


SQL, எது எளிமையாக இருக்க முடியும்? நாம் ஒவ்வொருவரும் ஒரு எளிய கோரிக்கையை எழுதலாம் - நாங்கள் தட்டச்சு செய்கிறோம் தேர்வு, தேவையான நெடுவரிசைகளை பட்டியலிடுங்கள் இருந்து, அட்டவணை பெயர், சில நிபந்தனைகள் எங்கே அவ்வளவுதான் - பயனுள்ள தரவு எங்கள் பாக்கெட்டில் உள்ளது, மேலும் (கிட்டத்தட்ட) அந்த நேரத்தில் எந்த டிபிஎம்எஸ் ஹூட் கீழ் இருந்தாலும் (அல்லது இருக்கலாம் ) இதன் விளைவாக, எந்தவொரு தரவு மூலத்துடனும் பணிபுரிவது (தொடர்புடையது மற்றும் அவ்வாறு இல்லை) சாதாரண குறியீட்டின் பார்வையில் இருந்து பரிசீலிக்கப்படலாம் (அது குறிக்கும் அனைத்தையும் கொண்டு - பதிப்பு கட்டுப்பாடு, குறியீடு மதிப்பாய்வு, நிலையான பகுப்பாய்வு, தன்னியக்க சோதனைகள் மற்றும் அவ்வளவுதான்). இது தரவு, திட்டங்கள் மற்றும் இடம்பெயர்வுகளுக்கு மட்டுமல்ல, பொதுவாக சேமிப்பகத்தின் முழு வாழ்க்கைக்கும் பொருந்தும். இந்தக் கட்டுரையில், "டேட்டாபேஸ் அஸ் கோட்" என்ற லென்ஸின் கீழ் பல்வேறு தரவுத்தளங்களுடன் பணிபுரியும் அன்றாட பணிகள் மற்றும் சிக்கல்களைப் பற்றி பேசுவோம்.
மற்றும் இப்போதிலிருந்து ஆரம்பிக்கலாம் . "SQL vs ORM" வகையின் முதல் போர்கள் மீண்டும் கவனிக்கப்பட்டன .
பொருள்-தொடர்பு மேப்பிங்
ORM ஆதரவாளர்கள் பாரம்பரியமாக வேகம் மற்றும் வளர்ச்சியின் எளிமை, DBMS இலிருந்து சுதந்திரம் மற்றும் சுத்தமான குறியீட்டை மதிக்கிறார்கள். நம்மில் பலருக்கு, தரவுத்தளத்துடன் வேலை செய்வதற்கான குறியீடு (பெரும்பாலும் தரவுத்தளமே)
இது பொதுவாக இப்படி இருக்கும்...
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...மாடல் புத்திசாலித்தனமான சிறுகுறிப்புகளுடன் தொங்கவிடப்பட்டுள்ளது, மேலும் எங்கோ திரைக்குப் பின்னால் ஒரு வீரமிக்க ORM சில SQL குறியீட்டை உருவாக்கி செயல்படுத்துகிறது. மூலம், டெவலப்பர்கள் தங்கள் தரவுத்தளத்திலிருந்து கிலோமீட்டர் சுருக்கங்கள் மூலம் தங்களைத் தனிமைப்படுத்த முயற்சி செய்கிறார்கள், இது சிலவற்றைக் குறிக்கிறது .
தடுப்புகளின் மறுபுறத்தில், தூய "கையால்" SQL ஐப் பின்பற்றுபவர்கள் கூடுதல் அடுக்குகள் மற்றும் சுருக்கங்கள் இல்லாமல் தங்கள் DBMS இலிருந்து அனைத்து சாறுகளையும் பிழியும் திறனைக் குறிப்பிடுகின்றனர். இதன் விளைவாக, "தரவு-மைய" திட்டங்கள் தோன்றும், அங்கு சிறப்புப் பயிற்சி பெற்ற நபர்கள் தரவுத்தளத்தில் ஈடுபட்டுள்ளனர் (அவர்களும் "அடிப்படைவாதிகள்", அவர்களும் "அடிப்படைவாதிகள்", அவர்களும் "பேஸ்டெனர்கள்" போன்றவை), மற்றும் டெவலப்பர்கள் விவரங்களுக்குச் செல்லாமல், ஆயத்தமான பார்வைகள் மற்றும் சேமிக்கப்பட்ட நடைமுறைகளை மட்டுமே "இழுக்க" வேண்டும்.
இரு உலகங்களிலும் சிறந்தவை நம்மிடம் இருந்தால் என்ன செய்வது? வாழ்க்கையை உறுதிப்படுத்தும் பெயருடன் ஒரு அற்புதமான கருவியில் இது எவ்வாறு செய்யப்படுகிறது . எனது இலவச மொழிபெயர்ப்பில் பொதுக் கருத்திலிருந்து ஓரிரு வரிகளைத் தருகிறேன், மேலும் நீங்கள் அதை இன்னும் விரிவாக அறிந்துகொள்ளலாம். .
Clojure என்பது DSLகளை உருவாக்குவதற்கான ஒரு சிறந்த மொழியாகும், ஆனால் SQL ஆனது ஒரு சிறந்த DSL ஆகும், மேலும் எங்களுக்கு வேறு ஒன்று தேவையில்லை. எஸ்-எக்ஸ்பிரஷன்கள் சிறப்பாக உள்ளன, ஆனால் அவை இங்கு புதிதாக எதையும் சேர்க்கவில்லை. இதன் விளைவாக, அடைப்புக்குறிகளுக்காக அடைப்புக்குறிகளைப் பெறுகிறோம். சம்மதமில்லை? தரவுத்தளத்தின் மீதான சுருக்கம் கசியத் தொடங்கும் தருணத்திற்காக காத்திருங்கள் மற்றும் நீங்கள் செயல்பாட்டுடன் போராடத் தொடங்குவீர்கள் (raw-sql)
எனவே நான் என்ன செய்ய வேண்டும்? SQL ஐ வழக்கமான SQL ஆக விடுவோம் - ஒரு கோரிக்கைக்கு ஒரு கோப்பு:
-- name: users-by-country
select *
from users
where country_code = :country_code... பின்னர் இந்தக் கோப்பைப் படித்து, வழக்கமான Clojure செயல்பாடாக மாற்றவும்:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; A function with the name `users-by-country` has been created.
;;; Let's use it:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)"SQL by தானே, Clojure by self" கொள்கையை கடைபிடிப்பதன் மூலம், நீங்கள் பெறுவீர்கள்:
- வாக்கிய ஆச்சரியங்கள் இல்லை. உங்கள் தரவுத்தளம் (மற்றவற்றைப் போல) SQL தரநிலையுடன் 100% இணங்கவில்லை - ஆனால் இது Yesql க்கு ஒரு பொருட்டல்ல. SQL சமமான தொடரியல் கொண்ட செயல்பாடுகளை வேட்டையாடுவதில் நீங்கள் நேரத்தை வீணடிக்க மாட்டீர்கள். நீங்கள் ஒருபோதும் செயல்பாட்டிற்குத் திரும்ப வேண்டியதில்லை (raw-sql "some('funky'::SYNTAX)")).
- சிறந்த எடிட்டர் ஆதரவு. உங்கள் எடிட்டருக்கு ஏற்கனவே சிறந்த SQL ஆதரவு உள்ளது. SQL ஐ SQL ஆக சேமிப்பதன் மூலம் நீங்கள் அதைப் பயன்படுத்தலாம்.
- குழு இணக்கம். உங்கள் DBAகள் உங்கள் Clojure திட்டத்தில் நீங்கள் பயன்படுத்தும் SQL ஐப் படிக்கவும் எழுதவும் முடியும்.
- எளிதான செயல்திறன் சரிப்படுத்தும். பிரச்சனைக்குரிய வினவலுக்கு ஒரு திட்டத்தை உருவாக்க வேண்டுமா? உங்கள் வினவல் வழக்கமான SQL ஆக இருக்கும்போது இது ஒரு பிரச்சனையல்ல.
- வினவல்களை மீண்டும் பயன்படுத்துதல். அதே SQL கோப்புகளை மற்ற திட்டங்களுக்கு இழுத்து விடுங்கள், ஏனெனில் இது வெறும் பழைய SQL தான் - அதைப் பகிரவும்.
என் கருத்துப்படி, யோசனை மிகவும் அருமையாகவும் அதே நேரத்தில் மிகவும் எளிமையானதாகவும் இருக்கிறது, இதற்கு நன்றி திட்டம் பலவற்றைப் பெற்றுள்ளது பல்வேறு மொழிகளில். ORM க்கு அப்பால் உள்ள எல்லாவற்றிலிருந்தும் SQL குறியீட்டைப் பிரிக்கும் இதேபோன்ற தத்துவத்தைப் பயன்படுத்த முயற்சிப்போம்.
IDE & DB மேலாளர்கள்
ஒரு எளிய அன்றாட பணியுடன் தொடங்குவோம். பெரும்பாலும் நாம் தரவுத்தளத்தில் சில பொருட்களைத் தேட வேண்டும், எடுத்துக்காட்டாக, ஸ்கீமாவில் ஒரு அட்டவணையைக் கண்டுபிடித்து அதன் கட்டமைப்பைப் படிக்கவும் (என்ன நெடுவரிசைகள், விசைகள், குறியீடுகள், கட்டுப்பாடுகள் போன்றவை பயன்படுத்தப்படுகின்றன). எந்த வரைகலை IDE அல்லது ஒரு சிறிய DB மேலாளரிடமிருந்தும், முதலில், இந்த திறன்களை நாங்கள் எதிர்பார்க்கிறோம். எனவே இது வேகமானது மற்றும் தேவையான தகவல்களுடன் கூடிய சாளரம் வரையப்படும் வரை நீங்கள் அரை மணி நேரம் காத்திருக்க வேண்டியதில்லை (குறிப்பாக தொலைநிலை தரவுத்தளத்துடன் மெதுவான இணைப்புடன்), அதே நேரத்தில், பெறப்பட்ட தகவல்கள் புதியதாகவும் பொருத்தமானதாகவும் இருக்கும், மற்றும் தற்காலிக சேமிப்பு குப்பை அல்ல. மேலும், மிகவும் சிக்கலான மற்றும் பெரிய தரவுத்தளம் மற்றும் அவற்றின் எண்ணிக்கை அதிகமாக இருந்தால், இதைச் செய்வது மிகவும் கடினம்.
ஆனால் பொதுவாக நான் சுட்டியை தூக்கி எறிந்துவிட்டு குறியீட்டை எழுதுவேன். "HR" திட்டத்தில் எந்த அட்டவணைகள் (மற்றும் எந்த பண்புகளுடன்) உள்ளன என்பதை நீங்கள் கண்டுபிடிக்க வேண்டும் என்று வைத்துக்கொள்வோம். பெரும்பாலான DBMS களில், information_schema இலிருந்து இந்த எளிய வினவல் மூலம் விரும்பிய முடிவை அடைய முடியும்:
select table_name
, ...
from information_schema.tables
where schema = 'HR'தரவுத்தளத்திலிருந்து தரவுத்தளத்திற்கு, அத்தகைய குறிப்பு அட்டவணைகளின் உள்ளடக்கங்கள் ஒவ்வொரு DBMS இன் திறன்களைப் பொறுத்து மாறுபடும். மேலும், எடுத்துக்காட்டாக, MySQL க்கு, அதே குறிப்பு புத்தகத்திலிருந்து இந்த DBMS க்கு குறிப்பிட்ட அட்டவணை அளவுருக்களைப் பெறலாம்:
select table_name
, storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc)
, row_format -- Формат строки ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle க்கு information_schema தெரியாது, ஆனால் அது உள்ளது , மற்றும் பெரிய பிரச்சனைகள் எதுவும் இல்லை:
select table_name
, pct_free -- Минимум свободного места в блоке данных (%)
, pct_used -- Минимум используемого места в блоке данных (%)
, last_analyzed -- Дата последнего сбора статистики
, ...
from all_tables
where owner = 'HR'ClickHouse விதிவிலக்கல்ல:
select name
, engine -- Используемый "движок" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'கசாண்ட்ராவில் இதேபோன்ற ஒன்றைச் செய்யலாம் (அட்டவணைகளுக்குப் பதிலாக நெடுவரிசைக் குடும்பங்கள் மற்றும் திட்டங்களுக்குப் பதிலாக கீஸ்பேஸ்கள் உள்ளன):
select columnfamily_name
, compaction_strategy_class -- Стратегия сборки мусора
, gc_grace_seconds -- Время жизни мусора
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'பிற தரவுத்தளங்களுக்கு, நீங்கள் இதே போன்ற வினவல்களைக் கொண்டு வரலாம் (மோங்கோவிடம் கூட உள்ளது , இது கணினியில் உள்ள அனைத்து சேகரிப்புகள் பற்றிய தகவல்களையும் கொண்டுள்ளது).
நிச்சயமாக, இந்த வழியில் நீங்கள் அட்டவணைகள் பற்றி மட்டும் தகவல் பெற முடியும், ஆனால் பொதுவாக எந்த பொருள் பற்றி. அவ்வப்போது, அன்பானவர்கள் வெவ்வேறு தரவுத்தளங்களுக்கான குறியீட்டைப் பகிர்ந்து கொள்கிறார்கள், எடுத்துக்காட்டாக, ஹப்ரா கட்டுரைகளின் தொடரில் “PostgreSQL தரவுத்தளங்களை ஆவணப்படுத்துவதற்கான செயல்பாடுகள்” (, , ) நிச்சயமாக, இந்த முழு அளவிலான வினவல்களையும் என் தலையில் வைத்து, அவற்றைத் தொடர்ந்து தட்டச்சு செய்வது மிகவும் மகிழ்ச்சி அளிக்கிறது, எனவே எனக்குப் பிடித்த ஐடிஇ/எடிட்டரில் அடிக்கடி பயன்படுத்தப்படும் வினவல்களுக்கு முன்பே தயாரிக்கப்பட்ட துணுக்குகளின் தொகுப்பு உள்ளது, மேலும் தட்டச்சு செய்வது மட்டுமே மீதமுள்ளது. வார்ப்புருவில் பொருள் பெயர்கள்.
இதன் விளைவாக, வழிசெலுத்தல் மற்றும் பொருள்களைத் தேடும் இந்த முறை மிகவும் நெகிழ்வானது, நிறைய நேரத்தை மிச்சப்படுத்துகிறது, மேலும் இப்போது தேவையான வடிவத்தில் தகவல்களைப் பெற உங்களை அனுமதிக்கிறது (எடுத்துக்காட்டாக, இடுகையில் விவரிக்கப்பட்டுள்ளது ).
பொருள்களுடன் செயல்பாடுகள்
தேவையான பொருட்களைக் கண்டுபிடித்து ஆய்வு செய்த பிறகு, அவற்றுடன் பயனுள்ள ஒன்றைச் செய்ய வேண்டிய நேரம் இது. இயற்கையாகவே, உங்கள் விரல்களை விசைப்பலகையில் இருந்து எடுக்காமல்.
ஒரு அட்டவணையை நீக்குவது கிட்டத்தட்ட எல்லா தரவுத்தளங்களிலும் ஒரே மாதிரியாக இருக்கும் என்பது இரகசியமல்ல:
drop table hr.personsஆனால் அட்டவணையின் உருவாக்கத்துடன் அது மிகவும் சுவாரஸ்யமாகிறது. ஏறக்குறைய எந்த டிபிஎம்எஸ்ஸும் (பல NoSQL உட்பட) ஒரு வடிவத்தில் "அட்டவணையை உருவாக்க" முடியும், மேலும் அதன் முக்கிய பகுதி சற்று மாறுபடும் (பெயர், நெடுவரிசைகளின் பட்டியல், தரவு வகைகள்), ஆனால் மற்ற விவரங்கள் வியத்தகு முறையில் வேறுபடலாம் மற்றும் சார்ந்தது உள் சாதனம் மற்றும் ஒரு குறிப்பிட்ட DBMS இன் திறன்கள். எனக்கு பிடித்த உதாரணம், ஆரக்கிள் ஆவணத்தில் "அட்டவணையை உருவாக்கு" தொடரியல் "நிர்வாண" BNFகள் மட்டுமே உள்ளன. . மற்ற DBMS கள் மிகவும் எளிமையான திறன்களைக் கொண்டுள்ளன, ஆனால் அவை ஒவ்வொன்றும் அட்டவணைகளை உருவாக்குவதற்கான பல சுவாரஸ்யமான மற்றும் தனித்துவமான அம்சங்களைக் கொண்டுள்ளன (, , , ) மற்றொரு IDE (குறிப்பாக உலகளாவிய ஒன்று) இலிருந்து எந்த வரைகலை "விஜார்ட்" இந்த திறன்களை முழுமையாக மறைக்க முடியும் என்பது சாத்தியமில்லை, அது முடிந்தாலும் கூட, அது இதயத்தின் மயக்கத்திற்கு ஒரு காட்சியாக இருக்காது. அதே நேரத்தில், சரியான நேரத்தில் எழுதப்பட்ட அறிக்கை அட்டவணையை உருவாக்கவும் அவை அனைத்தையும் எளிதாகப் பயன்படுத்தவும், சேமிப்பகம் மற்றும் உங்கள் தரவை அணுகவும் நம்பகமானதாகவும், உகந்ததாகவும், முடிந்தவரை வசதியாகவும் உங்களை அனுமதிக்கும்.
மேலும், பல டிபிஎம்எஸ்கள் மற்ற டிபிஎம்எஸ்களில் இல்லாத குறிப்பிட்ட வகை பொருட்களைக் கொண்டுள்ளன. மேலும், தரவுத்தளப் பொருட்களில் மட்டுமின்றி, டிபிஎம்எஸ்ஸிலும் செயல்பாடுகளைச் செய்யலாம், எடுத்துக்காட்டாக, ஒரு செயல்முறையை "கொல்ல", சில நினைவகப் பகுதியை விடுவிக்க, டிரேஸிங்கை இயக்க, "படிக்க மட்டும்" பயன்முறைக்கு மாறவும் மற்றும் பல.
இப்போது கொஞ்சம் வரைவோம்
மிகவும் பொதுவான பணிகளில் ஒன்று, தரவுத்தள பொருள்களுடன் ஒரு வரைபடத்தை உருவாக்குவதும், அவற்றுக்கிடையே உள்ள பொருள்கள் மற்றும் இணைப்புகளை அழகான படத்தில் பார்ப்பதும் ஆகும். ஏறக்குறைய எந்த வரைகலை IDE, தனி "கட்டளை வரி" பயன்பாடுகள், சிறப்பு வரைகலை கருவிகள் மற்றும் மாடலர்கள் இதைச் செய்யலாம். அவர்கள் உங்களுக்காக எதையாவது "அவர்களால் முடிந்தவரை" வரைவார்கள், மேலும் உள்ளமைவு கோப்பில் உள்ள சில அளவுருக்கள் அல்லது இடைமுகத்தில் உள்ள தேர்வுப்பெட்டிகளின் உதவியுடன் மட்டுமே இந்த செயல்முறையை நீங்கள் சிறிது பாதிக்கலாம்.
ஆனால் இந்த சிக்கலை மிகவும் எளிமையான, மிகவும் நெகிழ்வான மற்றும் நேர்த்தியான, மற்றும் நிச்சயமாக குறியீட்டின் உதவியுடன் தீர்க்க முடியும். எந்தவொரு சிக்கலான வரைபடங்களையும் உருவாக்க, எங்களிடம் பல பிரத்யேக மார்க்அப் மொழிகள் (DOT, GraphML போன்றவை) உள்ளன, மேலும் அவற்றுக்கான முழு அளவிலான பயன்பாடுகள் (GraphViz, PlantUML, Mermaid) போன்ற வழிமுறைகளைப் படித்து அவற்றைப் பல்வேறு வடிவங்களில் காட்சிப்படுத்தலாம். . பொருள்கள் மற்றும் அவற்றுக்கிடையேயான இணைப்புகள் பற்றிய தகவல்களை எவ்வாறு பெறுவது என்பது எங்களுக்கு ஏற்கனவே தெரியும்.
PlantUML ஐப் பயன்படுத்தி இது எப்படி இருக்கும் என்பதற்கான சிறிய உதாரணம் இங்கே (இடதுபுறத்தில் ஒரு SQL வினவல் உள்ளது, இது PlantUML க்கு தேவையான வழிமுறைகளை உருவாக்கும், வலதுபுறம் முடிவு உள்ளது):
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
select '@enduml'நீங்கள் சிறிது முயற்சி செய்தால், அதன் அடிப்படையில் உண்மையான ER வரைபடத்தைப் போன்ற ஒன்றை நீங்கள் பெறலாம்:
SQL வினவல் இன்னும் கொஞ்சம் சிக்கலானது
-- Шапка
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Таблицы
select format('Table(%s, "%s n information about %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Связи между таблицами
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may haven many %s"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Подвал
select '@enduml'
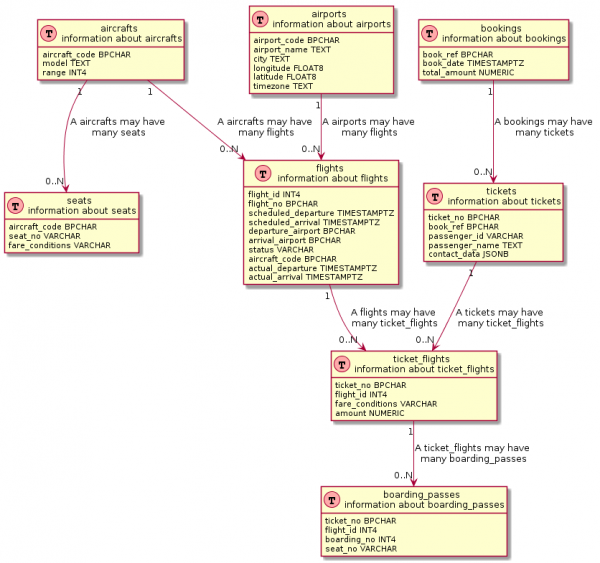
நீங்கள் உற்று நோக்கினால், பல காட்சிப்படுத்தல் கருவிகளும் இதே போன்ற வினவல்களைப் பயன்படுத்துகின்றன. உண்மை, இந்த கோரிக்கைகள் பொதுவாக ஆழமானவை , அவற்றில் எந்த மாற்றத்தையும் குறிப்பிடவில்லை.
அளவீடுகள் மற்றும் கண்காணிப்பு
பாரம்பரியமாக சிக்கலான தலைப்புக்கு செல்லலாம் - தரவுத்தள செயல்திறன் கண்காணிப்பு. "என் நண்பர்களில் ஒருவர்" என்னிடம் சொன்ன ஒரு சிறிய உண்மை கதை எனக்கு நினைவிருக்கிறது. மற்றொரு திட்டத்தில் ஒரு குறிப்பிட்ட சக்திவாய்ந்த டிபிஏ வாழ்ந்தார், மேலும் சில டெவலப்பர்கள் அவரை தனிப்பட்ட முறையில் அறிந்திருக்கிறார்கள், அல்லது அவரை நேரில் பார்த்திருக்கிறார்கள் (வதந்திகளின்படி, அவர் அடுத்த கட்டிடத்தில் எங்காவது பணிபுரிந்த போதிலும்) . "எக்ஸ்" மணி நேரத்தில், ஒரு பெரிய சில்லறை விற்பனையாளரின் உற்பத்தி முறை மீண்டும் "மோசமாக" உணரத் தொடங்கியபோது, அவர் ஆரக்கிள் எண்டர்பிரைஸ் மேலாளரிடமிருந்து வரைபடங்களின் ஸ்கிரீன் ஷாட்களை அமைதியாக அனுப்பினார், அதில் அவர் "புரிந்துகொள்ளுதல்" க்கான சிவப்பு மார்க்கருடன் முக்கியமான இடங்களை கவனமாக முன்னிலைப்படுத்தினார். இது, லேசாகச் சொன்னால், அதிகம் உதவவில்லை). இந்த "புகைப்பட அட்டை" அடிப்படையில் நான் சிகிச்சை செய்ய வேண்டியிருந்தது. அதே நேரத்தில், விலைமதிப்பற்ற (வார்த்தையின் இரு அர்த்தங்களிலும்) நிறுவன மேலாளரை யாரும் அணுகவில்லை, ஏனெனில் கணினி சிக்கலானது மற்றும் விலை உயர்ந்தது, திடீரென்று "டெவலப்பர்கள் எதையாவது தடுமாறி எல்லாவற்றையும் உடைக்கிறார்கள்." எனவே, டெவலப்பர்கள் "அனுபவ ரீதியாக" பிரேக்குகளின் இருப்பிடத்தையும் காரணத்தையும் கண்டுபிடித்து ஒரு பேட்சை வெளியிட்டனர். டிபிஏவிடமிருந்து அச்சுறுத்தும் கடிதம் எதிர்காலத்தில் மீண்டும் வரவில்லை என்றால், அனைவரும் நிம்மதிப் பெருமூச்சு விட்டுவிட்டு தங்கள் தற்போதைய பணிகளுக்கு (புதிய கடிதம் வரை) திரும்புவார்கள்.
ஆனால் கண்காணிப்பு செயல்முறை மிகவும் வேடிக்கையாகவும் நட்பாகவும் இருக்கும், மிக முக்கியமாக, அனைவருக்கும் அணுகக்கூடிய மற்றும் வெளிப்படையானது. குறைந்தபட்சம் அதன் அடிப்படை பகுதி, முக்கிய கண்காணிப்பு அமைப்புகளுக்கு கூடுதலாக (நிச்சயமாக பயனுள்ள மற்றும் பல சந்தர்ப்பங்களில் ஈடுசெய்ய முடியாதது). எந்தவொரு டிபிஎம்எஸ்ஸும் அதன் தற்போதைய நிலை மற்றும் செயல்திறன் பற்றிய தகவல்களைப் பகிர்ந்து கொள்ள இலவசம் மற்றும் முற்றிலும் இலவசம். அதே "இரத்தம் தோய்ந்த" ஆரக்கிள் DB இல், செயல்திறன் பற்றிய எந்தவொரு தகவலையும் கணினி பார்வைகளிலிருந்து பெறலாம், செயல்முறைகள் மற்றும் அமர்வுகள் முதல் இடையக தற்காலிக சேமிப்பின் நிலை வரை (உதாரணமாக, , பிரிவு "கண்காணிப்பு"). Postgresql க்கு கணினி பார்வைகளின் முழு தொகுப்பையும் கொண்டுள்ளது , குறிப்பாக எந்த DBA இன் அன்றாட வாழ்விலும் இன்றியமையாதவை, போன்றவை , , . MySQL இதற்கென ஒரு தனித் திட்டத்தைக் கொண்டுள்ளது. . ஏ இன் மோங்கோ உள்ளமைந்துள்ளது செயல்திறன் தரவை கணினி சேகரிப்பில் ஒருங்கிணைக்கிறது .
எனவே, தனிப்பயன் sql வினவல்களைச் செய்யக்கூடிய சில வகையான அளவீடுகள் சேகரிப்பான் (டெலிகிராஃப், மெட்ரிக்பீட், கலெக்ட்), இந்த அளவீடுகளின் சேமிப்பு (InfluxDB, Elasticsearch, Timescaledb) மற்றும் ஒரு விஷுவலைசர் (Grafana, Kibana) ஆகியவற்றைக் கொண்டு நீங்கள் எளிதாகப் பெறலாம். மற்றும் ஒரு நெகிழ்வான கண்காணிப்பு அமைப்பு மற்ற கணினி அளவிலான அளவீடுகளுடன் நெருக்கமாக ஒருங்கிணைக்கப்படும் (உதாரணமாக, பயன்பாட்டு சேவையகத்திலிருந்து, OS இலிருந்து பெறப்பட்டது). எடுத்துக்காட்டாக, இது pgwatch2 இல் செய்யப்படுகிறது, இது InfluxDB + Grafana கலவையைப் பயன்படுத்துகிறது மற்றும் கணினி பார்வைகளுக்கான வினவல்களின் தொகுப்பையும் பயன்படுத்துகிறது. .
மொத்தம்
இது வழக்கமான SQL குறியீட்டைப் பயன்படுத்தி எங்கள் தரவுத்தளத்தில் என்ன செய்ய முடியும் என்பதற்கான தோராயமான பட்டியல் மட்டுமே. நீங்கள் இன்னும் பல பயன்பாடுகளைக் காணலாம் என்று நான் நம்புகிறேன், கருத்துகளில் எழுதுங்கள். இதையெல்லாம் தானியங்குபடுத்துவது மற்றும் அடுத்த முறை உங்கள் CI/CD பைப்லைனில் எப்படி சேர்ப்பது என்பது பற்றி (மிக முக்கியமாக ஏன்) பேசுவோம்.
ஆதாரம்: www.habr.com
