

Artikeln diskuterar flera sätt att bestämma den matematiska ekvationen för en enkel (parad) regressionslinje.
Alla metoder för att lösa ekvationen som behandlas här är baserade på minstakvadratmetoden. Låt oss beteckna metoderna enligt följande:
- Аналитическое решение
- Gradient Descent
- Stokastisk gradientnedgång
För var och en av metoderna för att lösa ekvationen för en rät linje tillhandahåller artikeln olika funktioner, vilka huvudsakligen är indelade i de som skrivs utan att använda biblioteket. numpy och de som används för beräkningar numpy. Man tror att skicklig användning numpy kommer att minska datorkostnaderna.
All kod som tillhandahålls i artikeln är skriven i språket python 2.7 med Jupyter Notebook. Källkoden och exempeldatafilen finns publicerade på
Artikeln riktar sig mer till både nybörjare och de som redan har börjat gradvis behärska studiet av ett mycket omfattande avsnitt inom artificiell intelligens – maskininlärning.
För att illustrera materialet kommer vi att använda ett mycket enkelt exempel.
Exempelvillkor
Vi har fem värden som kännetecknar beroendet Y från X (Tabell nr 1):
Tabell nr 1 "Exempelvillkor"

Låt oss anta att värdena  — detta är årets månad, och
— detta är årets månad, och  — intäkter denna månad. Med andra ord beror intäkterna på årets månad, och
— intäkter denna månad. Med andra ord beror intäkterna på årets månad, och  — den enda egenskapen som intäkterna är beroende av.
— den enda egenskapen som intäkterna är beroende av.
Exemplet är sådär, både ur synvinkeln av intäkternas villkorliga beroende av årets månad, och ur antalet värdens synvinkel - det finns väldigt få av dem. En sådan förenkling kommer dock att tillåta, som de säger, att förklara på fingrarna det material som inte alltid är lätt att assimilera av nybörjare. Och även siffrornas enkelhet gör det möjligt för de som vill lösa exemplet på papper utan betydande arbetskraftskostnader.
Låt oss anta att beroendet som ges i exemplet kan approximeras ganska väl med den matematiska ekvationen för en enkel (parad) regressionslinje av formen:

där  — är den månad då intäkterna mottogs,
— är den månad då intäkterna mottogs,  — intäkter motsvarande månaden,
— intäkter motsvarande månaden,  и
и  — regressionskoefficienter för den uppskattade linjen.
— regressionskoefficienter för den uppskattade linjen.
Observera att koefficienten  ofta kallad lutningen eller gradienten för den uppskattade linjen; representerar det belopp med vilket förändringen kommer att ske
ofta kallad lutningen eller gradienten för den uppskattade linjen; representerar det belopp med vilket förändringen kommer att ske  när man byter
när man byter  .
.
Självklart är vår uppgift i exemplet att välja sådana koefficienter i ekvationen  и
и  , där avvikelserna mellan våra beräknade intäktsvärden per månad från de sanna svaren, dvs. värden som presenteras i urvalet, kommer att vara minimala.
, där avvikelserna mellan våra beräknade intäktsvärden per månad från de sanna svaren, dvs. värden som presenteras i urvalet, kommer att vara minimala.
Minsta kvadratmetoden
Enligt minstakvadratmetoden bör avvikelsen beräknas genom att kvadrera den. Denna teknik gör det möjligt att undvika ömsesidig annullering av avvikelser om de har motsatta tecken. Till exempel, om avvikelsen i ett fall är +5 (plus fem), och i den andra -5 (minus fem), så kommer summan av avvikelserna att ta ut varandra och uppgå till 0 (noll). Det är möjligt att inte kvadrera avvikelsen, utan att använda modulens egenskap, och då kommer alla våra avvikelser att vara positiva och ackumuleras. Vi kommer inte att uppehålla oss vid denna punkt i detalj, utan helt enkelt notera att det för att underlätta beräkningarna är brukligt att kvadrera avvikelsen.
Så här ser formeln ut, med vilken vi ska bestämma den minsta summan av kvadrerade avvikelser (fel):

där  — detta är approximationsfunktionen för de sanna svaren (det vill säga den intäkt vi beräknade),
— detta är approximationsfunktionen för de sanna svaren (det vill säga den intäkt vi beräknade),
 — dessa är de sanna svaren (intäkter anges i urvalet),
— dessa är de sanna svaren (intäkter anges i urvalet),
 — är stickprovsindexet (numret på den månad då avvikelsen bestäms)
— är stickprovsindexet (numret på den månad då avvikelsen bestäms)
Låt oss derivera funktionen, bestämma de partiella differentialekvationerna och vara redo att gå vidare till den analytiska lösningen. Men först, låt oss ta en kort utflykt i vad differentiering är och erinra oss den geometriska betydelsen av derivatan.
Differentiering
Derivering är operationen för att hitta derivatan av en funktion.
Vad är derivatan till för? Derivatan av en funktion karaktäriserar funktionens förändringshastighet och anger dess riktning. Om derivatan vid en given punkt är positiv, ökar funktionen; annars minskar funktionen. Och ju större derivatans värde är i absolutbelopp, desto högre är förändringshastigheten för funktionsvärdena och desto brantare är lutningen på funktionsgrafen.
Till exempel, i det kartesiska koordinatsystemet är värdet på derivatan i punkten M(0,0) lika med +25 betyder att vid en given punkt, när värdet förskjuts  till höger med en konventionell enhet, värde
till höger med en konventionell enhet, värde  ökar med 25 konventionella enheter. På grafen ser detta ut som en ganska brant värdeökning.
ökar med 25 konventionella enheter. På grafen ser detta ut som en ganska brant värdeökning.  från en given punkt.
från en given punkt.
Ett annat exempel. Derivatans värde är lika med -0,1 betyder att när man växlar  per konventionell enhet, värde
per konventionell enhet, värde  minskar med endast 0,1 konventionella enheter. Samtidigt kan vi på funktionsgrafen observera en knappt märkbar nedåtgående lutning. Om vi drar en analogi med ett berg, är det som om vi väldigt långsamt går nerför en svag sluttning från berget, till skillnad från i föregående exempel, där vi var tvungna att ta väldigt branta toppar :)
minskar med endast 0,1 konventionella enheter. Samtidigt kan vi på funktionsgrafen observera en knappt märkbar nedåtgående lutning. Om vi drar en analogi med ett berg, är det som om vi väldigt långsamt går nerför en svag sluttning från berget, till skillnad från i föregående exempel, där vi var tvungna att ta väldigt branta toppar :)
Således, efter att ha differentierat funktionen  med koefficienter
med koefficienter  и
и  , definierar vi partiella derivataekvationer av första ordningen. Efter att ha definierat ekvationerna får vi ett system med två ekvationer, och genom att lösa vilka vi kan välja sådana värden på koefficienterna
, definierar vi partiella derivataekvationer av första ordningen. Efter att ha definierat ekvationerna får vi ett system med två ekvationer, och genom att lösa vilka vi kan välja sådana värden på koefficienterna  и
и  , där värdena på motsvarande derivator vid givna punkter förändras med en mycket, mycket liten mängd, och i fallet med en analytisk lösning inte förändras alls. Med andra ord kommer felfunktionen för de funna koefficienterna att nå ett minimum, eftersom värdena på partiella derivator vid dessa punkter kommer att vara lika med noll.
, där värdena på motsvarande derivator vid givna punkter förändras med en mycket, mycket liten mängd, och i fallet med en analytisk lösning inte förändras alls. Med andra ord kommer felfunktionen för de funna koefficienterna att nå ett minimum, eftersom värdena på partiella derivator vid dessa punkter kommer att vara lika med noll.
Så, enligt differentieringsreglerna, ekvationen för den första ordningens partiella derivata med avseende på koefficienten  kommer att ha formen:
kommer att ha formen:

första ordningens partiella derivataekvation med avseende på  kommer att ha formen:
kommer att ha formen:

Som ett resultat erhöll vi ett ekvationssystem som har en ganska enkel analytisk lösning:
börja{ekvation*}
börja{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
slut{cases}
slut{ekvation*}
Innan vi löser ekvationen, låt oss förladda, kontrollera att inläsningen är korrekt och formatera data.
Laddar och formaterar data
Det bör noteras att på grund av att vi för den analytiska lösningen, och senare för gradient och stokastisk gradientnedgång, kommer att använda koden i två varianter: med hjälp av biblioteket numpy och utan att använda den behöver vi lämplig dataformatering (se kod).
Datainläsning och bearbetningskod
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Visualisering
Nu, efter att vi först har laddat in data, sedan kontrollerat att inläsningen är korrekt och slutligen formaterat data, låt oss göra den första visualiseringen. Metoden som ofta används för detta ändamål är parplot bibliotek sjöfödd. I vårt exempel, på grund av det begränsade antalet nummer, finns det ingen mening med att använda biblioteket sjöfödd. Vi kommer att använda ett vanligt bibliotek matplotlib och låt oss bara titta på spridningsdiagrammet.
Spridningsdiagramkod
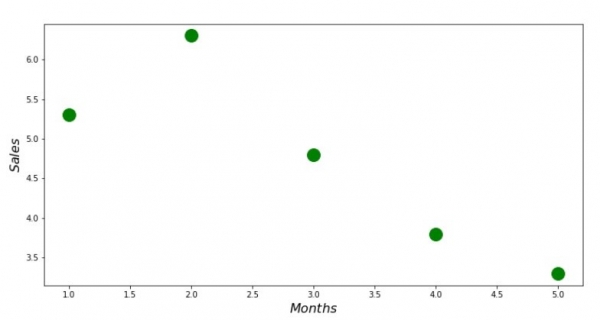
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Diagram nr 1 "Intäkternas beroende på årets månad"
Аналитическое решение
Låt oss använda de vanligaste verktygen i pytonorm och lös ekvationssystemet:
börja{ekvation*}
börja{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
slut{cases}
slut{ekvation*}
Enligt Cramers regel vi kommer att hitta en gemensam determinant, såväl som determinanter genom  och
och  , varefter determinanten divideras med
, varefter determinanten divideras med  på den gemensamma determinanten - vi hittar koefficienten
på den gemensamma determinanten - vi hittar koefficienten  , på liknande sätt hittar vi koefficienten
, på liknande sätt hittar vi koefficienten  .
.
Analytisk lösningskod
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Detta är vad vi fick:

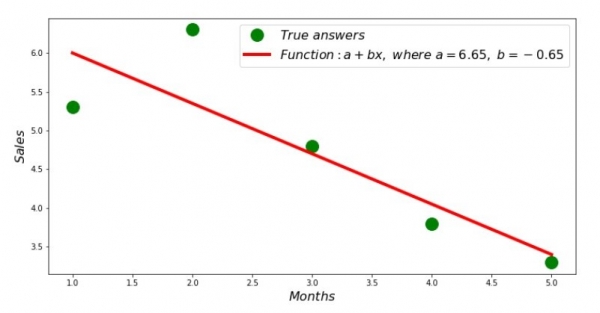
Så har koefficienternas värden hittats, summan av kvadraterna av avvikelserna har fastställts. Låt oss rita en rak linje på spridningshistogrammet i enlighet med de funna koefficienterna.
Regressionslinjekod
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Diagram #2 "Rätta och beräknade svar"
Du kan titta på grafen över avvikelser för varje månad. I vårt fall kommer vi inte att få något betydande praktiskt värde av det, men vi kommer att tillfredsställa vår nyfikenhet på hur väl den enkla linjära regressionsekvationen karakteriserar intäkternas beroende av årets månad.
Avvikelsegrafkod
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Diagram nr 3 "Avvikelser, %"
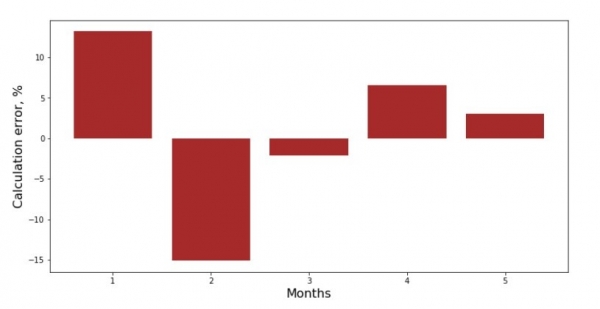
Det är inte perfekt, men vi uppnådde vårt mål.
Låt oss skriva en funktion som bestämmer koefficienterna  и
и  använder biblioteket numpy, mer exakt, kommer vi att skriva två funktioner: en med hjälp av en pseudo-invers matris (rekommenderas inte i praktiken, eftersom processen är beräkningsmässigt komplex och instabil), den andra med hjälp av en matrisekvation.
använder biblioteket numpy, mer exakt, kommer vi att skriva två funktioner: en med hjälp av en pseudo-invers matris (rekommenderas inte i praktiken, eftersom processen är beräkningsmässigt komplex och instabil), den andra med hjälp av en matrisekvation.
Analytisk lösningskod (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npLåt oss jämföra tiden det tog att bestämma koefficienterna  и
и  , i enlighet med de 3 presenterade metoderna.
, i enlighet med de 3 presenterade metoderna.
Kod för att beräkna beräkningstid
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
På en liten mängd data kommer en "självskriven" funktion ut framöver, som hittar koefficienterna med hjälp av Cramers metod.
Nu kan vi gå vidare till andra metoder för att hitta koefficienter  и
и  .
.
Gradient Descent
Låt oss först definiera vad en gradient är. Enkelt uttryckt är gradienten ett segment som anger riktningen för en funktions maximala tillväxt. I analogi med att bestiga ett berg, där lutningen är vänd, är den brantaste klättringen till toppen av berget. När vi utvecklar exemplet med berget kommer vi ihåg att vi faktiskt behöver den brantaste nedstigningen för att nå botten så snabbt som möjligt, det vill säga minimum - den plats där funktionen varken ökar eller minskar. Vid denna tidpunkt kommer derivatan att vara noll. Därför behöver vi inte en gradient, utan en antigradient. För att hitta antigradienten behöver du bara multiplicera gradienten med -1 (minus ett).
Låt oss notera att funktionen kan ha flera minimumvärden, och om vi har gått ner till ett av dem enligt den algoritm som föreslås nedan, kommer vi inte att kunna hitta ett annat minimum, vilket kan vara lägre än det som hittats. Låt oss slappna av, vi är inte i fara! I vårt fall har vi att göra med ett enda minimum, eftersom vår funktion  På grafen ser det ut som en vanlig parabel. Och som vi alla borde veta mycket väl från vår matematikkurs i skolan, har en parabel bara ett minimum.
På grafen ser det ut som en vanlig parabel. Och som vi alla borde veta mycket väl från vår matematikkurs i skolan, har en parabel bara ett minimum.
Efter att vi förstått varför vi behövde en gradient, och även att en gradient är ett segment, det vill säga en vektor med givna koordinater, vilka är just de koefficienterna  и
и  Vi kan implementera gradientnedstigning.
Vi kan implementera gradientnedstigning.
Innan jag börjar föreslår jag att du läser några meningar om nedstigningsalgoritmen:
- Vi bestämmer koefficienternas koordinater på ett pseudoslumpmässigt sätt
 и . I vårt exempel definierar vi koefficienter nära noll. Detta är vanlig praxis, men varje fall kan ha sin egen praxis.
и . I vårt exempel definierar vi koefficienter nära noll. Detta är vanlig praxis, men varje fall kan ha sin egen praxis. - Från koordinaten vi subtraherar värdet av första ordningens partiella derivata i punkten . Så, om derivatan är positiv, ökar funktionen. Genom att subtrahera derivatans värde kommer vi därför att röra oss i motsatt riktning mot tillväxten, det vill säga i nedgångsriktningen. Om derivatan är negativ, minskar funktionen i denna punkt och genom att subtrahera derivatans värde rör vi oss i nedåtgående riktning.
- Vi utför en liknande operation med koordinaten : subtrahera värdet av den partiella derivatan i punkten .
- För att inte hoppa över minimum och inte flyga iväg ut i rymden är det nödvändigt att ställa in steglängden i nedstigningsriktningen. Generellt sett skulle man kunna skriva en hel artikel om hur man ställer in steget korrekt och hur man ändrar det under nedstigningen för att minska beräkningskostnaderna. Men nu har vi en något annorlunda uppgift framför oss, och vi kommer att använda den vetenskapliga trial and error-metoden, eller som man säger i dagligt tal, empiriskt, för att fastställa stegstorleken.
- Efter att vi har satt koordinaterna и subtraherar vi värdena på derivatorna, får vi nya koordinater и . Vi tar nästa steg (subtraktion), redan från de beräknade koordinaterna. Och så börjar cykeln om och om igen tills den erforderliga konvergensen uppnås.
 и
и  . I vårt exempel definierar vi koefficienter nära noll. Detta är vanlig praxis, men varje fall kan ha sin egen praxis.
. I vårt exempel definierar vi koefficienter nära noll. Detta är vanlig praxis, men varje fall kan ha sin egen praxis. vi subtraherar värdet av första ordningens partiella derivata i punkten
vi subtraherar värdet av första ordningens partiella derivata i punkten  . Så, om derivatan är positiv, ökar funktionen. Genom att subtrahera derivatans värde kommer vi därför att röra oss i motsatt riktning mot tillväxten, det vill säga i nedgångsriktningen. Om derivatan är negativ, minskar funktionen i denna punkt och genom att subtrahera derivatans värde rör vi oss i nedåtgående riktning.
. Så, om derivatan är positiv, ökar funktionen. Genom att subtrahera derivatans värde kommer vi därför att röra oss i motsatt riktning mot tillväxten, det vill säga i nedgångsriktningen. Om derivatan är negativ, minskar funktionen i denna punkt och genom att subtrahera derivatans värde rör vi oss i nedåtgående riktning.  : subtrahera värdet av den partiella derivatan i punkten
: subtrahera värdet av den partiella derivatan i punkten  .
. и
и  subtraherar vi värdena på derivatorna, får vi nya koordinater
subtraherar vi värdena på derivatorna, får vi nya koordinater  и
и  . Vi tar nästa steg (subtraktion), redan från de beräknade koordinaterna. Och så börjar cykeln om och om igen tills den erforderliga konvergensen uppnås.
. Vi tar nästa steg (subtraktion), redan från de beräknade koordinaterna. Och så börjar cykeln om och om igen tills den erforderliga konvergensen uppnås.Alla! Nu är vi redo att ge oss ut på jakt efter Marianergravens djupaste ravin. Låt oss börja.
Kod för gradientnedgång
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Vi dök ner till botten av Marianergraven och fann samma koefficientvärden där.  и
и  , vilket faktiskt var vad man kunde förvänta sig.
, vilket faktiskt var vad man kunde förvänta sig.
Låt oss göra ett nytt dyk, fast den här gången kommer fyllningen av vår djuphavsapparat att vara olika teknologier, nämligen ett bibliotek. numpy.
Kod för gradientnedgång (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Värden på koefficienterna  и
и  oförändrad.
oförändrad.
Låt oss titta på hur felet förändrades under gradientnedgången, det vill säga hur summan av de kvadrerade avvikelserna förändrades med varje steg.
Kod för summan av kvadratiska avvikelser graf
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Diagram #4 "Summa av kvadrerade avvikelser i gradientnedgång"
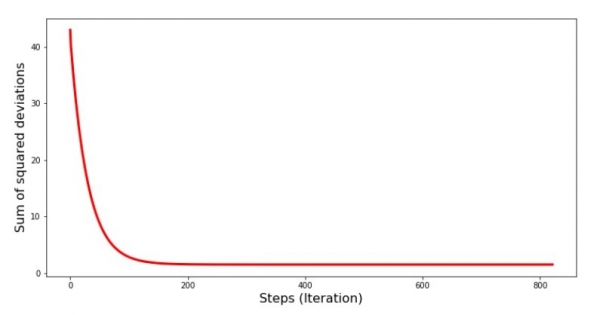
På grafen ser vi att felet minskar med varje steg, och efter ett visst antal iterationer observerar vi en nästan horisontell linje.
Slutligen, låt oss utvärdera skillnaden i kodkörningstid:
Kod för att bestämma beräkningstiden för gradientnedgång
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Kanske gör vi något fel, men återigen en enkel "hemgjord" funktion som inte använder ett bibliotek. numpy överträffar funktionen som använder biblioteket i termer av beräkningstid numpy.
Men vi står inte stilla, utan går mot att studera ett annat fascinerande sätt att lösa ekvationen för enkel linjär regression. Möta!
Stokastisk gradientnedgång
För att snabbt förstå hur stokastisk gradientdescent fungerar är det bättre att definiera dess skillnader från vanlig gradientdescent. Vid gradientnedgång, i ekvationerna för derivator av  и
и  använde summorna av värdena för alla funktioner och sanna svar som fanns tillgängliga i urvalet (det vill säga summorna av alla
använde summorna av värdena för alla funktioner och sanna svar som fanns tillgängliga i urvalet (det vill säga summorna av alla  и
и  ). I stokastisk gradientdescent kommer vi inte att använda alla värden som finns tillgängliga i urvalet, utan istället kommer vi pseudoslumpmässigt att välja ett så kallat urvalsindex och använda dess värden.
). I stokastisk gradientdescent kommer vi inte att använda alla värden som finns tillgängliga i urvalet, utan istället kommer vi pseudoslumpmässigt att välja ett så kallat urvalsindex och använda dess värden.
Om till exempel indexet bestäms till nummer 3 (tre), tar vi värdena  и
и  , sedan sätter vi in värdena i derivatekvationerna och bestämmer nya koordinater. Sedan, efter att ha bestämt koordinaterna, bestämmer vi återigen pseudoslumpmässigt provindexet, ersätter värdena som motsvarar indexet i partiella derivatekvationer och bestämmer koordinaterna på nytt.
, sedan sätter vi in värdena i derivatekvationerna och bestämmer nya koordinater. Sedan, efter att ha bestämt koordinaterna, bestämmer vi återigen pseudoslumpmässigt provindexet, ersätter värdena som motsvarar indexet i partiella derivatekvationer och bestämmer koordinaterna på nytt.  и
и  etc. tills konvergensen blir grön. Vid första anblicken kan det verka som att detta skulle kunna fungera alls, men det gör det. Det är sant att det är värt att notera att felet inte minskar med varje steg, men trenden finns definitivt där.
etc. tills konvergensen blir grön. Vid första anblicken kan det verka som att detta skulle kunna fungera alls, men det gör det. Det är sant att det är värt att notera att felet inte minskar med varje steg, men trenden finns definitivt där.
Vilka är fördelarna med stokastisk gradientnedstigning jämfört med vanlig gradientnedstigning? Om vårt urval är mycket stort och mäts i tiotusentals värden, är det mycket lättare att bearbeta, säg, ett slumpmässigt tusental av dem, än hela urvalet. Det är här stokastisk gradientnedgång kommer in i bilden. I vårt fall kommer vi förstås inte att märka någon större skillnad.
Låt oss titta på koden.
Kod för stokastisk gradientnedgång
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Vi tittar noga på koefficienterna och märker att vi ställer oss frågan "Hur är detta möjligt?" Vi fick olika värden på koefficienterna  и
и  . Kanske stokastisk gradientnedgång hittade mer optimala parametrar för ekvationen? Tyvärr, nej. Det räcker att titta på summan av kvadraterna av avvikelserna och se att med nya värden på koefficienterna är felet större. Låt oss inte rusa till förtvivlan. Låt oss rita ett diagram över felförändringen.
. Kanske stokastisk gradientnedgång hittade mer optimala parametrar för ekvationen? Tyvärr, nej. Det räcker att titta på summan av kvadraterna av avvikelserna och se att med nya värden på koefficienterna är felet större. Låt oss inte rusa till förtvivlan. Låt oss rita ett diagram över felförändringen.
Kod för stokastisk gradientnedgångssummafeldiagram
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Diagram #5 "Summa av kvadrerade avvikelser i stokastisk gradientnedgång"
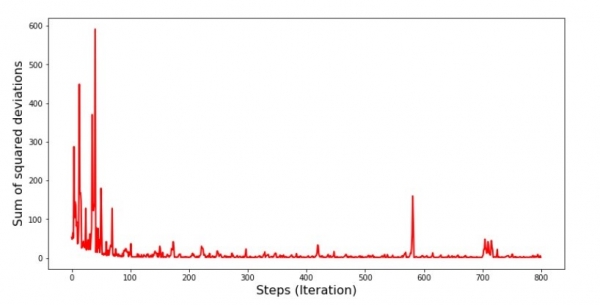
När man tittar på diagrammet faller allt på plats och nu ska vi fixa allt.
Så vad hände? Följande hände. När vi slumpmässigt väljer en månad är det för den valda månaden som vår algoritm försöker minska felet i intäktsberäkningen. Sedan väljer vi en annan månad och upprepar beräkningen, men vi minskar felet för den andra valda månaden. Låt oss nu komma ihåg att våra två första månader avviker avsevärt från linjen i den enkla linjära regressionsekvationen. Det betyder att när någon av dessa två månader väljs, genom att minska felet för var och en av dem, ökar vår algoritm felet avsevärt för hela urvalet. Så vad ska man göra? Svaret är enkelt: du måste minska nedstigningssteget. Genom att minska nedstigningssteget kommer felet trots allt också att sluta "hoppa" upp och ner. Mer exakt kommer felet inte att sluta "hoppa", men det kommer inte att göra det lika snabbt :) Låt oss kolla.
Kod för att köra SGD med mindre steg
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Diagram #6 “Summa av kvadrerade avvikelser i stokastisk gradientnedgång (80 tusen steg)”
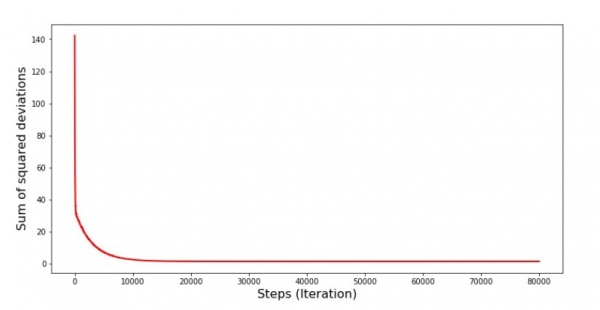
Koefficientvärdena har förbättrats, men är fortfarande inte idealiska. Hypotetiskt sett skulle detta kunna lösas på detta sätt. Till exempel väljer vi, under de senaste 1000 iterationerna, värdena på de koefficienter med vilka det minsta felet gjordes. Visst, för detta måste vi skriva ner värdena på själva koefficienterna. Vi kommer inte att göra det, utan snarare vara uppmärksamma på diagrammet. Det ser jämnt ut och felet verkar minska jämnt. Faktum är att detta inte är sant. Låt oss titta på de första 1000 iterationerna och jämföra dem med de senaste.
Kod för SGD-diagram (första 1000 stegen)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Diagram #7 “SGD Summa av kvadratiska avvikelser (första 1000 stegen)”
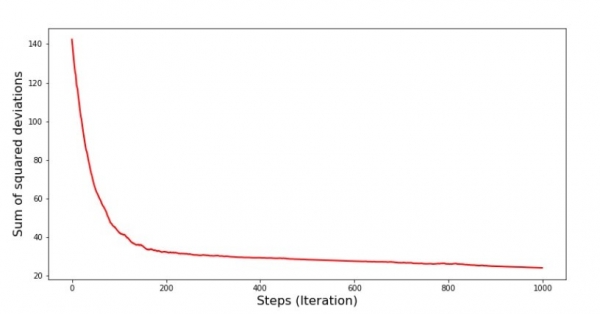
Diagram #8 “SGD Summa av kvadratiska avvikelser (senaste 1000 steg)”
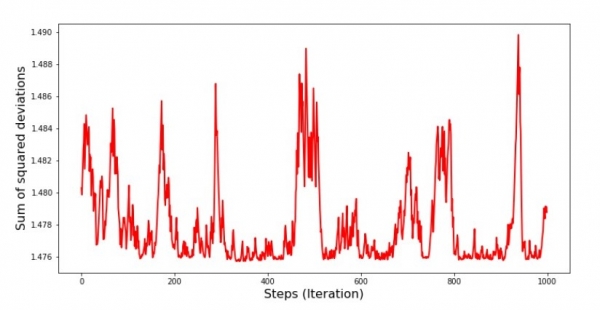
Alldeles i början av nedstigningen observerar vi en ganska jämn och brant minskning av felet. I de senaste iterationerna ser vi att felet går runt och runt värdet 1,475 och vid vissa punkter till och med är lika med detta optimala värde, men sedan går det fortfarande upp... Jag upprepar, du kan skriva ner värdena på koefficienterna.  и
и  och välj sedan de för vilka felet är minimalt. Vi hade dock ett allvarligare problem: vi var tvungna att ta 80 tusen steg (se kod) för att få värden nära optimala. Och detta motsäger redan idén att spara beräkningstid med stokastisk gradientdescent i förhållande till gradientdescent. Vad kan korrigeras och förbättras? Det är inte svårt att märka att vi i de första iterationerna rör oss med säkerhet nedåt och därför bör vi lämna ett stort steg i de första iterationerna och minska steget allt eftersom vi går framåt. Det kommer vi inte att göra i den här artikeln – den är redan för lång. De som vill kan själva fundera ut hur man gör detta, det är inte svårt 🙂
och välj sedan de för vilka felet är minimalt. Vi hade dock ett allvarligare problem: vi var tvungna att ta 80 tusen steg (se kod) för att få värden nära optimala. Och detta motsäger redan idén att spara beräkningstid med stokastisk gradientdescent i förhållande till gradientdescent. Vad kan korrigeras och förbättras? Det är inte svårt att märka att vi i de första iterationerna rör oss med säkerhet nedåt och därför bör vi lämna ett stort steg i de första iterationerna och minska steget allt eftersom vi går framåt. Det kommer vi inte att göra i den här artikeln – den är redan för lång. De som vill kan själva fundera ut hur man gör detta, det är inte svårt 🙂
Nu ska vi utföra en stokastisk gradientnedstigning med hjälp av biblioteket. numpy (och låt oss inte snubbla på stenarna som vi identifierade tidigare)
Kod för stokastisk gradientnedgång (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Värdena var nästan desamma som vid nedstigning utan att använda numpy. Detta är dock logiskt.
Låt oss ta reda på hur mycket tid det tog oss att utföra stokastiska gradientnedgångar.
Kod för att bestämma beräkningstiden för SGD (80 tusen steg)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Ju längre in i skogen, desto mörkare moln: återigen visar den "självskrivna" formeln det bästa resultatet. Allt detta tyder på att det måste finnas ännu mer subtila sätt att använda biblioteket. numpy, vilket verkligen snabbar upp datoroperationerna. Vi kommer inte att lära oss om dem i den här artikeln. Det kommer finnas något att fundera över på fritiden :)
sammanfatta
Innan jag sammanfattar vill jag besvara en fråga som troligtvis uppstått hos vår kära läsare. Varför, egentligen, sådan "plåga" med nedförsbackar, varför måste vi gå upp och ner för berget (mestadels ner) för att hitta det värdefulla låglandet, om vi har en så kraftfull och enkel apparat i våra händer, i form av en analytisk lösning, som omedelbart teleporterar oss till rätt plats?
Svaret på denna fråga ligger på ytan. Nu har vi tittat på ett mycket enkelt exempel där det sanna svaret är  beror på ett tecken
beror på ett tecken  . Det här ser man inte särskilt ofta i livet, så låt oss föreställa oss att vi har 2, 30, 50 eller fler tecken. Låt oss lägga till detta tusentals, om inte tiotusentals värden för varje funktion. I det här fallet kanske den analytiska lösningen inte håller måttet och misslyckas. I sin tur kommer gradientens nedgång och dess variationer sakta men säkert att föra oss närmare målet - funktionens minimum. Och oroa dig inte för hastigheten – vi kommer förmodligen fortfarande att titta på metoder som gör att vi kan ställa in och reglera steglängden (det vill säga hastigheten).
. Det här ser man inte särskilt ofta i livet, så låt oss föreställa oss att vi har 2, 30, 50 eller fler tecken. Låt oss lägga till detta tusentals, om inte tiotusentals värden för varje funktion. I det här fallet kanske den analytiska lösningen inte håller måttet och misslyckas. I sin tur kommer gradientens nedgång och dess variationer sakta men säkert att föra oss närmare målet - funktionens minimum. Och oroa dig inte för hastigheten – vi kommer förmodligen fortfarande att titta på metoder som gör att vi kan ställa in och reglera steglängden (det vill säga hastigheten).
Och nu, en kort sammanfattning.
För det första hoppas jag att materialet som presenteras i artikeln kommer att hjälpa nybörjare inom "data scientists" att förstå hur man löser enkla (och inte bara) linjära regressionsekvationer.
För det andra tittade vi på flera sätt att lösa ekvationen. Nu kan vi, beroende på situationen, välja den som är bäst lämpad för att lösa problemet.
För det tredje såg vi kraften i en ytterligare justering, nämligen steglängden för gradientnedgången. Denna parameter kan inte försummas. Som nämnts ovan bör steglängden ändras under nedstigningen för att minska kostnaden för att utföra beräkningar.
För det fjärde, i vårt fall visade de "självskrivna" funktionerna det bästa tidsresultatet av beräkningarna. Detta beror förmodligen på att bibliotekets möjligheter används mindre professionellt. numpy. Men hur det än må vara, följande slutsats antyder sig själv. Å ena sidan är det ibland värt att ifrågasätta etablerade åsikter, men å andra sidan är det inte alltid värt att komplicera allting – tvärtom visar sig ibland ett enklare sätt att lösa ett problem vara mer effektivt. Och eftersom vårt mål var att analysera tre metoder för att lösa ekvationen för enkel linjär regression, var användningen av "självskrivna" funktioner fullt tillräcklig för oss.
Litteratur (eller något liknande)
1. Linjär regression
2. Minsta kvadratmetoden
3. Derivat
4. Gradient
5. Gradientnedgång
6. NumPy-biblioteket
Källa: will.com
