

ఏప్రిల్ 27 సదస్సులో , “DevOps” విభాగంలో భాగంగా, “Autoscaling and resource management in Kubernetes” నివేదిక ఇవ్వబడింది. మీ అప్లికేషన్ల అధిక లభ్యతను నిర్ధారించడానికి మరియు గరిష్ట పనితీరును నిర్ధారించడానికి మీరు K8లను ఎలా ఉపయోగించవచ్చనే దాని గురించి ఇది మాట్లాడుతుంది.

సంప్రదాయం ప్రకారం, మేము ప్రదర్శించడానికి సంతోషిస్తున్నాము (44 నిమిషాలు, కథనం కంటే చాలా సమాచారం) మరియు టెక్స్ట్ రూపంలో ప్రధాన సారాంశం. వెళ్ళండి!
నివేదిక యొక్క అంశాన్ని పదం ద్వారా విశ్లేషించి, చివరి నుండి ప్రారంభిద్దాం.
Kubernetes
మా హోస్ట్లో డాకర్ కంటైనర్లు ఉన్నాయని అనుకుందాం. దేనికోసం? పునరావృతం మరియు ఐసోలేషన్ను నిర్ధారించడానికి, ఇది సరళమైన మరియు మంచి విస్తరణను అనుమతిస్తుంది, CI/CD. కంటైనర్లతో కూడిన ఇలాంటి వాహనాలు చాలా ఉన్నాయి.
ఈ సందర్భంలో కుబెర్నెట్స్ ఏమి అందిస్తుంది?
- మేము ఈ యంత్రాల గురించి ఆలోచించడం మానేస్తాము మరియు “క్లౌడ్”తో పని చేయడం ప్రారంభిస్తాము కంటైనర్ల క్లస్టర్ లేదా పాడ్లు (కంటైనర్ల సమూహాలు).
- అంతేకాకుండా, మేము వ్యక్తిగత పాడ్ల గురించి కూడా ఆలోచించము, కానీ మరిన్నింటిని నిర్వహిస్తాముоపెద్ద సమూహాలు. అటువంటి ఉన్నత స్థాయి ఆదిమానవులు నిర్దిష్ట పనిభారాన్ని అమలు చేయడానికి ఒక టెంప్లేట్ ఉందని మరియు దానిని అమలు చేయడానికి అవసరమైన సందర్భాల సంఖ్య ఇక్కడ ఉందని చెప్పడానికి మమ్మల్ని అనుమతిస్తుంది. మేము తరువాత టెంప్లేట్ను మార్చినట్లయితే, అన్ని సందర్భాలు మారుతాయి.
- సహాయంతో డిక్లరేటివ్ API నిర్దిష్ట ఆదేశాల క్రమాన్ని అమలు చేయడానికి బదులుగా, మేము "ప్రపంచం యొక్క నిర్మాణం" (YAMLలో) గురించి వివరిస్తాము, ఇది కుబెర్నెటెస్చే సృష్టించబడింది. మరియు మళ్లీ: వివరణ మారినప్పుడు, దాని వాస్తవ ప్రదర్శన కూడా మారుతుంది.
వనరుల నిర్వహణ
CPU
సర్వర్లో nginx, php-fpm మరియు mysqlలను అమలు చేద్దాం. ఈ సేవలు వాస్తవానికి మరింత ఎక్కువ ప్రక్రియలను కలిగి ఉంటాయి, వీటిలో ప్రతిదానికి కంప్యూటింగ్ వనరులు అవసరం:
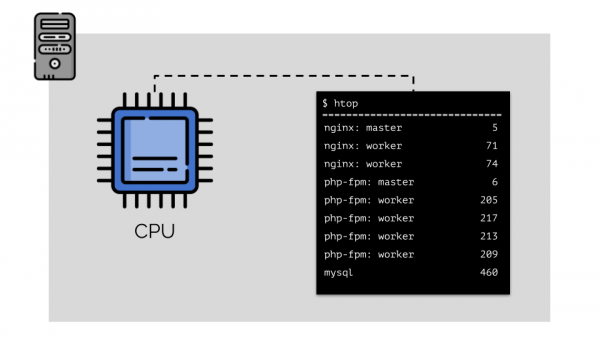
(స్లైడ్లోని సంఖ్యలు “చిలుకలు”, కంప్యూటింగ్ పవర్ కోసం ప్రతి ప్రక్రియ యొక్క నైరూప్య అవసరం)
దీనితో పని చేయడం సులభతరం చేయడానికి, ప్రక్రియలను సమూహాలుగా కలపడం తార్కికం (ఉదాహరణకు, అన్ని nginx ప్రక్రియలు ఒక సమూహంగా "nginx"). దీన్ని చేయడానికి సులభమైన మరియు స్పష్టమైన మార్గం ఏమిటంటే, ప్రతి సమూహాన్ని కంటైనర్లో ఉంచడం:
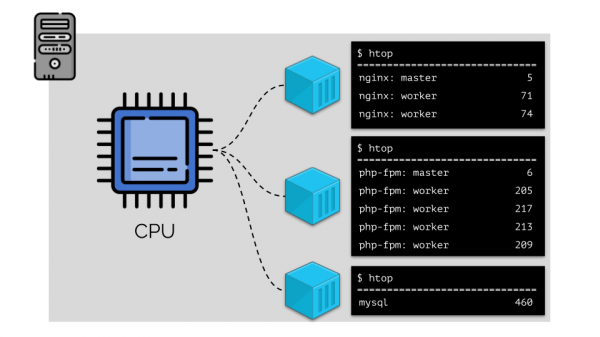
కొనసాగించడానికి, కంటైనర్ అంటే ఏమిటో మనం గుర్తుంచుకోవాలి (లో Linuxచాలా కాలం క్రితమే అమలు చేయబడిన కెర్నల్లోని మూడు కీలక ఫీచర్ల వల్ల వాటి ఆవిర్భావం సాధ్యమైంది: , и . మరియు ఇతర సాంకేతికతలు (డాకర్ వంటి అనుకూలమైన "షెల్స్"తో సహా) మరింత అభివృద్ధిని సులభతరం చేశాయి:
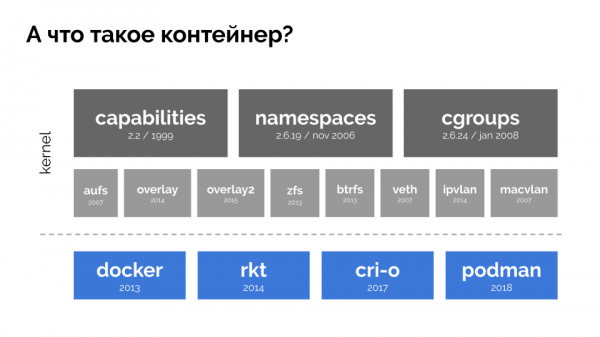
నివేదిక సందర్భంలో, మేము మాత్రమే ఆసక్తి కలిగి ఉన్నాము cgroups, ఎందుకంటే నియంత్రణ సమూహాలు వనరుల నిర్వహణను అమలు చేసే కంటైనర్ల (డాకర్, మొదలైనవి) కార్యాచరణలో భాగం. మేము కోరుకున్నట్లు సమూహాలుగా కలిపిన ప్రక్రియలు నియంత్రణ సమూహాలు.
ఈ ప్రక్రియల కోసం CPU అవసరాలకు తిరిగి వెళ్దాం మరియు ఇప్పుడు ప్రక్రియల సమూహాల కోసం:
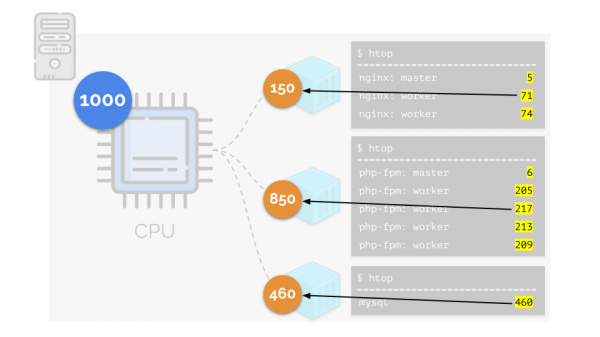
(అన్ని సంఖ్యలు వనరుల అవసరం యొక్క నైరూప్య వ్యక్తీకరణ అని నేను పునరావృతం చేస్తున్నాను)
అదే సమయంలో, CPU కూడా నిర్దిష్ట పరిమిత వనరును కలిగి ఉంటుంది (ఉదాహరణలో ఇది 1000), ఇది ప్రతి ఒక్కరికీ లోపించవచ్చు (అన్ని సమూహాల అవసరాల మొత్తం 150+850+460=1460). ఈ సందర్భంలో ఏమి జరుగుతుంది?
కెర్నల్ వనరులను పంపిణీ చేయడం ప్రారంభిస్తుంది మరియు ప్రతి సమూహానికి అదే మొత్తంలో వనరులను అందజేస్తూ "చాలా" చేస్తుంది. కానీ మొదటి సందర్భంలో, వాటిలో అవసరమైన దానికంటే ఎక్కువ ఉన్నాయి (333>150), కాబట్టి అదనపు (333-150=183) నిల్వలో ఉంటుంది, ఇది రెండు ఇతర కంటైనర్ల మధ్య సమానంగా పంపిణీ చేయబడుతుంది:
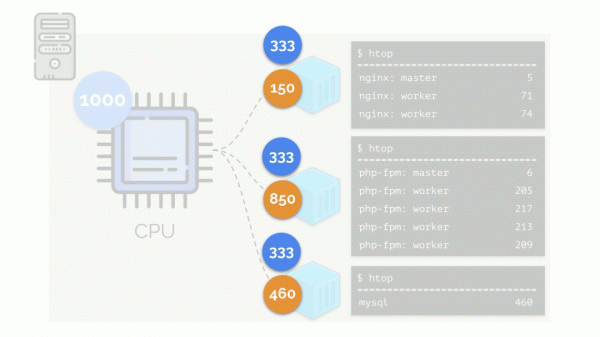
ఫలితంగా: మొదటి కంటైనర్ తగినంత వనరులను కలిగి ఉంది, రెండవది - దీనికి తగినంత వనరులు లేవు, మూడవది - దీనికి తగినంత వనరులు లేవు. ఇది చర్యల ఫలితం "నిజాయితీగల" ప్రణాళికాదారుడు Linux - . అసైన్మెంట్ని ఉపయోగించి దీని ఆపరేషన్ని సర్దుబాటు చేయవచ్చు బరువులు కంటైనర్లు ప్రతి. ఉదాహరణకు, ఇలా:
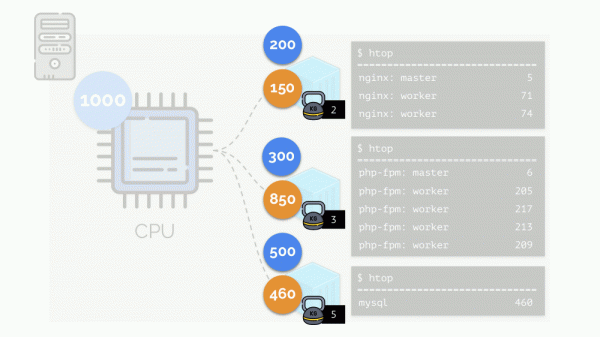
రెండవ కంటైనర్ (php-fpm) లో వనరుల కొరత విషయంలో చూద్దాం. అన్ని కంటైనర్ వనరులు ప్రక్రియల మధ్య సమానంగా పంపిణీ చేయబడతాయి. ఫలితంగా, మాస్టర్ ప్రాసెస్ బాగా పనిచేస్తుంది, కానీ కార్మికులందరూ వేగాన్ని తగ్గించారు, వారికి అవసరమైన దానిలో సగం కంటే తక్కువ పొందుతారు:
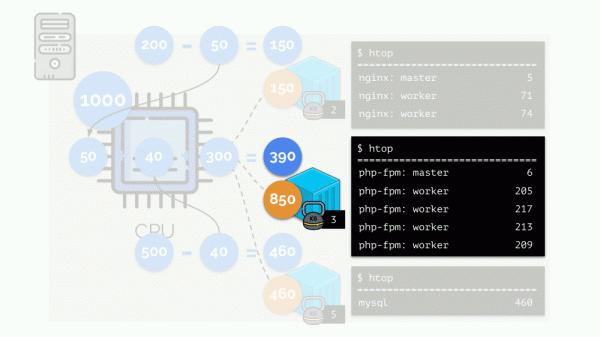
ఈ విధంగా CFS షెడ్యూలర్ పని చేస్తుంది. మేము కంటైనర్లకు కేటాయించే బరువులను మరింత పిలుస్తాము అభ్యర్థనలు. ఇది ఎందుకు జరిగింది - మరింత చూడండి.
మొత్తం పరిస్థితిని మరొక వైపు నుండి చూద్దాం. మీకు తెలిసినట్లుగా, అన్ని రోడ్లు రోమ్కి మరియు కంప్యూటర్ విషయంలో CPUకి దారి తీస్తాయి. ఒక CPU, అనేక పనులు - మీకు ట్రాఫిక్ లైట్ అవసరం. వనరులను నిర్వహించడానికి సులభమైన మార్గం “ట్రాఫిక్ లైట్”: వారు ఒక ప్రాసెస్కు CPUకి స్థిరమైన యాక్సెస్ సమయాన్ని ఇచ్చారు, తర్వాత తదుపరిది మొదలైనవి.
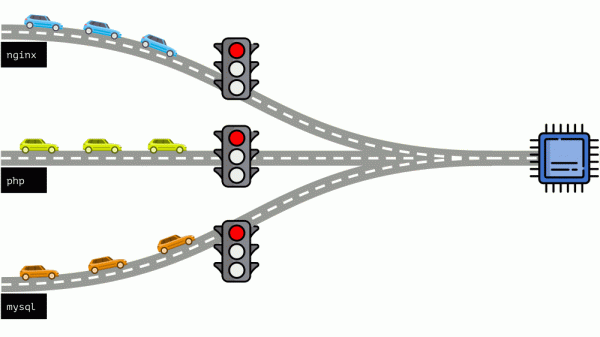
ఈ విధానాన్ని హార్డ్ కోటాలు అంటారు (కఠినమైన పరిమితి). సింపుల్ గా గుర్తు చేసుకుందాం పరిమితులు. అయినప్పటికీ, మీరు అన్ని కంటైనర్లకు పరిమితులను పంపిణీ చేస్తే, ఒక సమస్య తలెత్తుతుంది: mysql రహదారిపై డ్రైవింగ్ చేస్తోంది మరియు ఏదో ఒక సమయంలో దాని CPU అవసరం ముగిసింది, కానీ అన్ని ఇతర ప్రక్రియలు CPU వరకు వేచి ఉండవలసి వస్తుంది. పనిలేకుండా.
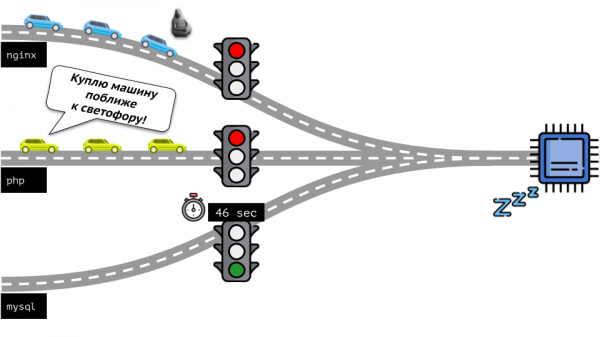
మనం అసలు విషయానికి తిరిగి వెళ్దాం. Linux మరియు CPUతో దాని పరస్పర చర్య - మొత్తం చిత్రం ఈ క్రింది విధంగా ఉంది:
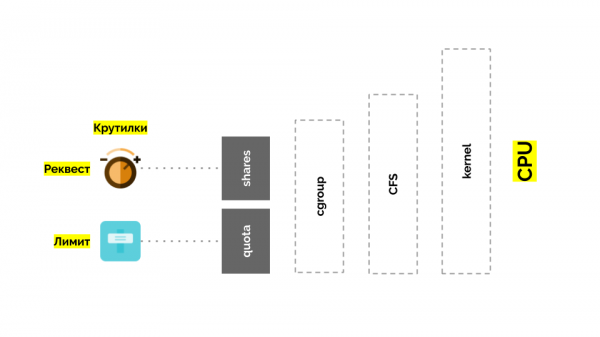
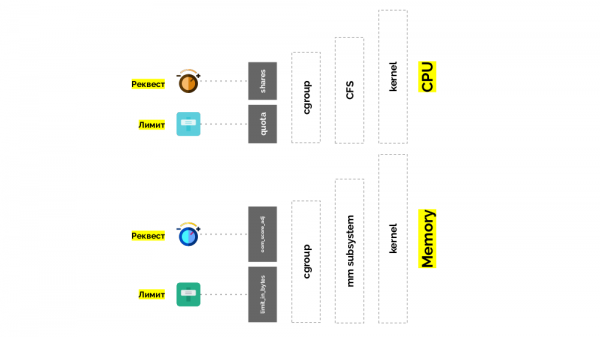
cgroupలో రెండు సెట్టింగులు ఉన్నాయి - ముఖ్యంగా ఇవి రెండు సాధారణ “ట్విస్ట్లు”, ఇవి మిమ్మల్ని గుర్తించడానికి అనుమతిస్తాయి:
- కంటైనర్ కోసం బరువు (అభ్యర్థనలు) ఉంది షేర్లు;
- కంటైనర్ టాస్క్లపై పని చేయడానికి మొత్తం CPU సమయం (పరిమితులు) శాతం కోటా.
CPUని ఎలా కొలవాలి?
వివిధ మార్గాలు ఉన్నాయి:
- ఏం చిలుకలు, ఎవరికీ తెలియదు - మీరు ప్రతిసారీ చర్చలు జరపాలి.
- వడ్డీ స్పష్టంగా, కానీ సాపేక్షంగా: 50 కోర్లు మరియు 4 కోర్లతో సర్వర్లో 20% పూర్తిగా భిన్నమైన విషయాలు.
- మీరు ఇప్పటికే పేర్కొన్న వాటిని ఉపయోగించవచ్చు బరువులుఅతనికి తెలిసిన Linuxకానీ అవి సాపేక్షమైనవి కూడా.
- కంప్యూటింగ్ వనరులను కొలవడం చాలా సరిఅయిన ఎంపిక సెకన్లు. ఆ. రియల్ టైమ్ సెకన్లకు సంబంధించి ప్రాసెసర్ సమయం యొక్క సెకన్లలో: 1 రియల్ సెకనుకు 1 సెకను ప్రాసెసర్ సమయం ఇవ్వబడింది - ఇది మొత్తం CPU కోర్.
మాట్లాడటం మరింత సులభతరం చేయడానికి, వారు నేరుగా కొలవడం ప్రారంభించారు కెర్నలు, అంటే వాటి ప్రకారం వాస్తవమైన దానితో పోలిస్తే అదే CPU సమయం. ఎందుకంటే Linux వెయిట్స్ను అర్థం చేసుకుంటుంది, కానీ ప్రాసెసర్ టైమ్/కోర్స్ను కాదు, కాబట్టి ఒకదాని నుండి మరొకదానికి మార్చడానికి ఒక యంత్రాంగం అవసరమైంది.
3 CPU కోర్లతో సర్వర్తో ఒక సాధారణ ఉదాహరణను పరిశీలిద్దాం, ఇక్కడ మూడు పాడ్లకు బరువులు (500, 1000 మరియు 1500) ఇవ్వబడతాయి, అవి వాటికి కేటాయించిన కోర్ల సంబంధిత భాగాలుగా సులభంగా మార్చబడతాయి (0,5, 1 మరియు 1,5).
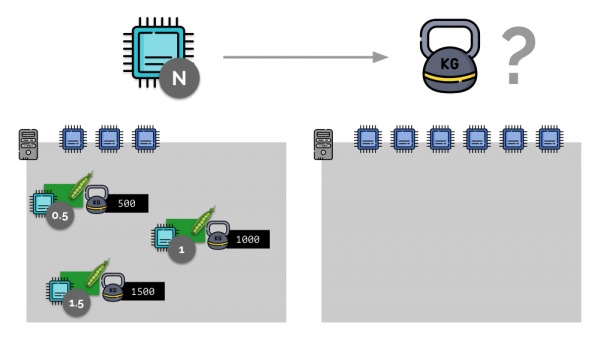
మీరు రెండవ సర్వర్ని తీసుకుంటే, అక్కడ రెండు రెట్లు ఎక్కువ కోర్లు (6) ఉంటాయి మరియు అదే పాడ్లను అక్కడ ఉంచినట్లయితే, కోర్ల పంపిణీని 2 (వరుసగా 1, 2 మరియు 3) ద్వారా గుణించడం ద్వారా సులభంగా లెక్కించవచ్చు. కానీ ఈ సర్వర్లో నాల్గవ పాడ్ కనిపించినప్పుడు ఒక ముఖ్యమైన క్షణం సంభవిస్తుంది, దీని బరువు సౌలభ్యం కోసం 3000 ఉంటుంది. ఇది CPU వనరులలో కొంత భాగాన్ని (సగం కోర్లు) తీసివేస్తుంది మరియు మిగిలిన పాడ్ల కోసం అవి మళ్లీ లెక్కించబడతాయి (సగం):
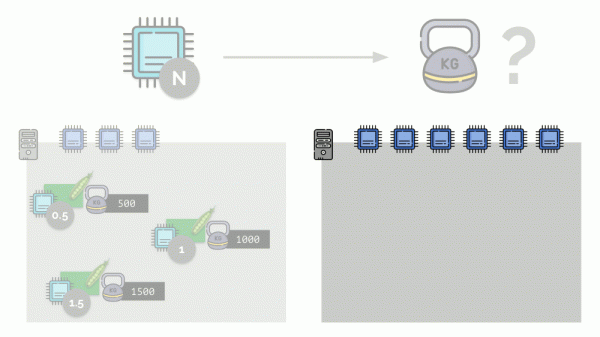
కుబెర్నెట్స్ మరియు CPU వనరులు
కుబెర్నెట్స్లో, CPU వనరులను సాధారణంగా కొలుస్తారు మిల్లీడ్రాక్స్, అనగా 0,001 కోర్లను బేస్ వెయిట్గా తీసుకుంటారు. (పదజాలంలో అదే) Linux/cగ్రూపులను CPU షేర్లు అని పిలుస్తారు, అయితే, మరింత కచ్చితంగా చెప్పాలంటే, 1000 మిల్లీకోర్లు = 1024 CPU షేర్లు.) K8s అన్ని పాడ్ల బరువుల మొత్తానికి CPU వనరుల కంటే ఎక్కువ పాడ్లను సర్వర్లో ఉంచదని నిర్ధారిస్తుంది.
ఇది ఎలా జరుగుతుంది? మీరు Kubernetes క్లస్టర్కి సర్వర్ని జోడించినప్పుడు, అది ఎన్ని CPU కోర్లు అందుబాటులో ఉందో నివేదించబడుతుంది. మరియు కొత్త పాడ్ని క్రియేట్ చేస్తున్నప్పుడు, ఈ పాడ్కి ఎన్ని కోర్లు అవసరమో కుబెర్నెట్స్ షెడ్యూలర్కు తెలుసు. అందువలన, పాడ్ తగినంత కోర్లు ఉన్న సర్వర్కు కేటాయించబడుతుంది.
ఉంటే ఏమవుతుంది కాదు అభ్యర్థన పేర్కొనబడింది (అనగా పాడ్కు అవసరమైన కోర్ల సంఖ్యను నిర్వచించలేదా)? కుబెర్నెట్స్ సాధారణంగా వనరులను ఎలా లెక్కిస్తారో తెలుసుకుందాం.
పాడ్ కోసం, మీరు అభ్యర్థనలు (CFS షెడ్యూలర్) మరియు పరిమితులు రెండింటినీ పేర్కొనవచ్చు (ట్రాఫిక్ లైట్ గుర్తుందా?):
- అవి సమానంగా పేర్కొనబడితే, పాడ్కి QoS తరగతి కేటాయించబడుతుంది హామీ. దీనికి ఎల్లప్పుడూ అందుబాటులో ఉండే ఈ కోర్ల సంఖ్య హామీ ఇవ్వబడుతుంది.
- అభ్యర్థన పరిమితి కంటే తక్కువగా ఉంటే - QoS తరగతి పగిలిపోయే. ఆ. మేము ఒక పాడ్, ఉదాహరణకు, ఎల్లప్పుడూ 1 కోర్ని ఉపయోగించాలని ఆశిస్తున్నాము, కానీ ఈ విలువ దానికి పరిమితి కాదు: కొన్నిసార్లు పాడ్ మరింత ఉపయోగించవచ్చు (సర్వర్ దీని కోసం ఉచిత వనరులను కలిగి ఉన్నప్పుడు).
- QoS తరగతి కూడా ఉంది ఉత్తమ ప్రయత్నం - ఇది అభ్యర్థనను పేర్కొనని అదే పాడ్లను కలిగి ఉంటుంది. వనరులు వారికి చివరిగా ఇవ్వబడతాయి.
మెమరీ
జ్ఞాపకశక్తితో, పరిస్థితి సారూప్యంగా ఉంటుంది, కానీ కొద్దిగా భిన్నంగా ఉంటుంది - అన్ని తరువాత, ఈ వనరుల స్వభావం భిన్నంగా ఉంటుంది. సాధారణంగా, సారూప్యత క్రింది విధంగా ఉంటుంది:
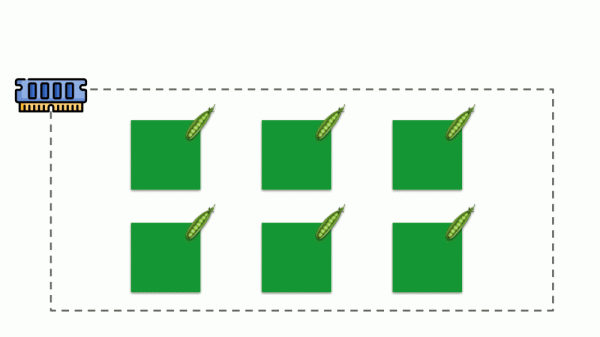
మెమరీలో అభ్యర్థనలు ఎలా అమలు చేయబడతాయో చూద్దాం. పాడ్లు సర్వర్లో జీవించనివ్వండి, మెమరీ వినియోగాన్ని మారుస్తుంది, వాటిలో ఒకటి మెమరీ అయిపోయేంత వరకు పెద్దదిగా మారుతుంది. ఈ సందర్భంలో, OOM కిల్లర్ కనిపిస్తుంది మరియు అతిపెద్ద ప్రక్రియను చంపుతుంది:
ఇది ఎల్లప్పుడూ మాకు సరిపోదు, కాబట్టి ఏ ప్రక్రియలు మనకు ముఖ్యమైనవి మరియు చంపబడకూడదో నియంత్రించడం సాధ్యమవుతుంది. దీన్ని చేయడానికి, పరామితిని ఉపయోగించండి ఓమ్_స్కోర్_adj.
CPU యొక్క QoS తరగతులకు తిరిగి వెళ్లి, పాడ్ల కోసం మెమరీ వినియోగ ప్రాధాన్యతలను నిర్ణయించే oom_score_adj విలువలతో సారూప్యతను గీయండి:
- పాడ్ కోసం అతి తక్కువ oom_score_adj విలువ - -998 - అంటే అటువంటి పాడ్ను చివరిగా చంపాలి, ఇది హామీ.
- అత్యధిక - 1000 - ఉంది ఉత్తమ ప్రయత్నం, అటువంటి కాయలు మొదట చంపబడతాయి.
- మిగిలిన విలువలను లెక్కించేందుకు (పగిలిపోయే) ఒక ఫార్ములా ఉంది, దాని సారాంశం పాడ్ ఎంత ఎక్కువ వనరులను కోరితే, అది చంపబడే అవకాశం తక్కువగా ఉంటుంది.

రెండవ "ట్విస్ట్" - బైట్లలో_పరిమితి - పరిమితుల కోసం. దానితో, ప్రతిదీ సరళమైనది: మేము జారీ చేసిన మెమరీ యొక్క గరిష్ట మొత్తాన్ని కేటాయిస్తాము మరియు ఇక్కడ (CPU వలె కాకుండా) దానిని (మెమరీ) ఎలా కొలవాలి అనే ప్రశ్న లేదు.
మొత్తం
కుబెర్నెట్స్లోని ప్రతి పాడ్ ఇవ్వబడుతుంది requests и limits - CPU మరియు మెమరీ కోసం రెండు పారామితులు:
- అభ్యర్థనల ఆధారంగా, కుబెర్నెట్స్ షెడ్యూలర్ పని చేస్తుంది, ఇది సర్వర్ల మధ్య పాడ్లను పంపిణీ చేస్తుంది;
- అన్ని పారామితుల ఆధారంగా, పాడ్ యొక్క QoS తరగతి నిర్ణయించబడుతుంది;
- సంబంధిత బరువులు CPU అభ్యర్థనల ఆధారంగా లెక్కించబడతాయి;
- CFS షెడ్యూలర్ CPU అభ్యర్థనల ఆధారంగా కాన్ఫిగర్ చేయబడింది;
- OOM కిల్లర్ మెమరీ అభ్యర్థనల ఆధారంగా కాన్ఫిగర్ చేయబడింది;
- CPU పరిమితుల ఆధారంగా "ట్రాఫిక్ లైట్" కాన్ఫిగర్ చేయబడింది;
- మెమరీ పరిమితుల ఆధారంగా, cgroup కోసం పరిమితి కాన్ఫిగర్ చేయబడింది.
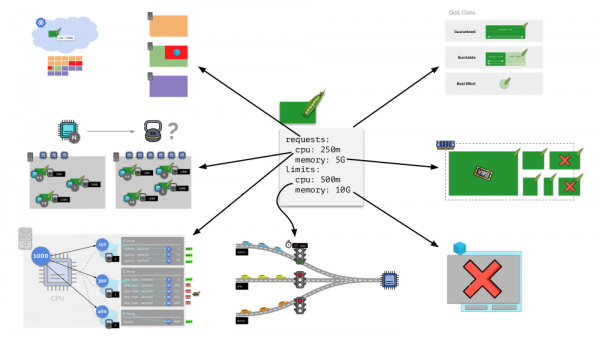
సాధారణంగా, ఈ చిత్రం కుబెర్నెట్స్లో వనరుల నిర్వహణ యొక్క ప్రధాన భాగం ఎలా జరుగుతుందనే దాని గురించి అన్ని ప్రశ్నలకు సమాధానమిస్తుంది.
ఆటోస్కేలింగ్
K8s క్లస్టర్-ఆటోస్కేలర్
మొత్తం క్లస్టర్ ఇప్పటికే ఆక్రమించబడిందని మరియు కొత్త పాడ్ని సృష్టించాల్సిన అవసరం ఉందని ఊహించుకుందాం. పాడ్ కనిపించనప్పటికీ, అది స్థితిలో వేలాడుతోంది పెండింగ్. అది కనిపించడం కోసం, మేము క్లస్టర్కి కొత్త సర్వర్ని కనెక్ట్ చేయవచ్చు లేదా... క్లస్టర్-ఆటోస్కేలర్ని ఇన్స్టాల్ చేయవచ్చు, ఇది మన కోసం చేస్తుంది: క్లౌడ్ ప్రొవైడర్ నుండి వర్చువల్ మెషీన్ను ఆర్డర్ చేయండి (API అభ్యర్థనను ఉపయోగించి) మరియు దానిని క్లస్టర్కి కనెక్ట్ చేయండి , దాని తర్వాత పాడ్ జోడించబడుతుంది.
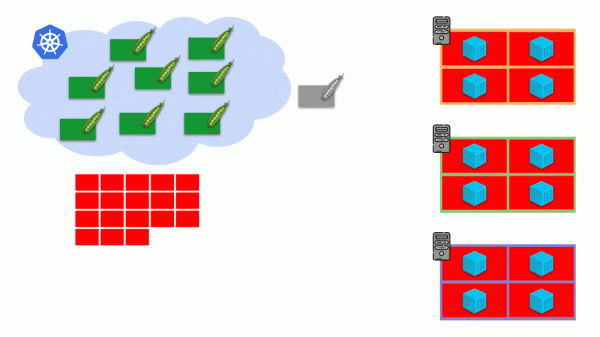
ఇది కుబెర్నెట్స్ క్లస్టర్ యొక్క ఆటోస్కేలింగ్, ఇది గొప్పగా పనిచేస్తుంది (మా అనుభవంలో). అయితే, ఇతర చోట్ల వలె, ఇక్కడ కొన్ని సూక్ష్మ నైపుణ్యాలు ఉన్నాయి ...
మేము క్లస్టర్ పరిమాణాన్ని పెంచినంత కాలం, అంతా బాగానే ఉంది, అయితే క్లస్టర్లో ఏమి జరుగుతుంది తనను తాను విడిపించుకోవడం ప్రారంభించాడు? సమస్య ఏమిటంటే, పాడ్లను తరలించడం (హోస్ట్లను ఖాళీ చేయడానికి) చాలా సాంకేతికంగా కష్టం మరియు వనరుల పరంగా ఖరీదైనది. Kubernetes పూర్తిగా భిన్నమైన విధానాన్ని ఉపయోగిస్తుంది.
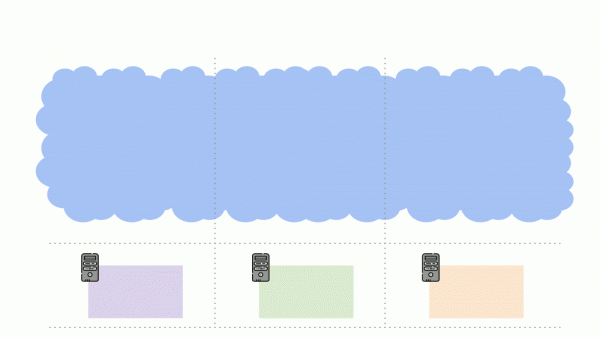
డిప్లాయ్మెంట్ ఉన్న 3 సర్వర్ల క్లస్టర్ను పరిగణించండి. ఇది 6 పాడ్లను కలిగి ఉంది: ఇప్పుడు ప్రతి సర్వర్కు 2 ఉన్నాయి. కొన్ని కారణాల వల్ల మేము సర్వర్లలో ఒకదాన్ని ఆఫ్ చేయాలనుకుంటున్నాము. దీన్ని చేయడానికి, మేము ఆదేశాన్ని ఉపయోగిస్తాము kubectl drain, ఇది:
- ఈ సర్వర్కి కొత్త పాడ్లను పంపడాన్ని నిషేధిస్తుంది;
- సర్వర్లో ఇప్పటికే ఉన్న పాడ్లను తొలగిస్తుంది.
పాడ్ల సంఖ్యను (6) నిర్వహించడానికి కుబెర్నెటెస్ బాధ్యత వహిస్తాడు కాబట్టి, ఇది కేవలం పునఃసృష్టి చేస్తుంది కొత్త పాడ్లను హోస్ట్ చేయడానికి ఇది ఇప్పటికే అందుబాటులో లేదని గుర్తించబడినందున, వాటిని ఇతర నోడ్లలో, కానీ నిలిపివేయబడిన వాటిపై కాదు. ఇది కుబెర్నెటీస్కు ప్రాథమిక మెకానిక్.
అయితే, ఇక్కడ కూడా ఒక స్వల్పభేదం ఉంది. ఇదే విధమైన పరిస్థితిలో, స్టేట్ఫుల్సెట్ (డిప్లాయ్మెంట్కు బదులుగా), చర్యలు భిన్నంగా ఉంటాయి. ఇప్పుడు మనకు ఇప్పటికే స్టేట్ఫుల్ అప్లికేషన్ ఉంది - ఉదాహరణకు, మొంగోడిబితో ఉన్న మూడు పాడ్లు, వాటిలో ఒక రకమైన సమస్య ఉంది (డేటా పాడైంది లేదా పాడ్ సరిగ్గా ప్రారంభించకుండా నిరోధించే మరొక లోపం). మరియు మేము మళ్లీ ఒక సర్వర్ని నిలిపివేయాలని నిర్ణయించుకున్నాము. ఏమి జరుగుతుంది?
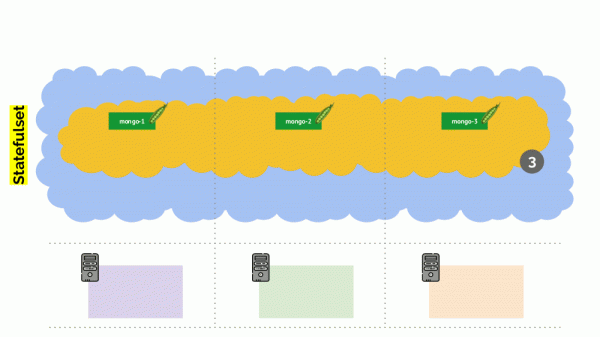
MongoDB కాలేదు డై ఎందుకంటే దీనికి కోరం అవసరం: మూడు ఇన్స్టాలేషన్ల క్లస్టర్ కోసం, కనీసం రెండు తప్పనిసరిగా పనిచేయాలి. అయితే, ఈ జరగడం లేదు - ధన్యవాదాలు PodDisruptionBudget. ఈ పరామితి పని చేసే పాడ్ల కనీస అవసరమైన సంఖ్యను నిర్ణయిస్తుంది. MongoDB పాడ్లలో ఒకటి ఇప్పుడు పని చేయడం లేదని తెలుసుకోవడం మరియు MongoDB కోసం PodDisruptionBudget సెట్ చేయబడిందని తెలుసుకోవడం minAvailable: 2, Kubernetes పాడ్ను తొలగించడానికి మిమ్మల్ని అనుమతించదు.
బాటమ్ లైన్: క్లస్టర్ విడుదలైనప్పుడు పాడ్ల కదలిక (మరియు వాస్తవానికి, పునఃసృష్టి) సరిగ్గా పని చేయడానికి, PodDisruptionBudgetని కాన్ఫిగర్ చేయడం అవసరం.
క్షితిజసమాంతర స్కేలింగ్
మరొక పరిస్థితిని పరిశీలిద్దాం. కుబెర్నెట్స్లో డిప్లాయ్మెంట్గా ఒక అప్లికేషన్ నడుస్తోంది. వినియోగదారు ట్రాఫిక్ దాని పాడ్లకు వస్తుంది (ఉదాహరణకు, వాటిలో మూడు ఉన్నాయి), మరియు మేము వాటిలో ఒక నిర్దిష్ట సూచికను కొలుస్తాము (చెప్పండి, CPU లోడ్). లోడ్ పెరిగినప్పుడు, మేము దీన్ని షెడ్యూల్లో రికార్డ్ చేస్తాము మరియు అభ్యర్థనలను పంపిణీ చేయడానికి పాడ్ల సంఖ్యను పెంచుతాము.
ఈ రోజు కుబెర్నెట్స్లో ఇది మానవీయంగా చేయవలసిన అవసరం లేదు: కొలిచిన లోడ్ సూచికల విలువలను బట్టి పాడ్ల సంఖ్యలో స్వయంచాలక పెరుగుదల / తగ్గుదల కాన్ఫిగర్ చేయబడింది.
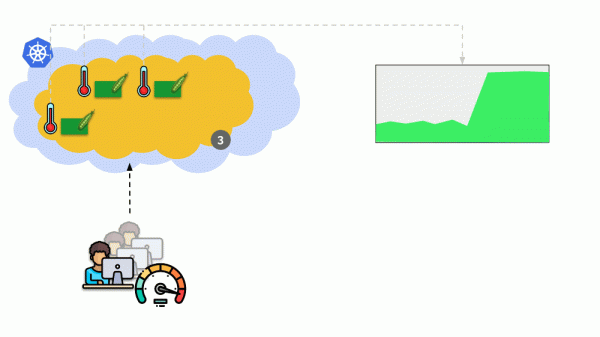
ఇక్కడ ప్రధాన ప్రశ్నలు: సరిగ్గా ఏమి కొలవాలి и ఎలా అర్థం చేసుకోవాలి పొందిన విలువలు (పాడ్ల సంఖ్యను మార్చడంపై నిర్ణయం తీసుకోవడానికి). మీరు చాలా కొలవవచ్చు:

సాంకేతికంగా దీన్ని ఎలా చేయాలి - కొలమానాలు, మొదలైనవి సేకరించండి. - గురించి నేను నివేదికలో వివరంగా మాట్లాడాను . మరియు సరైన పారామితులను ఎంచుకోవడానికి ప్రధాన సలహా ప్రయోగం!
ఉన్నాయి (యుటిలైజేషన్ సంతృప్తత మరియు లోపాలు), దీని అర్థం క్రింది విధంగా ఉంది. ఏ ప్రాతిపదికన స్కేల్ చేయడం సమంజసం, ఉదాహరణకు, php-fpm? కార్మికులు అయిపోతున్నారనే వాస్తవం ఆధారంగా, ఇది వినియోగం. మరియు కార్మికులు అయిపోయినట్లయితే మరియు కొత్త కనెక్షన్లు అంగీకరించబడకపోతే, ఇది ఇప్పటికే ఉంది సంతృప్తత. ఈ రెండు పారామితులు తప్పనిసరిగా కొలవబడాలి మరియు విలువలను బట్టి, స్కేలింగ్ తప్పనిసరిగా నిర్వహించబడాలి.
ముగింపుకు బదులుగా
నివేదికకు కొనసాగింపు ఉంది: నిలువు స్కేలింగ్ గురించి మరియు సరైన వనరులను ఎలా ఎంచుకోవాలి. నేను దీని గురించి భవిష్యత్ వీడియోలలో మాట్లాడతాను - సబ్స్క్రయిబ్ చేసుకోండి కాబట్టి మీరు మిస్ అవ్వకండి!
వీడియోలు మరియు స్లయిడ్లు
ప్రదర్శన నుండి వీడియో (44 నిమిషాలు):

నివేదిక ప్రదర్శన:
PS
మా బ్లాగులో Kubernetes గురించి ఇతర నివేదికలు:
- «» (ఆండ్రీ పోలోవోవ్; ఏప్రిల్ 8, 2019 సెయింట్ హైలోడ్++లో);
- «» (డిమిత్రి స్టోలియారోవ్; నవంబర్ 8, 2018 హైలోడ్++లో);
- «» (డిమిత్రి స్టోలియారోవ్; మే 28, 2018 రూట్కాన్ఫ్లో);
- «» (డిమిత్రి స్టోలియారోవ్; నవంబర్ 7, 2017 హైలోడ్++లో);
- «» (డిమిత్రి స్టోలియారోవ్; జూన్ 6, 2017 రూట్కాన్ఫ్లో).
మూలం: www.habr.com
