


Kulingana na hotuba zangu katika Highload++ na DataFest Minsk 2019.
Kwa wengi leo, barua ni sehemu muhimu ya maisha ya mtandaoni. Kwa msaada wake, tunafanya mawasiliano ya biashara, kuhifadhi kila aina ya taarifa muhimu zinazohusiana na fedha, uhifadhi wa hoteli, kuweka maagizo na mengi zaidi. Katikati ya 2018, tuliandaa mkakati wa bidhaa kwa ajili ya kutengeneza barua. Barua za kisasa zinapaswa kuwaje?
Barua lazima iwe mwerevu, yaani, kusaidia watumiaji kuvinjari kiasi kinachoongezeka cha habari: chujio, muundo na uipe kwa njia rahisi zaidi. Lazima awe muhimu, kukuwezesha kutatua kazi mbalimbali kwenye sanduku lako la barua, kwa mfano, kulipa faini (kazi ambayo, kwa bahati mbaya, ninatumia). Na wakati huo huo, kwa kweli, barua lazima itoe ulinzi wa habari, kukata barua taka na kulinda dhidi ya utapeli, ambayo ni, kuwa. salama.
Maeneo haya yanafafanua idadi ya matatizo muhimu, mengi ambayo yanaweza kutatuliwa kwa ufanisi kwa kutumia kujifunza kwa mashine. Hapa kuna mifano ya vipengele vilivyopo tayari vilivyotengenezwa kama sehemu ya mkakati - moja kwa kila mwelekeo.
- Jibu Jibu. Barua ina kipengele cha kujibu mahiri. Mtandao wa neva huchanganua maandishi ya barua, huelewa maana na madhumuni yake, na matokeo yake hutoa chaguo tatu za majibu zinazofaa zaidi: chanya, hasi na upande wowote. Hii husaidia kuokoa muda sana wakati wa kujibu barua, na pia mara nyingi hujibu kwa njia isiyo ya kawaida na ya kuchekesha.
- Kupanga barua pepekuhusiana na maagizo katika maduka ya mtandaoni. Mara nyingi tunanunua mtandaoni, na, kama sheria, maduka yanaweza kutuma barua pepe kadhaa kwa kila agizo. Kwa mfano, kutoka kwa AliExpress, huduma kubwa zaidi, barua nyingi zinakuja kwa amri moja, na tulihesabu kuwa katika kesi ya terminal idadi yao inaweza kufikia hadi 29. Kwa hiyo, kwa kutumia mfano wa Kutambua Entity Recognition, tunatoa nambari ya utaratibu. na habari nyingine kutoka kwa maandishi na kuweka herufi zote kwenye uzi mmoja. Pia tunaonyesha maelezo ya msingi kuhusu agizo katika kisanduku tofauti, ambacho hurahisisha kufanya kazi na aina hii ya barua pepe.

- Kupinga wizi wa data binafsi. Hadaa ni aina hatari sana ya ulaghai ya barua pepe, kwa usaidizi ambao wavamizi hujaribu kupata taarifa za kifedha (ikiwa ni pamoja na kadi za benki za mtumiaji) na kuingia. Barua kama hizo huiga zile halisi zilizotumwa na huduma, pamoja na kuibua. Kwa hiyo, kwa msaada wa Maono ya Kompyuta, tunatambua nembo na mtindo wa kubuni wa barua kutoka kwa makampuni makubwa (kwa mfano, Mail.ru, Sber, Alfa) na kuzingatia hili pamoja na maandishi na vipengele vingine katika spam na classifiers za ulaghai. .
Kujifunza kwa mashine
Kidogo kuhusu kujifunza kwa mashine katika barua pepe kwa ujumla. Barua ni mfumo uliojaa sana: wastani wa herufi bilioni 1,5 kwa siku hupitia kwenye seva zetu kwa watumiaji milioni 30 wa DAU. Takriban mifumo 30 ya kujifunza kwa mashine inasaidia kazi na vipengele vyote muhimu.
Kila barua hupitia bomba zima la uainishaji. Kwanza tunakata barua taka na kuacha barua pepe nzuri. Watumiaji mara nyingi hawatambui kazi ya antispam, kwa sababu 95-99% ya barua taka haiishii kwenye folda inayofaa. Utambuzi wa taka ni sehemu muhimu sana ya mfumo wetu, na ngumu zaidi, kwa kuwa katika uwanja wa kupambana na barua taka kuna marekebisho ya mara kwa mara kati ya mifumo ya ulinzi na mashambulizi, ambayo hutoa changamoto ya uhandisi inayoendelea kwa timu yetu.
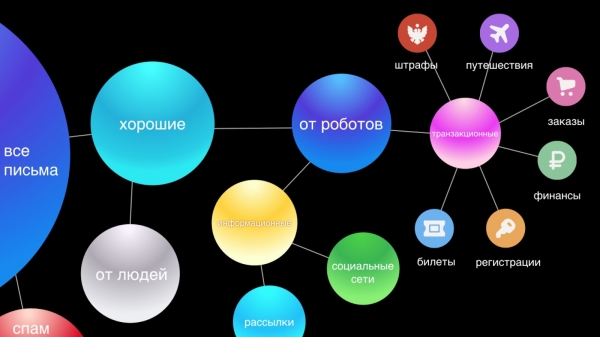
Ifuatayo, tunatenganisha barua kutoka kwa watu na roboti. Barua pepe kutoka kwa watu ndizo muhimu zaidi, kwa hivyo tunatoa vipengele kama vile Majibu ya Haraka kwa ajili yao. Barua kutoka kwa roboti zimegawanywa katika sehemu mbili: shughuli - hizi ni barua muhimu kutoka kwa huduma, kwa mfano, uthibitisho wa ununuzi au uhifadhi wa hoteli, fedha, na habari - haya ni matangazo ya biashara, punguzo.
Tunaamini kuwa barua pepe za miamala ni sawa kwa umuhimu na mawasiliano ya kibinafsi. Zinapaswa kuwa karibu, kwa sababu mara nyingi tunahitaji kupata habari haraka kuhusu agizo au uhifadhi wa tikiti ya ndege, na tunatumia wakati kutafuta barua hizi. Kwa hiyo, kwa urahisi, tunawagawanya moja kwa moja katika makundi sita kuu: usafiri, maagizo, fedha, tiketi, usajili na, hatimaye, faini.
Barua za habari ndio kundi kubwa zaidi na labda sio muhimu sana, ambalo hauitaji majibu ya haraka, kwani hakuna kitu muhimu kitakachobadilika katika maisha ya mtumiaji ikiwa hatasoma barua kama hiyo. Katika kiolesura chetu kipya, tunazikunja katika nyuzi mbili: mitandao ya kijamii na majarida, hivyo kuibua kufuta kikasha na kuacha ujumbe muhimu pekee unaoonekana.
Unyonyaji
Idadi kubwa ya mifumo husababisha matatizo mengi katika uendeshaji. Baada ya yote, mifano huharibika kwa muda, kama programu yoyote: vipengele vinavunjika, mashine hazifanyi kazi, kanuni inakuwa potovu. Kwa kuongeza, data inabadilika mara kwa mara: mpya huongezwa, mifumo ya tabia ya mtumiaji inabadilishwa, nk, hivyo mfano bila usaidizi sahihi utafanya kazi mbaya na mbaya zaidi kwa muda.
Hatupaswi kusahau kwamba jinsi ujifunzaji wa kina wa mashine hupenya katika maisha ya watumiaji, ndivyo athari inayoongezeka kwenye mfumo wa ikolojia, na, kwa hivyo, hasara zaidi za kifedha au faida ambazo wachezaji wa soko wanaweza kupokea. Kwa hivyo, katika idadi inayoongezeka ya maeneo, wachezaji wanazoea kazi ya algoriti za ML (mifano ya kawaida ni utangazaji, utaftaji na antispam iliyotajwa tayari).
Pia, kazi za kujifunza mashine zina upekee: mabadiliko yoyote, hata madogo, katika mfumo yanaweza kuzalisha kazi nyingi na mfano: kufanya kazi na data, retraining, kupelekwa, ambayo inaweza kuchukua wiki au miezi. Kwa hiyo, kwa kasi mazingira ambayo mifano yako hufanya kazi hubadilika, jitihada zaidi inahitaji kudumisha. Timu inaweza kuunda mifumo mingi na kuifurahia, lakini kisha kutumia karibu rasilimali zake zote kuitunza, bila fursa ya kufanya chochote kipya. Wakati mmoja tulikutana na hali kama hiyo katika timu ya antispam. Na walifanya hitimisho dhahiri kwamba msaada unahitaji kuwa otomatiki.
Operesheni
Ni nini kinachoweza kuwa kiotomatiki? Karibu kila kitu, kwa kweli. Nimebainisha maeneo manne ambayo yanafafanua miundombinu ya kujifunza mashine:
- ukusanyaji wa data;
- mafunzo ya ziada;
- kupeleka;
- kupima & ufuatiliaji.
Ikiwa mazingira ni imara na yanabadilika mara kwa mara, basi miundombinu yote karibu na mfano inageuka kuwa muhimu zaidi kuliko mfano yenyewe. Huenda ikawa kiainishaji kizuri cha zamani cha mstari, lakini ukiilisha vipengele vinavyofaa na kupata maoni mazuri kutoka kwa watumiaji, itafanya kazi vizuri zaidi kuliko miundo ya State-Of-The-Art yenye kengele na filimbi zote.
Kitanzi cha Maoni
Mzunguko huu unachanganya ukusanyaji wa data, mafunzo ya ziada na upelekaji - kwa kweli, mzunguko mzima wa sasisho la mfano. Kwa nini ni muhimu? Angalia ratiba ya usajili katika barua:
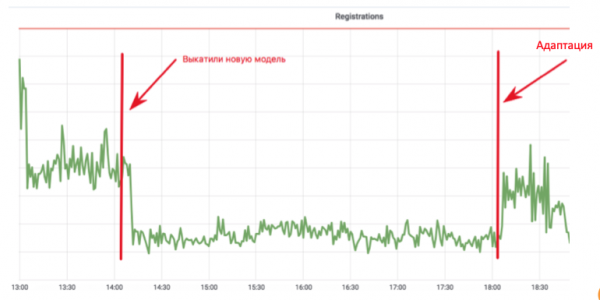
Msanidi programu wa kujifunza mashine ametekeleza muundo wa anti-bot unaozuia roboti kusajili katika barua pepe. Grafu hushuka hadi thamani ambapo watumiaji halisi pekee wamesalia. Kila kitu ni nzuri! Lakini saa nne hupita, roboti hurekebisha maandishi yao, na kila kitu kinarudi kwa kawaida. Katika utekelezaji huu, msanidi programu alitumia mwezi mmoja kuongeza vipengele na kurejesha mfano, lakini spammer aliweza kukabiliana na saa nne.
Ili tusiwe na uchungu sana na sio lazima tufanye tena kila kitu baadaye, lazima kwanza tufikirie jinsi kitanzi cha maoni kitaonekana na tutafanya nini ikiwa mazingira yatabadilika. Wacha tuanze na kukusanya data - hii ndio mafuta ya algorithms yetu.
Mkusanyiko wa data
Ni wazi kwamba kwa mitandao ya kisasa ya neural, data zaidi, bora zaidi, na kwa kweli, zinazozalishwa na watumiaji wa bidhaa. Watumiaji wanaweza kutusaidia kwa kuashiria data, lakini hatuwezi kutumia vibaya hii, kwa sababu wakati fulani watumiaji watachoka kukamilisha miundo yako na watabadilisha hadi bidhaa nyingine.
Mojawapo ya makosa ya kawaida (hapa ninarejelea Andrew Ng) ni kuzingatia sana metriki kwenye hifadhidata ya majaribio, na sio maoni kutoka kwa mtumiaji, ambayo kwa kweli ndio kipimo kikuu cha ubora wa kazi, kwani tunaunda. bidhaa kwa mtumiaji. Ikiwa mtumiaji haelewi au haipendi kazi ya mfano, basi kila kitu kinaharibiwa.
Kwa hivyo, mtumiaji anapaswa kuwa na uwezo wa kupiga kura kila wakati na apewe zana ya maoni. Ikiwa tunafikiri kuwa barua inayohusiana na fedha imefika kwenye kisanduku cha barua, tunahitaji kuashiria "fedha" na kuchora kifungo ambacho mtumiaji anaweza kubofya na kusema kuwa hii sio fedha.
Ubora wa maoni
Hebu tuzungumze kuhusu ubora wa maoni ya mtumiaji. Kwanza, wewe na mtumiaji mnaweza kuweka maana tofauti katika dhana moja. Kwa mfano, wewe na wasimamizi wa bidhaa zako mnafikiri kwamba "fedha" inamaanisha barua kutoka kwa benki, na mtumiaji anafikiri kwamba barua kutoka kwa bibi kuhusu pensheni yake pia inahusu fedha. Pili, kuna watumiaji ambao hupenda kubonyeza vifungo bila mantiki yoyote. Tatu, mtumiaji anaweza kuwa amekosea sana katika hitimisho lake. Mfano mzuri kutoka kwa mazoezi yetu ni utekelezaji wa kiainishaji , aina ya kuchekesha sana ya barua taka ambapo mtumiaji anaombwa kuchukua dola milioni kadhaa kutoka kwa jamaa aliyepatikana kwa ghafla barani Afrika. Baada ya kutekeleza kiainishaji hiki, tuliangalia mibofyo ya "Si Barua Taka" kwenye barua pepe hizi, na ikabainika kuwa 80% kati yazo zilikuwa barua taka za Kinijeria, jambo ambalo linapendekeza kuwa watumiaji wanaweza kuaminika sana.
Na tusisahau kwamba vifungo vinaweza kubofya sio tu na watu, bali pia na aina zote za bots zinazojifanya kuwa kivinjari. Kwa hivyo maoni ghafi sio mazuri kwa kujifunza. Unaweza kufanya nini na habari hii?
Tunatumia njia mbili:
- Maoni kutoka kwa ML iliyounganishwa. Kwa mfano, tuna mfumo wa kupambana na bot mtandaoni, ambao, kama nilivyosema, hufanya uamuzi wa haraka kulingana na idadi ndogo ya ishara. Na kuna mfumo wa pili, polepole ambao hufanya kazi baada ya ukweli. Ina data zaidi kuhusu mtumiaji, tabia yake, nk. Kama matokeo, uamuzi wenye ufahamu zaidi hufanywa; ipasavyo, ina usahihi wa hali ya juu na utimilifu. Unaweza kuelekeza tofauti katika utendakazi wa mifumo hii hadi ya kwanza kama data ya mafunzo. Kwa hivyo, mfumo rahisi utajaribu kila wakati kukaribia utendaji wa ngumu zaidi.
- Bofya uainishaji. Unaweza tu kuainisha kila kubofya kwa mtumiaji, kutathmini uhalali wake na utumiaji. Tunafanya hivi kwa barua ya antispam, kwa kutumia sifa za mtumiaji, historia yake, sifa za mtumaji, maandishi yenyewe na matokeo ya waainishaji. Matokeo yake, tunapata mfumo wa kiotomatiki unaothibitisha maoni ya mtumiaji. Na kwa kuwa inahitaji kufunzwa tena mara kwa mara, kazi yake inaweza kuwa msingi wa mifumo mingine yote. Kipaumbele kuu katika mfano huu ni usahihi, kwa sababu mafunzo ya mfano juu ya data isiyo sahihi yanajaa matokeo.
Wakati tunasafisha data na kutoa mafunzo zaidi kwa mifumo yetu ya ML, hatupaswi kusahau kuhusu watumiaji, kwa sababu kwetu, maelfu, mamilioni ya makosa kwenye grafu ni takwimu, na kwa mtumiaji, kila hitilafu ni janga. Mbali na ukweli kwamba mtumiaji lazima kwa namna fulani aishi na kosa lako katika bidhaa, baada ya kupokea maoni, anatarajia kuwa hali kama hiyo itaondolewa katika siku zijazo. Kwa hivyo, inafaa kila wakati kuwapa watumiaji sio tu fursa ya kupiga kura, lakini pia kurekebisha tabia ya mifumo ya ML, kuunda, kwa mfano, maandishi ya kibinafsi kwa kila kubofya kwa maoni; kwa kesi ya barua, hii inaweza kuwa uwezo wa kuchuja. herufi kama hizo kwa mtumaji na jina la mtumiaji huyu.
Pia unahitaji kuunda muundo kulingana na ripoti au maombi ya kusaidia katika hali ya nusu otomatiki au ya mwongozo ili watumiaji wengine wasipate shida kama hizo.
Heuristics kwa ajili ya kujifunza
Kuna matatizo mawili na heuristics na magongo haya. Ya kwanza ni kwamba idadi inayoongezeka ya magongo ni vigumu kudumisha, achilia mbali ubora na utendaji wao kwa muda mrefu. Tatizo la pili ni kwamba kosa haliwezi kuwa mara kwa mara, na kubofya chache ili kufundisha zaidi mfano hautatosha. Inaweza kuonekana kuwa athari hizi mbili zisizohusiana zinaweza kubadilishwa kwa kiasi kikubwa ikiwa mbinu ifuatayo itatumika.
- Tunaunda crutch ya muda.
- Tunatuma data kutoka kwake kwa mfano, inajisasisha mara kwa mara, pamoja na data iliyopokelewa. Hapa, bila shaka, ni muhimu kwamba heuristics iwe na usahihi wa juu ili usipunguze ubora wa data katika seti ya mafunzo.
- Kisha tunaweka ufuatiliaji ili kuchochea crutch, na ikiwa baada ya muda crutch haifanyi kazi tena na inafunikwa kabisa na mfano, basi unaweza kuiondoa kwa usalama. Sasa shida hii haiwezekani kutokea tena.
Kwa hivyo jeshi la magongo ni muhimu sana. Jambo kuu ni kwamba huduma yao ni ya haraka na sio ya kudumu.
Mafunzo ya ziada
Kufunza upya ni mchakato wa kuongeza data mpya iliyopatikana kutokana na maoni kutoka kwa watumiaji au mifumo mingine, na kufundisha muundo uliopo juu yake. Kunaweza kuwa na shida kadhaa na mafunzo ya ziada:
- Mfano huo hauwezi kuunga mkono mafunzo ya ziada, lakini jifunze kutoka mwanzo tu.
- Hakuna mahali popote katika kitabu cha asili imeandikwa kwamba mafunzo ya ziada hakika yataboresha ubora wa kazi katika uzalishaji. Mara nyingi kinyume chake hutokea, yaani, kuzorota tu kunawezekana.
- Mabadiliko yanaweza kuwa yasiyotabirika. Hili ni jambo la hila ambalo tumejitambulisha sisi wenyewe. Hata kama muundo mpya katika jaribio la A/B unaonyesha matokeo sawa ikilinganishwa na ya sasa, hii haimaanishi kuwa itafanya kazi sawa. Kazi yao inaweza kutofautiana kwa asilimia moja tu, ambayo inaweza kuleta makosa mapya au kurejesha ya zamani ambayo tayari yamesahihishwa. Sisi na watumiaji tayari tunajua jinsi ya kuishi na makosa ya sasa, na wakati idadi kubwa ya makosa mapya yanatokea, mtumiaji anaweza pia kutoelewa kinachotokea, kwa sababu anatarajia tabia inayotabirika.
Kwa hiyo, jambo muhimu zaidi katika mafunzo ya ziada ni kuhakikisha kuwa mfano huo unaboreshwa, au angalau sio mbaya zaidi.
Jambo la kwanza linalokuja akilini tunapozungumza kuhusu mafunzo ya ziada ni mbinu ya Kujifunza Amilifu. Hii ina maana gani? Kwa mfano, kiainishaji huamua ikiwa barua pepe inahusiana na fedha, na kuzunguka mpaka wake wa uamuzi tunaongeza sampuli ya mifano iliyo na lebo. Hii inafanya kazi vizuri, kwa mfano, katika utangazaji, ambapo kuna maoni mengi na unaweza kufundisha mfano mtandaoni. Na ikiwa kuna maoni kidogo, basi tunapata sampuli ya upendeleo sana kuhusiana na usambazaji wa data ya uzalishaji, kwa misingi ambayo haiwezekani kutathmini tabia ya mfano wakati wa operesheni.
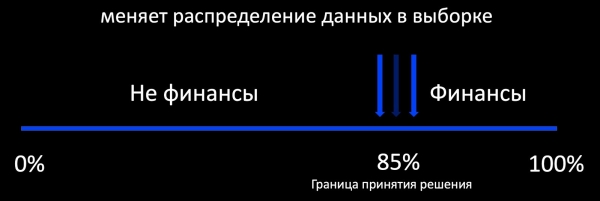
Kwa kweli, lengo letu ni kuhifadhi mifumo ya zamani, mifano inayojulikana tayari, na kupata mpya. Kuendelea ni muhimu hapa. Mfano, ambao mara nyingi tulichukua uchungu mkubwa kusambaza, tayari unafanya kazi, ili tuweze kuzingatia utendaji wake.
Mifano tofauti hutumiwa kwa barua: miti, linear, mitandao ya neural. Kwa kila tunatengeneza algorithm yetu ya ziada ya mafunzo. Katika mchakato wa mafunzo ya ziada, hatupokea data mpya tu, lakini pia mara nyingi vipengele vipya, ambavyo tutazingatia katika algorithms zote hapa chini.
Mifano ya mstari
Wacha tuseme tunayo urekebishaji wa vifaa. Tunaunda mfano wa kupoteza kutoka kwa vipengele vifuatavyo:
- LogLoss kwenye data mpya;
- tunarekebisha uzani wa huduma mpya (hatugusi zile za zamani);
- pia tunajifunza kutoka kwa data ya zamani ili kuhifadhi mifumo ya zamani;
- na, labda, jambo muhimu zaidi: tunaongeza Udhibiti wa Harmonic, ambayo inathibitisha kwamba uzito hautabadilika sana kuhusiana na mfano wa zamani kulingana na kawaida.
Kwa kuwa kila kipengee cha Hasara kina coefficients, tunaweza kuchagua thamani bora zaidi za kazi yetu kupitia uthibitishaji mtambuka au kulingana na mahitaji ya bidhaa.
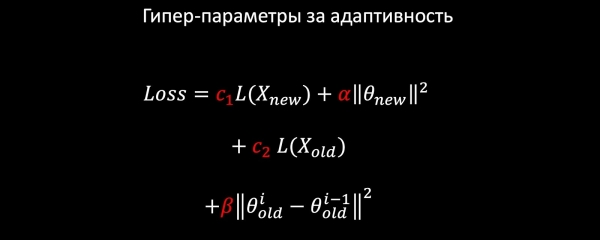
Miti
Wacha tuendelee kwenye miti ya maamuzi. Tumekusanya algorithm ifuatayo kwa mafunzo ya ziada ya miti:
- Uzalishaji huendesha msitu wa miti 100-300, ambayo imefunzwa kwenye seti ya data ya zamani.
- Mwishoni tunaondoa vipande vya M = 5 na kuongeza 2M = 10 mpya, zilizofundishwa kwenye seti nzima ya data, lakini kwa uzito mkubwa wa data mpya, ambayo kwa kawaida inathibitisha mabadiliko ya kuongezeka kwa mfano.
Kwa wazi, baada ya muda, idadi ya miti huongezeka sana, na lazima ipunguzwe mara kwa mara ili kufikia muda. Ili kufanya hivyo, tunatumia Usambazaji Maarifa unaoenea kila mahali (KD). Kwa kifupi kuhusu kanuni ya uendeshaji wake.
- Tuna mtindo wa sasa "tata". Tunaiendesha kwenye seti ya data ya mafunzo na kupata usambazaji wa uwezekano wa darasa kwenye matokeo.
- Kisha, tunafunza modeli ya wanafunzi (mfano ulio na miti michache katika kesi hii) kurudia matokeo ya kielelezo kwa kutumia usambazaji wa darasa kama kigezo kinacholengwa.
- Ni muhimu kutambua hapa kwamba hatutumii markup ya kuweka data kwa njia yoyote, na kwa hiyo tunaweza kutumia data ya kiholela. Bila shaka, tunatumia sampuli ya data kutoka kwa mkondo wa mapigano kama sampuli ya mafunzo ya modeli ya wanafunzi. Kwa hivyo, seti ya mafunzo inatuwezesha kuhakikisha usahihi wa mfano, na sampuli ya mkondo inathibitisha utendaji sawa kwenye usambazaji wa uzalishaji, fidia kwa upendeleo wa seti ya mafunzo.
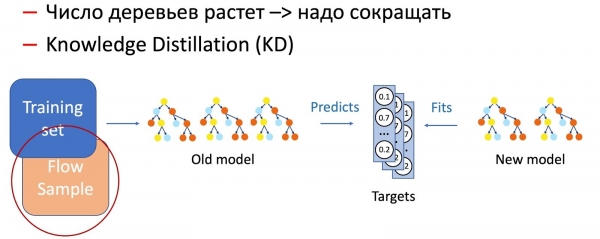
Mchanganyiko wa mbinu hizi mbili (kuongeza miti na kupunguza mara kwa mara idadi yao kwa kutumia Usambazaji wa Maarifa) huhakikisha kuanzishwa kwa mifumo mpya na mwendelezo kamili.
Kwa usaidizi wa KD, pia tunafanya shughuli tofauti kwenye vipengele vya muundo, kama vile kuondoa vipengele na kushughulikia mapengo. Kwa upande wetu, tuna idadi ya vipengele muhimu vya takwimu (na watumaji, heshi za maandishi, URL, n.k.) ambazo zimehifadhiwa kwenye hifadhidata, ambazo huwa na kushindwa. Mfano huo, bila shaka, hauko tayari kwa maendeleo hayo ya matukio, kwani hali za kushindwa hazifanyiki katika seti ya mafunzo. Katika hali kama hizi, tunachanganya mbinu za KD na uongezaji: wakati wa mafunzo kwa sehemu ya data, tunaondoa au kuweka upya vipengele muhimu, na tunachukua lebo asili (matokeo ya mtindo wa sasa), na mfano wa mwanafunzi hujifunza kurudia usambazaji huu. .
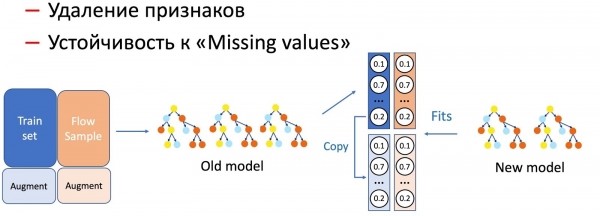
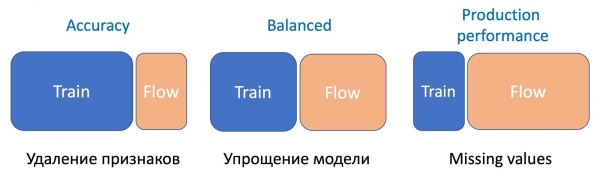
Tuligundua kuwa jinsi upotoshaji mkubwa wa muundo unavyotokea, ndivyo asilimia kubwa ya sampuli ya uzi inavyohitajika.
Uondoaji wa kipengele, operesheni rahisi zaidi, inahitaji sehemu ndogo tu ya mtiririko, kwa kuwa vipengele kadhaa tu vinabadilika, na mfano wa sasa ulifundishwa kwenye seti sawa - tofauti ni ndogo. Ili kurahisisha mfano (kupunguza idadi ya miti mara kadhaa), 50 hadi 50 tayari inahitajika. Na kwa kuachwa kwa vipengele muhimu vya takwimu ambavyo vitaathiri sana utendaji wa mfano, mtiririko zaidi unahitajika ili kusawazisha kazi ya muundo mpya unaostahimili upungufu kwenye aina zote za herufi.
FastText
Wacha tuendelee kwenye FastText. Acha nikukumbushe kwamba uwakilishi (Upachikaji) wa neno unajumuisha jumla ya upachikaji wa neno lenyewe na herufi yake yote N-gramu, kwa kawaida trigrams. Kwa kuwa kunaweza kuwa na trigrams nyingi, Bucket Hashing hutumiwa, ambayo ni, kubadilisha nafasi nzima kuwa hashmap fulani iliyowekwa. Kama matokeo, matrix ya uzani hupatikana na kipimo cha safu ya ndani kwa idadi ya maneno + ndoo.
Kwa mafunzo ya ziada, ishara mpya zinaonekana: maneno na trigrams. Hakuna muhimu kinachotokea katika mafunzo ya kawaida ya ufuatiliaji kutoka kwa Facebook. Vipimo vya zamani pekee vilivyo na mtambuka hufunzwa upya kwenye data mpya. Kwa hivyo, vipengele vipya havitumiwi; kwa kweli, mbinu hii ina hasara zote zilizoelezwa hapo juu zinazohusiana na kutotabirika kwa mfano katika uzalishaji. Ndio maana tulirekebisha FastText kidogo. Tunaongeza uzani wote mpya (maneno na trigramu), panua matrix nzima na mtambuka na kuongeza urekebishaji wa usawa kwa mlinganisho na mfano wa mstari, ambao unahakikisha mabadiliko madogo katika uzani wa zamani.

CNN
Mitandao ya ubadilishaji ni ngumu zaidi. Ikiwa tabaka za mwisho zimekamilika katika CNN, basi, bila shaka, unaweza kuomba utaratibu wa usawa na uhakikisho wa kuendelea. Lakini ikiwa mafunzo ya ziada ya mtandao mzima yanahitajika, basi utaratibu huo hauwezi tena kutumika kwa tabaka zote. Walakini, kuna chaguo la kutoa mafunzo ya upachikaji wa ziada kupitia Upotezaji wa Triplet ().
Hasara Mara tatu
Kwa kutumia kazi ya kupambana na hadaa kama mfano, hebu tuangalie Upotevu wa Triplet kwa ujumla. Tunachukua nembo yetu, pamoja na mifano chanya na hasi ya nembo za makampuni mengine. Tunapunguza umbali kati ya ya kwanza na kuongeza umbali kati ya pili, tunafanya hivyo kwa pengo ndogo ili kuhakikisha ujumuishaji mkubwa wa madarasa.
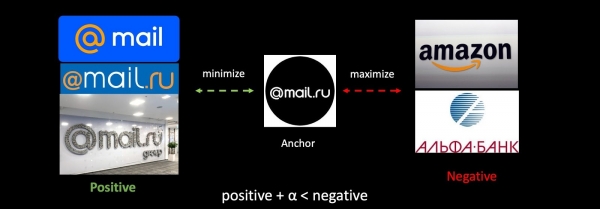
Ikiwa tutafunza mtandao zaidi, basi nafasi yetu ya metri inabadilika kabisa, na inakuwa haiendani kabisa na ile ya awali. Hili ni tatizo kubwa katika matatizo ambayo hutumia vekta. Ili kuzunguka tatizo hili, tutachanganya katika upachikaji wa zamani wakati wa mafunzo.
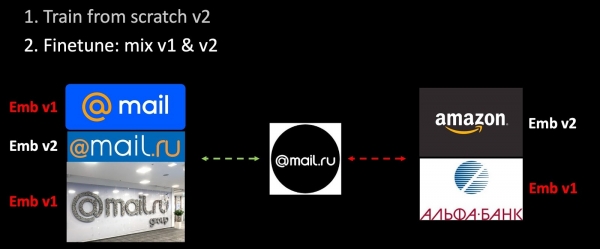
Tumeongeza data mpya kwenye seti ya mafunzo na tunafunza toleo la pili la modeli kuanzia mwanzo. Katika hatua ya pili, tunafundisha zaidi mtandao wetu (Finetuning): kwanza safu ya mwisho imekamilika, na kisha mtandao wote haujahifadhiwa. Katika mchakato wa kuunda triplets, tunahesabu sehemu tu ya upachikaji kwa kutumia mfano wa mafunzo, wengine - kwa kutumia wa zamani. Kwa hivyo, katika mchakato wa mafunzo ya ziada, tunahakikisha utangamano wa nafasi za metri v1 na v2. Toleo la kipekee la urekebishaji wa usawa.
Usanifu mzima
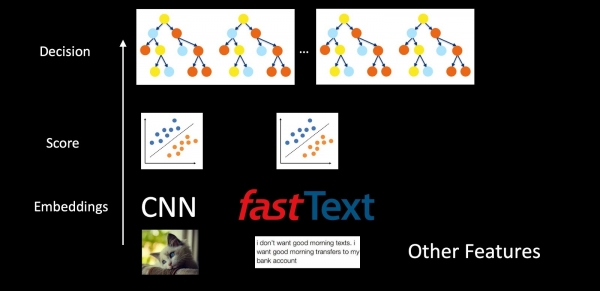
Ikiwa tunazingatia mfumo mzima kwa kutumia antispam kama mfano, basi mifano haijatengwa, lakini imewekwa ndani ya kila mmoja. Tunapiga picha, maandishi na vipengele vingine, kwa kutumia CNN na Maandishi Haraka tunapata upachikaji. Ifuatayo, waainishaji hutumiwa juu ya upachikaji, ambao hutoa alama kwa madarasa mbalimbali (aina za barua, barua taka, uwepo wa alama). Ishara na ishara tayari zinaingia kwenye msitu wa miti kwa uamuzi wa mwisho kufanywa. Viainishi vya kibinafsi katika mpango huu hufanya iwezekane kutafsiri vyema matokeo ya mfumo na haswa zaidi kutoa vipengele tena ikiwa kuna matatizo, badala ya kulisha data zote katika miti ya maamuzi katika fomu ghafi.
Kwa hivyo, tunahakikisha mwendelezo katika kila ngazi. Katika kiwango cha chini katika CNN na Maandishi Haraka tunatumia urekebishaji wa uelewano, kwa viainishi vilivyo katikati pia tunatumia urekebishaji wa uelewano na urekebishaji wa viwango kwa uthabiti wa usambazaji wa uwezekano. Kweli, ukuzaji wa miti hufunzwa mara kwa mara au kutumia kunereka kwa Maarifa.
Kwa ujumla, kudumisha mfumo kama huo wa kujifunza mashine ya kiota ni kawaida maumivu, kwani sehemu yoyote katika kiwango cha chini husababisha sasisho la mfumo mzima hapo juu. Lakini kwa kuwa katika usanidi wetu kila sehemu inabadilika kidogo na inaendana na ile ya awali, mfumo mzima unaweza kusasishwa kipande kwa kipande bila ya haja ya kurejesha muundo mzima, ambayo inaruhusu kuungwa mkono bila overhead kubwa.
Weka
Tumejadili ukusanyaji wa data na mafunzo ya ziada ya aina tofauti za miundo, kwa hivyo tunaendelea na uwekaji wao katika mazingira ya uzalishaji.
Mtihani wa A/B
Kama nilivyosema hapo awali, katika mchakato wa kukusanya data, kawaida tunapata sampuli ya upendeleo, ambayo haiwezekani kutathmini utendaji wa uzalishaji wa mfano. Kwa hiyo, wakati wa kupeleka, mfano lazima ulinganishwe na toleo la awali ili kuelewa jinsi mambo yanavyoenda, yaani, kufanya vipimo vya A / B. Kwa kweli, mchakato wa kusambaza na kuchambua chati ni wa kawaida kabisa na unaweza kujiendesha kwa urahisi. Tunasambaza miundo yetu hatua kwa hatua hadi 5%, 30%, 50% na 100% ya watumiaji, huku tukikusanya vipimo vyote vinavyopatikana kwenye majibu ya miundo na maoni ya watumiaji. Kwa upande wa watoa huduma wengine wakubwa, tunarudisha kielelezo kiotomatiki, na kwa visa vingine, baada ya kukusanya idadi ya kutosha ya mibofyo ya watumiaji, tunaamua kuongeza asilimia. Kwa hivyo, tunaleta muundo mpya kwa 50% ya watumiaji kiotomatiki kabisa, na uchapishaji kwa hadhira yote utaidhinishwa na mtu, ingawa hatua hii inaweza kujiendesha kiotomatiki.
Hata hivyo, mchakato wa majaribio ya A/B unatoa nafasi ya uboreshaji. Ukweli ni kwamba mtihani wowote wa A / B ni mrefu sana (kwa upande wetu inachukua kutoka saa 6 hadi 24 kulingana na kiasi cha maoni), ambayo inafanya kuwa ghali kabisa na kwa rasilimali ndogo. Zaidi ya hayo, asilimia kubwa ya kutosha ya mtiririko wa jaribio inahitajika ili kuharakisha muda wa jumla wa jaribio la A/B (kuajiri sampuli muhimu ya kitakwimu ili kutathmini vipimo kwa asilimia ndogo kunaweza kuchukua muda mrefu sana), ambayo hufanya. idadi ya nafasi za A/B ni ndogo sana. Ni wazi, tunahitaji kujaribu tu mifano ya kuahidi zaidi, ambayo tunapokea mengi wakati wa mchakato wa ziada wa mafunzo.
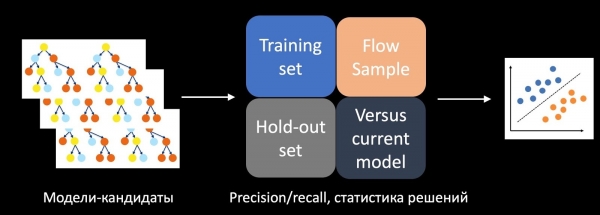
Ili kusuluhisha tatizo hili, tulifunza kiainishaji tofauti ambacho kinatabiri kufaulu kwa jaribio la A/B. Ili kufanya hivyo, tunachukua takwimu za kufanya maamuzi, Usahihi, Recall na vipimo vingine kwenye seti ya mafunzo, kwenye ile iliyoahirishwa, na kwenye sampuli kutoka kwa mtiririko kama vipengele. Pia tunalinganisha mtindo na wa sasa katika uzalishaji, na heuristics, na kuzingatia Ugumu wa mfano. Kwa kutumia vipengele hivi vyote, kiainishi kilichofunzwa kwenye historia ya majaribio hutathmini miundo ya watahiniwa, kwa upande wetu hii ni misitu ya miti, na huamua ni ipi ya kutumia katika jaribio la A/B.
Wakati wa utekelezaji, mbinu hii ilituruhusu kuongeza idadi ya majaribio ya A/B yenye mafanikio mara kadhaa.
Upimaji & Ufuatiliaji
Upimaji na ufuatiliaji, isiyo ya kawaida, haidhuru afya yetu; badala yake, badala yake, wanaiboresha na kutupunguzia mafadhaiko yasiyo ya lazima. Jaribio hukuruhusu kuzuia kutofaulu, na ufuatiliaji hukuruhusu kugundua kwa wakati ili kupunguza athari kwa watumiaji.
Ni muhimu kuelewa hapa kwamba mapema au baadaye mfumo wako utafanya makosa daima - hii ni kutokana na mzunguko wa maendeleo ya programu yoyote. Mwanzoni mwa maendeleo ya mfumo daima kuna mende nyingi mpaka kila kitu kiweke na hatua kuu ya uvumbuzi imekamilika. Lakini baada ya muda, entropy inachukua ushuru wake, na makosa yanaonekana tena - kutokana na uharibifu wa vipengele karibu na mabadiliko ya data, ambayo nilizungumzia mwanzoni.
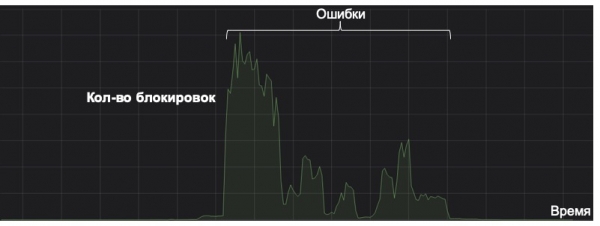
Hapa ningependa kutambua kwamba mfumo wowote wa kujifunza mashine unapaswa kuzingatiwa kutoka kwa mtazamo wa faida yake katika mzunguko wake wote wa maisha. Grafu iliyo hapa chini inaonyesha mfano wa jinsi mfumo unavyofanya kazi kupata aina adimu ya barua taka (mstari kwenye grafu uko karibu na sufuri). Siku moja, kwa sababu ya sifa iliyohifadhiwa vibaya, alipatwa na kichaa. Kama bahati ingekuwa hivyo, hapakuwa na ufuatiliaji wa uanzishaji usio wa kawaida; kwa sababu hiyo, mfumo ulianza kuhifadhi barua kwa wingi kwenye folda ya "spam" kwenye mpaka wa kufanya maamuzi. Licha ya kurekebisha matokeo, mfumo huo tayari umefanya makosa mara nyingi kiasi kwamba hautajilipa hata kwa miaka mitano. Na hii ni kushindwa kamili kutoka kwa mtazamo wa mzunguko wa maisha ya mfano.
Kwa hivyo, jambo rahisi kama ufuatiliaji linaweza kuwa muhimu katika maisha ya mfano. Kando na vipimo vya kawaida na dhahiri, tunazingatia usambazaji wa majibu na alama za miundo, pamoja na usambazaji wa thamani za vipengele muhimu. Kwa kutumia mseto wa KL, tunaweza kulinganisha usambazaji wa sasa na ule wa kihistoria au thamani katika jaribio la A/B na mtiririko mwingine, ambayo huturuhusu kutambua hitilafu katika muundo na kurejesha mabadiliko kwa wakati ufaao.
Mara nyingi, tunazindua matoleo yetu ya kwanza ya mifumo kwa kutumia mifumo rahisi ya utabiri au miundo tunayotumia kama ufuatiliaji katika siku zijazo. Kwa mfano, tunafuatilia kielelezo cha NER kwa kulinganisha na zile za kawaida kwa maduka mahususi ya mtandaoni, na ikiwa chanjo ya kiainishaji itapungua kwa kulinganisha nayo, basi tunaelewa sababu. Matumizi mengine muhimu ya heuristics!
Matokeo ya
Hebu tupitie mawazo muhimu ya makala tena.
- Fibdeck. Sisi daima tunafikiri juu ya mtumiaji: jinsi atakavyoishi na makosa yetu, jinsi atakavyoweza kuripoti. Usisahau kwamba watumiaji sio chanzo cha maoni safi kwa mifano ya mafunzo, na inahitaji kufutwa kwa usaidizi wa mifumo ya msaidizi ya ML. Ikiwa haiwezekani kukusanya ishara kutoka kwa mtumiaji, basi tunatafuta vyanzo mbadala vya maoni, kwa mfano, mifumo iliyounganishwa.
- Mafunzo ya ziada. Jambo kuu hapa ni kuendelea, kwa hiyo tunategemea mfano wa sasa wa uzalishaji. Tunatoa mafunzo kwa aina mpya ili zisitofautiane sana na ile ya awali kwa sababu ya urekebishaji wa usawa na hila zinazofanana.
- Weka. Usambazaji wa kiotomatiki kulingana na vipimo hupunguza sana muda wa kutekeleza miundo. Ufuatiliaji wa takwimu na usambazaji wa kufanya maamuzi, idadi ya maporomoko kutoka kwa watumiaji ni lazima kwa usingizi wako wa utulivu na wikendi yenye matokeo.
Naam, natumai hii itakusaidia kuboresha mifumo yako ya ML haraka, kuipeleka sokoni haraka, na kuifanya iwe ya kuaminika zaidi na isiyo na mafadhaiko.
Chanzo: mapenzi.com
