

Halo watu wote, jina langu ni Alexander, ninafanya kazi katika CIAN kama mhandisi na ninahusika katika usimamizi wa mfumo na otomatiki wa michakato ya miundombinu. Katika maoni kwa moja ya nakala zilizopita, tuliulizwa kuelezea ni wapi tunapata TB 4 za magogo kwa siku na tunafanya nini nazo. Ndiyo, tuna magogo mengi, na nguzo tofauti ya miundombinu imeundwa ili kuzishughulikia, ambayo inaruhusu sisi kutatua matatizo haraka. Katika nakala hii nitazungumza juu ya jinsi tulivyoibadilisha kwa muda wa mwaka ili kufanya kazi na mtiririko unaokua wa data.
Tulianzia wapi?
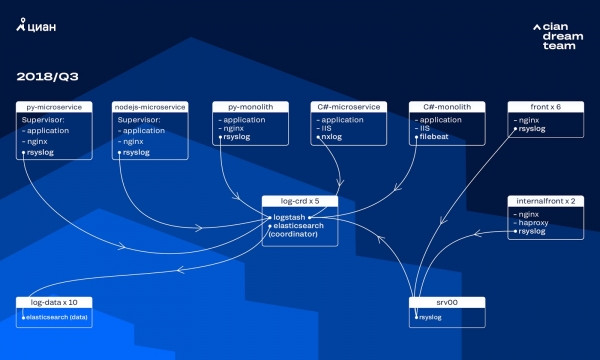
Katika miaka michache iliyopita, mzigo kwenye cian.ru umeongezeka haraka sana, na kwa robo ya tatu ya 2018, trafiki ya rasilimali ilifikia watumiaji milioni 11.2 wa kipekee kwa mwezi. Wakati huo, kwa wakati muhimu tulipoteza hadi 40% ya magogo, ndiyo sababu hatukuweza kukabiliana na matukio haraka na tulitumia muda mwingi na jitihada kusuluhisha. Pia mara nyingi hatukuweza kupata sababu ya tatizo, na ingejirudia baada ya muda fulani. Ilikuwa kuzimu na kitu kilipaswa kufanywa juu yake.
Wakati huo, tulitumia kundi la nodi 10 za data zenye toleo la 5.5.2 la ElasticSearch na mipangilio ya kawaida ya faharasa ili kuhifadhi kumbukumbu. Ilianzishwa zaidi ya mwaka mmoja uliopita kama suluhisho maarufu na la bei nafuu: basi mtiririko wa magogo haukuwa mkubwa sana, hakukuwa na maana ya kuja na usanidi usio wa kawaida.
Uchakataji wa kumbukumbu zinazoingia ulitolewa na Logstash kwenye bandari tofauti kwenye waratibu watano wa ElasticSearch. Ripoti moja, bila kujali ukubwa, ilijumuisha shards tano. Mzunguko wa kila saa na wa kila siku ulipangwa, kwa sababu hiyo, karibu shards 100 mpya zilionekana kwenye nguzo kila saa. Ingawa hapakuwa na magogo mengi, nguzo hiyo ilishughulikia vizuri na hakuna mtu aliyezingatia mipangilio yake.
Changamoto za ukuaji wa haraka
Kiasi cha magogo yaliyotengenezwa kilikua haraka sana, kwani michakato miwili ilipishana. Kwa upande mmoja, idadi ya watumiaji wa huduma ilikua. Kwa upande mwingine, tulianza kubadili kikamilifu kwa usanifu wa huduma ndogo, tukiona monoliths zetu za zamani katika C # na Python. Huduma ndogo kadhaa mpya ambazo zilibadilisha sehemu za monolith zilizalisha kumbukumbu nyingi zaidi za nguzo ya miundombinu.
Ilikuwa ni kuongeza ambayo ilituongoza hadi mahali ambapo nguzo hiyo haikuweza kudhibitiwa. Wakati magogo yalianza kufika kwa kiwango cha ujumbe elfu 20 kwa pili, mzunguko wa mara kwa mara usio na maana uliongeza idadi ya shards hadi 6 elfu, na kulikuwa na zaidi ya 600 shards kwa node.
Hii ilisababisha matatizo katika mgao wa RAM, na wakati nodi ilipoanguka, vipande vyote vilihama kwa wakati mmoja, na kuongeza trafiki na kupakia nodi zilizobaki, na kufanya iwe vigumu kuandika data kwenye kundi. Na katika kipindi hiki, tuliachwa bila kumbukumbu. Na ikiwa kulikuwa na tatizo na seva Tulikuwa tunapoteza 1/10 ya kundi kwa ujumla. Idadi kubwa ya fahirisi ndogo iliongeza ugumu.
Bila kumbukumbu, hatukuelewa sababu za tukio hilo na mapema au baadaye tunaweza kuingia kwenye safu moja tena, na kwa itikadi ya timu yetu hii haikukubalika, kwani mifumo yetu yote ya kazi imeundwa kufanya kinyume - kamwe usirudie. matatizo sawa. Ili kufanya hivyo, tulihitaji ujazo kamili wa kumbukumbu na uwasilishaji wao karibu kwa wakati halisi, kwani timu ya wahandisi wa zamu ilifuatilia arifa sio tu kutoka kwa vipimo, lakini pia kutoka kwa kumbukumbu. Ili kuelewa ukubwa wa tatizo, wakati huo kiasi cha jumla cha magogo kilikuwa karibu 2 TB kwa siku.
Tuliweka lengo la kuondoa kabisa upotevu wa magogo na kupunguza muda wa utoaji wao kwa nguzo ya ELK hadi upeo wa dakika 15 wakati wa nguvu majeure (baadaye tulitegemea takwimu hii kama KPI ya ndani).
Utaratibu mpya wa mzunguko na nodi za joto-joto
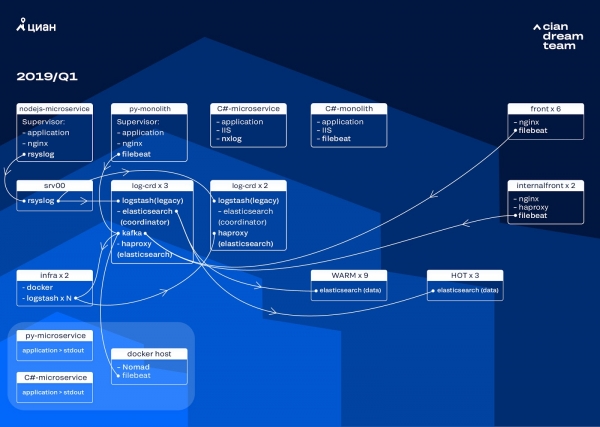
Tulianza ubadilishaji wa nguzo kwa kusasisha toleo la ElasticSearch kutoka 5.5.2 hadi 6.4.3. Kwa mara nyingine tena nguzo yetu ya toleo la 5 ilikufa, na tuliamua kuizima na kuisasisha kabisa - bado hakuna kumbukumbu. Kwa hivyo tulifanya mabadiliko haya kwa saa chache tu.
Mabadiliko makubwa zaidi katika hatua hii yalikuwa utekelezaji wa Apache Kafka kwenye nodi tatu na mratibu kama buffer ya kati. Wakala wa ujumbe alituokoa kutokana na kupoteza kumbukumbu wakati wa matatizo na ElasticSearch. Wakati huo huo, tuliongeza nodes 2 kwenye nguzo na kubadili usanifu wa joto la joto na nodes tatu za "moto" ziko kwenye racks tofauti katika kituo cha data. Tulielekeza kumbukumbu kwao kwa kutumia mask ambayo haipaswi kupotea kwa hali yoyote - nginx, pamoja na kumbukumbu za makosa ya programu. Kumbukumbu ndogo zilitumwa kwa nodi zilizobaki - utatuzi, onyo, nk, na baada ya masaa 24, magogo "muhimu" kutoka kwa nodi za "moto" zilihamishwa.
Ili sio kuongeza idadi ya fahirisi ndogo, tulibadilisha kutoka kwa mzunguko wa wakati hadi utaratibu wa rollover. Kulikuwa na habari nyingi kwenye mabaraza ambayo mzunguko kwa saizi ya faharisi hauaminiki sana, kwa hivyo tuliamua kutumia mzunguko kwa idadi ya hati kwenye faharisi. Tulichanganua kila faharasa na kurekodi idadi ya hati ambazo baada ya mzunguko unapaswa kufanya kazi. Kwa hivyo, tumefikia ukubwa wa shard bora - si zaidi ya 50 GB.
Uboreshaji wa nguzo
Walakini, hatujamaliza kabisa shida. Kwa bahati mbaya, fahirisi ndogo bado zilionekana: hazikufikia kiwango maalum, hazikuzungushwa, na zilifutwa na utakaso wa kimataifa wa faharisi za zamani zaidi ya siku tatu, kwani tuliondoa mzunguko kwa tarehe. Hii ilisababisha upotezaji wa data kutokana na ukweli kwamba faharisi kutoka kwa nguzo ilipotea kabisa, na jaribio la kuandika kwa fahirisi isiyokuwepo ilivunja mantiki ya mtunzaji ambayo tulitumia kwa usimamizi. Lakabu ya uandishi ilibadilishwa kuwa faharisi na ikavunja mantiki ya kuzunguka, na kusababisha ukuaji usiodhibitiwa wa faharisi zingine hadi 600 GB.
Kwa mfano, kwa usanidi wa mzunguko:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Ikiwa hapakuwa na lakabu ya kusambaza, hitilafu ilitokea:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Tuliacha suluhisho la tatizo hili kwa marudio yaliyofuata na tukachukua suala lingine: tulibadilisha mantiki ya kuvuta ya Logstash, ambayo huchakata kumbukumbu zinazoingia (kuondoa maelezo yasiyo ya lazima na kuimarisha). Tuliiweka kwenye dokta, ambayo tunazindua kupitia utungaji wa docker, na pia tuliweka logstash-exporter huko, ambayo hutuma vipimo kwa Prometheus kwa ufuatiliaji wa uendeshaji wa mtiririko wa kumbukumbu. Kwa njia hii tulijipa fursa ya kubadilisha kwa urahisi idadi ya matukio ya logstash yanayohusika na usindikaji wa kila aina ya logi.
Tulipokuwa tukiboresha kikundi, trafiki ya cian.ru iliongezeka hadi watumiaji wa kipekee milioni 12,8 kwa mwezi. Matokeo yake, ikawa kwamba mabadiliko yetu yalikuwa nyuma kidogo ya mabadiliko katika uzalishaji, na tulikuwa tunakabiliwa na ukweli kwamba nodes za "joto" hazikuweza kukabiliana na mzigo na kupunguza kasi ya utoaji mzima wa magogo. Tulipokea data "ya moto" bila kushindwa, lakini tulipaswa kuingilia kati katika utoaji wa wengine na kufanya rollover ya mwongozo ili kusambaza sawasawa indexes.
Wakati huo huo, kuongeza na kubadilisha mipangilio ya matukio ya logstash kwenye nguzo ilikuwa ngumu na ukweli kwamba ilikuwa mtunzi wa ndani, na vitendo vyote vilifanywa kwa mikono (ili kuongeza ncha mpya, ilikuwa ni lazima kupitia kwa mikono yote. seva na fanya docker-compose up -d kila mahali).
Ugawaji upya wa logi
Mnamo Septemba mwaka huu, tulikuwa bado tunakata monolith, mzigo kwenye nguzo ulikuwa unaongezeka, na mtiririko wa magogo ulikuwa unakaribia ujumbe elfu 30 kwa pili.
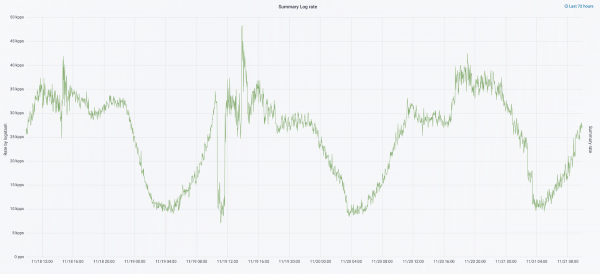
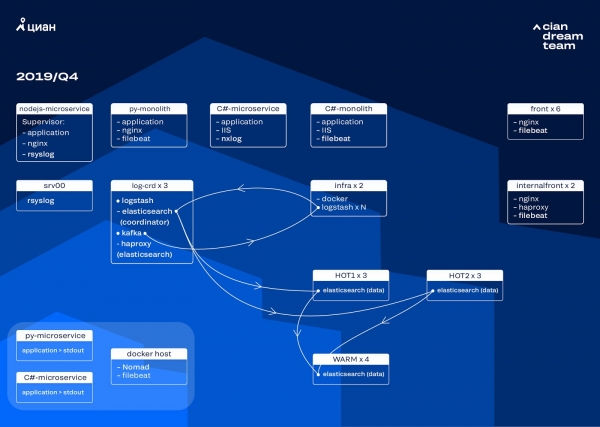
Tulianza kurudia tena na sasisho la maunzi. Tulibadilisha kutoka kwa waratibu watano hadi watatu, tukabadilisha nodi za data na tukashinda kwa suala la pesa na nafasi ya kuhifadhi. Kwa nodi tunatumia usanidi mbili:
- Kwa nodi za "moto": E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 kwa Hot1 na 3 kwa Hot2).
- Kwa nodi za "joto": E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Kwa kurudia hii, tulihamisha index na kumbukumbu za upatikanaji wa microservices, ambayo inachukua nafasi sawa na magogo ya mstari wa mbele wa nginx, kwa kundi la pili la nodi tatu za "moto". Sasa tunahifadhi data kwenye nodes za "moto" kwa saa 20, na kisha uhamishe kwenye nodes za "joto" kwenye magogo mengine.
Tulitatua tatizo la faharisi ndogo kutoweka kwa kurekebisha mzunguko wao. Sasa faharisi zinazungushwa kila masaa 23 kwa hali yoyote, hata ikiwa kuna data kidogo hapo. Hii iliongeza kidogo idadi ya shards (kulikuwa na karibu 800 kati yao), lakini kutoka kwa mtazamo wa utendaji wa nguzo inaweza kuvumiliwa.
Matokeo yake, kulikuwa na "moto" sita na nodes nne tu za "joto" kwenye nguzo. Hii husababisha kuchelewa kidogo kwa maombi kwa muda mrefu, lakini kuongeza idadi ya nodi katika siku zijazo kutatua tatizo hili.
Rudia hii pia ilisuluhisha tatizo la ukosefu wa kuongeza nusu otomatiki. Ili kufanya hivyo, tulisambaza nguzo ya Nomad ya miundombinu - sawa na ile ambayo tayari tumeweka katika uzalishaji. Kwa sasa, kiasi cha Logstash haibadilika kiatomati kulingana na mzigo, lakini tutakuja kwa hili.
Mipango ya siku zijazo
Mizani ya usanidi iliyotekelezwa kikamilifu, na sasa tunahifadhi 13,3 TB ya data - kumbukumbu zote kwa siku 4, ambayo ni muhimu kwa uchambuzi wa dharura wa tahadhari. Tunabadilisha baadhi ya kumbukumbu kuwa vipimo, ambavyo tunaongeza kwenye Graphite. Ili kurahisisha kazi ya wahandisi, tuna vipimo vya nguzo ya miundombinu na hati za ukarabati wa nusu otomatiki wa matatizo ya kawaida. Baada ya kuongeza idadi ya nodi za data, ambazo zimepangwa kwa mwaka ujao, tutabadilisha uhifadhi wa data kutoka siku 4 hadi 7. Hii itakuwa ya kutosha kwa ajili ya kazi ya uendeshaji, kwa kuwa sisi daima tunajaribu kuchunguza matukio haraka iwezekanavyo, na kwa uchunguzi wa muda mrefu kuna data ya telemetry.
Mnamo Oktoba 2019, trafiki kwa cian.ru tayari ilikuwa imeongezeka hadi watumiaji wa kipekee milioni 15,3 kwa mwezi. Hii ikawa mtihani mzito wa suluhisho la usanifu wa kutoa magogo.
Sasa tunajitayarisha kusasisha ElasticSearch hadi toleo la 7. Hata hivyo, kwa hili tutalazimika kusasisha upangaji ramani wa faharasa nyingi katika ElasticSearch, kwa kuwa zilihama kutoka toleo la 5.5 na kutangazwa kuwa hazitumiki katika toleo la 6 (hazipo katika toleo la 7). 7). Hii ina maana kwamba wakati wa mchakato wa sasisho hakika kutakuwa na aina fulani ya nguvu majeure, ambayo itatuacha bila magogo wakati suala linatatuliwa. Kati ya toleo la XNUMX, tunatazamia zaidi Kibana iliyo na kiolesura kilichoboreshwa na vichujio vipya.
Tulifikia lengo letu kuu: tuliacha kupoteza kumbukumbu na kupunguza muda wa chini wa nguzo ya miundombinu kutoka kwa ajali 2-3 kwa wiki hadi saa kadhaa za kazi ya ukarabati kwa mwezi. Kazi hii yote katika uzalishaji karibu haionekani. Hata hivyo, sasa tunaweza kuamua hasa kinachotokea na huduma yetu, tunaweza kufanya haraka kwa hali ya utulivu na usijali kwamba magogo yatapotea. Kwa ujumla, tumeridhika, tunafurahi na tunajiandaa kwa ushujaa mpya, ambao tutazungumza baadaye.
Chanzo: mapenzi.com
