

Katika makala haya, nitaelezea hali iliyotokea hivi karibuni na moja ya seva zetu za wingu za VPS, ambayo ilinisumbua kwa saa kadhaa. Nimekuwa nikisanidi na kutatua matatizo ya seva kwa takriban miaka 15. Linux, lakini kesi hii haiendani kabisa na utendaji wangu - nilifanya mawazo kadhaa ya uongo na nilikuwa na tamaa kidogo kabla sijaweza kutambua kwa usahihi chanzo cha tatizo na kulitatua.
Kuelezea
Tunatumia wingu la ukubwa wa wastani, ambalo tunaunda kwenye seva za kawaida na usanidi ufuatao: cores 32, RAM ya GB 256, na kiendeshi cha 4 TB PCI-E Intel P4500 NVMe. Tunapenda sana usanidi huu kwa sababu huondoa hitaji la IO kwa kuhakikisha kuteleza vizuri katika kiwango cha mfano cha VM. Tangu Intel NVMe Ina utendakazi wa kuvutia, tunaweza kutoa wakati huo huo utoaji kamili wa IOPS kwa mashine na hifadhi ya chelezo kwenye seva ya chelezo bila IOWAIT sifuri.
Sisi ni miongoni mwa wale watu wa zamani ambao hawatumii SDN iliyounganishwa au vifaa vingine vya mtindo, vya mtindo, vya ujana ili kuhifadhi kiasi cha VM, tukiamini kwamba mfumo rahisi zaidi, ni rahisi zaidi kutatua wakati "mkuu mkuu amekwenda milimani." Kwa hivyo, tunahifadhi juzuu za VM katika umbizo la QCOW2 kwenye XFS au EXT4, ambayo inatumwa juu ya LVM2.
Pia tunalazimika kutumia QCOW2 na bidhaa tunayotumia kwa uimbaji—Apache CloudStack.
Ili kufanya nakala rudufu, tunachukua picha kamili ya kiasi kama picha ya LVM2 (ndio, tunajua vijipicha vya LVM2 ni polepole, lakini Intel P4500 hutusaidia hapa pia). Sisi hufanya lvmcreate -s .. na kwa msaada wa dd Tunatuma nakala rudufu kwa seva ya mbali na uhifadhi wa ZFS. Tunapiga hatua hapa—ZFS inaweza kuhifadhi data katika mfumo uliobanwa, na tunaweza kuirejesha kwa haraka kwa kutumia DD au toa kiasi cha VM binafsi kwa kutumia mount -o loop ....
Bila shaka, huwezi kuchukua picha kamili ya kiasi cha LVM2, lakini weka mfumo wa faili katika hali
ROna nakala za picha za QCOW2 zenyewe. Walakini, tumekumbana na hali ambapo hii husababisha XFS kufanya kazi vibaya, sio mara moja, lakini bila kutarajia. Hatupendi wakati waandaji wa hypervisor wanapoganda ghafla wikendi, usiku au wakati wa likizo kutokana na hitilafu zinazotokea kwa wakati usiojulikana. Kwa hivyo, hatutumii kuweka picha kwa XFS.ROkutoa kiasi, lakini nakili tu kiasi kizima cha LVM2.
Kwa upande wetu, kasi ya chelezo kwa seva ya chelezo imedhamiriwa na utendaji wa seva ya chelezo, ambayo ni takriban 600-800 MB/s kwa data isiyoweza kubatizwa. Kizuizi zaidi ni chaneli ya 10 Gbit/s inayounganisha seva mbadala kwenye nguzo.
Wakati huo huo, nakala 8 za chelezo hupakiwa kwenye seva moja ya chelezo kwa wakati mmoja. seva Vidhibiti vya Haipakuni. Kwa hivyo, diski na mifumo midogo ya mtandao ya seva mbadala, ingawa ni polepole, huzuia mifumo midogo ya diski ya mwenyeji wa haipakuni kuzidiwa, kwani haiwezi kushughulikia, tuseme, 8 GB/sekunde, ambayo mwenyeji wa haipakuni anaweza kushughulikia kwa urahisi.
Mchakato wa nakala hapo juu ni muhimu sana kwa hadithi zaidi, ikiwa ni pamoja na maelezo - kwa kutumia gari la haraka la Intel P4500, kwa kutumia NFS na, pengine, kwa kutumia ZFS.
Historia ya Hifadhi Nakala
Kwenye kila nodi ya hypervisor tuna kizigeu kidogo cha SWAP cha GB 8, na "tunatoa" nodi ya hypervisor yenyewe kwa kutumia. DD Kutoka kwa picha ya bwana. Kwa kiasi cha mfumo kwenye seva, tunatumia 2xSATA SSD RAID1 au 2xSAS HDD RAID1 kwenye LSI au kidhibiti cha maunzi cha HP. Kimsingi, hatujali kilicho ndani, kwani kiasi cha mfumo hufanya kazi katika hali ya "karibu kusoma tu", isipokuwa kwa kubadilishana. Na kwa kuwa tuna RAM nyingi kwenye seva na ni 30-40% bila malipo, hatuna wasiwasi kuhusu kubadilishana.
Mchakato wa kuunda nakala rudufuKazi hii inaonekana kama hii:
#!/bin/bash
mkdir -p /mnt/backups/volumes
DIR=/mnt/images-snap
VOL=images/volume
DATE=$(date "+%d")
HOSTNAME=$(hostname)
lvcreate -s -n $VOL-snap -l100%FREE $VOL
ionice -c3 dd iflag=direct if=/dev/$VOL-snap bs=1M of=/mnt/backups/volumes/$HOSTNAME-$DATE.raw
lvremove -f $VOL-snapMakini na ionice -c3, kwa kweli, jambo hili halina maana kabisa kwa vifaa vya NVMe, kwani mpangilio wa IO kwao umewekwa kama:
cat /sys/block/nvme0n1/queue/scheduler
[none] Walakini, tuna idadi ya nodi za urithi zilizo na RAID za kawaida za SSD, kwao hii ni muhimu, kwa hivyo inahamishwa. AS IS. Kwa ujumla, ni kipande cha msimbo cha kuvutia kinachoelezea ubatili ionice katika kesi ya usanidi kama huo.
Makini na bendera iflag=direct kwa DDTunatumia IO ya moja kwa moja kukwepa akiba ya akiba ili kuepuka ubadilishanaji wa bafa wa IO wakati wa kusoma. Hata hivyo, oflag=direct Hatufanyi hivi kwa sababu tumekumbana na masuala ya utendaji na ZFS tunapoitumia.
Tumekuwa tukitumia mpango huu kwa mafanikio kwa miaka kadhaa bila shida yoyote.
Na kisha ilianza…Tuligundua kuwa hifadhi rudufu zimesimamishwa kwa mojawapo ya nodi, na hifadhi rudufu ya awali ilikuwa imekamilika kwa IOWAIT ya kutisha ya karibu 50%. Wakati tukijaribu kubaini kwa nini chelezo hazifanyiki, tulikumbana na hali ifuatayo:
Volume group "images" not foundTulianza kufikiria kuwa Intel P4500 imekufa, lakini kabla ya kuzima seva ili kuchukua nafasi ya kiendeshi, bado tulihitaji kufanya nakala rudufu. Tulirekebisha LVM2 kwa kurejesha metadata kutoka kwa nakala rudufu ya LVM2:
vgcfgrestore imagesTulianza nakala rudufu na tukaona picha hii:
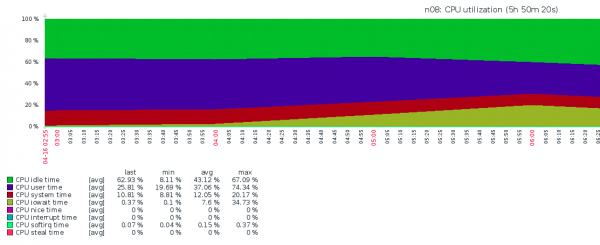
Tulihuzunika sana tena—ilikuwa wazi kwamba hatungeweza kuishi hivi, kwani VPS wote wangeteseka, na hiyo ilimaanisha kwamba tungeteseka pia. Kilichokuwa kikitokea hakikuwa wazi kabisa - iostat Ilikuwa inaonyesha IOPS ya kusikitisha na IOWAIT ya juu angani. Sikuwa na maoni mengine zaidi ya "wacha tubadilishe NVMe," lakini basi nilikuwa na ufunuo.
Kuchambua hali hiyo hatua kwa hatua
Jarida la kihistoriaSiku chache mapema, VPS kubwa yenye 128 GB ya RAM ilihitajika kuundwa kwenye seva hii. Kumbukumbu ilionekana kutosha, lakini kama hatua ya usalama, GB 32 ya ziada ilitengwa kwa kubadilishana. VPS iliundwa, ikakamilisha kazi yake kwa mafanikio, na tukio hilo lilisahauliwa, lakini kizigeu cha kubadilishana kilibaki.
Vipengele vya UsanidiKwa seva zote za wingu, parameter vm.swappiness iliwekwa kwa thamani chaguo-msingi 60Na SWAP iliundwa kwenye SAS HDD RAID1.
Nini kilifanyika (kulingana na wahariri)Wakati wa kuhifadhi nakala DD ilikuwa ikitoa data nyingi za kuandika, ambazo ziliwekwa kwenye vihifadhi vya RAM kabla ya kuandikwa kwa NFS. Kiini cha mfumo, kinachoongozwa na sera swappiness, ilihamisha kurasa nyingi za kumbukumbu za VPS ili kubadilishana nafasi, ambayo ilikuwa kwenye sauti ya polepole ya HDD RAID1. Hii ilisababisha IOWAIT kuongezeka kwa kasi, si kutokana na NVMe IO, lakini kutokana na HDD RAID1 IO.
Jinsi tatizo lilitatuliwaSehemu ya kubadilishana ya 32GB ilizimwa. Hii ilichukua masaa 16. Unaweza kusoma kuhusu jinsi na kwa nini kizigeu cha kubadilishana ni polepole sana kuzima kando. Vigezo vilibadilishwa. swappiness kwa thamani sawa na 5 katika wingu lote.
Je, hili lisingetokeaje?Kwanza, ikiwa SWAP ilikuwa kwenye SSD RAID au kifaa cha NVMe, na pili, ikiwa hakukuwa na kifaa cha NVMe, lakini kifaa cha polepole ambacho hakingeweza kushughulikia kiasi kama hicho cha data - kwa kushangaza, shida iliibuka kwa sababu NVMe ni haraka sana.
Baada ya hapo, kila kitu kilianza kufanya kazi kama hapo awali - na sifuri IOWAIT.
Chanzo: mapenzi.com
