

Del två:
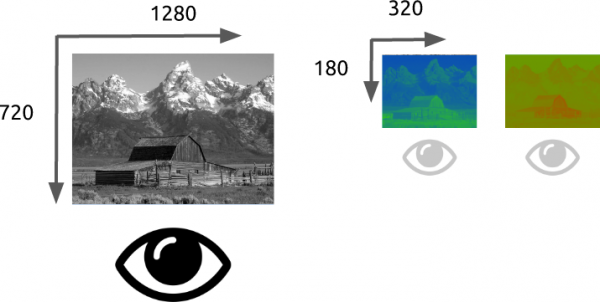
Vilket raster som helst bild kan representeras som tvådimensionell matrisNär det gäller färger kan idén utvecklas vidare genom att betrakta bilden som tredimensionell matris, där ytterligare dimensioner används för att lagra data för var och en av färgerna.
Om vi betraktar den slutliga färgen som en kombination av de så kallade primärfärgerna (röd, grön och blå), definierar vi i vår tredimensionella matris tre plan: det första för rött, det andra för grönt och det sista för blått.
Vi kommer att kalla varje punkt i denna matris för en pixel (bildelement). Varje pixel innehåller information om intensiteten (vanligtvis som ett numeriskt värde) för varje färg. Till exempel, röd pixel betyder att den har 0 grönt, 0 blått och maximalt rött. Pixelrosa kan bildas av en kombination av tre färger. Med ett numeriskt intervall från 0 till 255 definieras en rosa pixel som Röd = 255, Grön = 192 и Blå = 203.
Artikeln publicerades med stöd av EDISON.Vi utvecklar , och även vi är förlovade .
Alternativa metoder för att koda en färgbild
Det finns många andra modeller för att representera färgerna som utgör en bild. Till exempel kan du använda en indexerad palett, som bara kräver en byte för att representera varje pixel, istället för de tre som krävs av RGB-modellen. Denna modell kan använda en 2D-matris istället för en 3D-matris för att representera varje färg. Detta sparar minne, men producerar ett mindre färgomfång.

RGB
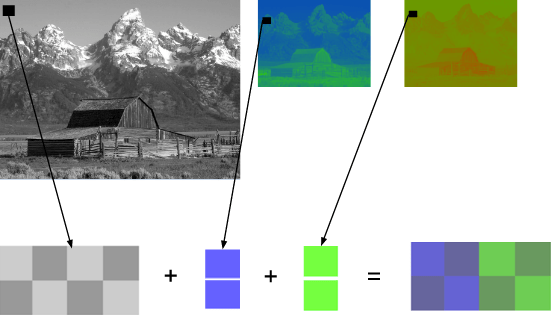
Titta till exempel på bilden nedan. Den första ytan är helt färgad. De andra är röda, gröna och blå plan (intensiteten hos motsvarande färger visas i gråskala).

Vi ser att de röda tonerna i originalet kommer att finnas på samma ställen där de ljusaste delarna av det andra ansiktet observeras. Medan bidraget från blått huvudsakligen bara kan ses i Marios ögon (det sista ansiktet) och delar av hans kläder. Observera var alla tre färgplan bidrar minst (de mörkaste delarna av bilderna) - detta är Marios mustasch.
Att lagra intensiteten för varje färg kräver ett visst antal bitar - detta värde kallas bitdjupLåt oss säga att 8 bitar används (baserat på värdet från 0 till 255) på ett färgplan. Då har vi ett färgdjup på 24 bitar (8 bitar * 3 R/G/B-plan).
En annan egenskap hos bilden är att tillstånd, vilket är antalet pixlar i en dimension. Ofta betecknad som bredd x höjd, som nedan i exempelbilden 4 gånger 4.
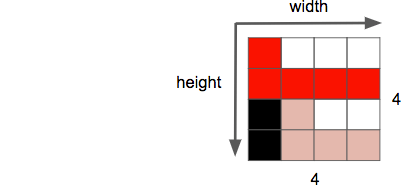
En annan egenskap vi hanterar när vi arbetar med bilder/videor är bildförhållande, som beskriver det normala proportionella förhållandet mellan bredden och höjden på en bild eller pixel.
När folk säger att en viss film eller bild är 16 gånger 9, menar de vanligtvis bildförhållande (DAR - från Bildförhållande). Ibland kan det dock finnas olika former på enskilda pixlar – i det här fallet talar vi om pixelförhållande (PAR - från Pixelbildförhållande).

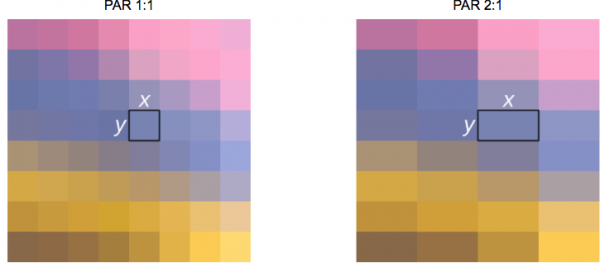
Meddelande till värdinnan: dvd motsvarar DAR 4 till 3
Även om den faktiska upplösningen för DVD är 704×480, bibehåller den fortfarande ett bildförhållande på 4:3 eftersom PAR är 10:11 (704×10 / 480×11).
Nå, äntligen kan vi avgöra video som en sekvens av n ramar för perioden tid, vilket kan betraktas som en ytterligare dimension. A n då är det bildfrekvensen eller antalet bildrutor per sekund (FPS - från Bildrutor per sekund).
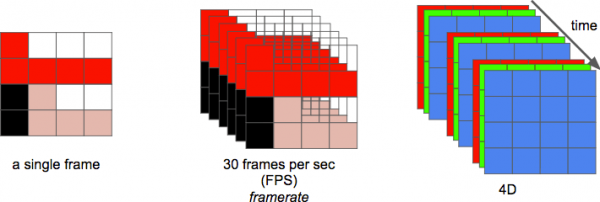
Antalet bitar per sekund som krävs för att visa en video är dess överföringshastighet - bithastighet.
bitrate = bredd * höjd * bitdjup * bildrutor per sekund
Till exempel skulle en video med 30 fps, 24 bitar per pixel och 480x240 kräva 82,944,000 82,944 30 bitar per sekund eller 480 Mbps (240x24xXNUMXxXNUMX) – men det är om ingen komprimeringsmetod används.
Om överföringshastigheten nästan konstant, då kallas det konstant bithastighet (CBR - från konstant bithastighet). Men det kan också variera, i vilket fall det kallas variabel bithastighet (VBR - från variabel bithastighet).
Denna graf visar begränsad VBR där inte alltför många bitar går till spillo vid en helt mörk bildruta.

Ingenjörer utvecklade ursprungligen en metod för att fördubbla den upplevda bildfrekvensen för en videoskärm utan att använda ytterligare bandbredd. Denna metod är känd som sammanflätad video; i princip skickar den halva skärmen i den första "bildrutan" och den andra hälften i nästa "bildruta".
Numera görs scenrendering huvudsakligen med hjälp av progressiva skanningsteknikerDet är en metod för att visa, lagra eller överföra rörliga bilder där alla linjer i varje bildruta ritas sekventiellt.

Nåväl! Nu vet vi hur en bild representeras digitalt, hur dess färger är arrangerade, hur många bitar per sekund vi behöver för att visa en video om överföringshastigheten är konstant (CBR) eller variabel (VBR). Vi känner till en given upplösning med en given bildhastighet, vi har bekantat oss med många andra termer, såsom sammanflätad video, PAR och några andra.
Ta bort redundans
Det är känt att okomprimerad video inte kan användas normalt. En timmeslång video med en upplösning på 720p och en frekvens på 30 bildrutor per sekund skulle ta upp 278 GB. Vi kommer fram till detta värde genom att multiplicera 1280 x 720 x 24 x 30 x 3600 (bredd, höjd, bitar per pixel, FPS och tid i sekunder).
Använd förlustfria komprimeringsalgoritmer, liksom DEFLATE (används i PKZIP, Gzip och PNG), kommer inte att minska den erforderliga bandbredden tillräckligt. Du måste leta efter andra sätt att komprimera video.
För att göra detta kan vi använda våra synfunktioner. Vi är bättre på att skilja ljusstyrka än färger. Video är en uppsättning bilder som upprepas över tid. Mellan intilliggande bildrutor i samma scen är skillnaderna små. Dessutom innehåller varje bildruta många områden som använder samma (eller liknande) färg.
Färg, ljusstyrka och våra ögon
Våra ögon är mer känsliga för ljusstyrka än för färg. Du kan se detta själv genom att titta på den här bilden.
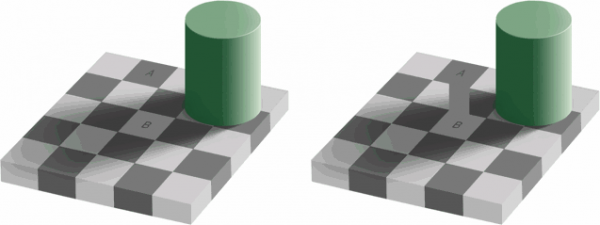
Om du inte ser att den vänstra halvan av bilden har samma färg som rutorna A и B faktiskt är desamma, så är detta normalt. Vår hjärna får oss att vara mer uppmärksamma på ljus och skugga, inte färg. På höger sida mellan de angivna rutorna finns en bygel i samma färg - så vi (dvs. vår hjärna) kan enkelt avgöra att det faktiskt finns samma färg.
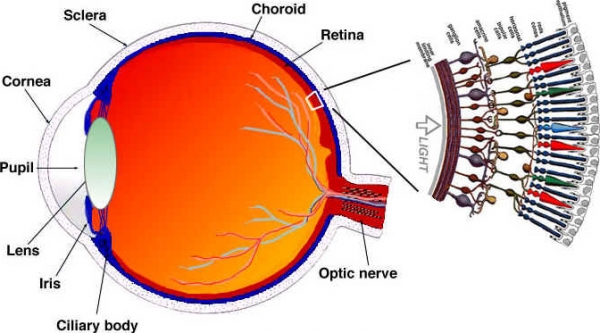
Låt oss ta en (förenklad) titt på hur våra ögon fungerar. Ögat är ett komplext organ som består av många delar. De delar vi är mest intresserade av är dock stavarna och tapparna. Ögat innehåller cirka 120 miljoner stavar och 6 miljoner tappar.
Låt oss titta på uppfattningen av färg och ljusstyrka som separata funktioner hos specifika delar av ögat (i verkligheten är det lite mer komplicerat än så, men vi ska förenkla). Stavceller är främst ansvariga för ljusstyrka, medan tappar är ansvariga för färg. Tappar delas in i tre typer, beroende på vilket pigment de innehåller: S-koner (blå), M-koner (gröna) och L-koner (röda).
Eftersom vi har många fler stavar (ljusstyrka) än koner (färg) följer det att vi bättre kan skilja övergångar mellan mörkt och ljust än mellan färger.
Funktioner för kontrastkänslighet
Forskare inom experimentell psykologi och många andra områden har utvecklat många teorier om mänsklig syn. En av dem kallas kontrastkänslighetsfunktionerDe är relaterade till rumslig och tidsmässig belysning. Kort sagt handlar det om hur mycket förändring som krävs innan observatören märker den. Observera pluralformen av ordet "funktion". Detta beror på att vi kan mäta kontrastkänslighetsfunktioner inte bara för svartvita bilder, utan även för färgbilder. Resultaten av dessa experiment visar att våra ögon i de flesta fall är mer känsliga för ljusstyrka än för färg.
Eftersom det är känt att vi är mer känsliga för en bilds ljusstyrka kan vi försöka använda oss av detta faktum.
Färgmodell
Vi har gått igenom lite hur man arbetar med färgbilder med hjälp av RGB-schemat. Det finns även andra modeller. Det finns en modell som skiljer ljusstyrka från färg, och den kallas YCbCrFörresten, det finns andra modeller som gör en liknande uppdelning, men vi kommer bara att betrakta denna.
I denna färgmodell Y — är en representation av ljusstyrka, och två färgkanaler används: Cb (rik blå) och Cr (rikt rött). YCbCr kan härledas från RGB, och omvänd transformation är också möjlig. Med hjälp av denna modell kan vi skapa bilder i fullfärg, som vi ser nedan:

Konvertering mellan YCbCr och RGB
Någon kommer att invända: hur är det möjligt att få alla färger om grönt inte används?
För att besvara denna fråga kommer vi att omvandla RGB till YCbCr. Vi kommer att använda koefficienterna som antagits i standarden. BT.601, vilket rekommenderades av enheten ITU-RDenna indelning definierar standarder för digital video. Till exempel: vad är 4K? Vilken bildfrekvens, upplösning och färgmodell bör vara?
Låt oss först beräkna ljusstyrkan. Vi använder konstanterna som föreslagits av ITU och ersätter RGB-värdena.
Y = 0.299R + 0.587G + 0.114B
När vi har ljusstyrkan separerar vi de blå och röda färgerna:
Cb = 0.564(B - Y)
Cr = 0.713(R - Y)
Och vi kan också konvertera tillbaka och till och med bli gröna med hjälp av YCbCr:
R = Y + 1.402Cr
B = Y + 1.772Cb
G = Y - 0.344Cb - 0.714Cr
Vanligtvis använder skärmar (monitorer, TV-apparater, skärmar etc.) endast RGB-modellen. Men den här modellen kan organiseras på olika sätt:

Kromasubsampling
Med en bild representerad som en kombination av luminans och krominans kan vi utnyttja det mänskliga visuella systemets större känslighet för luminans än för krominans genom att selektivt ta bort information. Kromasubsampling är en metod för att koda bilder med lägre upplösning för krominans än för luminans.
Hur mycket är det acceptabelt att minska färgupplösningen?! Det visar sig att det redan finns några scheman som beskriver hur man hanterar upplösningen och sammanfogningen (Slutlig färg = Y + Cb + Cr).
Dessa system är kända som delprovtagningssystem och uttrycks som ett 3-faldigt förhållande - a:x:y, vilket bestämmer antalet sampel av luminans- och färgskillnadssignaler.
a — horisontell provtagningsstandard (vanligtvis lika med 4)
x — antalet färgprover i den första raden med pixlar (horisontell upplösning i förhållande till a)
y — antalet ändringar i färgprover mellan den första och andra raden med pixlar.
Undantaget är 4:1:0, vilket ger ett färgprov i varje 4 x 4 luma-upplösningsblock.
Vanliga scheman som används i moderna codecs:
- 4:4:4 (utan delprovtagning)
- 4:2:2
- 4:1:1
- 4:2:0
- 4:1:0
- 3:1:1
YCbCr 4:2:0 - exempel på sammanslagning
Här är ett sammanfogat bildfragment med YCbCr 4:2:0. Observera att vi bara använder 12 bitar per pixel.
Så här ser samma bild ut kodad med de viktigaste typerna av kroma-subsampling. Den första raden är den slutliga YCbCr, den nedre raden visar kroma-upplösningen. Ganska hyfsade resultat, med tanke på den lilla kvalitetsförlusten.

Kommer du ihåg hur vi beräknade 278 GB diskutrymme för att lagra en timslång videofil med en upplösning på 720p och 30 bildrutor per sekund? Om vi använder YCbCr 4:2:0 kommer denna storlek att minskas med hälften - 139 GB. Hittills är det fortfarande långt ifrån ett acceptabelt resultat.
Du kan själv få YCbCr-histogrammet med hjälp av FFmpeg. I den här bilden är blått mer dominant än rött, vilket syns tydligt i själva histogrammet.

Färg, ljusstyrka, färgskala - videorecension
Jag rekommenderar att du tittar på den här grymma videon. Den förklarar vad ljusstyrka är och sätter punkterna i alla I:n och korsar alla T:n. ё om ljusstyrka och färg.

Ramtyper
Låt oss gå vidare. Låt oss försöka eliminera tidsredundans. Men först, låt oss definiera lite grundläggande terminologi. Låt oss säga att vi har en film med 30 bildrutor per sekund, här är dess första 4 bildrutor:




Vi kan se mycket upprepning i bildrutorna: till exempel ändras inte den blå bakgrunden från bildruta till bildruta. För att lösa detta problem kan vi abstrakt klassificera dem i tre typer av bildrutor.
I-ram (Intro-ram)
En I-bildruta (referensbildruta, nyckelbildruta, innerbildruta) är fristående. Oavsett vad som behöver visualiseras är en I-bildruta i huvudsak ett statiskt fotografi. Den första bilden är vanligtvis en I-bildruta, men vi ser regelbundet I-bildrutor bland bildrutor som är långt ifrån den första.

P-ram (P(förvrängd ram)
P-bildruta (prediktiv bildruta) utnyttjar det faktum att nästan alltid den aktuella bilden kan reproduceras med hjälp av den föregående bildrutan. Till exempel, i bildruta 2 är den enda förändringen att bollen rör sig framåt. Vi kan få bildruta 1 genom att helt enkelt modifiera bildruta 2 något, och endast använda skillnaden mellan de två bildrutorna. För att konstruera bildruta 1 hänvisar vi till den föregående bildrutan XNUMX.
 ←
← 
B-ram (Bi-prediktiv ram)
Vad sägs om att referera inte bara till tidigare bildrutor, utan även till framtida bildrutor, för att ge ännu bättre komprimering?! Detta är i grunden en B-bildruta (dubbelriktad bildruta).
 ←
←  →
→ 
Mellanslutsats
Dessa bildrutetyper används för att ge bästa möjliga komprimering. Vi ska titta på hur detta sker i nästa avsnitt. Observera för tillfället att den "dyraste" minnesmässigt är I-bildrutan, P-bildrutan är betydligt billigare och det mest lönsamma alternativet för video är B-bildrutan.

Temporal redundans (interframe-prediktion)
Låt oss överväga vilka möjligheter vi har att minimera upprepningar över tid. Vi kommer att lösa denna typ av redundans med hjälp av ömsesidiga prognosmetoder.
Låt oss försöka använda så få bitar som möjligt för att koda en sekvens av bildrutorna 0 och 1.
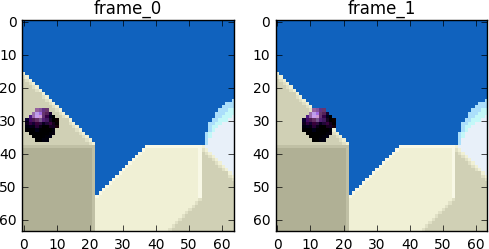
Vi kan producera subtraktion, subtraherar vi helt enkelt bildruta 1 från bildruta 0. Vi får bildruta 1, men vi använder bara skillnaden mellan den och föregående bildruta, och i själva verket kodar vi bara den resulterande resten.
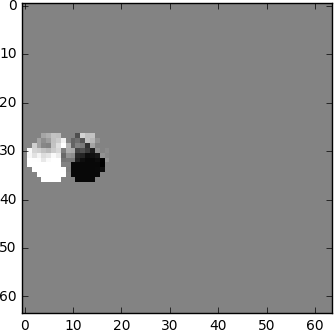
Men tänk om jag sa att det fanns en ännu bättre metod som använder ännu färre bitar?! Låt oss först dela upp bildruta 0 i ett snyggt rutnät av block. Sedan försöker vi matcha blocken från bildruta 0 till bildruta 1. Med andra ord, låt oss uppskatta rörelsen mellan bildrutorna.
Från Wikipedia - blockrörelsekompensation
Blockrörelsekompensation delar upp den aktuella bildrutan i icke-överlappande block och rörelsekompensationsvektorn anger var blocken kommer ifrån (en vanlig missuppfattning är att föregående Bildrutan är uppdelad i block som inte skär varandra, och rörelsekompensationsvektorerna visar var dessa block rör sig. Faktum är att det motsatta är sant - inte den föregående bildrutan analyseras, utan nästa, det tas reda på inte var blocken rör sig, utan var de kom ifrån. Vanligtvis överlappar de ursprungliga blocken den ursprungliga bildrutan. Vissa videokomprimeringsalgoritmer sätter ihop den aktuella bildrutan från delar av inte ens en, utan flera tidigare överförda bildrutor samtidigt.
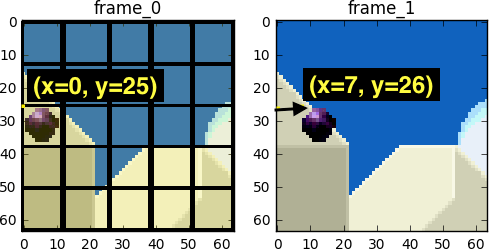
Under utvärderingsprocessen ser vi att bollen har rört sig från (x= 0, y=25) på (x= 6, y=26), värden x и y definiera rörelsevektorn. Ett annat steg vi kan ta för att spara bitar är att endast koda rörelsevektorskillnaden mellan den sista blockpositionen och den förutspådda, så den slutliga rörelsevektorn blir (x=6-0=6, y=26-25=1).
I en verklig situation skulle denna boll delas in i n block, men detta förändrar inte sakens kärna.
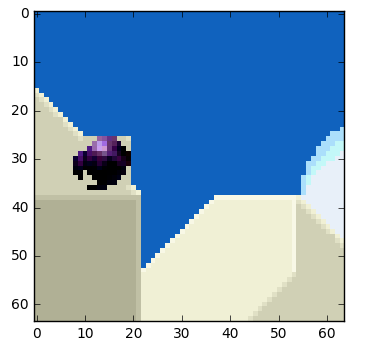
Objekt i bilden rör sig i tre dimensioner, så när bollen rör sig kan den verka mindre (eller större om den rör sig mot betraktaren). Det är normalt att det inte blir en perfekt matchning mellan blocken. Här är en sammansatt vy av vår uppskattning och den verkliga varan.
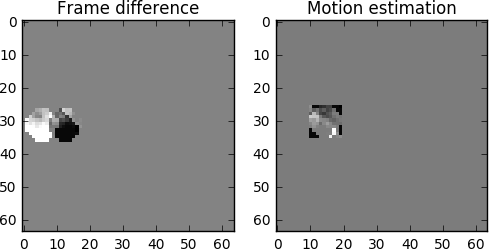
Men vi ser att när vi använder rörelseestimering finns det betydligt mindre data för kodning än när vi använder en enklare metod för att beräkna deltat mellan bildrutor.
Hur kommer verklig rörelsekompensation att se ut?
Denna teknik tillämpas på alla block samtidigt. Ofta delas vår villkorliga rörliga boll upp i flera block samtidigt.

Du kan själv uppleva dessa koncept med hjälp av .
För att se rörelsevektorerna kan du skapa en video med extern prediktion med hjälp av .

Du kan också använda (det är betalt, men det finns en gratis provversion som är begränsad till endast de första tio bildrutorna).
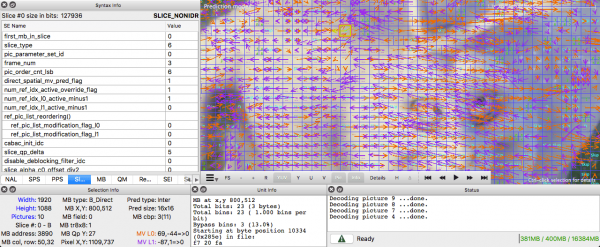
Spatial redundans (intern prediktion)
Om vi analyserar varje bildruta i videon hittar vi många sammankopplade områden.

Låt oss gå igenom det här exemplet. Den här scenen är mestadels blå och vit.

Detta är en I-frame. Vi kan inte använda tidigare frames för prediktion, men vi kan komprimera den. Låt oss koda markeringen av det röda blocket. Om vi tittar på dess grannar märker vi att det finns vissa färgtrender runt det.
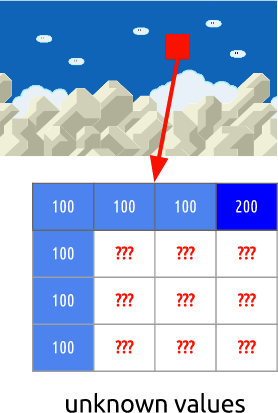
Vi antar att bildrutans färger är vertikalt fördelade. Vilket innebär att färgen på okända pixlar kommer att innehålla värdena för dess grannar.
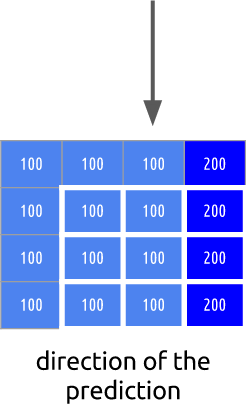
Denna förutsägelse kan också vara felaktig. Det är därför vi behöver tillämpa denna metod (intern förutsägelse) och sedan subtrahera de verkliga värdena. Detta ger oss ett residualblock, vilket resulterar i en mycket mer komprimerad matris jämfört med originalet.

Om du vill öva med intraprediktioner kan du skapa en video med makroblock och deras prediktioner med hjälp av ffmpeg. För att förstå betydelsen av varje blockfärg måste du läsa ffmpeg-dokumentationen.

Eller så kan du använda Intel Video Pro Analyzer (som jag nämnde ovan är den kostnadsfria testversionen begränsad till de första 10 bildrutorna, men det borde räcka för dig till en början).
Del två:
Källa: will.com
