


Msanidi programu wa nyuma anajuaje ikiwa swali la SQL litafanya kazi vizuri katika uzalishaji? Katika makampuni makubwa au yanayokua kwa kasi, si kila mtu ana uwezo wa kupata uzalishaji. Hata kwa ufikiaji, sio hoja zote zinaweza kujaribiwa kwa urahisi, na kuunda nakala ya hifadhidata mara nyingi huchukua masaa. Ili kutatua matatizo haya, tuliunda DBA ya syntetisk—Joe. Tayari ametumwa kwa mafanikio katika kampuni kadhaa na anasaidia watengenezaji kadhaa.
Video:

Jambo kila mtu! Jina langu ni Anatoly Stansler. Ninafanya kazi kwa kampuni Tunalenga kuharakisha mchakato wa usanidi kwa kuondoa ucheleweshaji unaohusiana na Postgres kwa wasanidi programu, DBA na QA.
Tuna wateja wazuri, na wasilisho la leo litaangazia kesi ambazo tumekumbana nazo tulipokuwa tukifanya kazi nao. Nitashiriki jinsi tulivyowasaidia kutatua matatizo makubwa sana.

Tunapounda na kutekeleza uhamiaji changamano, wa kiwango cha juu, tunajiuliza, "Je, uhamaji huu utafanya kazi?" Tunatumia hakiki, na tunapata ujuzi wa wenzetu wenye uzoefu zaidi na wataalam wa DBA. Na wanaweza kutuambia ikiwa itaruka au haitaruka.
Lakini labda itakuwa bora ikiwa tunaweza kujaribu hii wenyewe kwenye nakala za ukubwa kamili. Leo, tutajadili mbinu za sasa za majaribio na jinsi bora ya kuifanya, kwa kutumia zana zipi. Tutajadili pia faida na hasara za mbinu hizi, na kile tunachoweza kuboresha.
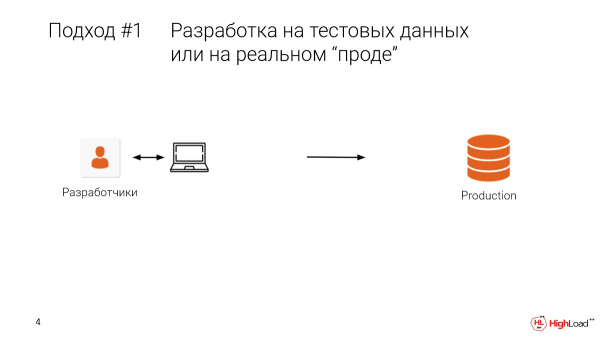
Je, kuna mtu yeyote amewahi kuunda faharasa au kufanya mabadiliko yoyote moja kwa moja kwenye uzalishaji? Wachache kabisa. Je, hii imesababisha upotevu wa data au muda wa chini? Kisha unajua maumivu. Asante kwa wema tuna chelezo.

Njia ya kwanza ni kupima katika uzalishaji. Au, wakati msanidi anafanya kazi kwenye mashine ya ndani, ana data ya majaribio, sampuli ndogo. Kisha tunapeleka kwenye uzalishaji, na hii ndiyo tunayopata.

Ni chungu, ni ghali. Pengine ni bora kutofanya hivi.
Ni ipi njia bora ya kuifanya?
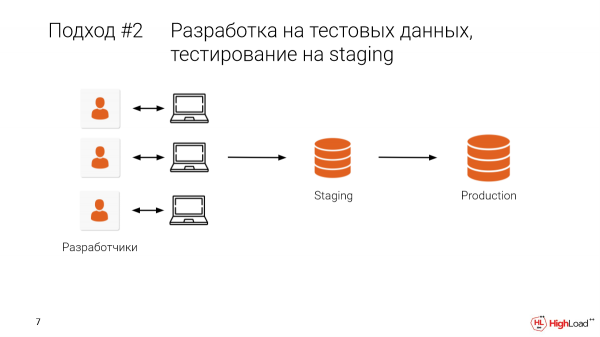
Wacha tuchukue hatua na tugawanye data ya uzalishaji kwake. Au, bora zaidi, hebu tuchukue data halisi ya uzalishaji, data yote. Na baada ya kuitengeneza ndani ya nchi, tutafanya majaribio ya ziada kwenye uwekaji hatua pia.
Hii itaturuhusu kuondoa baadhi ya makosa, i.e. kuzuia kutokea katika uzalishaji.
Je, ni matatizo gani?
- Shida ni kwamba tunashiriki maonyesho haya na wenzetu. Na mara nyingi hutokea kwamba unafanya mabadiliko, na bam - hakuna data, kazi yako inapotea. Jukwaa lilikuwa la terabyte nyingi. Na itabidi ungojee kwa muda mrefu ili kuinuka na kukimbia tena. Kwa hivyo tunaamua kurekebisha kesho. Ni hayo tu, maendeleo yetu yamesimama.
- Na, kwa kweli, tuna wenzake wengi wanaofanya kazi huko, timu nyingi. Na tunapaswa kuratibu kila kitu kwa mikono. Na hiyo ni usumbufu.

Inafaa kukumbuka kuwa tuna risasi moja tu, jaribio moja, ikiwa tunataka kufanya mabadiliko yoyote kwenye hifadhidata, kuchezea data, au kubadilisha muundo. Na ikiwa kitu kitaenda vibaya, ikiwa kuna hitilafu katika uhamiaji, hakuna njia ya haraka ya kurudi nyuma.
Hii ni bora kuliko mbinu ya awali, lakini bado kuna uwezekano mkubwa kwamba mdudu fulani ataishia katika uzalishaji.
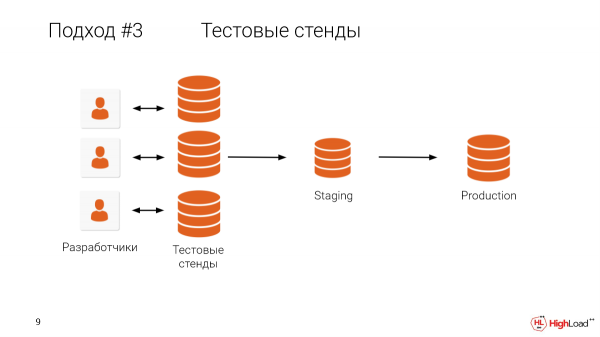
Ni nini kinatuzuia kumpa kila msanidi programu ya majaribio, nakala ya ukubwa kamili? Nadhani ni wazi ni nini kinatuzuia.
Database ya nani ni kubwa kuliko terabyte? Zaidi ya nusu ya chumba.
Na ni wazi kwamba kudumisha mashine kwa kila mtengenezaji wakati uzalishaji ni mkubwa sana ni ghali sana, na pia huchukua muda mrefu.
Tuna wateja ambao wanaelewa umuhimu wa kujaribu mabadiliko yote kwenye nakala za ukubwa kamili, lakini hifadhidata zao ni chini ya terabyte, na hawana nyenzo za kudumisha kifaa cha majaribio kwa kila msanidi. Kwa hivyo lazima wapakue dampo ndani ya mashine zao na kuzijaribu kwa njia hiyo. Hii inachukua muda mwingi.

Hata kama unaifanya ndani, kupakua terabaiti moja ya data kwa saa tayari ni nzuri sana. Lakini wanatumia madampo yenye mantiki; wanapakua ndani kutoka kwa wingu. Kwao, kasi ni karibu gigabytes 200 kwa saa. Na pia inachukua muda kupeleka kutoka kwa dampo la kimantiki, jenga faharisi, na kadhalika.
Lakini wanatumia njia hii kwa sababu inawaruhusu kuweka uzalishaji wa kuaminika.
Tunaweza kufanya nini hapa? Wacha tufanye vitanda vya majaribio kwa bei nafuu na tumpe kila msanidi programu kitanda chake cha majaribio.
Na hili linawezekana.
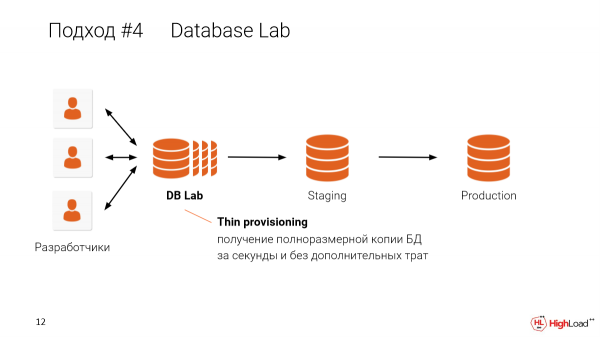
Na kwa mbinu hii, tunapounda clones nyembamba kwa kila msanidi, tunaweza kuzishiriki kwenye mashine moja. Kwa mfano, ikiwa una hifadhidata ya terabaiti nne na unataka kuishiriki na wasanidi programu 10, huhitaji hifadhidata 10 za terabaiti nne. Unahitaji mashine moja tu kuunda nakala nyembamba zilizotengwa kwa kila msanidi, kwa kutumia mashine moja. Nitaelezea jinsi hii inavyofanya kazi baadaye kidogo.

Mfano wa maisha halisi:
DB - 4,5 terabytes.
Tunaweza kupata nakala za kujitegemea katika sekunde 30.
Huna haja ya kusubiri rig ya mtihani au kutegemea ukubwa wake. Unaweza kupata moja kwa sekunde. Haya yatakuwa mazingira ya pekee kabisa, lakini yanashiriki data.
Hii ni poa. Tunazungumza juu ya uchawi na ulimwengu sambamba hapa.

Kwa upande wetu, hii inafanya kazi kwa kutumia mfumo wa OpenZFS.

OpenZFS ni mfumo wa faili wa kunakili-kwa-kuandika ambao unaauni vijipicha na clones nje ya boksi. Inaaminika na inaweza kupanuka. Ni rahisi sana kusimamia. Unaweza kuipeleka kwa amri mbili halisi.
Kuna chaguzi zingine:
lvm,
Mifumo ya uhifadhi (kwa mfano, Hifadhi safi).
Maabara ya Hifadhidata ninayozungumza ni ya kawaida. Inaweza kutekelezwa kwa kutumia chaguzi hizi. Lakini kwa sasa, tunaangazia OpenZFS kwa sababu tulikuwa na maswala na LVM haswa.
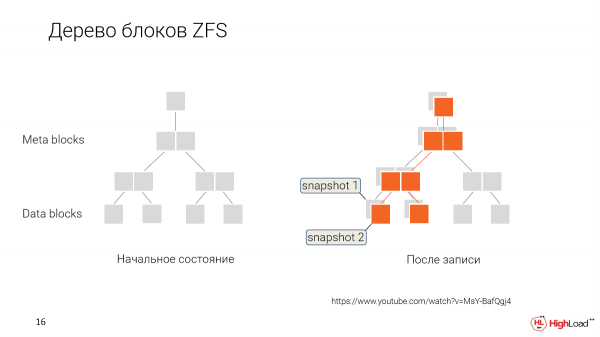
Je, inafanyaje kazi? Badala ya kuandika upya data kila wakati tunapoibadilisha, tunaihifadhi kwa kuitia alama kuwa ni ya sehemu mpya ya wakati, muhtasari mpya.
Na baadaye, tunapotaka kurudisha nyuma au tunataka kutengeneza nakala mpya kutoka kwa toleo la zamani, tunasema tu: "Sawa, tupe vizuizi hivi vya data ambavyo vimewekwa alama kama hii."
Na mtumiaji huyu atafanya kazi na seti hii ya data. Wataibadilisha hatua kwa hatua, na kuunda snapshots zao wenyewe.
Na tutakuwa na matawi. Kila msanidi kwa upande wetu atakuwa na mshirika wake binafsi atakaohariri, na data iliyoshirikiwa itashirikiwa kati ya kila mtu.
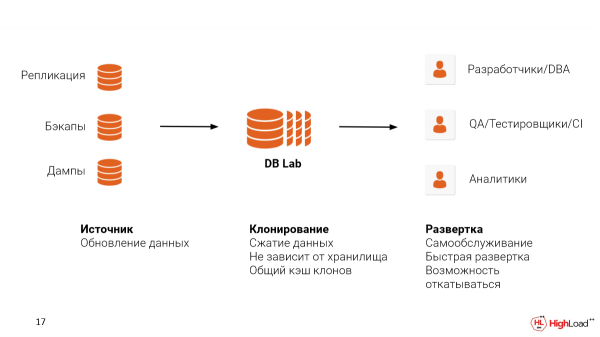
Ili kupeleka mfumo kama huo, unahitaji kutatua shida mbili:
Ya kwanza ni chanzo cha data ambapo utakuwa ukiichukua. Unaweza kusanidi urudufishaji kutoka kwa toleo la umma. Unaweza pia kutumia chelezo zilizopo, kwa matumaini, kama WAL-E, WAL-G, au Barman. Hata kama unatumia suluhisho la wingu, kama vile RDS au Cloud SQL, unaweza kutumia utupaji wa kimantiki. Hata hivyo, bado tunapendekeza kutumia hifadhi rudufu kwa sababu mbinu hii itahifadhi muundo halisi wa faili, kukuwezesha kukaribia zaidi vipimo ambavyo ungeona katika toleo la umma, hivyo kukuruhusu kubainisha matatizo yoyote yanayotokea.
Ya pili ni pale unapotaka kukaribisha Maabara ya Hifadhidata. Hii inaweza kuwa katika wingu au juu ya msingi. Ni muhimu kutambua kwamba ZFS inasaidia ukandamizaji wa data, na inafanya vizuri kabisa.
Fikiria kwamba kila clone itakuza diski ya dev kulingana na shughuli tunazofanya kwenye hifadhidata. Diski hii ya dev pia itahitaji nafasi. Lakini kwa kuwa tumechukua hifadhidata ya terabyte 4,5, ZFS itaibana hadi terabaiti 3,5. Hii inaweza kubadilishwa kulingana na mipangilio. Na bado tutakuwa na nafasi iliyobaki kwa diski ya dev.
Mfumo huu unaweza kutumika kwa kesi tofauti.
Hawa ni wasanidi, DBA za kukagua maswali, kwa uboreshaji.
Hii inaweza kutumika katika majaribio ya QA ili kuthibitisha uhamishaji mahususi kabla hatujaisukuma hadi toleo la umma. Tunaweza pia kuweka mazingira maalum ya QA na data halisi, ambapo wanaweza kujaribu utendakazi mpya. Na itachukua sekunde badala ya saa za kusubiri, au hata siku, katika hali nyingine ambapo nakala nyembamba hazitumiki.
Na hapa kuna kesi nyingine tofauti. Ikiwa kampuni haina mfumo wa uchanganuzi ulioanzishwa, tunaweza kuunda safu nyembamba ya hifadhidata ya bidhaa na kuitumia kwa maswali ya muda mrefu au kwa faharasa maalum zinazoweza kutumika kwa uchanganuzi.

Kwa mbinu hii:
Uwezekano mdogo wa hitilafu katika uzalishaji kwa sababu tulijaribu mabadiliko yote kwenye data ya ukubwa kamili.
Tunaunda utamaduni wa majaribio kwa sababu hatuhitaji tena kusubiri saa kwa kitanda chetu cha majaribio.
Na hakuna vikwazo, hakuna kusubiri kati ya vipimo. Unaweza kweli kwenda na kuangalia ni nje. Na itakuwa bora kwa njia hii, kwani tutaharakisha maendeleo.
Kutakuwa na urekebishaji mdogo. Hitilafu chache zitaifanya kuwa prod. Tutazirekebisha kidogo baadaye.
Tunaweza kubadilisha mabadiliko yasiyoweza kutenduliwa, jambo ambalo mbinu za kawaida haziruhusu.
- Hii ni ya manufaa kwa sababu tunashiriki rasilimali za madawati ya majaribio.
Hiyo tayari ni nzuri, lakini ni nini kingine kinachoweza kuharakishwa?

Shukrani kwa mfumo kama huo, tunaweza kupunguza kwa kiasi kikubwa kizingiti cha kuingia kwa majaribio kama haya.
Kwa sasa kuna mzunguko mbaya ambapo msanidi lazima awe mtaalamu ili kupata ufikiaji wa data halisi, ya kiwango kamili. Lazima waaminiwe na ufikiaji kama huo.
Lakini unawezaje kukua ikiwa huna? Je, ikiwa unaweza tu kufikia seti ndogo sana ya data ya majaribio? Kisha hutaweza kupata matumizi ya ulimwengu halisi.
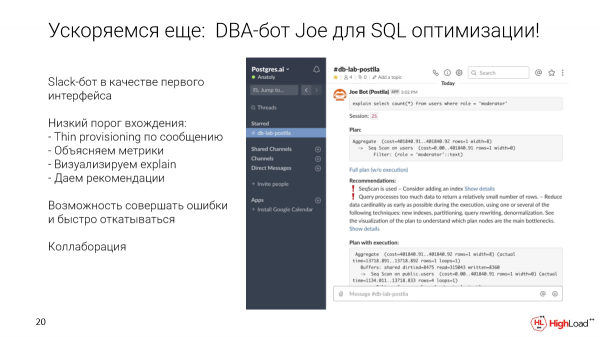
Je, tunatokaje kwenye mzunguko huu? Tulichagua Slack bot kama kiolesura cha kwanza, kinachofaa mtumiaji kwa wasanidi wa viwango vyote vya ujuzi. Lakini interface yoyote inaweza kutumika.
Je, inakuruhusu kufanya nini? Unaweza kuchukua hoja mahususi na kuituma kwa kituo maalum cha hifadhidata. Tutatuma kiotomatiki kisanii chembamba katika sekunde chache. Tutaendesha swali. Tutakusanya vipimo na mapendekezo. Tutaonyesha taswira. Na kisha clone hii itabaki ili uweze kuboresha hoja, kuongeza faharisi, na kadhalika.
Slack pia hutupatia uwezo wa kushirikiana nje ya boksi. Kwa kuwa ni chaneli tu, unaweza kuanza kujadili ombi hapo hapo kwenye mazungumzo, ukisisitiza wenzako na DBAs ndani ya kampuni.

Lakini kuna, bila shaka, changamoto. Kwa kuwa huu ndio ulimwengu wa kweli, na tunatumia seva inayopangisha kloni nyingi kwa wakati mmoja, tunapaswa kubana kiasi cha kumbukumbu na nguvu ya CPU inayopatikana kwa clones.
Lakini kwa vipimo hivi kuwa vya kuaminika, tatizo hili linahitaji kushughulikiwa kwa namna fulani.
Kwa wazi, ufunguo ni data sawa. Lakini tayari tuna hiyo. Na tunataka kufikia usanidi thabiti. Na tunaweza kutoa usanidi unaofanana kabisa.
Itakuwa nzuri kuwa na vifaa sawa na katika uzalishaji, lakini inaweza kuwa tofauti.
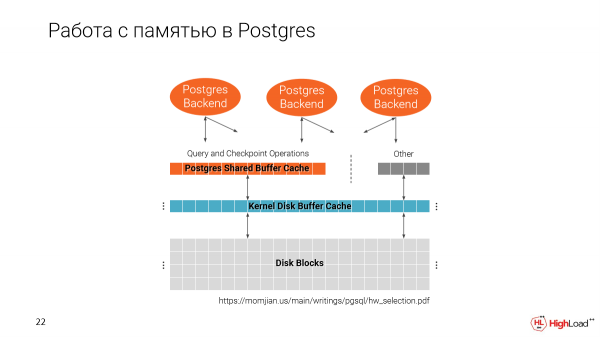
Wacha tuangalie jinsi Postgres inavyoshughulikia kumbukumbu. Tuna akiba mbili: moja kutoka kwa mfumo wa faili na moja asili ya Postgres, Kache ya Buffer iliyoshirikiwa.
Ni muhimu kutambua kwamba Akiba ya Buffer ya Pamoja imetengwa kwenye uanzishaji wa Postgres kulingana na saizi unayobainisha katika usanidi.
Na kashe ya pili hutumia nafasi zote zinazopatikana.
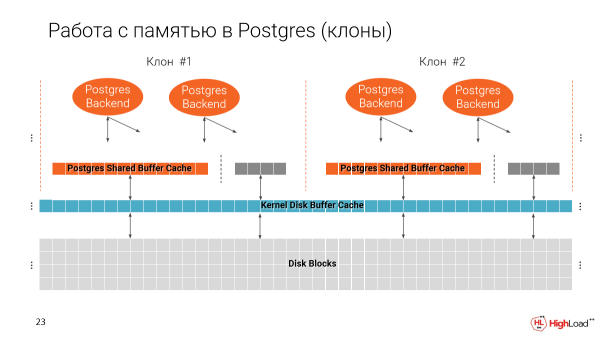
Na tunapounda clones nyingi kwenye mashine moja, hatua kwa hatua tunajaza kumbukumbu. Kwa hakika, Akiba ya Akiba ya Pamoja ni 25% ya jumla ya kumbukumbu inayopatikana kwenye mashine.
Kwa hivyo inabadilika kuwa ikiwa hatutabadilisha kigezo hiki, tutaweza tu kutekeleza matukio manne kwenye mashine moja-yaani, clones nne nyembamba kama hizo. Na hiyo ni mbaya, bila shaka, kwa sababu tunataka kuwa na wengi zaidi.
Lakini kwa upande mwingine, Cache ya Buffer inatumika kwa utekelezaji wa hoja na faharisi, ikimaanisha kuwa mpango unategemea saizi ya kache zetu. Na ikiwa tutapunguza kigezo hiki, mipango yetu inaweza kubadilika sana.
Kwa mfano, ikiwa tuna akiba kubwa kwenye uzalishaji, Postgres itapendelea kutumia faharasa. Lakini ikiwa sivyo, basi SeqScan itatumika. Na itakuwaje ikiwa mipango hii hailingani?
Lakini hapa tunafikia hitimisho kwamba kwa kweli mpango katika Postgres hautegemei saizi maalum iliyoainishwa kwenye Kihifadhi Pamoja katika mpango, inategemea ufanisi_kache_size.

Effective_cache_size ni makadirio ya kiasi cha akiba kinachopatikana kwetu, yaani, jumla ya Akiba ya Buffer na akiba ya mfumo wa faili. Hii imewekwa na usanidi. Kumbukumbu hii haijatengwa.
Na kwa kigezo hiki, tunaweza kuhadaa Postgres kufikiria kuwa tuna data nyingi zinazopatikana, hata kama hatuna. Kwa njia hii, mipango yetu itaendana kabisa na uzalishaji.
Lakini hii inaweza kuathiri wakati. Tunaboresha hoja kulingana na muda, lakini ni muhimu kutambua kuwa muda unategemea mambo mengi:
Inategemea mzigo wa sasa kwenye prod.
Inategemea sifa za mashine yenyewe.
Na hii ni parameta isiyo ya moja kwa moja, lakini kwa kweli tunaweza kuboresha kwa usahihi kwa kiasi cha data ambayo swali hili litasoma ili kupata matokeo.
Ikiwa tunataka muda uwe karibu na kile tutakachoona katika uzalishaji, tunahitaji kutumia maunzi ambayo yanafanana iwezekanavyo, na pengine hata zaidi, ili kuhakikisha clones zote zinafaa. Lakini hii ni maelewano: utapata mipango sawa, utaona ni data ngapi swali mahususi litasoma, na utaweza kubaini ikiwa swali hili (au uhamiaji) ni nzuri au mbaya na linahitaji uboreshaji zaidi.
Wacha tuangalie jinsi uboreshaji unavyofanya kazi na Joe.
Wacha tuchukue swali kutoka kwa mfumo halisi. Katika kesi hii, hifadhidata ni 1 terabyte. Na tunataka kuhesabu idadi ya machapisho ya hivi majuzi yaliyo na zaidi ya kupenda 10.
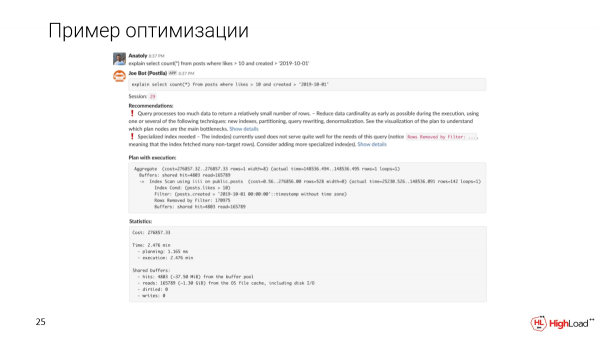
Tunatuma ujumbe kwa kituo, na mshirika anatumwa kwa ajili yetu. Na tutaona kwamba ombi kama hilo litashughulikiwa katika dakika 2,5. Hilo ndilo jambo la kwanza tutaliona.
B Joe atakuonyesha mapendekezo ya kiotomatiki kulingana na mpango wako na vipimo.
Tutaona kuwa hoja huchakata data nyingi sana ili kurejesha idadi ndogo ya safu mlalo. Faharasa maalum inahitajika, kwani tumegundua kuwa hoja ina safu mlalo nyingi zilizochujwa.
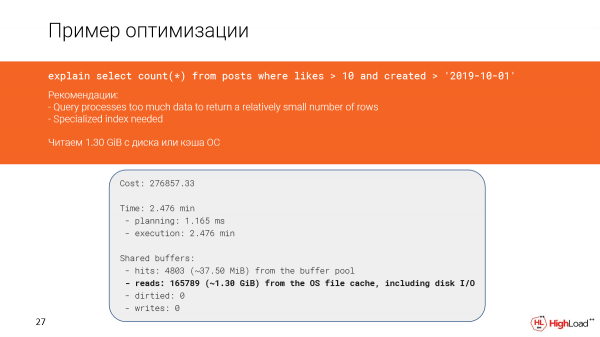
Hebu tuchunguze kwa undani zaidi kilichotokea. Hakika, tunaona kwamba tunasoma karibu gigabytes moja na nusu ya data kutoka kwa cache ya faili au hata kutoka kwa diski. Na hiyo sio nzuri, kwani tulipata safu 142 pekee.
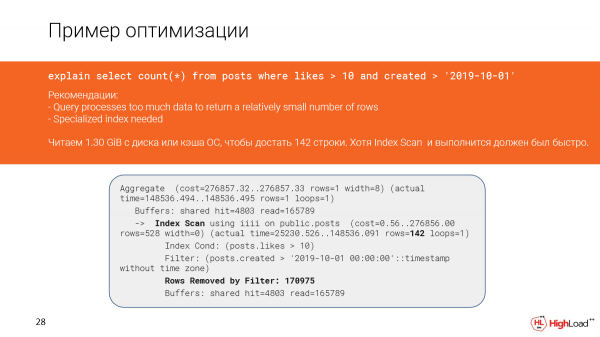
Na ingeonekana kuwa tuna skanisho ya faharasa hapa na ingefaa kufanya kazi haraka, lakini kwa kuwa tulichuja safu mlalo nyingi sana (tulilazimika kuzihesabu), hoja ilifanya kazi polepole.
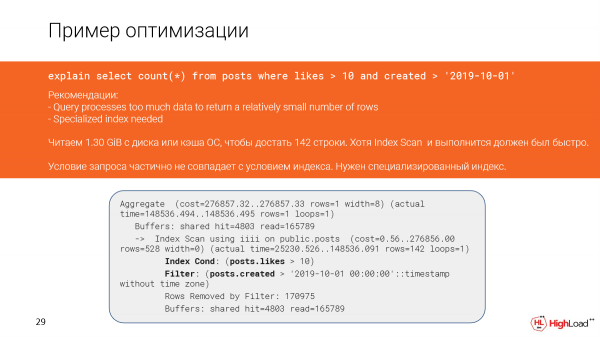
Na hii ilitokea katika mpango kwa sababu masharti katika swala na masharti katika faharisi hayakulingana.
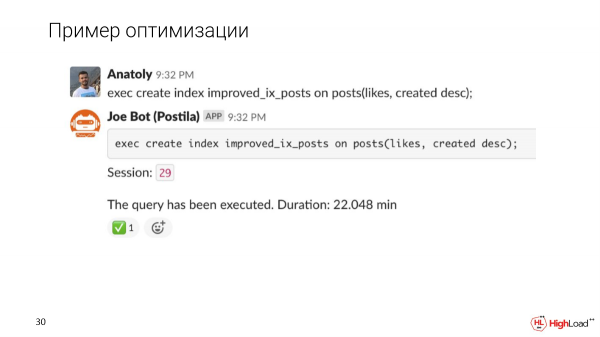
Wacha tujaribu kufanya faharisi kuwa sahihi zaidi na tuone jinsi utekelezaji wa hoja unabadilika baada ya hapo.
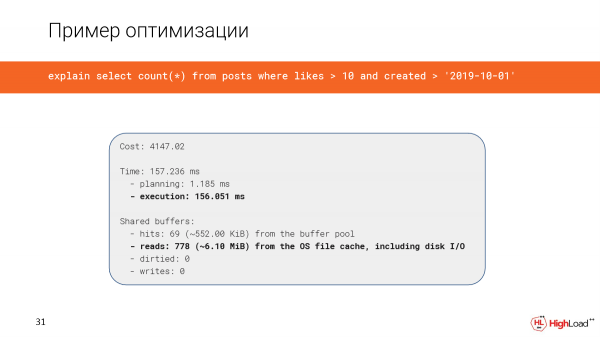
Kuunda fahirisi kulichukua muda mrefu, lakini sasa tunaangalia swali na kuona kwamba wakati umekwenda kutoka dakika 2,5 hadi milliseconds 156 tu, ambayo ni nzuri kabisa. Na tunasoma megabaiti 6 pekee za data.
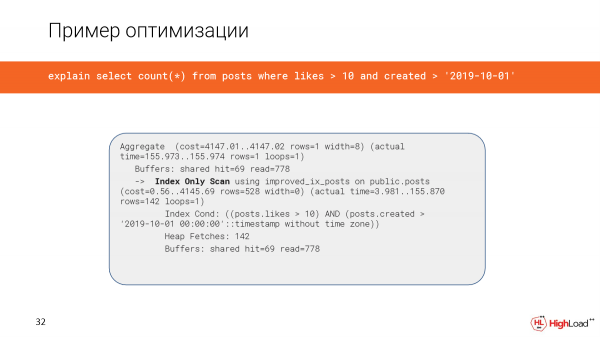
Na sasa tunatumia index tu scan.
Kipengele kingine muhimu ni kwamba tunataka kuwasilisha mpango kwa njia inayoeleweka zaidi. Tumetekeleza taswira kwa kutumia Grafu za Moto.
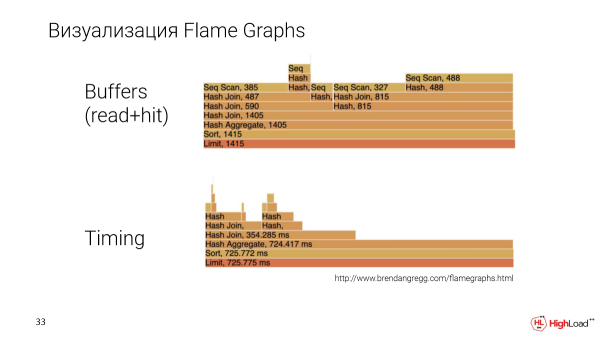
Hili ni swali tofauti, ngumu zaidi. Tunaunda Grafu za Moto kulingana na vigezo viwili: kiasi cha data ambayo nodi maalum katika mpango ilisoma na muda, yaani, muda wa utekelezaji wa nodi.
Hapa tunaweza kulinganisha nodi maalum na kila mmoja. Hii itakuonyesha ni nodi zipi zinachukua nafasi zaidi au kidogo, jambo ambalo kwa kawaida ni gumu kufanya na mbinu zingine za taswira.
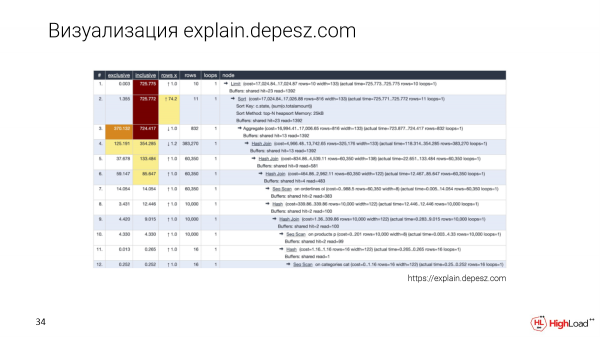
Bila shaka, kila mtu anajua explain.depesz.com. Kipengele kikubwa cha taswira hii ni kwamba huhifadhi mpango wa maandishi na pia huonyesha baadhi ya vigezo muhimu katika jedwali la kupanga.
Wasanidi programu ambao bado hawajaangazia mada hii pia hutumia explain.depesz.com kwa sababu ni rahisi kwao kubaini ni vipimo vipi ni muhimu na ambavyo si muhimu.
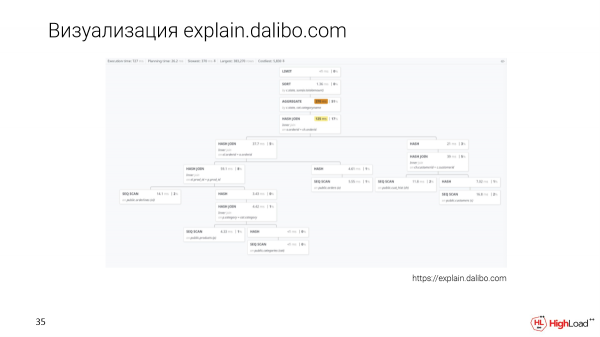
Kuna mbinu mpya ya taswira-explain.dalibo.com. Wanaunda taswira ya msingi wa mti, lakini ni ngumu sana kulinganisha nodi. Ni rahisi kuelewa muundo, ingawa ikiwa una swali kubwa, itabidi usogeze mbele na nyuma, lakini bado ni chaguo.
Ushirikiano
Na, kama nilivyotaja tayari, Slack inaturuhusu kushirikiana. Kwa mfano, ikiwa tutakumbana na swali tata ambalo hatuelewi jinsi ya kuboresha, tunaweza kufafanua suala hilo na wenzetu katika mazungumzo ya Slack.

Tunaamini ni muhimu kufanya majaribio kwenye data ya kiwango kamili. Kwa kusudi hili, tuliunda zana ya Maabara ya Hifadhidata ya Usasishaji, ambayo ni chanzo wazi. Unaweza pia kutumia bot ya Joe. Unaweza kunyakua sasa hivi na kutekeleza mwenyewe. Miongozo yote inapatikana hapo.
Ni muhimu pia kutambua kuwa suluhisho lenyewe sio la mapinduzi. Delphix tayari inapatikana, lakini ni suluhisho la biashara. Ni chanzo kilichofungwa kabisa na ni ghali sana. Sisi utaalam katika Postgres. Hizi zote ni bidhaa huria. Jiunge nasi!
Hapa ndipo ninapohitimisha. Asante!
maswali
Habari! Asante kwa uwasilishaji! Inafurahisha sana, haswa kwangu kwa sababu nilitatua shida kama hiyo wakati fulani uliopita. Kwa hiyo, nina rundo zima la maswali. Natumai nitajibu angalau baadhi yao.
Ninatamani kujua jinsi unavyohesabu nafasi inayohitajika kwa mazingira haya. Teknolojia inadhania kuwa chini ya hali fulani, clones zako zinaweza kukua hadi ukubwa wao wa juu. Kwa kusema, ikiwa una hifadhidata ya terabaiti 10 na kloni 10, ni rahisi kuiga hali ambapo kila kloni itakuwa na vipengee 10 vya kipekee vya data. Je, unahesabuje nafasi hii, ile delta uliyotaja, ambapo clones hizi zitaishi?
Swali zuri. Ni muhimu kufuatilia clones maalum hapa. Klani ikibadilika sana na kuanza kukua, tunaweza kutoa onyo kwa mtumiaji au kusimamisha koni hiyo mara moja ili kuzuia kutofaulu.
Ndio, nina swali linalohusiana. Je, unahakikisha vipi mzunguko wa maisha wa moduli hizi? Hili ni tatizo kwetu, na hadithi tofauti kabisa. Je, hii hutokeaje?
Kila clone ina TTL fulani. Kimsingi, tuna TTL fasta.
Ni ipi, ikiwa sio siri?
Saa 1, i.e., bila kazi - saa 1. Ikiwa haitumiki, tunaiua. Lakini hii haishangazi, kwa kuwa tunaweza kuleta nakala kwa sekunde. Na ikiwa tunaihitaji tena, basi unaweza kwenda.
Pia ninavutiwa na uchaguzi wa teknolojia, kwa sababu sisi, kwa mfano, tunatumia njia kadhaa kwa sambamba kwa sababu mbalimbali. Kwa nini ZFS? Kwa nini hukutumia LVM? Ulisema kuwa kulikuwa na maswala na LVM. Masuala gani hayo? Kwa maoni yangu, chaguo la mfumo wa uhifadhi ni bora zaidi katika suala la utendaji.
Ni nini shida kuu ya ZFS? Ni kwamba lazima uiendeshe kwa mwenyeji mmoja, ikimaanisha kuwa hali zote zitaishi ndani ya mfumo sawa wa kufanya kazi. Lakini kwa mfumo wa kuhifadhi, unaweza kuunganisha vifaa tofauti. Kikwazo pekee ni vitalu kwenye mfumo wa kuhifadhi. Swali la uchaguzi wa teknolojia ni ya kuvutia hasa. Kwa nini sio LVM?
Tunaweza kujadili LVM haswa kwenye mkutano. Kuhusu hifadhi, ni ghali tu. Tunaweza kusambaza ZFS popote. Unaweza kuisambaza kwenye mashine yako. Unaweza kupakua tu hifadhi na kuisambaza. ZFS inaweza kusakinishwa karibu popote, ikiwa tunazungumzia Linux Tunazungumzia hilo. Kwa hivyo, tunapata suluhisho linaloweza kubadilika sana. Na ZFS yenyewe inatoa mengi kutoka kwenye kisanduku. Unaweza kupakia data nyingi ndani yake upendavyo, kuunganisha idadi kubwa ya diski, na ina picha. Na, kama nilivyosema tayari, ni rahisi kuisimamia. Kwa hivyo, inaonekana kupendeza sana kuitumia. Imethibitishwa, imekuwapo kwa miaka mingi. Ina jumuiya kubwa sana inayokua. ZFS ni suluhisho la kuaminika sana.
Nikolay Samokhvalov: Je! ninaweza kutoa maoni zaidi? Jina langu ni Nikolay, na Anatoly na mimi hufanya kazi pamoja. Ninakubali kuwa mifumo ya kuhifadhi ni nzuri. Na baadhi ya wateja wetu wana Hifadhi Safi, nk.
Anatoly alibainisha kwa usahihi kuwa tunalenga urekebishaji. Na katika siku zijazo, tunaweza kutekeleza kiolesura kimoja: kuchukua picha, tengeneza clone, kuharibu clone. Yote ni rahisi. Na mfumo wa uhifadhi ni mzuri, ikiwa upo.
Lakini ZFS inapatikana kwa kila mtu. DelPhix imekuwa na kutosha; wana wateja 300. Kati ya hizo, Fortune 100 ina wateja 50, kumaanisha kuwa wanalenga NASA na kadhalika. Ni wakati wa kila mtu kuwa na teknolojia hii. Ndio maana tumefungua chanzo cha Core. Tuna upande wa mbele ambao sio chanzo wazi. Ni jukwaa ambalo tutaonyesha. Lakini tunataka ipatikane na kila mtu. Tunataka kuibadilisha ili wanaojaribu wakome kubahatisha kwenye kompyuta ndogo. Tunapaswa kuwa na uwezo wa kuandika CHAGUA na kuona mara moja kwamba ni polepole. Acha kusubiri DBA watuambie. Hilo ndilo lengo kuu. Na nadhani sote tutafika. Na tunatengeneza jambo hili ili kila mtu awe nalo. Ndio maana tunatumia ZFS, kwa sababu itapatikana kila mahali. Shukrani kwa jumuiya kwa kutatua matatizo na kwa kuwa na leseni huria, n.k.*
Salamu! Asante kwa uwasilishaji! Jina langu ni Maxim. Tumekuwa tukisuluhisha matatizo sawa. Tumeyatatua wenyewe. Je, unagawaje rasilimali kati ya clones hizi? Kila mshirika anaweza kufanya jambo lake wakati wowote: mmoja anajaribu kitu kimoja, mwingine kitu kingine, anaunda fahirisi, mwingine anafanya kazi nzito. Na wakati unaweza kugawanya rasilimali na CPU, unazigawaje kwa IO? Hilo ndilo swali la kwanza.
Na swali la pili ni juu ya kutofautiana kwa usanidi. Wacha tuseme nina ZFS hapa na kila kitu ni sawa, lakini usanidi wa uzalishaji wa mteja hauna ZFS, lakini ext4, kwa mfano. Nini kingetokea katika kesi hii?
Haya ni maswali mazuri sana. Niligusia kwa ufupi suala la kugawana rasilimali. Suluhisho ni kama ifuatavyo. Fikiria unajaribu kwenye jukwaa. Unaweza pia kuwa na hali ambapo mfumo mmoja unaendesha mzigo mmoja kwa wakati mmoja, wakati mwingine unaendesha tofauti. Kwa hivyo, unaona vipimo vinavyochanganya. Tatizo sawa linaweza kutokea hata kwa uzalishaji. Unapotaka kujaribu ombi na kuona kwamba ni polepole, tatizo halikuwa ombi lenyewe, lakini mzigo sambamba.
Kwa hivyo, ni muhimu kuzingatia mpango, hatua zinazohusika, na ni data ngapi tutahitaji kupakia. Ukweli kwamba disks zetu ni, kwa mfano, chini ya mzigo fulani utaathiri moja kwa moja wakati. Lakini tunaweza kukadiria mzigo kwenye swali hili kulingana na kiasi cha data. Haijalishi sana ikiwa kuna utekelezaji mwingine unaoendeshwa kwa wakati mmoja.
Nina maswali mawili. Hiki ni kipengele kizuri sana. Je, kumekuwa na matukio yoyote ambapo data katika uzalishaji ni muhimu, kama vile nambari za kadi ya mkopo? Kuna kitu kimetengenezwa tayari, au hii ni kazi tofauti? Na swali la pili: kuna kitu sawa kwa MySQL?
Kuhusu data, tutaififisha hadi tuifanye. Lakini ikiwa utapeleka Joe haswa, ikiwa hautoi ufikiaji wa wasanidi programu, basi hakuna ufikiaji wa data. Kwa nini? Kwa sababu Joe haonyeshi data. Inaonyesha tu vipimo, mipango, na ndivyo hivyo. Hii ilifanyika kwa makusudi, kwa sababu ilikuwa moja ya mahitaji ya mteja wetu. Walitaka kuweza kuboresha, lakini wakati huo huo wasimpe kila mtu ufikiaji.
Kuhusu MySQL, mfumo huu unaweza kutumika kwa kitu chochote ambacho huhifadhi hali kwenye diski. Na kwa kuwa tunafanya kazi na Postgres, kwa sasa tunaangazia uwekaji otomatiki wa Postgres. Tunataka kurejesha urejeshaji data kiotomatiki kutoka kwa hifadhi rudufu. Tunasanidi Postgres kwa usahihi. Tunajua jinsi ya kuhakikisha kuwa mipango inalingana, nk.
Lakini kwa kuwa mfumo unaweza kupanuka, unaweza pia kutumika kwa MySQL. Na kuna mifano ya hii. Yandex ina kitu sawa, lakini haichapishi popote. Wanaitumia ndani ya Yandex.Metrica. Na hapo ndipo hadithi ya MySQL inapokuja. Lakini teknolojia ni sawa, ZFS.
Asante kwa uwasilishaji! Pia nina maswali kadhaa. Ulisema kuwa cloning inaweza kutumika kwa uchanganuzi, kwa mfano, kuunda faharisi za ziada. Unaweza kueleza jinsi hii inavyofanya kazi kwa undani zaidi?
Na swali langu la pili mara moja ni juu ya usanidi sawa na mipango inayofanana. Mpango huo unategemea, miongoni mwa mambo mengine, juu ya takwimu zilizokusanywa na Postgres. Je, unatatuaje tatizo hili?
Hatuna matukio yoyote maalum ya matumizi ya uchanganuzi kwa sababu bado hatujaitumia, lakini uwezo upo. Ikiwa tunazungumzia faharasa, fikiria kuendesha swali dhidi ya jedwali lenye mamia ya mamilioni ya rekodi na safu wima ambayo kwa kawaida haijaorodheshwa katika toleo la umma. Na tunataka kuhesabu data fulani. Tukiendesha swali hili kwenye toleo la umma, kuna uwezekano kwamba seva ya uzalishaji itakabiliwa na wakati kwa sababu hoja itachukua dakika moja kuchakatwa.
Sawa, hebu tuunde kisanii chembamba ambacho tunaweza kusitisha kwa usalama kwa dakika chache. Na ili kufanya uchanganuzi kuwa rahisi zaidi, hebu tuongeze faharasa kwenye safu wima ambapo tunavutiwa na data.
Je! faharisi itaundwa kila wakati?
Tunaweza kuisanidi ili tuweze kugusa data, kupiga picha, kisha kurejesha kutoka kwa muhtasari huo na kuendesha hoja mpya. Kwa maneno mengine, tunaweza kuisanidi ili tuweze kuunda clones mpya na faharasa tayari ziko.
Kuhusu swali kuhusu takwimu, ikiwa tutarejesha kutoka kwa hifadhi rudufu au kufanya nakala, takwimu zetu zitakuwa sawa kabisa. Kwa sababu tuna muundo mzima wa data halisi, kumaanisha kwamba tutarejesha data kama ilivyo, pamoja na vipimo vyote vya takwimu.
Kuna tatizo lingine hapa. Ikiwa unatumia suluhisho la wingu, utupaji wa kimantiki pekee ndio unaopatikana kwa sababu Google na Amazon haziruhusu nakala halisi. Ndio tatizo hapo.
Asante kwa uwasilishaji. Maswali mawili mazuri yaliulizwa hapa kuhusu MySQL na ushiriki wa rasilimali. Lakini, kimsingi, yote yanategemea ukweli kwamba hii si mada ya DBMS maalum, bali kwa mfumo wa faili kwa ujumla. Na, ipasavyo, masuala ya ushiriki wa rasilimali yanapaswa pia kushughulikiwa kuanzia hapo, si tu katika Postgres, bali katika mfumo wa faili wenyewe. seva, kwa mfano.
Swali langu ni tofauti kidogo. Inahusiana kwa karibu zaidi na hifadhidata yenye tabaka nyingi. Kwa mfano, tumesanidi sasisho la picha la terabyte 10, na tuna urudiaji unaoendeshwa. Na sisi hutumia suluhisho hili haswa kwa hifadhidata. Urudiaji unaendelea, data inasasishwa. Tuna wafanyakazi 100 wanaofanya kazi sambamba, wakiendesha kila mara vijipicha hivi tofauti. Tufanye nini? Tunawezaje kuzuia migogoro ambapo wanaendesha moja, na kisha mfumo wa faili unabadilishwa, na snapshots hizi zote zinafanya kazi?
Hawatafanya, kwa sababu ndivyo ZFS inavyofanya kazi. Tunaweza kuweka mabadiliko ya mfumo wa faili kuja kwa njia ya urudufishaji tofauti katika mtiririko mmoja. Na tunaweza kuweka nakala za matoleo ya zamani ya data ambayo wasanidi hutumia. Na inatufanyia kazi; kila kitu kiko sawa na hilo.
Inabadilika kuwa sasisho litatokea kama safu ya ziada, na picha zote mpya zitachukuliwa kulingana na safu hii, sivyo?
Kutoka kwa tabaka zilizopita ambazo zilitoka kwa nakala zilizopita.
Tabaka zilizopita zitaanguka, lakini zitarejelea safu ya zamani, na picha mpya zitachukuliwa kutoka safu ya mwisho iliyopokelewa kwenye sasisho?
Kwa ujumla, ndiyo.
Kwa hivyo basi, kama matokeo, tutakuwa na tani ya tabaka. Na baada ya muda, watahitaji kukandamizwa?
Ndiyo, hiyo ni sahihi. Kuna dirisha. Tunaweka snapshots za kila wiki. Inategemea rasilimali zako. Ikiwa una uwezo wa kuhifadhi data nyingi, unaweza kuweka snapshots kwa muda mrefu. Hazitafutwa kiotomatiki. Hakutakuwa na ufisadi wowote wa data. Ikiwa tutaona kuwa vijipicha vimepitwa na wakati—yaani, kulingana na sera ya kampuni—tunaweza tu kuzifuta na kuongeza nafasi.
Habari, asante kwa ripoti! Kuhusu Joe, nina swali. Ulisema mteja hakutaka kila mtu afikie data. Kwa kweli, ikiwa mtu ana matokeo ya Uchambuzi wa Eleza, anaweza kuchungulia data.
Hiyo yote ni kweli. Kwa mfano, tunaweza kuandika: "CHAGUA KUTOKA WAPI barua pepe = hivyo-na-hivyo." Kwa hivyo, hatutaona data yenyewe, lakini tunaweza kuona viashiria vingine visivyo vya moja kwa moja. Hii ni muhimu kuelewa. Lakini kwa upande mwingine, yote yanaonekana. Tuna ukaguzi wa kumbukumbu, na tuna ufuatiliaji kutoka kwa wenzetu wengine ambao pia wanaona kile ambacho wasanidi programu wanafanya. Na ikiwa mtu atajaribu kufanya hivi, timu ya usalama itakuja na kulifanyia kazi suala hilo.
Habari za mchana! Asante kwa uwasilishaji! Nina swali haraka. Ikiwa Slack haitumiki katika kampuni, je, kuna muunganisho wowote nayo sasa, au tunaweza kupeleka matukio kwa wasanidi programu kuunganisha programu ya majaribio kwenye hifadhidata?
Kwa sasa, inahusishwa na Slack, kumaanisha kwamba hakuna mjumbe mwingine, lakini ninataka sana kuongeza usaidizi kwa wajumbe wengine pia. Unaweza kufanya nini? Unaweza kupeleka DB Lab bila Joe, kwa kutumia REST API au jukwaa letu, kuunda clones, na kuunganisha na PSQL. Lakini hii inawezekana tu ikiwa uko tayari kuwapa wasanidi programu wako ufikiaji wa data, kwani hakutakuwa na skrini yoyote.
Sihitaji safu hii, lakini ninahitaji fursa hii.
Kisha ndiyo, inaweza kufanyika.
Chanzo: mapenzi.com
