

Huu hata si mzaha; inaonekana kama picha hii inaonyesha kwa usahihi kiini cha hifadhidata hizi, na mwishowe itakuwa wazi kwa nini:

Kulingana na Nafasi ya DB-Engines, hifadhidata mbili maarufu za safuwima za NoSQL ni Cassandra (hapa CS) na HBase (HB).
Kwa mapenzi ya hatima, timu yetu ya usimamizi wa upakiaji data katika Sberbank tayari ina na inafanya kazi kwa karibu na HB. Katika wakati huu, tumepata ufahamu mzuri wa uwezo na udhaifu wake na tumejifunza jinsi ya kuitumia. Walakini, uwepo wa njia mbadala katika mfumo wa CS ulitufanya tujitese kila wakati na mashaka: tulifanya chaguo sahihi? Hasa kutokana na matokeo Majaribio ya DataStax yalidai kuwa CS inashinda HB kwa urahisi kwa mporomoko mkubwa. Walakini, DataStax ina masilahi, kwa hivyo haifai kuchukua neno lao kwa hilo. Maelezo machache kuhusu hali ya majaribio pia yalihusu, kwa hivyo tuliamua kujitafutia wenyewe ni nani mfalme wa BigData NoSql, na matokeo yalikuwa ya kuvutia sana.
Hata hivyo, kabla ya kujadili matokeo ya mtihani, ni muhimu kuelezea vipengele muhimu vya usanidi wa mazingira. CS inaweza kutumika katika hali ya kustahimili data-hasara. Hii ina maana kwamba seva moja tu (node) inawajibika kwa data kwa ufunguo fulani, na ikiwa inashindwa kwa sababu yoyote, thamani ya ufunguo huo itapotea. Kwa programu nyingi, hii sio muhimu, lakini kwa benki, ni ubaguzi badala ya sheria. Kwa upande wetu, ni muhimu kuwa na nakala nyingi za data kwa hifadhi salama.
Kwa hivyo, hali ya kurudia mara tatu tu ya CS ilizingatiwa, i.e. uundaji wa nafasi muhimu ulifanywa na vigezo vifuatavyo:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; Kuna njia mbili za kuhakikisha kiwango kinachohitajika cha uthabiti. Kanuni ya jumla ni:
NW + NR > RF
Hii ina maana kwamba idadi ya uthibitishaji wa uandishi wa nodi (NW) pamoja na nambari ya uthibitishaji wa nodi zilizosomwa (NR) lazima iwe kubwa kuliko kipengele cha kurudia. Kwa upande wetu, RF = 3, ikimaanisha kuwa chaguzi zifuatazo zinafaa:
2 + 2 > 3
3 + 1 > 3
Kwa kuwa ni muhimu kwetu kuhifadhi data kwa usalama iwezekanavyo, tulichagua mpango wa 3+1. Zaidi ya hayo, HB hufanya kazi kwa kanuni sawa, kumaanisha ulinganisho huu utakuwa wa haki zaidi.
Inafaa kumbuka kuwa DataStax ilifanya kinyume katika utafiti wao: waliweka RF = 1 kwa CS na HB (mwisho kwa kubadilisha mipangilio ya HDFS). Hiki ni kipengele muhimu sana, kwani athari kwa utendaji wa CS katika kesi hii ni kubwa. Kwa mfano, picha iliyo hapa chini inaonyesha ongezeko la muda unaohitajika ili kupakia data kwenye CS:
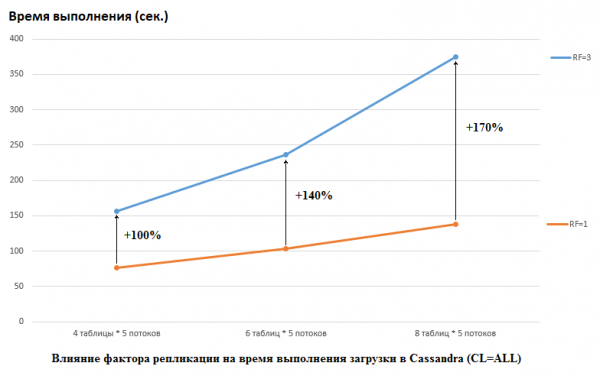
Hapa tunaona yafuatayo: nyuzi zinazoshindana zaidi zinaandika data, inachukua muda mrefu. Hii ni ya asili, lakini ni muhimu kutambua kwamba uharibifu wa utendaji wa RF=3 ni wa juu zaidi. Kwa maneno mengine, ikiwa tunaandika kwa meza 4 na nyuzi 5 kila moja (20 kwa jumla), basi RF=3 inapoteza kwa takriban mara 2 (sekunde 150 kwa RF=3 dhidi ya 75 kwa RF=1). Lakini ikiwa tunaongeza mzigo kwa kupakia data kwenye meza 8 na nyuzi 5 kila moja (40 kwa jumla), basi RF=3 inapoteza kwa sababu ya 2,7 (sekunde 375 dhidi ya 138).
Labda hii ndiyo siri ya majaribio ya upakiaji ya DataStax yaliyofaulu ya CS, kwani kubadilisha kipengele cha replication kutoka 2 hadi 3 hakukuwa na athari kwa HB katika usanidi wetu. Hii inamaanisha kuwa diski sio kizuizi kwa HB katika usanidi wetu. Hata hivyo, kuna vikwazo vingine vingi hapa, kwani ni muhimu kuzingatia kwamba toleo letu la HB lilikuwa limepigwa kidogo na kupangwa, mazingira ni tofauti kabisa, nk. Pia ni muhimu kuzingatia kwamba huenda nisiwe na hakika jinsi ya kuandaa CS vizuri, na kunaweza kuwa na njia bora zaidi za kufanya kazi nayo. Natumaini tunaweza kufahamu hili katika maoni. Lakini mambo ya kwanza kwanza.
Majaribio yote yalifanywa kwenye nguzo ya maunzi yenye seva 4, kila moja ikiwa na usanidi ufuatao:
CPU: Xeon E5-2680 v4 @ nyuzi 2.40GHz 64.
Anatoa: 12 SATA HDD
Toleo la Java: 1.8.0_111
Toleo la CS: 3.11.5
vigezo vya cassandra.ymlnambari_ishara: 256
hinted_handoff_enabled: kweli
alidokeza_handoff_throttle_in_kb: 1024
nyuzi_za_madokezo_max: 2
hints_directory: /data10/cassandra/hints
Vidokezo_vya_muda_katika_ms: 10000
max_hints_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
kithibitishaji: AllowAllAuthenticator
idhini: RuhusuAllAuthorizer
role_manager: CassandraRoleManager
majukumu_uhalali_katika_ms: 2000
ruhusa_uhalali_katika_ms: 2000
sifa_uhalali_katika_ms: 2000
kigawa: org.apache.cassandra.dht.Murmur3Partitioner
saraka_faili_za_data:
— /data1/cassandra/data # kila saraka ya dataN ni diski tofauti
— /data2/cassandra/data
— /data3/cassandra/data
— /data4/cassandra/data
— /data5/cassandra/data
— /data6/cassandra/data
— /data7/cassandra/data
— /data8/cassandra/data
dhamira_ya_ya_data: /data9/cassandra/commitlog
cdc_enabled: uongo
diski_failure_sera: acha
sera_ya_kutofaulu: acha
tayari_taarifa_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
saizi_ya_kache_mlalo_katika_mb: 0
kipindi_cha_hifadhi_kache_mlalo: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
saved_caches_directory: /data10/cassandra/saved_caches
commitlog_sync: mara kwa mara
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
mtoa_mbegu:
- jina_la_darasa: org.apache.cassandra.locator.SimpleSeedProvider
vigezo:
- mbegu: "*,*"
concurrent_reads: 256 # ilijaribu 64 - hakuna tofauti iliyoonekana
concurrent_writes: 256 # walijaribu 64 - hakuna tofauti iliyoonekana
concurrent_counter_writes: 256 # walijaribu 64 - hakuna tofauti iliyoonekana
mwonekano_wa_vifaa_pamoja_huandika: 32
memtable_heap_space_in_mb: 2048 # ilijaribu GB 16 - ilikuwa polepole
memtable_allocation_aina: lundo_bafa
index_summary_capacity_katika_mb:
index_summary_resize_interval_in_dakika: 60
trickle_fsync: uongo
trickle_fsync_interval_in_kb: 10240
Hifadhi_bandari: 7000
ssl_storage_bandari: 7001
sikiliza_anwani: *
tangaza_anwani: *
sikiliza_kwenye_matangazo_anuani: kweli
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: kweli
Usafiri_wa_wa_wa_bandari: 9042
start_rpc: kweli
rpc_anwani: *
bandari_ya_rpc: 9160
rpc_keepalive: kweli
rpc_server_aina: kusawazisha
thrift_framed_transport size_in_mb: 15
incremental_backups: uongo
snapshot_before_compaction: uongo
auto_snapshot: kweli
saizi_ya_safu_ya_katika_kb: 64
saizi_ya_kielezo_cha_kache_katika_kb: 2
kompakta_pamoja: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
soma_request_timeout_ms: 100000
range_request_timeout_ms: 200000
write_request_timeout_ms: 40000
counter_write_request_timeout_ins: 100000
ca_contention_timeout_in_ms: 20000
punguza_request_timeout_ins: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: sivyo
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_ins_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
chaguzi_za_simbuaji_za_seva:
internode_encryption: hakuna
Chaguo_za_simbuaji_za_mteja:
kuwezeshwa: uongo
internode_compression: dc
inter_dc_tcp_nodelay: uongo
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: uongo
enable_scripted_user_defined_functions: uongo
windows_timer_interval: 1
chaguzi_za_usimbuaji_wa_data_wazi:
kuwezeshwa: uongo
tombstone_onya_kizingiti: 1000
kaburi_la_kutofaulu_kizingiti: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
bechi_iliyofunguliwa_katika_vitengo_onya_kizingiti: 10
compaction_partition_large_onyo_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: uongo
enable_materialized_views: kweli
enable_sasi_indexes: kweli
Mipangilio ya GC:
### Mipangilio ya CMS-XX:+TumiaParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkImewashwa
-XX:Uwiano wa Aliyenusurika=8
-XX:MaxTenuringThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+TumiaCMSIInitiatingOccupancyPekee
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkImewashwa
-XX:+CMSEdenChunksRecordDaima
-XX:+CMSClassUnloadingImewashwa
Kumbukumbu ya jvm.options ilitengwa 16 Gb (pia tulijaribu 32 Gb, hakuna tofauti iliyoonekana).
Jedwali ziliundwa kwa kutumia amri:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};Toleo la HB: 1.2.0-cdh5.14.2 (katika darasa la org.apache.hadoop.hbase.regionserver.HRegion, hatukujumuisha MetricsRegion, ambayo ilisababisha GC wakati idadi ya maeneo kwenye RegionServer ilikuwa zaidi ya 1000)
Vigezo vya HBase visivyo chaguomsingizookeeper.session.timeout: 120000
hbase.rpc.timeout: dakika 2
hbase.client.scanner.timeout.period: dakika 2(s)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: dakika 2(s)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: Saa 4(saa)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: GiB 1
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionKizingiti: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: siku 1(siku)
Kijisehemu cha Usanidi wa Kina wa Huduma ya HBase (Valve ya Usalama) ya hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Chaguzi za Usanidi wa Java kwa HBase RegionServer:
-XX:+TumiaParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkImewezeshwa -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: dakika 2(s)
hbase.snapshot.region.timeout: dakika 2(s)
hbase.snapshot.master.timeout.millis: dakika 2(s)
HBase REST Server Max Ukubwa wa logi: 100 MiB
Hifadhi Nakala za Hifadhidata za Seva ya HBase REST: 5
Ukubwa wa logi wa Seva ya HBase Thrift Max: 100 MiB
Hifadhi Nakala za Hifadhidata za Seva ya HBase Thrift: 5
Ukubwa wa logi wa Max Max: 100 MiB
Upeo wa Hifadhi Nakala za Faili za Kumbukumbu: 5
Ukubwa wa Regi ya Seva ya Mkoa: MiB 100
Upeo wa Hifadhi Nakala za Faili za Kumbukumbu za Seva ya Mkoa: 5
Dirisha la Utambuzi la HBase Active Master: dakika 4
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: milisekunde 10
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Upeo wa Maelezo ya Faili ya Mchakato: 180000
hbase.thrift.minWorkerThreads: 200
nyuzi.hbase.master.mtekelezaji.openregion: 30
nyuzi.za.master.mtekelezaji.za.karibu: 30
nyuzi.hbase.master.executor.serverops: 60
hbase.regionserver.thread.compaction.ndogo: 6
hbase.ipc.server.read.threadpool.size: 20
Nyuzi za Kusogeza Mkoa: 6
Ukubwa wa Lundo la Java ya Mteja katika Baiti: 1 GiB
Kundi Chaguomsingi la Seva ya HBase REST: 3 GiB
Kundi Chaguomsingi la Seva ya HBase Thrift: 3 GiB
Ukubwa wa Lundo la Java la Mwalimu wa HBase katika Baiti: 16 GiB
Java Lundo Ukubwa wa HBase RegionServer katika Bytes: 32 GiB
+ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Kutengeneza meza:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Kuna jambo moja muhimu hapa: maelezo ya DataStax hayabainishi ni maeneo ngapi yaliyotumika kuunda jedwali za HB, ingawa hii ni muhimu kwa idadi kubwa. Kwa hiyo, mikoa 64 ilichaguliwa kwa ajili ya kupima, kuruhusu kuhifadhi hadi 640 GB, yaani, meza ya ukubwa wa kati.
Wakati wa jaribio, HBase ilikuwa na meza elfu 22 na mikoa elfu 67 (hii ingekuwa mbaya kwa toleo la 1.2.0, ikiwa sivyo kwa kiraka kilichotajwa hapo juu).
Sasa, kuhusu kanuni. Kwa kuwa haikuwa wazi ni usanidi gani ulikuwa wa manufaa zaidi kwa kila hifadhidata, majaribio yaliendeshwa katika michanganyiko mbalimbali. Hiyo ni, katika vipimo vingine, upakiaji ulifanyika wakati huo huo kwenye meza nne (nodes zote nne zilitumiwa kwa uunganisho). Katika vipimo vingine, meza nane tofauti zilitumiwa. Katika baadhi ya matukio, ukubwa wa kundi ulikuwa 100, kwa wengine 200 (parameter ya kundi-tazama kanuni hapa chini). Saizi ya data kwa thamani ilikuwa baiti 10 au baiti 100 (Ukubwa wa data). Jumla ya rekodi milioni 5 ziliandikwa na kusomwa katika kila jedwali kila mara. nyuzi tano (thNum thread number) zilizoandikwa/kusomwa katika kila jedwali, kila moja ikitumia safu yake ya ufunguo (hesabu = milioni 1):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Ipasavyo, utendakazi sawa ulitolewa kwa HB:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Kwa kuwa katika HB mteja lazima atunze usambazaji sawa wa data, kazi kuu ya kuweka chumvi ilionekana kama hii:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Sasa sehemu ya kuvutia zaidi - matokeo:
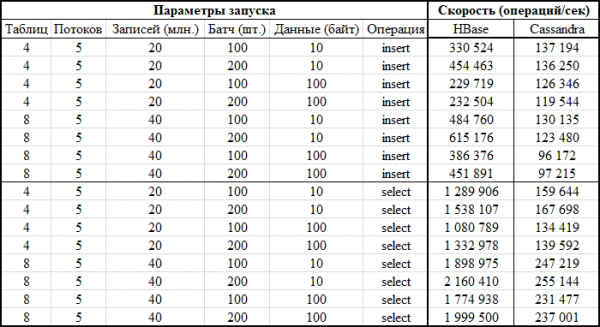
Sawa katika fomu ya grafu:
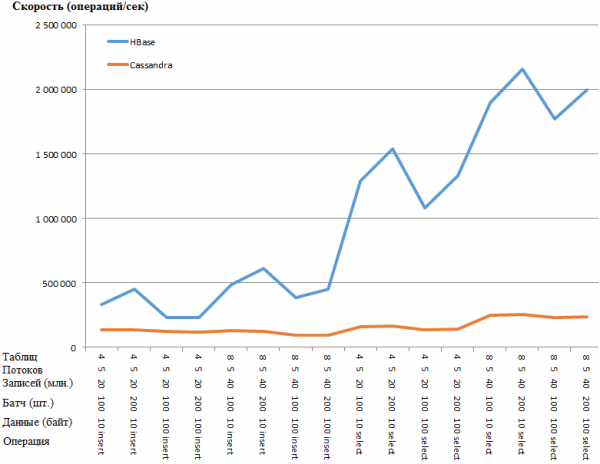
Faida ya HB ni ya kushangaza sana hivi kwamba ninashuku kuwa kuna shida katika mipangilio ya CS. Hata hivyo, Googling na kurekebisha vigezo dhahiri zaidi (kama vile_vya_kuandika au memtable_heap_space_in_mb) hakuleta kasi. Wakati huo huo, magogo ni safi, bila masuala.
Data inasambazwa sawasawa katika nodi, na takwimu kutoka nodi zote ni takriban sawa.
Hivi ndivyo takwimu za jedwali iliyo na nodi moja zinavyoonekana.Nafasi muhimu: ks
Kusoma Hesabu: 9383707
Muda wa Kuchelewa Kusoma: 0.04287025042448576 ms
Andika Hesabu: 15462012
Muda wa Kuandika: 0.1350068438699957 ms
Majimaji yanayosubiri: 0
Jedwali: t1
Idadi thabiti: 16
Nafasi iliyotumika (moja kwa moja): 148.59 MiB
Nafasi iliyotumika (jumla): 148.59 MiB
Nafasi inayotumiwa na vijipicha (jumla): baiti 0
Kumbukumbu ya nje ya lundo iliyotumika (jumla): 5.17 MiB
Uwiano wa Mfinyazo wa SSTable: 0.5720989576459437
Idadi ya partitions (makadirio): 3970323
Idadi ya seli inayoweza kukumbukwa: 0
Saizi ya data inayoweza kukumbukwa: baiti 0
Kumbukumbu ya lundo inayoweza kukumbukwa iliyotumika: baiti 0
Idadi ya swichi inayoweza kukumbukwa: 5
Idadi ya waliosoma ndani: 2346045
Muda wa kusubiri wa kusoma ndani: NaN ms
Idadi ya maandishi ya ndani: 3865503
Muda wa kusubiri uandishi wa ndani: NaN ms
Majimaji yanayosubiri: 0
Asilimia iliyorekebishwa: 0.0
Kichujio cha Bloom chanya chanya cha uongo: 25
Uwiano wa uwongo wa kichujio cha Bloom: 0.00000
Nafasi ya kichujio cha Bloom iliyotumika: 4.57 MiB
Bloom chujio mbali na kumbukumbu lundo kutumika: 4.57 MiB
Muhtasari wa faharasa wa kumbukumbu ya lundo iliyotumika: 590.02 KiB
Metadata ya mfinyizo kutoka kwa kumbukumbu ya lundo iliyotumika: 19.45 KiB
Sehemu ya chini ya baiti iliyounganishwa: 36
Sehemu ya juu ya baiti iliyounganishwa: 42
Sehemu iliyounganishwa ya wastani ya baiti: 42
Wastani wa seli hai kwa kila kipande (dakika tano zilizopita): NaN
Idadi ya juu ya seli hai kwa kila kipande (dakika tano zilizopita): 0
Wastani wa mawe ya kaburi kwa kila kipande (dakika tano za mwisho): NaN
Upeo wa mawe ya kaburi kwa kila kipande (dakika tano zilizopita): 0
Mabadiliko yaliyopungua: baiti 0
Jaribio la kupunguza ukubwa wa kundi (hata kutuma makundi ya mtu binafsi) hakuwa na athari; ilizidi kuwa mbaya zaidi. Inawezekana kwamba huu ndio utendakazi wa juu zaidi wa CS, kwani matokeo yaliyopatikana kwa CS yanafanana na yale ya DataStax—takriban oparesheni laki moja kwa sekunde. Zaidi ya hayo, tukiangalia utumiaji wa rasilimali, tunaona kwamba CS hutumia zaidi CPU na nafasi ya diski:
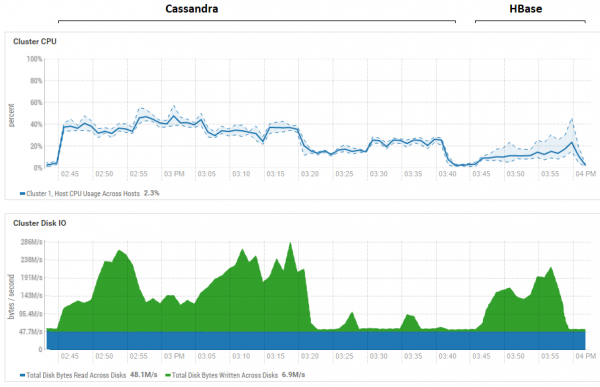
Takwimu inaonyesha matumizi wakati wa kufanya majaribio yote mfululizo kwa hifadhidata zote mbili.
Kuhusu faida kubwa ya HB katika utendaji wa kusoma, ni wazi kwamba kwa hifadhidata zote mbili, utumiaji wa diski wakati wa usomaji ni wa chini sana (majaribio ya kusoma ni sehemu ya mwisho ya mzunguko wa majaribio ya kila hifadhidata; kwa CS, kwa mfano, hii ni kutoka 15:20 PM hadi 15:40 PM). Kwa upande wa HB, sababu iko wazi—data nyingi ziko kwenye kumbukumbu, kwenye memstore, na zingine zimehifadhiwa kwenye blockcache. Kuhusu CS, haijulikani kabisa jinsi inavyofanya kazi, lakini utumiaji wa diski hauonekani pia. Iwapo tu, nilijaribu kuwezesha kashe (row_cache_size_in_mb = 2048) na kuweka caching = {'keys': 'ALL', 'rows_per_partition': '2000000'}, lakini hii kwa kweli ilifanya mambo kuwa mabaya zaidi.
Inafaa pia kusisitiza jambo muhimu kuhusu idadi ya maeneo katika HB. Kwa upande wetu, 64 ilibainishwa. Ikiwa tunapunguza, sema, 4, kasi ya kusoma inashuka kwa sababu ya 2. Hii ni kwa sababu memstore itajaza kwa kasi, faili zitawaka mara kwa mara, na kusoma kutahitaji usindikaji faili zaidi, ambayo ni operesheni ngumu ya HB. Katika hali za ulimwengu halisi, hili linaweza kushughulikiwa kwa kutengeneza mkakati wa kugawanya na kubana. Hasa, tunatumia matumizi maalum ambayo yanaendelea kukusanya takataka na ukandamizaji wa HFiles chinichini. Inawezekana kwamba majaribio ya DataStax yaliundwa na mkoa mmoja tu kwa kila jedwali (ambayo sio sahihi), na hii inaweza kuelezea kwa nini HB ilifanya vibaya katika majaribio yao ya kusoma.
Hitimisho zifuatazo za awali zinaweza kutolewa kutoka kwa hili. Kwa kudhani hakuna makosa makubwa yaliyofanywa wakati wa majaribio, Cassandra ni kama colossus na miguu ya udongo. Kwa usahihi, wakati inasawazisha kwenye mguu mmoja, kama kwenye picha mwanzoni mwa kifungu, inaonyesha matokeo mazuri, lakini inapojaribiwa chini ya hali sawa, inapoteza kabisa. Zaidi ya hayo, kwa kuzingatia matumizi ya chini ya CPU kwenye maunzi yetu, tulijifunza kupeleka RegionServer HB mbili kwa kila mpangishi, na hivyo kuongeza utendakazi maradufu. Kwa hivyo, kwa kuzingatia utumiaji wa rasilimali, hali ya CS inakuwa mbaya zaidi.
Kwa kweli, majaribio haya ni ya syntetisk kabisa, na kiasi cha data kinachotumiwa hapa ni cha kawaida. Inawezekana kwamba hali ingekuwa tofauti tungeongezeka hadi terabaiti, lakini ingawa tunaweza kushughulikia terabaiti za data ya HB, hii ilionekana kuwa tatizo kwa CS. Mara kwa mara ilirusha OperationTimedOutException hata katika viwango hivi, licha ya vigezo vya muda wa kuisha kwa majibu tayari kuongezwa kwa kiasi kikubwa ikilinganishwa na chaguo-msingi.
Natumai kuwa kupitia juhudi zetu za pamoja tutapata vikwazo katika CS, na ikiwa tunaweza kuharakisha, hakika nitaongeza habari kuhusu matokeo ya mwisho mwishoni mwa chapisho.
HABARI HII: Shukrani kwa ushauri wa wenzangu, niliweza kuharakisha usomaji wangu. Ilikuwa:
Ops 159,644 (meza 4, nyuzi 5, kundi 100).
Imeongezwa:
.withLoadBancingPolicy(New TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
Na nilicheza karibu na idadi ya nyuzi. Hii ndio nilipata:
Jedwali 4, nyuzi 100, bechi = 1 (mmoja mmoja): op 301,969
Jedwali 4, nyuzi 100, bechi = 10: op 447,608
Jedwali 4, nyuzi 100, bechi = 100: op 447,608
Baadaye nitatumia vidokezo vingine vya kurekebisha, kuendesha mzunguko kamili wa majaribio, na kuongeza matokeo mwishoni mwa chapisho.
Chanzo: mapenzi.com
