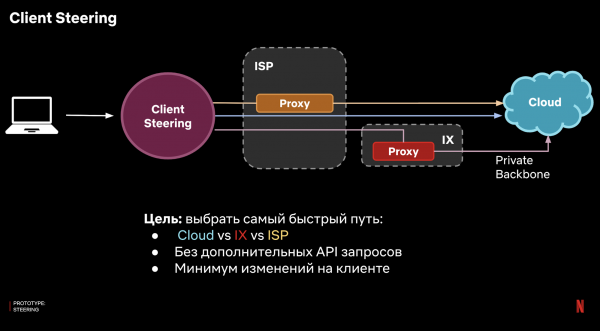
Hur ska man genomföra detta? Vi kan inte använda logik på serversidan eftersom målet är att ansluta till den här servern. Vi måste göra detta på klienten på något sätt. Och helst bör detta göras med ett minimum av komplex logik, för att inte behöva hantera problemet med integration med ett stort antal klientplattformar.
Svaret är att använda DNS. I vårt fall har vi vår egen DNS-infrastruktur, och vi kan konfigurera en domänzon som våra servrar kommer att vara auktoritativa för. Det fungerar så här:
- Klienten gör en begäran till DNS-servern med hjälp av en värd, till exempel api.netflix.xom.
- Begäran skickas till vår DNS-server.
- DNS-servern vet vilken sökväg som är snabbast för den här klienten och utfärdar motsvarande IP-adress.
Det finns en ytterligare komplikation med lösningen: auktoritära DNS-leverantörer ser inte klientens IP-adress och kan bara läsa IP-adressen för den rekursiva resolver som klienten använder.
Som ett resultat måste vår auktoritära resolver fatta beslut inte för en enskild klient, utan för en grupp klienter baserat på den rekursiva resolvern.
För att lösa detta använder vi samma prober, aggregerar mätresultaten från klienter för var och en av de rekursiva resolvrarna och bestämmer vart vi ska skicka denna grupp – proxy via IX med TCP Anycast, via ISP-proxy eller direkt till molnet.
Vi får följande system:
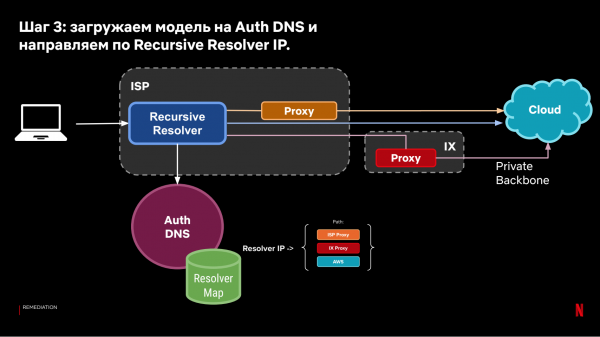
Den resulterande DNS-styrningsmodellen gör det möjligt att dirigera klienter baserat på historiska observationer av anslutningshastigheter från klienter till molnet.
Återigen är frågan: hur effektivt kommer den här metoden att fungera? För att besvara denna fråga använder vi återigen vårt testsystem. Därför konfigurerar vi en konfiguration för aktuellhet där ett av målen följer riktningen från DNS-styrning, det andra går direkt till molnet (nuvarande produktion).
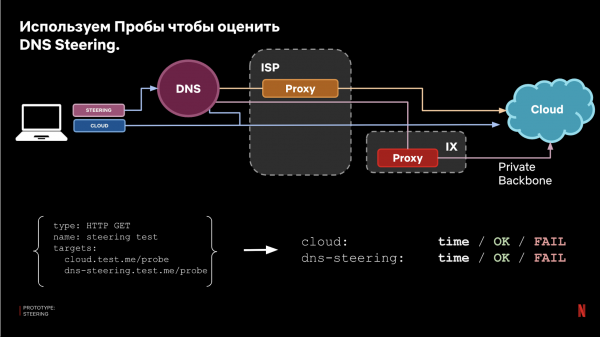
Som ett resultat jämför vi resultaten och får en bedömning av effektiviteten:
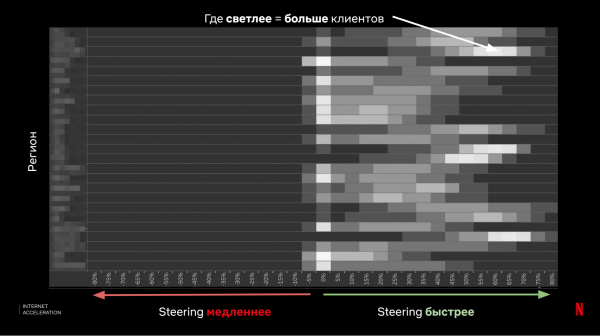
Till slut lärde vi oss några viktiga saker:
- Vi uppskattade den förväntade prestandan för förfrågningar från klienter till molnet med hjälp av DNS-styrning.
- Vi fick data från riktiga kunder, från alla typer av enheter.
- Effektiviteten av den föreslagna idén har bevisats.
- Vi tog inga risker – vi ändrade inte produktionskonfigurationer för kunder.
- Ingenting var trasigt.
Nu till det svåra – produktionsstart
Den enklaste delen är nu bakom oss – vi har en fungerande prototyp. Nu kommer den svåra delen – att lansera lösningen för all Netflix trafik, driftsätta den till 150 miljoner användare, tusentals enheter, hundratals mikrotjänster och en ständigt föränderlig produkt och infrastruktur. Netflix-servrar tar emot miljontals förfrågningar per sekund, och det är lätt att bryta tjänsten med en slarvig åtgärd. Samtidigt vill vi dynamiskt dirigera trafik genom tusentals CDN-servrar, på internet, där saker och ting förändras och går sönder ständigt och vid de mest olämpliga tillfällen.
Och med allt detta består teamet av 3 ingenjörer som ansvarar för utveckling, driftsättning och fullständig support av systemet.
Därför kommer vi att fortsätta prata om lugn och hälsosam sömn.
Hur kan man fortsätta utvecklingen och inte lägga all sin tid på support? Vårt tillvägagångssätt bygger på tre principer:
- Vi minskar den potentiella omfattningen av haverier (explosionsradie).
- Förbered dig på överraskningar – förvänta dig att något går sönder, trots tester och personlig erfarenhet.
- Elegant nedbrytning – om något går sönder bör det repareras automatiskt, även om det inte är på det mest effektiva sättet.
Det visade sig att vi i vårt fall, med denna metod för att hantera problemet, kan hitta en enkel och effektiv lösning och avsevärt förenkla systemstödet. Vi insåg att vi kunde lägga till en liten kodbit till klienten och övervaka nätverksförfrågningsfel orsakade av anslutningsproblem. Vid nätverksfel utför vi en reservlösning direkt till molnet. Denna lösning kräver inte någon större ansträngning från kundteamen, men minskar risken för oväntade haverier och överraskningar för oss avsevärt.
Naturligtvis, trots reservlösningen, följer vi fortfarande strikt disciplin under utvecklingen:
- Provprov.
- A/B-testning eller Kanarieöarna.
- Progressiv utrullning.
Testmetoden beskrevs – ändringar testas först med hjälp av ett anpassat recept.
För canary-testning behöver vi jämförbara servrar där vi kan jämföra hur systemet fungerar före och efter ändringarna. För att göra detta väljer vi serverpar från våra många CDN-sajter som får jämförbar trafik:
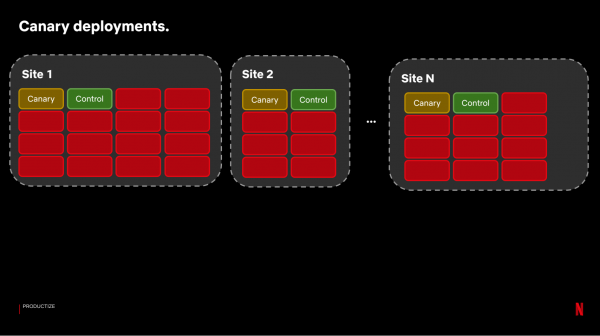
Sedan lägger vi upp build-filen med ändringarna på Canary-servern. För att utvärdera resultaten kör vi ett system som jämför cirka 100–150 mätvärden med ett urval av kontrollservrar:
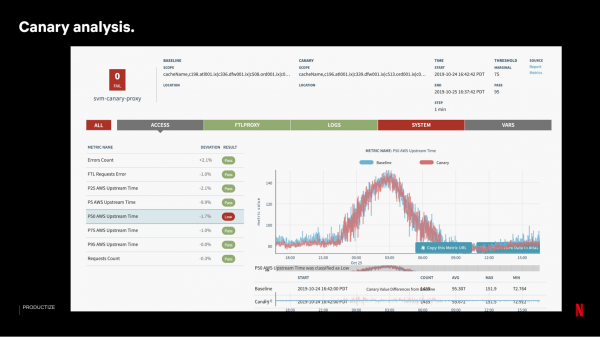
Om Canary-testningen lyckas släpper vi den gradvis, i vågor. Vi uppgraderar inte servrar samtidigt på varje webbplats – att förlora en hel webbplats på grund av problem har större inverkan på tjänsten för användarna än att förlora samma antal servrar på olika platser.
I allmänhet beror effektiviteten och säkerheten för denna metod på kvantiteten och kvaliteten på de insamlade mätvärdena. För vårt frågeaccelerationssystem samlar vi in mätvärden från alla möjliga komponenter:
- från klienter - antal sessioner och förfrågningar, reservfrekvens;
- proxy - statistik över antalet och tidpunkten för förfrågningar;
- DNS - antal och resultat av förfrågningar;
- molnkant — antalet och tiden för bearbetning av förfrågningar i molnet.
Allt detta samlas i en enda pipeline, och beroende på behoven bestämmer vi vilka mätvärden som ska skickas till realtidsanalys och vilka till Elasticsearch eller Big Data för mer detaljerad diagnostik.
Vi övervakar

I vårt fall gör vi ändringar i den kritiska vägen för förfrågningar mellan klienten och servern. Samtidigt är antalet olika komponenter på klienten, på servern och på vägen genom internet enormt. Förändringar på klienten och servern sker ständigt, eftersom dussintals team arbetar och naturliga förändringar i ekosystemet inträffar. Vi är mittemellan – när problem diagnostiseras finns det en god chans att vi blir involverade. Därför behöver vi tydligt förstå hur man definierar, samlar in och analyserar mätvärden för att snabbt lokalisera problem.
Idealt - full åtkomst till alla typer av mätvärden och filter i realtid. Men det finns många mätvärden, så frågan om kostnad uppstår. I vårt fall separerar vi mätvärden och utvecklingsverktyg enligt följande:

Vi använder vårt eget realtidssystem med öppen källkod för att upptäcka och prioritera problem. и — för visualisering. Den lagrar aggregerade mätvärden i minnet, är tillförlitlig och integreras med varningssystemet. För lokalisering och diagnostik har vi tillgång till loggar från Elasticsearch och Kibana. För statistisk analys och modellering använder vi stordata och visualisering i Tableau.
Det verkar som att den här metoden är mycket svår att arbeta med. Men genom att organisera mätvärden och verktyg hierarkiskt kan vi snabbt analysera ett problem, fastställa problemtypen och sedan gå ner i detalj i mätvärden. I allmänhet lägger vi ungefär 1–2 minuter på att identifiera källan till haveriet. Därefter arbetar vi med ett specifikt team med diagnostik – från tiotals minuter till flera timmar.
Även om diagnosen ställs snabbt vill vi inte att det ska hända ofta. Helst skulle vi bara få en kritisk varning när det finns en betydande påverkan på tjänsten. För vårt system för frågeacceleration har vi bara två aviseringar som meddelar:
- Klientreservprocent - bedömning av kundbeteende;
- Probfelprocent - data om nätverkskomponenternas stabilitet.
Dessa kritiska varningar övervakar om systemet fungerar för majoriteten av användarna. Vi tittar på hur många kunder som använde reservfunktioner om de inte kunde få förfrågningsacceleration. Vi har i genomsnitt mindre än en kritisk varning per vecka, trots att systemet genomgår en enorm mängd förändringar. Varför räcker detta för oss?
- Det finns en klientreserv ifall vår proxy inte fungerar.
- Det finns ett automatiskt styrsystem som reagerar på problem.
Låt oss prata om det senare mer i detalj. Vårt probingsystem och systemet för att automatiskt bestämma den optimala vägen för förfrågningar från klienten till molnet gör att vi automatiskt kan hantera vissa problem.
Låt oss gå tillbaka till vår exempelkonfiguration och 3 kategorier av sökvägar. Förutom lastningstiden kan vi titta på själva leveransen. Om vi misslyckas med att läsa in data kan vi genom att titta på resultaten för olika sökvägar avgöra var och vad som gick fel, och om vi kan åtgärda det automatiskt genom att ändra sökvägen till begäran.
Exempel:
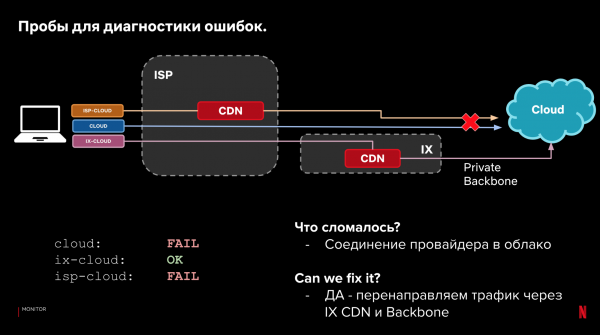
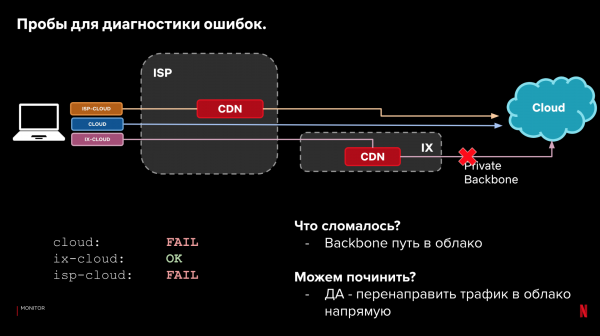
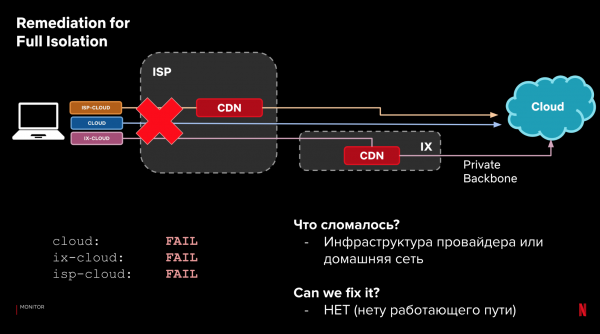
Denna process kan automatiseras. Inkludera den i styrsystemet. Och lär den att reagera på prestanda- och tillförlitlighetsproblem. Om något börjar gå sönder, reagera om det finns ett bättre alternativ. Samtidigt är den omedelbara reaktionen inte kritisk, tack vare reservfunktionen hos klienter.
Således kan principerna för systemstöd formuleras enligt följande:
- vi minskar omfattningen av haverier;
- vi samlar in mätvärden;
- vi reparerar automatiskt haverier om vi kan;
- om det inte kan, meddelar vi det;
- Vi arbetar med dashboards och prioriteringsverktyg för snabb respons.
Lärdomar
Det tar inte mycket tid att skriva en prototyp. I vårt fall var det klart på bara 4 månader. Med den fick vi nya mätvärden, och 10 månader efter utvecklingsstarten fick vi den första produktionstrafiken. Sedan började det tråkiga och mycket svåra arbetet: att gradvis produktifiera och skala upp systemet, migrera huvudtrafiken och lära av misstagen. Denna effektiva process kommer dock inte att vara linjär – trots alla ansträngningar är det omöjligt att förutsäga allt. Mycket effektivare är snabb iteration och respons på ny data.
Baserat på vår erfarenhet kan vi ge följande råd:
- Lita inte på din intuition.
Vår intuition svek oss ständigt, trots våra teammedlemmars stora erfarenhet. Till exempel förutspådde vi felaktigt den förväntade hastighetsökningen från att använda en CDN-proxy, eller beteendet hos TCP Anycast.
- Hämta data från produktionen.
Det är viktigt att få tillgång till åtminstone en liten mängd produktionsdata så snabbt som möjligt. Det är praktiskt taget omöjligt att få fram antalet unika fall, konfigurationer och inställningar i laboratorieförhållanden. Snabb åtkomst till resultaten gör att du snabbt kan identifiera potentiella problem och ta hänsyn till dem i systemarkitekturen.
- Följ inte andras råd och resultat – samla in din egen data.
Följ principerna för datainsamling och analys, men acceptera inte blint andras resultat och påståenden. Bara du kan veta exakt vad som fungerar för dina användare. Era system och era kunder kan skilja sig mycket från andra företags. Lyckligtvis finns analysverktyg nu tillgängliga och enkla att använda. Resultaten du får kanske inte stämmer överens med vad Netflix, Facebook, Akamai och andra företag påstår. I vårt fall skiljer sig prestandan för TLS-, HTTP2- eller DNS-frågestatistik från resultaten för Facebook, Uber och Akamai – eftersom vi har olika enheter, klienter och dataströmmar.
- Följ inte modetrender utan behov och utan att utvärdera deras effektivitet.
Börja enkelt. Det är bättre att skapa ett enkelt fungerande system på kort tid än att lägga ner enormt mycket tid på att utveckla komponenter du inte behöver. Lös problem och frågor som är viktiga baserat på dina mätningar och resultat.
- Var beredd på nya applikationer.
Precis som det är svårt att förutse alla problem, är det svårt att förutse fördelarna och tillämpningarna i förväg. Ta ett exempel från startups – deras förmåga att anpassa sig till kundernas behov. I ditt fall kan du upptäcka nya problem och deras lösningar. I vårt projekt satte vi upp målet att minska förfrågningslatensen. Under analysen och diskussionerna insåg vi dock att vi också kan använda proxyservrar:
- att balansera trafiken mellan AWS-regioner och minska kostnaderna;
- att modellera CDN-stabilitet;
- för att konfigurera DNS;
- för att konfigurera TLS/TCP.
Slutsats
I mitt föredrag beskrev jag hur Netflix löser problemet med att accelerera internetförfrågningar mellan klienter och molnet. Hur vi samlar in data genom ett kundurvalssystem och använder insamlad historisk data för att dirigera produktionsförfrågningar från kunder via den snabbaste vägen på internet. Hur vi använder nätverksprotokollprinciper, vår CDN-infrastruktur, stamnätverk och DNS-servrar för att uppnå detta mål.
Vår lösning är dock bara ett exempel på hur vi på Netflix har implementerat ett sådant system. Vad som fungerade för oss. Den praktiska delen av min rapport till er är de principer för utveckling och stöd som vi följer och uppnår goda resultat.
Vår lösning på ditt problem kanske inte fungerar för dig. Teorin och principerna för utveckling kvarstår dock, även om du inte har en egen CDN-infrastruktur, eller om den skiljer sig avsevärt från vår.
Hastigheten på affärsförfrågningar är också fortfarande viktig. Och även för en enkel tjänst måste du göra ett val: mellan molnleverantörer, serverplatser, CDN- och DNS-leverantörer. Ditt val kommer att påverka hur effektiva internetsökningar är för dina kunder. Och det är viktigt för dig att mäta och förstå detta inflytande.
Börja med enkla lösningar, var uppmärksam på hur du byter produkt. Lär dig allt eftersom och förbättra systemet baserat på data från dina kunder, din infrastruktur och ditt företag. Tänk på möjligheten till oväntade haverier under designprocessen. Och då kan du snabba upp din utvecklingsprocess, förbättra effektiviteten i din lösning, undvika onödig supportbörda och sova gott.
I år i onlineformat. Du kommer att kunna ställa frågor till en av DevOps grundare, John Willis själv!
Källa: will.com
