


Salaam wote! Jina langu ni Oleg Sidorenkov, ninafanya kazi katika DomClick kama mkuu wa timu ya miundombinu. Tumekuwa tukitumia Kubik katika uzalishaji kwa zaidi ya miaka mitatu, na wakati huu tumepata wakati mwingi wa kupendeza nayo. Leo nitakuambia jinsi, kwa mbinu sahihi, unaweza kubana utendaji zaidi kutoka kwa vanilla Kubernetes kwa nguzo yako. Uko tayari kwenda!
Ninyi nyote mnajua vyema kwamba Kubernetes ni mfumo wa chanzo huria unaoweza kusambazwa kwa uandaaji wa kontena; vizuri, au jozi 5 ambazo hufanya kazi ya uchawi kwa kudhibiti mzunguko wa maisha wa huduma ndogo zako katika mazingira ya seva. Kwa kuongezea, ni zana inayoweza kunyumbulika kwa haki ambayo inaweza kuunganishwa kama Lego kwa ubinafsishaji wa hali ya juu kwa kazi tofauti.
Na kila kitu kinaonekana kuwa sawa: tupa seva kwenye nguzo kama kuni kwenye kisanduku cha moto, na hautajua huzuni yoyote. Lakini ikiwa unazingatia mazingira, utafikiri: "Ninawezaje kuweka moto kuwaka na kuokoa msitu?" Kwa maneno mengine, jinsi ya kutafuta njia za kuboresha miundombinu na kupunguza gharama.
1. Fuatilia timu na rasilimali za maombi

Njia moja ya kawaida, lakini yenye ufanisi ni kuanzishwa kwa maombi / mipaka. Gawanya programu kwa nafasi za majina, na nafasi za majina na timu za ukuzaji. Kabla ya kupelekwa, weka maadili ya programu kwa matumizi ya wakati wa processor, kumbukumbu, na uhifadhi wa muda mfupi.
resources:
requests:
memory: 2Gi
cpu: 250m
limits:
memory: 4Gi
cpu: 500mKupitia uzoefu, tulifikia hitimisho: haupaswi kuongeza maombi kutoka kwa mipaka kwa zaidi ya mara mbili. Kiasi cha nguzo kinahesabiwa kulingana na maombi, na ikiwa unatoa maombi tofauti katika rasilimali, kwa mfano, mara 5-10, basi fikiria nini kitatokea kwa node yako wakati imejaa maganda na ghafla inapokea mzigo. Hakuna kitu kizuri. Kwa kiwango cha chini, kupiga, na kwa kiwango cha juu, utasema kwaheri kwa mfanyakazi na kupata mzigo wa mzunguko kwenye nodes zilizobaki baada ya maganda kuanza kusonga.
Kwa kuongeza, kwa msaada limitranges Mwanzoni, unaweza kuweka maadili ya rasilimali kwa kontena - kiwango cha chini, cha juu na chaguo-msingi:
➜ ~ kubectl describe limitranges --namespace ops
Name: limit-range
Namespace: ops
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 10 100m 100m 2
Container ephemeral-storage 12Mi 8Gi 128Mi 4Gi -
Container memory 64Mi 40Gi 128Mi 128Mi 2Usisahau kuweka kikomo rasilimali za nafasi ya majina ili timu moja isiweze kuchukua rasilimali zote za nguzo:
➜ ~ kubectl describe resourcequotas --namespace ops
Name: resource-quota
Namespace: ops
Resource Used Hard
-------- ---- ----
limits.cpu 77250m 80
limits.memory 124814367488 150Gi
pods 31 45
requests.cpu 53850m 80
requests.memory 75613234944 150Gi
services 26 50
services.loadbalancers 0 0
services.nodeports 0 0Kama inavyoonekana kutoka kwa maelezo resourcequotas, ikiwa timu ya ops inataka kupeleka maganda ambayo yatatumia cpu nyingine 10, kipanga ratiba hakitaruhusu hili na atatupa hitilafu:
Error creating: pods "nginx-proxy-9967d8d78-nh4fs" is forbidden: exceeded quota: resource-quota, requested: limits.cpu=5,requests.cpu=5, used: limits.cpu=77250m,requests.cpu=53850m, limited: limits.cpu=10,requests.cpu=10Ili kutatua tatizo hilo, unaweza kuandika chombo, kwa mfano, kama , uwezo wa kuhifadhi na kutekeleza hali ya rasilimali za amri.
2. Chagua hifadhi bora ya faili
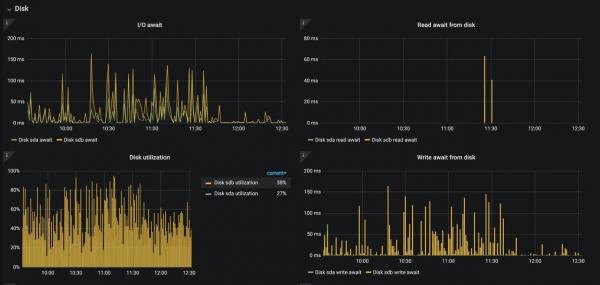
Hapa ningependa kugusa juu ya mada ya idadi inayoendelea na mfumo mdogo wa diski wa nodi za wafanyikazi wa Kubernetes. Natumaini kwamba hakuna mtu anayetumia "Cube" kwenye HDD katika uzalishaji, lakini wakati mwingine SSD ya kawaida haitoshi tena. Tulipata shida ambapo magogo yalikuwa yakiua diski kwa sababu ya shughuli za I/O, na hakuna suluhisho nyingi:
Tumia SSD za utendaji wa juu au ubadilishe hadi NVMe (ikiwa unadhibiti maunzi yako mwenyewe).
Punguza kiwango cha ukataji miti.
Fanya kusawazisha "smart" ya maganda ambayo hubaka diski (
podAntiAffinity).
Skrini iliyo hapo juu inaonyesha kile kinachotokea chini ya nginx-ingress-controller kwenye diski wakati access_logs logs imewashwa (~ magogo elfu 12/sek). Hali hii, bila shaka, inaweza kusababisha uharibifu wa maombi yote kwenye node hii.
Kuhusu PV, ole, sijajaribu kila kitu Kiasi cha Kudumu. Tumia chaguo bora zaidi ambacho kinafaa kwako. Kwa kihistoria, imetokea katika nchi yetu kwamba sehemu ndogo ya huduma zinahitaji kiasi cha RWX, na muda mrefu uliopita walianza kutumia hifadhi ya NFS kwa kazi hii. Nafuu na ... kutosha. Kwa kweli, yeye na mimi tulikula shit - ubarikiwe, lakini tulijifunza kuirekebisha, na kichwa changu hakiumi tena. Na ikiwezekana, nenda kwenye hifadhi ya kitu cha S3.
3. Kusanya picha zilizoboreshwa

Ni bora kutumia picha zilizoboreshwa kwa kontena ili Kubernetes iweze kuzileta kwa haraka na kuzitekeleza kwa ufanisi zaidi.
Imeboreshwa inamaanisha kuwa picha:
vyenye programu moja tu au fanya kazi moja tu;
ndogo kwa ukubwa, kwa sababu picha kubwa hupitishwa mbaya zaidi kwenye mtandao;
kuwa na miisho ya afya na utayari ambayo inaruhusu Kubernetes kuchukua hatua katika tukio la kupungua;
tumia mifumo ya uendeshaji ya chombo (kama Alpine au CoreOS), ambayo ni sugu zaidi kwa hitilafu za usanidi;
tumia miundo ya hatua nyingi ili uweze kupeleka tu programu zilizokusanywa na sio vyanzo vinavyoandamana.
Kuna zana na huduma nyingi zinazokuruhusu kuangalia na kuboresha picha unaporuka. Ni muhimu kuwaweka kila wakati na kupimwa kwa usalama. Kama matokeo, unapata:
Imepunguza mzigo wa mtandao kwenye nguzo nzima.
Kupunguza muda wa kuanza kwa kontena.
Saizi ndogo ya usajili wako wote wa Docker.
4. Tumia akiba ya DNS

Ikiwa tunazungumza juu ya mizigo ya juu, basi maisha ni ya kupendeza bila kurekebisha mfumo wa DNS wa nguzo. Hapo zamani za kale, watengenezaji wa Kubernetes waliunga mkono suluhisho lao la kube-dns. Pia ilitekelezwa hapa, lakini programu hii haikutunzwa hasa na haikutoa utendaji unaohitajika, ingawa ilionekana kuwa kazi rahisi. Kisha coredns ilionekana, ambayo tulibadilisha na hatukuwa na huzuni; baadaye ikawa huduma ya msingi ya DNS katika K8s. Wakati fulani, tulikua rps elfu 40 kwa mfumo wa DNS, na suluhisho hili pia likawa haitoshi. Lakini, kwa bahati nzuri, Nodelocaldns walitoka, aka node local cache, aka .
Kwa nini tunatumia hii? Katika kiini Linux Kuna hitilafu ambayo, maombi mengi yanapofanywa kupitia Conntrack NAT juu ya UDP, husababisha hali ya mbio kwa maingizo kwenye majedwali ya Conntrack, na baadhi ya trafiki kupitia NAT hupotea (kila rufaa kupitia Huduma ni NAT). Nodelocaldns hutatua tatizo hili kwa kuondoa NAT na kusasisha muunganisho wa TCP kwa DNS ya mkondo wa juu, pamoja na uhifadhi wa ndani wa maombi ya DNS hadi DNS ya mkondo wa juu (ikiwa ni pamoja na kashe fupi hasi ya sekunde 5).
5. Piga maganda kwa usawa na wima moja kwa moja
Je, unaweza kusema kwa ujasiri kwamba microservices zako zote ziko tayari kwa ongezeko la mara mbili hadi tatu la mzigo? Jinsi ya kugawa rasilimali vizuri kwa programu zako? Kuweka maganda kadhaa yanayopita zaidi ya mzigo wa kazi kunaweza kuwa sio lazima, lakini kuwaweka nyuma kunaendesha hatari ya muda wa kupumzika kutokana na kuongezeka kwa ghafla kwa trafiki kwenye huduma. Huduma kama vile и .
VPA hukuruhusu kuongeza ombi/vikomo vya kontena zako kiotomatiki kwenye ganda kulingana na matumizi halisi. Inawezaje kuwa na manufaa? Ikiwa una maganda ambayo hayawezi kupunguzwa kwa usawa kwa sababu fulani (ambayo sio ya kuaminika kabisa), basi unaweza kujaribu kukabidhi mabadiliko kwenye rasilimali zake kwa VPA. Kipengele chake ni mfumo wa mapendekezo kulingana na data ya kihistoria na ya sasa kutoka kwa seva ya kipimo, kwa hivyo ikiwa hutaki kubadilisha ombi/vikomo kiotomatiki, unaweza kufuatilia rasilimali zinazopendekezwa kwa vyombo vyako na kuboresha mipangilio ili kuokoa CPU na. kumbukumbu katika nguzo.
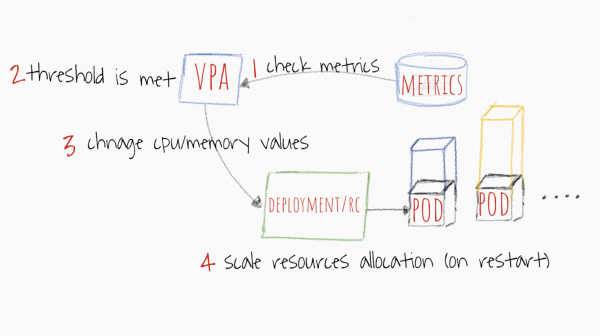 Picha imechukuliwa kutoka https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Picha imechukuliwa kutoka https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Kipanga ratiba katika Kubernetes kinategemea maombi kila wakati. Thamani yoyote unayoweka hapo, mpangaji atatafuta nodi inayofaa kulingana nayo. Viwango vya maadili vinahitajika kwa mchemraba kuelewa wakati wa kutuliza au kuua ganda. Na kwa kuwa parameter muhimu pekee ni thamani ya maombi, VPA itafanya kazi nayo. Wakati wowote unapopanua programu wima, unafafanua maombi yanapaswa kuwa nini. Nini kitatokea kwa mipaka basi? Kigezo hiki pia kitaongezwa kwa uwiano.
Kwa mfano, hapa kuna mipangilio ya kawaida ya ganda:
resources:
requests:
memory: 250Mi
cpu: 200m
limits:
memory: 500Mi
cpu: 350mInjini ya mapendekezo huamua kuwa programu yako inahitaji 300m CPU na 500Mi ili kufanya kazi ipasavyo. Utapata mipangilio ifuatayo:
resources:
requests:
memory: 500Mi
cpu: 300m
limits:
memory: 1000Mi
cpu: 525mKama ilivyotajwa hapo juu, hii ni kuongeza uwiano kulingana na uwiano wa maombi/kikomo kwenye faili ya maelezo:
CPU: 200m → 300m: uwiano 1:1.75;
Kumbukumbu: 250Mi → 500Mi: uwiano 1:2.
Kwa upande wa HPA, basi utaratibu wa operesheni ni wazi zaidi. Vipimo kama vile CPU na kumbukumbu vimewekewa kizingiti, na ikiwa wastani wa nakala zote unazidi kiwango, programu hupunguzwa kwa +1 ndogo hadi thamani iko chini ya kizingiti au hadi idadi ya juu zaidi ya nakala ifikiwe.
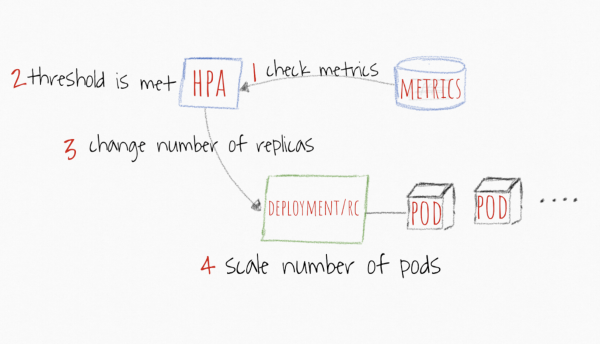 Picha imechukuliwa kutoka https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Picha imechukuliwa kutoka https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Kando na vipimo vya kawaida kama vile CPU na kumbukumbu, unaweza kuweka vizingiti kwenye vipimo vyako maalum kutoka Prometheus na ufanye kazi navyo ikiwa unaona hiyo ndiyo dalili sahihi zaidi ya wakati wa kuongeza programu yako. Punde tu programu itakapotengemaa chini ya kiwango cha kipimo kilichobainishwa, HPA itaanza kupunguza maganda hadi idadi ya chini kabisa ya nakala au hadi mzigo ufikie kiwango kilichobainishwa.
6. Usisahau kuhusu Node Affinity na Pod Affinity

Sio nodi zote zinazoendesha kwenye maunzi sawa, na sio maganda yote yanahitaji kuendesha programu-tumizi kubwa. Kubernetes hukuruhusu kuweka utaalam wa nodi na maganda kwa kutumia Mshikamano wa nodi и Mshikamano wa Pod.
Ikiwa una nodes zinazofaa kwa shughuli za compute-intensive, basi kwa ufanisi wa juu ni bora kuunganisha maombi kwa nodes zinazofanana. Ili kufanya matumizi haya nodeSelector na lebo ya nodi.
Wacha tuseme una nodi mbili: moja na CPUType=HIGHFREQ na idadi kubwa ya cores haraka, mwingine na MemoryType=HIGHMEMORY kumbukumbu zaidi na utendaji wa haraka. Njia rahisi ni kugawa kupelekwa kwa nodi HIGHFREQkwa kuongeza sehemu spec kiteuzi hiki:
…
nodeSelector:
CPUType: HIGHFREQNjia ya gharama kubwa na maalum ya kufanya hivyo ni kutumia nodeAffinity shambani affinity razdela spec. Kuna chaguzi mbili:
requiredDuringSchedulingIgnoredDuringExecution: mpangilio mgumu (mpangaji atapeleka maganda tu kwenye nodi maalum (na mahali pengine popote));preferredDuringSchedulingIgnoredDuringExecution: mpangilio laini (mpangaji atajaribu kupeleka kwa nodi maalum, na ikiwa hiyo itashindwa, itajaribu kupeleka kwa nodi inayofuata inayopatikana).
Unaweza kubainisha sintaksia maalum ya kudhibiti lebo za nodi, kama vile In, NotIn, Exists, DoesNotExist, Gt au Lt. Hata hivyo, kumbuka kwamba mbinu changamano katika orodha ndefu za lebo zitapunguza kasi ya kufanya maamuzi katika hali ngumu. Kwa maneno mengine, iwe rahisi.
Kama ilivyoelezwa hapo juu, Kubernetes hukuruhusu kuweka mshikamano wa maganda ya sasa. Hiyo ni, unaweza kuhakikisha kuwa maganda fulani yanafanya kazi pamoja na maganda mengine katika eneo la upatikanaji sawa (linalohusika na mawingu) au nodi.
В podAffinity shamba affinity razdela spec mashamba sawa zinapatikana kama katika kesi ya nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution и preferredDuringSchedulingIgnoredDuringExecution. Tofauti pekee ni hiyo matchExpressions itafunga maganda kwenye nodi ambayo tayari inaendesha ganda na lebo hiyo.
Kubernetes pia inatoa uwanja podAntiAffinity, ambayo, kinyume chake, haina kumfunga pod kwa node na maganda maalum.
Kuhusu misemo nodeAffinity Ushauri sawa unaweza kutolewa: jaribu kuweka sheria rahisi na za kimantiki, usijaribu kupakia vipimo vya pod na seti ngumu ya sheria. Ni rahisi sana kuunda sheria ambayo hailingani na masharti ya nguzo, kuunda mzigo usiohitajika kwenye mpangilio na kupunguza utendaji wa jumla.
7. Taints & Tolerances
Kuna njia nyingine ya kusimamia mpangilio. Ikiwa una kikundi kikubwa na mamia ya nodes na maelfu ya microservices, basi ni vigumu sana kuruhusu pods fulani kuwa mwenyeji kwenye nodes fulani.
Utaratibu wa uchafu - sheria za kukataza - husaidia na hili. Kwa mfano, katika hali fulani unaweza kuzuia nodi fulani kutoka kwa maganda ya kukimbia. Ili kutumia taint kwa nodi maalum unahitaji kutumia chaguo taint katika kubectl. Bainisha ufunguo na thamani kisha weka kama NoSchedule au NoExecute:
$ kubectl taint nodes node10 node-role.kubernetes.io/ingress=true:NoScheduleInafaa pia kuzingatia kuwa utaratibu wa taint inasaidia athari kuu tatu: NoSchedule, NoExecute и PreferNoSchedule.
NoScheduleinamaanisha kuwa kwa sasa hakutakuwa na ingizo linalolingana katika maelezo ya gandatolerations, haitaweza kupelekwa kwenye nodi (katika mfano huunode10).PreferNoSchedule- toleo rahisiNoSchedule. Katika kesi hii, mpangaji atajaribu kutotenga maganda ambayo hayana kiingilio kinacholinganatolerationskwa nodi, lakini hii sio kizuizi kigumu. Ikiwa hakuna rasilimali kwenye nguzo, basi pods zitaanza kupeleka kwenye nodi hii.NoExecute- athari hii inasababisha uhamishaji wa haraka wa maganda ambayo hayana kiingilio sawatolerations.
Inashangaza, tabia hii inaweza kufutwa kwa kutumia utaratibu wa uvumilivu. Hii ni rahisi wakati kuna node "iliyokatazwa" na unahitaji tu kuweka huduma za miundombinu juu yake. Jinsi ya kufanya hivyo? Ruhusu tu maganda ambayo kuna uvumilivu unaofaa.
Hivi ndivyo maelezo ya ganda yangeonekana kama:
spec:
tolerations:
- key: "node-role.kubernetes.io/ingress"
operator: "Equal"
value: "true"
effect: "NoSchedule"Hii haimaanishi kuwa uwekaji upya unaofuata utaanguka kwenye nodi hii, hii sio utaratibu wa Uhusiano wa Node na nodeSelector. Lakini kwa kuchanganya vipengele kadhaa, unaweza kufikia mipangilio ya mpangilio rahisi sana.
8. Weka Kipaumbele cha Usambazaji wa Podi
Kwa sababu tu una maganda yaliyowekwa kwenye nodi haimaanishi kuwa maganda yote lazima yatibiwe kwa kipaumbele sawa. Kwa mfano, unaweza kutaka kupeleka maganda fulani kabla ya mengine.
Kubernetes inatoa njia tofauti za kusanidi Kipaumbele cha Pod na Preemption. Mpangilio una sehemu kadhaa: kitu PriorityClass na maelezo ya shamba priorityClassName katika vipimo vya ganda. Hebu tuangalie mfano:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 99999
globalDefault: false
description: "This priority class should be used for very important pods only"Tunaunda PriorityClass, ipe jina, maelezo na thamani. Ya juu value, ndivyo kipaumbele kinavyokuwa juu. Thamani inaweza kuwa nambari kamili ya biti 32 chini ya au sawa na 1. Thamani za juu zaidi zimehifadhiwa kwa maganda ya mfumo muhimu wa dhamira ambayo kwa ujumla haiwezi kuepukwa. Uhamisho utatokea tu ikiwa pod ya kipaumbele cha juu haina mahali pa kugeuka, basi baadhi ya maganda kutoka kwenye node fulani yataondolewa. Ikiwa utaratibu huu ni mgumu sana kwako, unaweza kuongeza chaguo preemptionPolicy: Never, na kisha hakutakuwa na kizuizi, pod itasimama kwanza kwenye foleni na kusubiri mpangaji kupata rasilimali za bure kwa ajili yake.
Ifuatayo, tunaunda ganda ambalo tunaonyesha jina priorityClassName:
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
priorityClassName: high-priority
Unaweza kuunda madarasa mengi ya kipaumbele kama unavyopenda, ingawa inashauriwa kutochukuliwa na hii (sema, jizuie kwa kipaumbele cha chini, cha kati na cha juu).
Kwa hivyo, ikiwa ni lazima, unaweza kuongeza ufanisi wa kupeleka huduma muhimu kama vile nginx-ingress-controller, coredns, nk.
9. Boresha nguzo ya ETCD

ETCD inaweza kuitwa ubongo wa nguzo nzima. Ni muhimu sana kudumisha uendeshaji wa database hii kwa kiwango cha juu, kwani kasi ya shughuli katika Cube inategemea. Kiwango cha haki, na wakati huo huo, suluhisho zuri litakuwa kuweka nguzo ya ETCD kwenye nodi kuu ili kuwa na ucheleweshaji wa chini kwa kube-apiserver. Ikiwa huwezi kufanya hivyo, basi weka ETCD karibu iwezekanavyo, na bandwidth nzuri kati ya washiriki. Pia makini na nodi ngapi kutoka ETCD zinaweza kuanguka bila madhara kwa nguzo
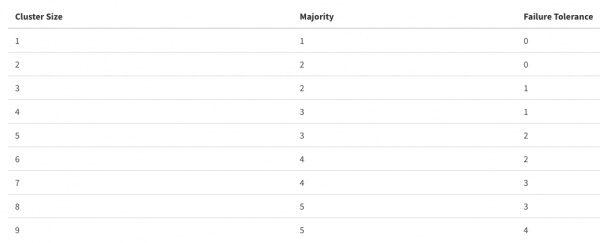
Kumbuka kwamba kuongezeka kwa idadi ya wanachama katika nguzo kunaweza kuongeza uvumilivu wa makosa kwa gharama ya utendaji, kila kitu kinapaswa kuwa kwa kiasi.
Ikiwa tunazungumza juu ya kuanzisha huduma, kuna mapendekezo machache:
Kuwa na vifaa vyema, kulingana na saizi ya nguzo (unaweza kusoma ).
Tengeneza vigezo vichache ikiwa umeeneza nguzo kati ya jozi ya DC au mtandao wako na diski huacha kuhitajika (unaweza kusoma ).
Hitimisho
Makala haya yanaelezea mambo ambayo timu yetu inajaribu kutii. Haya si maelezo ya hatua kwa hatua ya vitendo, lakini chaguo ambazo zinaweza kuwa muhimu kwa kuboresha uendeshaji wa nguzo. Ni wazi kwamba kila nguzo ni ya kipekee kwa njia yake, na suluhu za usanidi zinaweza kutofautiana sana, kwa hivyo itapendeza kupata maoni yako kuhusu jinsi unavyofuatilia nguzo yako ya Kubernetes na jinsi unavyoboresha utendaji wake. Shiriki uzoefu wako katika maoni, itakuwa ya kuvutia kujua.
Chanzo: mapenzi.com
