

Hej alla. Nedan är utskriften .
– ett övervakningssystem för olika system och tjänster, med hjälp av vilket systemadministratörer kan samla in information om aktuella parametrar för system och sätta upp larm för att ta emot aviseringar om avvikelser i driften av systemen.
Rapporten kommer att innehålla en jämförelse и — Projekt för långtidslagring av Prometheus-mått.



Först ska jag berätta om Prometheus. Detta är ett övervakningssystem som samlar in mätvärden från specificerade mål och sparar dem till lokal lagring. Prometheus kan spela in mätvärden till fjärrlagring och kan generera varningar och inspelningsregler.

Prometheus begränsningar:
- Den har ingen global frågevy. Det är när du har flera oberoende instanser av prometheus. De samlar in mått. Och du vill fråga utöver alla dessa mätvärden som samlats in från olika prometheus-instanser. Prometheus tillåter inte detta.
- Med prometheus är prestandan begränsad till endast en server. Prometheus skalar inte automatiskt över flera servrar. Du kan bara manuellt dela upp dina mål mellan flera Prometheus.
- Omfattningen av mätvärden i Prometheus är begränsad till bara en server av samma anledning som den inte kan skalas automatiskt över flera servrar.
- Det är inte så lätt att organisera datasäkerhet i Prometheus.

Lösningar på dessa problem/utmaningar?
Lösningarna är:
Alla dessa lösningar är för fjärrlagring av data som samlats in av Prometheus. De löser problemet med fjärrlagring från föregående bild på olika sätt. I den här presentationen kommer jag bara att prata om de två första lösningarna: и .
För första gången information om dök upp av . Arkitekturen beskrivs där och hur det fungerar.

Thanos tar data som Prometheus sparade till den lokala disken och kopierar den till S3, till eller till en annan objektlagring.

Thanos tillhandahåller alltså en global frågevy. Du kan söka efter data som lagras i objektlagring från flera Prometheus-instanser.

Thanos stöder PromQL och .

Thanos använder Prometheus-kod för att lagra data.

Thanos är utvecklad av samma utvecklare som Prometheus.
Про . här , där vi först pratade om .
VictoriaMetrics tar emot data från flera prometheus protokoll som stöds av Prometheus.
VictoriaMetrics tillhandahåller en global frågevy, eftersom flera Prometheus-instanser kan skriva data till en VictoriaMetrics. Följaktligen kan du göra frågor om alla dessa data.

VictoriaMetrics stöder också, som Thanos, PromQL och Prometheus querying API.

Till skillnad från Thanos är VictoriaMetrics källkod skriven från grunden och är optimerad för hastighet och resursförbrukning.

VictoriaMetrics, till skillnad från Thanos, skalar både vertikalt och horisontellt. Äta , som skalar vertikalt. Du kan börja med en processor och 1 GB minne och gradvis växa till hundratals processorer och 1 TB minne. VictoriaMetrics kan använda alla dessa resurser. Dess prestanda kommer att öka med cirka 100 gånger jämfört med ett 1-kärnigt system.

Thanos historia började i november 2017, när det första offentliga engagemanget dök upp. Innan detta utvecklades Thanos internt .

I juni 2019 fanns det en landmärkeversion 0.5.0, där protokoll. Han togs bort från Thanos eftersom han inte presterade bra. Ofta fungerade inte Thanos-klustret korrekt, noder kopplade till det felaktigt på grund av skvallerprotokollet. Därför bestämde vi oss för att ta bort honom därifrån. Jag tror att detta är rätt beslut.

Samma juni 2019 skickade de ansökningsnummer в .

Och efter ett par månader antogs Thanos , som inkluderar Prometheus, Kubernetes och andra populära projekt.

I januari 2018 började utvecklingen av VictoriaMetrics.

I september 2018 nämnde jag VictoriaMetrics offentligt för första gången.

I december 2018 publicerades en enkelnodsversion.

I maj 2019 källor för både enkelnods- och klusterversioner.

I juni 2019 skickade vi, precis som Thanos, in en ansökan till CNCF-stiftelsen under nummer . Vi ansökte en dag innan Thanos ansökte.

Men tyvärr har vi fortfarande inte blivit accepterade där. Samhällshjälp behövs.

Låt oss titta på de viktigaste bilderna som visar arkitekturen i Thanos och VictoriaMetrics.
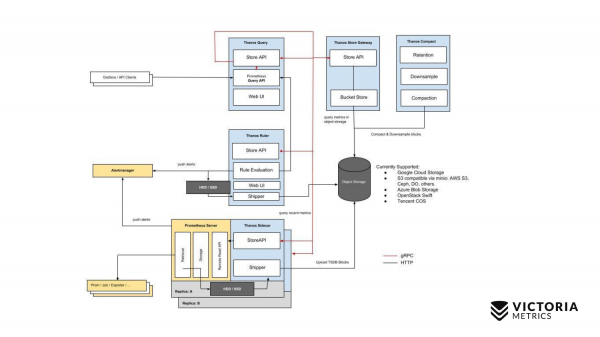
Låt oss börja med Thanos. De gula komponenterna är Prometheus-komponenter. Allt annat är Thanos-komponenter. Låt oss börja med den viktigaste komponenten. Thanos sidovagn är en komponent som installeras bredvid varje Prometheus. Den laddar Prometheus-data från lokal lagring till S3 eller annan objektlagring.
Det finns också en komponent som heter Thanos Store Gateway, som kan läsa denna data från Object Storage vid inkommande förfrågningar från Thanos Query. Thanos Query implementerar PromQL och Prometheus API. Det vill säga från utsidan ser det ut som Prometheus. Tar emot PromQL-förfrågningar, skickar dem till Thanos Store Gateway, Thanos Store Gateway hämtar nödvändig data från Object Storage, skickar tillbaka den.
Men vi lagrar data i Object Storage utan de senaste två timmarna på grund av en funktion i Thanos Sidecar-implementeringen, som inte kan ladda upp de senaste två timmarna till Object Storage S3, eftersom Prometheus ännu inte har skapat filer för dessa två timmar i lokal lagring.
Hur bestämde du dig för att komma runt detta? Thanos Query, förutom förfrågningar till Thanos Store Gateway, skickar parallella förfrågningar till varje Thanos Sidecar, som ligger bredvid Prometheus.
Och Thanos Sidecar, i sin tur, fullmaktsförfrågningar vidare till Prometheus och hämtar data för de senaste två timmarna.
Utöver dessa komponenter finns det också en valfri komponent utan vilken Thanos inte kommer att fungera bra. Det här är Thanos Compact, som ansvarar för att slå samman små filer på Object Storage till större filer som laddades upp här av Thanos Sidecars. Thanos Sidecar laddar upp datafiler dit på två timmar. Dessa filer, om de inte slås samman till större filer, kan deras antal växa mycket avsevärt. Ju fler sådana filer, desto mer minne behövs för Thanos Store Gateway, desto mer resurser behövs för att överföra data över nätverket och metadata. Thanos Store Gateway blir ineffektiv. Därför är det nödvändigt att köra Thanos Compact, som slår samman små filer till större, så att det finns färre sådana filer och för att minska overhead på Thanos Store Gateway.
Det finns också en sådan komponent som Thanos Ruler. Den kör Prometheus varningsregler och kan utvärdera Prometheus inspelningsregler för att skriva tillbaka data till Object Storage. Men den här komponenten rekommenderas inte att användas, eftersom... han .
Detta är Thanos enkla schema.
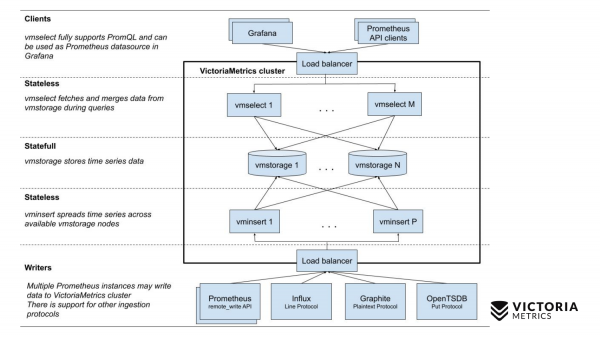
Låt oss nu jämföra det med VictoriaMetrics-schemat.
VictoriaMetrics har 2 versioner: Enkelnods- och klusterversion. Enkelnod körs på en dator. Single-nod har inte dessa komponenter, bara en binär. Den här binären på bilden ser ut som den här kvadraten. Allt som finns inuti kvadraten är innehållet i den binära filen för Single-nod-versionen. Du behöver inte veta om honom. Du kör bara binären och allt fungerar för oss.
Klusterversionen är mer komplicerad. Inuti den finns tre olika komponenter: vmselect, vminsert och vmstorage. Av deras namn borde det framgå vad var och en av dem gör. Insert-komponenten accepterar data i olika format: från Prometheus fjärrskriv-API, Influx-linjeprotokollet, Graphite-protokollet och OpenTSDB-protokollet. Insert-komponenten accepterar dem, analyserar dem och distribuerar dem mellan befintliga lagringskomponenter, där data redan är lagrad. Select-komponenten accepterar i sin tur PromQL-frågor. Han genomför , såväl som Prometheus förfrågnings-API, och det kan användas som en ersättning för Prometheus i Grafana eller andra Prometheus API-klienter. Select accepterar en promql-begäran, analyserar den, läser nödvändig data för att exekvera denna begäran från lagringsnoder, bearbetar dessa data och returnerar ett svar.

Låt oss jämföra komplexiteten i att installera Thanos och VictoriaMetrics.

Låt oss börja med Thanos. Innan du börjar arbeta med Thanos måste du skapa en hink i Object Storage, till exempel S3 eller GCS, så att Thanos Sidecar kan skriva data till den.

Sedan måste du installera Thanos sidovagn för varje Prometheus. Innan detta måste du komma ihåg att inaktivera datakomprimering i Prometheus. Datakomprimering komprimerar regelbundet data i lokal Prometheus-lagring för att minska resursförbrukningen.
När du installerar Thanos Sidecar på din Prometheus måste du inaktivera denna datakomprimering, eftersom Thanos Sidecar inte fungerar korrekt med datakomprimering aktiverad. Detta innebär att din Prometheus börjar spara data i tvåtimmarsblock och slutar slå samman dessa block till större. Följaktligen, om du gör frågor som överskrider längden på de senaste två timmarna, kommer de inte att fungera lika effektivt som de skulle kunna fungera om datakomprimering var aktiverad.

Därför rekommenderar Thanos att minska lagringstiden för data i lokal lagring till 6-8 timmar för att minska omkostnaderna för ett stort antal små block.
När du har installerat Thanos Sidecar måste du installera två komponenter för varje objektlagringshink. Dessa är Thanos Compactor och Thanos Store Gateway.

Efter det måste du installera Thanos Query och konfigurera den så att den kan ansluta till alla Thanos Store Gateways som du har, och även kan ansluta till alla Thanos Sidecars.
Det kan finnas ett litet problem här.

Du måste konfigurera en pålitlig och säker anslutning från Thanos Query till dessa komponenter. Och om din Prometheus är placerad i olika datacenter, eller i olika VPC:er, är anslutningar till dem utifrån förbjudna. Men för att Thanos Query ska fungera måste du på något sätt konfigurera anslutningen där, och du måste hitta ett sätt.
Om du har många sådana datacenter, minskar därför tillförlitligheten för hela systemet. Eftersom Thanos Query ständigt måste upprätthålla anslutningar till alla Thanos Sidecars som finns i olika datacenter. För varje inkommande förfrågan kommer den att dirigera förfrågningar till alla Thanos sidovagnar. Om anslutningen avbryts kommer du antingen att få en ofullständig datauppsättning eller så får du ett "kluster är nere"-svar.

I VictoriaMetrics är allt lite enklare. För Single-nod-versionen behöver du bara köra en binär och allt fungerar.

I klusterversionen räcker det att köra alla ovanstående tre typer av komponenter i vilken mängd du behöver, eller använder för att automatisera lanseringen av komponenter i Kubernetes. Vi planerar också att göra en Kubernetes-operatör. Helm-diagrammet täcker inte vissa fall och låter dig skjuta dig själv i foten. Till exempel låter det dig minska antalet lagringsnoder, vilket kommer att leda till dataförlust.

Efter att du har lanserat en binär eller en klustrad version behöver du bara lägga till Prometheus i konfigurationen så att den börjar skriva data parallellt med lokal lagring och fjärrlagring. Som du kan se bör denna konfiguration fungera mycket mer tillförlitligt jämfört med Thanos-konfigurationen. Vi behöver inte upprätthålla en anslutning från VictoriaMetrics till alla Prometheus, eftersom Prometheus själva ansluter till VictoriaMetrics och överför data.

Låt oss överväga stödet från Thanos och VictoriaMetrics.

Thanos måste övervaka Sidecar för att se till att de inte slutar ladda data till Object Storage. De kan stoppa denna datanedladdning på grund av nedladdningsfel, till exempel är din nätverksanslutning till Object Storage tillfälligt avbruten eller Object Storage är tillfälligt otillgänglig. Thanos Sidecar kommer att märka detta just nu, rapportera ett fel, kan krascha och sedan sluta fungera. Om du inte övervakar det kommer du att sluta överföra data till Object Storage. Om lagringstiden går över (6-8 timmar rekommenderas) så kommer du att förlora data som inte hamnat i Object Storage.

Thanos komprimatorer kan sluta fungera pga . Kompaktörer tar data från Object Storage och slår samman dem till större databitar. Eftersom komprimatorer inte är synkroniserade med Sidecars kan följande hända: Sidecar har ännu inte hunnit slutföra blocket, Compactor beslutar att detta block är helt skrivet. Compactor börjar läsa den. Den läser inte blocket i sin helhet och slutar fungera. Se detaljer .

Store Gateway kan returnera inkonsekventa data på grund av tävlingar mellan Compactor och Sidecars. Samma sak händer här, eftersom Store Gateway inte är synkroniserad med Compactors och Sidecars på något sätt. Följaktligen kan tävlingsförhållanden uppstå när Store Gateway inte ser delar av data eller ser onödig data.

Frågekomponenten i Thanos returnerar som standard ett delresultat om vissa sidovagnar eller butiksgateways inte är tillgängliga för tillfället. Du kommer att få en del av uppgifterna, och du kommer inte ens att veta att du inte har fått alla uppgifter. Så här fungerar det som standard. I en liknande situation returnerar VictoriaMetrics markerade data som partiella.

Till skillnad från Thanos förlorar VictoriaMetrics sällan data. Även om anslutningen från Prometheus till VictoriaMetrics avbryts är detta inget problem, eftersom Prometheus fortsätter att registrera inkommande ny data i Write Ahead Log, vars storlek är 2 timmar. Om du återställer din anslutning till VictoriaMetrics inom två timmar kommer din data inte att gå förlorad. Prometheus .

Till skillnad från Thanos, som skriver data till objektlagring först efter två timmar, replikerar Prometheus automatiskt data med hjälp av fjärrskrivprotokollet till fjärrlagring, såsom VictoriaMetrics. Du är inte rädd för att förlora lokal lagring i Prometheus. Om han plötsligt förlorade lokal lagring, så kommer du i värsta fall att förlora de sista sekunderna av data som inte hann spelas in i fjärrlagring.

Kubernetes hanterar automatiskt klustret, till skillnad från Thanos. Det är svårt att placera alla Thanos-komponenter i ett Kubernetes-kluster, till skillnad från VictoriaMetrics-klusterkomponenter.

VictoriaMetrics har en mycket enkel uppdatering till den nya versionen. Stoppa bara VictoriaMetrics, uppdatera binärfilerna och starta den. När de stoppas via en SIGINT-signal utför alla VictoriaMetrics-binärer en graciös avstängning. De sparar nödvändig data korrekt, stänger inkommande anslutningar korrekt för att inte förlora något. Så du kommer inte att förlora något när du uppgraderar.

VictoriaMetrics gör det mycket enkelt att utöka ett kluster. Lägg bara till de nödvändiga komponenterna och fortsätt arbeta.

Om fallgropar i Thanos och VictoriaMetrics.

Thanos har följande fallgropar. Prometheus måste lagra data för de senaste två timmarna. Om de går vilse kommer du att förlora dem helt eftersom de ännu inte har skrivits till Object Storage som S3.

Store Gateway-komponenten och komprimeringskomponenten kan kräva mycket minne för att fungera med en stor objektlagring om det finns många små filer lagrade där. Ju större antal och storlek på filer, desto mer Store Gateway och komprimator-RAM krävs för att lagra metainformation. Thanos har många frågor om det .

Thanos annonseras för att skala på obestämd tid med mängden Prometheus du har. Detta är faktiskt inte sant. Eftersom alla förfrågningar går igenom Query-komponenten, som samtidigt måste polla alla Store Gateway-komponenter och alla Sidecar-komponenter, hämtar du data därifrån och förbearbetar den sedan. Uppenbarligen begränsas förfrågningshastigheten av den långsammaste svaga länken, den långsammaste Store Gatewayen eller den långsammaste Sidecar.
Dessa komponenter kan vara ojämnt belastade. Till exempel har du Prometheus, som samlar in miljontals mätvärden per sekund. Och det finns Prometheus, som samlar in tusentals mätvärden per sekund. Prometheus, som samlar in miljontals mätvärden per sekund, lägger en mycket högre belastning på servern den körs på. Följaktligen fungerar Sidecar långsammare där. Och i allmänhet fungerar allt långsamt där. Och Query-komponenten kommer att hämta data därifrån mycket långsamt. Följaktligen kommer prestandan för hela ditt kluster att begränsas av denna långsamma sidovagn.

Som standard ger Thanos partiell data om vissa sidovagnar och antingen Store Gateway är otillgängliga. Till exempel, om dina Sidecars är utspridda runt om i världen i olika datacenter, ökar sannolikheten för ett anslutningsfel och otillgänglighet av komponenter avsevärt. Följaktligen kommer du i de flesta fall att få delar av data utan att ens veta om det.
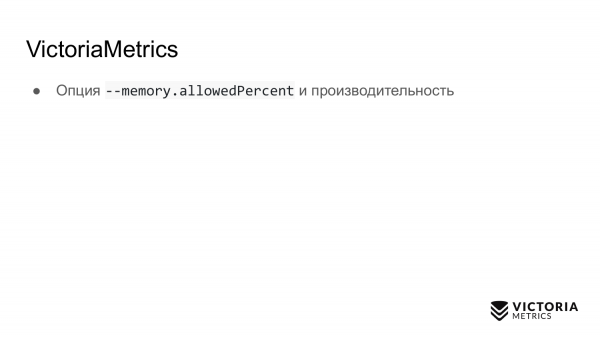
VictoriaMetrics har också fallgropar. Den första fallgropen är alternativet som begränsar mängden RAM som används för VictoriaMetrics cache. Som standard är det lika med 60 % av RAM-minnet på maskinen där VictoriaMetrics körs eller 60 % av RAM-minnet för VictoriaMetrics-podden i Kubernetes.
Om du ändrar detta värde felaktigt kan du förstöra prestandan för VictoriaMetrics. Till exempel, om du ställer in värdet för lågt kanske data inte längre får plats i VictoriaMetrics cache. På grund av detta kommer hon att behöva göra extra arbete och ladda processorn och disken. Om du gör det här alternativet för stort ökar det för det första sannolikheten att VictoriaMetrics kraschar med ett minnesfel, och för det andra kommer det att leda till att det kommer att finnas väldigt lite RAM kvar i operativsystemets minne för filcache. Och VictoriaMetrics förlitar sig på en filcache för prestanda. Om det inte räcker kan belastningen på disken öka kraftigt. Därför råd: ändra inte parametern om det inte är absolut nödvändigt.
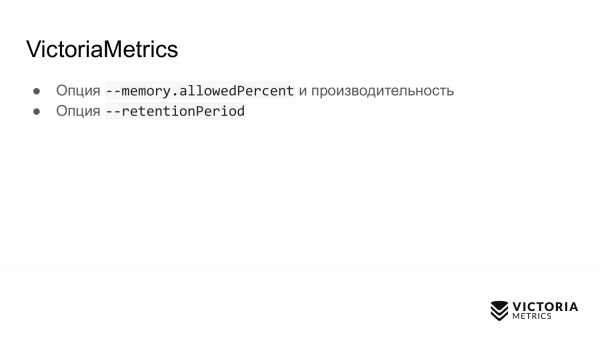
Andra alternativet. Detta är retentionPeriod - en period som är inställd på 1 månad som standard. Detta är hur lång tid VictoriaMetrics lagrar data. Efter denna period raderar VictoriaMetrics data.
Många kör VictoriaMetrics utan denna parameter och registrerar data under en månad. Och då frågar de: varför försvann uppgifterna för föregående månad? Eftersom standardretentionsperioden är 1 månad. Därför måste du känna till och ställa in rätt retentionsperiod.

Låt oss ta en titt på de unika funktionerna.

Thanos har en funktion som kallas nedsampling: 5-minuters- och timintervall, vilket ofta . Om du googlar och tittar på deras problem på github så finns det många problem relaterade till denna nedsampling, att det ibland inte fungerar korrekt, eller inte fungerar som användarna förväntar sig.

Thanos har datadeduplicering för Prometheus HA-par. När två Prometheus samlar in samma mätvärden från samma mål och Thanos lagrar dem i Object Storage. Thanos kan korrekt deduplicera denna data, till skillnad från VictoriaMetrics.

Thanos har en varningskomponent som fanns i Thanos-schemat. Men han .

Thanos har fördelen att Thanos och Prometheus delar samma kod. Thanos och Prometheus är utvecklade av samma utvecklare. Med förbättringar av Thanos eller Prometheus vinner den andra sidan.

VictoriaMetrics huvudfunktion är MetricsQL. Det här är VictoriaMetrics-tillägg för PromQL, som jag pratade om vid den tidigare stora övervakningsmetupen.

VictoriaMetrics stöder dataladdning med många olika protokoll. VictoriaMetrics kan inte bara acceptera data från Prometheus, utan även via protokollen Influx, OpenTSDB och Graphite.

VictoriaMetrics-data tar mycket mindre plats jämfört med Thanos och Prometheus.
Om du spelar in riktig data talar användarna om en 2-5 gångers minskning av storleken på data på disk jämfört med Prometheus och Thanos.

En annan fördel med VictoriaMetrics är att den är optimerad för hastighet.

Låt oss titta på kostnaderna för infrastruktur.

En av fördelarna med Thanos är att den lagrar data i objektlagring, vilket är relativt billigt.
När du lagrar data i objektlagring måste du betala för dataskriv- och läsoperationer ($10 per miljon operationer). När du skriver data till objektlagring betalar du dina hostingkostnader för att ladda upp data till Internet; om ditt kluster inte finns i AWS är det gratis där. När du läser data betalar du mellan $10 och $230 per 1TB. Detta kan vara viktigt om du ofta frågar efter historiska data från Thanos-klustret.

För ett Thanos-kluster måste du betala för servrar för Compact, Store Gateway, Query-komponenter som kräver mycket minne och CPU för stora datamängder.

VictoriaMetrics har följande utgifter. Om du lagrar data på GCE HDD-enheter kommer det ut på $40 för 1TB. För VictoriaMetrics räcker det med vanliga hårddiskar, inga SSD-enheter, som kostar fem gånger mer, behövs. VictoriaMetrics är optimerad för hårddisk.

VictoriaMetrics kräver servrar för komponenter: antingen Single-nod eller klustrade komponenter, som, till skillnad från Thanos-komponenter, kräver mycket mindre CPU och RAM - och blir därför billigare.

Exempel på genomförande.

Thanos har ett implementeringsexempel i Gitlab. Gitlab körs helt på Thanos. Men allt är inte så smidigt där. Om man tittar på dem , då kan du se att de hela tiden har några : Det finns inte tillräckligt med minne för Store Gateway- eller Query-komponenterna. De måste hela tiden öka mängden minne.
På grund av detta ökar kostnaderna för att lösa dessa problem.
Den andra implementeringen, som kan vara mer framgångsrik, är företaget Improbable, som började utveckla Thanos. De publicerade Thanos källkod. Improbable är ett företag som utvecklar spelmotorer.

VictoriaMetrics har exempel på offentliga implementeringar:
- wix.com webbplatsbyggare
- Adidas implementerar VictoriaMetrics och gjorde till och med en presentation vid den senaste PromCon 2019
- TrafficStars - annonsnätverk
- Seznam.cz är en populär tjeckisk sökmotor.
Och så fanns det företag utan namn som jag inte kan namnge nu. De samtyckte inte.
- En stor spelutvecklare. Större än osannolikt.
- Stor grafisk mjukvaruutvecklare.
- Stor rysk bank.
- Europeisk vindkraftstillverkare som framgångsrikt har testat VictoriaMetrics. Denna tillverkare implementerar VictoriaMetrics för att övervaka data som samlas in från vindkraftverk med en hastighet av 50 prover per sekund per sensor. Varje vindturbin har flera hundra sensorer. De har flera hundra vindkraftverk.
- Ryska flygbolag som vill implementera VictoriaMetrics, men som fortfarande inte kan. Vi är på kontraktsstadiet med dem.
 Slutsatser.
Slutsatser.
VictoriaMetrics och Thanos löser liknande problem, men på olika sätt:
- Global frågevy
- horisontell skalning
- godtycklig retention

Tack.
Vi väntar på dig hos oss .

Endast registrerade användare kan delta i undersökningen. , Snälla du.
Vad använder du som långtidsförvaring för Prometheus?
35,3%Thanos6
0,0%Cortex0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%andra 4
17 användare röstade. 16 användare avstod från att rösta.
Källa: will.com
