

Kuna hali wakati kwa meza bila ufunguo wa msingi au faharasa nyingine ya kipekee, kwa sababu ya uangalizi, nakala kamili za rekodi zilizopo tayari zimejumuishwa.

Kwa mfano, maadili ya metriki ya mpangilio huandikwa kwa PostgreSQL kwa kutumia mkondo wa COPY, na kisha kuna kutofaulu kwa ghafla, na sehemu ya data inayofanana kabisa hufika tena.
Jinsi ya kuondoa hifadhidata ya clones zisizo za lazima?
Wakati PK sio msaidizi
Njia rahisi ni kuzuia hali kama hiyo kutokea hapo awali. Kwa mfano, tembeza UFUNGUO WA MSINGI. Lakini hii haiwezekani kila wakati bila kuongeza kiasi cha data iliyohifadhiwa.
Kwa mfano, ikiwa usahihi wa mfumo wa chanzo ni wa juu kuliko usahihi wa sehemu kwenye hifadhidata:
metric | ts | data
--------------------------------------------------
cpu.busy | 2019-12-20 00:00:00 | {"value" : 12.34}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 10}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 11.2}
cpu.busy | 2019-12-20 00:00:03 | {"value" : 15.7}
Je, umeona? Siku iliyosalia badala ya 00:00:02 ilirekodiwa kwenye hifadhidata na ts pili mapema, lakini ilibaki halali kutoka kwa maoni ya maombi (baada ya yote, maadili ya data ni tofauti!).
Bila shaka unaweza kufanya hivyo PK(kipimo, ts) - lakini basi tutapata migongano ya kuingizwa kwa data halali.
Inaweza kufanyika PK(kipimo, ts, data) - lakini hii itaongeza sana kiasi chake, ambacho hatutatumia.
Kwa hiyo, chaguo sahihi zaidi ni kufanya index ya kawaida isiyo ya kipekee (kipimo, ts) na kushughulikia matatizo baada ya ukweli kama yatatokea.
"Vita ya clonic imeanza"
Aina fulani ya ajali ilitokea, na sasa tunapaswa kuharibu rekodi za clone kutoka kwa meza.

Wacha tuige mfano wa data asili:
CREATE TABLE tbl(k text, v integer);
INSERT INTO tbl
VALUES
('a', 1)
, ('a', 3)
, ('b', 2)
, ('b', 2) -- oops!
, ('c', 3)
, ('c', 3) -- oops!!
, ('c', 3) -- oops!!
, ('d', 4)
, ('e', 5)
;Hapa mkono wetu ulitetemeka mara tatu, Ctrl+V ilikwama, na sasa...
Kwanza, wacha tuelewe kuwa meza yetu inaweza kuwa kubwa sana, kwa hivyo baada ya kupata clones zote, inashauriwa sisi "kunyoosha kidole" ili kufuta. rekodi maalum bila kuzitafuta tena.
Na kuna njia kama hiyo - hii , kitambulisho halisi cha rekodi mahususi.
Hiyo ni, kwanza kabisa, tunahitaji kukusanya ctid ya rekodi katika muktadha wa yaliyomo kamili ya safu ya jedwali. Chaguo rahisi ni kutupa mstari mzima katika maandishi:
SELECT
T::text
, array_agg(ctid) ctids
FROM
tbl T
GROUP BY
1;
t | ctids
---------------------------------
(e,5) | {"(0,9)"}
(d,4) | {"(0,8)"}
(c,3) | {"(0,5)","(0,6)","(0,7)"}
(b,2) | {"(0,3)","(0,4)"}
(a,3) | {"(0,2)"}
(a,1) | {"(0,1)"}
Je, inawezekana si kutupwa?Kimsingi, inawezekana katika hali nyingi. Hadi uanze kutumia sehemu kwenye jedwali hili aina bila operator usawa:
CREATE TABLE tbl(k text, v integer, x point);
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T;
-- ERROR: could not identify an equality operator for type tbl
Ndio, tunaona mara moja kwamba ikiwa kuna zaidi ya ingizo moja kwenye safu, hizi zote ni clones. Wacha tuwaache:
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T;unnest
------
(0,6)
(0,7)
(0,4)Kwa wale wanaopenda kuandika kwa ufupiUnaweza pia kuandika kama hii:
SELECT
unnest((array_agg(ctid))[2:])
FROM
tbl T
GROUP BY
T::text;Kwa kuwa thamani ya mfuatano wa safu yenyewe haituvutii, tuliitupa nje ya safu wima zilizorejeshwa za hoja ndogo.
Imesalia kidogo tu kufanya - fanya DELETE kutumia seti tuliyopokea:
DELETE FROM
tbl
WHERE
ctid = ANY(ARRAY(
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T
)::tid[]);Wacha tujichunguze:
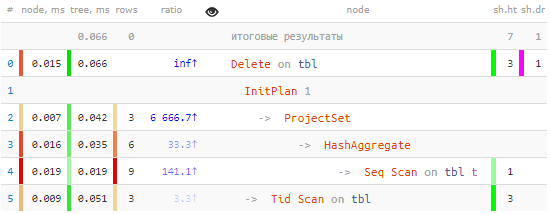
Ndiyo, kila kitu ni sahihi: rekodi zetu 3 zilichaguliwa kwa Seq Scan pekee ya jedwali zima, na nodi ya Futa ilitumiwa kutafuta data. pasi moja na Tid Scan:
-> Tid Scan on tbl (actual time=0.050..0.051 rows=3 loops=1)
TID Cond: (ctid = ANY ($0))Ikiwa ulifuta rekodi nyingi, .
Wacha tuangalie jedwali kubwa na idadi kubwa ya nakala:
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
chr(ascii('a'::text) + (random() * 26)::integer) k -- a..z
, (random() * 100)::integer v -- 0..99
FROM
generate_series(1, 10000) i; 
Kwa hivyo, njia hiyo inafanya kazi kwa mafanikio, lakini lazima itumike kwa tahadhari fulani. Kwa sababu kwa kila rekodi inayofutwa, kuna ukurasa mmoja wa data unaosomwa kwenye Tid Scan, na moja kwenye Futa.
Chanzo: mapenzi.com
